为什么金融 Agent 没那么容易做出来:我们最近踩到的几个坑
最近我们一直在做一个金融 Agent 产品,内部叫 QFB。
先说结论:它还没有真正做出来。
如果把“做出来”定义成用户打开后能稳定完成分析、取数、回测、对比、报告、保存、分享、发布,那现在还差得很远。
但这段时间的推进也不是没有价值。相反,它让我们更清楚地看到一件事:
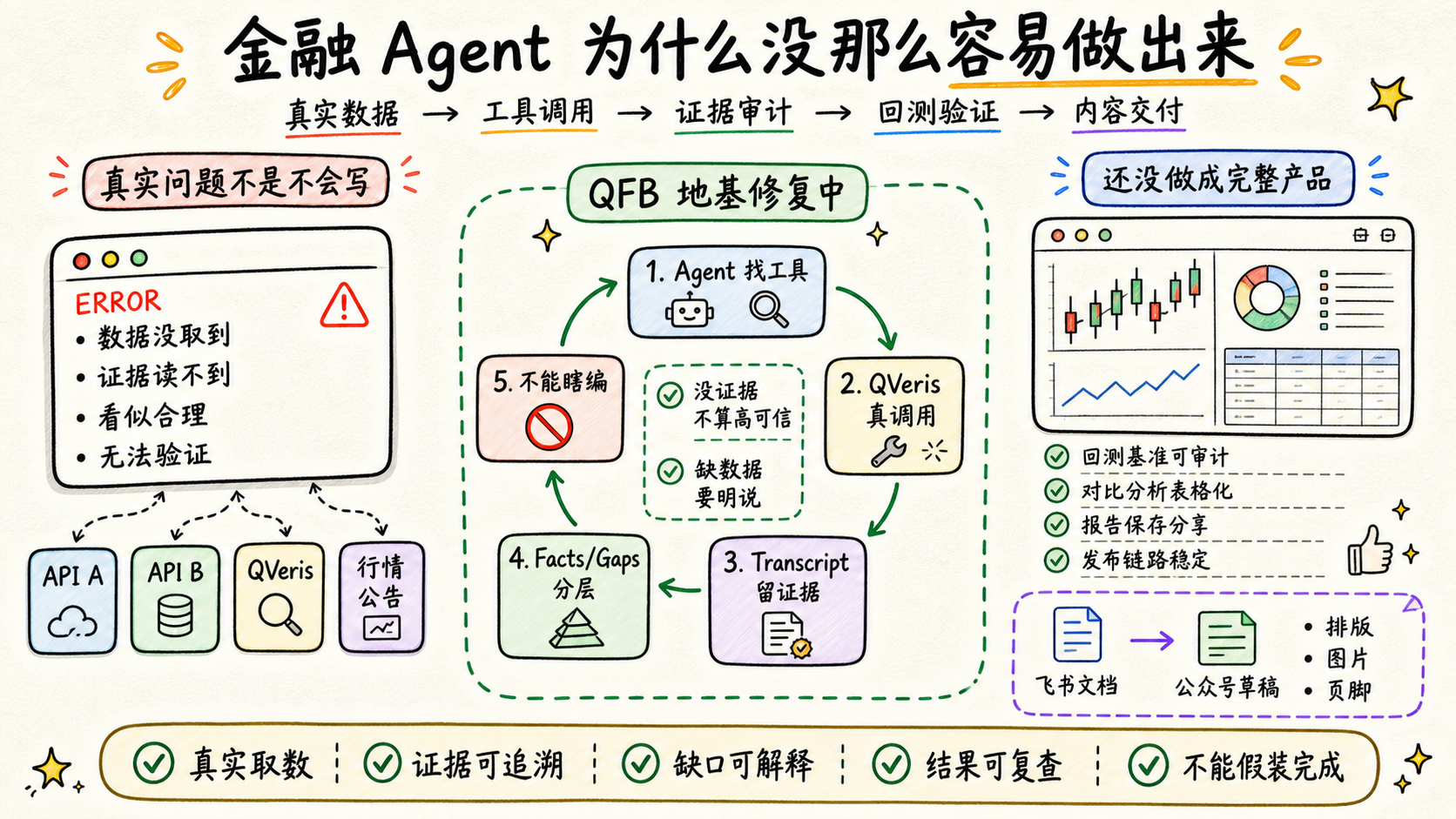
金融 Agent 难的不是让模型写一段分析,而是让它在真实数据、真实工具、真实用户预期下面,不乱说、不乱算、不乱承诺。
这篇文章不讲一个已经成功的产品故事。
它讲的是:为什么这个东西没那么容易做出来,以及我们最近到底在补哪些地基。
一、用户要的不是“AI 很会说”,而是“数据真的可靠”
我们最近看了一组 QVeris 订阅调研,66 份有效样本里有几个信号很明显。
79% 的用户是个人投资者。
他们现在已经在用很多工具:AKShare、东方财富、同花顺 iFinD、Tushare、万得、TradingView,还有一部分人有自建数据库。
也就是说,用户不是没有工具。
真正的问题是,这些工具很分散,数据接口、调用方式、覆盖范围、稳定性都不一样。用户想要的不是再多一个查询入口,而是一个能被 Agent 稳定调用的数据能力层。
调研里,用户最担心的是:
-
数据不够准
-
价格太高
-
数据不够全
-
调用不稳定
-
和现有工具相比优势不明显
还有一个很关键的信号:接近 60% 的用户已经尝试把 QVeris 接入自己的 Agent。
这说明,金融数据 API 的使用方式正在变化。
以前是人去查数据。
现在越来越多场景是 Agent 去找数据、选工具、调接口,再把结果组织成分析。
但这也带来一个新问题:Agent 一旦拿不到数据,很容易开始“猜”。
金融场景里,这件事很危险。
二、QFB 最大的问题,不是界面没做好,而是后端不能乱来
QFB 最近暴露出来的一个核心矛盾是:
我们希望它像产品一样稳定,但它背后其实是一组还在打磨的 Agent 工作流。
最容易偷懒的做法是:
Agent 没取到数据,后端直接调一次 QVeris 补上。
或者模型没拿到完整结果,就用经验写一段看似合理的分析。
这两种方式短期都能让 demo 好看一点。
但长期看,会直接破坏系统可信度。
所以我们后来把边界收紧:
QVeris 的真实调用,应该发生在 child agent 工作流里。
也就是 Agent 自己完成:
discover:找到可能可用的数据工具。
inspect:理解工具需要什么参数、返回什么结构。
call:真实调用 QVeris 拿结果。
后端不应该在 runner、coordinator 里偷偷直调 QVeris,更不应该在没证据的时候替 Agent 编一个结果。
后端真正该做的是:
-
编排任务
-
读取 transcript
-
审计 tool calls
-
归并 facts
-
标记 data gaps
-
计算 confidence
-
生成可复查的报告结构
这听起来像工程细节,但它其实决定了产品底线。
因为金融 Agent 必须能回答:
这个结论是不是有真实工具调用支撑?
如果没有,就不能包装成高可信分析。
三、我们一度连“有数据”和“没数据”都分不清
QFB 早期有一个很典型的问题:
QVeris 明明返回了真实数据,但系统显示可信度很低,甚至一堆红色缺口。
用户看到的第一感觉就是:不靠谱。
但深挖以后会发现,问题不一定是“没拿到数据”,而是后端验证层没有正确识别数据。
比如:
transcript 还没完全落盘,后端就开始读取。
tool result 的消息格式和验证代码预期不一致。
读取失败被误判成 Agent 没有调用工具。
于是系统把 facts 清空,把 confidence 打到很低。
这类问题非常要命。
因为它会把真实数据误判成无效数据,也会让用户低估系统能力。
后来我们修的不是“放宽可信度”,而是修验证逻辑本身:
要区分三件事:
Agent 确实没调用工具。
Agent 调了工具但数据缺失。
验证层读取失败,暂时无法确认。
这三种情况不能混在一起。
尤其是第三种,不能简单清空事实。更合理的做法是保留低可信信息,并明确标记“无法验证”。
这也是金融 Agent 和普通聊天机器人的区别。
普通聊天可以说“我认为”。
金融 Agent 必须说清楚“我凭什么认为”。
四、回测也不是跑出一条收益曲线就完了
回测是另一个坑。
用户要的不只是“策略收益 20%”这种结果。
他会继续问:
用的是哪段历史数据?
标的数据和基准数据是不是同一个区间?
频率是不是一致?
基准是谁?
如果基准没取到,策略结果还能不能看?
我们最近给 QFB 回测补基准对比时,也专门加了硬约束:
基准数据不能由后端直调 QVeris。
不能新增一个专门 subagent。
不能写死 AAPL 对 SPY 这种具体映射。
正确做法是:后端只根据市场段推断默认基准,把 benchmarkSymbol 写入任务输入;然后复用已有 market_agent,让它多取一组基准 K 线。
如果取不到,就写 data_gap。
不能用标的数据冒充基准。
不能因为基准缺失就把核心回测判死。
更重要的是,回测结果要说明“用了什么数据”:
-
标的 symbol
-
基准 symbol
-
K 线数量
-
日期范围
-
频率
-
数据来源路径
否则用户看到的只是一条漂亮曲线,但没法判断它是不是可信。
这也是为什么 QFB 还不能说已经做好。
现在只是把一部分回测链路变得更可审计,还没到完整产品体验。
五、对比分析不能只散在自然语言里
“比较 AAPL 和 MSFT”这种需求,看起来很简单。
模型很容易写:
苹果硬件收入占比更高,微软云业务更强,估值结构不同。
这段话可能没错,但产品化还不够。
真正的对比报告应该是同维度并列表:
-
现价
-
涨跌幅
-
RSI / MACD
-
PE / PB
-
新闻情绪
-
关键风险
每一个格子都应该尽量带 evidence_refs。
某个标的某个维度缺数据,就留空,并写入 data_gaps。
不能用主标的数据补对比标的。
不能用新闻情绪替代估值数据。
不能让 Agent 自由文本里“看起来提到了”就算完成对比。
所以我们最近补 comparison section,本质不是为了多一个 UI 表格,而是为了让对比分析从“散文”变成“结构化报告”。
这件事也还没完全做完。
但方向是对的:金融 Agent 不能只输出一段流畅文字,它要把关键维度结构化,让用户能复查。
六、公众号发布链路反而更快进入了可用状态
和 QFB 相比,公众号发布链路更像一个已经能跑起来的生产工具。
群里最近反复在做这些事:
把飞书文档转成公众号草稿。
处理飞书图片,下载后上传到微信素材库。
自动生成封面。
自动追加 QVeris AI 页脚和二维码。
修微信公众号编辑器里的首行缩进。
统一正文字号到 16px。
去掉图片边框。
让标题、段落、列表、引用左对齐。
这条链路的特点是目标很清楚:把一篇飞书文档稳定变成公众号草稿。
问题也更具体:缩进、字号、图片、封面、页脚、草稿箱。
所以它比 QFB 更容易闭环。
但它也提醒我们一个现实:
一个 Agent 产品如果要进入真实工作流,最后一定要碰到“交付”。
不是模型回答完就结束。
而是文档能不能保存,文章能不能发布,结果能不能复查,格式能不能稳定。
公众号链路解决的是内容交付。
QFB 还在解决的是金融分析的可信地基。
两者难度不是一个量级。
七、为什么我不想把 QFB 写成“已经成功”
因为这会误导。
QFB 现在做了一些重要工作:
-
后端开始收紧 QVeris 调用边界
-
transcript / tool call 验证在加固
-
facts、gaps、confidence 开始分层
-
回测开始补基准对比和数据摘要
-
对比分析开始结构化
-
Chat 入口开始避免把金融命令丢给普通 LLM
-
公众号发布链路逐渐稳定
但这些加起来,不等于“QFB 已经做出来了”。
它更准确的状态是:
一个金融 Agent 产品的地基正在被补齐。
很多 demo 里可以糊过去的问题,在这里都必须正面解决。
比如:
数据没取到怎么办?
工具调用失败怎么办?
验证层读不到 transcript 怎么办?
LLM 生成了漂亮但没证据的话怎么办?
用户要回测基准,但基准数据缺失怎么办?
用户要对比多个标的,但每个标的数据维度不齐怎么办?
这些问题解决之前,不能说产品已经完成。
八、我们现在更相信一种慢一点的路线
快的路线是:让模型直接写答案。
慢一点的路线是:让 Agent 先找数据源,再调用工具,再留下证据,再生成报告。
更慢一点的路线是:把回测、对比、缺口、可信度、发布链路都做成可复查的结构。
但金融场景里,慢一点是值得的。
用户不缺一段看起来聪明的分析。
用户缺的是一个能稳定接入真实数据、能承认数据缺口、能保留证据、能复查过程、能交付结果的系统。
QFB 还没做出来。
但最近这些坑至少说明了:如果一个金融 Agent 真要做出来,它不能只会聊天。
它必须学会取证。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)