从猫狗分类到医学影像分割:基于 2D U-Net 的脾脏 CT 分割项目复盘
项目任务:MSD Task09 Spleen 脾脏 CT 单器官分割
项目地址:GitHub-SpleenSeg_UNet
方法:2D U-Net / MONAI UNet
输入:腹部 CT slice
输出:脾脏二值 mask
结果:Dice 约 94%–95%
项目定位:从图像分类过渡到医学影像分割的学习项目
一、项目背景:为什么在猫狗分类之后做脾脏分割
在完成猫狗大战分类项目之后,我开始进入医学影像分割方向的学习。猫狗大战解决的是普通图像分类问题:模型输入一张图片,输出一个类别,比如猫或狗。这个项目则进入了医学影像分割任务:模型输入腹部 CT 图像,输出脾脏所在区域的 mask。
这两类任务的本质区别在于,分类只需要判断整张图“是什么”,而分割需要判断图像中每个像素“属于哪里”。对于医学影像来说,这个变化非常重要。医生或算法系统往往不只是想知道图像中有没有某个器官或病灶,还需要知道它的位置、边界和形状。
这个项目做的是 MSD Task09_Spleen 数据集上的脾脏单器官分割。它在我的学习路线里处于猫狗分类之后、3D U-Net 和 nnU-Net 之前。选择 2D U-Net 并不是因为它是最强的医学分割方法,而是因为它适合作为一个过渡项目:先从普通 2D 图像分类过渡到 2D 医学图像分割,再进一步进入 3D CT 分割和更成熟的医学分割框架。
从学习角度看,这个项目的目标不是单纯刷 Dice,而是把医学影像分割的完整流程跑通:原始 NIfTI 数据怎么处理,CT 图像怎么归一化,3D volume 怎么切成 2D slice,U-Net 怎么输出 mask,DiceLoss 怎么优化,推理阶段怎么重新组成 3D mask,以及后续如何用 MONAI 重构整个流程。
二、项目整体流程
这个项目可以理解为一条从 3D CT 到 3D 分割结果的完整链路:
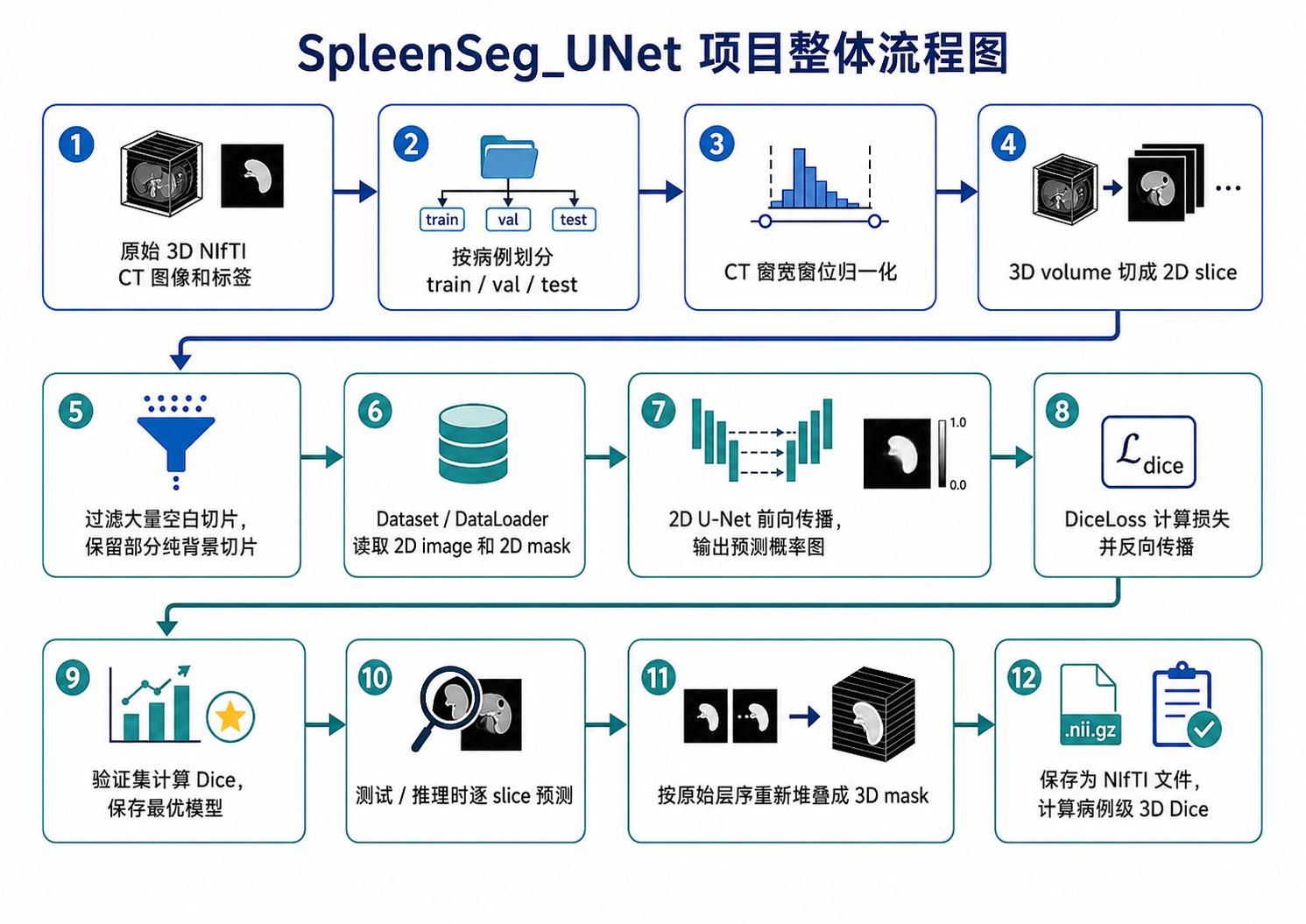
图 1:项目整体流程图
这条流程里有一个很重要的特点:训练时模型看到的是 2D slice,但医学影像任务的原始单位和最终结果单位仍然是 3D 病例。也就是说,2D U-Net 只是降低训练难度的一种实现方式,并不代表这个任务真正变成了普通 2D 图片任务。
三、数据准备与预处理
1. 病例级划分,避免 slice 级数据泄漏
这个项目的原始数据是 3D CT volume 和对应的 3D mask。虽然训练时会把 volume 切成 2D slice,但 train / val / test 的划分必须先按病例进行,而不能把所有 slice 打乱后随机划分。
这是医学影像项目里非常容易踩的坑。如果按 slice 随机划分,同一个病人的不同切片可能同时出现在训练集和测试集中。由于同一个 CT volume 内部的相邻切片在灰度分布、器官形态和空间结构上高度相似,模型在测试阶段可能并不是面对真正独立的新病例,而是在预测训练时已经“见过”的同一病例的相邻切片。这样得到的 Dice 会偏乐观,不能真实反映模型的泛化能力。
所以这个项目的正确流程是:先把完整病例划分到 train、val、test,再在各自集合内部切成 2D slice。这里我真正理解到的一点是:2D 训练不等于 slice 级随机划分。只要原始数据来自 3D 病例,数据划分就应该保持病例级独立。
2. CT 窗宽窗位归一化
在猫狗分类项目中,图像归一化主要是为了适配自然图像模型,尤其是使用 ImageNet 预训练模型时,需要让输入图像分布接近模型预训练时看到的数据分布。
但 CT 图像不是普通 RGB 图像。CT 的像素值通常表示不同组织对 X 射线的衰减程度,也就是 HU 值。空气、脂肪、软组织、骨骼等结构分布在不同的 HU 区间。原始 CT 的数值范围远大于普通 0–255 图像,如果直接输入网络,很多与脾脏分割无关的极端值会占据动态范围,反而削弱腹部软组织之间的对比。
所以这个项目对 CT 做了窗宽窗位归一化。它不是简单把数值缩放到某个范围,而是根据腹部软组织的显示需要,截取一个更适合观察脾脏及周围组织的 HU 区间,再归一化到网络容易处理的范围。
这个过程让我意识到,医学影像预处理不能完全照搬自然图像经验。自然图像归一化更多是为了统一输入分布,而 CT 的窗宽窗位归一化本身带有医学影像先验:先把对当前器官分割有用的灰度范围突出出来,再交给模型学习。
3. 从 3D volume 切成 2D slice
完成病例划分和 CT 归一化后,手写版项目会把 3D volume 沿轴向切成一张张 2D slice,并保存为 .npy 文件。训练时,Dataset 直接读取这些已经处理好的 2D 图像和对应的 2D mask。
这样做的好处是简单、直观,也比较适合从猫狗分类项目过渡过来。之前做分类时,DataLoader 读取的是一张张图片;现在虽然原始数据是 3D CT,但经过切片后,训练流程仍然可以理解成读取一批 2D 图像,只是标签从类别变成了 mask。
当然,它的代价也很明显。2D slice 训练无法直接利用上下层切片之间的 3D 空间信息。对于脾脏这类三维连续器官来说,相邻层面的形态变化其实是有价值的,这也是后续需要进入 3D U-Net 的原因。
4. 过滤空白切片,但保留部分纯背景切片
把 3D CT 切成 2D slice 后,会产生大量不包含脾脏的空白切片。如果这些切片全部保留,训练集会被背景样本占据,模型容易学成一种保守策略:大部分区域都预测为背景。这样训练效率低,也不利于模型重点学习真正包含脾脏的切片。
但空白切片也不能全部删除。因为真实推理时,一个完整 CT volume 中本来就有很多没有脾脏的层面。如果训练阶段模型从没见过纯背景切片,它可能会误以为每张图都应该分割出目标,导致在空白层面上也预测出假阳性区域。
所以项目中保留了一部分空白切片。可以把它理解为告诉模型:题目里是有“空白题”的,遇到没有脾脏的切片时应该输出空 mask。这个比例不是绝对标准,而是一种工程上的平衡:既让模型学会抑制误检,又不让大量背景样本淹没有效训练数据。
5. 数据对齐是医学分割里的地雷
在医学影像分割项目中,很多问题表面上像模型问题,实际上可能是数据对齐错了。
这个项目里,image 和 mask 必须始终一一对应。CT 图像的第几层,就应该对应 mask 的第几层。病例编号不能错,切片顺序不能乱。推理阶段重新堆叠 3D mask 时,也必须保持原始层序,否则预测结果就会发生空间错位。
此外,image 和 mask 的预处理方式也不能混淆。image 可以做窗宽窗位和归一化,但 mask 不能当普通图像一样归一化。如果后续涉及 resize,image 可以使用线性插值,但 mask 应该使用最近邻插值,否则标签值可能被插出小数,破坏原本的类别标注。
保存预测结果时,还要尽量保留原始图像的 spacing、origin、direction 等空间信息。否则数组本身看起来对了,但放回医学图像软件中可能位置不对。
这部分对我来说是一个很重要的提醒:医学分割不是网络能跑就行,image、mask、slice 顺序和空间信息都必须对齐。
四、模型结构:2D U-Net
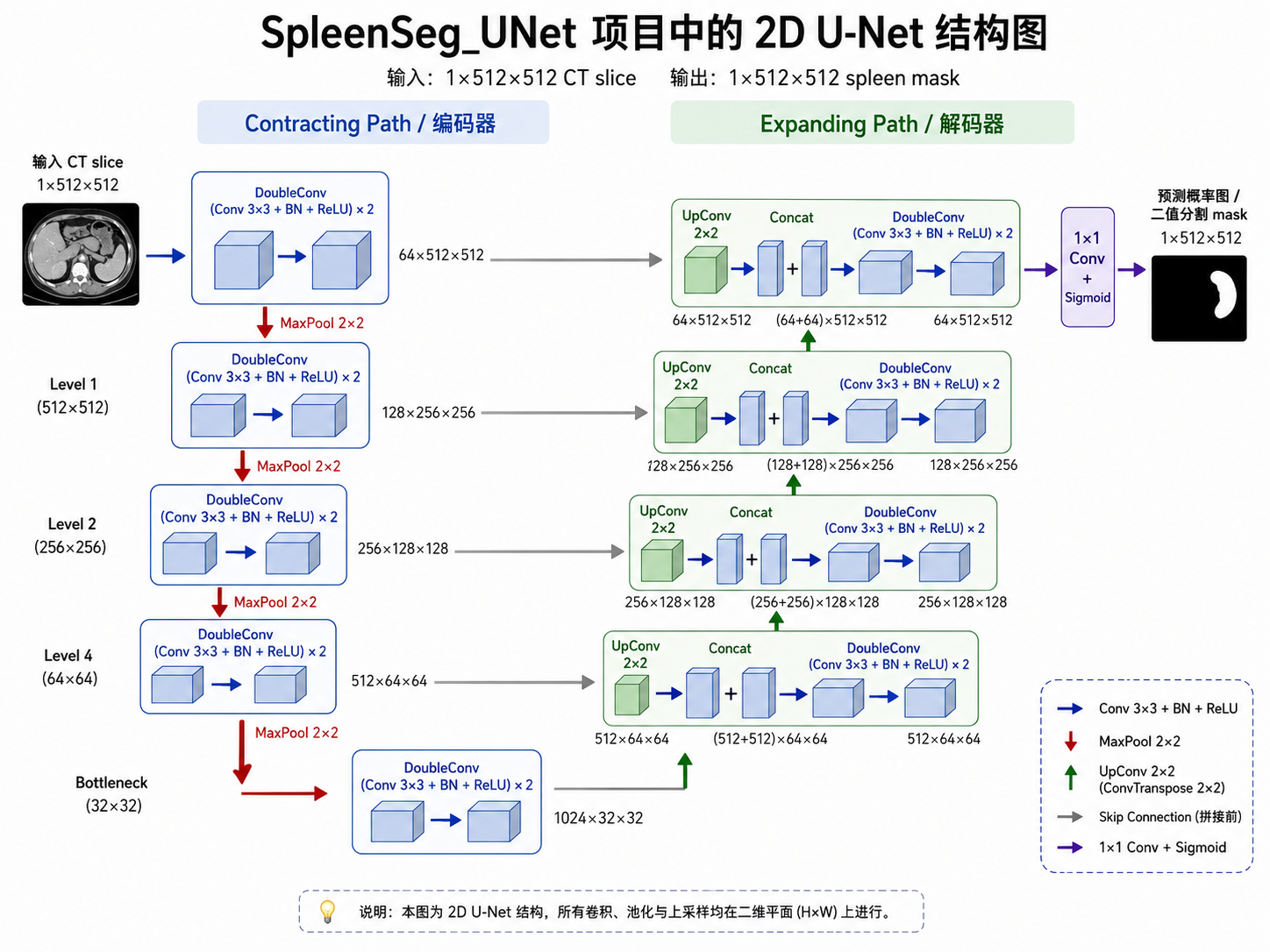
图2:项目中的 2D U-Net 结构图
这个项目的主分支使用的是手写 2D U-Net。U-Net 的整体结构可以分成 encoder、decoder 和 skip connection 三部分。
encoder 通过卷积和下采样逐层提取特征。这里处理的不是原始 CT 图本身,而是网络中间的特征图。随着网络加深,特征会从低级纹理、边缘逐渐变成更高级的语义信息,同时特征图尺寸变小,感受野变大。
感受野变大不是指特征图变大,而是指特征图上的一个点能够对应原始图像中更大的区域。也就是说,虽然下采样后特征图看起来更小了,但每个特征点包含的上下文信息更多了。
decoder 的作用是通过上采样逐步恢复特征图尺寸。因为分割任务最终要输出一张和输入图像空间尺寸对应的 mask,所以模型不能只停留在低分辨率的高级语义特征上,还需要恢复到像素级预测。
skip connection 是 U-Net 中非常关键的结构。下采样过程中,深层特征虽然语义更强,但会丢失一部分空间细节。skip connection 会把 encoder 对应层的高分辨率特征图拼接到 decoder 中,帮助模型在恢复 mask 时补回边界、纹理和空间位置信息。
简单说,encoder 负责理解“是什么”,decoder 负责恢复“到哪里”,skip connection 负责让边界画得更准。这也是 U-Net 特别适合医学图像分割的原因之一:医学分割既需要识别器官,也需要尽量准确地描绘器官边界。
五、训练流程
手写版训练流程基本延续了 PyTorch 项目的常规结构,但任务从分类变成了分割。
首先,Dataset 读取预处理好的 2D image 和 2D mask。image 是模型输入,mask 是监督标签。DataLoader 按 batch 提供数据。和猫狗分类项目不同的是,这里的标签不再是一个类别编号,而是一张和输入图像对应的二值 mask。
模型前向传播后,U-Net 输出的是一张单通道预测图。经过 sigmoid 后,可以理解为每个像素属于脾脏的概率。训练阶段使用 DiceLoss 来优化模型。
Dice 衡量的是预测 mask 和真实 mask 的重叠程度,可以理解为:
Dice = 2 × 重合区域 /(预测区域 + 真实区域)
在医学图像分割中,前景和背景通常极不平衡。对于脾脏分割来说,背景像素远多于脾脏像素。如果只看 pixel accuracy,模型即使大部分区域都预测成背景,也可能得到一个看起来不错的准确率,但这对分割器官没有意义。
DiceLoss 的意义就是让模型直接围绕“脾脏区域有没有和真实 mask 重合”来优化,而不是被大量背景像素带偏。
训练过程中,验证集 Dice 用来观察模型在未参与训练的数据上的表现。如果验证 Dice 提升,就保存当前最优模型。这样最终测试和推理时使用的是验证表现最好的权重,而不是随便使用最后一个 epoch 的模型。
这部分流程虽然和普通分类项目一样也包括 forward、loss、backward、optimizer step、validation、checkpoint,但它的核心变化在于:输入输出和评价指标都已经变成了分割任务的形式。
六、测试与推理:从 2D 预测回到 3D 病例
推理阶段是这个项目里很能体现医学影像特点的一步。
训练时,模型输入的是单张 2D slice;但测试时,一个病例仍然是完整的 3D CT volume。所以推理时需要逐 slice 进行预测:把一个 3D CT 按层取出,每一层经过同样的预处理后送入 2D U-Net,得到这一层的预测 mask。
当所有 slice 都预测完成后,再按照原始层序把这些 2D mask 重新堆叠起来,组成完整的 3D mask。最后把这个 3D mask 保存成 NIfTI 文件,并尽量继承原图的空间信息,方便后续在医学图像软件中查看。
这里我理解到一个重要区别:训练单位可以是 2D slice,但评估和保存结果的单位仍然应该是 3D 病例。不能因为用了 2D 模型,就把医学影像任务完全当成普通 2D 图片任务。
Dice 的计算也最好回到 3D 病例级别,而不是简单对每张 2D slice 的 Dice 求平均。因为很多空白层和边缘层的单张 Dice 波动很大,简单平均不一定能真实反映整个器官的分割效果。病例级 3D Dice 更符合医学分割最终要评价“这个病例的脾脏整体有没有分好”的目标。
七、MONAI 重构版:从手写流程到框架化流程
这个项目除了手写版,还做了 MONAI 重构版。这个分支的意义不是简单“又用一个库写了一遍 U-Net”,而是把手写流程逐步迁移到医学影像框架化管线中。
手写版是“先切好,再训练”。它提前把 3D NIfTI 图像离线切成 2D .npy,训练时 Dataset 直接读取这些已经处理好的切片。U-Net 结构、DiceLoss、训练逻辑、推理重建和后处理也大多是自己写的。
MONAI 版则更接近“直接读取 3D 原图,用 transform 在线处理”。它不再提前把所有切片保存成 .npy,而是直接读取原始 NIfTI 文件,通过 MONAI transforms 完成读取、加 channel、窗宽窗位归一化、正负样本采样、2D slice 抽取、维度处理和 tensor 转换。
模型方面,MONAI 版使用 MONAI 提供的 UNet;loss 使用 MONAI 的 DiceLoss;评估中使用 MONAI 的 DiceMetric、后处理和 sliding window 推理流程。这样做的好处是代码更规范,也更接近真实医学影像项目中常见的工程写法。
但这里需要特别注意:这个 MONAI 版本仍然是 2D U-Net,不是真正的 3D U-Net。它的 sliding window 推理更像是在 3D volume 上用 MONAI 管理推理流程,但每次实际送入模型的仍然是 2D slice 或 depth=1 的小块。它没有真正让模型学习 3D patch 中的上下文信息。
所以 MONAI 版的主要价值不是模型突然变强,而是让我从手写 PyTorch 脚本过渡到更规范的医学影像分割框架。手写版帮助我理解底层逻辑,MONAI 版帮助我理解这些逻辑在成熟工具链中是怎么组织起来的。
八、实验结果与理解
| 版本 | 验证集 Dice | 测试集 Dice |
|---|---|---|
| 手写版 main 分支 | 94.44% | 94.74% |
| MONAI 重构版 | 95.59% | 94.89% |
可以看到手写版和 MONAI 版的 Dice 都在 94%–95% 左右。对于一个学习型项目来说,这个结果可以说明模型已经基本学会了脾脏分割的主要模式,也说明数据预处理、mask 对齐、U-Net 训练、DiceLoss、推理重建和后处理这些关键环节是有效的。
但这个结果不能过度解读。它不能直接说明模型已经达到工业级或临床级,因为真实应用还要考虑外部数据泛化、不同医院扫描协议、异常病例、边界误差、推理速度和部署稳定性等问题。脾脏本身也是相对明确的单器官分割任务,比小病灶、多器官复杂边界要简单一些。
MONAI 版分数略高,也不能简单说“MONAI 一定比手写版强”。因为两个版本在网络实现、数据采样方式、loss 实现、评估流程和后处理上都有差异,并不是严格控制变量的对比实验。更合理的理解是:两个版本都证明了 U-Net 路线在这个任务上有效,而 MONAI 版的主要意义在于流程工程化,而不是单纯追求 Dice 提升。
对我来说,这个结果最重要的意义是:它证明我已经能用 U-Net 完整跑通一个医学影像单器官分割任务,并且理解了从数据、模型、loss、指标到推理评估的基本闭环。
九、项目局限与后续方向
从学习项目的角度看,这个项目已经完成了它应有的作用。它让我从普通图像分类过渡到医学影像分割,理解了 CT 数据、mask、窗宽窗位、U-Net、DiceLoss、Dice 指标、推理重建和 MONAI 流程。
但从项目本身看,它仍然有两个主要局限。
第一,它是单器官分割任务,只需要区分背景和脾脏。后续多器官分割会面对更多类别、更复杂的器官边界、更明显的器官尺度差异和类别不平衡问题。
第二,它仍然是 2D U-Net。它每次只能看单张 CT slice,不能直接利用上下层切片之间的三维空间连续性。而 CT 本质上是 3D 体数据,器官形态和空间位置都具有体素级连续性,所以后续过渡到 3D U-Net 是很自然的升级。
再往后进入 nnU-Net,则不是简单换一个网络,而是学习成熟医学分割框架如何系统化地处理任务,包括自动配置预处理方式、patch size、网络结构、训练策略和推理流程。这个项目可以看作从手写基础流程走向 3D 和框架化方法的中间台阶。
十、总结
这个项目对我最大的价值,不是单纯得到一个 94%–95% 的 Dice,也不是证明 2D U-Net 有多强,而是让我第一次完整走完了医学影像分割项目的基本流程。
从猫狗大战到脾脏分割,任务从分类变成了像素级预测;数据从普通图片变成了 CT volume;输出从类别标签变成了 mask;评价指标从 accuracy 变成了 Dice;模型也从分类网络变成了 encoder-decoder 结构的 U-Net。
手写版让我理解了医学影像分割的底层逻辑,MONAI 版让我开始接触更规范的医学影像框架化流程。这个项目不是终点,而是一个过渡台阶。它为后续学习 3D U-Net、nnU-Net、多器官分割,以及更复杂的医学影像算法项目打下了基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)