P5:基于Pytorch实现运动鞋识别
- 🍨 本文为🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者:K同学啊
学习目的:学会调整模块提升准确率
一、 前期准备
关于环境
- 语言环境:Python3.13
- 编译器:vsCode
- 深度学习环境:torch==2.11.0+cu130;torchvision==0.26.0+cu130torchvision==0.26.0+cu130
1.设置GPU
设置分析环境:
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device运行结果:
![]()
2. 导入数据
由于本次是本地数据,因此不需要有download代码,只需读取路径里的数据集即可
import os,PIL,random,pathlib
data_dir = './5-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[1] for path in data_paths]
classeNames代码运行结果:
![]()
数据集内已划分好训练集和测试集,因此无需再次随机划分
3.图片预处理
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
# transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
test_transform = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
train_dataset = datasets.ImageFolder("./5-data/train/",transform=train_transforms)
test_dataset = datasets.ImageFolder("./5-data/test/",transform=test_transform)代码解读:
在进行图片识别前,为提高模型的泛化能力,一般要对图片进行统一的预处理 以保证图片的基本格式一致
模型要求输入尺寸一致 → Resize。
PyTorch 模型要求输入是张量 → ToTensor。
标准化有助于模型更快收敛 → Normalize。
mean与std数值是怎么来的?
这些均值和标准差是通过计算ImageNet数据集中所有训练图像的RGB通道均值和标准差得出的。具体计算过程如下:
获取ImageNet数据集:ImageNet包含120万张训练图像,每张图像通常具有RGB三个通道。
计算均值(Mean):
遍历所有图像,分别计算每个通道(R、G、B)的像素值平均值,得到:
Red 通道均值 ≈ 0.485
Green 通道均值 ≈ 0.456
Blue 通道均值 ≈ 0.406
计算标准差(Standard Deviation):
遍历所有图像,计算每个通道的像素值标准差,得到:
Red 通道标准差 ≈ 0.229
Green 通道标准差 ≈ 0.224
Blue 通道标准差 ≈ 0.225
train_dataset.class_to_idx代码解读:
total_data.class_to_idx是一个存储了数据集类别和对应索引的字典。在PyTorch的ImageFolder数据加载器中,根据数据集文件夹的组织结构,每个文件夹代表一个类别,class_to_idx字典将每个类别名称映射为一个数字索引。
具体来说,如果数据集文件夹包含两个子文件夹,比如Monkeypox和Others,class_to_idx字典将返回类似以下的映射关系:{'Monkeypox': 0, 'Others': 1}
相当于将0赋值于'Monkeypox';1赋值于'Others'
代码运行结果:
![]()
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break代码运行将结果:

根据运行结果可知图片以32张为一组,每一张图片的形状为[3,224,224]
二、构建简单的CNN网络
对于一般的CNN网络来说,都是由特征提取 网络和分类网络构成,其中特征提取网络用于提取图片的特征,分类网络用于将图片进行分类。
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv1=nn.Sequential(
nn.Conv2d(3, 12, kernel_size=5, padding=0), # 12*220*220
nn.BatchNorm2d(12),
nn.ReLU())
self.conv2=nn.Sequential(
nn.Conv2d(12, 12, kernel_size=5, padding=0), # 12*216*216
nn.BatchNorm2d(12),
nn.ReLU())
self.pool3=nn.Sequential(
nn.MaxPool2d(2)) # 12*108*108
self.conv4=nn.Sequential(
nn.Conv2d(12, 24, kernel_size=5, padding=0), # 24*104*104
nn.BatchNorm2d(24),
nn.ReLU())
self.conv5=nn.Sequential(
nn.Conv2d(24, 24, kernel_size=5, padding=0), # 24*100*100
nn.BatchNorm2d(24),
nn.ReLU())
self.pool6=nn.Sequential(
nn.MaxPool2d(2)) # 24*50*50
self.dropout = nn.Sequential(
nn.Dropout(0.2))
self.fc=nn.Sequential(
nn.Linear(24*50*50, len(classeNames)))
def forward(self, x):
batch_size = x.size(0)
x = self.conv1(x) # 卷积-BN-激活
x = self.conv2(x) # 卷积-BN-激活
x = self.pool3(x) # 池化
x = self.conv4(x) # 卷积-BN-激活
x = self.conv5(x) # 卷积-BN-激活
x = self.pool6(x) # 池化
x = self.dropout(x)
x = x.view(batch_size, -1) # flatten 变成全连接网络需要的输入 (batch, 24*50*50) ==> (batch, -1), -1 此处自动算出的是24*50*50
x = self.fc(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Model().to(device)
model代码运行结果: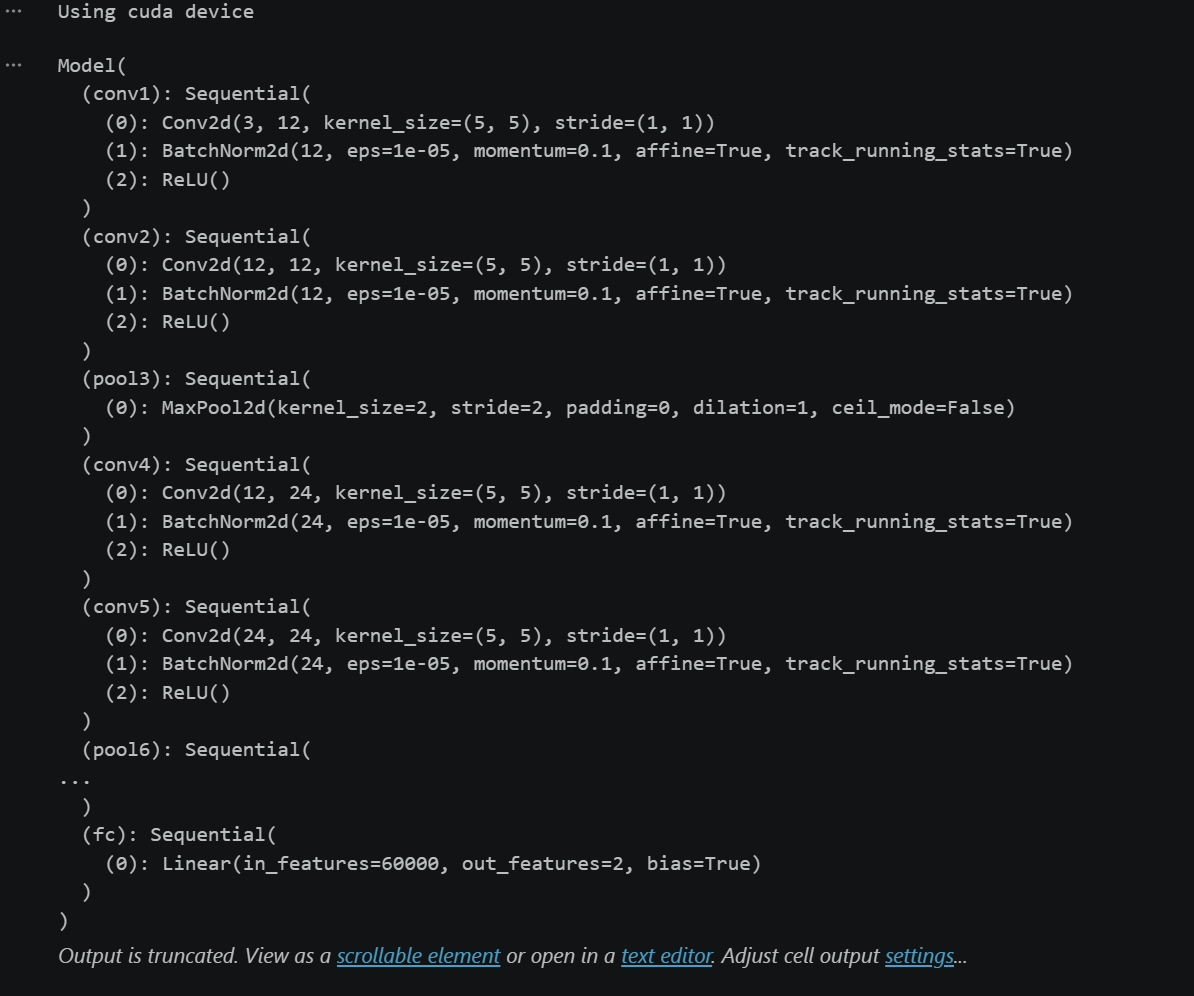
三、 训练模型
1.编写训练函数
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss2.编写测试函数
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小
num_batches = len(dataloader) # 批次数目, (size/batch_size,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss3. 设置动态学习率
def adjust_learning_rate(optimizer, epoch, start_lr):
# 每 2 个epoch衰减到原来的 0.92
lr = start_lr * (0.92 ** (epoch // 2))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
learn_rate = 1e-4 # 初始学习率
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)代码解读:
epoch:当前训练的轮数(从 0 开始计数)。
start_lr:初始学习率,这里设为1e-4。
epoch // 2:整数除法,例如:
epoch=0,1 → 0 → 0.92^0 = 1 → lr = 1e-4
epoch=2,3 → 1 → 0.92^1 = 0.92 → lr = 9.2e-5
epoch=4,5 → 2 → 0.92^2 ≈ 0.8464 → lr ≈ 8.46e-5
每经历 2 个 epoch,学习率乘以 0.92,呈指数下降。
什么是学习率(learning rate)?
学习率决定了模型参数每次更新的步长。
太大:可能震荡不收敛,甚至发散。
太小:收敛太慢,容易陷入局部最优。
为什么需要动态调整?
在训练初期,我们希望学习率大一点,快速接近最优解;到后期,希望学习率小一点,在最优解附近精细调整,避免来回震荡。
常用的策略有:阶梯下降、指数衰减、余弦退火等。在本次代码中使用的是阶梯下降的策略,其他策略还包括:
1. 指数衰减(Exponential Decay)
每个 epoch 都乘以一个固定的衰减率,比阶梯下降更平滑。
python
lr = start_lr * gamma ** epoch # gamma 通常取 0.9~0.99PyTorch 内置:
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.95)2. 余弦退火(Cosine Annealing)
学习率按照余弦函数周期性地下降,常用于训练后期精细调优。
python
lr = start_lr * 0.5 * (1 + cos(π * epoch / T_max))PyTorch 内置:
torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=50)3. 分段常数衰减(MultiStep Decay)
在预设的几个 epoch 节点(如 [30, 60, 80])突然降低学习率(如乘以 0.1)。
python
scheduler = MultiStepLR(optimizer, milestones=[30,60,80], gamma=0.1)4. 自适应调整(ReduceLROnPlateau)
当验证集上的损失或准确率在连续若干 epoch 内不再提升时,自动降低学习率。这种方法是基于训练状态而非固定步长。
python
scheduler = ReduceLROnPlateau(optimizer, mode='min', patience=5, factor=0.5)配合
scheduler.step(val_loss)在每个 epoch 后调用。5. 预热(Warmup)
前几个 epoch 学习率从很小逐渐上升到初始学习率,然后再进行衰减。常与余弦退火结合使用(如 “cosine with warmup”)。
6. 单周期(One Cycle)
学习率先线性上升到一个最大值,再对称下降,通常能更快收敛。PyTorch 提供
OneCycleLR。
4.正式训练
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
epochs = 40
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
# 更新学习率(使用自定义学习率时使用)
adjust_learning_rate(optimizer, epoch, learn_rate)
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer)
# scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
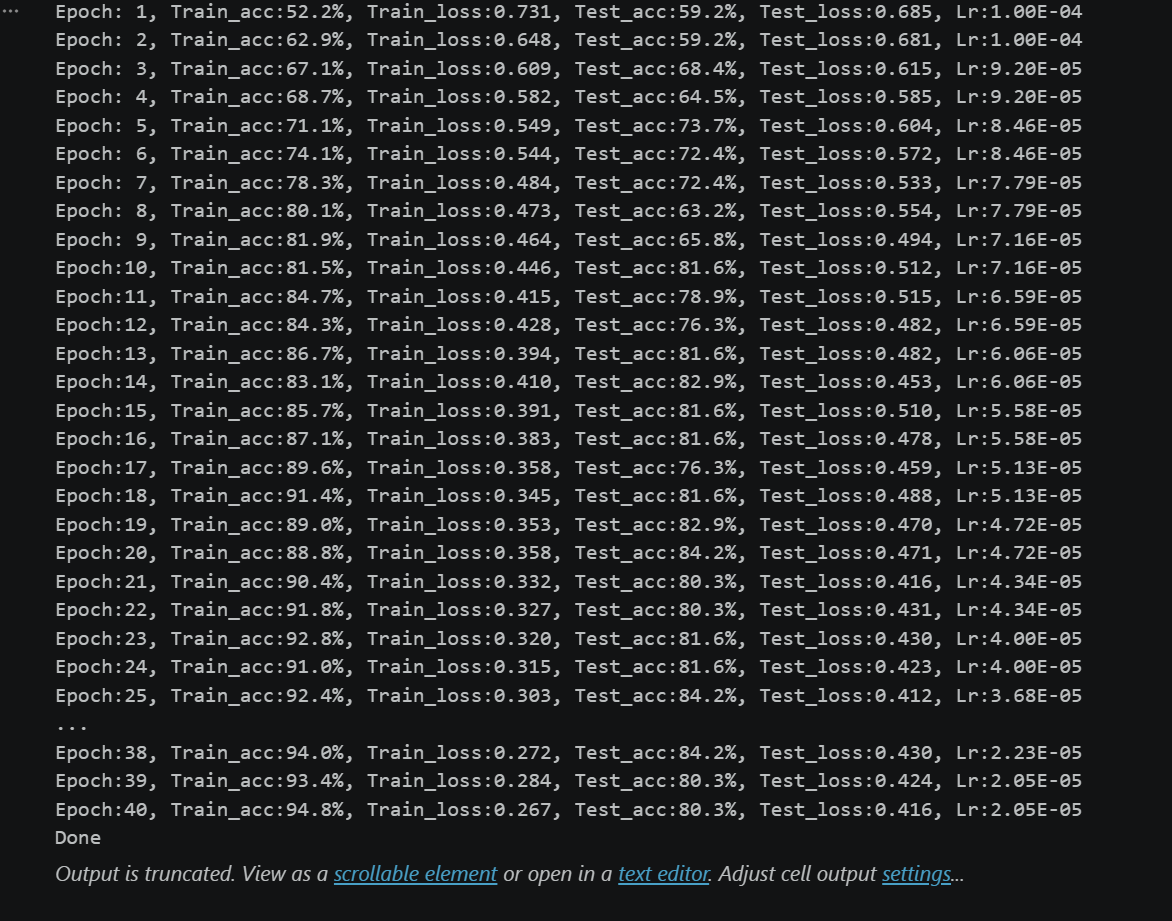
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss,
epoch_test_acc*100, epoch_test_loss, lr))
print('Done')代码解读:
每个 epoch 开始前先调整学习率,然后训练。
打印时显示当前学习率(如
1.00E-04、9.20E-05等)。
代码运行结果:
四、 结果可视化
1. Loss 与Accuracy图
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
from datetime import datetime
current_time = datetime.now() # 获取当前时间
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.xlabel(current_time) # 打卡请带上时间戳,否则代码截图无效
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()代码运行结果: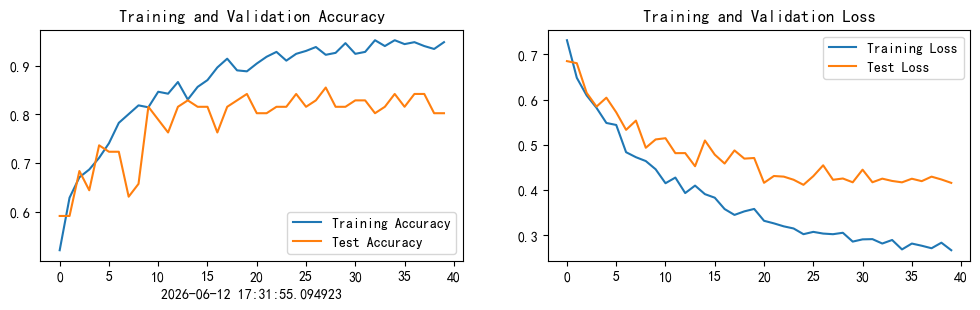
五、提高模型效能
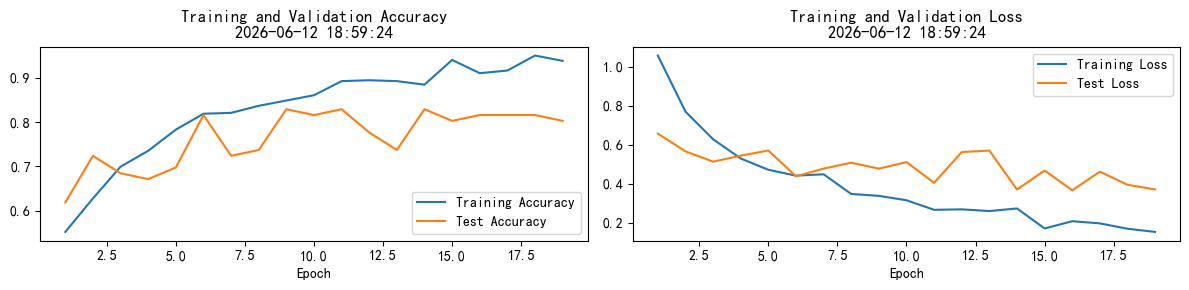
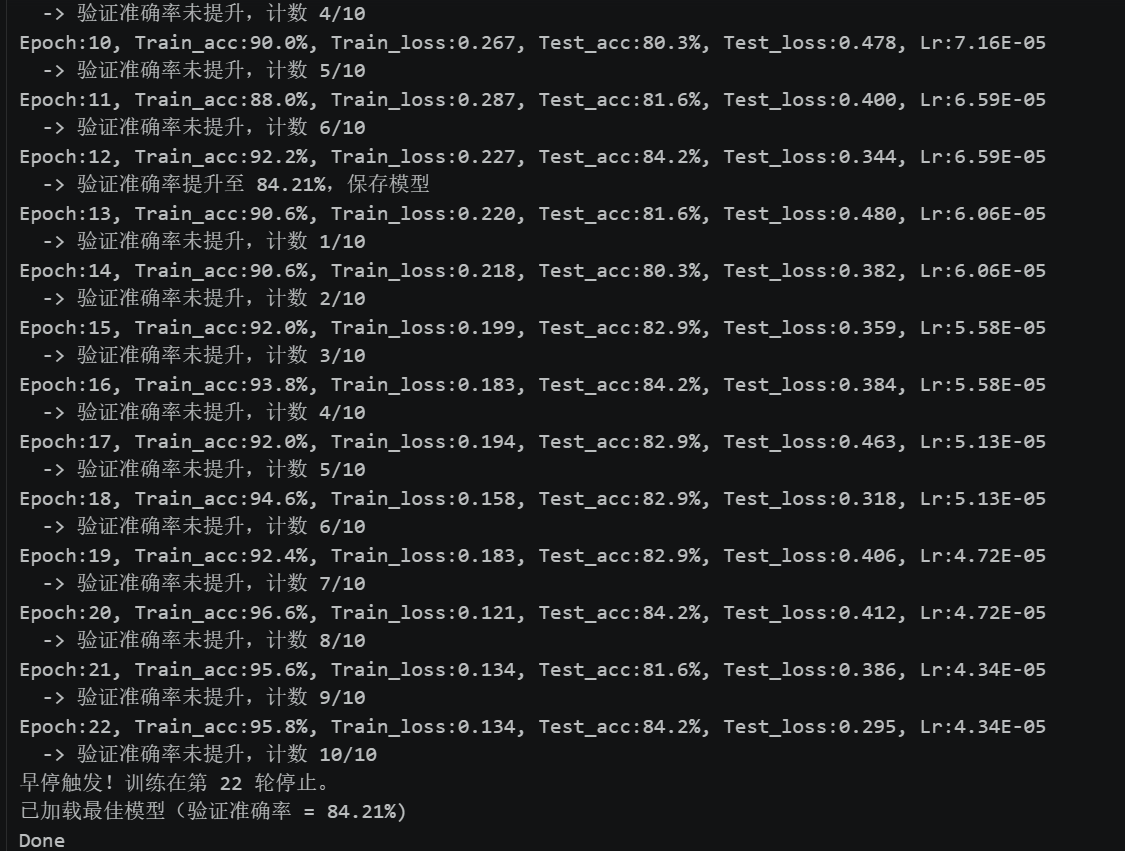
虽然目前模型的准确率已达84%,但是后面几个epoch训练集和测试集准确率相差有点大,说明出现了过拟合,为提高准确率,尝试提升Dropout正则化至0.5,未达到提升准确率的目的,同时调整优化器为Adam,但是严重过拟合,予提升Dropout正则化至0.6,依然过拟合,再次提升至0.7后测试集最佳模型准确率达85.5%,使用早停输出最佳模型,但过拟合情况依然存在。
Dropout正则化0.7,优化器为Adam运行结果:
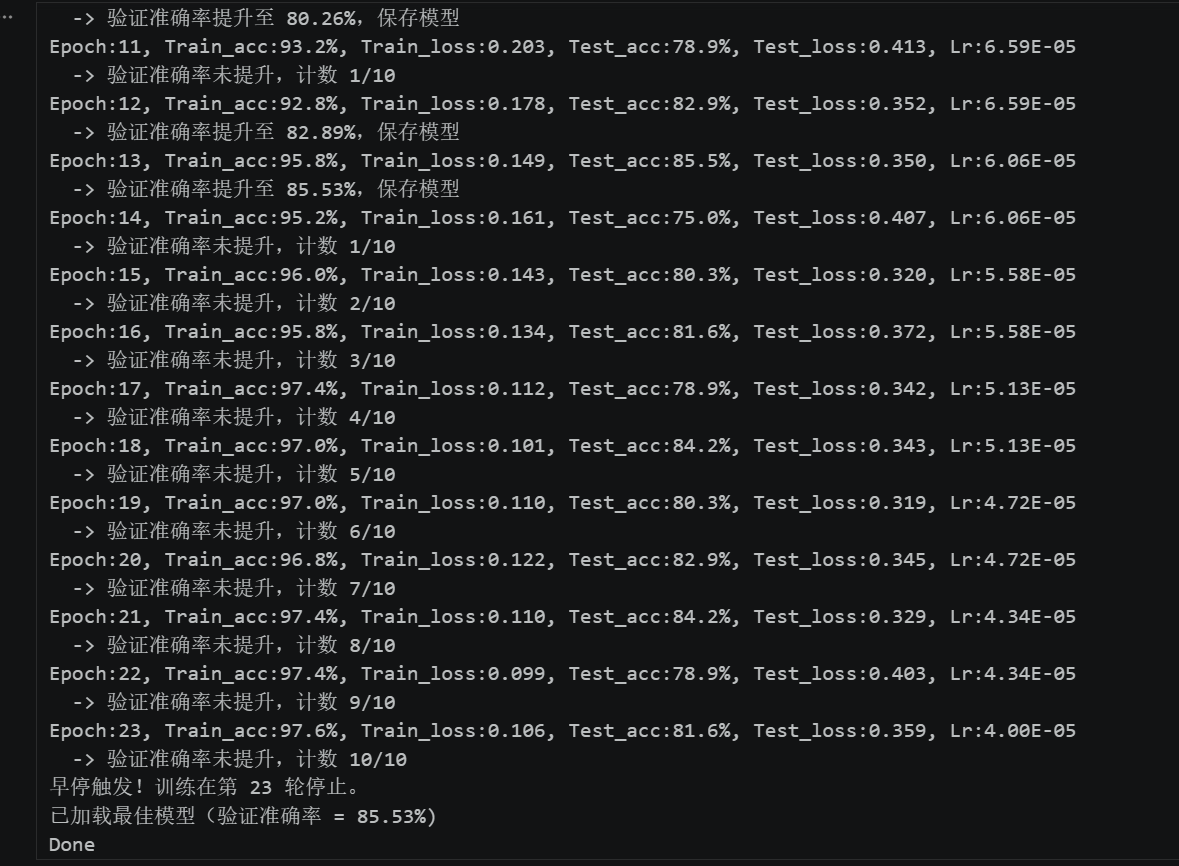
Dropout正则化0.8,优化器为Adam运行结果:
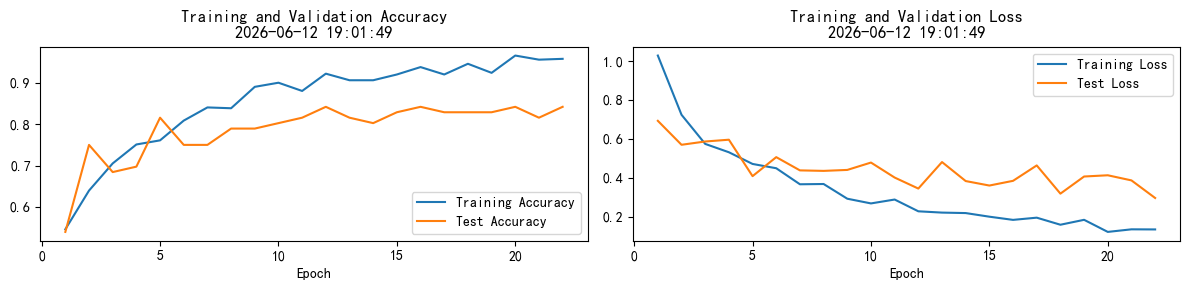
这个模型过拟合情况较严重,即使Dropout正则化至0.8依然提示过拟合,那么过拟合还有什么处理方法呢?deep seek回答:
1. 增加数据增强(Data Augmentation)
训练数据只做了
Resize、ToTensor、Normalize,没有使用任何数据增强(如随机翻转、旋转、裁剪等)。数据增强可以有效扩充训练样本的多样性,抑制过拟合。改进方法:在
train_transforms中添加随机变换。例如:python
train_transforms = transforms.Compose([ transforms.Resize([224, 224]), transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 transforms.RandomRotation(10), # 随机旋转 ±10 度 transforms.ColorJitter(brightness=0.2, contrast=0.2), # 颜色抖动 transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ])注意:测试集不应使用数据增强,只需
Resize+ToTensor+Normalize(保持原样)。
2. 增加 Dropout 强度或添加更多 Dropout 层
模型中已经在全连接层之前加了一个
Dropout(0.2),但可能强度不够。可以:
增大 dropout 概率,例如
Dropout(0.5)。在卷积层之间也添加 dropout(例如
nn.Dropout2d)。python
self.dropout = nn.Dropout(0.5) # 从 0.2 提高到 0.5注意:Dropout 只在训练时生效,
model.eval()时会自动关闭。
3. 使用权重衰减(Weight Decay,即 L2 正则化)
你的优化器是 SGD,但没有设置 weight decay。添加 weight decay 可以惩罚大的权重,使模型更简单。
修改优化器:
python
optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate, weight_decay=1e-4)常用 weight decay 值:
1e-4或5e-5。
4. 减小模型复杂度
你的模型对于这个二分类任务可能过于复杂(24×50×50 = 60000 个全连接输入特征)。可以尝试:
减少卷积层的通道数(例如 12→24 改为 12→16)。
减少卷积层数量(例如去掉 conv5)。
在全连接层之前增加全局平均池化(Global Average Pooling)代替直接展平,大幅减少参数量。
例如添加全局平均池化:
python
self.global_pool = nn.AdaptiveAvgPool2d((1, 1)) # 在 forward 中,pool6 之后调用 x = self.global_pool(x) # 然后 x = x.view(batch_size, -1) 得到 24 维特征,再送入全连接层这样全连接层的参数量从 60000×2 骤降到 24×2。
5. 早停(Early Stopping)
使用验证集准确率或损失作为早停依据,防止模型在训练后期过度拟合训练集。你已经有了早停的实现,这是抑制过拟合的有力工具。
6. 降低学习率或使用更平缓的学习率衰减
当前学习率从 1e-4 开始,每 2 个 epoch 乘以 0.92,40 轮后学习率约为 2e-5,整体学习率偏高。可以尝试:
初始学习率改为 5e-5。
使用更平缓的衰减(例如每 3 个 epoch 乘以 0.95)。
学习率过高可能导致模型在训练集上震荡,反而更容易过拟合。
7. 使用批量归一化
每个卷积层后使用
BatchNorm2d,这本身有轻微的正则化效果。
8. 收集更多数据
过拟合的根本原因是训练数据不足。如果可能,收集更多图片(尤其是多样化的背景、角度、光照),或者使用外部类似数据集预训练模型。
9. 使用预训练模型(迁移学习)
模型是随机初始化的。使用在大数据集(如 ImageNet)上预训练的模型(如 ResNet18、ResNet34),然后微调最后几层,可以显著减少过拟合。
六、总结
本周重点学习了动态学习率和模型过拟合后怎么办,动态学习率主要是为了保证在模型训练过程中在早期能够提升学习效率,在后期能够避免错过最佳模型。而在模型训练过程中,过拟合现象相对常见,在面对过拟合时要如何处理也是一个重要的工程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)