当AI有了情绪感知:我用魔珐星云做了一个会“共情“的具身Agent
文章目录
如果AI能感知你的情绪,并且用温暖的眼神和语气回应你——这还算"人机交互"吗?
一、一个让我停下来想的问题
今年我在做一个情绪陪伴相关的AI项目。做到一半的时候,一个问题反复冒出来:纯文字的AI,真的能给人"陪伴感"吗?
我知道各种心理辅导App、情绪日记工具、AI聊天伴侣已经很多了。你打字说"我今天心情不太好",AI回一段安慰的文字。逻辑上没毛病,信息也到位了。但怎么说呢——就像你给朋友发微信说"我难过",朋友回了一句"抱抱"——你知道她在乎你,但你还是觉得少了点什么。
少了什么?
少了"在场感"。 一个人真正在听你说话的时候,他会微微前倾身体,眼神专注地看着你,适时地点头。当你难过时,他的语气会放柔;当你焦虑时,他会放慢节奏。这些非语言信息传递的是"我在这里,我在认真听"——这不是文字能替代的。
这让我产生了一个实验想法:如果把情绪感知和具身数字人表达结合起来,做一个能"看到你情绪、用身体语言回应你"的AI具身智能体,体验会怎样?
于是我做了个尝试——搭了一个情绪陪伴数字人。不列功能清单,就说一个让我意外的瞬间:测试的时候,一个朋友对它说"我今天压力好大",数字人没有立刻回复,而是先安静地微微前倾了身体,像是认真在听,然后才用放柔的语气说"我能感受到你现在很紧绷,要不要先放下手头的事,跟我做个呼吸练习?"——就这几秒钟的互动,那个朋友后来跟我说,他竟然有一种"被接住了"的感觉。一个会"看"你情绪、会"调整"自己回应方式的数字人,和一段纯文字回复之间的差距,比我想象的大得多。

二、文字AI的温度天花板
在动手之前,我认真想了一下当前AI在情绪陪伴场景中的几个根本性限制。
2.1 表情是信息的载体,不是装饰
心理学研究表明,面对面沟通中,文字内容只传递了约35%的信息,其余65%来自语气、表情、肢体动作等非语言通道。这意味着一个纯文字AI,不管回复内容多温暖,它在信息传递上先天"缺了一大块"。
当用户说"我今天被领导批评了",一个优秀的LLM能生成非常共情的回复:"听到这件事我能感受到你的沮丧,被当众批评确实很伤人。"文字写得很好,但——它从哪里"说"出来的?一个空白的聊天框。没有同情的眼神,没有安慰的语气,没有微微皱起的眉头。
这种"内容到位但温度缺失"的体验,在情绪陪伴场景中尤其致命。
2.2 文字无法传递"陪伴"本身
陪伴的核心不是信息交换,而是"我在这里"的持续信号。一个人坐在你身边什么都不说,你也能感受到陪伴。但一个文字聊天窗口——你不打字,它就静止。它不会主动看你一眼,不会因为你的沉默而投来关切的目光。
这不是LLM能力的问题,是交互形态的天花板。
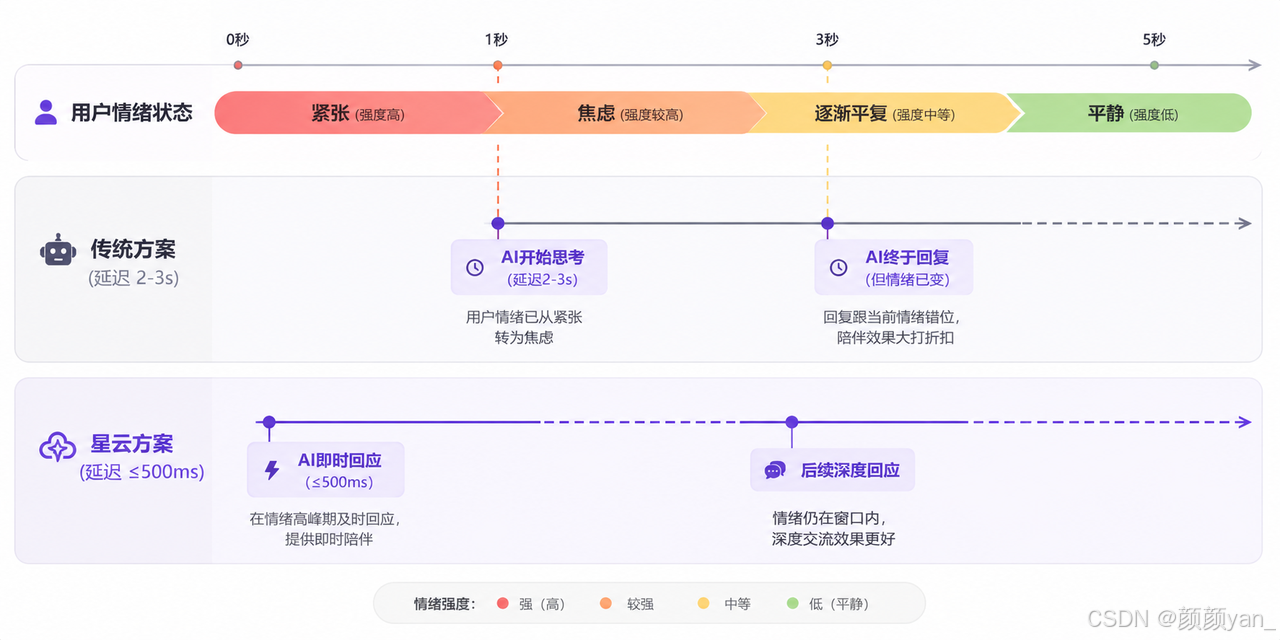
2.3 延迟打断情绪流
还有一个容易被忽略的问题:情绪是流动的。你说"我今天好累",这是情绪的一个瞬间状态。如果AI要2-3秒才回复,这个情绪瞬间已经过去了——你可能在想别的事了,或者情绪已经自己淡化了。AI的回复来得太晚,跟不上情绪的自然节律。
传统云端数字人的视频流方案,2-5秒的延迟在情绪陪伴场景中是灾难性的——它打断了情绪的自然流动,让用户从"我在倾诉"切换到了"我在等回复"。
三、实验设计:情绪感知 × 具身表达
明确了问题,我的实验方案就清楚了:做一个能感知用户情绪、并用数字人的表情和动作做出回应的AI具身智能体。
技术栈选型很直接:
| 能力 | 方案 | 理由 |
|---|---|---|
| 情绪感知 | Qwen3-VL + 关键词兜底 | LLM分析深层情绪,关键词做即时兜底 |
| 共情回复 | Qwen3-VL 四层共情prompt | 表面→情绪→需求→价值 逐层深入 |
| 具身表达 | 魔珐星云XmovAvatar SDK | 参数流+端侧渲染,≤500ms响应 |
| 正念引导 | 内置呼吸/身体扫描练习 | 数字人带领,配合呼吸动画 |
选魔珐星云的核心原因就一个:端到端≤500ms的响应速度。在情绪陪伴场景中,响应速度不只是一个技术指标,它直接决定了AI能不能"跟上"用户的情绪节奏。500ms意味着你说完一句话,数字人几乎"秒回"——这种即时响应传递的是"我在认真听你说话"的信号。
四、几个关键实验的代码实现
下面是实验过程中几个核心模块的代码。开始之前,先介绍一下我们用到的主要平台——魔珐星云具身智能数字人开放平台。
注册登录后,在控制台创建应用即可获取 App ID 和 App Secret,这是调用星云SDK的凭证。平台同时提供了完整的开发者文档、SDK下载和示例代码,上手门槛很低。
4.1 交互核心:用户说话→数字人即时回应
在展开具体的技术模块之前,先展示这个项目最核心的一条交互链路——用户开口说话,数字人即时感知并回应。这是整个体验"活"起来的基础:
// interactiveLoop.js — 核心交互循环
// 用户输入 → 情绪感知 → 数字人姿态切换 → LLM生成共情回复 → 流式驱动数字人说话
async function handleUserInput(text, sdk, llmClient) {
// 1. 即时情绪感知(关键词层,零延迟)
const emotion = quickDetect(text);
// 2. 根据情绪切换数字人姿态(用户一说话,数字人立刻做出反应)
await sdk.listen(); // 先切换到"倾听"姿态
await respondToEmotion(emotion); // 再根据情绪调整:焦虑→前倾关注,悲伤→温柔注视
// 3. 调用LLM生成共情回复(流式)
await sdk.think(); // 数字人做出"思考"表情
const stream = await llmClient.chat({
model: 'Qwen/Qwen3-VL-235B-A22B-Instruct',
messages: [
{ role: 'system', content: EMPATHY_SYSTEM_PROMPT },
...chatHistory,
{ role: 'user', content: text }
],
stream: true
});
// 4. LLM边生成,数字人边"说"——用户不需要等完整回复
let buffer = '';
let isFirst = true;
for await (const chunk of stream) {
const content = chunk.choices[0]?.delta?.content || '';
buffer += content;
if (buffer.length >= 20) {
await sdk.speak(buffer, isFirst, false);
isFirst = false;
buffer = '';
}
}
// 发送剩余文本,标记结束
if (buffer) await sdk.speak(buffer, false, true);
}
这段代码展示的交互闭环是:用户说话 → 数字人立刻切换到倾听姿态 → 感知情绪后调整表情 → LLM流式生成回复 → 数字人边"听"边说。整个过程端到端在500ms内启动,用户感受到的是"我刚说完,它就理解了,而且用正确的表情回应了我"。
这也是魔珐星云参数流架构的价值所在——不是某个单点技术优秀,而是让"感知-理解-表达"这条交互链路足够快、足够自然,用户才会产生"它在认真听我说话"的感觉。
后面的三个实验,分别对应这条链路上的三个关键环节。
4.2 实验一:让AI"读懂"你的情绪
情绪感知分两层:LLM深度分析做主力,关键词匹配做兜底。
// emotionAnalyzer.js — 双层情绪感知
const EMOTION_KEYWORDS = {
anxiety: ['焦虑', '紧张', '不安', '担心'],
sadness: ['难过', '伤心', '失落', '想哭'],
anger: ['生气', '愤怒', '烦死', '受不了'],
happiness: ['开心', '高兴', '太好了', '幸福'],
calm: ['平静', '放松', '安心', '踏实'],
loneliness: ['孤独', '寂寞', '没人理', '好孤单'],
confusion: ['迷茫', '纠结', '不知道', '困惑'],
fatigue: ['好累', '疲惫', '撑不住', '精疲力竭']
};
// 第一层:关键词即时识别(零延迟)
function quickDetect(text) {
for (const [emotion, keywords] of Object.entries(EMOTION_KEYWORDS)) {
if (keywords.some(kw => text.includes(kw))) {
return {
primary: emotion,
intensity: 0.6,
source: 'keyword'
};
}
}
return { primary: 'calm', intensity: 0.3, source: 'keyword' };
}
// 第二层:LLM深度分析(异步,更精确)
async function deepAnalyze(text, llmClient) {
const response = await llmClient.chat({
model: 'Qwen/Qwen3-VL-235B-A22B-Instruct',
messages: [{
role: 'system',
content: `分析用户文本的情绪状态,返回JSON:
{
"primary_emotion": "anxiety|sadness|anger|happiness|calm|loneliness|confusion|fatigue",
"intensity": 0.0-1.0,
"nuances": ["次要情绪1", "次要情绪2"],
"urgency": "low|medium|high",
"needs": ["用户深层心理需求"],
"suggested_style": "warm_comfort|exploratory_guidance|positive_encouragement|quiet_companionship"
}`
}, {
role: 'user', content: text
}],
response_format: { type: 'json_object' }
});
return JSON.parse(response.choices[0].message.content);
}
为什么需要两层?因为LLM分析需要300-800ms,但情绪陪伴的即时性要求很高。用户说"我好焦虑",关键词层立刻识别出 anxiety 并触发数字人的"关注"姿态(微微前倾),同时LLM在后台做深度分析。两层并行,既保证即时性又不丢失深度。
4.3 实验二:让数字人"配合情绪做动作"
这一步是整个实验最核心的部分——把情绪分析结果映射到数字人的行为上。
星云SDK提供了一套状态机来控制数字人的姿态。在情绪陪伴场景中,我扩展了标准的状态机,加入了"情绪驱动"的逻辑:
// emotionAvatarDriver.js — 情绪驱动的数字人行为
const EMOTION_BEHAVIORS = {
anxiety: {
posture: 'listen', // 微微前倾,表示关注
speechRate: 'slow', // 放慢语速
ssmlActions: ['Calm'], // 安抚性动作
greeting: '我能感受到你现在有些紧张,我们先深呼吸好吗?'
},
sadness: {
posture: 'empathize', // 身体前倾,温柔注视
speechRate: 'slow',
ssmlActions: ['Comfort'], // 安慰性动作
greeting: '你看起来不太开心,我在这里陪你。'
},
anger: {
posture: 'listen', // 专注倾听
speechRate: 'normal',
ssmlActions: ['Nod'], // 理解性点头
greeting: '我理解你的感受,这件事确实让人不舒服。'
},
happiness: {
posture: 'interactiveidle', // 放松状态
speechRate: 'normal',
ssmlActions: ['Celebrate'], // 开心的动作
greeting: '看到你开心我也很高兴!'
},
loneliness: {
posture: 'empathize',
speechRate: 'slow',
ssmlActions: ['Comfort'],
greeting: '你并不是一个人,我一直在这里。'
},
fatigue: {
posture: 'empathize',
speechRate: 'slow',
ssmlActions: ['Reassure'],
greeting: '辛苦了,要不要试试放松呼吸?'
}
};
class EmotionAvatarDriver {
constructor(sdk) {
this.sdk = sdk;
}
// 根据情绪驱动数字人行为
async respondToEmotion(emotion, intensity) {
const behavior = EMOTION_BEHAVIORS[emotion] || EMOTION_BEHAVIORS.calm;
// 1. 切换姿态
await this.sdk[behavior.posture]();
// 2. 高强度情绪时先给一句即时回应
if (intensity > 0.5 && behavior.greeting) {
await this.sdk.speak(behavior.greeting, true, true);
}
}
// 带情绪感知的流式朗读
async speakWithEmotion(text, emotion) {
const behavior = EMOTION_BEHAVIORS[emotion] || EMOTION_BEHAVIORS.calm;
// 按标点分块,控制节奏
const chunks = text.match(/[^。!?;…]+[。!?;…]?/g) || [text];
let isFirst = true;
for (let i = 0; i < chunks.length; i++) {
const chunk = chunks[i].trim();
if (!chunk) continue;
const isEnd = i === chunks.length - 1;
await this.sdk.speak(chunk, isFirst, isEnd);
isFirst = false;
// 悲伤/焦虑时在句间增加短暂停顿
if (['sadness', 'anxiety', 'fatigue'].includes(emotion)) {
await new Promise(r => setTimeout(r, 200));
}
}
}
}
这段代码做了两件重要的事:
情绪驱动的姿态切换。 用户焦虑时,数字人前倾身体表示关注(listen状态);用户悲伤时,数字人做出共情的姿态(empathize状态,实际调用interactiveidle);用户开心时,数字人放松身体配合开心的动作。
情绪感知的语速控制。 悲伤和焦虑时,在句间增加200ms的停顿,让数字人的语速自然放慢。这不是通过调整TTS参数实现的,而是通过分块策略——更大的分块间隔意味着更慢的节奏。
4.4 实验三:让数字人带你做正念呼吸
这是整个实验中我最喜欢的一个功能。情绪激烈的时候,纯文字说"深呼吸"几乎没用。但如果有一个数字人坐在你面前,用温柔的声音说"来,跟着我,吸气……屏住……呼气……",同时配合呼吸节奏做出身体起伏——这个体验完全不同。
<!-- 简化版:呼吸引导组件核心逻辑 -->
<script>
// 4-7-8 呼吸法:吸气4秒 → 屏息7秒 → 呼气8秒
async function startBreathingGuide(sdk) {
// 数字人先说引导语
await sdk.speak(
'好的,我们来做一个简单的呼吸练习,帮助你放松下来。跟着我的节奏,慢慢来。',
true, true
);
// 等语音播完
await waitForVoiceEnd(sdk);
for (let cycle = 1; cycle <= 4; cycle++) {
// 吸气阶段(4秒)
await sdk.speak('吸气……', true, false);
await delay(4000);
// 屏息阶段(7秒)
await sdk.speak('屏住……', false, false);
await delay(7000);
// 呼气阶段(8秒)
await sdk.speak('慢慢呼气……', false, cycle === 4);
await delay(8000);
}
// 完成后的安抚
await delay(500);
await sdk.interactiveidle();
await sdk.speak(
'很好,你完成了呼吸练习。现在感觉怎么样?身体是不是放松了一些?',
true, true
);
}
function delay(ms) {
return new Promise(r => setTimeout(r, ms));
}
function waitForVoiceEnd(sdk) {
return new Promise(resolve => {
const original = sdk.onVoiceStateChange;
sdk.onVoiceStateChange = (status) => {
if (original) original(status);
if (status === 'end') {
sdk.onVoiceStateChange = original;
resolve();
}
};
});
}
</script>
这段代码的巧妙之处在于:数字人不是在"播放音频",而是在"带你呼吸"。 每个阶段(吸气、屏息、呼气)由数字人用语音引导,配合SDK的流式speak接口精确控制节奏。4个循环下来约76秒——一个完整的4-7-8呼吸周期。
在实际体验中,当数字人用温柔的声音说"吸气……“,然后安静地等待4秒(数字人处于平静的待机姿态),再轻声说"屏住……”——这种有节奏的"人带领你"的感觉,跟看着屏幕上的文字提示完全不同。
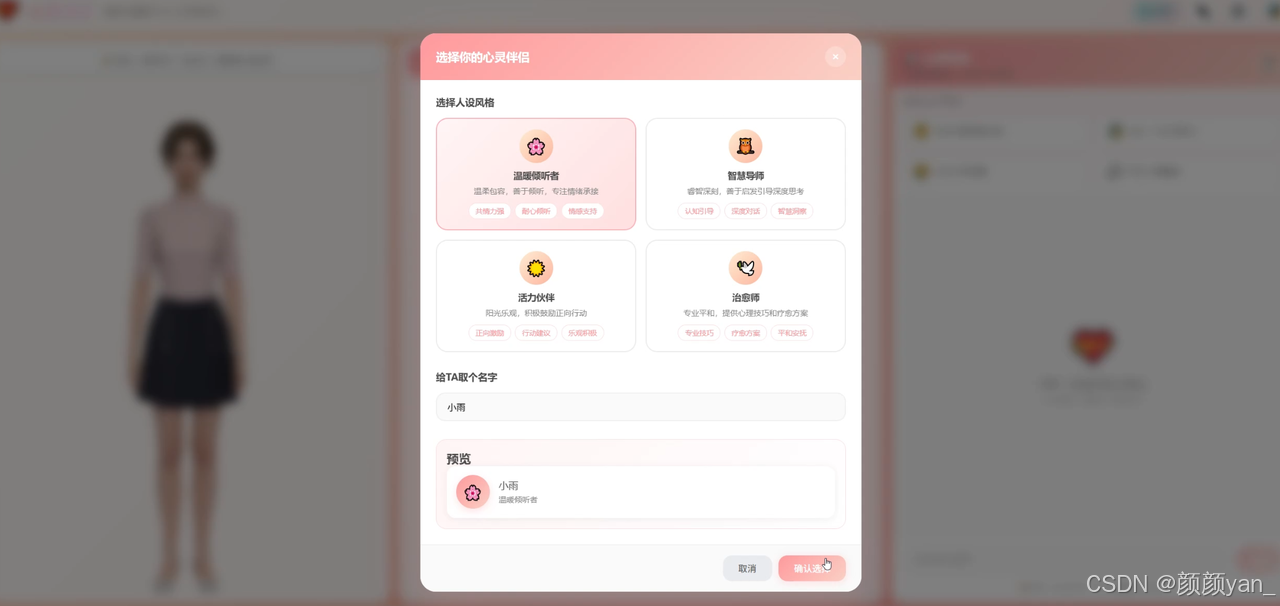
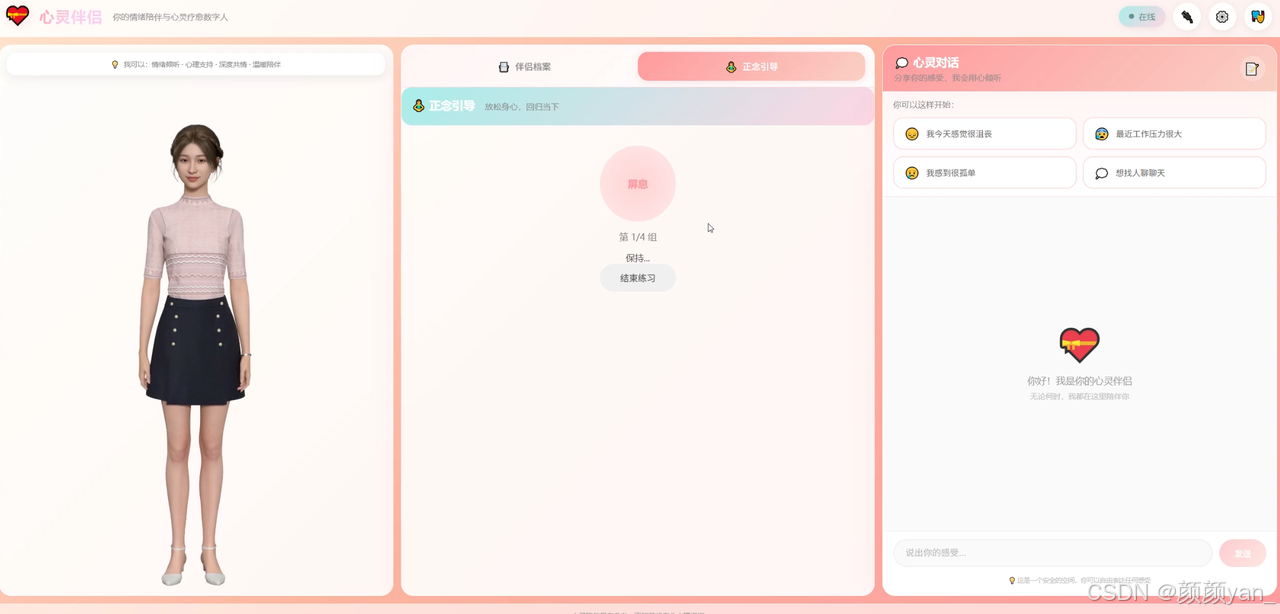
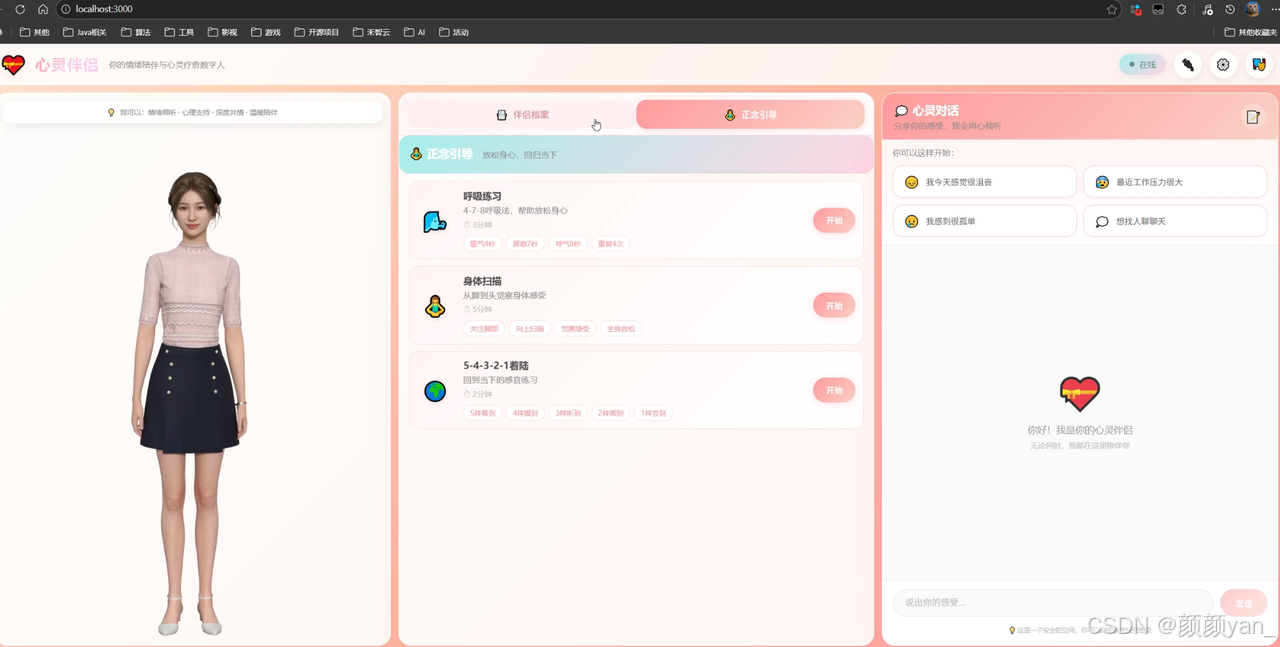
五、意料之外的发现
做这个实验的过程中,有两个发现让我印象很深。
第一个发现关于开发效率。 这个项目涉及情绪分析prompt设计、数字人状态机管理、流式语音驱动、正念引导时序控制等多个模块,听起来工作量不小。但实际上,借助AI Coding工具——Claude code,整个核心功能的开发周期只有三天左右。
具体来说:Claude Code负责后端情绪分析服务的搭建和Qwen3-VL的prompt调优,它擅长理解全局架构和跨模块逻辑;Cursor配合魔珐星云官方提供的AI Coding Skill文件处理前端SDK集成,部署Skill后AI编辑器就能自动生成符合最佳实践的数字人初始化、状态管理和流式speak代码。作为"大脑"的Qwen3-VL大模型(通过ModelScope API调用)负责情绪分析和共情回复生成,国产模型在中文情绪理解上的表现完全够用。这种"AI工具+国产大模型"的开发模式,让一个本该耗时两周的项目压缩到了两天。
第二个发现关于用户体验。 我让几个朋友试用了这个情绪陪伴数字人(用的是完整版项目,包含情绪分析、正念引导、心情日记等功能)。反馈中有一条反复出现:
“它说’我理解你的感受’的时候,我竟然信了。因为它当时的表情和语气让我觉得它是真的在认真听。”
这句话让我重新思考了一个问题:"共情"的本质到底是什么?
从技术角度看,这个系统做的不过是:检测关键词→调用LLM生成回复→用TTS朗读→数字人做出对应姿态。每一步都是可解析的技术过程,没有任何真正的"理解"或"共情"。
但从用户体验角度看,当这些技术环节被端到端地整合在一起——情绪感知足够快(≤500ms),数字人的回应足够自然(表情+语气+动作同步),正念引导有真实的节奏感——用户确实产生了"被陪伴"的感觉。
这让我意识到:具身Agent的价值不在于AI是否"真的"理解情绪,而在于它能否在交互层面传递"我在这里"的信号。 这个信号不是靠某一项单点技术传递的,而是靠多模态的整体协同——你的情绪被感知了(关键词层即时响应),你的感受被回应了(LLM生成共情内容),而且这一切是由一个"看着你"的数字人完成的(端侧渲染的低延迟保证了即时感)。
这也是魔珐星云参数流架构在这个场景中的核心价值:它不是因为某个单项指标出色,而是因为端到端的整体体验——从情绪感知到数字人回应的整个链路被压缩到了500ms以内,用户感受到的是一个连贯的、即时的、有温度的回应,而不是一堆技术模块的拼接产物。
六、具身Agent落地:几个实际的考量
从"实验"走向"落地",有几个现实问题需要考虑。
6.1 部署门槛
星云SDK基于端侧渲染,硬件要求很低。RK3588芯片跑1080p数字人,成本百元级。这意味着情绪陪伴Agent可以部署到智能音箱、平板电脑、甚至带屏智能家居设备上——不需要高配GPU服务器,不需要持续的高带宽连接。
对于一个"陪伴型"产品来说,低部署门槛非常重要。你不会希望用户为了使用一个情绪陪伴AI,先花几千块买一台高配设备或者付昂贵的月费。参数流的Kbps级带宽消耗意味着移动网络环境下也能流畅运行。
6.2 隐私
情绪数据是高度敏感的个人信息。星云SDK的端侧渲染架构在这方面有一个隐性优势:渲染在本地完成,只有参数数据经过网络传输(语音和动画参数,而不是视频画面)。对话内容的隐私保护依然需要额外的加密措施,但至少不需要把用户的视频画面传到云端处理。
6.3 多场景适配
情绪陪伴Agent不只适用于"聊天"。我在实验中尝试了几个场景延伸:
-
正念冥想引导:数字人带你做呼吸练习、身体扫描——前面已经展示了代码
-
心情日记:每天记录心情,数字人根据情绪趋势主动关心
-
睡眠陪伴:睡前数字人用缓慢的语速讲放松的故事或引导语
-
儿童情绪教育:帮助小朋友识别和表达自己的情绪
这些场景有一个共同特征:需要AI有一个"身体"来传递陪伴感。 纯文字做不到——你不会对着一个聊天框做呼吸练习。
6.4 端到端的完整性
从开发者的角度,魔珐星云SDK在这个场景中的优势在于"端到端"的完整性。我不需要分别对接TTS服务、3D渲染引擎、动画系统——一个SDK搞定从文本到数字人表达的整个链路。这大幅降低了开发复杂度,让我能专注于情绪感知和交互逻辑的设计。
配合AI Coding工具,从零搭建一个可运行的情绪陪伴Demo大概只需要1-2天。星云官方还提供了AI Coding Skill文件,部署到AI编辑器后能自动生成符合最佳实践的SDK集成代码——对于快速验证创意想法来说非常方便。

七、写在最后:关于"陪伴"的个人思考
做完这个实验,我对"AI陪伴"有了一些不一样的理解。
以前我觉得AI陪伴是一个伪需求——真正的情感连接怎么可能来自一段代码?但做完这个项目后,我的看法变了。不是因为我相信AI能"真的"共情,而是因为我意识到:陪伴的核心体验是"被感知"和"被回应"——而这两个动作,具身Agent确实可以做到。
当你说"我好累",一个文字AI回复"辛苦了"和一个数字人微微前倾身体、用温柔的语气说"辛苦了"——后者传递的"被感知"信号要强得多。这不是因为数字人"更智能",而是因为它多了一条非语言的信息通道——表情、姿态、语速、眼神。这些在人类沟通中传递了65%信息的通道,在纯文字AI中是完全缺失的。
魔珐星云在这个实验中扮演的角色不是"让数字人更逼真",而是让AI的表达从单通道变成了多通道。参数流+端侧渲染的架构确保了这条多通道是实时的、低成本的、可落地的。没有2-3秒的延迟打断情绪流,没有高昂的带宽成本阻碍产品化,不需要高端GPU就能部署到消费级设备上。
当然,我也清楚这个实验有很多局限。情绪感知的准确度还有提升空间,SSML动作库在"微表情"方面的粒度还不够细,长时间对话的上下文管理也需要更完善的记忆系统。这些都是后续可以迭代的方向。
但如果回到最初的问题——纯文字AI能给人陪伴感吗? 我的答案是:不够。不是内容不够好,是交互形态的天花板。而具身Agent——一个能感知你的情绪、看着你的眼睛、用恰当的语气回应你的数字人——至少在这条路上迈出了实质性的一步。
相关资源:
-
魔珐星云开发者文档:https://xingyun3d.com/developers/52-183
-
魔珐星云AI Coding Skill:https://rsjqcmnt5p.feishu.cn/wiki/ULNQwoiKwid2tVkTpAlcMb49nKg

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)