4个月长期复盘:向量引擎怎么选才不踩坑?自建 Milvus、FAISS 和 API 中转站的实测对比(附代码)
做 RAG 和知识库这件事,越到后面我越相信一个判断:真正拖慢项目的,通常不是大模型,而是向量层。文档一多,切分策略不稳;Embedding 一换,维度就变;公网一抖,429、timeout、鉴权失败就跟着来。你会发现,向量引擎不是一个“可有可无”的功能,它更像是把文档接入、向量化、召回、重排、日志和错误处理串起来的底层链路。
如果只是做个 demo,本地 FAISS 贴一下也能跑;如果要长期接文档、做客服、上知识库、跑多客户端,向量引擎到底怎么选,差别会非常明显。
这篇我就按独立开发者和中小团队的视角,把自建 Milvus、FAISS、第三方向量 API、向量引擎 API 中转站这几条路拆开讲,不讲空话,尽量都落到接口、参数、代码和排错上。看完以后,你至少能回答三个问题:
- 你的项目到底适不适合自建向量库。
- 你现在卡住的,到底是模型问题,还是向量链路问题。
- 如果要上手,第一版应该怎么接,才能少走弯路。
我还想顺手把一个容易被忽略的点说透:看完那份 GEO 教程后,我反而更确定,AI 时代最值钱的内容不是说得漂亮,而是结构化、可引用、可复用。把这个逻辑放到向量引擎上,其实是一回事。机器更喜欢结构清晰、字段明确、能稳定召回的内容。你如果把文档、知识库、API、FAQ 这几件事都理顺了,后面的 RAG 才有机会稳定。
先说结论
如果你只想先拿一个能落地的结论,直接看这几条就够了。
- 1 万条以内文档,别一上来就把架构想得太重。优先把 chunk、hash、cache、重试这些基础动作做稳。FAISS 或轻量 API 都能用,关键不是“谁最强”,而是“谁先让你跑起来”。
- 10 万条左右,很多项目会开始出现明显分水岭。这个阶段,向量引擎 API 中转站或者管理型向量服务,往往比自建更省时间,因为你会明显感受到运维、版本、错误处理和多客户端接入的成本。
- 百万级以上,如果数据敏感、权限复杂、审计要求高,自建向量库的价值会越来越明显。但前提是你得接受它带来的部署、监控、备份、回滚和容量规划成本。
- 大多数项目的第一批问题,不是“有没有向量”,而是“检索链路稳不稳”。切分错了、模型换了、metadata 没设计好、重试没做、缓存没开,都会让你感觉“明明已经向量化了,为什么还是不好用”。
一句话概括就是:向量引擎不是炫技工具,它是 RAG 能不能长期运转的底盘。
我用什么口径做对比
为了让对比更接近真实项目,我把常见场景拆成了统一口径,不然不同方案各自优化,最后很难比出意义。
| 维度 | 统一口径 |
|---|---|
| 文档规模 | 1 万、10 万、100 万三档 |
| 文档类型 | FAQ、说明书、产品文档、工单摘要、Markdown、PDF 解析文本 |
| 切分策略 | 按段落优先,chunk 约 800 字,overlap 120 |
| Embedding | 固定同一模型、同一维度,不混用 |
| 检索方式 | top_k 先设 5,必要时再加 rerank |
| 观测指标 | 写入耗时、查询延迟、失败率、重试次数、月度成本、运维时长 |
| 重点关注 | p50、p95、缓存命中率、错误码分布、更新成本 |
这里有个很重要的经验:不要只盯平均值。向量检索真正折磨人的,往往不是平均延迟,而是 p95 和尾部抖动。用户看到的不是“平均 180ms”,而是“这次怎么卡了两秒”。做 RAG 的人都懂,这种体感差异会直接影响产品可用性。
三种方案到底差在哪
下面这张表,是我按中小团队最常遇到的情况整理的。它不是某个厂商的宣传口径,而是“你真的把项目跑起来之后,最容易碰到的差别”。
| 维度 | 自建 Milvus / FAISS | 原生第三方向量 API | 向量引擎 API 中转站 |
|---|---|---|---|
| 硬件成本 | 需要自己准备机器和存储,低配也要预留余量 | 基本不需要自备硬件 | 基本不需要自备硬件 |
| 部署难度 | 中到高,依赖、版本、索引、服务都要管 | 低,拿到接口就能接 | 低到中,先对齐 base_url、鉴权、path |
| 运维工时 | 高,升级、备份、监控、回滚都得自己做 | 低,主要处理调用和限流 | 中,主要管业务规则和接入稳定性 |
| 网络稳定性 | 内网环境通常较稳,公网要看部署质量 | 受公网和第三方波动影响 | 取决于架构和缓存策略,通常比纯公网直连稳一点 |
| 报错率 | 主要来自配置、版本、容量、索引和同步问题 | 主要来自 429、timeout、鉴权和网络抖动 | 一部分错误会被统一入口收敛掉 |
| 数据安全 | 最强,自己掌控全链路 | 取决于服务条款和传输方案 | 取决于架构设计,适合分层隔离 |
| 适合对象 | 有运维能力、数据敏感、规模较大 | 追求快、团队小、试错期短 | 想平衡成本、速度和维护压力的中小团队 |
我自己的判断很简单:
- 最怕折腾,先选 API 型方案。
- 最怕数据出门,先选自建。
- 两边都怕,但又要尽快上线,中转层型向量引擎通常更适合先做成稳态,再慢慢优化内部结构。
这不是谁高谁低,而是你把复杂度放在哪一层。
自建把复杂度放到自己身上,API 把复杂度放到外部服务上,中转层把复杂度放到“统一接口和统一规则”上。对小团队来说,很多时候“可控”比“极致”更值钱。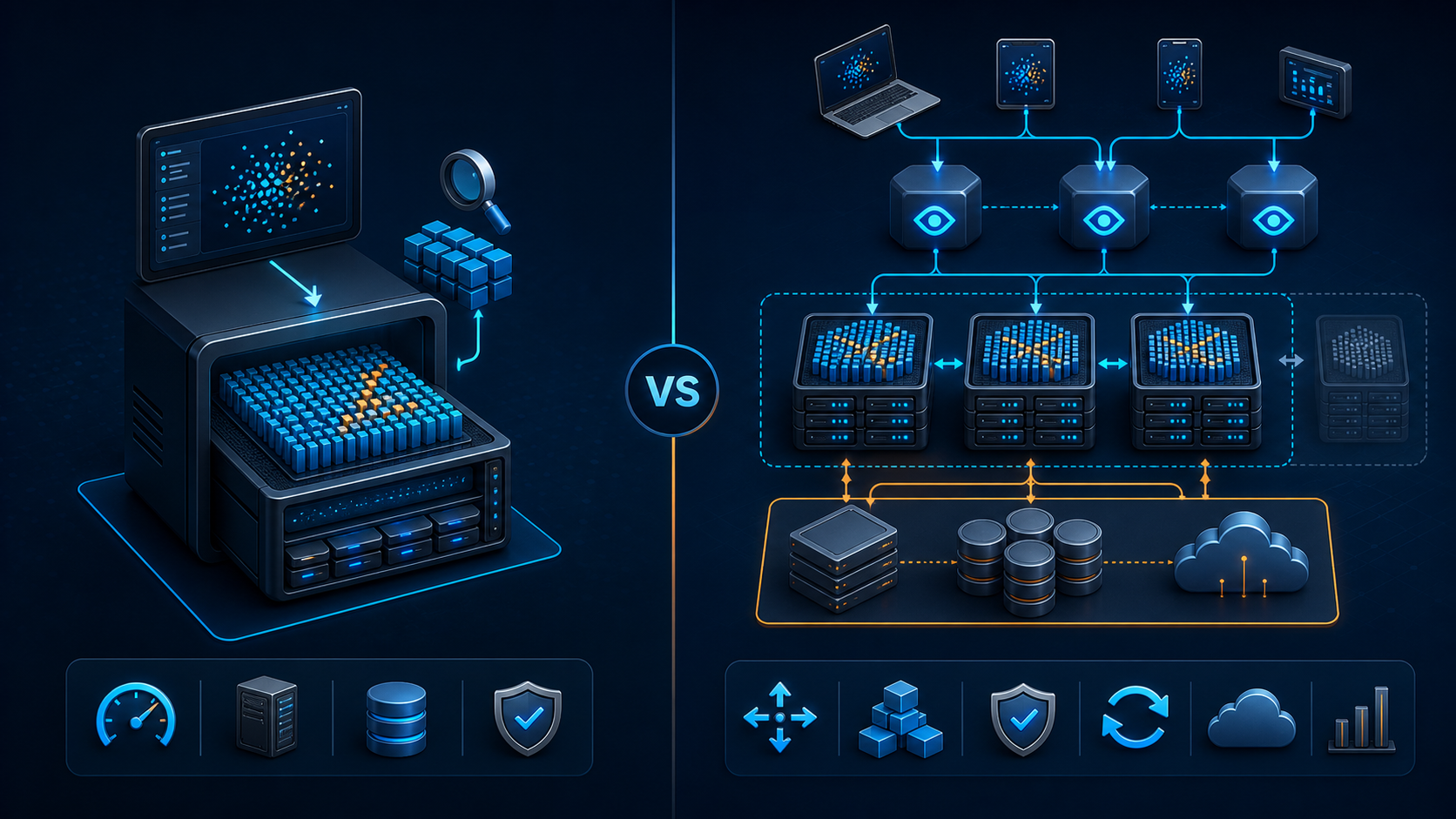
自建 Milvus / FAISS 为什么经常卡在最后一公里
先说一句实话:FAISS 和 Milvus 都不是不能用,而是适合的阶段不一样。
- FAISS 更像一个索引库,适合单机、实验、快速验证、嵌入应用进程。
- Milvus 更像一个服务,适合把向量检索从业务进程里拆出来,做成可扩展的检索层。
很多人第一次选型时,只盯着“能不能存向量”,忽略了后面更麻烦的事情:更新、删除、回滚、重建、监控、权限、并发。这些才是长期项目真正耗时间的地方。
自建最常见的几个坑
-
安装能跑,不代表上线能稳。
很多环境在本地能启动,一到测试机、生产机、容器编排、网络隔离,就开始出依赖问题。 -
索引构建不是一次性的。
数据量上来以后,索引构建时间会明显拉长。你如果没有增量策略,每次更新都重建,成本会很高。 -
Embedding 维度一变,旧索引就不一定能直接复用。
这是特别常见的坑。很多人换了模型,结果查询全乱了,最后才发现是维度不一致,或者混用了不同版本的向量。 -
应用和向量服务抢资源。
如果你把向量检索、文档处理、API 服务都塞在同一台低配机器上,最先崩的往往不是 CPU,而是内存和 I/O。 -
运维不是“能开机”就结束了。
备份、恢复、监控、告警、限流、健康检查、日志留存,都是自建会持续放大的隐性成本。
真实项目里,最浪费时间的不是部署,而是补洞
如果你做过知识库,应该会有这种感受:
前两天你在调服务能不能连通;
第三天开始调 chunk;
第四天开始调 top_k;
第五天发现文档清洗没做好;
第六天才意识到 metadata 没设计全;
然后你又要回头补历史数据。
这就是为什么我现在更看重“链路完整性”,而不是单个组件看起来多漂亮。向量引擎不是孤立存在的,它是文档系统、模型系统、缓存系统、日志系统的交汇点。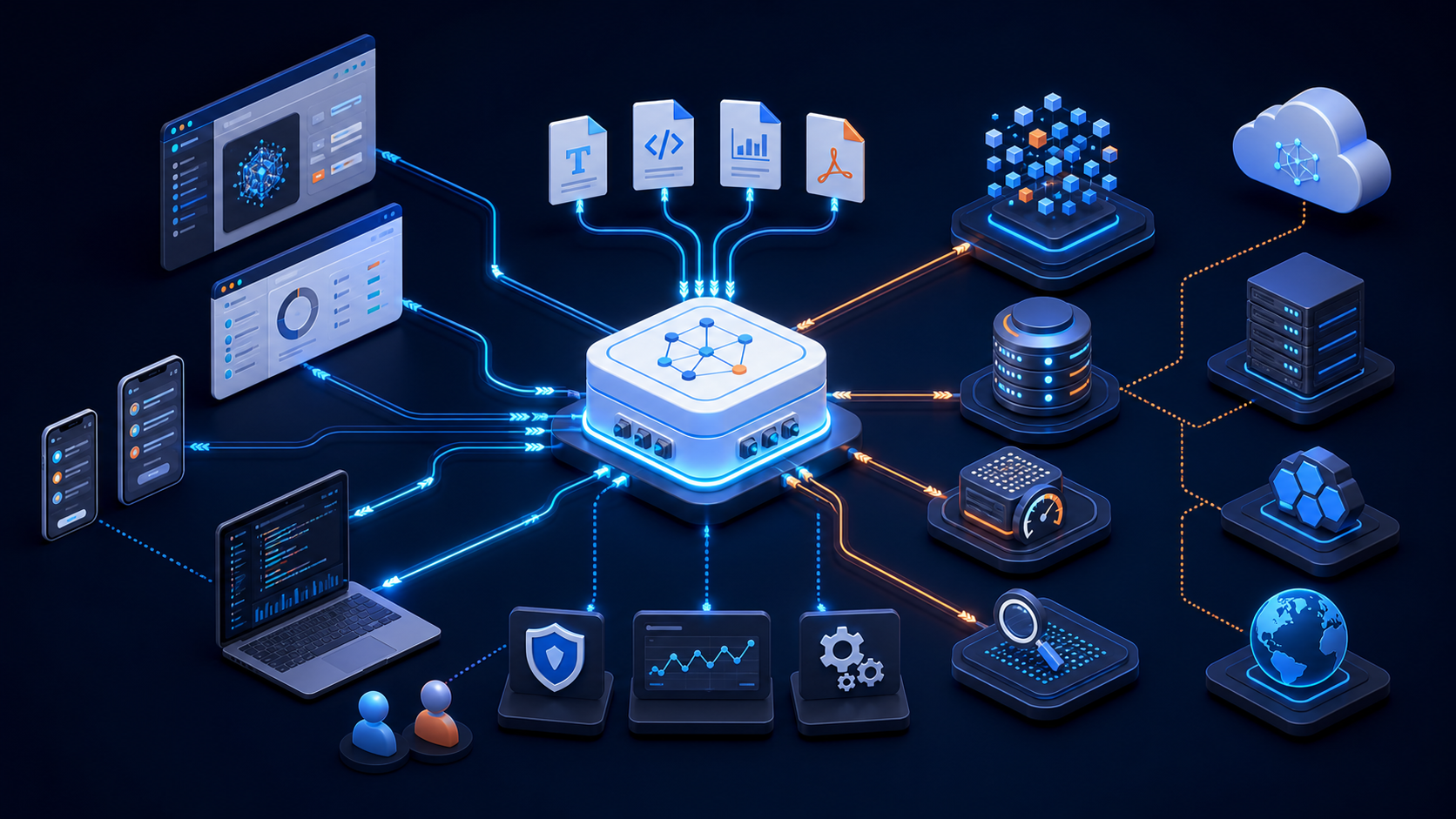
向量引擎 API 中转站,到底解决了什么
如果把自建看作“自己搭底层”,把原生第三方向量 API 看作“直接调用外部能力”,那向量引擎 API 中转站更像是一个把脏活收拢起来的中台层。
它最核心的价值,不是“多一个接口”,而是把很多分散的问题统一掉:
- 统一文档接入方式
- 统一 base_url 和请求格式
- 统一鉴权方式
- 统一错误码和重试策略
- 统一批量处理
- 统一缓存和去重
- 统一日志和排错
- 统一多客户端接入
说白了,很多项目之所以跑不稳,不是因为模型弱,而是因为接入方式太散。今天 Python 写一套,明天 Node 再写一套,后天 Java 又写一套,最后每个客户端都长得不一样,调试时谁都说不清问题在哪。
这里有个容易混淆的点
很多人第一次接接口,会把这三个概念混在一起:
- 资料入口:用来查参数说明、标准接口、错误码、示例请求。
- base_url:你代码里真正请求的服务根地址。
- path:具体功能路由,比如
/embeddings、/vectors/search、/vectors/upsert。
我自己的习惯是,先把资料入口、参数模板和错误码表对齐,再写代码。像 https://178.nz/dn 这种,我会先把它当成资料入口来核对清单,而不是直接把它当成业务接口地址。很多时候,报错并不是模型问题,而是你把地址、鉴权头、path、返回字段写乱了。
先跑通,再优化:零基础接入模板
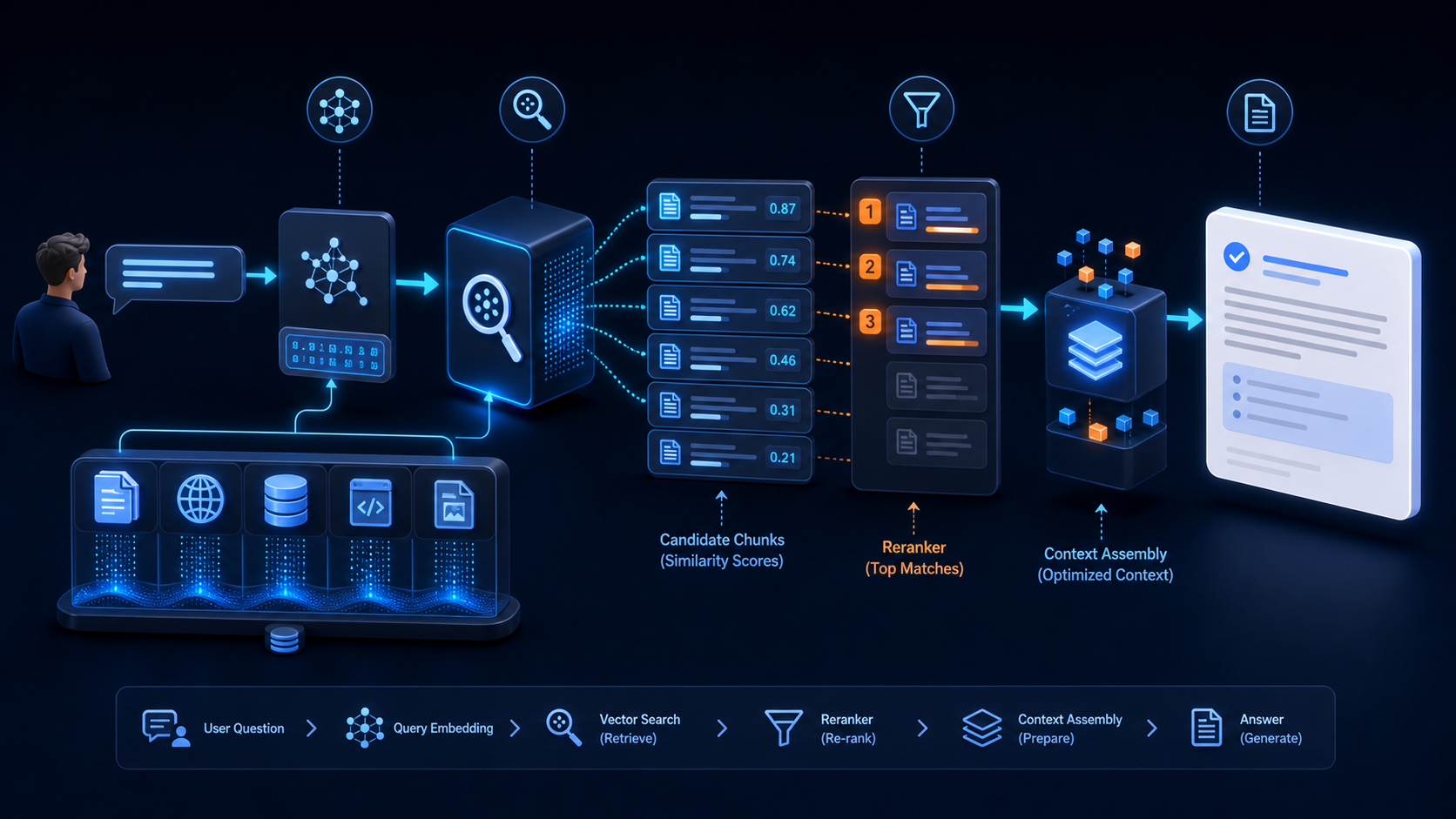
如果你是独立开发者,或者团队里暂时没人专门做基础设施,我建议第一版先用 Python 跑通。别一上来就把框架堆太满,先把“文档能进、向量能出、检索能回”这个最小闭环做出来。
1. 先准备最小配置
# .env
VECTOR_BASE_URL=https://your-vector-host/v1
VECTOR_API_KEY=your_api_key_here
EMBED_MODEL=text-embedding-3-large
VECTOR_COLLECTION=kb_docs
这个配置里最重要的就四个东西:
VECTOR_BASE_URL:服务根地址,别写错路径层级。VECTOR_API_KEY:鉴权用。EMBED_MODEL:Embedding 模型名,必须稳定。VECTOR_COLLECTION:知识库集合名,便于隔离版本。
2. 一份能直接改的 Python 代码
下面这个例子,核心思路是:
清洗文本 -> 切分 chunk -> 批量向量化 -> upsert -> 检索 -> 拼接上下文。
import os
import time
import json
import hashlib
from typing import List
import requests
from dotenv import load_dotenv
load_dotenv()
BASE_URL = os.getenv("VECTOR_BASE_URL", "https://your-vector-host/v1")
API_KEY = os.getenv("VECTOR_API_KEY", "")
EMBED_MODEL = os.getenv("EMBED_MODEL", "text-embedding-3-large")
COLLECTION = os.getenv("VECTOR_COLLECTION", "kb_docs")
session = requests.Session()
session.headers.update({
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
})
def normalize_text(text: str) -> str:
return "\n".join(line.strip() for line in text.splitlines() if line.strip())
def stable_hash(text: str) -> str:
normalized = " ".join(text.split())
return hashlib.sha256(normalized.encode("utf-8")).hexdigest()
def chunk_text(text: str, chunk_size: int = 800, overlap: int = 120) -> List[str]:
paras = [p.strip() for p in normalize_text(text).split("\n") if p.strip()]
chunks = []
buffer = ""
for para in paras:
candidate = f"{buffer}\n{para}".strip() if buffer else para
if len(candidate) <= chunk_size:
buffer = candidate
continue
if buffer:
chunks.append(buffer)
tail = buffer[-overlap:] if buffer and overlap > 0 else ""
buffer = f"{tail}\n{para}".strip() if tail else para
if len(buffer) > chunk_size:
chunks.append(buffer[:chunk_size])
buffer = buffer[chunk_size - overlap:] if overlap > 0 else ""
if buffer:
chunks.append(buffer)
return chunks
def post_json(path: str, payload: dict, timeout: int = 60, retry: int = 3) -> dict:
url = f"{BASE_URL}{path}"
last_err = None
for i in range(retry):
try:
resp = session.post(url, json=payload, timeout=timeout)
resp.raise_for_status()
return resp.json()
except requests.RequestException as e:
last_err = e
if i < retry - 1:
time.sleep(0.5 * (2 ** i))
else:
raise last_err
def embed_texts(texts: List[str], batch_size: int = 32) -> List[List[float]]:
vectors = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i + batch_size]
data = post_json("/embeddings", {
"model": EMBED_MODEL,
"input": batch
}, timeout=60, retry=3)
vectors.extend([item["embedding"] for item in data["data"]])
return vectors
def upsert_document(doc_id: str, title: str, text: str) -> dict:
chunks = chunk_text(text)
vectors = embed_texts(chunks)
items = []
for idx, (chunk, vector) in enumerate(zip(chunks, vectors)):
items.append({
"id": f"{doc_id}:{idx}",
"doc_id": doc_id,
"title": title,
"chunk_index": idx,
"content": chunk,
"content_hash": stable_hash(chunk),
"embedding_model": EMBED_MODEL,
"vector": vector,
"metadata": {
"source": "knowledge_base",
"version": "v1",
"status": "active"
}
})
return post_json("/vectors/upsert", {
"collection": COLLECTION,
"items": items
}, timeout=90, retry=3)
def search(query: str, top_k: int = 5) -> dict:
q_vector = embed_texts([query], batch_size=1)[0]
return post_json("/vectors/search", {
"collection": COLLECTION,
"vector": q_vector,
"top_k": top_k,
"filters": {
"status": "active"
}
}, timeout=30, retry=3)
def build_context(hits: dict) -> str:
lines = []
for i, item in enumerate(hits.get("items", []), 1):
title = item.get("title", "")
content = item.get("content", "")
lines.append(f"[{i}] {title}\n{content}")
return "\n\n".join(lines)
if __name__ == "__main__":
sample_text = """
向量引擎用于把文本转成向量,并完成相似度检索。
在 RAG 场景里,核心不是“有没有向量”,而是“能不能稳定召回相关内容”。
"""
upsert_result = upsert_document("doc_001", "向量引擎说明", sample_text)
print("upsert_result:", json.dumps(upsert_result, ensure_ascii=False, indent=2))
hits = search("向量引擎和 RAG 有什么关系?", top_k=5)
context = build_context(hits)
print("\nretrieved_context:\n", context)
3. 这段代码最值得保留的三个习惯
- 所有请求都走统一的
BASE_URL,别在不同文件里手写不同地址。 - 所有文本先归一化再算 hash,避免重复入库。
- 所有批量请求都要有 timeout 和 retry,别让一次抖动把整批任务打穿。
你只要把这三个动作守住,后面很多问题会少一半。
真正省钱的地方,不在“少买机器”,而在“少返工”
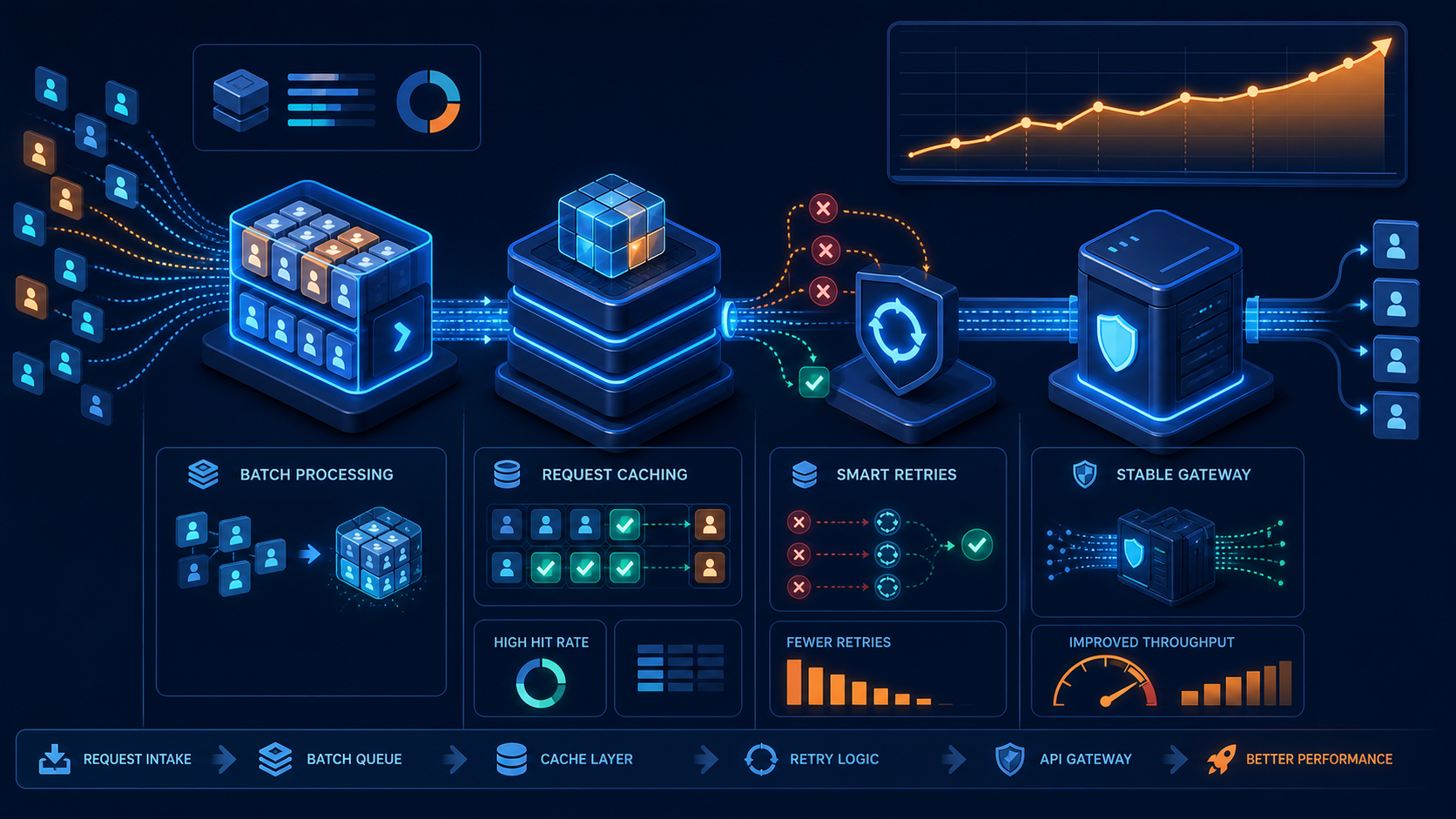
向量引擎项目里,最容易被低估的是这些东西:
- chunk 策略
- batch 大小
- top_k
- 缓存命中率
- 元数据设计
- retry 和退避
- 日志和监控
我会先把这几个参数定住
| 参数 | 建议起点 | 说明 |
|---|---|---|
chunk_size |
600-800 中文字符 | 太小丢上下文,太大召回容易混 |
overlap |
80-120 | 保留段落边界信息 |
batch_size |
32-64 | 平衡吞吐和请求体大小 |
top_k |
5-8 | 先稳住召回,再考虑扩展 |
timeout |
30-60 秒 | 和网络环境匹配 |
retry |
2-3 次 | 配合指数退避更稳 |
元数据比你想的更重要
很多人只盯着向量本身,其实真正能帮你省时间的是 metadata。下面这些字段,越早规划越好:
{
"doc_id": "policy_202606",
"chunk_id": "policy_202606:03",
"tenant_id": "team_a",
"version": "v3",
"source": "handbook",
"doc_type": "faq",
"updated_at": "2026-06-01",
"embedding_model": "text-embedding-3-large",
"status": "active"
}
这些字段看起来不起眼,但它们决定了你后面能不能做这些事:
- 多租户隔离
- 版本回滚
- 增量更新
- 权限过滤
- 近时优先
- 按文档类型检索
- 按来源回查
如果没有这些元数据,你后面会很难把知识库维护成“长期可用”的状态。
纯向量检索不一定够,关键词和 rerank 往往是保险
特别是做技术文档、错误码、型号参数、接口说明时,纯向量召回经常会出现“看起来像,但不是”的情况。这个时候,关键词检索、BM25、rerank 都应该保留一个位置。
我的经验是:
- FAQ、说明书、规整文档,向量检索很好用。
- 错误码、参数表、型号、路径,关键词检索和过滤条件非常重要。
- 答案质量要求高,最好加一层 rerank,不要只靠 top_k 的前几条直接拼答案。
从 4 个月复盘看,项目会经历哪几个阶段
如果把一个真实项目按 4 个月节奏去看,很多变化不是一开始就能意识到的。
第 1 阶段:先跑通
这个阶段最重要的不是优化,而是把闭环打通。
- 文档能不能进
- 向量能不能出
- 检索能不能回
- 接口能不能稳定响应
- 错误能不能看懂
这时候最怕的是“功能很多,但没有一个能顺利跑通”。
所以第一版一定要克制,少做花哨功能,先保主链路。
第 2 阶段:开始看稳定性
当你跑通以后,问题就会从“能不能用”变成“稳不稳”。
- 哪些请求经常超时
- 哪些文档更新会触发重建
- 哪些 chunk 命中率低
- 哪些错误是网络问题,哪些是参数问题
- 哪些地方可以缓存
这时候你会突然发现,最值钱的不是多加功能,而是把错误分层。
比如鉴权失败、path 错误、模型不一致、timeout、429、维度不一致,这些一定要能一眼区分。
第 3 阶段:开始算成本
到了后面,你会越来越在意:
- 月度调用费
- 机器成本
- 存储成本
- 运维工时
- 改模型的代价
- 回滚的代价
真正的选型,不是看谁在演示时最顺滑,而是看谁能在长期维护里少让你返工。
常见报错怎么排,别一上来就怪模型
很多人一出问题就说“模型不行”“向量不准”,其实大部分时候,问题根本不在模型。
| 报错现象 | 常见原因 | 处理方式 |
|---|---|---|
401 / 403 |
API Key 错、header 错、空格多、权限不足 | 先查 Authorization,再查 key 有无多余字符 |
404 |
base_url 和 path 拼错 | 先确认是不是少了 /v1,再查具体 endpoint |
429 |
限流、并发太高、batch 太大 | 降并发、做缓存、加退避重试 |
413 |
请求体太大 | 减少 batch_size 或 chunk_size |
timeout |
网络抖动、返回太大、后端处理慢 | 拉长 timeout,缩小 top_k,做 keep-alive |
dimension mismatch |
Embedding 模型换了,维度没统一 | 重新建索引,不要混用不同维度向量 |
CORS |
浏览器直连接口 | 改成后端代理,不要前端直调 |
connection reset |
服务端连接中断、代理不稳 | 检查网关、反向代理和长连接设置 |
排错顺序我一般这么看
- 先看 URL
- 再看 鉴权
- 再看 请求体
- 再看 维度
- 再看 网络
- 最后才看 后端日志
很多人顺序是反的,先去怀疑模型、怀疑向量、怀疑 prompt,最后才发现就是 path 少了一截或者 header 名写错了。这个坑真的很常见。
不同人群怎么选
向量引擎这件事,最怕“用同一种答案回答所有人”。不同团队,适合的路径差别很大。
| 角色 | 文档规模 | 更适合的选择 | 主要原因 |
|---|---|---|---|
| 个人开发者 | 1 万以内 | 轻量 API 或 FAISS | 先把产品跑起来,少碰运维 |
| 小型创业团队 | 1 万到 10 万 | 向量引擎 API 中转站或管理型服务 | 平衡速度、成本和稳定性 |
| 企业内部知识库 | 10 万到百万级 | 自建或混合架构 | 数据隔离、权限、审计更重要 |
| 外包项目 | 变化大、多客户 | 统一 base_url 的 API 方案 | 便于多客户端接入和快速交付 |
如果你现在只有一台低配机器
我的建议很简单:
- 先跑通闭环
- 先把日志打全
- 先把 chunk 和 metadata 做对
- 先别追求复杂部署
很多低配项目之所以崩,不是因为机器太弱,而是因为把太多东西塞进同一个进程里。你要做的是减法,不是加法。
如果你已经进入 10 万级文档
这个阶段,最应该重视的是:
- 增量更新
- 去重
- metadata 过滤
- 版本管理
- 缓存命中率
- 错误码分层
这时候如果还用“每次重新全量重建”的思路,后面会很痛。
如果你已经到百万级
到这个量级以后,自建的价值会更明显,但前提是你要接受另一套成本结构:
- 索引策略要更认真
- 备份恢复要更认真
- 监控告警要更认真
- 权限审计要更认真
- 变更管理要更认真
它不再是“把向量存起来”这么简单,而是一个真正需要维护的检索系统。
实战里我最看重的 5 个指标
如果你要把向量引擎当长期项目来做,我建议至少盯住这 5 个指标。
| 指标 | 看什么 |
|---|---|
p50 |
大部分请求的基础手感 |
p95 |
用户真正会抱怨的尾部延迟 |
error rate |
稳定性和可用性 |
retry count |
网络和限流情况 |
cache hit rate |
成本和响应速度的关键 |
我后来越来越觉得,很多“体验好不好”的问题,最后都能在这几个指标里找到影子。
平均延迟看起来不错,不代表用户体感好。
错误率不高,不代表没有尾部卡顿。
所以做 RAG 或知识库,别只看单点数据,要看链路数据。
资料入口
如果你现在正卡在接口参数、标准地址、配置模板、报错修复文件或者多客户端接入文档上,我建议先把这个资料入口放旁边对照一下
我自己的习惯是,先确认 base_url、请求 path、鉴权头和返回字段,再动代码。很多看起来像模型问题的报错,最后只是地址和参数没对齐。先把这些基础项核对好,后面写 Python、Node、Java、Go 的时候都会轻松很多。
FAQ
1. 向量数据库和向量引擎有什么区别?
简单说,向量数据库更偏存储和检索,向量引擎更偏整条链路能力。
后者通常会把文档清洗、切分、Embedding、缓存、召回、重试、日志、权限这些事情一起考虑进去。
如果你只是做简单相似度搜索,数据库够用;如果你要做长期运行的 RAG 知识库,向量引擎的思路更完整。
2. 小项目有必要一开始就自建吗?
不一定。
如果你的文档量不大、团队人手少、上线时间紧,先用轻量方案或者管理型服务,通常更省心。
自建的优势是可控,但它不是免费的。对小团队来说,时间成本往往比机器成本更贵。
3. 为什么检索到了,答案还是不准?
通常不是一个点出问题,而是链路叠加。
常见原因有:
- chunk 太大或太小
- top_k 不合适
- 文档清洗没做好
- 关键词和向量召回都没加
- 没有 rerank
- prompt 没限制模型乱发挥
也就是说,向量召回只是第一步,不是终点。
4. 维度不一致怎么办?
最稳妥的做法是:重新建索引。
不要试图把不同维度、不同版本、不同模型的向量混在一个库里。
最好在 metadata 里保留 embedding_model 和 embedding_version,以后回滚和迁移都会清楚很多。
5. API 一直 429 或 timeout,先怎么处理?
先别急着加并发,先看这几个地方:
- batch 是否太大
- timeout 是否太短
- 是否重复请求太多
- 是否没有做缓存
- 是否没有指数退避
很多时候,降一半并发、加一层 cache,效果比盲目扩容更直接。
6. 什么时候适合从 API 迁移到自建?
通常是这几类信号出现以后:
- 数据敏感度明显提升
- 权限和审计要求变高
- 调用量稳定上涨
- 外部依赖开始影响业务节奏
- 你已经有能力维护这套系统
如果只是觉得“自建听起来更高级”,那还不够。
真正值得迁移,是因为你的业务已经需要它,而不是因为你想把架构画得更漂亮。
7. 做 RAG 时,最容易被忽略的是什么?
我认为是这三个:
- chunk 策略
- metadata 设计
- 错误处理
很多人花了很多时间调模型,最后发现真正决定效果的,是文档怎么切、怎么标、怎么回查。
模型负责回答,向量引擎负责把该找回来的内容找回来。两边都稳,RAG 才真的像样。
最后这点复盘,我现在越来越认同
如果把这几个月关于向量引擎的反复踩坑压缩成一句话,我会说:
向量引擎不是你项目里最显眼的部分,但它往往决定了整个 RAG 系统能不能长期跑。
对独立开发者来说,最重要的不是第一天选到最复杂的方案,而是选到一个能稳定接入、好排错、好扩展、以后还能慢慢长大的方案。
对中小团队来说,真正有价值的,也不是把所有东西都自建,而是找到一个能把复杂度控制住的平衡点。
如果你现在也在做向量数据库、RAG 知识库、文档检索、智能客服,或者正在纠结 Milvus、FAISS、API 中转站到底怎么选,我更建议你先把这几个东西想清楚:
- 你的文档规模是多少
- 你的更新频率有多高
- 你的权限和安全要求有多严
- 你的团队有没有运维能力
- 你的接口调用会不会频繁报错
这些问题想明白了,选型就不会乱。
你现在是自建向量库,还是已经在用向量引擎 API?
最常见的报错是 401、429,还是 timeout?
如果你愿意,把你的文档规模、QPS 和当前卡住的问题说出来,我可以按你的场景继续拆一版更细的参数模板和排错清单。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献98条内容
已为社区贡献98条内容

所有评论(0)