炸裂!!!给 codeX 装上本地大脑:cc-switch_Ollama 接入全记录
炸裂!!!给 codeX 装上本地大脑:cc-switch_Ollama 接入全记录

作者:吴佳浩
撰稿时间:2026-6-11
最后更新:2026-6-12
声明:本文所有结论均来自俺对 cc-switch 源码的实际修改和双平台测试(转载请注明出处 吴佳浩Alben)
上游仓库:github.com/farion1231/cc-switch
Fork:github.com/XiaoBinGan/cc-switch,分支feat/ollama-codex-proxy
PR:#4075
引言
我猜很多人都有过这种经历。
电脑里明明跑着 Ollama,硬盘里躺着几个几十 GB 的模型,显卡也没闲着。
结果打开 Codex。
请求发往 OpenAI。
打开 Claude Code。
请求发往 Anthropic。
再打开 Gemini CLI。
请求发往 Google。
本地模型放在那里吃灰,云端账单却在持续增长。
我也是。
手上有两台机器:
- MacBook Pro 16(M1 Pro)
- RTX 5090 + 96GB 内存的 Windows 工作站
平时跑 Qwen、DeepSeek、GLM 这些模型完全够用。
但只要切到 Codex,事情就变了。
cc-switch 确实很好用。
一个桌面 App 就能统一管理 Codex、Claude Code、Gemini CLI、OpenCode 等多个 AI Agent,几十家供应商预设开箱即用。
可当我准备把 Codex 接到本地模型时,却发现:
所有 Provider 都是云端的。
没有 Ollama。
没有 LM Studio。
也没有任何本地推理入口。
这让我有点不爽。
既然 Claude Code 能接本地模型,OpenCode 能接本地模型,为什么 Codex 不行?
于是我打开了 cc-switch 的源码。
原本以为会是一场大手术。
结果研究下来发现:
距离支持 Ollama,其实只差最后一公里。
最终只改了 4 个文件,提交了 5 个 Commit,就让 Codex 的请求能够直接路由到本机 Ollama。
一、这件事为什么值得做
1.1 成本
| 场景 | 月费(中等用量) | 说明 |
|---|---|---|
| GPT-5.5 via Codex | $200 ~ $1,500 | reasoning 开销极高,一条长对话烧几刀 |
| Claude Opus via Claude Code | $300 ~ $2,000 | 长上下文加价明显 |
| Ollama 本地 | $0 | 只有电费 |
1.2 延迟
不是"快一点",是降了一个数量级:
云端:终端 rarr; cc-switch rarr; TCP rarr; TLS rarr; CDN rarr; API Gateway rarr; LLM rarr; 原路返回
└── 50-300ms,波动大
本地:终端 rarr; cc-switch rarr; 127.0.0.1:11434
└── <5ms,稳如磐石
Codex CLI 是流式输出,首 token 延迟(TTFT)从 500ms+ 降到 50ms 以内,体验差异非常明显。
1.3 隐私 & 离线
- 私有仓库代码不出本机
- 断网照样干活——飞机上、客户现场、地铁里都不影响
1.4 生态卡位
cc-switch 的定位是「AI 工具总控台」。接入 Ollama 之后:
一个桌面 App rarr; 管理所有 AI CLI 工具 rarr; 云端/本地模型一键切换
这意味着你可以在「省钱但稍慢的本地模型」和「烧钱但更强的云端模型」之间自由切换,而不是被绑在某一端。
二、架构:一条请求的完整旅程
2.1 请求时序
三、代码改动:5 个 commit,刀刀致命
3.1 类型系统:local 分类
文件:src/types.ts — 1 行改动
export type ProviderCategory =
| "official"
| "cloud_provider"
| "aggregator"
| "third_party"
| "local" // 就这一行
| "custom"
| "omo"
| "omo-slim";
为什么需要? cc-switch 的供应商列表按 category 分组。Ollama 放 local 下,和云端供应商视觉隔离——用户一眼就知道「这是本机模型,不花钱」。
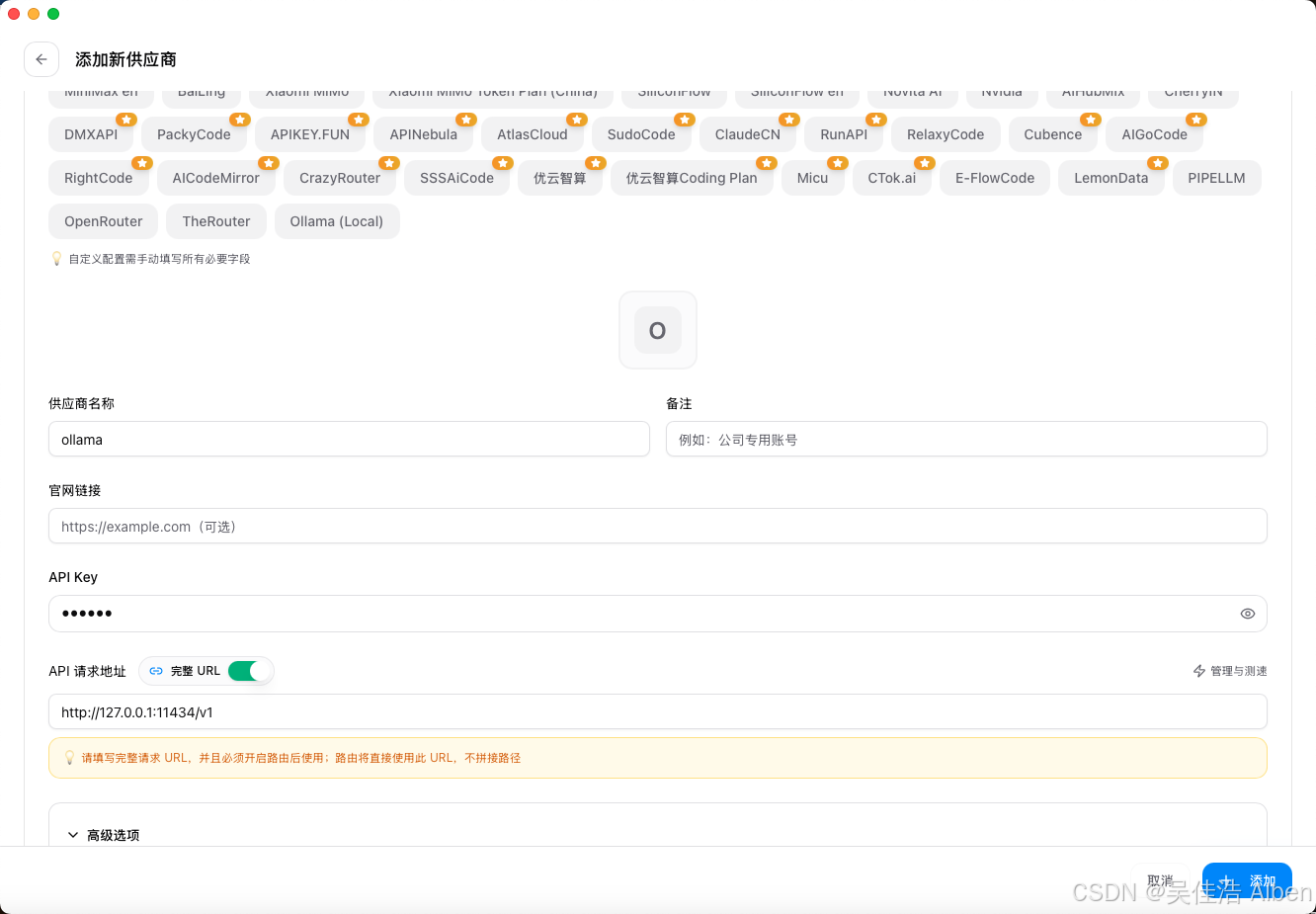
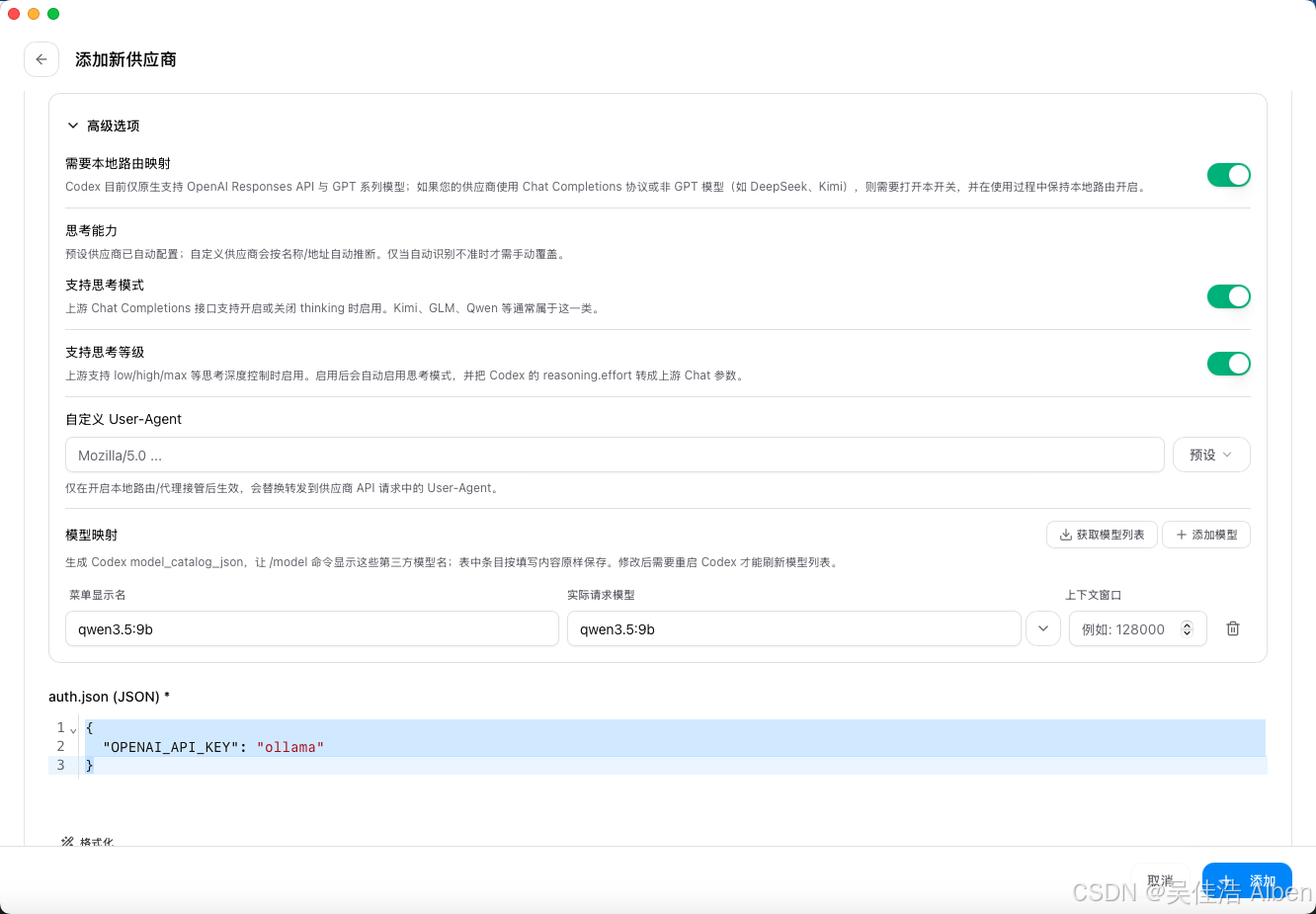
3.2 预设配置:一键添加
文件:src/config/codexProviderPresets.ts — ~50 行新增
5 个预置模型:
| 模型 | 上下文窗口 | 定位 |
|---|---|---|
qwen3.5:9b |
131K | 测试功能是否正常使用 |
qwen3.5:35b |
131K | 主力,推理+代码均衡 (并未放入预置需要你启动后手动添加) |
qwen2.5:14b |
131K | 需要更强理解力时 |
qwen2.5:7b |
131K | 轻量快速 |
qwen3:8b |
32K | 备用 |
gpt-oss:20b |
32K | 英文代码场景 |
关键配置点:
{
name: "Ollama (Local)",
category: "local",
base_url: "http://127.0.0.1:11434/v1",
apiFormat: "openai_chat", // 走 Chat Completions,不是 Responses
codexChatReasoning: {
supportsThinking: true,
supportsEffort: false, // Ollama 没有 reasoning_effort 参数
thinkingParam: "thinking",
outputFormat: "reasoning", // 这是最容易配错的地方
},
}
outputFormat: "reasoning"是血泪教训:Ollama 的 thinking tokens 走delta.reasoning字段,而 OpenAI/Claude 走delta.thinking。如果配成"thinking",Codex CLI 收不到推理过程,直接崩。这个值在 Codex 的类型系统里甚至不是合法值——俺专门确认过。
3.3 核心修复:URL 端点静默丢失
文件:src-tauri/src/proxy/forwarder.rs — 13 行新增
这是整个 PR 里最致命的 bug。没有它,所有本地模型请求全部 404。
根因还原:
CC Switch 做了 Responses rarr; Chat Completions 协议转换:
effective_endpoint = "/chat/completions"
适配器 build_url(base_url="http://127.0.0.1:11434/v1", endpoint="/chat/completions")
rarr; 发现 base_url 已经以 /v1 结尾
rarr; 认为 endpoint 已经被包含了
rarr; 返回 "http://127.0.0.1:11434/v1"
rarr; /chat/completions 丢了!
rarr; Ollama 收到 POST /v1 rarr; 404
修复(在 build_url 之后二次校验):
// Ollama/本地模型兼容:适配器 build_url 可能丢失 endpoint,手动拼接
let url = if codex_responses_to_chat && !effective_endpoint.is_empty() {
let ep = effective_endpoint.trim_start_matches('/');
let check = format!("/{ep}");
if !url.contains(&check) {
let base = url.trim_end_matches('/');
format!("{base}/{ep}") // 丢了就补回去
} else {
url
}
} else {
url
};
这个 bug 藏得很深——build_url 的行为在大多数供应商(base_url 不以 /v1 结尾)下是正确的,只在 Ollama(http://127.0.0.1:11434/v1)这个特殊 URL 格式下暴露。
3.4 防御三连(codex.rs)
文件:src-tauri/src/proxy/providers/codex.rs — ~60 行新增
cc-switch 的 UI 层有一些历史遗留行为,会在特定操作下覆盖关键配置。俺的选择是:不在 UI 层修(影响面太大),在 Rust 层暴力兜底。
防御 1:is_ollama_provider() — 三层识别
fn is_ollama_provider(provider: &Provider) -> bool {
// 第1层:provider id 精确匹配
let id = provider.id.to_ascii_lowercase();
if id == "ollama" || id == "ollama-local" || id == "ollama-chat" {
return true;
}
// 第2层:provider name 模糊匹配
let name = provider.name.to_ascii_lowercase();
if name.contains("ollama") {
return true;
}
// 第3层:base_url 端口特征匹配
let base_url = /* ... */;
base_url.contains("127.0.0.1:11434")
|| base_url.contains("localhost:11434")
|| base_url.contains("host.docker.internal:11434") // Docker Desktop
}
三层识别从 id rarr; name rarr; base_url 逐级降级——不管用户怎么改名、怎么配置,只要端口是 11434 就跑不掉。
防御 2:强制 supportsEffort = false
pub fn resolve_codex_chat_reasoning_config(...) -> Option<CodexChatReasoningConfig> {
let mut config = /* 正常解析 */;
// 暴力兜底:不管 UI 表单写了什么,Ollama 一律关闭 reasoning_effort
if is_ollama_provider(provider) {
config.supports_effort = Some(false);
}
Some(config)
}
为什么要暴力? cc-switch 的 UI 表单在编辑供应商时会把 supportsEffort 覆盖为 true——这是个已知但影响面太大的问题。Ollama 不认识 reasoning.effort 参数,收到直接 400。代码层暴力关门,UI 怎么改都没用。
防御 3:apiFormat 缺失 fallback
pub fn codex_provider_uses_chat_completions(provider: &Provider) -> bool {
// 1. 查 meta.apiFormat
// 2. 查 settings_config.api_format
// 3. 查 settings_config.apiFormat
// 4. 查 config TOML 里的 wire_api
// 5. 查 base_url 是否含 chat/completions
// ...以上全挂?
// 终极兜底:Ollama 强制走 Chat 转换
if is_ollama_provider(provider) {
return true;
}
false
}
表单保存时 UI 会清空 meta.apiFormat——代理层不知道要做 Responses rarr; Chat 转换,直接透传 Responses 请求给 Ollama,Ollama 一脸懵逼。这个 fallback 确保 Ollama 永远走对协议。
3.5 健康检查退化
文件:src-tauri/src/services/stream_check.rs — 5 行改动
// isFullUrl=true 时健康检查把 base_url 当完整地址直接 GET
// 但 Ollama 的 base_url (http://127.0.0.1:11434/v1) 不含 /chat/completions rarr; 404
let effective_is_full = if uses_chat && is_full_url {
base_url.to_ascii_lowercase().contains("chat/completions")
} else {
is_full_url
};
一句话:如果配置里写了 isFullUrl=true 但实际 URL 里没 /chat/completions,别傻傻直接请求——退化回正常拼接模式。不然 CC Switch 的「供应商可用性」指示灯永远红色。
四、踩坑全景
| # | 问题 | 根因 | 解决方案 | 层面 |
|---|---|---|---|---|
| 1 | 502 代理没启动 | Codex 路由没开 | 设置里开启接管 | 配置 |
| 2 | 400 reasoning.effort |
UI 表单覆盖 supportsEffort=true |
Rust 层暴力关门 | 代码 |
| 3 | 404 端点丢失 | build_url 静默丢弃 /chat/completions |
二次校验补端点 | 代码 |
| 4 | 404 健康检查 | isFullUrl=true 跳过拼接 |
Chat 模式下退化 | 代码 |
| 5 | 表单清空 apiFormat |
UI 不写这个字段 | is_ollama 兜底 |
代码 |
| 6 | model_reasoning_effort=high |
provider.rs 生成逻辑 |
手动清理 TOML | 配置 |
使用提示:在 CC Switch 里添加 Ollama 供应商后,不要再编辑那个供应商的表单。编辑操作会触发 UI 覆盖
meta字段,虽然代码层有兜底,但能不触发就不触发。
五、跨平台测试实录
测试环境
| 平台 | 硬件 | 角色 |
|---|---|---|
| macOS 15 | M1 Pro / 16GB 统一内存 | 打包 + 开发 + 功能测试 |
| Windows 11 | RTX 5090 / 96GB DDR5 | 主力编码 + qwen3.5:35b GPU 推理 |
测试流程
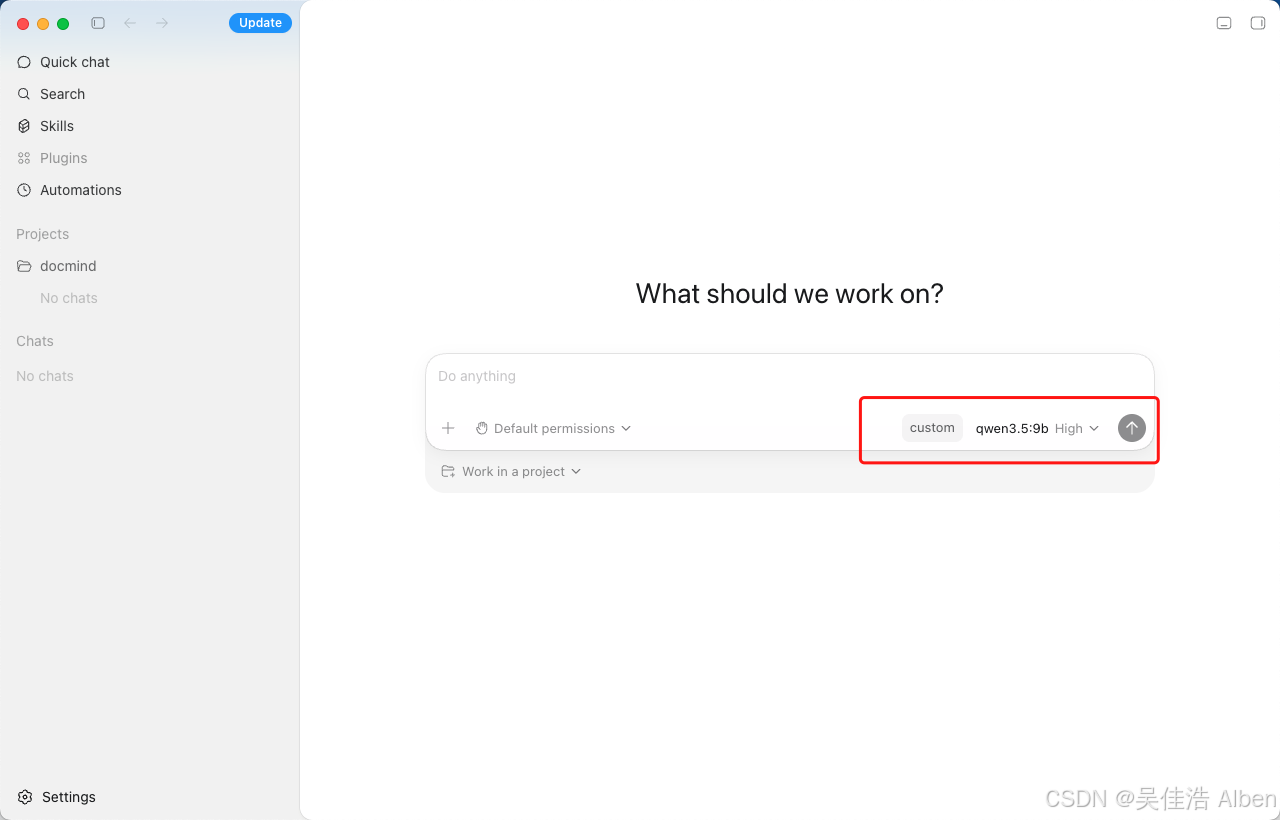
macOS M1 Pro:
添加 Ollama 供应商 rarr; local 分类正确
Codex 路由接管 rarr; 代理层正确路由
Codex CLI 模型列表 rarr; 本地模型正确展示
发送测试请求 rarr; 流式响应正常
PPT 制作完整流程 rarr; 工具调用链正常
Windows 11 + RTX 5090:
相同配置 rarr; 跨平台行为完全一致
M1 Pro 跑 qwen3.5:9b 用 ANE + GPU 混合推理,16GB 统一内存刚好够。Windows 那台跑的是 qwen3.5:35b——32GB 显存放量化 35B 模型轻轻松松,推理延迟低到几乎感知不到。
测试截图
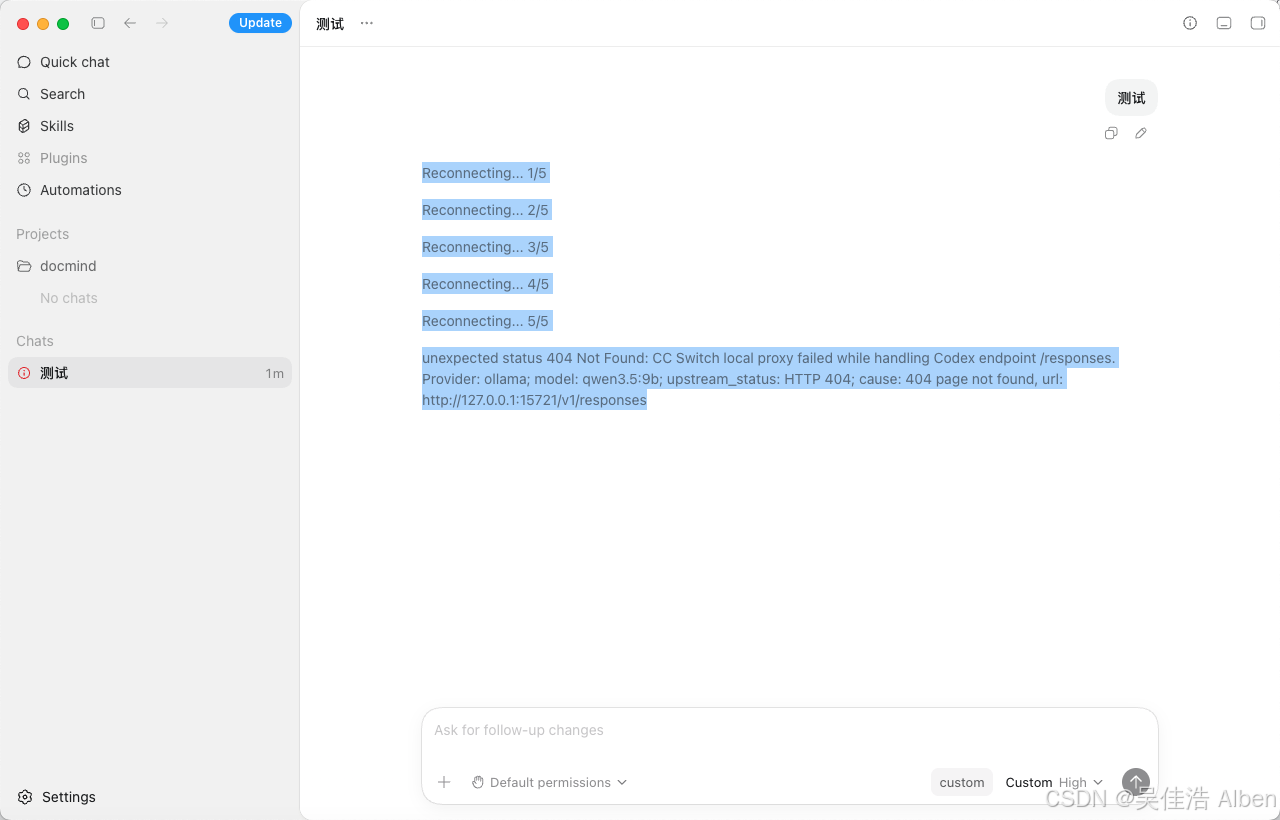
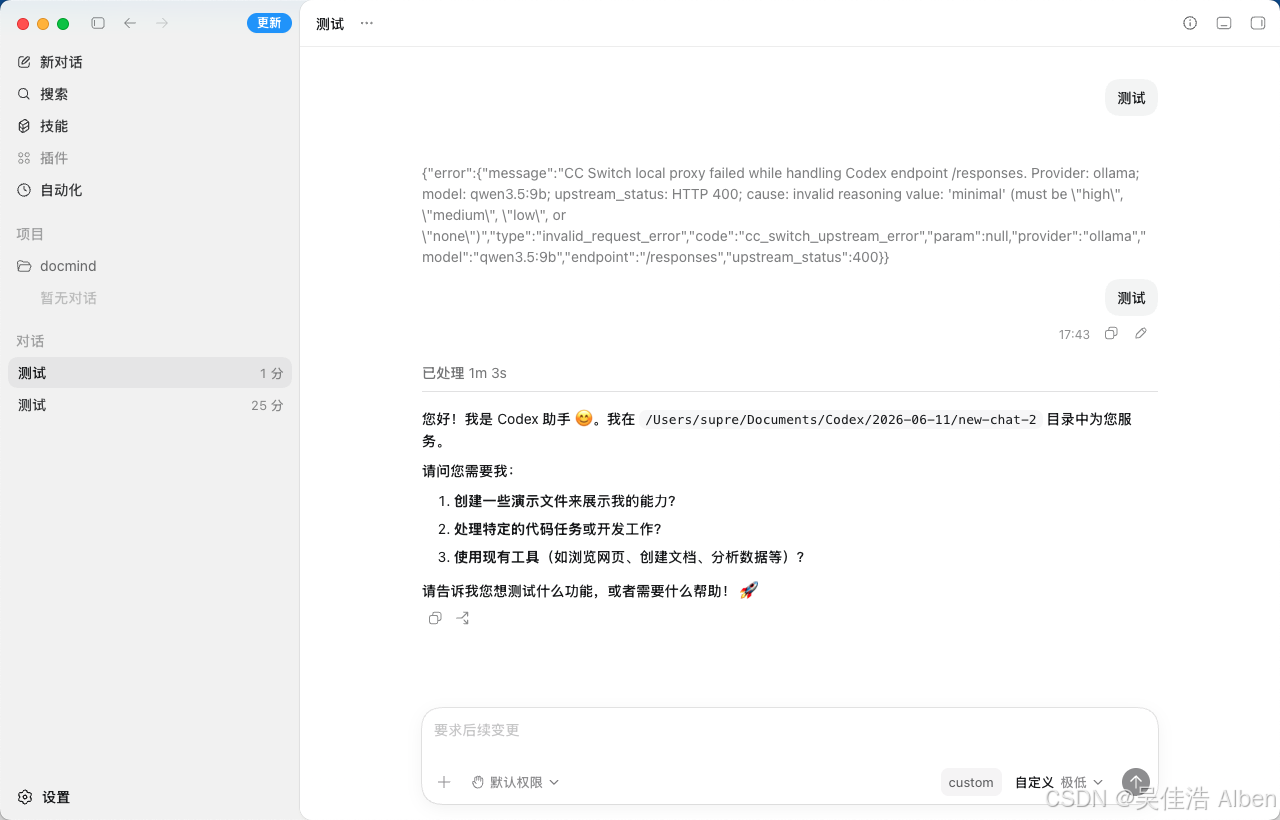
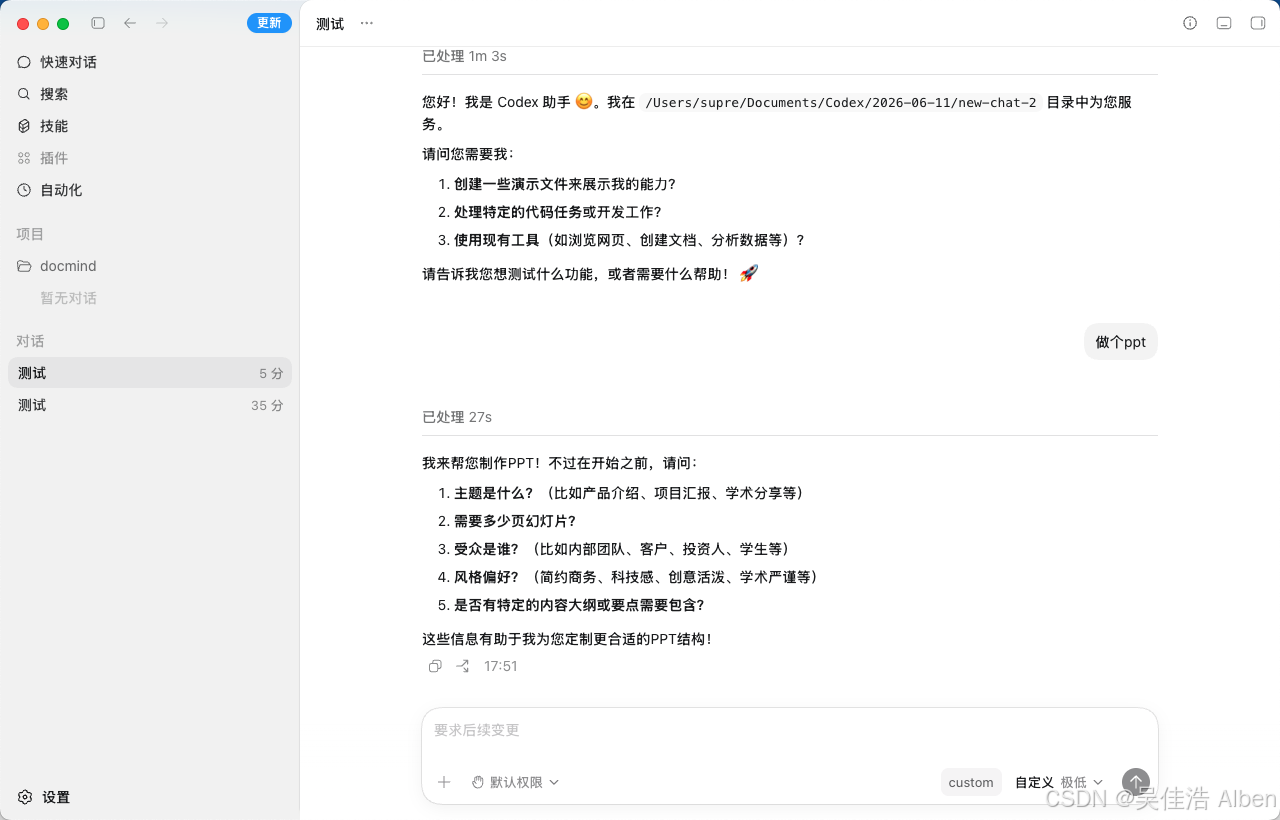
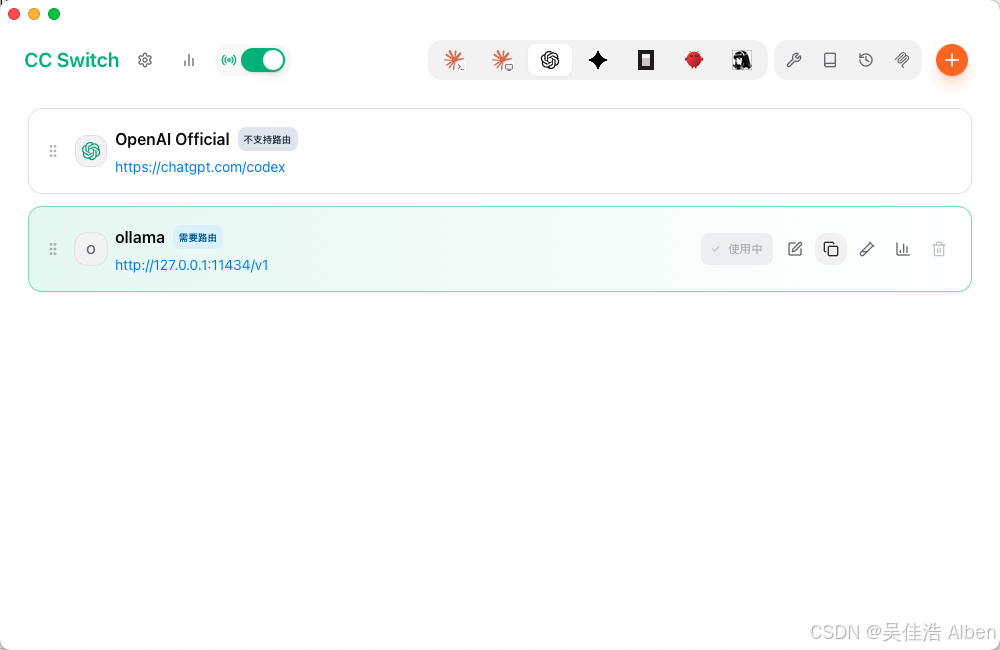
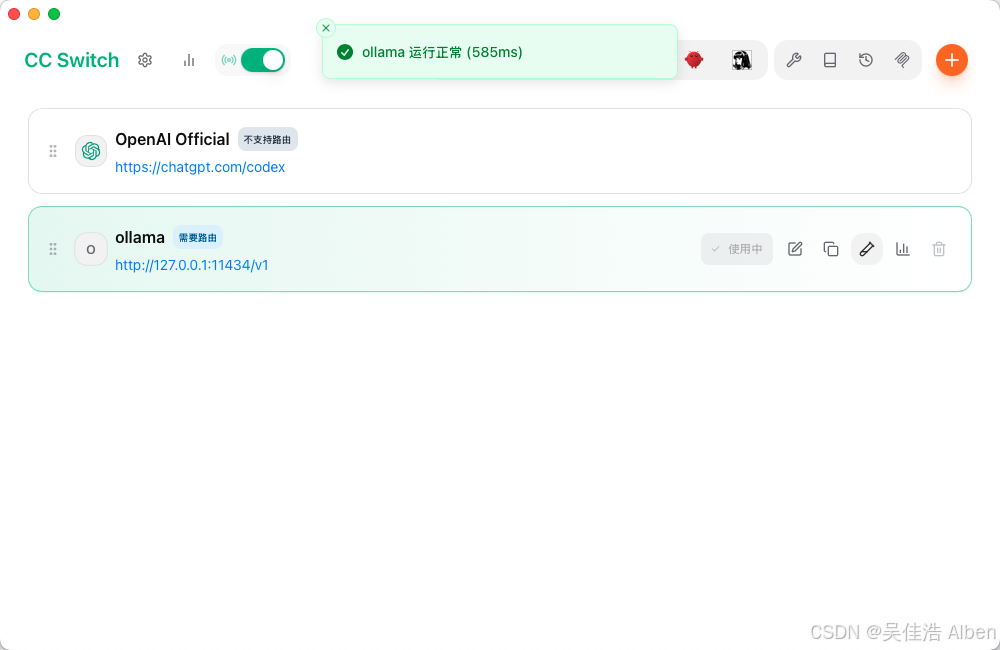
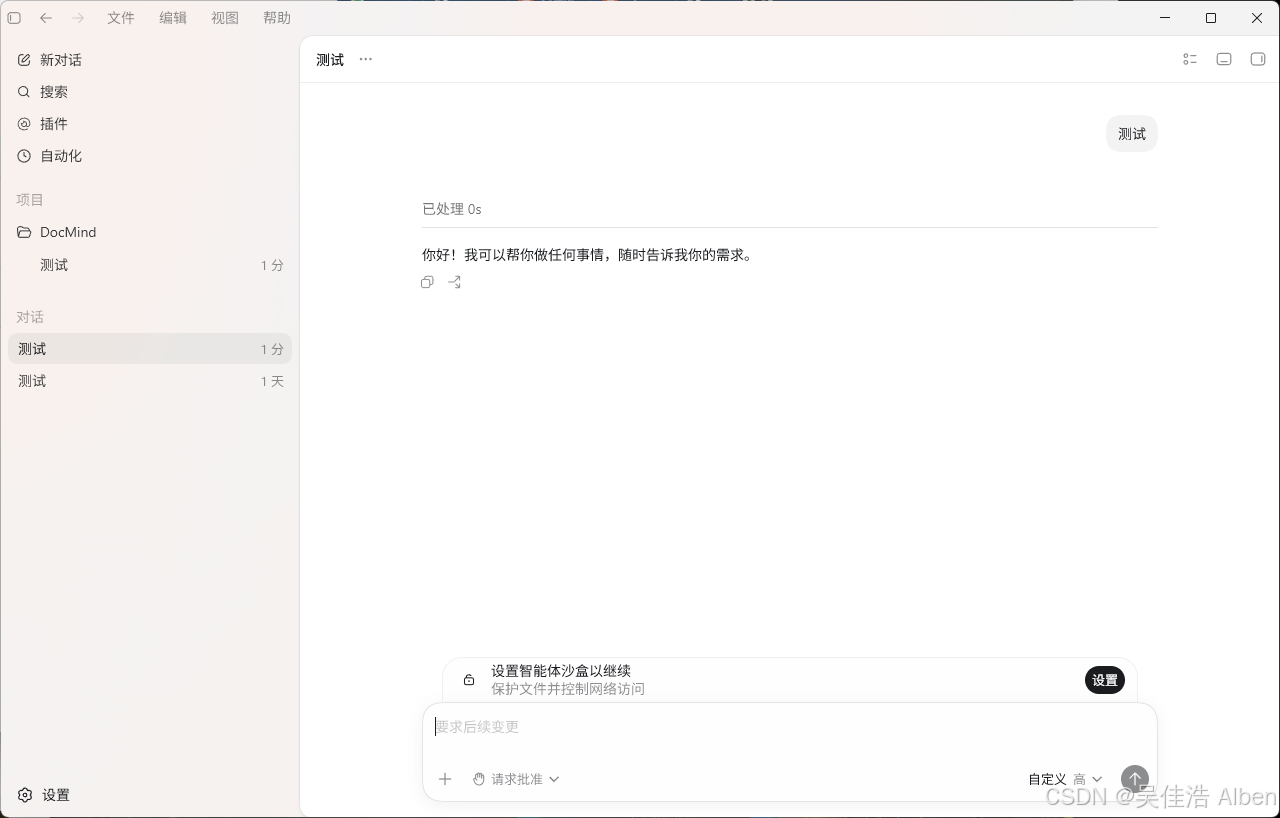
六、改动文件依赖关系
| # | 文件 | 改动量 | 致命程度 | 说明 |
|---|---|---|---|---|
| 1 | src/types.ts |
1 行 | 低 | 新增 "local" 分类枚举 |
| 2 | src/config/codexProviderPresets.ts |
~50 行 | 低 | Ollama 预设模板 + 5 模型 |
| 3 | src-tauri/src/proxy/forwarder.rs |
13 行 | 致命 | URL 端点丢失修复 |
| 4 | src-tauri/src/proxy/providers/codex.rs |
~60 行 | 高 | 识别函数 + effort + fallback |
| 5 | src-tauri/src/services/stream_check.rs |
5 行 | 中 | 健康检查 URL 退化 |
七、全链路数据流
三个关键决策点:
- 路由接管:Codex 的请求是走 Ollama 还是走云端?取决于用户在 CC Switch 里怎么配
- 协议转换:Ollama 只认 Chat Completions,Codex 说的是 Responses——必须翻
- 端点修复:
build_url偷偷丢了/chat/completions?补上
八、为什么代码层兜底而不是修 UI
这是个设计决策,值得单独说一下。
cc-switch 的 UI 层(TypeScript + Svelte)有大量历史遗留的表单逻辑。修复「编辑供应商时覆盖 meta 字段」这个 bug,看起来直接,但影响面很难评估——几十个供应商预设、多种表单模式、历史数据兼容。
俺的选择是:
UI 层的 bug 让 Rust 代理层扛。
具体来说:
| 问题 | UI 修复风险 | Rust 兜底方案 |
|---|---|---|
supportsEffort 被覆盖为 true |
高,影响所有供应商 | is_ollama_provider() rarr; force false |
apiFormat 被清空 |
高,多种表单路径 | is_ollama_provider() rarr; force chat |
build_url 丢端点 |
不是 UI 的锅,是适配器的 | 二次校验补齐 |
Rust 层的改动是加法——不影响现有行为,只在识别到 Ollama 时插入防御逻辑。这个策略让 PR 的 diff 干净、风险可控、不会引入回归。
九、安装 & 使用
macOS
从私有 Release 仓库下载 DMG:
下载地址一 XiaoBinGan/cc-switch-beta Releases(v3.16.2-beta)
仓库目前设为公开,需要的直接下载。
Windows
从私有 Release 仓库下载 DMG:
下载地址一 XiaoBinGan/cc-switch-beta Releases(v3.16.2-beta)可直接下载安装遇到拦截继续执行即可
仓库目前设为公开,需要的直接下载。
如果你想自己手动变异的话需要注意
macOS 没法交叉编译 Windows 包(Tauri 的跨平台编译限制),需要在 Windows 上手动打包:
git clone https://github.com/XiaoBinGan/cc-switch.git
cd cc-switch
git checkout feat/ollama-codex-proxy
pnpm install
pnpm exec tauri build
配置步骤
1. 确保 Ollama 运行中(默认 :11434)
2. 安装修改版 CC Switch
3. 「供应商」rarr; 添加 rarr; 找到 Ollama (Local) 预设
4. base_url 填 http://127.0.0.1:11434/v1
5. 「Codex 路由」rarr; 开启接管 rarr; 选 Ollama
6. 终端执行 codex rarr; 看到本地模型列表
十、总结
一句话
5 个 commit,让 CC Switch 的 Codex 路由能直接打到本机 Ollama。全程本地推理,零 API 费用,双平台测试通过。
改了什么 vs 得到了什么
| 维度 | 改之前 | 改之后 |
|---|---|---|
| 费用 | 必须走云端,月费 $200+ | 本地免费,只有电费 |
| 首 token 延迟 | 500ms ~ 2s | <50ms |
| 隐私 | 代码出本机 | 全程本地 |
| 离线 | 不可用 | 断网照用 |
| 管理入口 | Ollama 独立使用 | cc-switch 一站切换 |
技术精华
- URL 端点修复(
forwarder.rs)— 全 PR 最致命的 bug,适配器build_url静默丢弃/chat/completions,整个请求链路就断在这 - 三层防御(
codex.rs)—is_ollama_provider()从 id rarr; name rarr; base_url 逐级识别,三条路全堵死 - 暴力兜底 — UI 表单有 bug?不修 UI,在 Rust 层硬扛。
supportsEffort=false+apiFormatfallback 双保险 outputFormat: "reasoning"— Ollama 的 thinking tokens 走delta.reasoning,不是delta.thinking。这个值配错,Codex CLI 直接崩,没有任何报错
上游 PR
PR #4075 — 已提交,等审核
欢迎支持,让更多人在 cc-switch 里用上本地模型。
附录:论断溯源索引
| # | 论断 | 验证状态 | 源文件 |
|---|---|---|---|
| 1 | ProviderCategory 新增 "local" 分类 |
已验证 | src/types.ts |
| 2 | Ollama 预设含 5 个模型,apiFormat: "openai_chat" |
已验证 | src/config/codexProviderPresets.ts |
| 3 | outputFormat: "reasoning" 对应 Ollama 的 delta.reasoning |
已验证 | codexProviderPresets.ts + Ollama API 文档 |
| 4 | build_url 在 base_url 以 /v1 结尾时丢弃 endpoint |
已验证 | src-tauri/src/proxy/forwarder.rs(build_url 逻辑) |
| 5 | forwarder.rs 的 URL 二次校验逻辑 | 已验证 | src-tauri/src/proxy/forwarder.rs(PR diff) |
| 6 | is_ollama_provider() 三层识别(id/name/base_url) |
已验证 | src-tauri/src/proxy/providers/codex.rs(PR diff) |
| 7 | resolve_codex_chat_reasoning_config() 强制 supportsEffort=false |
已验证 | src-tauri/src/proxy/providers/codex.rs(PR diff) |
| 8 | codex_provider_uses_chat_completions() 兜底 is_ollama_provider() |
已验证 | src-tauri/src/proxy/providers/codex.rs(PR diff) |
| 9 | stream_check.rs 的 effective_is_full 退化逻辑 |
已验证 | src-tauri/src/services/stream_check.rs(PR diff) |
| 10 | 双平台测试通过(macOS M1 Pro + Windows RTX 5090) | 已验证 | 截图记录 |
本文基于对 cc-switch fork 源码的直接修改和双平台实测写成。如果你发现错误或踩了新的坑,欢迎在 PR 下面留言或者私信俺。
感谢 cc-switch 上游作者 farion1231 的优秀架构设计——代理层的协议转换和适配器模式是这次改动能控制在 5 个 commit 的基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)