不写一行代码,在 Linux 上微调大模型?LLaMA-Factory 真·保姆级教程
目录
前言:为什么需要 LLaMA Factory?
大语言模型(LLM)的训练和微调往往伴随着复杂的参数配置、分布式训练适配以及数据格式处理等问题。LLaMA Factory 正是为了解决这些痛点而生的框架。
简单来说,LLaMA Factory 是一个集成了多种主流高效微调技术(如 LoRA、QLoRA)的统一工具。它最大的特点就是「低门槛」与「高灵活度」。
告别代码:支持命令行(CLI)和 WebUI 两种操作方式,即使不擅长写代码,也能通过界面完成微调。
节省显存:集成了 QLoRA 等方案,让消费级显卡也能微调几十亿甚至上百亿参数的模型。
模型覆盖广:支持 LLaMA、Qwen、Baichuan 等主流开源模型。
本教程将基于 Ubuntu 22.04 系统,手把手教你安装LLaMA Factory并实现模型微调。
第一阶段:准备环境与硬件
- 安装好显卡驱动与
CUDA - 安装好
conda虚拟环境,并且python版本大于等于3.11 - 这部分内容网上参考资料颇多,就不再赘述
第二阶段:安装 LLaMA Factory
首先激活conda环境
conda activate qwenEnv
现在主流方式是从 GitHub 源码安装,这样可以保证使用的是最新版本,方便后续更新
# 克隆项目(如果网络慢,可以先去 GitHub 下载 zip 包)
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
安装依赖建议按照标准安装,这种方式不会建立源码链接,所有文件直接复制到 site-packages 目录,便于环境隔离,以及后续可能的conda环境的迁移
# 标准安装,不包含 -e 参数
pip install .[torch,metrics]
安装完成后,可通过如下命令来确认是否安装成功
# 快速验证
python -c "import torch; print(f'CUDA: {torch.cuda.is_available()}'); from llamafactory import get_version; print(f'LLaMA Factory: {get_version()}')"
第三阶段:LLaMA Factory使用
在虚拟环境中切换到cd LLaMA-Factory根目录,通过如下命令启动前端调试页面
llamafactory-cli webui
启动成功后,可通过http://服务器地址:7860/进行访问
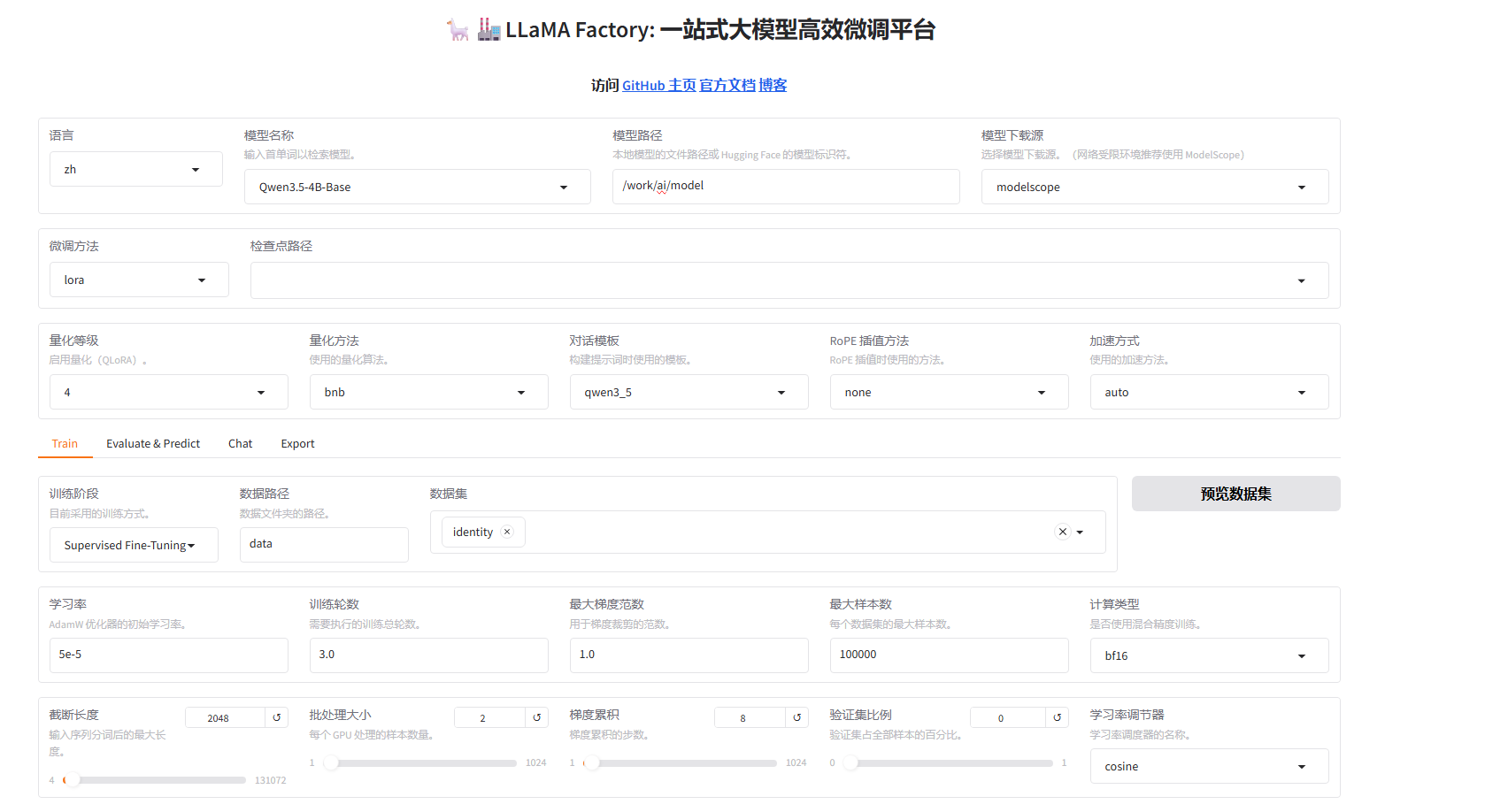
LLaMA-Factory主要分为训练模块、评估模块、对话模块以及导出模块
3.1 训练数据准备
先自定义json数据,标准格式如下。instruction有点类似于角色定位,input和output对应用户的输入和预计输出。其实在实际的训练过程中,promote=instruction+input,框架会自动将其拼接起来
[
{
"instruction": "判断以下评论的情感倾向(积极/消极/中性)",
"input": "这手机电池太垃圾了,充满电用不到半天就没电了,而且动不动就发烫,后悔死了!",
"output": "消极"
},
{
"instruction": "判断以下评论的情感倾向(积极/消极/中性)",
"input": "这个鼠标手感超棒,反应灵敏,颜值也很高,客服态度特别好,五星好评!",
"output": "积极"
}
]
当前写好的训练数据需要注册到LLaMA-Factory的数据配置文件中,只有注册了的数据集,才能被调用
编辑LLaMA-Factory/data/dataset_info.json文件,将我们的自定义数据集注册进去。名称可以自定义,file_name则填写自定义数据集的绝对路径。
3.2 train 训练模块
训练模块是LLaMA-Factory最核心的功能
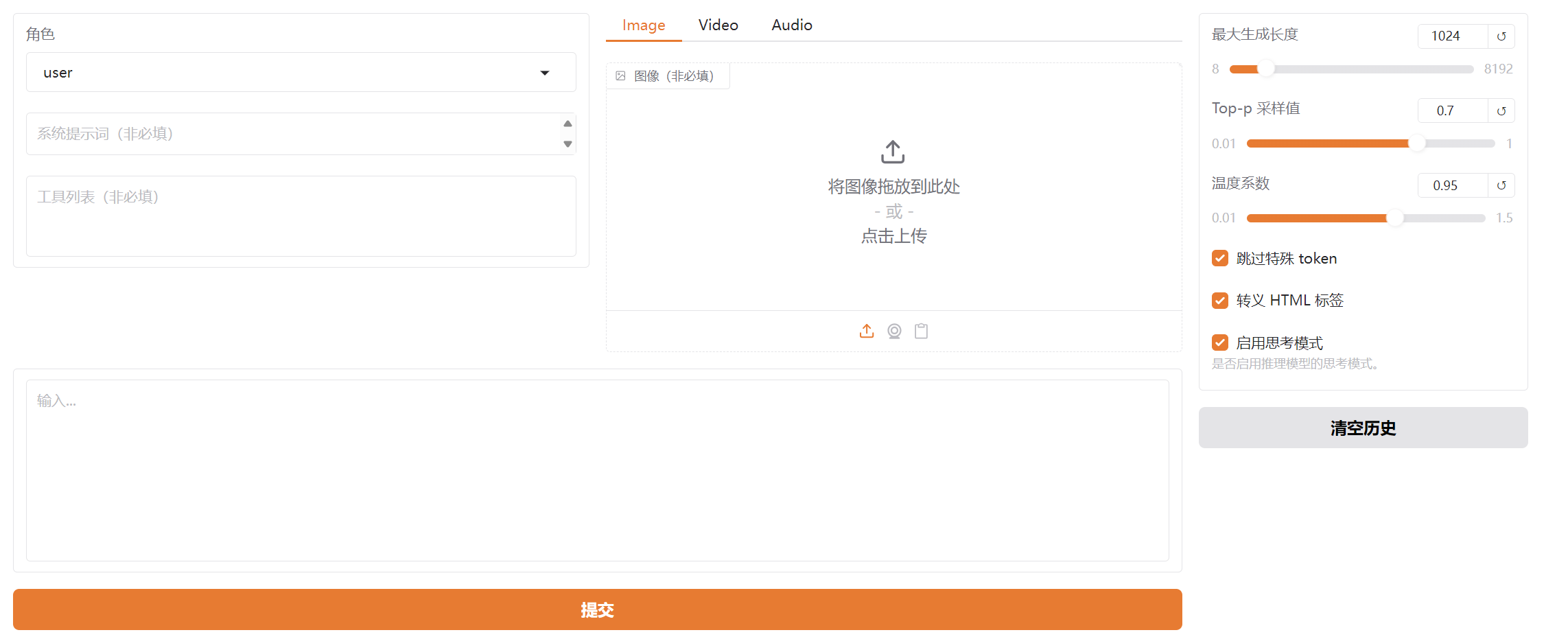
第一,搜索模型的名称,填写需要训练模型的绝对路径,以及模型的下载源

第二,微调方法一般选择lora即可,第一次训练的时候,检查点路径为空白即可

第三,选择量化等级和量化方法
量化等级:模型权重占比,位数越小,显存占用越低,精度轻微下降,根据电脑性能选择;
none表示16bit,无损耗,需要很高的显存8bit权重压缩一般,精度损耗小,性价比最高4bit权重压缩至四分之一,显存占用降低70%,精度有部分损耗,但依旧很难看出2/3bit逻辑混乱,回答错误
量化方法:在线微调适合bnb格式,速度稳定,当量化等级为none时不生效

第四,选择合适的数据集,在前端的数据集区域可通过下拉框选择对应的自定义数据(这里便是我们注册好的数据),右侧可预览数据

第五,设置微调参数,参数过多,这里不一一解释
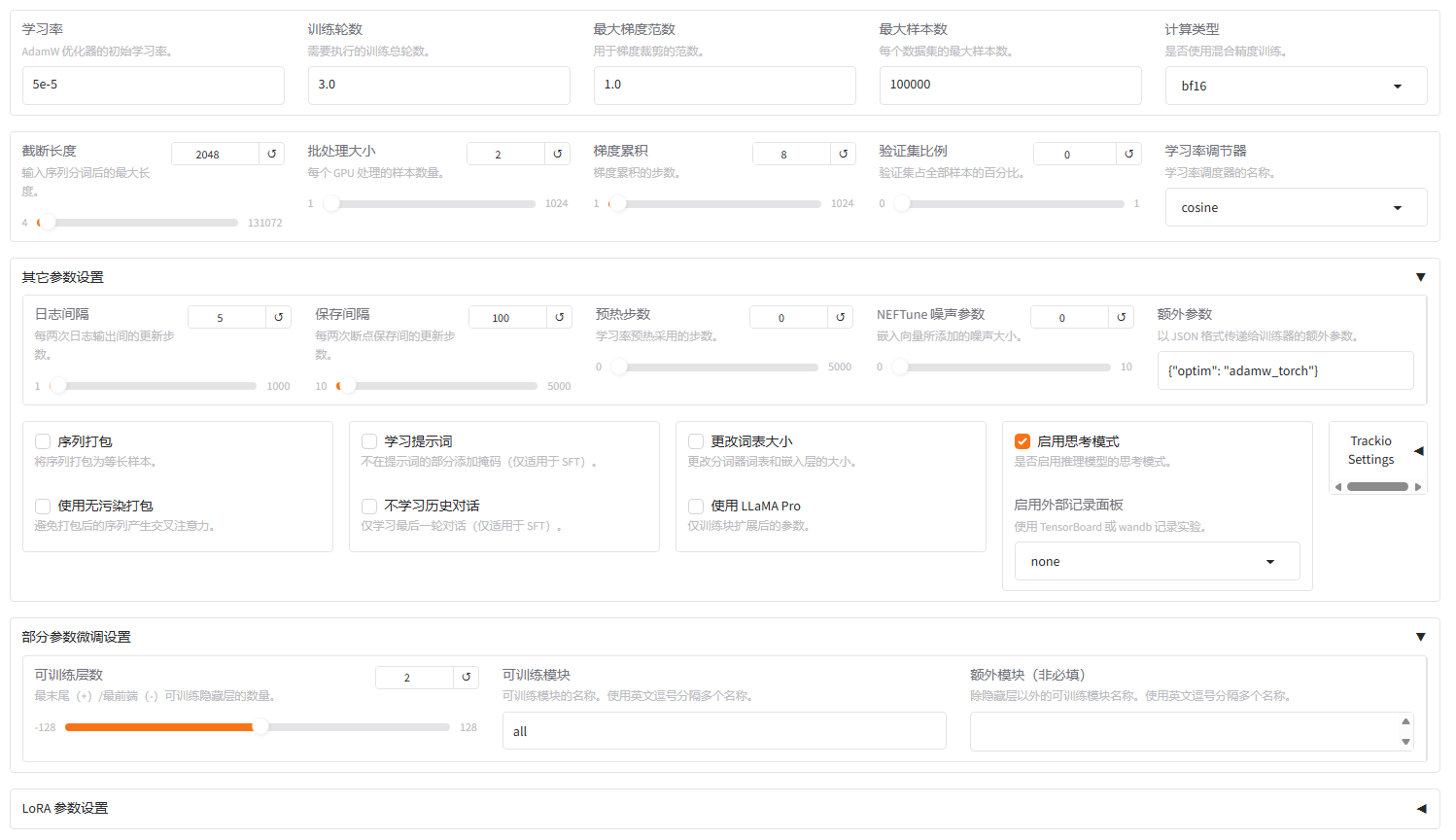
第六,设置训练输出目录名称(例如图中是intelligentLoraRound4),点击开始训练即可,训练时间和电脑性能相关
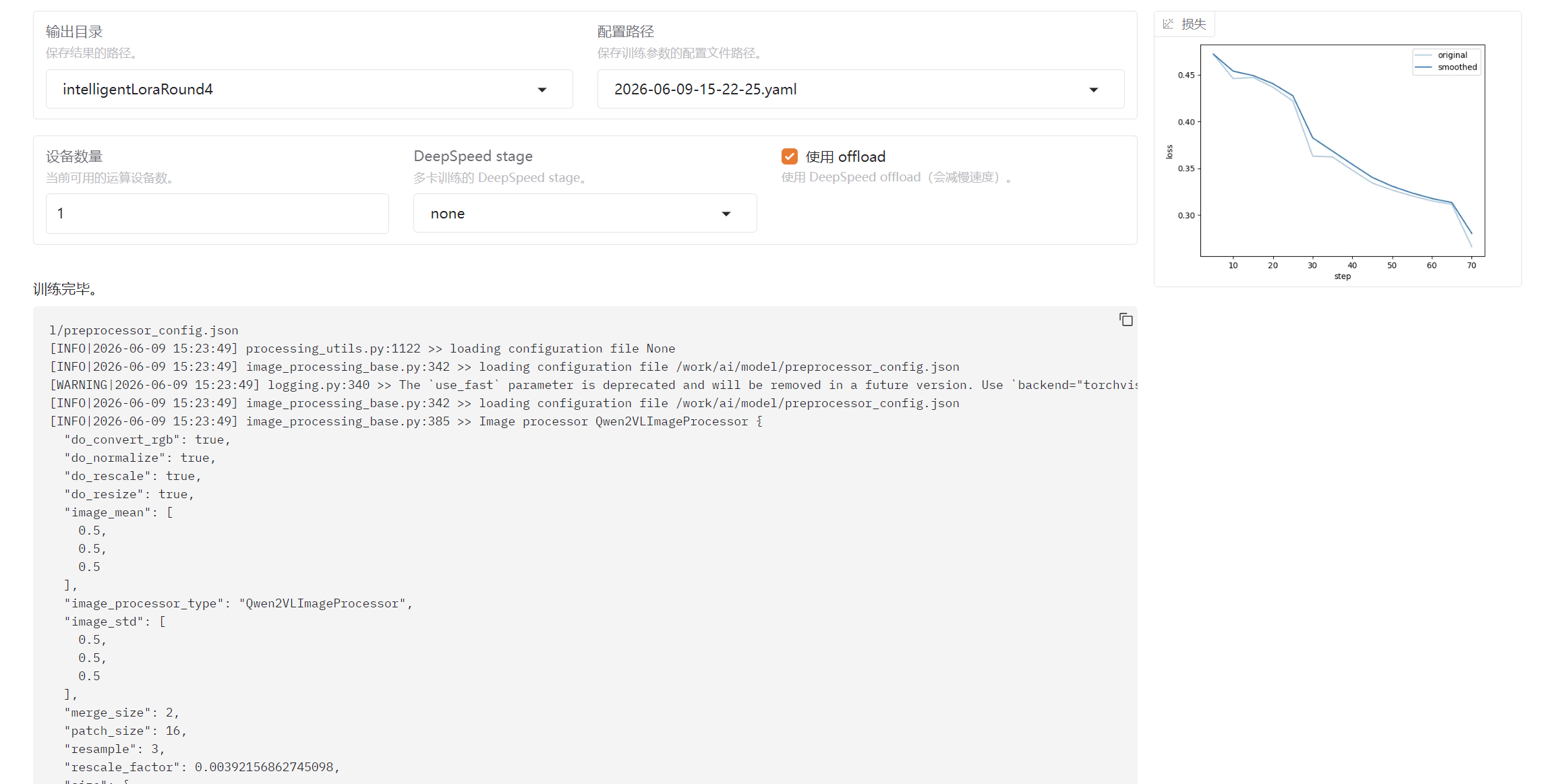
训练出来的模型参数被放置在如下位置 LLaMA-Factory/saves/模型名称/lora/输出目录名称,例如LLaMA-Factory/saves/Qwen3.5-4B-Base/lora/intelligentLoraRound4。训练好的lora文件夹可以被vLLM直接加载,实现不同的功能。
需要注意的是,如果数据量过大,显卡支撑不住,可以拆分数据集训练
对于第一次训练好的lora参数,可以在第二次训练的时候加载(即检查点路径),但是输出目录建议使用一个新的目录,不要和旧目录一致
例如我在第三次训练的时候,选择dataRound3数据集,输出目录为dataLoraRound3。第四次训练的时候,选择dataRound4数据集,选择检查点路径为dataLoraRound3,输出目录为dataLoraRound4即可,能明显的看到loss会在上一次终止左右地方开始下降
3.3 chat 对话模块
对话模块就是单纯加载基底模型 或 将 lora参数加载到基底模型中,进行对话
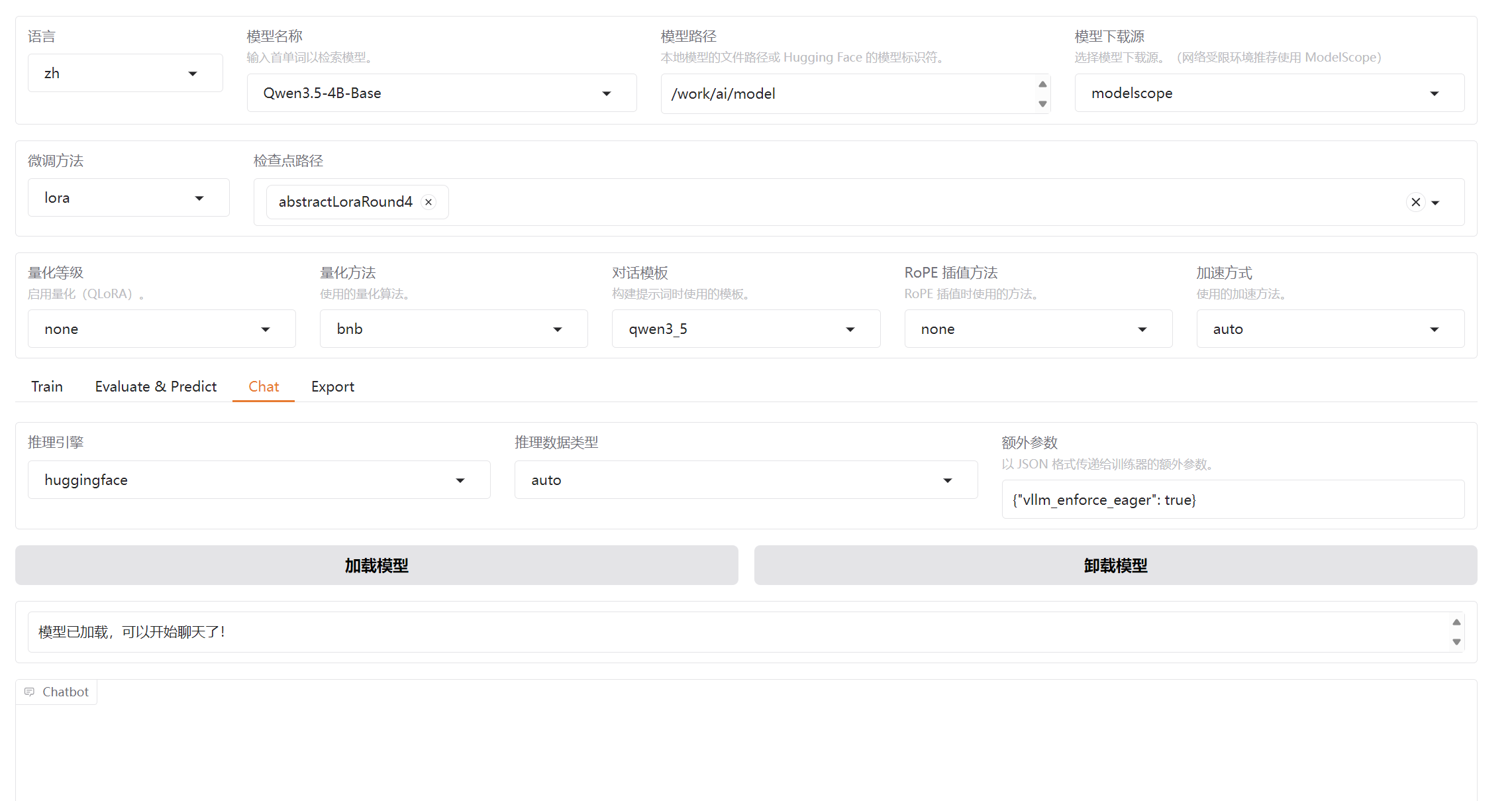
选择是否填入系统提示词,或者开启思考、设置最大生成长度等,即可开始对话
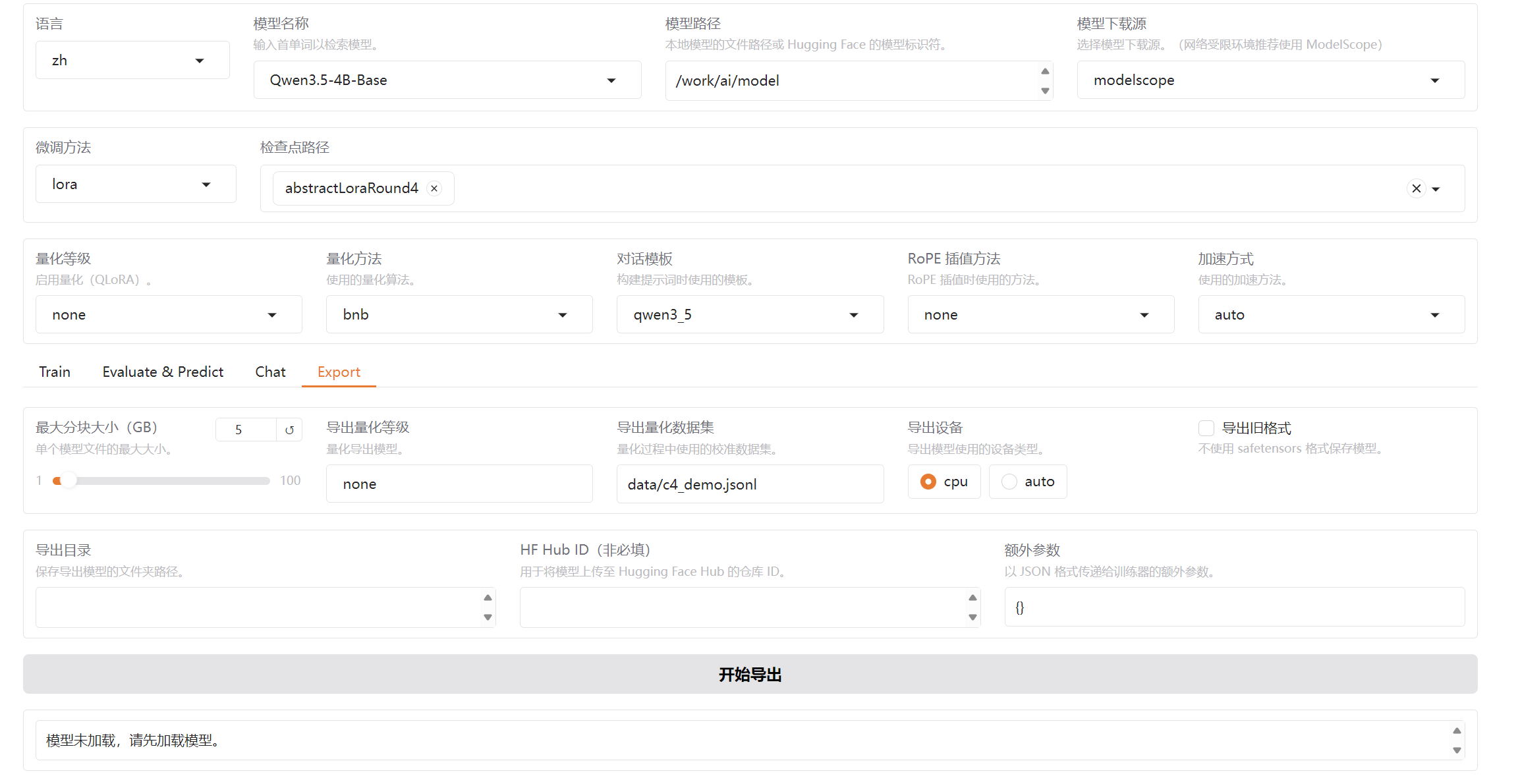
3.4 export 导出模块
导出模块就是将训练好的lora参数合并到基底模型中,形成一个新的模型
可以选择量化等级,自定义导出的目录

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)