600 + 语言背后:OmniVoice 如何重塑 AI 语音生成
有时候会有一种很明显的感觉:AI 语音这件事,好像已经从「能不能用」进入到「还能怎么往上加难度」的阶段了。前几年大家还在讨论「AI 读出来像不像人」,现在新的问题已经变成了:「AI 能不能用同一个声音说全世界的语言?」
最近,小米 AI Lab 开源的 OmniVoice,就在尝试解决这个问题。
简单科普一下。传统 TTS(文本转语音)的目标是把文字变成语音,但往往受限于语言、口音甚至说话人本身。换一种语言、换一种声音,很多时候就需要重新训练模型。
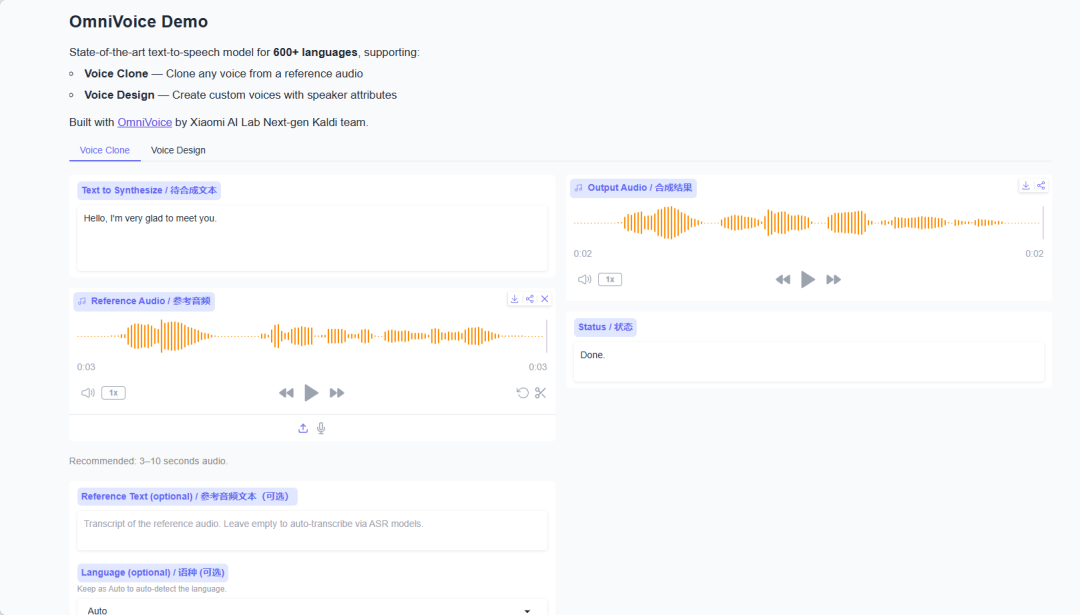
而 OmniVoice 的思路更加激进:训练一个支持 600 + 语言的统一语音模型。它不仅能根据 3~10 秒参考音频快速克隆声音,还支持通过自然语言直接设计音色。比如输入「年轻女性、英式口音、语速偏慢」,模型就能生成符合描述的新声音。更重要的是,它支持跨语言语音克隆。换句话说,你提供一段中文录音,模型可以保留原有音色,用英文、日文甚至更多语言进行表达。
此外,OmniVoice 还支持中文方言、多种英语口音,以及长文本自动分块生成等能力,对于数字人、AI 主播、有声书和内容出海等场景都非常实用。如果说过去的语音模型是在研究「怎么把字念出来」,那么 OmniVoice 更像是在探索另一件事:如何让 AI 真正拥有跨越语言边界的声音。 教程链接:https://go.openbayes.com/GNWZw
使用云平台: OpenBayes http://openbayes.com/console/signup?r=sony_0m6v
首先点击「公共教程」,找到「OmniVoice:支持 600+ 语言的高质量语音克隆与文本转语音」,单击打开。
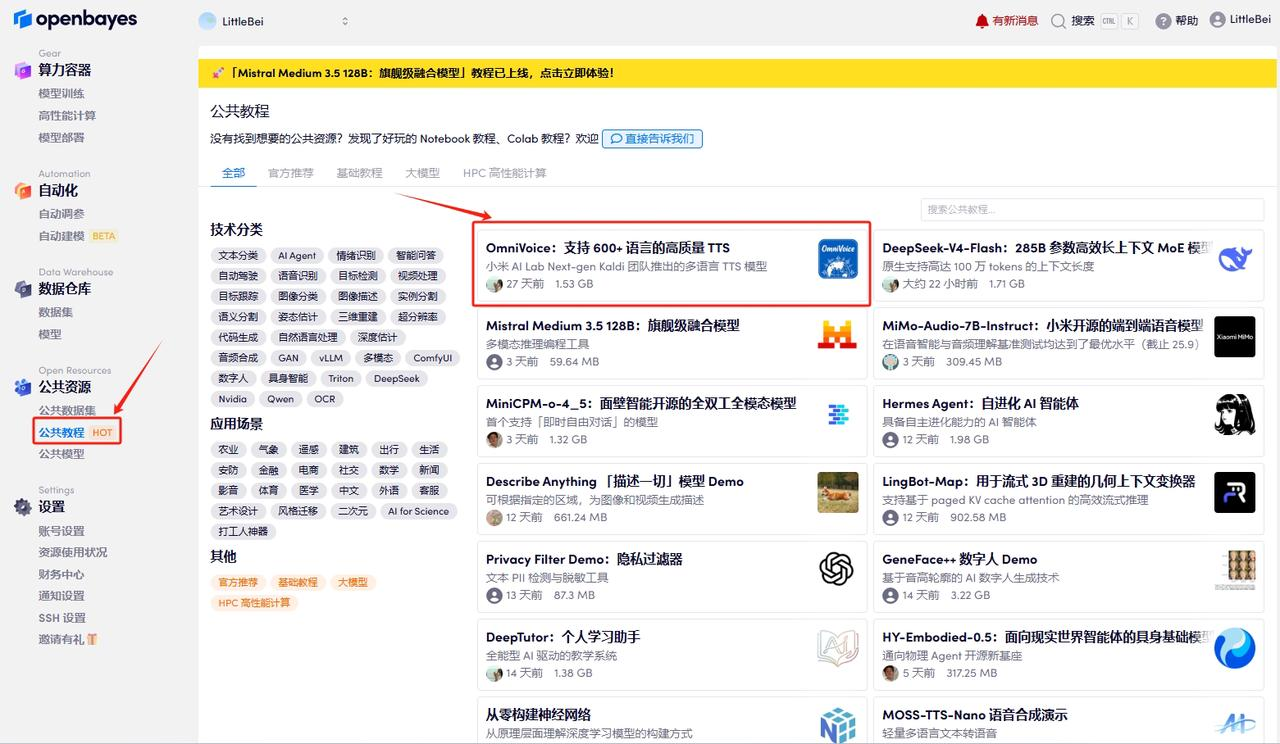
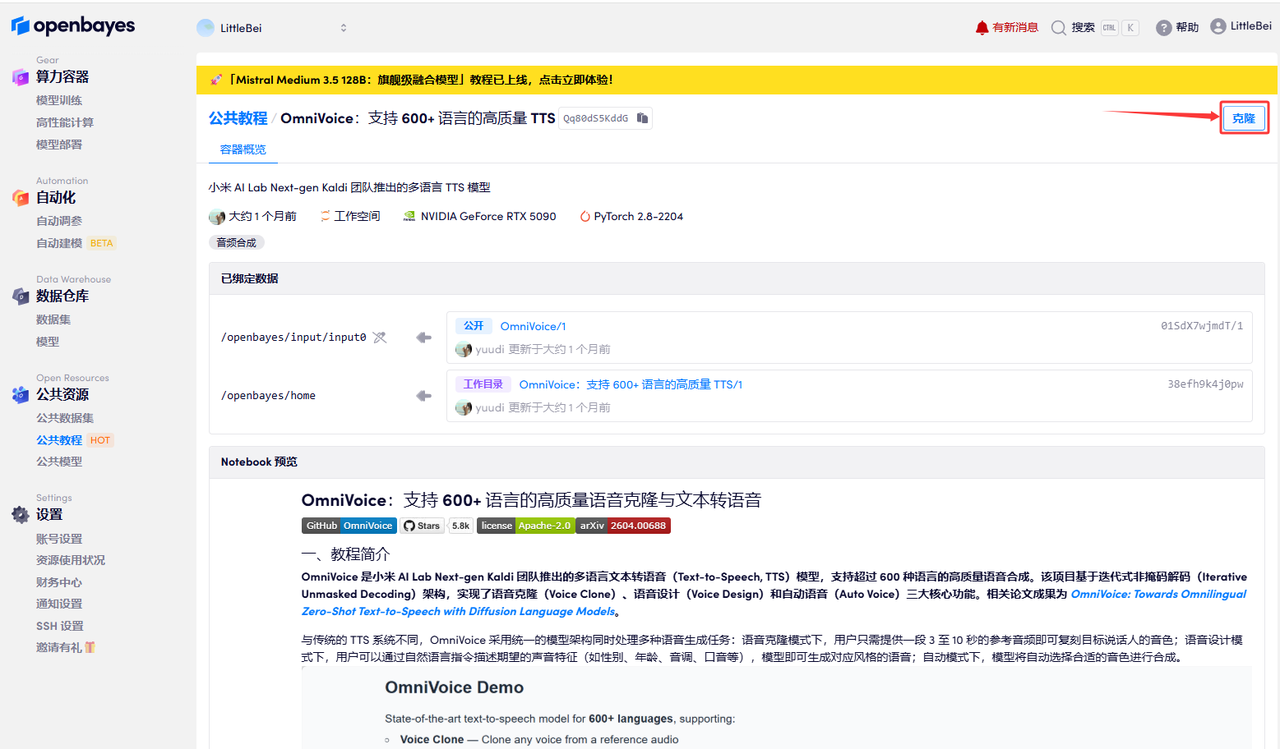
页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
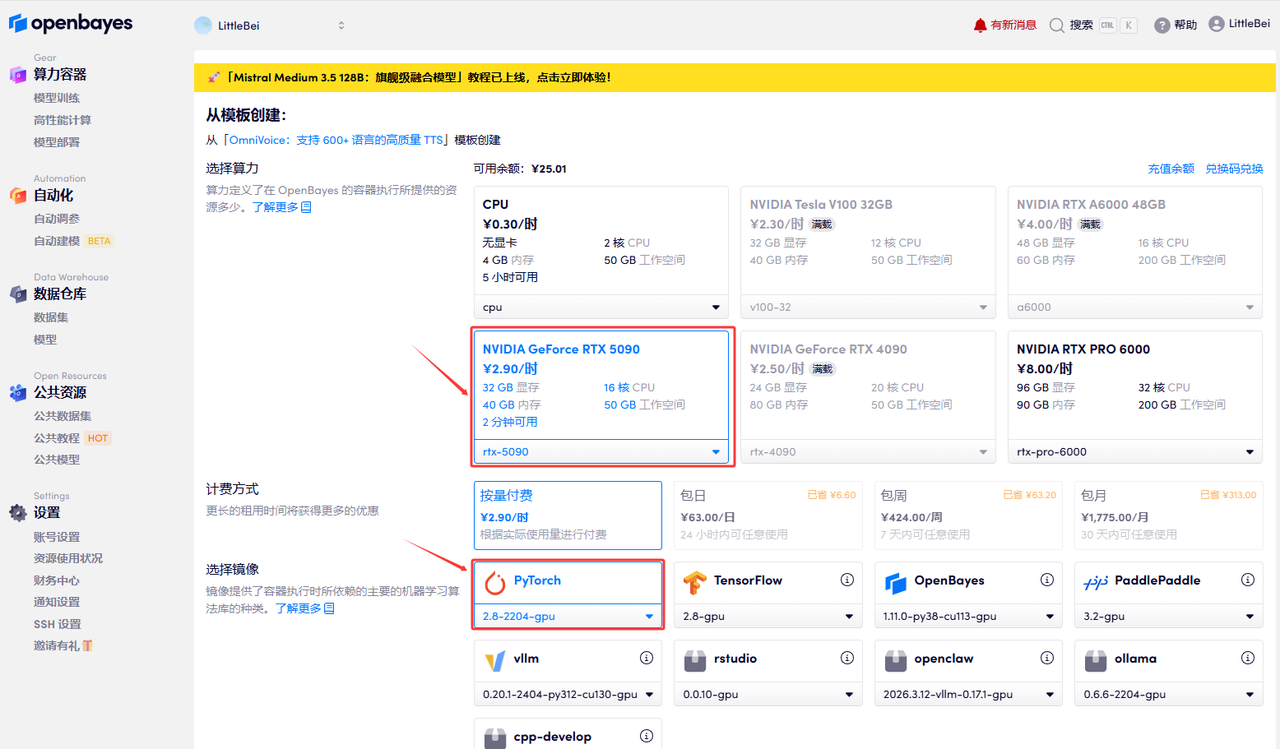
在当前页面中看到的算力资源均可以在平台一键选择使用。平台会默认选配好原教程所使用的算力资源、镜像版本,不需要再进行手动选择。点击「继续执行」,等待分配资源。
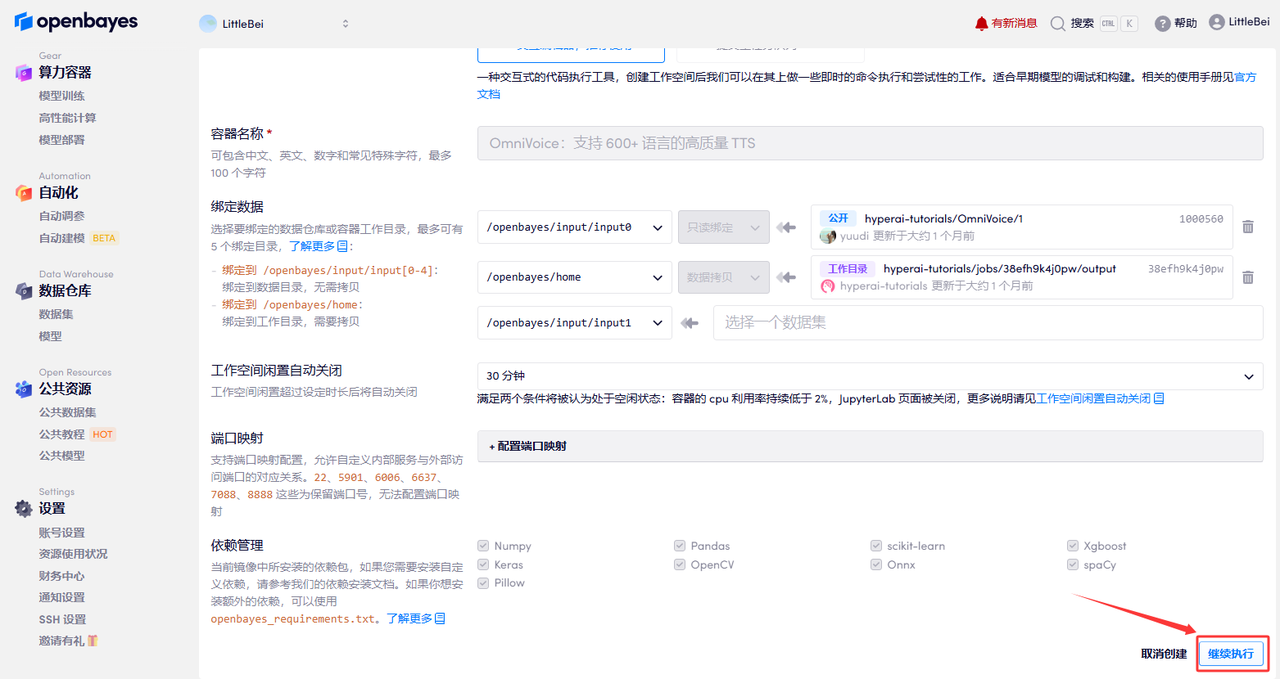
若显示「Bad Gateway」,这表示模型正在加载中,请等待约 2-3 分钟后刷新页面即可;若显示「运行中」,点击「打开工作空间」。
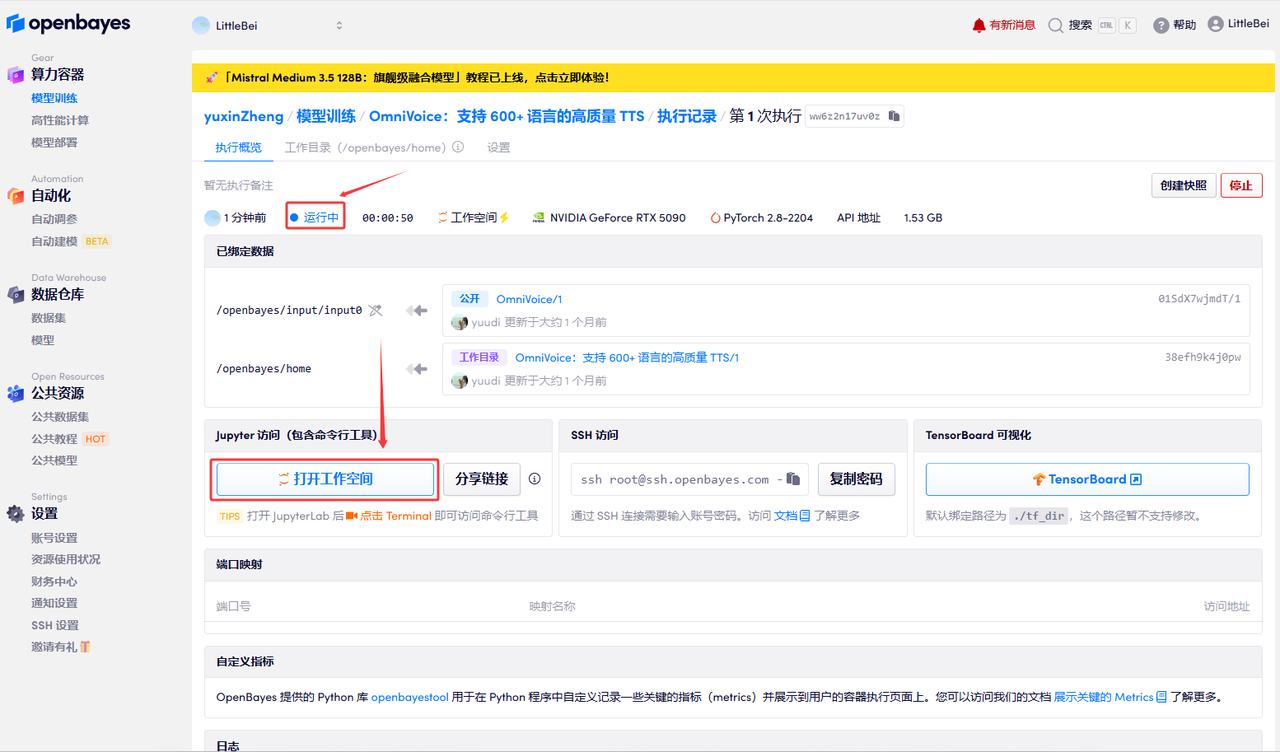
使用步骤如下:
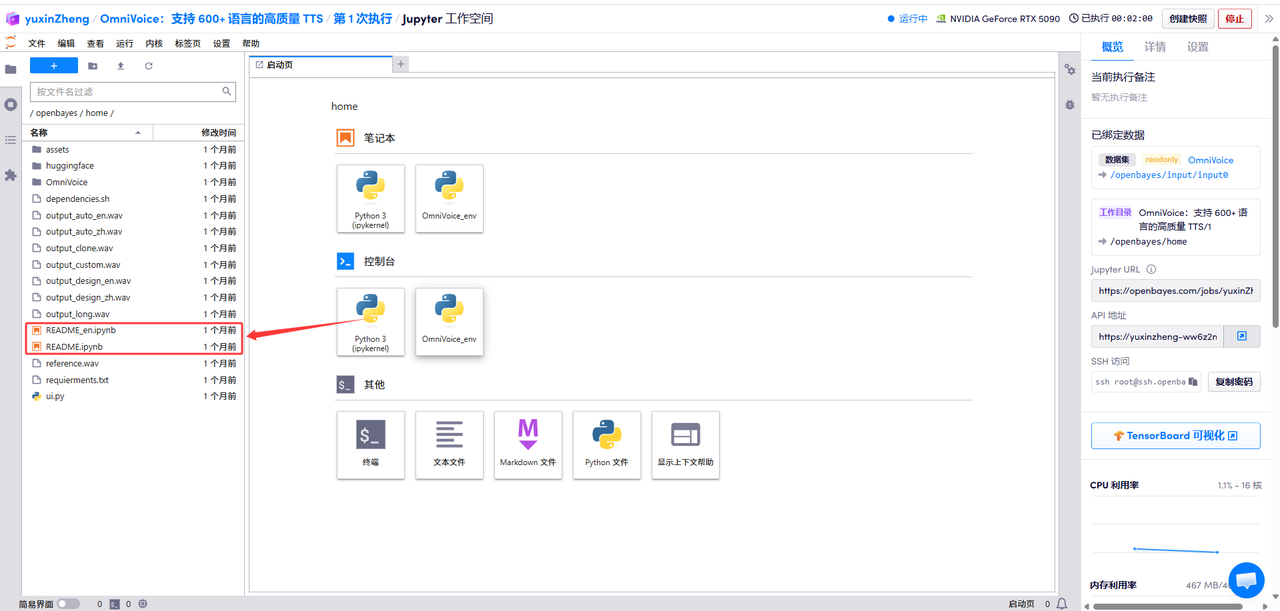
1.页面跳转后,点击左侧 README.ipynb 文件,点击上方「运行」。
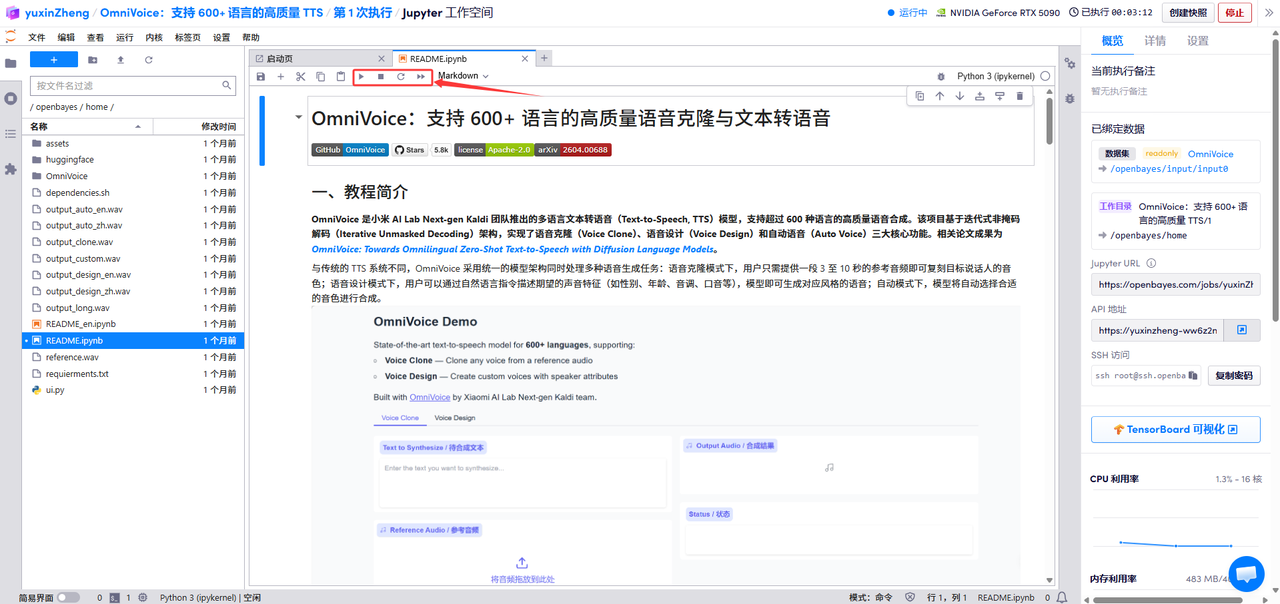
2.运行完成,即可点击右侧 API 地址跳转至 demo 页面。
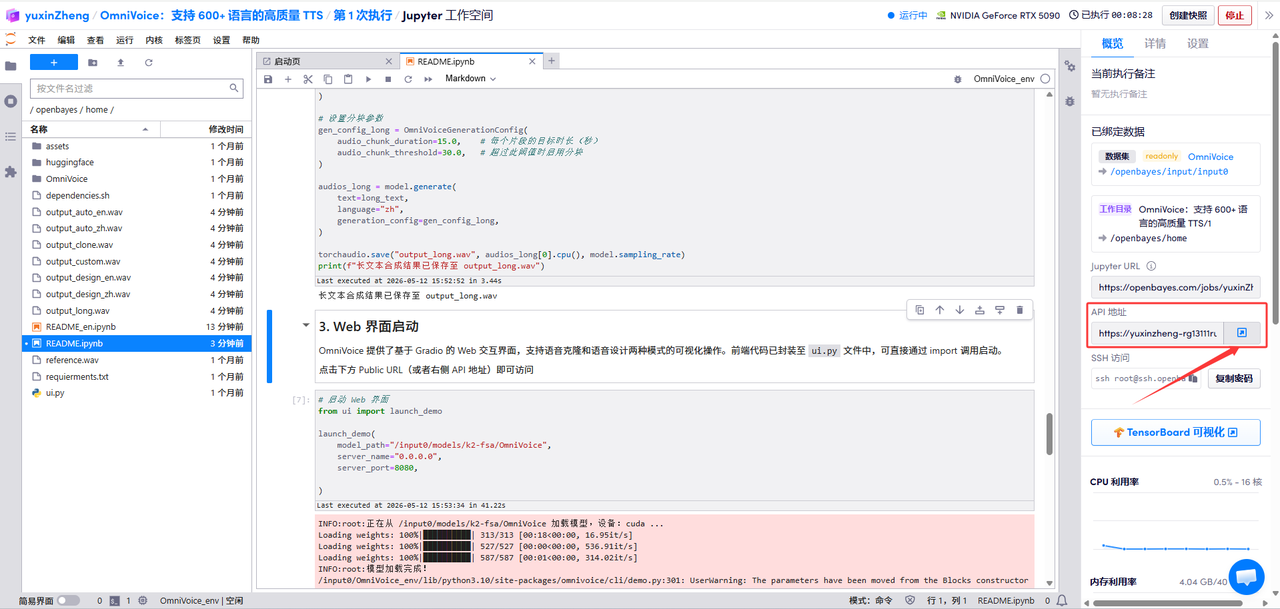
3.依据需求上传文本和音频文件,生成合成音频文件。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)