2024KGC论文
论文
- Mixture of Modality Knowledge Experts for Robust Multi-modal Knowledge Graph Completion
- Query-Enhanced Adaptive Semantic Path Reasoning for Inductive Knowledge Graph Completion
- CogMG:Collaborative Augmentation Between Large Language Model and Knowledge Graph
- Enhancing text-based knowledge graph completion with zero-shot large language models: A focus on semantic enhancement
- Contrast then Memorize: Semantic Neighbor Retrieval-Enhanced Inductive Multimodal Knowledge Graph Completion
- Unleashing the Power of Imbalanced Modality Information for Multi-modal Knowledge Graph Completion
- COSIGN: Contextual Facts Guided Generation for Knowledge Graph Completion
- Bilateral Masking with prompt for Knowledge Graph Completion
- Multi-hop neighbor fusion enhanced hierarchical transformer for multi-modal knowledge graph completion
- A knowledge graphs representation method based on IsA relation modeling
- 知识图谱补全综述
- 一种关系敏感文本信息增强知识图谱补全模型
- 基于结构增强的长尾知识图谱完成模型
- 基于多跳推理的知识图谱补全方法
- Scidown网盘(含科研工具)
- 学位论文软件设计:
Mixture of Modality Knowledge Experts for Robust Multi-modal Knowledge Graph Completion
https://arxiv.org/pdf/2405.16869
https://github.com/zjukg/MoMoK
Multi-modal knowledge graph completion (MMKGC)(进一步增强具有多模态特征的实体嵌入,旨在对三重结构和多模态内容进行协同建模,以实现鲁棒预测)
multi-modal knowledge graphs (MMKGs)(包含丰富的模态信息,如实体图像和文本描述,将结构化知识和非结构化多模态内容连接在一起)
问题:
Existing methods tend to focus on crafting elegant entity-wise multi-modal fusion strategies, yet they overlook the utilization of multi-perspective features concealed within the modalities under diverse relational contexts.
现有方法倾向于着眼于构建优雅的实体多模态融合策略,却忽视了在不同关系语境下隐藏在模态关系中的多视角特征的利用。
These entity embeddings are then mapped into a scalar score along with the relation embeddings as a basis for assessing the triple plausibility
Mixture-of-Experts(MoE)(专家组合:将给定任务划分为多个子任务,使用单个专家模型进行求解,并设计路由模块以选择合适的专家来解决当前任务。用来有效训练更大更强的LLMs)
方法:
设计关系引导模态知识专家获取关系感知模态嵌入,并整合多模态的预测,实现全面决策;通过尽量减少专家的相互信息来解开专家的纠缠。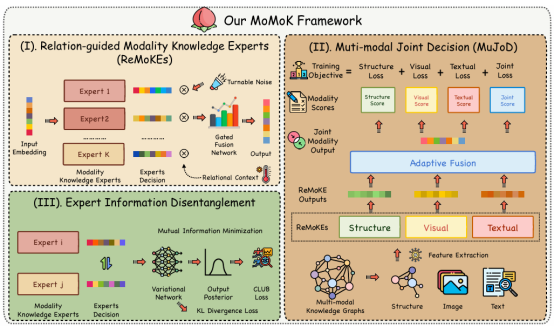
ReMoKE在关系文本下构建每个模态的混合专家网络
MuJod旨在通过整合多模态决策实现多模态融合和协同预测
ExID通过减小他们互信息进一步增强ReMoKE
未来工作:
不仅完成了MMKGC的任务,还找到了将MMKG与大型语言模型相结合的方法,实现了具有多模态知识感知的稀疏大型语言模型。
不足:
任务场景的局限(框架专门用来KGC,没有更多任务)
使用经典的基于嵌入的方法,没有结合最新大模型
实验局限(由于缺少超大规模的数据集,所以只在中等大小的数据集上实验)
Query-Enhanced Adaptive Semantic Path Reasoning for Inductive Knowledge Graph Completion
用于归纳知识图谱补全的查询增强自适应语义路径推理
<CIKM2024计划于2024年10月21日-10月25日在美国爱达荷州召开。CIKM是CCF推荐的B类国际学术会议,在信息检索和知识挖掘相关领域具有较高的学术声誉。这次会议的Full Research Paper Tack共收到1496篇有效投稿,录用347篇,录用率约23%。>
问题:
推理过程中容易受到嘈杂的结构信息的影响,并且难以捕获推理路径中的长程依赖关系。
目前方法:只关注推理路径中当前节点,而忽略了整个推理路径中实体之间关键的长程语义依赖关系。(论文方法识别有效推理的关键语义路径,捕获推理路径中的长程语义依赖关系)
方法:
查询相关掩码模块,用于自适应屏蔽噪声结构信息,同时保留与目标密切相关的重要信息。
·查询相关掩码模块(对噪声结构进行掩码,从而获得有效的结构特征)(具体来说,本模块首先提取单个规则并计算其置信度,以评估关系之间的相关性。随后,它应用归一化策略将这种置信度转换为概率。最后,采用伯努利分布过滤掉不相关的关系。)目的:从不相关的结构信息中重新移动噪声
·全局语义打分模块(动态更新机制,捕获推理路径中的长程语义依赖关系)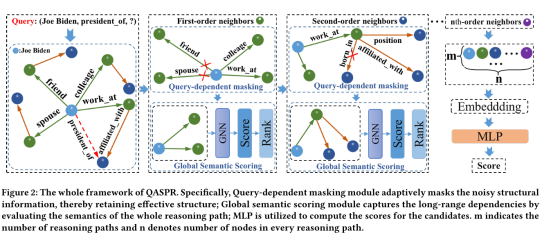
CogMG:Collaborative Augmentation Between Large Language Model and Knowledge Graph
中国科学院
问题:大模型产生幻觉。提出知识图谱和大模型协同增强
针对知识覆盖不完整和知识更新错位(知识更新目前两种策略:信息抽取和知识图谱补全)的问题。
当查询超出了当前 KG 的知识范围时,鼓励 LLM 明确分解所需的知识三元组。
方法:
查询知识图谱。
整合结果。
知识图谱演化(手动干预选项)
Enhancing text-based knowledge graph completion with zero-shot large language models: A focus on semantic enhancement
目前的KGC方法两类:embedding-based and text-based methods.
结合了基于文本的策略来扩展预测和增强数据.
保留了语义扩展提示中实体的原始描述。这种策略减少了由于多义性而导致的冗余文本,并降低了错误或幻觉输出的可能性。与压缩提示不同,语义扩展提示旨在引出具有丰富语义内容的文本。实现约束对于阻止模型反刍现有内容至关重要。
Contrast then Memorize: Semantic Neighbor Retrieval-Enhanced Inductive Multimodal Knowledge Graph Completion
面向归纳知识图谱补全(生成没见过的实体和关系)更好的基准数据集
传统上,对 KGC 的大多数研究都集中在直推设置上,在训练和测试过程中可以看到相同的实体和关系。
然而,很少有研究提出研究归纳MKGC (IMKGC)涉及新兴实体看不见的训练
首先提出一个统一的跨模态对比学习,在一个统一的表示空间中同时捕获查询实体对的文本-视觉和文本-文本相关性。
Unleashing the Power of Imbalanced Modality Information for Multi-modal Knowledge Graph Completion
现有的MMKGC方法忽略了实体间模态信息的不平衡问题,导致模态融合不充分和原始模态信息利用效率低下。为了解决上述问题,我们提出了自适应多通道融合和通道对抗训练(AdaMF-MAT)来释放MMKGC的不平衡通道信息。AdaMF-MAT通过自适应的模态权重实现多模态融合,并进一步通过模态对抗训练生成对抗样本以增强不平衡的模态信息。论文https://arxiv.org/abs/2402.15444代码https://github.com/zjukg/AdaMF-MAT
COSIGN: Contextual Facts Guided Generation for Knowledge Graph Completion
2024NAACL
上下文事实收集器
下文事实组织者
推理生成器
在本文中,我们提出了一种生成模型,称为COSIGN,用于各种KGC任务。与之前的方法不同,我们没有直接使用上下文事实来指导模型推断缺失的事实。相比之下,我们利用LLM的组织能力将收集到的分散的文本事实转化为连贯的上下文事实,并使用连贯的上下文事实来指导模型推断缺失的事实。具体来说,我们设计了一个上下文事实收集器来实现类似人类的检索行为。然后,提出一种情境事实组织方法,通过知识提炼来学习LLMs的组织能力。最后,将有组织的上下文事实作为推理生成器的输入,以生成缺失的事实。
Bilateral Masking with prompt for Knowledge Graph Completion
2024NAACL
问题:这些方法都无法获得令人满意的实体单一嵌入表示
知识图谱嵌入方法两类:基于结构的方法(TransE,RotatE,TuckER),基于描述的方法(进一步分类为句子匹配方法<SimKGC初次基于描述的方法超过了结构的方法>和词匹配方法)
方法:
受SimKGC启发,我们通过同时在头部和尾部编码器中进行预测来实现此操作。此外,我们设计了提示来缩小已知实体与预测实体之间的距离,以加强它们的关联性。
度偏差问题(节点更少的度展现出更弱的表征,在下游任务表现更差),受SimCSE启发,利用预训练语言模型的辍学机制来获取额外的正样本,解决知识图谱中的度偏差问题。
Multi-hop neighbor fusion enhanced hierarchical transformer for multi-modal knowledge graph completion
提出了一种新颖的分层Transformer架构,称为MNFormer,该架构通过完全集成多跳邻居路径和图像文本嵌入来捕获结构和语义信息,同时避免异构性问题。在MNFormer的编码阶段,我们设计了多层多跳邻居融合(MNF)模块,利用注意力来合并图像和文本特征。这些 MNF 模块逐步融合相邻实体的信息,沿着源实体的相邻路径逐跳融合。然后,在解码阶段利用Transformer来集成所有MNF模块的输出,其输出随后用于匹配目标实体并完成MKG完成。此外,我们开发了语义方向损失来增强MNFormer的拟合性能。
知识图谱互补算法主要可分为静态知识图谱互补和动态知识图谱互补两种类型。静态知识图谱互补的适用范围仅限于知识图谱中已有的实体,而动态知识图谱互补可以建立知识图谱与外界的联系,并创建一个包含新实体和新关系的三元组.
对比学习研究的成功改进了这些方法,但它们仍然受到现有负抽样的限制,这通常比基于嵌入的方法成本更高.
Siamese网络是一种基于两个或多个相同或相似输入的神经网络模型。 它的特点在于,通过比较这些输入之间的差异来学习识别输入的特征。 Siamese网络的基本结构包括两个相同的子网络,每个子网络都由一个神经网络层和一个节点组成.
A knowledge graphs representation method based on IsA relation modeling
2024Expert Systems With Applications一区
模拟了 isA 关系的两个特征——传递性和反对称性。传递性由向量的投影不变性建模,反对称性由偏阶约束建模。
(细粒度,isA,粗粒度)一方面,粗粒度实体为其细粒度实体提供基本类别信息;另一方面,细粒度实体为其对应的粗粒度实体提供详细信息,使得它们在实体表征的学习中相互受益,提高了表征的学习效率。对于包含 isA 关系三元组的知识图谱,可以利用 isA 关系的潜在语义信息来学习知识嵌入,可以缓解图稀疏性导致的学习不足问题,而无需增加额外的训练样本。
TransE无法对传递性进行建模。基于实例和概念的模型,如 TransC、JOIE 和 CIST 模型Instanceof 和 Subclassof 关系,它们是两种 isA 关系。这些方法忽略了 Descendantof 和 Partof 等关系。换言之,现有方法无法完全模拟isA关系的特征。
相关工作:
1.基本知识图谱表示学习(传统模型、基于神经网络的模型)
2.结合外部信息的知识图谱表示学习—基于实例和概念的知识图谱表示学习
知识图谱补全综述
首先,根据模型构建方法的不同,将知识图谱完成模型分为传统知识图谱完成模型、基于神经网络的知识图谱完成模型和基于元学习的知识图谱完成模型三大类;介绍了这三种知识图谱完成模型的分类方法。然后,对知识图谱补全法中采用的数据集和评价指标进行总结,并从各模型的优缺点角度对各模型进行了详细的对比分析。最后,对知识图谱的完成情况进行了总结和总结,并对未来的研究方向进行了展望.
综述:
知识图谱补全技术旨在通过预测缺失的实体或关系来丰富知识图谱的内容,一直是近年来的研究热点。特别是,基于嵌入的方法在知识图谱完成任务方面取得了显著的进展。它回顾了最近基于嵌入的静态知识图谱完成方法,并根据基于翻译的模型、张量分解、神经网络模型和预训练语言模型等方法对它们进行分类。
一种关系敏感文本信息增强知识图谱补全模型
虽然知识图谱嵌入模型和文本信息增强模型是该领域的两种趋势,但它们都存在一些缺点,例如,过分依赖单一模态信息可能会导致性能受限。然而,只有少数工作试图整合多种模式。
我们发现头部和尾部实体之间的语义相似性与文本信息的增强效果相关,语义相似性也与关系类型有关。我们称这种现象为关系敏感性。为了解决这些问题,我们提出了一种关系敏感文本信息增强知识图谱补全模型(RSTIE-KGC)
基于结构增强的长尾知识图谱完成模型
知识图谱完成模型将三元组映射到不同的向量空间进行表示,但仍存在以下缺点:1、文本编码器缺乏结构化知识;2、关系分布呈长尾,模型主要预测更频繁的关系。
1)为了解决第一个问题,我们将每个三元组划分为两个不对称的部分,就像在基于翻译的图嵌入方法中一样。我们使用连体样式的文本编码器对这两个部分进行编码。我们的模型分别采用分类器和空间测量进行表示和结构学习,以增加编码器的结构化知识。结合了文本编码和图嵌入方法,采用Siamese风格的编码器来注入结构化知识。
2)为了解决第二个问题,我们实施了焦点损失来解决正负样本之间的不平衡问题,并关注硬样本。此外,我们开发了一种自适应集成方案,通过结合现有的图嵌入模型来进一步提高性能。在损失函数中引入了一个焦点损失项,为困难的样本分配更高的权重。
基于多跳推理的知识图谱补全方法
知识图谱完成的多跳推理是一种通过遵循多个逻辑步骤来预测知识图谱中缺失事实的方法.多跳推理的关键优势是其可解释性。
之前方法:基于 RL 的解决方案具有高度的可解释性,但收敛速度慢且收敛性差。这些方法在大型稀疏知识图谱上的计算成本尤其高。与基于 RL 的解决方案相比,自然语言处理方法具有更好、更快的收敛性。然而,这些方法的特点是缺乏可解释性。
Scidown网盘(含科研工具)
https://www.scidown.cn/wangpan/index.php
学位论文软件设计:
1、基于神经网络的知识图谱链接预测方法研究
(学位论文)
电子科技大学
2023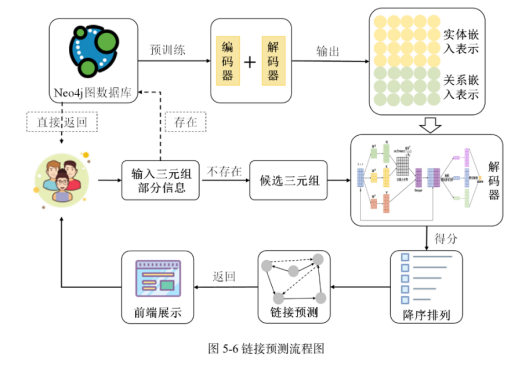
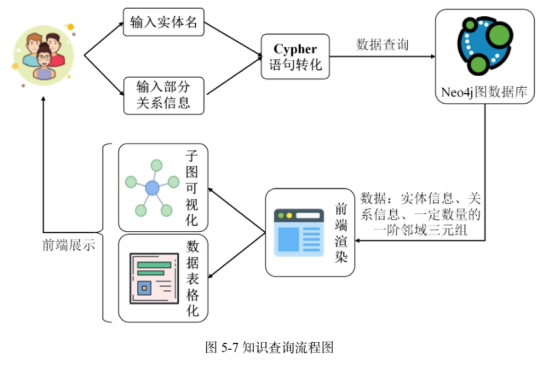
2、基于信息增强的知识图谱表示学习的方法研究与应用
(学位论文)
电子科技大学
2023
第三章 基于实体增强的补全
第四章 基于关系增强的补全
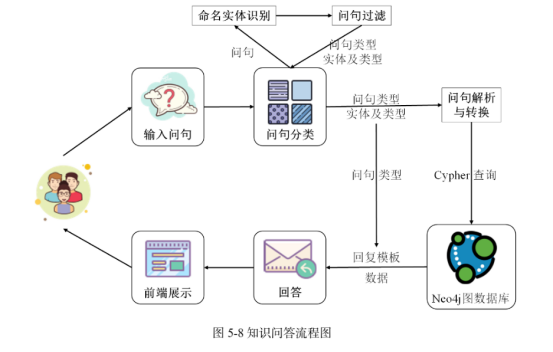
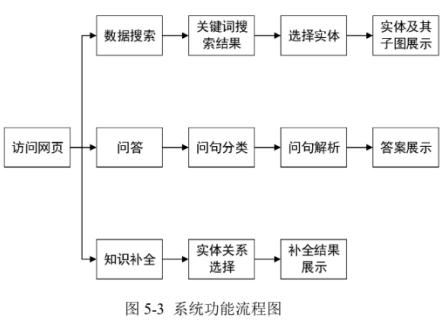
第五章 基于知识图谱补全的医疗智能问答系统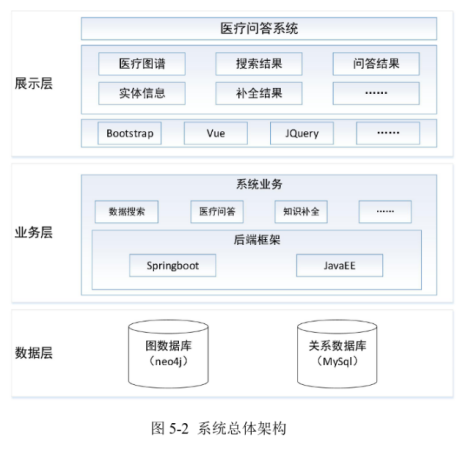
3、基于大模型高效知识图谱补全算法研究及应用
(学位论文)
江南大学
2025
基于预编码的描述文本嵌入构建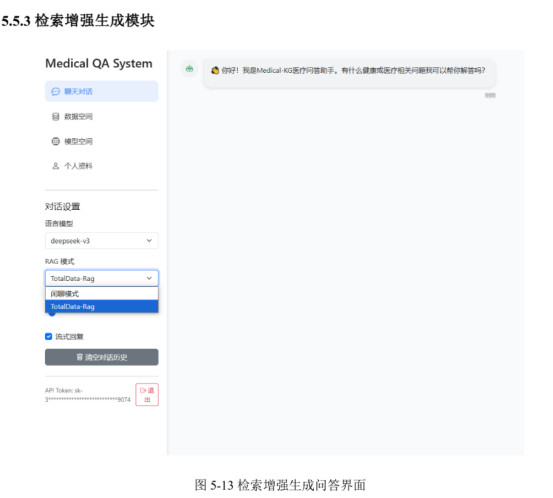

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)