Slurm 工作负载管理器:从入门到实践
·
1. 什么是 Slurm?
Slurm(Simple Linux Utility for Resource Management,资源管理简易 Linux 工具)是一个开源、高度可扩展、容错性强的集群管理和作业调度系统。它被广泛应用于高性能计算(HPC)、人工智能(AI)训练、大数据处理等需要大规模并行计算资源的场景。
简单来说,Slurm 就像是一个超级计算机集群的“操作系统”,负责将用户提交的计算任务(作业)合理地分配到集群中的各个计算节点上,并高效地管理这些节点上的 CPU、内存、GPU 等硬件资源。
2. Slurm 的核心组件与架构
一个典型的 Slurm 集群由以下核心组件构成:
- 控制守护进程(slurmctld):运行在管理节点上,是整个集群的“大脑”。它负责监控所有节点和分区的状态,接收并调度用户提交的作业,管理作业队列。如同:控制大脑
- 计算节点守护进程(slurmd):运行在每个计算节点上,是节点的“执行器”。它接收来自
slurmctld的指令,负责在本节点上启动、监控和终止作业任务。如同:工蜂 - 数据库守护进程(slurmdbd):可选组件,用于将作业记账、资源使用等数据持久化到数据库中,便于进行资源使用统计、计费和审计。如同:记账管理员,负责记账
- 用户命令行工具:用户与 Slurm 交互的主要接口,例如:
sbatch:提交批处理作业脚本。srun:交互式地运行并行作业。scancel:取消已提交的作业。squeue:查看作业队列状态。sinfo:查看集群节点和分区状态。sacct:查看已完成的作业记账信息。
架构示意图: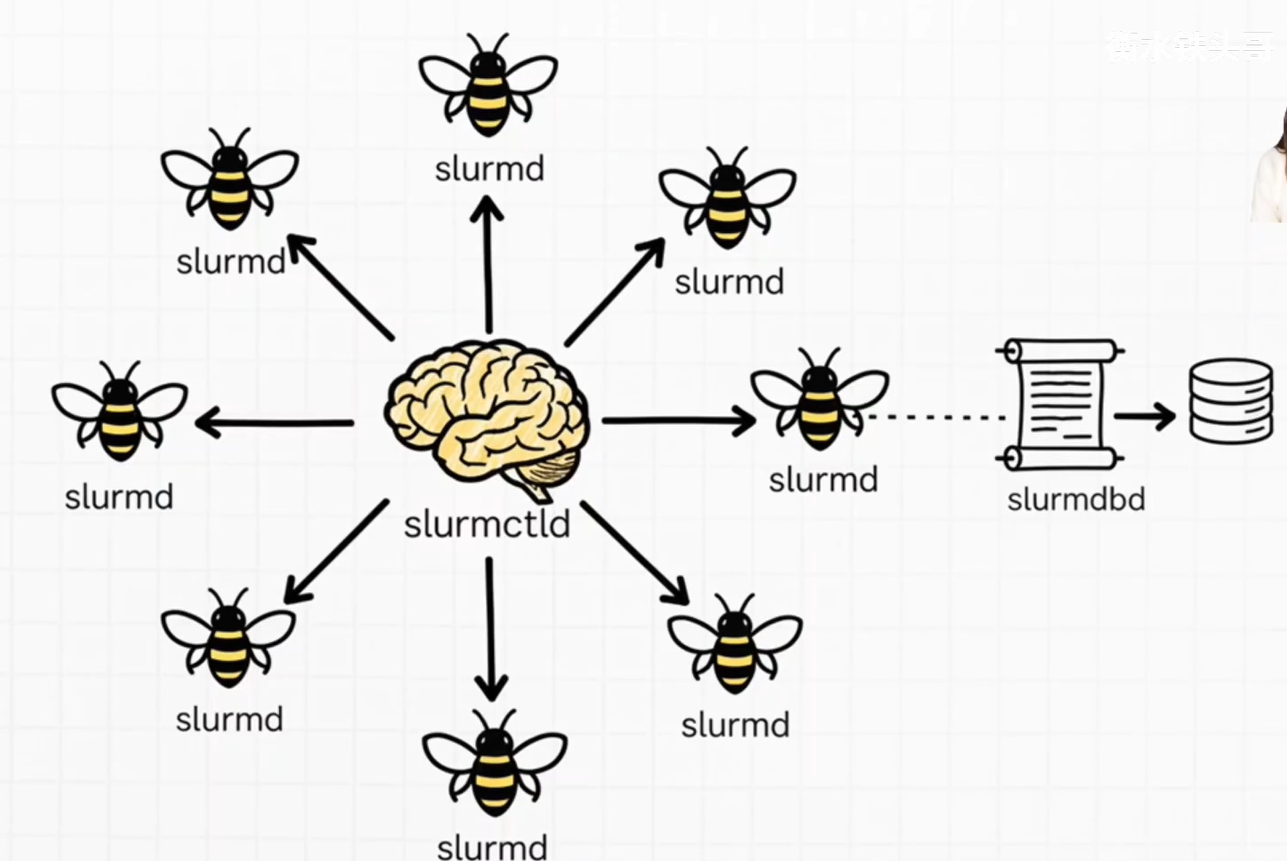
3. Slurm 的核心概念
理解以下几个关键概念是使用 Slurm 的基础:
- 作业(Job):用户提交的一个计算任务单元。一个作业可以包含一个或多个任务(Steps)。
- 任务(Task/Step):作业内的一个具体执行单元,通常对应一个并行进程。一个作业可以启动多个任务在多核或多节点上并行运行。
- 节点(Node):集群中的一台物理或虚拟服务器,包含 CPU、内存、GPU 等资源。
- 分区(Partition):节点的逻辑分组,类似于队列。不同分区可以配置不同的资源限制、访问权限和调度策略(例如,
debug分区用于短时间测试,compute分区用于长时间生产任务)。 - 作业数组(Job Array):一种高效提交大量相似作业的方式,只需一个脚本即可提交成百上千个参数化或数据并行的作业。
4. 基本使用命令
4.1 查看集群状态
# 查看所有分区和节点的状态
sinfo
# 以更详细的格式查看节点信息
sinfo -N -l
# 查看特定分区的信息
sinfo -p compute
4.2 提交批处理作业
创建一个名为 myjob.slurm 的脚本:
#!/bin/bash
#SBATCH --job-name=test-job # 作业名称
#SBATCH --output=job-%j.out # 标准输出文件
#SBATCH --error=job-%j.err # 标准错误文件
#SBATCH --partition=compute # 指定分区
#SBATCH --nodes=2 # 请求节点数
#SBATCH --ntasks-per-node=4 # 每个节点的任务数(总任务数 = nodes * ntasks-per-node)
#SBATCH --time=01:00:00 # 最大运行时间 (时:分:秒)
#SBATCH --mem=4G # 每个节点内存
echo “开始运行作业...”
srun hostname # 使用 srun 在分配的资源上运行命令
echo “作业完成。”
使用 sbatch 提交:
sbatch myjob.slurm
4.3 管理作业
# 查看作业队列(所有用户)
squeue
# 查看自己的作业
squeue -u $USER
# 取消一个作业(JOBID 通过 squeue 查看)
scancel <JOBID>
# 查看已完成作业的详细信息
sacct -j <JOBID> --format=JobID,JobName,Partition,Elapsed,State,ExitCode
4.4 交互式运行作业
适用于调试或需要即时交互的场景:
# 申请一个节点的一个核心,交互运行 1 小时
srun --pty -p debug -N 1 -n 1 -t 1:00:00 /bin/bash
# 申请一个节点,一个 GPU,交互运行
srun --pty -p gpu --gres=gpu:1 -t 0:30:00 /bin/bash
5. Slurm 的优势与适用场景
优势:
- 开源免费:无商业许可费用。
- 高可扩展性:支持从几个节点到数万个节点的超大规模集群。
- 高容错性:节点故障时能自动恢复或重新调度作业。
- 策略灵活:支持复杂的调度策略(公平共享、优先级、回填等)和资源管理(CPU、内存、GPU、许可证等)。
- 生态丰富:与众多 HPC 软件、监控工具、计费系统集成良好。
典型适用场景:
- 高校与科研机构:为多个课题组提供共享计算资源。
- 企业研发:运行大规模仿真、AI 模型训练、基因测序分析。
- 云计算:作为云上 HPC 服务的底层调度器。
6. 总结
Slurm 是现代高性能计算领域事实上的标准作业调度系统。它通过高效的资源管理和作业调度,使得昂贵的计算集群资源得以被多用户公平、高效地共享利用。掌握 Slurm 的基本概念和命令,是进入 HPC 和 AI 大规模计算世界的必备技能。
对于初学者,建议从在本地或小型测试集群上练习 sinfo、squeue、sbatch 等基本命令开始,逐步理解作业脚本的编写和资源参数的配置。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)