Blaze:用 Pandas 语法查数据库,不拖数据
Blaze:用 Pandas 语法查数据库,不拖数据
blaze 在 GitHub 上拿到了 3,192 Star。
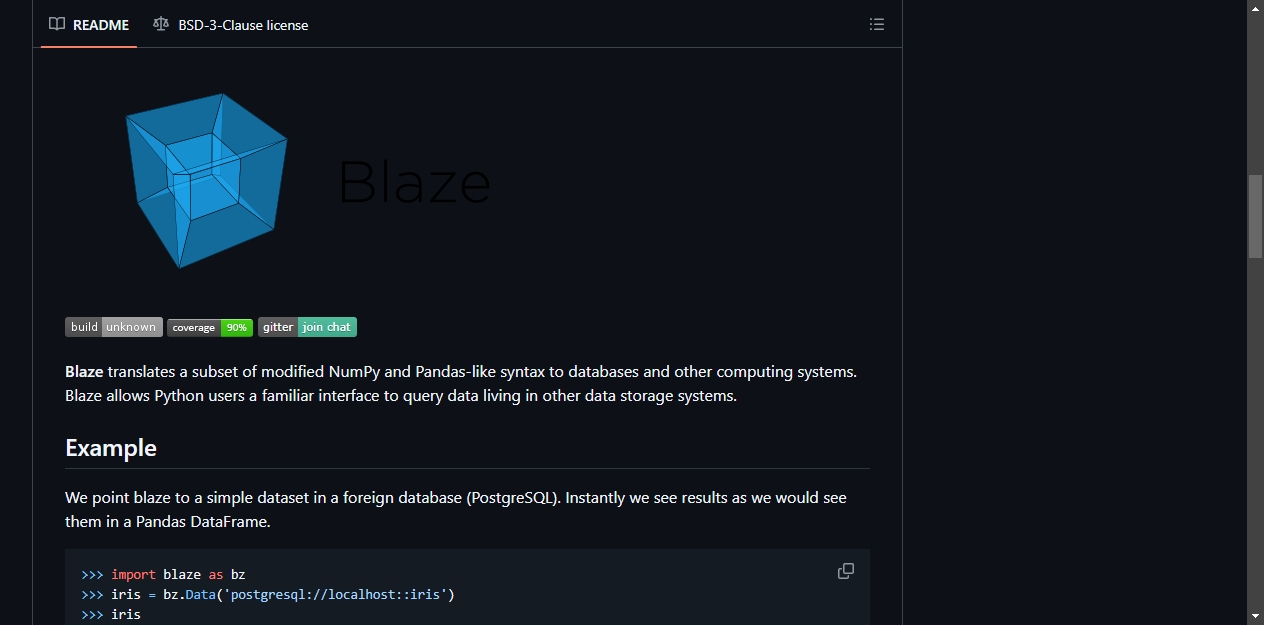
Blaze 做的事很直接:让 Python 开发者用 NumPy 和 Pandas 的写法,查询数据库和其他存储系统里的数据。
它解决了什么问题
数据分析里有个常见困境:数据在 PostgreSQL 或 Spark 里,但你最顺手的工具是 Pandas。把数据全拉到内存处理,量一大就卡死。不拉出来,就得写 SQL 或者学新接口。同一个分析需求,在数据库里写一遍 SQL,换到 CSV 文件又得重写一遍。
Blaze 把查询逻辑和底层存储分开了。你用 Pandas 语法写查询,它负责翻译成目标系统能懂的语言。数据不动,查询过去。
>>> import blaze as bz
>>> iris = bz.Data('postgresql://localhost::iris')
>>> iris.species.distinct()
species
0 Iris-setosa
1 Iris-versicolor
2 Iris-virginica
>>> bz.by(iris.species, smallest=iris.petal_length.min(),
... largest=iris.petal_length.max())
species largest smallest
0 Iris-setosa 1.9 1.0
1 Iris-versicolor 5.1 3.0
2 Iris-virginica 6.9 4.5
结果返回很快,Blaze 没有把数据从 Postgres 搬出来,只是把 Python 代码转成 SQL 发了过去。切换到 SQLite 或 CSV,同样的代码照跑。
它能接哪些后端
Blaze 支持的后端覆盖了常见的数据存储。关系型数据库有 PostgreSQL、MySQL、SQLite。大数据场景有 Spark、Impala。文档型有 MongoDB。文件格式支持 CSV、JSON、二进制文件。
同一套查询写法,切换后端不需要改代码。这对需要对接多种数据源的团队特别实用。
Blaze 的定位
需要说清楚 Blaze 不做什么。它自己不算数据,只负责把查询翻译好,交给 SQL 引擎、Spark 或 Pandas 去执行。Blaze 是一层翻译层,把查询交给后端去处理。
它也没有实现完整的 NumPy/Pandas API,只覆盖了一组常用操作。这个取舍换来的是能处理更大规模、存放在不同系统中的数据。
快速上手
安装方式和其他 Python 库一样:
conda install blaze
pip install blaze
开发版可以从 GitHub 直接安装。Blaze 同时依赖 odo 和 datashape 两个库,它们一起发布。
适合谁用
- 日常用 Pandas 但数据存在数据库里的 Python 用户
- 需要统一查询接口、减少后端切换成本的团队
- 做数据预处理,不想在多种查询语言之间反复横跳的人
Blaze 由 Continuum Analytics 赞助开发,采用 BSD 协议开源。
想在多种查询语言之间反复横跳的人
Blaze 由 Continuum Analytics 赞助开发,采用 BSD 协议开源。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)