AI Infra 硬件体系与编程模型:14. CUDA编程基础:事件与精确性能测量
CUDA事件与精确性能测量:让优化有据可依
在之前的系列文章中,我们学习了CUDA的核函数、内存模型、共享内存优化和CUDA流技术。但所有这些优化都建立在一个前提之上:我们能够精确地测量程序的性能。
"如果你不能测量它,你就不能优化它。"这句话在CUDA编程中尤为重要。很多初学者花费大量时间"优化"代码,却因为使用了错误的测量方法,根本不知道自己的优化是否真的有效,甚至可能让程序变得更慢。
CUDA提供了专门的事件(Event)机制来解决这个问题。它基于GPU硬件时间戳,能够精确到纳秒级别,是测量GPU操作执行时间的唯一正确方法。本文将详细讲解CUDA事件的工作原理、使用方法、高级技巧,以及如何进行科学严谨的性能测量。
一、为什么不能用CPU计时?
在讲解CUDA事件之前,我们首先要明确一个重要结论:绝对不要使用CPU的计时函数来测量GPU操作的执行时间。
很多初学者会习惯性地使用C++标准库的std::chrono或者C语言的clock()函数来测量核函数的执行时间,比如这样:
// 错误示例:使用CPU计时测量GPU核函数
auto start = std::chrono::high_resolution_clock::now();
kernel<<<grid, block>>>(d_data, n);
auto end = std::chrono::high_resolution_clock::now();
std::chrono::duration<float> duration = end - start;
printf("Kernel time: %.2f ms\n", duration.count() * 1000);
这个代码看起来很合理,但它测量的结果是完全错误的。为什么?因为CUDA核函数是异步执行的。
当你调用kernel<<<>>>时,CPU只是将核函数启动命令提交到GPU的队列中,然后立即返回继续执行后续代码。所以上面的代码测量的只是核函数启动的CPU开销,而不是核函数在GPU上的实际执行时间。
即使你在中间添加了cudaDeviceSynchronize():
auto start = std::chrono::high_resolution_clock::now();
kernel<<<grid, block>>>(d_data, n);
cudaDeviceSynchronize();
auto end = std::chrono::high_resolution_clock::now();
这个结果仍然不够准确,因为它包含了:
- CPU调用核函数的开销
- 核函数在GPU队列中等待的时间
- 核函数的实际执行时间
cudaDeviceSynchronize()的CPU开销
而且,CPU和GPU的时钟是不同步的,这会引入额外的误差。对于执行时间很短的核函数(比如几微秒),这些误差可能会超过实际执行时间本身。
二、CUDA事件:GPU级别的精确计时
CUDA事件是专门为测量GPU操作而设计的机制。它基于GPU硬件的内部时钟,能够提供纳秒级别的精度,并且完全不依赖于CPU的时钟。
2.1 什么是CUDA事件?
CUDA事件本质上是GPU时间线上的一个标记点。你可以在GPU的任何流中记录一个事件,当GPU执行到这个标记点时,事件就会被标记为"完成"。
通过记录两个事件:一个在操作开始前,一个在操作结束后,然后计算这两个事件之间的时间差,就可以精确地得到这个操作在GPU上的实际执行时间。
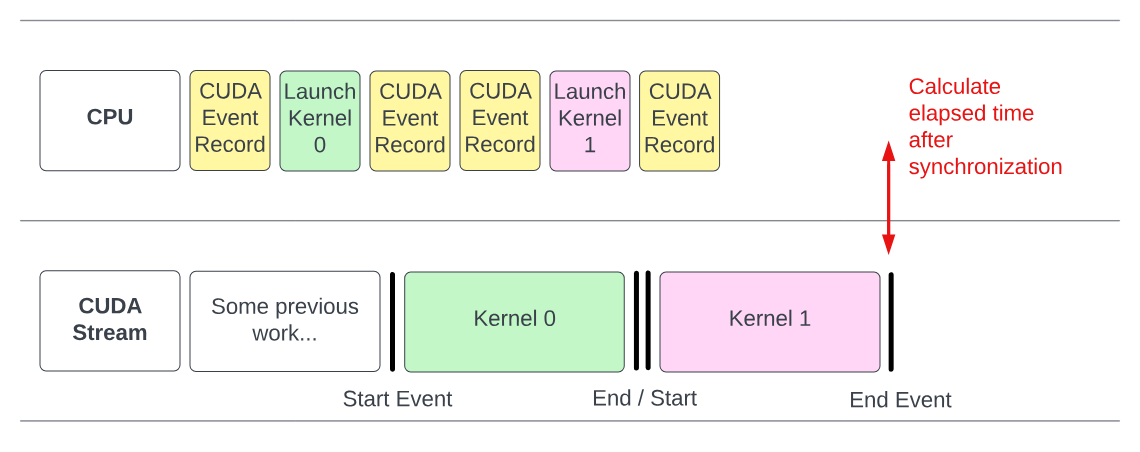
2.2 CUDA事件的基本使用流程
使用CUDA事件测量时间的基本流程分为四步:
- 创建两个事件对象:开始事件和结束事件
- 在操作开始前记录开始事件
- 在操作结束后记录结束事件
- 等待结束事件完成,然后计算两个事件之间的时间差
2.3 完整代码示例:测量单个核函数的执行时间
#include <iostream>
#include <cuda_runtime.h>
#define CHECK_CUDA_ERROR(err) \
if (err != cudaSuccess) { \
std::cerr << "CUDA Error: " << cudaGetErrorString(err) << " at line " << __LINE__ << std::endl; \
exit(1); \
}
__global__ void vectorAdd(const float* a, const float* b, float* c, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
c[i] = a[i] + b[i];
}
}
int main() {
const int n = 1 << 25; // 33M元素,约132MB
const size_t size = n * sizeof(float);
// 分配和初始化内存
float *h_a, *h_b, *h_c;
CHECK_CUDA_ERROR(cudaHostAlloc(&h_a, size, cudaHostAllocDefault));
CHECK_CUDA_ERROR(cudaHostAlloc(&h_b, size, cudaHostAllocDefault));
CHECK_CUDA_ERROR(cudaHostAlloc(&h_c, size, cudaHostAllocDefault));
for (int i = 0; i < n; i++) {
h_a[i] = static_cast<float>(i);
h_b[i] = static_cast<float>(i * 2);
}
float *d_a, *d_b, *d_c;
CHECK_CUDA_ERROR(cudaMalloc(&d_a, size));
CHECK_CUDA_ERROR(cudaMalloc(&d_b, size));
CHECK_CUDA_ERROR(cudaMalloc(&d_c, size));
// 数据传输
CHECK_CUDA_ERROR(cudaMemcpy(d_a, h_a, size, cudaMemcpyHostToDevice));
CHECK_CUDA_ERROR(cudaMemcpy(d_b, h_b, size, cudaMemcpyHostToDevice));
// 核函数配置
int blockSize = 256;
int gridSize = (n + blockSize - 1) / blockSize;
// ====================== 开始测量 ======================
// 1. 创建事件
cudaEvent_t start, stop;
CHECK_CUDA_ERROR(cudaEventCreate(&start));
CHECK_CUDA_ERROR(cudaEventCreate(&stop));
// 2. 记录开始事件
CHECK_CUDA_ERROR(cudaEventRecord(start));
// 3. 执行核函数
vectorAdd<<<gridSize, blockSize>>>(d_a, d_b, d_c, n);
CHECK_CUDA_ERROR(cudaGetLastError());
// 4. 记录结束事件
CHECK_CUDA_ERROR(cudaEventRecord(stop));
// 5. 等待结束事件完成
CHECK_CUDA_ERROR(cudaEventSynchronize(stop));
// 6. 计算时间差(单位:毫秒)
float milliseconds;
CHECK_CUDA_ERROR(cudaEventElapsedTime(&milliseconds, start, stop));
printf("VectorAdd kernel execution time: %.3f ms\n", milliseconds);
// ====================== 结束测量 ======================
// 验证结果
CHECK_CUDA_ERROR(cudaMemcpy(h_c, d_c, size, cudaMemcpyDeviceToHost));
bool success = true;
for (int i = 0; i < n; i++) {
if (h_c[i] != h_a[i] + h_b[i]) {
std::cerr << "Result verification failed at index " << i << std::endl;
success = false;
break;
}
}
if (success) {
std::cout << "Vector addition succeeded!" << std::endl;
}
// 销毁事件
CHECK_CUDA_ERROR(cudaEventDestroy(start));
CHECK_CUDA_ERROR(cudaEventDestroy(stop));
// 释放内存
CHECK_CUDA_ERROR(cudaFree(d_a));
CHECK_CUDA_ERROR(cudaFree(d_b));
CHECK_CUDA_ERROR(cudaFree(d_c));
CHECK_CUDA_ERROR(cudaFreeHost(h_a));
CHECK_CUDA_ERROR(cudaFreeHost(h_b));
CHECK_CUDA_ERROR(cudaFreeHost(h_c));
return 0;
}
2.4 关键API详解
1. cudaEventCreate
cudaError_t cudaEventCreate(cudaEvent_t* event);
- 功能:创建一个CUDA事件对象
- 参数:
event- 输出参数,指向创建的事件对象 - 返回值:CUDA错误码
2. cudaEventRecord
cudaError_t cudaEventRecord(cudaEvent_t event, cudaStream_t stream = 0);
- 功能:在指定的流中记录一个事件
- 参数:
event- 要记录的事件对象stream- 要记录事件的流,默认为默认流
- 返回值:CUDA错误码
重要说明:cudaEventRecord是异步的,它只是将记录事件的命令提交到流中,然后立即返回。事件会在GPU执行到流中的这个位置时被标记为完成。
3. cudaEventSynchronize
cudaError_t cudaEventSynchronize(cudaEvent_t event);
- 功能:阻塞主机线程,直到指定的事件完成
- 参数:
event- 要等待的事件对象 - 返回值:CUDA错误码
这是一个同步函数,它会一直阻塞,直到GPU上所有在记录该事件之前提交的操作都完成。
4. cudaEventElapsedTime
cudaError_t cudaEventElapsedTime(float* ms, cudaEvent_t start, cudaEvent_t stop);
- 功能:计算两个事件之间的时间差
- 参数:
ms- 输出参数,返回两个事件之间的时间差,单位为毫秒start- 开始事件stop- 结束事件
- 返回值:CUDA错误码
重要说明:
- 时间差的精度约为0.5微秒
- 两个事件必须在同一个设备上记录
- 必须先调用
cudaEventSynchronize(stop)等待结束事件完成,否则结果是未定义的
5. cudaEventDestroy
cudaError_t cudaEventDestroy(cudaEvent_t event);
- 功能:销毁一个CUDA事件对象,释放资源
- 参数:
event- 要销毁的事件对象 - 返回值:CUDA错误码
三、CUDA事件的高级用法
3.1 测量多流操作的执行时间
CUDA事件可以和流完美结合,用来测量多流程序中各个操作的执行时间,以及验证计算与传输的重叠效果。
// 测量多流向量加法的各个阶段时间
void measureMultiStream(const float* h_a, const float* h_b, float* h_c, int n) {
const int numStreams = 4;
const int blockSize = 256;
int elementsPerStream = (n + numStreams - 1) / numStreams;
size_t bytesPerStream = elementsPerStream * sizeof(float);
float *d_a, *d_b, *d_c;
cudaMalloc(&d_a, n * sizeof(float));
cudaMalloc(&d_b, n * sizeof(float));
cudaMalloc(&d_c, n * sizeof(float));
cudaStream_t streams[numStreams];
for (int i = 0; i < numStreams; i++) {
cudaStreamCreate(&streams[i]);
}
// 创建事件
cudaEvent_t totalStart, totalStop;
cudaEventCreate(&totalStart);
cudaEventCreate(&totalStop);
// 记录总开始时间
cudaEventRecord(totalStart);
// 向每个流提交操作
for (int i = 0; i < numStreams; i++) {
int offset = i * elementsPerStream;
int count = min(elementsPerStream, n - offset);
cudaMemcpyAsync(d_a + offset, h_a + offset, count * sizeof(float),
cudaMemcpyHostToDevice, streams[i]);
cudaMemcpyAsync(d_b + offset, h_b + offset, count * sizeof(float),
cudaMemcpyHostToDevice, streams[i]);
int gridSize = (count + blockSize - 1) / blockSize;
vectorAdd<<<gridSize, blockSize, 0, streams[i]>>>(
d_a + offset, d_b + offset, d_c + offset, count);
cudaMemcpyAsync(h_c + offset, d_c + offset, count * sizeof(float),
cudaMemcpyDeviceToHost, streams[i]);
}
// 记录总结束时间
cudaEventRecord(totalStop);
cudaEventSynchronize(totalStop);
float totalTime;
cudaEventElapsedTime(&totalTime, totalStart, totalStop);
printf("Total multi-stream time: %.3f ms\n", totalTime);
// 销毁资源
cudaEventDestroy(totalStart);
cudaEventDestroy(totalStop);
for (int i = 0; i < numStreams; i++) {
cudaStreamDestroy(streams[i]);
}
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
3.2 测量单个流中各个阶段的时间
我们可以在每个流中插入多个事件,精确测量每个流中H2D传输、核函数计算和D2H传输各自的时间:
// 测量单个流的各个阶段时间
void measureStreamStages(const float* h_a, const float* h_b, float* h_c, int n) {
const int blockSize = 256;
int gridSize = (n + blockSize - 1) / blockSize;
size_t size = n * sizeof(float);
float *d_a, *d_b, *d_c;
cudaMalloc(&d_a, size);
cudaMalloc(&d_b, size);
cudaMalloc(&d_c, size);
cudaStream_t stream;
cudaStreamCreate(&stream);
// 创建事件
cudaEvent_t start, h2dEnd, kernelEnd, d2hEnd;
cudaEventCreate(&start);
cudaEventCreate(&h2dEnd);
cudaEventCreate(&kernelEnd);
cudaEventCreate(&d2hEnd);
// 记录开始事件
cudaEventRecord(start, stream);
// H2D传输
cudaMemcpyAsync(d_a, h_a, size, cudaMemcpyHostToDevice, stream);
cudaMemcpyAsync(d_b, h_b, size, cudaMemcpyHostToDevice, stream);
cudaEventRecord(h2dEnd, stream);
// 核函数计算
vectorAdd<<<gridSize, blockSize, 0, stream>>>(d_a, d_b, d_c, n);
cudaEventRecord(kernelEnd, stream);
// D2H传输
cudaMemcpyAsync(h_c, d_c, size, cudaMemcpyDeviceToHost, stream);
cudaEventRecord(d2hEnd, stream);
// 等待所有事件完成
cudaEventSynchronize(d2hEnd);
// 计算各个阶段的时间
float h2dTime, kernelTime, d2hTime, totalTime;
cudaEventElapsedTime(&h2dTime, start, h2dEnd);
cudaEventElapsedTime(&kernelTime, h2dEnd, kernelEnd);
cudaEventElapsedTime(&d2hTime, kernelEnd, d2hEnd);
cudaEventElapsedTime(&totalTime, start, d2hEnd);
printf("H2D transfer time: %.3f ms\n", h2dTime);
printf("Kernel execution time: %.3f ms\n", kernelTime);
printf("D2H transfer time: %.3f ms\n", d2hTime);
printf("Total time: %.3f ms\n", totalTime);
// 销毁资源
cudaEventDestroy(start);
cudaEventDestroy(h2dEnd);
cudaEventDestroy(kernelEnd);
cudaEventDestroy(d2hEnd);
cudaStreamDestroy(stream);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
}
通过这个测量,我们可以清楚地看到程序的时间分布,找到真正的性能瓶颈。比如,如果H2D传输时间占了总时间的80%,那么我们的优化重点就应该放在减少数据传输或者提高传输效率上,而不是优化核函数。
3.3 使用事件进行流同步
除了测量时间,CUDA事件还可以用来实现流之间的同步。通过cudaStreamWaitEvent函数,我们可以让一个流等待另一个流中的某个事件完成,从而实现灵活的任务依赖关系。
cudaError_t cudaStreamWaitEvent(cudaStream_t stream,
cudaEvent_t event,
unsigned int flags = 0);
这个函数会让指定的流等待指定的事件完成后,再继续执行后续的操作。它不会阻塞主机线程,只会影响GPU上流的执行顺序。
代码示例:
cudaStream_t stream1, stream2;
cudaStreamCreate(&stream1);
cudaStreamCreate(&stream2);
cudaEvent_t event;
cudaEventCreate(&event);
// 流1执行一个核函数
kernel1<<<grid, block, 0, stream1>>>(d_data1, n);
cudaEventRecord(event, stream1);
// 流2等待流1的核函数完成后再执行
cudaStreamWaitEvent(stream2, event, 0);
kernel2<<<grid, block, 0, stream2>>>(d_data2, n);
这个特性在构建复杂的GPU流水线时非常有用,可以精确控制各个任务之间的依赖关系。
四、精确性能测量的最佳实践
使用CUDA事件进行性能测量看起来很简单,但有很多容易被忽视的细节会导致测量结果不准确。以下是经过工业界验证的最佳实践。
4.1 进行预热运行
第一次运行核函数时,会有很多额外的开销:
- CUDA驱动初始化
- 核函数的JIT编译(如果没有预编译)
- 内存页面的映射
- 缓存的预热
这些开销会让第一次运行的时间比实际运行时间长得多。因此,在进行正式测量之前,一定要先进行一次预热运行。
// 预热运行
vectorAdd<<<gridSize, blockSize>>>(d_a, d_b, d_c, n);
cudaDeviceSynchronize();
// 正式测量
cudaEventRecord(start);
vectorAdd<<<gridSize, blockSize>>>(d_a, d_b, d_c, n);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
4.2 多次测量取平均值
GPU的执行时间会有一定的波动,这是由于:
- GPU的动态频率调整
- 其他进程对GPU资源的竞争
- 操作系统的调度
为了得到稳定可靠的结果,应该多次运行同一个操作,然后取平均值。同时,最好去掉最高和最低的几个异常值。
const int iterations = 10;
float totalTime = 0.0f;
for (int i = 0; i < iterations; i++) {
cudaEventRecord(start);
vectorAdd<<<gridSize, blockSize>>>(d_a, d_b, d_c, n);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
float time;
cudaEventElapsedTime(&time, start, stop);
totalTime += time;
}
float averageTime = totalTime / iterations;
printf("Average kernel time: %.3f ms\n", averageTime);
4.3 避免测量内存分配和初始化的时间
cudaMalloc和cudaMemcpy的开销通常比核函数大得多,而且它们不是我们要优化的重点。因此,在测量核函数性能时,一定要将内存分配和数据传输的代码放在测量区间之外。
4.4 禁用GPU动态频率调整
现代GPU都支持动态频率调整,会根据负载自动调整核心频率和显存频率,以平衡性能和功耗。这会导致测量结果有很大的波动。
为了得到最稳定的测量结果,可以在NVIDIA控制面板中或者使用nvidia-smi命令将GPU设置为最高性能模式:
nvidia-smi -i 0 -pm 1 # 启用持久模式
nvidia-smi -i 0 -ac 1593,1710 # 设置为最高频率(具体值根据你的GPU型号而定)
4.5 确保GPU处于空闲状态
在进行性能测量时,确保没有其他进程在使用GPU。可以使用nvidia-smi命令查看GPU的使用情况。
4.6 不要测量空操作
不要测量一个什么都不做的核函数来估计核函数启动开销。编译器会优化掉空核函数,导致测量结果为0。
4.7 区分带宽和计算性能
在分析性能时,要区分程序是内存带宽受限还是计算能力受限:
- 对于内存带宽受限的程序,计算带宽利用率:
带宽利用率 = (实际数据传输量 / 执行时间) / 理论带宽 - 对于计算能力受限的程序,计算FLOPS:
FLOPS = (浮点运算次数 / 执行时间)
通过这些指标,你可以知道你的程序离GPU的理论极限还有多大差距。
五、常见误区与陷阱
5.1 忘记同步事件
这是最常见的错误。如果在调用cudaEventElapsedTime之前没有调用cudaEventSynchronize(stop),那么结束事件可能还没有完成,得到的时间差是未定义的,通常是0或者一个很小的随机数。
5.2 事件被销毁时还未完成
如果在事件还未完成时就调用cudaEventDestroy,会导致未定义行为。一定要确保在销毁事件之前,所有依赖该事件的操作都已经完成。
5.3 在不同的设备上记录事件
CUDA事件是和设备绑定的,不能在一个设备上记录事件,然后在另一个设备上计算时间差。
5.4 测量包含了CPU代码的时间
确保测量区间内只包含GPU操作,不要包含任何CPU代码。CPU代码的执行时间会被包含在事件的时间差中,导致结果偏大。
5.5 过度依赖微基准测试
微基准测试只能测量单个操作的性能,不能反映整个程序的实际性能。在进行优化时,一定要测量整个应用程序的端到端性能。
六、CUDA事件 vs 其他性能分析工具
CUDA事件是一个轻量级的、精确的性能测量工具,但它也有局限性。它只能测量时间,不能告诉你为什么操作很慢。
对于更深入的性能分析,你需要使用专门的性能分析工具:
| 工具 | 用途 | 优势 | 劣势 |
|---|---|---|---|
| CUDA事件 | 测量GPU操作的执行时间 | 轻量级、精确、可编程 | 只能测量时间,不能分析性能瓶颈 |
| nvprof | 命令行性能分析工具 | 可以分析核函数的各项性能指标,如带宽利用率、Bank冲突次数等 | 输出不够直观 |
| Nsight Compute | 新一代GPU性能分析工具 | 提供详细的硬件级性能数据,可视化界面,支持逐行分析 | 比较重,学习曲线较陡 |
| Nsight Systems | 系统级性能分析工具 | 可以分析整个应用程序的CPU和GPU交互,查看时间线 | 对于单个核函数的分析不够深入 |
最佳实践:
- 使用CUDA事件进行快速的性能测量和回归测试
- 使用Nsight Systems查看整个程序的时间线,找到性能瓶颈
- 使用Nsight Compute深入分析单个核函数的性能问题
七、总结
精确的性能测量是所有优化工作的基础。CUDA事件提供了一种轻量级、精确的方法来测量GPU操作的执行时间,是每个CUDA开发者必须掌握的工具。
本文详细讲解了:
- 为什么不能用CPU计时函数测量GPU操作
- CUDA事件的工作原理和基本使用方法
- 如何测量多流操作和各个阶段的执行时间
- 如何使用事件进行流同步
- 精确性能测量的最佳实践和常见误区
- CUDA事件与其他性能分析工具的对比
掌握了CUDA事件,你就能够科学地评估你的优化效果,让每一次优化都有据可依。在后续的文章中,我们将使用CUDA事件来验证各种优化技术的实际效果,并深入学习Nsight Compute的使用方法,进行更深入的性能分析。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)