auto-sklearn:机器学习自动化的实用方案
auto-sklearn:机器学习自动化的实用方案
机器学习项目中,模型选择和参数调优往往是最耗时的一环。数据准备好之后,面对几十种算法和成百上千个参数组合,手动尝试一遍不太现实。自动化机器学习(AutoML)就是要解决这个问题,auto-sklearn 是这个方向上最成熟的开源方案之一。它可以作为 scikit-learn 的直接替代品,目前已获得 8100+ Star。项目由德国弗莱堡大学机器学习团队主导,学术背景扎实。
auto-sklearn 的核心思路是让工具替你完成算法选择、超参数优化和模型集成这些流程。用户只需要准备好训练数据和标签,调用 fit 方法,系统会在后台自动搜索最优的模型配置,整个过程不需要人工干预。
四行代码跑起来
使用 auto-sklearn 非常直接,导入模块、初始化分类器、训练、预测,四行代码就能完成:
import autosklearn.classification
cls = autosklearn.classification.AutoSklearnClassifier()
cls.fit(X_train, y_train)
predictions = cls.predict(X_test)
对已经熟悉 scikit-learn 的用户来说,这套接口几乎没有学习成本。回归任务同样支持,只需换成 autosklearn.regression.AutoSklearnRegressor。
安装方式
通过 pip 直接安装:
pip install auto-sklearn
不同操作系统对 SWIG 等依赖包的支持情况不同,建议查阅官方安装指南获取针对你环境的配置说明。
背后原理
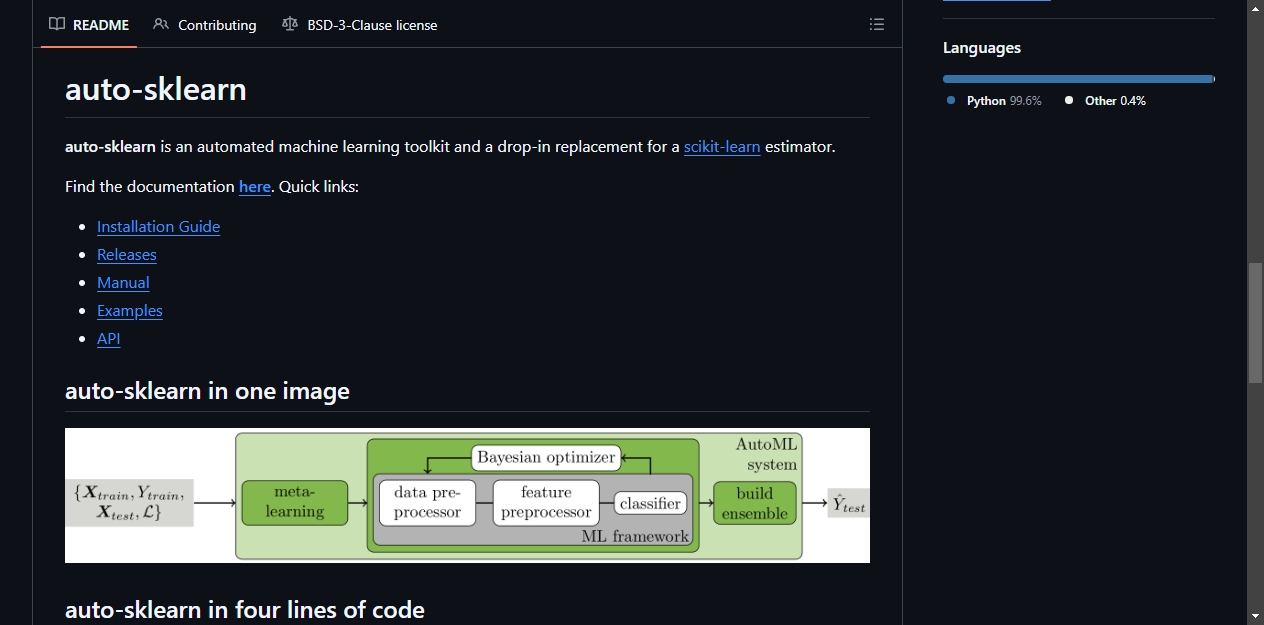
auto-sklearn 的效果来自三项关键技术的配合:
- 元学习:系统根据数据集的统计特征(如样本量、特征数、类别分布等),从历史任务中推荐过去表现最好的算法组合,有效缩小搜索范围。这一步让 auto-sklearn 不需要从头开始探索所有可能。
- 贝叶斯优化:在选定的算法空间内,用较少的评估次数找到合适的超参数配置。相比网格搜索逐一尝试所有组合,贝叶斯优化会参考之前的评估结果,把资源集中在有潜力的区域,效率高得多。
- 自动集成:训练结束后,选择多个表现优异的模型进行集成。集成模型的预测效果通常优于单个最佳模型,而且方差更小,结果更稳定。
这套方案在 NeurIPS 2015 上发表过论文,auto-sklearn 也是学术界和工业界认可度较高的 AutoML 方案之一。很多团队在构建机器学习管线时,会先用它跑出一个 baseline,再在这个基础上做精细化调整。
Auto-Sklearn 2.0
项目团队在 2020 年发布了 Auto-Sklearn 2.0,自动化程度进一步提升。新版本改进了元学习策略,用户几乎不需要手动设置搜索预算,系统会根据数据规模和可用时间自动调整搜索方式。对于非专业用户来说,这意味着更低的试错成本和更友好的使用体验。
适用场景
- 需要快速为分类或回归任务建立 baseline 模型,评估数据可用性
- 团队希望减少手动调参投入,把精力放在特征工程和业务理解上
- 非机器学习专家想在项目中引入预测能力,降低技术门槛
- 对 AutoML 技术感兴趣,想在自己数据集上验证效果的研究者
auto-sklearn 把自动化机器学习的能力封装在 sklearn 风格的接口里,从 scikit-learn 切换过来的成本很低。几行代码的改变,换来的是模型选择和参数调优环节的自动化。如果你的工作涉及分类或回归任务,可以把它加入工具箱试试。
行代码的改变,换来的是模型选择和参数调优环节的自动化。如果你的工作涉及分类或回归任务,可以把它加入工具箱试试。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)