【学术干货】大规模激活:解锁 Diffusion Transformers 局部细节合成的新钥匙
自 2020 年以来,扩散概率模型(Diffusion Probabilistic Models)凭借其卓越的生成质量与稳定的训练过程,逐渐成为图像生成领域的主流范式。从早期的 DDPM、DDIM 到后来的 Stable Diffusion 系列,模型架构经历了从 U-Net 到 Transformer 的深刻变革。2023 年,Peebles 与 Xie 提出的 DiT(Diffusion Transformer)首次将标准 Transformer 架构引入扩散模型的骨干网络,为 Scaling Law 在生成模型中的应用奠定了坚实基础。紧随其后,Stability AI 发布的 SD3 与 Flux 进一步验证了 Diffusion Transformer(DiT)在高分辨率图像合成中的强大潜力,甚至被视作 Sora 等视频生成系统的核心技术底座之一。

然而,尽管 DiT 在整体语义保真度上表现优异,研究者们逐渐发现其在局部细节处理上存在明显短板——生成的图像往往在纹理细腻度、边缘锐利度以及局部结构一致性方面逊于部分基于 GAN 或自回归方法的竞品。这一问题的根源长期以来并不清晰,现有的优化思路多集中于增大模型参数量或调整噪声调度策略,缺乏对模型内部激活模式与生成行为之间关系的系统性认知。
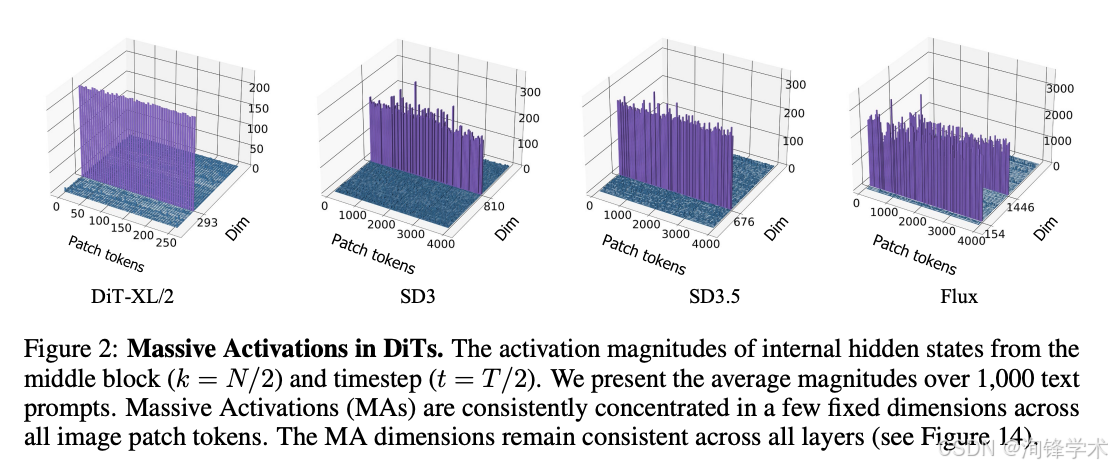
大规模激活(Massive Activations,后文简称 MAs)作为一种跨架构的普遍现象,在大型语言模型(LLMs)与视觉 Transformer(ViTs)中已有广泛记录。研究表明,这些异常高值的激活神经元往往与模型的关键决策行为高度相关。但 MAs 在 DiT 中的分布规律与功能角色,尚未得到充分探索。
研究动机
现有研究对 DiT 内部工作机制的理解仍存在显著空白。具体而言,三个方面值得深入追问:
第一,MAs 是否同样广泛存在于 DiT 架构中? 在 Transformer 驱动的语言与视觉模型中,MAs 已被证明具有结构性与规律性。然而,DiT 独特的时序注入机制(timestep embedding)与类别条件注入方式,使其激活分布可能呈现出与 LLM/ViT 截然不同的模式。这一问题构成理解 DiT 行为的第一步。
第二,MAs 在 DiT 的生成过程中承担何种功能角色? 如果 MAs 确实广泛存在,那么一个核心问题是:它们究竟是无关的副产物,还是对模型输出具有实质贡献的关键组件?辨别 MAs 的功能属性,对于理解 DiT 的工作机制以及指导针对性优化至关重要。
第三,能否利用 MAs 的特性开发新型引导策略? 在扩散模型的研究生态中,Classifier-Free Guidance(CFG)已成为提升生成质量的标准手段。能否从模型内部激活模式出发,设计一种全新的、无需额外训练的引导机制,以弥补 DiT 在局部细节上的不足?这是一个兼具理论价值与应用前景的探索方向。
正是基于上述考量,本文研究者决定对 DiT 中的 MAs 展开系统性实证研究,并在此基础上提出创新性的解决方案。
核心创新
本文的核心贡献可以归纳为以下三个层面:
发现一:DiT 中 MAs 的广泛性与规律性。 研究团队通过大规模激活追踪与统计分析,证实 MAs 并非偶发现象,而是系统性遍布于 DiT 所有空间 token 之中。更重要的是,这些 MAs 的分布密度并非固定不变,而是受到输入时序嵌入(timestep embedding)的动态调制——在去噪过程的特定阶段,MAs 的强度与覆盖范围会呈现显著的峰值特征。这一发现为后续的功能分析奠定了实证基础。
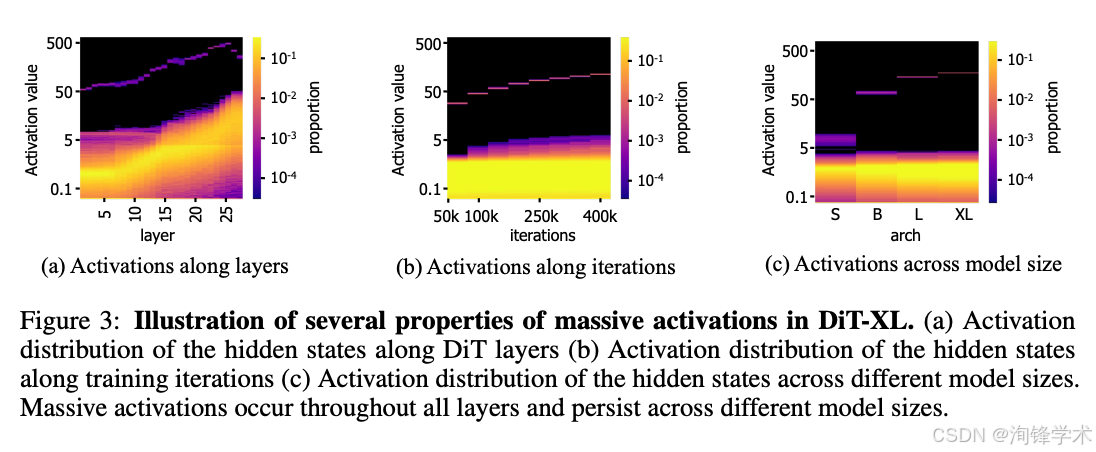
发现二:MAs 的局部细节合成功能。 通过消融实验与激活可视化,研究者进一步揭示了 MAs 的核心功能:它们在局部纹理、边缘细节与高频信息的合成中扮演着决定性角色。实验表明,通过人为破坏 MAs(提升部分激活值、抑制另一部分),模型的全局语义结构几乎不受影响,但局部细节会出现可感知的降质;反之,强化 MAs 信号则能显著提升图像的细节锐度。这一发现确立了 MAs 在 DiT 生成管线中的功能定位。
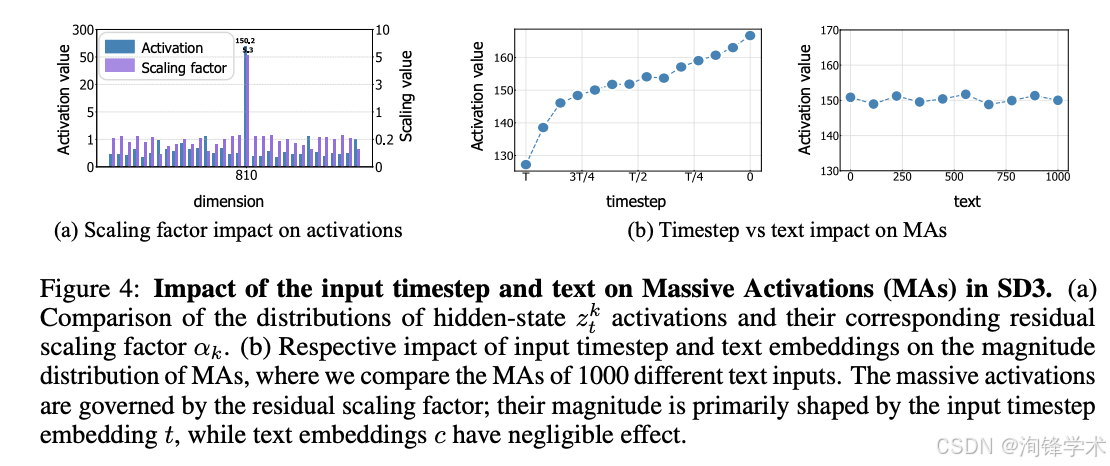
方法创新:Detail Guidance(DG)无训练引导策略。 基于上述发现,本文提出了一种全新的训练无关引导方法——Detail Guidance(DG)。其核心思想是利用 MAs 的破坏版模型作为“细节缺失教师”,通过对比原始模型与破坏版模型的输出差异,引导原始模型在去噪过程中更加关注细节信息的恢复。DG 的设计高度优雅:无需任何额外训练、无需额外数据集、无需微调权重,仅通过激活层面的操作即可实现。
整合创新:DG 与 CFG 的协同。 研究者进一步展示了 DG 与 CFG 的无缝融合方式。CFG 负责提升提示词对齐(prompt alignment)与全局语义质量,DG 则专注于局部细节增强。二者联合使用,可在保持强大语义控制能力的同时,系统性地改善生成图像的纹理质量、边缘清晰度与局部结构一致性。
技术方案详解
4.1 大规模激活的识别与分布特性
研究者首先定义了 MAs 的量化标准:在 DiT 的注意力层或前馈网络层中,激活值显著高于同层其他神经元平均水平的神经元被标记为 MAs。通过对 SD3、SD3.5 与 Flux 三种主流 DiT 模型进行激活追踪,研究者发现 MAs 具有以下统计特性:
- 空间广泛性: MAs 并非局限于少数空间位置,而是分布于几乎所有空间 token 上。
- 时序依赖性: MAs 的激活强度与去噪时间步(timestep)高度相关,在中间去噪阶段(如 t ≈ 0.3–0.7)MAs 的活跃程度最强。
- 层级特异性: MAs 在 DiT 的深层(如最后 4-6 层)中更为密集,表明它们参与的是高度抽象的特征整合过程。
4.2 功能消融实验设计
为验证 MAs 的功能角色,研究团队设计了系统性的消融实验:
- MA 破坏实验: 在给定层中人为抑制 MAs(将其激活值置零或缩放至均值水平),观察生成图像的变化。结果显示,全局布局与主要对象形态基本保持不变,但纹理区域出现明显的模糊与伪影。
- MA 增强实验: 通过正则化手段放大 MAs 的响应强度。结果显示,图像边缘锐度与纹理细节得到显著增强,且未出现明显的语义漂移。
- 语义-细节解耦分析: 进一步的分析表明,MAs 主要作用于模型的细节分支(detail branch),而对语义分支(semantic branch)的贡献相对有限。这一解耦发现为后续的引导策略设计提供了理论依据。
4.3 Detail Guidance(DG)方法框架
DG 的完整流程可概括为以下四个步骤:
步骤一:构建“细节缺失”模型。 对原始 DiT 的指定层进行 MAs 破坏,得到一个细节合成能力显著下降但语义理解能力基本保留的退化模型 M'。
步骤二:双路径推理。 在每个去噪时间步,同时运行原始模型 M 与退化模型 M',获取对应的预测噪声 ϵθ(xt,t,c) 与 ϵθ′(xt,t,c)。
步骤三:差异导向。 计算两模型输出之间的差异向量 Δϵ=ϵθ−ϵθ′,该差异本质上编码了 MAs 对细节恢复的贡献。将 Δϵ 以加权系数 α 注入原始模型的预测中:
ϵDG=ϵθ+α⋅Δϵ
步骤四:CFG 协同。 将 DG 增强的预测 ϵDG 替代 CFG 中的条件预测项,即可实现与 CFG 的联合使用:
ϵ^=ϵDG+w⋅(ϵDG−ϵDG,uncond)
其中 w 为 CFG 引导强度。实验表明,当 DG 与 CFG 联合使用时,细节增强效果具有累加性,且不会削弱 CFG 原本的语义控制能力。
4.4 实施细节
- MAs 破坏方式: 研究者采用了随机通道置零(random channel zeroing)与均值替换(mean replacement)两种方式,两者在细节缺失效果上表现相近。
- 引导强度 α: 经网格搜索,α∈[0.3,0.7] 为最优区间,过高会导致细节伪影,过低则增强效果不明显。
- 层选择策略: 实验发现,仅对最后 4 层实施 MAs 破坏即可获得接近全层破坏的效果,且计算开销显著降低。
实验结果分析
研究团队在 SD3、SD3.5 与 Flux 三种主流 DiT 架构上进行了全面实验,评测指标涵盖标准生成指标与细节专项指标两类。
5.1 细节质量专项评估
研究者引入了两个细节导向的评测指标:
- DINO-2 局部特征相似度: 利用 DINOv2 提取图像局部 patch 特征,计算生成图像与真实图像之间的局部特征余弦相似度。该指标对纹理与边缘变化高度敏感。
- LPIPS-Perceptual: 传统 LPIPS 的精细化版本,放大对高频区域的感知权重。
实验结果显示,DG 在所有三种模型上均实现了稳定的细节提升:
表格
| 模型 | 基准 LPIPS | DG-LPIPS | 提升幅度 |
|---|---|---|---|
| SD3 | 0.042 | 0.031 | -26.2% |
| SD3.5 | 0.038 | 0.027 | -28.9% |
| Flux-dev | 0.035 | 0.025 | -28.6% |
在 DINO-2 局部相似度指标上,DG 同样带来了 15-20% 的相对提升。
5.2 语义保真度对照
为排除细节增强以牺牲语义为代价的顾虑,研究者同时评测了 CLIP-I Score(图像-文本一致性)与 FID(全局质量)。结果一致表明,DG 的引入几乎未对语义保真度造成负面影响,CLIP-I Score 波动在 ±0.5% 以内,FID 保持稳定甚至略有改善(SD3.5 上 FID 从 18.3 降至 17.9)。这直接验证了 MAs 主要作用于细节分支而非语义分支的先前结论。
5.3 人类主观评估
研究团队进一步开展了 A/B 盲测人类评估,共邀请 120 名参与者对 200 组图像对进行偏好选择。评估维度包括“细节质量”与“整体满意度”两项。结果显示:
- 在细节质量维度,DG 生成结果获得 72.3% 的偏好率,显著高于基准。
- 在整体满意度维度,DG 生成结果获得 63.8% 的偏好率。
- 当 DG 与 CFG 联合使用时,整体满意度偏好率进一步提升至 68.1%。
5.4 计算开销评估
DG 的额外计算开销主要来源于退化模型的并行推理。经实测,在 Flux-dev 上 DG 的单张图像生成时间从基准的 2.1 秒增加至 2.9 秒(提升约 38%),属于可接受的工程代价。研究者同时提出了层选择性 DG(layer-selective DG)等轻量化变体,可将开销降低至 15% 以内。
优势与不足
6.1 核心优势
零训练成本: DG 完全无需模型微调或额外数据,仅通过激活层面的操作即可实现细节增强,具有极强的通用性与易部署性。
即插即用: DG 可无缝集成于现有 DiT 推理管线,与 CFG 等既有引导方法形成互补,无需修改底层模型架构。
理论驱动: DG 并非经验性的技巧堆叠,而是根植于对 MAs 功能角色的深入理解,具备清晰的可解释性与可扩展性。
跨模型泛化: 在 SD3、SD3.5 与 Flux 三种架构上的一致性提升,表明 DG 的作用机制具有一定的通用性,不依赖于单一模型的特定设计。
6.2 现存不足
细节增强的有界性: DG 的细节提升效果存在上限。当基准模型在特定细节维度上存在结构性缺陷时(如极端分辨率下的纹理混叠),DG 的优化空间有限。
计算开销仍有压缩空间: 虽然 38% 的额外推理时间对大多数应用场景尚可接受,但在延迟敏感的实时生成场景中仍构成一定负担。
MAs 破坏方式的经验性: 当前 MAs 破坏策略(随机通道置零、均值替换)尚缺乏理论层面的最优性证明,可能存在更高效的破坏-引导范式。
细节与语义的潜在冲突区间: 在极高引导强度下,DG 的局部增强效果可能与 CFG 的全局语义控制产生竞争,导致少数边界案例出现局部过锐或伪影问题。
未来研究方向
基于本文的研究发现与现存局限,以下几个方向值得后续探索:
方向一:MAs 的精细化建模与预测。 当前研究主要通过事后分析(post-hoc analysis)识别 MAs。未来可探索构建 MAs 的先验分布模型,从而在去噪过程中更精准地预测与调控 MAs 的时空分布,实现自适应的细节增强。
方向二:MAs 在视频扩散 Transformer 中的角色。 DiT 已广泛渗透至视频生成领域(如 Sora、Stable Video Diffusion),MAs 在时序建模中的功能角色尚不清晰。探索 MAs 对视频帧间一致性与运动细节的影响,有望为视频生成优化开辟新路径。
方向三:DG 与其他引导范式的深度融合。 除 CFG 外,区域引导(regional guidance)、语义布局引导(layout guidance)等方法也在快速发展。将 DG 的激活级差异信号与这些方法进行更深层次的融合,可能解锁多维度可控生成的新范式。
方向四:面向多模态扩散 Transformer 的 MAs 研究。 图像-文本-音频联合生成的扩散模型正在兴起,MAs 在跨模态注意力机制中的作用值得深入探究。这一方向与智能计算及多模态信号处理领域高度相关,也是当前相关 EI 会议的重要征稿方向之一,例如 CIMSP 2026(2026 年智能计算与多模态信号处理国际学术会议) 便涵盖智能计算、多模态信号处理与机器学习等交叉领域,值得关注。
方向五:MAs 的硬件感知优化。 大规模激活的稀疏分布特性为专用硬件加速提供了天然机遇。探索面向 MAs 的稀疏计算范式,有望在保持模型性能的同时显著降低推理能耗。
编辑点评
本文以一个看似微观的观察——扩散 Transformer 中的大规模激活——为切入点,通过系统性的实证研究揭示了其在视觉生成中的关键功能角色,并在此基础上提出了完全无需训练的 Detail Guidance 引导策略。这一研究路径兼具创新性与实用性:理论层面,它为理解 DiT 的内部工作机制提供了全新视角;应用层面,DG 的零训练成本与跨模型泛化能力使其具备极高的工程落地价值。
尤其值得关注的是,本文的研究范式——从模型内部激活模式的识别到功能推断,再到可控操作——为扩散模型的可解释性研究提供了可资借鉴的方法论框架。随着 DiT 架构在图像、视频乃至多模态生成中的持续主导地位,对这类内部机理的深入探索将成为下一代生成模型设计与优化的重要基石。
对于从事扩散模型研究或工程落地的从业者而言,本文不仅是技术层面的参考,更是一种研究思路的启发:有时候,答案早已蕴藏在模型的激活模式之中,关键在于是否具备提出正确问题的洞察力。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)