什么是AD-AIDC?AD-AIDC包括哪些关键技术?
笔记转载自:“H3C ICT知识百科”
什么是AD-AIDC?
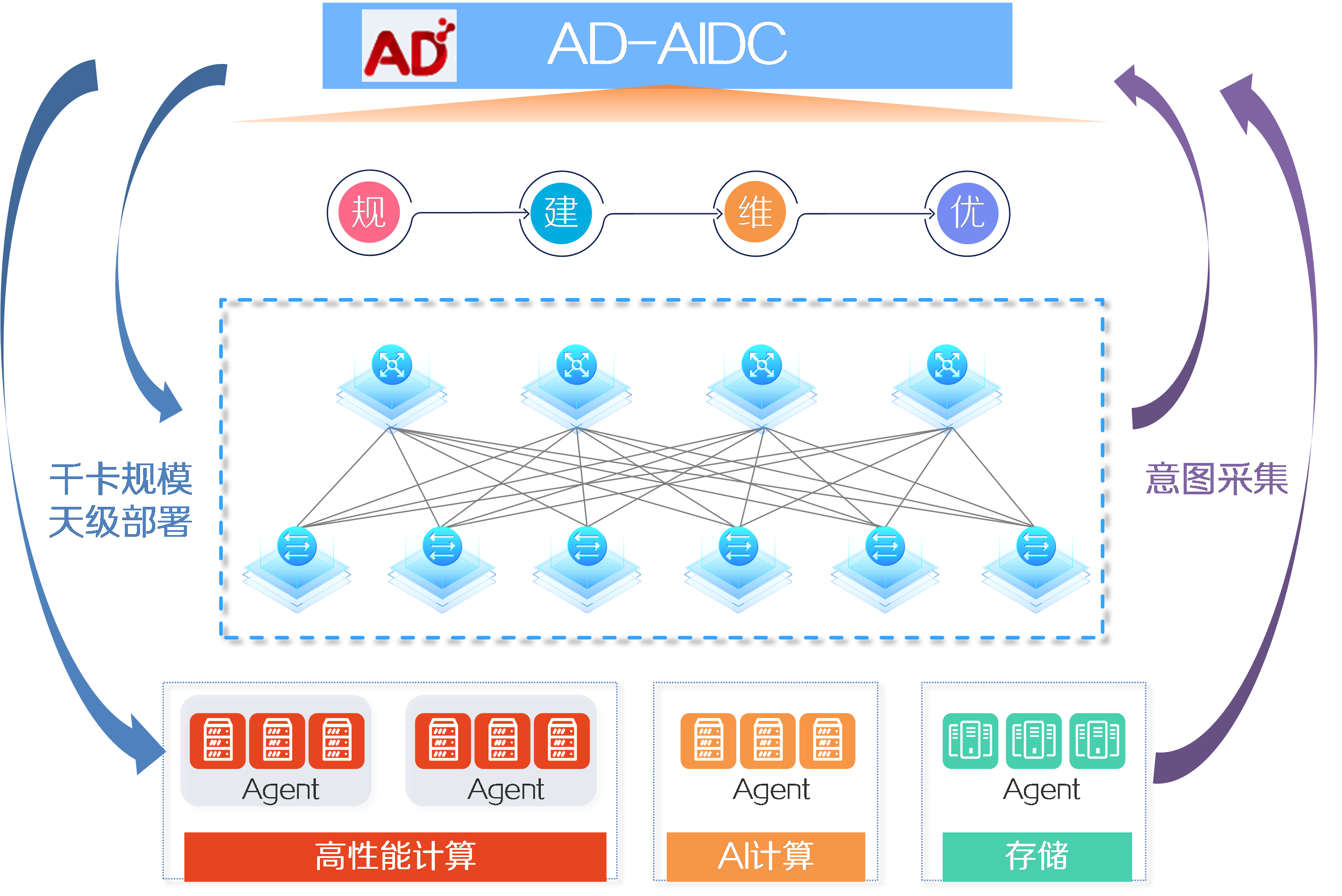
AD-AIDC(Application-Driven Artificial Intelligence Data Center,应用驱动的人工智能数据中心),是新华三专门为AI算力集群和模型训练场景打造的全栈智能管控方案,也叫“AD-DC智算版”。它就像AI数据中心的“大脑”,能够将计算、网络和存储等核心资源统一管理并高效协同,解决传统AI数据中心在部署和运维过程中普遍存在的启动复杂、配置周期长、资源不同步导致浪费、训练过程问题难以定位以及缺乏全程可视化等痛点。凭借自动化的一键开局、贯穿训前到训后的全局可视、瓶颈或故障时的智能路径优化以及算力网络存储的融合管理,AD-AIDC帮助用户快速投入使用整套AI算力集群、降低技术门槛、减轻运维压力,同时提升训练过程的稳定性与高效性,让算力、网络和存储资源得到充分利用,实现大规模AI训练的稳定顺畅运行。
为什么需要AD-AIDC?
随着人工智能与深度学习技术的飞速演进,算力需求呈现爆发式增长,GPU服务器集群规模正从数千卡迅速扩展至数万卡甚至更高,尤其在支撑多模态大模型训练时,这一趋势更为显著。集群规模的指数级扩张,带来了前所未有的运维复杂性:故障根源往往横跨计算域、网络域和存储域,涉及软件、硬件、驱动、配置、性能等多维度问题,单一域的监控数据难以支撑精准的根因分析。例如,网络传输效率下降可能并非由网络链路故障直接导致,而是源于服务器网卡驱动兼容性问题或后端存储I/O瓶颈,此类隐性因素易使问题被误判为网络层异常,从而延长故障定位周期。
与此同时,高效的训练复盘对优化模型收敛性、提升资源利用率和降低成本至关重要。它能通过分析训练过程中的瞬时事件(如毫秒级性能波动)、模型结构与超参数,识别潜在风险并指导后续优化。但传统运维体系严重依赖离散化监控工具,缺乏对训练过程的流级、毫秒级数据采集能力,且计算、存储、网络域的日志与指标分散在孤立系统中,无法实现全局关联分析。这使得故障复盘流于表面,难以捕捉瞬时瓶颈,更无法为资源调度和模型迭代提供数据支撑。
面对上述挑战,仅靠局部优化已无法满足大规模集群的运维需求。亟需一套具备全流程运维能力的解决方案:它必须支持高精度实时数据采集(如GPU利用率、网络吞吐量)、全域日志分析、跨域信息整合与分析、智能化瓶颈识别与优化建议,从而将故障定位从“经验驱动”转向“数据驱动”。
AD-AIDC正是为此而生——它基于统一数字底盘,融合计算、网络与存储域的监控组件,提供一站式入口,实现从部署、实时监控到闭环优化的全流程覆盖。通过智能分析引擎,AD-AIDC不仅破解了跨域故障定位与训练复盘的行业难题,更奠定了未来智算中心大规模集群高效运维的基石。
AD-AIDC包括哪些关键技术?
AD-AIDC面向万卡级超大规模AI数据中心,集自动化部署、智能流量调度、全域可视化监控、训练前后故障防控与优化分析于一体,并支持新一代DDC组网,实现算力、网络、存储的高效协同,大幅缩短部署周期、提升资源利用率与训练稳定性,助力AI任务高速顺畅运行。
详细介绍请参见:“H3C ICT知识百科”

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)