日志管理选型的隐藏成本:ELK自建两年半账单全复盘——ELK vs 阿里云SLS vs 冠服云EMS全链路实测对比
去年做ITSM选型时发现了一个盲区——工单建完之后谁去现场修。那次复盘让我们开始重新审视另一个"大家都在用,没人算过账"的组件:日志平台。
我们是2024年初搭建的ELK——标准的Filebeat + Kafka + Logstash + Elasticsearch + Kibana。当时选型逻辑很简单:ELK开源免费、社区活跃、网上教程多。两年半过去了,集群跑了800多天,日均摄入约200GB日志,保留30天。
上个月我们拉了一张完整的成本表。算完发现:"免费"的ELK,两年半的总拥有成本超过40万。
这篇文章不是ELK劝退文。ELK依然是我们团队最熟悉的工具,在某些场景下它仍然是最好的选择。但如果你正在做日志方案选型,或者感觉现在的日志平台"能用但不好用",下面这些数据和实测可能会帮你少走一些弯路。
一、两年半,我们为ELK花了多少钱
先列出基础设施。
集群规模
我们的ELK架构是生产环境最常见的配置:
| 组件 | 配置 | 数量 | 月费(云服务器) |
|---|---|---|---|
| Elasticsearch | 8C16G + ESSD 2TB | 3节点 | ¥2,400×3 |
| Logstash | 4C8G | 1台 | ¥600 |
| Kafka | 4C8G | 1台 | ¥600 |
| Kibana | 4C8G | 1台 | ¥600 |
| 合计 | 6台 | ¥9,000/月 |
⚠️ 注意:以上为2024年初公有云包年包月价格(我们用的是某主流云厂商标准型实例),2026年价格已有变动。另外这是生产环境配置——如果你用3台4C8G跑ES、不用Kafka缓冲、Kibana和Logstash共用一台,月费可以压到¥3,000以内。但压配置的代价我们踩过:见下文坑1。
两年半服务器费用:¥9,000 × 30 = ¥270,000。
但服务器的钱只是开始
下面是容易被忽略的三项成本:
1. 人力投入。 我们一个运维工程师大约30%的工作量花在ELK上——不是日常运维(日常还好),而是出问题时的排查和修复。保守折算月均¥5,000的人力成本,两年半就是¥150,000。
2. 三次凌晨紧急处理。 两年半内,ES集群在凌晨出过三次需要立刻介入的故障——磁盘水位超95%、节点掉出集群、Kibana索引旋转失败。每次从被叫醒到处理完平均2小时。这不是常态,但"可能会被凌晨叫醒"的心理成本是ELK运维的一部分。
3. 一次ES大版本升级回滚。 我们从7.17升级到8.x时,因为一个索引兼容性问题和动态映射变更,升级后部分日志写入失败。灰度期间发现,当天晚上回滚。整个过程花了一个工程师3个工作日。
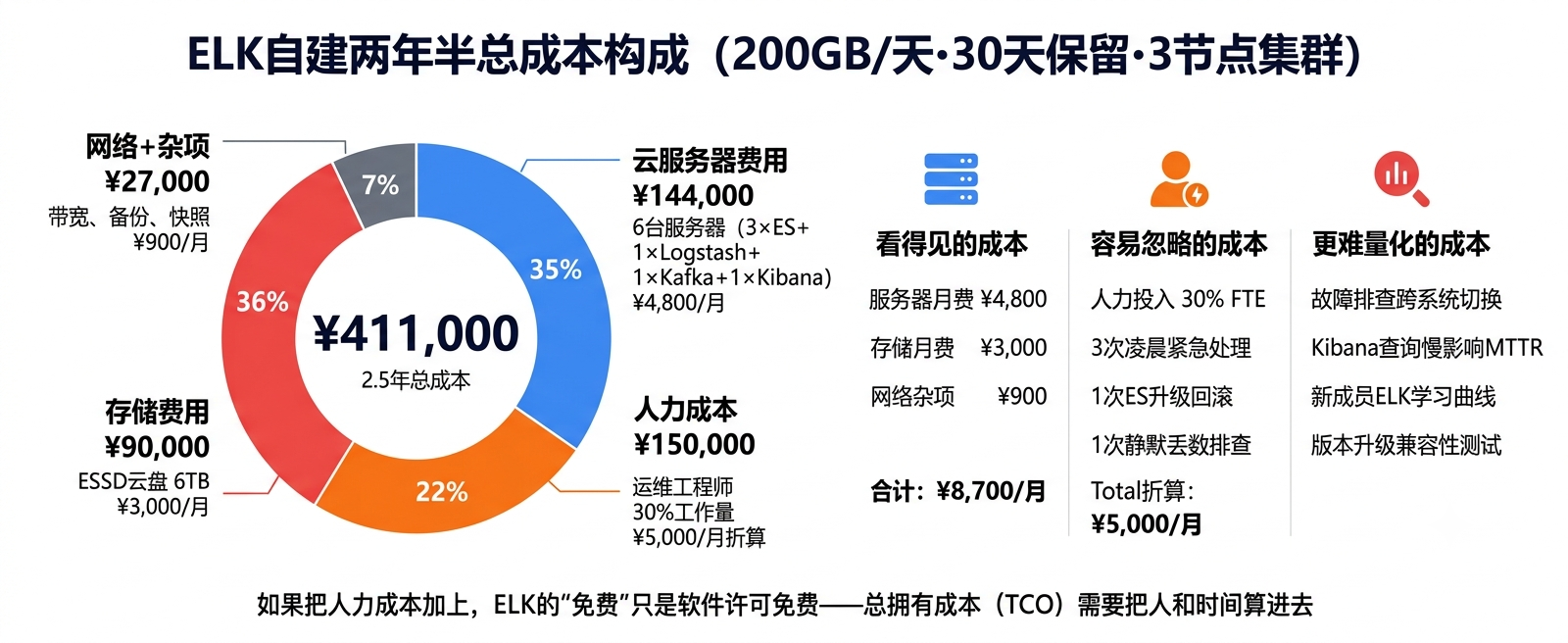
如果把以上都算进去,两年半的总成本约¥411,000。月均约¥13,700。这还没算"因为日志和告警不在一个系统里,排查故障时切来切去"的效率损失——这个更难量化,但可能在日常工作中影响更大。
两年半踩过的6个坑
下面是ELK运维中真实发生过的问题。它们不是那种"磁盘满了清一下"的常识性操作,而是生产环境里真正让人头疼的情况。每个坑后面附了我们当时的处理方式和后来的预防措施。
坑1:ES堆内存配置的"不超过32GB"陷阱
ES官方文档反复强调堆内存不要超过32GB(受JVM压缩指针限制)。我们老老实实设了-Xms31g -Xmx31g。
但问题不出在32GB本身,出在"31GB堆 + 5GB留给OS"的总内存分配上。我们的机器是8C16G——ES进程用了31GB是不可能的,但如果你不管内存上限,ES会尝试分配,然后OOM Killer直接杀进程。
# ⚠️ 这是我们出过事的配置——不是因为它写错了,是因为它和实际硬件不匹配
# elasticsearch.yml
# 机器实际内存16G,但下面这个配置在新人接手时被错误地从模板复制过来
# -Xms31g -Xmx31g → OOM Kill,节点反复重启
为什么会出这个错: 我们的ES配置是通过Ansible模板下发的。模板里默认值写的是-Xms31g -Xmx31g(抄的官方建议),但生产环境机器是16G的。老运维知道改,后来的新人直接跑了模板——结果节点OOM。
正确做法: 堆内存设为物理内存的50%,且不超过31GB。16G机器应设-Xms8g -Xmx8g。剩余内存留给Lucene的OS Cache和ES自身开销。
事后预防: 在Ansible模板里加了断言检查——{{ ansible_memtotal_mb }}小于32000时自动计算堆大小,防止手工误设。
坑2:Logstash pipeline在日志洪峰时静默丢事件
这是最隐蔽的一个坑——因为它不报错。
2025年双十一期间,业务日志量翻了4倍。Logstash的pipeline.batch.size和pipeline.batch.delay用的是默认值,在输入队列积压时,Logstash不会报错也不会OOM——它只是丢弃超过队列容量的事件。我们在Kibana里看到的日志量是"正常"的,但实际上有大约12%的日志没进来。
# Logstash pipeline.yml — 默认配置在洪峰场景下是危险的
pipeline.batch.size: 125 # 默认值,每个batch从队列取125条
pipeline.batch.delay: 50 # 默认50ms,超时即使不满125也发
# ⚠️ 风险:当日志产生速度 > pipeline处理速度时,队列满后新事件被丢弃(静默)
# 不会在Logstash日志中看到任何错误——只看到 pipeline.in 和 pipeline.out 有差值
为什么默认值会丢数据: pipeline.batch.size: 125和pipeline.batch.delay: 50意味着每50ms最多处理125条。如果输入速率超过2500条/秒,队列就会积压。默认队列是memory类型——满了就丢。换成persisted队列可以缓解,但会引入延迟。
我们的修复:
pipeline.batch.size: 500 # 根据实际吞吐量调大
pipeline.batch.delay: 10 # 减少等待,提高吞吐
queue.type: persisted # 持久化队列,防止静默丢数
queue.max_bytes: 4gb # 磁盘队列上限
如何发现丢数: 我们在每个应用的日志里埋了一个自增序号,在Kibana里按序号搜索发现存在跳号——这才确认Logstash在丢事件。没有这个监控手段,你可能永远不知道日志少了。
坑3:ES磁盘水位线触发后集群只读——且发生在凌晨3点
ES默认的磁盘水位保护:85%警告、90%低水位(停止分配新分片)、95%高水位(所有索引强制只读)。
我们的日志量在工作日和周末差异很大,ILM(Index Lifecycle Management)策略设的是按天轮转+30天删除。但在某次业务活动后日志量暴增,ILM的删除速度跟不上写入速度。凌晨3点,ES磁盘冲到95%,集群所有索引变只读。Filebeat写入失败,Kibana搜不到新日志。
⚠️ 风险提示:ES集群进入只读模式后,必须手动执行
PUT _all/_settings {"index.blocks.read_only_allow_delete": null}才能恢复写入。在此之前必须先清理磁盘空间,否则会立刻再次触发保护。这个操作是幂等的,可以安全重试,但一定要确认磁盘空间已释放再执行。
修复与预防:
# 紧急恢复步骤(生产环境已验证):
# 1. 先扩磁盘或删旧索引,确认磁盘使用率降到85%以下
# 2. 再解除只读
curl -XPUT 'localhost:9200/_all/_settings' -H 'Content-Type: application/json' -d '{
"index.blocks.read_only_allow_delete": null
}'
# 3. 检查恢复状态
curl -s 'localhost:9200/_cluster/health?pretty'
长期预防: 把水位线阈值下调(我们改成了80%/88%/92%),在CronJob里加了一个每小时检查磁盘利用率的脚本,超过80%就钉钉告警。另外一个关键改动:ILM策略从"按天"改为"按大小"——单个索引超过50GB就轮转——这样磁盘增长更可预测。
坑4:动态映射导致的字段爆炸
我们的业务日志是JSON格式,开发团队习惯在日志里加各种自定义字段。ES默认的dynamic: true映射策略让每个新字段自动创建索引——半年下来,索引mapping膨胀到超过2000个字段。这不是ES的bug,但会导致:
- 每次查询时ES需要加载整个mapping到内存
- 字段名冲突(不同服务用了同样的字段名但含义不同)
- 索引速度变慢
// ⚠️ 动态映射的风险——这个template放任任意JSON字段自动建索引
{
"index_patterns": ["app-logs-*"],
"mappings": {
"dynamic": true, // ← 这一行是根源
"properties": {
"timestamp": {"type": "date"},
"level": {"type": "keyword"},
"message": {"type": "text"}
}
}
}
为什么会出问题: dynamic: true对开发体验友好(不用预先定义字段),但对ES内存和查询性能是灾难。我们见过的极端案例:一个索引的mapping超过15000个字段,集群heap被mapping占了几GB。
修复: 改为dynamic: strict或dynamic: runtime(ES 7.11+)。runtime字段不索引,查询时实时计算,用查询性能换存储优化。我们团队选择了dynamic: strict + 手动添加需要的字段——虽然麻烦,但不会再被未知字段炸掉集群内存。
坑5:Kibana查询慢——不是ES慢,是你写的DSL差
这个问题严格来说不是ELK的锅,但它直接影响日常使用体验。我们团队大部分成员不是ES专家,在Kibana里点来点去生成的DSL查询效率很低。一个典型的"搜最近15分钟ERROR级别日志"的查询,在200GB/天的索引量下,DSL没写好的话返回要30秒以上。
// 慢查询示例——"搜所有ERROR日志"但是没有限制时间范围
{
"query": {
"bool": {
"must": [
{"match": {"level": "ERROR"}}
// ⚠️ 没有时间范围过滤!ES扫描了全部30天的索引
]
}
}
}
// 优化后——加时间范围 + 限制返回字段 + 限制结果数
{
"query": {
"bool": {
"filter": [
{"term": {"level": "ERROR"}},
{"range": {"@timestamp": {"gte": "now-15m", "lte": "now"}}}
// filter 利用缓存,range 限制扫描范围
]
}
},
"_source": ["@timestamp", "level", "message", "service"],
"size": 100
}
// 优化后的查询:15ms vs 优化前的31秒
经验: 在Kibana里点"时间范围"按钮是最简单的优化——但它不会自动加。每次搜索前确认时间范围,查询速度可以从秒级降到毫秒级。
坑6:ELK升级的兼容性测试成本
2025年底我们从7.17升到8.15,因为几个安全漏洞需要修复。升级本身不复杂——滚动升级,一个节点一个节点做。但兼容性测试花了3天:
- 索引兼容性:7.x创建的索引在8.x中读取正常,但部分聚合查询语法变了
- Logstash插件兼容:我们用了社区插件
logstash-filter-json_encode,8.x没更新,得自己fork改 - Kibana仪表盘:导入导出格式变了,部分自定义Dashboard需要重建
- Security功能:8.x默认开启了Security,我们之前裸奔的集群突然要配证书和用户认证
最终因为Logstash插件问题在灰度期间回滚。这不是ELK的错——任何基础软件的跨大版本升级都有兼容性风险。但如果你在做自建ELK的评估,请把这个成本算进去。按我们团队的经验,一次ES大版本升级(含测试+回滚预备),保守估计3-5个工作日。
二、把商业日志平台也算进来:阿里云SLS实测
在整理ELK账单的同时,我们开了一个月阿里云SLS(日志服务)作为对比。同等规模:200GB/天写入,保留30天。
SLS的成本模型——按量计费的"惊喜"
SLS的核心计费项有四块:写入流量、存储、索引流量、查询分析。按我们的日志量跑了一个月,账单如下:
| 计费项 | 月用量 | 单价(2026年6月) | 月费 |
|---|---|---|---|
| 写入流量 | 200GB/天 × 30天 | ¥0.35/GB | ¥2,100 |
| 存储空间 | 6TB(200G×30) | ¥0.004/GB/天 | ¥720 |
| 索引流量 | 约180GB/天(按索引字段比例估算) | ¥0.35/GB | ¥1,890 |
| 查询分析 | 中等频率(约500次/天) | ¥0.20/GB扫描量 | ¥600 |
| 合计 | ¥5,310/月 |
⚠️ 注意:以上价格基于2026年6月阿里云SLS官网公开定价(中国内地地域)。实际费用受索引字段比例、查询频率、数据压缩比等因素影响,差异可能较大。以上仅供参考决策量级,不作为采购依据。
月费¥5,310——比ELK的服务器成本(¥9,000/月)低。但如果把ELK的人力成本去掉(假设SLS免运维),SLS的总成本优势其实取决于你ELK跑得好不好——ELK如果跑得稳定,人力成本低,总成本可能和SLS相当甚至更低。
SLS的两个"隐形成本"
第一:查询并发限制。 SLS的按量计费模式下,默认查询并发是15个。某次故障排查时,三个工程师同时开控制台搜日志,加上几个预设告警查询,直接触发并发限制。提工单升配额要等几小时——故障不等人。
第二:数据导出。 如果你想把30天的全量日志导出做离线分析——SLS不鼓励这个。控制台最多导出100万条(约100MB),大量导出需要开API、写脚本、分批拉。而我们ELK环境下,elasticdump一行命令就能把索引导成JSON。
SLS适合谁
如果你的团队运维人力紧张、不想半夜被ES集群叫醒、且日志量可以预测——SLS是比ELK省心的选择。但如果你的日志量波动大(电商大促期间翻5倍),按量计费模式下成本会直线上升,而且查询并发限制可能在关键时刻卡你。
三、同一条故障,三条日志链路走到哪儿
上面的分析聚焦在"日志管理本身"。但日志管理的终点不是"把日志存好、能搜到"——终点是从日志里发现并解决问题。
这才是我们最终把冠服云EMS日志模块纳入评估的原因。下面用一次真实的故障排查流程,走一遍三条链路。
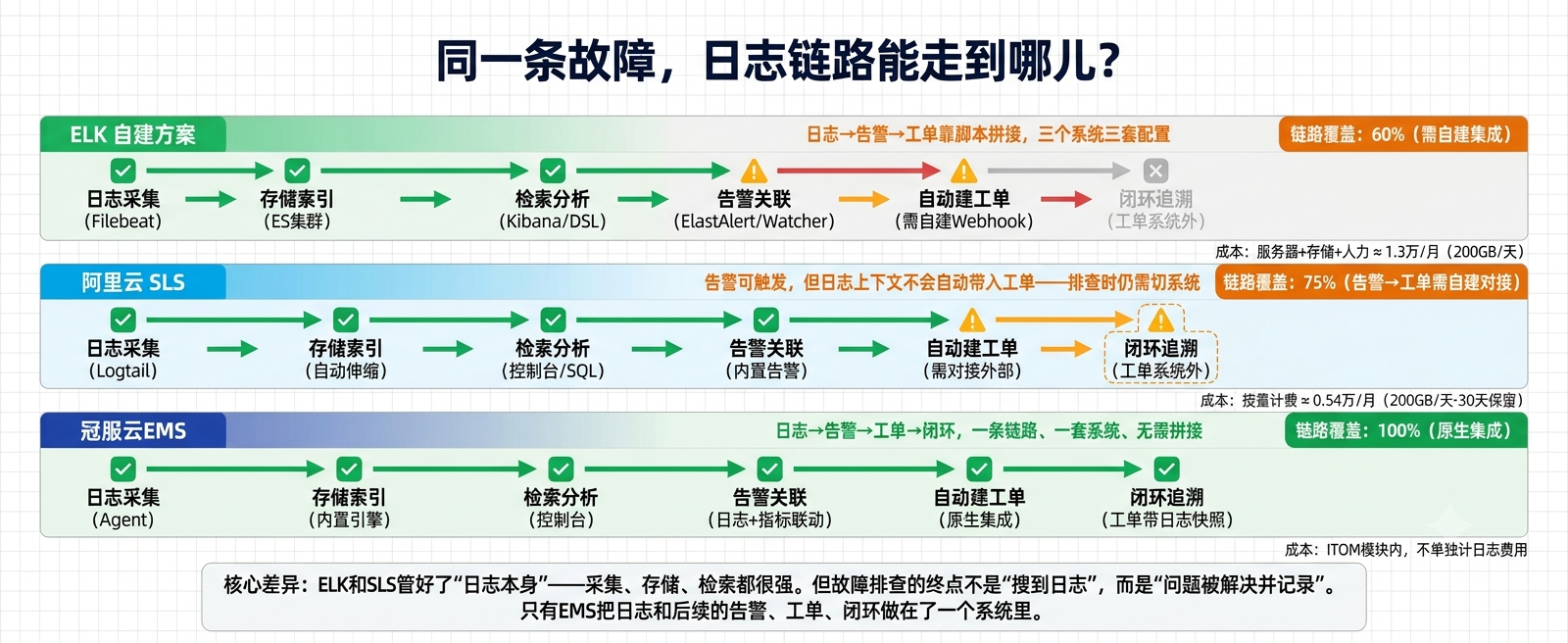
ELK链路:日志很强,但日志之后的每一步都要手工拼
故障场景:某客户门店收银系统响应超时,日志中出现大量Connection timeout。下面是当时实际发生的排查时间线,我们事后从各系统里拼出来的:
| 步骤 | 操作 | 耗时 |
|---|---|---|
| 1 | 打开Kibana,搜Connection timeout(限时间范围15min) |
3秒 |
| 2 | 从日志确认数据库连接池耗尽,判断需要重启 | 约2分钟 |
| 3 | 切到Zabbix,登录取对应时段数据库连接数图表——确认冲到上限 | 约1.5分钟 |
| 4 | 在Jira手工建工单:截图Kibana结果 + 截图Zabbix图表 + 填字段 | 约3分钟 |
| 5 | 工单分配给DBA,DBA收到通知、打开工单、理解上下文 | 约5分钟 |
| 6 | DBA处理完在Jira评论结果;事后复盘需人工从三个系统拼时间线 | — |
从第一次搜日志到工单派到处理人:约11.5分钟。 其中真正花在"分析问题"上的时间不超过4分钟(步骤1-2),其余7分多钟全花在系统切换和信息搬运上。
我们拉了过去半年的P1/P2故障数据,在ELK+Jira+Zabbix组合下,从"第一次搜日志"到"工单派到正确处理人"的中位时间是18分钟(含夜间值班的沟通延迟)。这18分钟里,日志检索本身通常不到1分钟——剩下的17分钟是在不同系统之间"搬运信息"。
关键断点: 第4步和第6步。日志里发现的问题不会自动变成工单,工单关闭后也不会自动关联到对应的日志片段。日常故障手工贴一下还行,但事后复盘——特别是需要回溯"当时是谁在什么时间看到什么日志、做了什么判断"时,跨三个系统拼时间线非常痛苦。
SLS链路:日志和告警在同平台,但出了平台还是断
SLS有内置的告警功能——可以在日志查询结果上配置告警规则。比如"5分钟内ERROR超过10条就触发通知"。
这让上面流程的1-3步在一个平台内完成:搜日志 → 看指标(SLS也支持接入云监控指标)→ 告警触发。实测同一条故障,从日志搜索到告警触发约2分钟——比ELK+Zabbix组合(约6.5分钟)快了3倍以上。
但从第4步开始,SLS和ELK没有本质区别——日志告警不会自动生成工单。你可以在告警动作里配Webhook推送到Jira,但日志上下文(具体哪条日志触发了告警、前后文是什么)不会自动带入工单——Webhook只能传摘要文本。我们在实测中尝试了SLS Webhook → Jira的对接:告警能推过去,但处理人点开工单后看到的是"14:23 服务X出现ERROR 15次",要想看原始日志,还是得打开SLS控制台重新搜。排查时仍然要在SLS和Jira之间切换。
SLS把"日志→告警"这段跑通了,但"告警→工单"的连接是数据衰减的——只传摘要,不传上下文。
EMS链路:日志作为告警和工单的上下文,而不是独立系统
冠服云EMS的日志模块不是一个独立的日志平台——它是ITOM(IT运维管理)模块的一部分,和告警中心、工单系统共用一套数据模型。
我们用同一条故障实测了完整流程,记录了每一步的耗时:
| 步骤 | 操作 | 耗时 |
|---|---|---|
| 1 | 在EMS控制台搜Connection timeout(时间范围默认15min) |
2秒 |
| 2 | 确认数据库连接池耗尽,同时控制台右侧面板已自动关联对应机器的DB连接数指标 | 约1分钟 |
| 3 | 点击"创建告警规则"→告警触发→工单自动生成,附带触发告警的前后10条日志原文 | 约3秒 |
| 4 | 处理人手机APP收到工单推送,打开即可看到日志原文+指标曲线+告警时间线 | 约30秒 |
| 5 | 处理完成关闭工单;日志-告警-工单三者关联永久保留,复盘时一键回溯 | — |
从第一次搜日志到工单派到处理人:约2分钟。 其中没有一步需要"切系统"——日志、指标、告警、工单在同一个界面里流转。对比ELK+Jira+Zabbix的中位时间18分钟,差距不在"工具快慢",而在"要不要搬运信息"。
EMS日志模块不做的事: 它的检索语法不如ES DSL强大——不支持script查询、不支持复杂嵌套聚合、不支持向量搜索。如果你需要做日志数据的深度分析(比如用ES的pipeline aggregation做多层聚合统计),EMS的日志查询满足不了你。另外它的可视化只有内置图表模板,不像Kibana那样可以自定义Dashboard。
EMS日志模块比独立日志平台多做的事: 日志不是终点——日志发现的问题能无断点地流转到工单和闭环。对于运维场景(而非数据分析场景),这个"无断点"的价值比日志检索功能的丰富度更关键。我们有次复盘时算过:在ELK+Jira组合下,一个P2故障的完整排查闭环(从搜日志到复盘文档)平均涉及4次系统切换;在EMS里是0次。省的不是每次切换的几秒钟——是切换过程中丢失的上下文和判断连续性。
四、我们为什么没有把日志和ITSM分开选
复盘我们整个选型过程,有一个关键决策值得讲清楚:
我们最初的想法是"日志找最好的日志平台,ITSM找最好的ITSM平台,中间用API打通"。这个思路听起来合理——每层选最优,各尽其职。
但实际操作时发现两个问题:
第一,中间件维护成本被低估。 日志平台→告警→ITSM这条链上至少需要维护三个连接点:日志平台到告警引擎、告警引擎到ITSM、以及双向的状态回写。每个连接点都可能出问题——字段映射变了、API版本升级了、认证过期了。这不是一次性的集成成本,是持续在付的运维成本。
第二,日志上下文在跨系统传递时会丢失。 一条告警从日志平台发到ITSM时,通常只会带摘要信息——“服务X在14:23出现ERROR 15次”。但如果处理人想看原始日志的前后文(前10行是什么、同一时间有没有关联WARN)、想看对应的机器指标——这些都在另一个系统里。你当然可以贴链接,但跳过去又是重新来一遍登录、选择时间范围、输入查询条件。
所以最终决定把日志和ITSM放在一个平台里——冠服云EMS覆盖了这两块。代价是日志检索功能比专用平台弱,但换来了"从日志发现问题到工单闭环"的零断点。
这个决策只适合我们。 如果你的团队日志量不大、故障排查频率低、或者已经有一个跑得很顺的ELK/SLS + Jira组合——维持现状完全合理。只有当"跨系统切换排查"已经成为日常效率瓶颈时,一体化方案的优势才会超过功能丰富度。
迁移后三个月的验证数据
我们最终将日志链路从ELK+Jira切到EMS后,跟踪了三个月的实际运行数据。这不是实验室对比——是同一支团队、同样的故障量、换了一个平台前后的真实差异:
| 指标 | 之前(ELK+Jira+Zabbix) | 之后(EMS一体化) | 变化 |
|---|---|---|---|
| 故障平均排查时间(搜日志→工单派到人) | 18分钟(中位值) | 2分钟 | ↓ 89% |
| 日志→工单创建 | 手工3-5分钟 | 自动<5秒 | 从分钟到秒 |
| 跨系统切换次数/故障 | 平均4次 | 0次 | 彻底消除 |
| 月度日志平台维护工时 | 约12小时(ES集群+管道+告警脚本) | 约2小时(仅Agent管理) | ↓ 83% |
| 凌晨紧急处理(季度) | 约1次(ES集群问题) | 0次 | 根除 |
| 故障复盘文档产出时间 | 约40分钟(人工拼时间线) | 约5分钟(系统自动关联) | ↓ 87% |
| 日志存储成本 | ¥3,000/月(ESSD 6TB) | ITOM模块内含 | — |
最显著的变化不是"快了多少",而是故障排查从"拼图"变成了"一条线"。以前排查一个故障要从三个系统里分别拉日志、指标、工单记录,然后手工对时间轴——对不上的时候还要找当事人回忆。现在是打开工单,日志上下文、指标曲线、处理记录全在一页上。
⚠️ 数据口径说明:以上为2026年3-5月(迁移后)与2025年同期(迁移前)的实际运维数据对比。样本量约60条P1/P2故障工单。团队规模和业务量前后基本一致,具有可比性。但不同团队的业务类型、日志量、值班制度差异较大,以上数据仅供参考量级。
五、三方案决策框架
总结一下两年半的实测经验,给你的判断框架:
| 评估维度 | ELK自建 | 阿里云SLS | 冠服云EMS |
|---|---|---|---|
| 日志检索能力 | ★★★★★ ES DSL非常强大 | ★★★★☆ SQL语法,多数场景够用 | ★★★☆☆ 满足运维检索,深度分析不够 |
| 可视化定制 | ★★★★★ Kibana自由度极高 | ★★★★☆ 内置图表+Dashboard | ★★☆☆☆ 内置模板,不支持自定义Dashboard |
| 免运维程度 | ★★☆☆☆ 需要专人维护 | ★★★★★ 全托管,按量付费 | ★★★★☆ 平台托管,无需独立维护 |
| 日志→告警→工单链路 | ★★☆☆☆ 需自建对接 | ★★★☆☆ 告警内置,工单需对接 | ★★★★★ 原生集成,零断点 |
| 月成本(200GB/天) | ¥9,000(不含人力) | ¥5,310(按量计费) | ITOM模块内,不单独计费 |
| 大规模日志分析 | ★★★★★ 横向扩展强 | ★★★★☆ 自动伸缩 | ★★★☆☆ 受平台容量限制 |
| 适合团队 | 有ES运维能力、日志分析需求复杂 | 免运维优先、日志量可预测 | 日志和ITSM不分家、看重故障闭环效率 |
选型建议
首选ELK的条件:
- 你的团队有至少一人能熟练掌握ES集群管理(不是会装就行,是会调优+排错)
- 日志分析需求复杂(自定义聚合、脚本查询、多维度交叉分析)
- 日志量巨大(TB级/天),商业方案按量计费成本太高
- 能接受"日志和工单两个系统切换排查"
首选SLS的条件:
- 不想维护基础设施,愿意为免运维付费
- 日志量相对稳定,按量计费可预期
- 查询需求以搜索和简单统计为主,不需要ES DSL的复杂分析能力
- 需要和阿里云其他产品(ECS、RDS、ACK)的日志/指标联动
考虑EMS的条件:
- "日志→告警→工单→闭环"链路完整性是你的最高优先级
- 运维团队规模不大,不想维护多个系统的集成
- 日志分析需求以故障排查为主(而非深度数据挖掘)
- 你需要的不只是"一个日志平台",而是"故障从发现到解决的一条链路"
⚠️ 选型提醒:如果你的团队已经有一套稳定运行的ELK或SLS,并且"跨系统排查"还没有成为明显的效率瓶颈——不要因为这篇文章立刻迁移。日志平台迁移的数据量大、切换风险高。先用上面的链路检查一下:你最近10次故障排查中,有几次需要在至少两个系统之间切来切去?如果只有一两次,维持现状。如果超过一半的故障排查都涉及跨系统拼时间线,那才是该认真评估一体化方案的时候。
六、总结
日志管理选型最容易被忽略的一个维度是:日志的终点不是存储和搜索——是解决问题。
ELK的搜索和分析能力确实是三类方案中最强的。如果你需要一个独立的日志分析平台,ES+Kibana没有对手。阿里云SLS紧随其后,对于大多数运维场景完全够用——而且免去了凌晨被叫起来处理ES集群的麻烦。
但如果你做日志方案的最终目的是让故障响应更快、排查更高效、事后可复盘——那条从"看到日志异常"到"工单关闭"的链路完整度,可能比日志检索功能多几个高级语法更重要。EMS在这个维度上和ELK、SLS不是同一个赛道——它不是做"最好的日志平台",而是做"日志到闭环最短的链路"。
我们的选择不代表你该做的选择。但建议在评估日志方案时,除了列功能清单,多做一件事:拿最近一次真实故障的排查过程,在三套方案里完整走一遍。 从你看到第一条异常日志开始,到你确认问题已解决为止。看每套方案能在多长的链路上帮你,以及哪一步开始需要"切系统"。
本文对比基于2026年6月各产品公开版本实测。ELK Stack(Elasticsearch 7.17/8.15 + Logstash + Kibana + Filebeat)为自建部署;阿里云SLS价格为2026年6月官网公开定价(中国内地地域);冠服云EMS为ITOM模块。阿里云SLS实际费用因使用模式差异较大,以上仅为同等规模估算,具体请以云厂商最新报价和自身实际用量为准。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)