前言
本流程围绕 “指标驱动、标准先行、模型落地、质量闭环、安全合规、资产沉淀” 六大核心逻辑,形成端到端的数据治理闭环。
一、全流程说明
1. 流程图
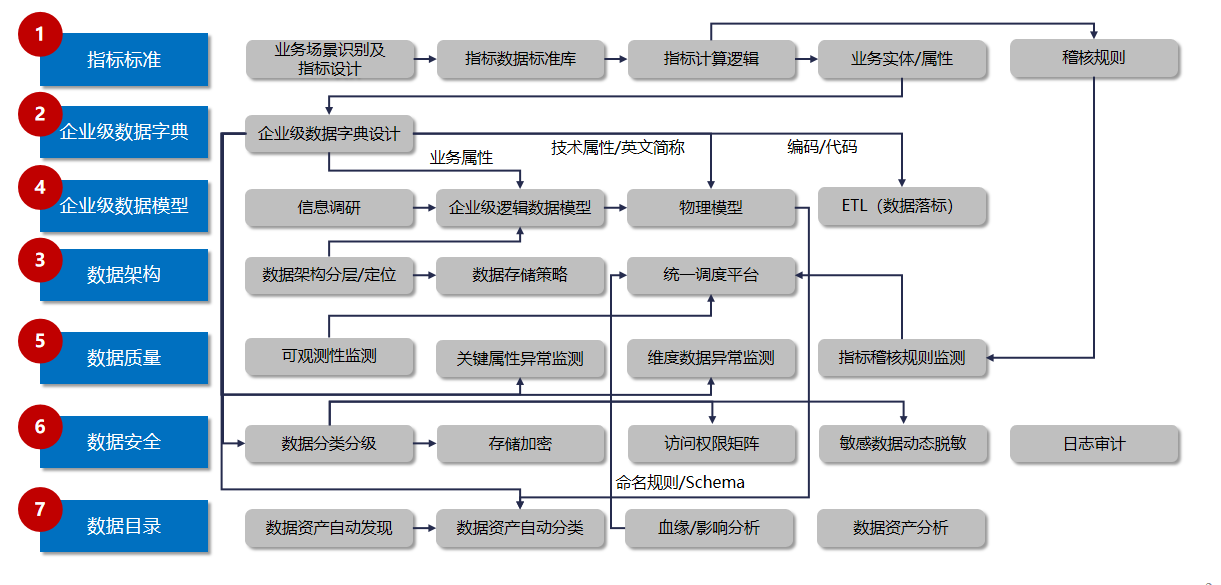
2. 关键链路说明
- 指标标准是业务起点,驱动数据字典、模型设计与数据质量规则的制定;
- 数据字典为模型设计、ETL 开发、数据治理提供统一标准;
- 数据架构 + 企业级数据模型是技术落地的核心,实现数据从源到数仓的标准化流转;
- 数据质量基于数据架构、模型、指标规则,实现全链路数据校验;
- 数据安全嵌入数据分类、存储、访问、脱敏全流程,保障数据合规;
- 数据目录沉淀所有治理成果,实现数据资产的可发现、可理解、可追溯。
3. 全流程逻辑闭环
从业务指标出发,通过数据字典统一标准,驱动数据模型与架构落地,以数据质量与安全保障可信合规,最终沉淀为数据目录实现资产价值释放,各模块相互支撑、迭代优化,形成完整的数据治理闭环。
二、流程详解
1. 指标标准:业务驱动的治理起点
- 核心目标:统一业务指标口径,解决 “数出多门、口径不一” 问题
- 关键工作:业务场景识别与指标设计 → 指标数据标准库建设 → 指标计算逻辑定义 → 业务实体 / 属性梳理 → 指标稽核规则制定
- 输出成果:指标标准库、业务实体清单、指标稽核规则库
| 工作项 |
输入 |
输出 |
工作方式 / 核心内容 |
| 业务场景识别及指标设计 |
业务需求文档、现有报表口径、业务部门访谈记录 |
业务指标清单、指标业务定义初稿 |
访谈业务部门,梳理核心业务场景,识别关键指标,统一指标业务含义与统计维度 |
| 指标数据标准库建设 |
业务指标清单、数据字典 |
指标数据标准库(含指标编码、口径、维度、频度) |
对指标进行标准化定义,统一指标编码、统计口径、计算逻辑、分析维度、统计频度 |
| 指标计算逻辑定义 |
指标数据标准库、业务实体 / 属性清单 |
指标计算规则文档、SQL / 算法逻辑初稿 |
基于业务实体与属性,明确指标的计算规则、关联数据来源、过滤条件、聚合方式 |
| 业务实体 / 属性梳理 |
指标计算逻辑、企业级数据字典 |
业务实体 - 属性关系清单 |
梳理支撑指标计算的核心业务实体,明确实体的关键属性、数据来源及依赖关系 |
| 指标稽核规则制定 |
指标计算逻辑、业务实体 / 属性清单 |
指标稽核规则库(含校验逻辑、异常阈值) |
定义指标数据的完整性、准确性、一致性校验规则,设置异常阈值与告警条件 |
2. 企业级数据字典:数据标准化的核心依据
- 核心目标:建立企业级统一数据语言,消除跨系统数据差异
- 关键工作:企业级数据字典设计 → 业务属性标准化 → 技术属性 / 英文简称标准化 → 编码 / 代码标准化
- 输出成果:企业级数据字典、业务 / 技术属性标准清单、公共代码标准库
| 工作项 |
输入 |
输出 |
工作方式 / 核心内容 |
| 企业级数据字典设计 |
指标数据标准库、现有系统字段清单、业务属性定义 |
企业级数据字典规范、数据字典主文档 |
统一数据字典的业务属性、技术属性、编码规则,建立字段级标准定义 |
| 业务属性标准化 |
企业级数据字典规范、业务实体 / 属性清单 |
业务属性标准清单 |
统一字段的业务含义、数据类型、取值范围、业务规则,消除跨系统口径差异 |
| 技术属性 / 英文简称标准化 |
企业级数据字典规范、源系统字段清单 |
技术属性标准清单(含字段英文名、数据类型、长度) |
统一字段的英文命名、数据类型、长度、精度,适配物理模型与 ETL 开发 |
| 编码 / 代码标准化 |
企业级数据字典规范、公共代码清单 |
公共代码标准库(如部门编码、状态编码) |
统一企业级公共编码、代码的取值规则,实现跨系统编码一致性 |
3. 企业级数据模型:数据治理的技术载体
- 核心目标:构建标准化、可复用的数据模型体系
- 关键工作:信息调研 → 企业级逻辑数据模型设计 → 物理模型设计 → ETL(数据落标)流程设计
- 输出成果:逻辑模型(ER 图)、物理模型(表结构)、ETL 流程设计文档
| 工作项 |
输入 |
输出 |
工作方式 / 核心内容 |
| 数据架构分层 / 定位 |
业务场景、数据规模、现有系统架构 |
数据架构分层方案(ODS/DWD/DWS/ADS 等) |
设计企业级数据仓库分层架构,明确各层定位、数据流转路径与边界 |
| 数据存储策略制定 |
数据架构分层方案、数据量预估、数据生命周期 |
数据存储策略文档(含分层存储、冷热数据管理) |
基于数据分层,制定数据存储介质、存储周期、归档策略、冷热数据分离方案 |
| 统一调度平台建设 |
数据存储策略、ETL 流程需求 |
统一调度平台方案、调度任务框架 |
搭建统一调度平台,实现 ETL 任务的定时调度、依赖管理、异常告警与监控 |
4. 数据架构:数据流转的基础支撑
- 核心目标:搭建分层、可控的数据流转与存储架构
- 关键工作:数据架构分层 / 定位 → 数据存储策略制定 → 统一调度平台建设
- 输出成果:数据架构分层方案、存储策略文档、统一调度平台框架
| 工作项 |
输入 |
输出 |
工作方式 / 核心内容 |
| 信息调研 |
业务需求、现有系统数据结构、数据字典 |
调研分析报告(含业务实体、数据分布) |
调研现有业务系统的数据结构、数据流转、实体关系,梳理建模基础信息 |
| 企业级逻辑数据模型设计 |
调研分析报告、数据字典、指标标准库 |
企业级逻辑数据模型(ER 图、实体关系) |
基于业务实体与指标需求,构建逻辑模型,定义实体、属性、关系与业务规则 |
| 物理模型设计 |
逻辑数据模型、数据存储策略、技术属性标准 |
物理数据模型(表结构、字段定义、索引设计) |
将逻辑模型转化为物理表结构,定义字段、数据类型、索引、分区、主键 / 外键 |
| ETL(数据落标)设计 |
物理模型、数据字典、编码标准 |
ETL 流程设计文档、数据落标脚本 |
基于物理模型与数据标准,设计数据抽取、转换、加载流程,实现数据标准化落标 |
5. 数据质量:数据可信的全链路保障
- 核心目标:实现数据全生命周期质量可控、可监测、可追溯
- 关键工作:可观测性监测 → 关键属性异常监测 → 维度数据异常监测 → 指标稽核规则监测
- 输出成果:数据质量监控看板、异常监测规则库、质量稽核报告
| 工作项 |
输入 |
输出 |
工作方式 / 核心内容 |
| 可观测性监测 |
统一调度平台、ETL 流程、数据落标结果 |
数据质量监控看板(含数据流转状态、运行日志) |
搭建数据质量监控体系,监测数据流转过程的状态、延迟、成功率等基础指标 |
| 关键属性异常监测 |
企业级数据字典、物理模型、业务属性标准 |
关键属性异常监测规则、告警配置 |
针对核心字段(如主键、外键、关键指标字段),监测空值、重复值、格式异常等问题 |
| 维度数据异常监测 |
维度数据标准、维度表、数据字典 |
维度数据异常监测规则、维度数据校验报告 |
监测维度数据的完整性、一致性、维值有效性,如维度缺失、维值不匹配、层级异常 |
| 指标稽核规则监测 |
指标稽核规则库、ETL 结果、统一调度平台 |
指标稽核监测报告、异常告警日志 |
基于指标稽核规则,对指标数据进行实时 / 离线校验,识别数据质量问题并触发告警 |
6. 数据安全:数据合规的全流程防护
- 核心目标:建立数据分类分级、访问控制与安全审计体系
- 关键工作:数据分类分级 → 存储加密 → 访问权限矩阵制定 → 敏感数据动态脱敏 → 日志审计
- 输出成果:数据分类分级标准、权限矩阵、脱敏规则库、安全审计方案
| 工作项 |
输入 |
输出 |
工作方式 / 核心内容 |
| 数据分类分级 |
业务需求、数据字典、敏感数据清单 |
数据分类分级标准、数据分级清单 |
对企业数据进行分类分级,明确公开数据、内部数据、敏感数据、核心数据的划分规则 |
| 存储加密 |
数据分类分级清单、物理模型、存储策略 |
数据存储加密方案、加密配置脚本 |
针对敏感数据,制定存储加密方案,实现静态数据加密存储,防止数据泄露 |
| 访问权限矩阵制定 |
数据分类分级清单、用户角色清单 |
数据访问权限矩阵、权限配置文档 |
基于数据分级与用户角色,定义数据访问权限,实现最小权限原则,控制数据访问范围 |
| 敏感数据动态脱敏 |
数据分类分级清单、ETL 流程、数据服务需求 |
动态脱敏规则库、脱敏配置脚本 |
针对对外输出的数据,制定动态脱敏规则,实现敏感数据在使用场景中的自动脱敏 |
| 日志审计 |
访问权限矩阵、数据访问日志、操作日志 |
数据安全审计报告、日志审计方案 |
采集数据访问、操作、变更日志,实现数据安全行为的全流程审计与追溯 |
7. 数据目录:数据资产的沉淀与价值释放
- 核心目标:实现数据资产的可发现、可理解、可追溯
- 关键工作:数据资产自动发现 → 数据资产自动分类 → 血缘 / 影响分析 → 数据资产分析
- 输出成果:数据资产目录、血缘图谱、资产分析报告
| 工作项 |
输入 |
输出 |
工作方式 / 核心内容 |
| 数据资产自动发现 |
物理模型、ETL 流程、统一调度平台 |
数据资产清单(表、字段、接口) |
基于数据源自动发现数据资产,识别数据表、字段、接口等数据对象,构建资产清单 |
| 数据资产自动分类 |
数据资产清单、数据字典、命名规则 / Schema |
数据资产分类目录、分类标签 |
基于数据字典与命名规则,对数据资产进行自动分类,建立主题域 / 业务域分类目录 |
| 血缘 / 影响分析 |
数据资产清单、ETL 流程、指标计算逻辑 |
数据血缘图谱、影响分析报告 |
构建数据血缘关系,追踪数据从源系统到指标的流转路径,支持变更影响分析 |
| 数据资产分析 |
数据资产目录、数据质量报告、访问日志 |
数据资产分析报告(含资产热度、使用情况) |
分析数据资产的使用情况、访问热度、质量状况,为数据资产优化与价值评估提供依据 |




 8
8 0
0


 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)