利用按需和批量管道动态提取数据
许多公司拥有大量纸质或电子文档,其中蕴藏着尚未开发的商业智能。随着生成式人工智能 (GI)的发展,各种大型语言模型可用于从这些文档中准确提取相关数据。本文展示了一个智能文档处理流程,该流程在Amazon Bedrock上结合了按需推理和批量推理选项,从而能够灵活控制文档处理的时间和成本。对于时间紧迫的请求,可以使用按需推理选项;而批量推理选项则具有最佳的成本优化。本文还解释了如何在文档级别动态指定大型语言模型和提示,从而使您能够使用相同的流程从多种类型的文档中提取数据。
解决方案概述
如果您像我们的客户一样,积压了数亿份扫描版 PDF 格式的土地租赁文件(仅包含图像,不含可编辑文本的 PDF 文件,例如本例中的扫描版土地租赁文件),并且每天都有新文件涌入,那么您可以利用此解决方案高效地从这些文档中提取数据。如下图所示,此解决方案构建了两个推理管道:按需推理和批量推理,并提供了一种动态调用机制。通过使用 Amazon Bedrock Prompt Management中精心设计的提示,可以从格式和规范各异的扫描版 PDF 文件或文本文件中提取并标准化数据。
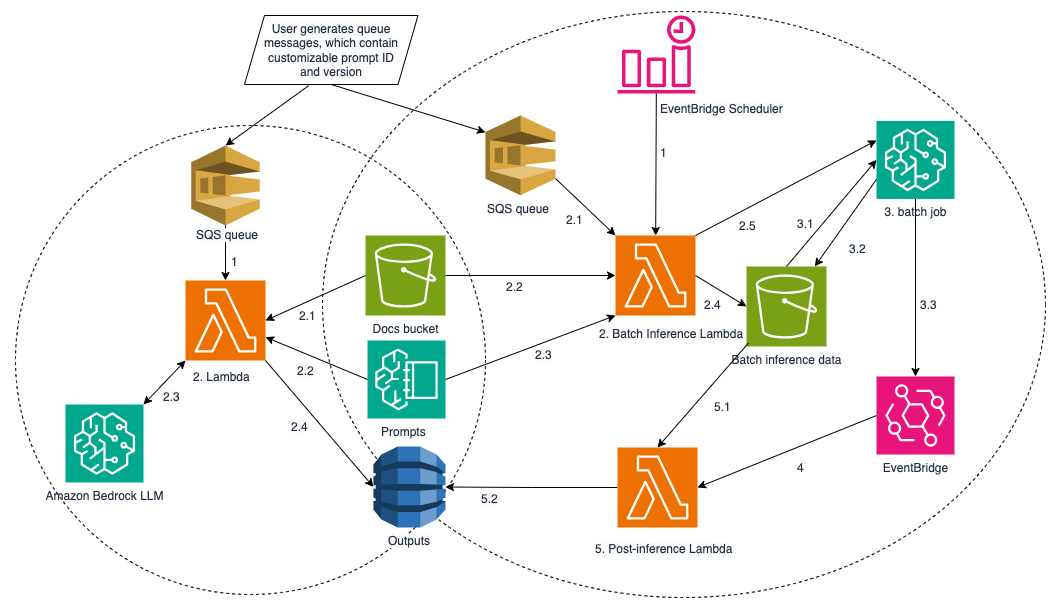
左侧的管道是按需管道,它逐个从文档中提取数据,并在几秒钟内返回结果。这使其非常适合对时间要求严格的请求。
右侧的管道是批量推理管道,它会在单个 Amazon Bedrock批量推理作业中处理多个文档请求,其中模型调用将异步处理。用户可以在两个管道的请求中指定提示 ID 和版本,相应的提示文本将从 Amazon Bedrock 提示管理中检索。
以下各节将详细介绍这两条管道。
1. 按需推理管道
在按需推理管道中创建一个AWS SQS先进先出 (FIFO) 队列。当包含文档 ID、LLM 模型 ID、提示 ID/版本和系统提示 ID/版本的队列消息到达时,会触发一个 AWS Lambda 函数。该函数从指定的 Amazon S3 存储桶中检索 PDF 文档,将 PDF 页面转换为 PNG 图像,从 Amazon Bedrock Prompt Management 中检索相关提示,构建调用 LLM 的消息,并将结果保存到Amazon DynamoDB表中。
1.1. AWS SQS FIFO 队列
当单个文档到达时,AWS SQS FIFO 队列用于触发 Amazon Bedrock 推理。使用 FIFO 队列的主要原因如下:
- 可靠的消息传递——确保每条消息只传递一次。
- 先进先出 (FIFO) 处理——保持严格的顺序,为处理提供更好的可预测性。
- 消息分组——消息组 ID 属性确保消息在每个组内按顺序处理。每个生产者都可以使用唯一的消息组 ID 来维护相关消息的顺序。
如何创建队列消息?
队列消息可以通过 AWS CLI 或 AWS SDK API 在外部创建。以下是一个 AWS CLI 命令示例:
<span style="color:#333333"><code class="language-powershell">aws sqs send-message --queue-url https://sqs.us-east-1.amazonaws.com/1111111111/ondemand-data-pipeline-queue.fifo --message-group-id "1" --message-body "msg 1" --message-attributes file://message_txt.txt</code></span>本示例中的文件message_txt.txt是一个 JSON 文件,其中包含应用程序所需的消息属性。详情请参见下文“测试管道”部分。
Lambda 函数会在 Amazon Bedrock 返回提取的数据后删除队列消息。
1.2. Lambda 函数——队列消息处理和推理
1.2.1 检索文档、转换为图像以及分割大文件
Lambda 函数使用队列消息中的属性下载文档s3_location。如果文档是扫描的 PDF 文件,则会将其转换为图像,以便多模态模型能够理解。
截至撰写本文时,Claude 4 Sonnet 模型每次多模态调用最多只允许 20 张图像。因此,如果文档包含超过 20 页的图像,则必须将其拆分为 20 页一组的块。这些图像、doc_id提取chunk_count结果chunk_id和模型性能指标都存储在 Amazon DynamoDB 表中。
doc_id文档的标识符chunk_count该文档的块总数chunk_id文档中每个数据块的标识符
1.2.2. 从 Amazon Bedrock 提示管理中检索提示
土地租赁文件的格式各不相同——有的以编号列表的形式呈现地块属性,有的以表格形式呈现,有的甚至以土地图纸的形式呈现。因此,针对每种文件格式使用不同的提示信息可以提高提取的准确性。
LLM 调用中使用的提示信息存储在 Amazon Bedrock Prompt Management 中。每个提示信息都有一个唯一的 ID 并带有版本号。SQS 消息必须指定相关的提示信息 ID 和版本,以便在 Lambda 执行期间检索提示信息正文。
注意:每个区域最多只能有 50 个提示,每个提示最多只能有 10 个版本。
1.2.3 编写 LLM 调用消息并处理响应
Lambda 函数继续执行以下步骤:
- 将提示信息正文和图片连接起来,即可编写 LLM 消息。
- 使用Converse API向 Amazon Bedrock 发送请求。
LLM 将以 JSON 字符串的形式返回提取的数据,您可以按照以下测试管道部分所示,在 DynamoDB 表中检查结果。
1.2.4 保存结果
最后,Lambda 函数通过以下方式完成整个过程:
- 解析 JSON 并将地块属性存储到 DynamoDB 表中。
- 如果文档已成功处理且结果已存储,则从队列中删除 SQS 消息。
2. 批量推理流程
由于 AWS SQS 标准队列吞吐量高,因此批量推理管道采用该队列。队列消息的创建方式与按需管道类似,只是message-group-id属性不是必需的。
批量推理流程的主要组成部分包括:
- Amazon EventBridge 调度器。
- 使用 AWS Lambda 函数进行批量推理,预处理扫描的 PDF 文件,创建 JSONL 文件并提交批量推理作业。
- Amazon EventBridge 规则。
- 对 AWS Lambda 函数进行后处理。
以下各节将详细介绍批量推理流程。
2.1. Amazon EventBridge 调度器
Amazon EventBridge Scheduler 会按计划启动批量推理 Lambda 函数。
2.2. 批量推理 Lambda 函数
该函数首先检查队列中是否有足够的消息,然后再继续执行。截至撰写本文时,Amazon Bedrock 批量推理作业的最小记录数为 100 条。
2.2.1 接收队列消息
Lambda 函数循环遍历队列中的消息,并提取文档 ID、LLM 模型 ID、提示 ID/版本和系统提示 ID/版本。
2.2.2 检索无重复文档、转换为图像以及分割大文件
Lambda 函数随后检索文档,如果文档是扫描的 PDF 文件,则将其转换为图像,并根据需要拆分大文件——这与按需管道中的操作相同。由于标准 SQS 队列不能保证消息只传递一次,因此该函数还会确保忽略重复消息。
2.2.3 允许在批量推理作业中使用不同的提示
与按需管道类似,不同的文档格式需要不同的用户提示才能更有效地提取数据。
SQS 消息中指定了每个文档的预期提示 ID 和版本。Lambda 函数执行期间,会从 Amazon Bedrock Prompt Management 中检索提示正文。
2.2.4 为批量推理作业创建 JSONL 工件
Lambda 函数随后处理以下任务:
- 在批量推理数据 S3 存储桶中创建一个文件
metadata.json,用于存储消息属性,包括 SQS 消息 ID、doc_id提示 ID/版本、系统提示 ID/版本以及其他项目相关属性。此文件稍后将由后处理 Lambda 函数用于填充 DynamoDB 表。 - 处理文档以创建 Amazon Bedrock 批量推理作业所需的 JSONL 文件。为了提高效率,此过程使用 Python 的 multiprocessing 模块进行并行处理。生成的 JSONL 文件将上传到批量推理数据 S3 存储桶。
- 文档准备完毕并上传到 S3 存储桶后,删除 SQS 消息。这需要为队列设置较大的可见性超时时间。
2.2.5 编写消息并提交批量推理作业
最后,批量推理 Lambda 函数会使用上一步生成的 JSONL 工件创建 Amazon Bedrock 批量推理作业。请注意,每个批量作业只能使用一个模型处理文档,这意味着同一个批量作业中的 SQS 消息必须指定相同的模型 ID。如果传入消息中指定了多个模型 ID,Lambda 函数会使用轮询机制,选择使用出现频率最高的模型 ID。
2.3. Amazon Bedrock 批量推理作业
当 Amazon Bedrock 收到批量推理作业时,它会将其放入队列中。作业启动后,将执行以下步骤。
2.3.1 为批量推理作业检索 JSONL 工件
Amazon Bedrock 会检索在创建作业期间指定的 JSONL 工件。
2.3.2 存储批量推理输出
完成后,Amazon Bedrock 会将输出存储到批量推理数据 S3 存储桶中,该存储桶也在作业创建中指定。
2.3.3 通知 Amazon EventBridge
作业完成后,Amazon Bedrock 会向 Amazon EventBridge 发送作业状态更改事件,该事件会被 EventBridge 规则捕获。
2.4. Amazon EventBridge 规则触发推理后的 Lambda 函数
EventBridge 规则触发后处理 Lambda 函数来处理进一步的模型输出处理。
2.5. Lambda 函数的后处理
2.5.1 获取输出 JSONL
Lambda 函数从批量推理数据 S3 存储桶中获取推理输出 JSONL。
2.5.2 保存推理输出
该函数解析 JSONL 文件,并将提取的地块属性保存到 DynamoDB 表中。
先决条件
如果您想亲自尝试这个例子,请确保满足以下前提条件:
- 拥有访问 AWS 管理控制台权限的AWS账户
- 创建和管理 CloudFormation 堆栈所需的相应 IAM 权限,通常包括:
- cloudformation:CreateStack
- cloudformation:描述堆栈
- cloudformation:UpdateStack
- cloudformation:DeleteStack
部署 CloudFormation 堆栈
部署按需管道:
![]()
选择“启动堆栈”链接后,您将被引导至AWS CloudFormation以启动 CloudFormation 堆栈:
- 在“创建堆栈”页面上,选择“下一步”。
- 在“指定堆栈详细信息”页面上,选择“下一步”。
- 在“配置堆栈选项”页面上,选择“下一步”。
- 在“审核并创建”页面上,选择“我确认 AWS CloudFormation 可能会创建 IAM 资源”。
- 选择提交
提交后,您可以查看堆栈的一些详细信息,例如堆栈信息、事件、资源等。以下屏幕截图显示了事件信息,供您参考:
您也可以按照相同的步骤部署批处理管道。
![]()
测试管道
以下步骤指导您测试按需管道。如果您有至少 100 个文档,也可以使用类似的步骤测试批量管道。
- 将数据下载到您的本地环境中。您需要从德克萨斯州土地记录和县记录网站购买温克勒县、安德鲁斯县和萨顿县的三份土地文件。
- 将下载的 PDF 文件上传到CloudFormation 堆栈中创建的S3 工件存储桶ondemand-data-pipeline-bucket-${account_id} 。
- 使用以下示例创建文本文件 message_txt.json,方法是将提示 ID、系统提示 ID 和 S3 存储桶替换为从 CloudFormation 堆栈创建的提示 ID、系统提示 ID 和 S3 存储桶。
<span style="color:#333333"><code class="language-js"><span style="color:#5f6364">{</span>
<span style="color:#c92c2c">"application"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#5f6364">{</span>
<span style="color:#c92c2c">"DataType"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"String"</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"StringValue"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"bedrock-example"</span>
<span style="color:#5f6364">}</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"id"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#5f6364">{</span>
<span style="color:#c92c2c">"DataType"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"String"</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"StringValue"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"Winkler_2024-06-05_N_C42758_V_OPR"</span>
<span style="color:#5f6364">}</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"model_id"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#5f6364">{</span>
<span style="color:#c92c2c">"DataType"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"String"</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"StringValue"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"anthropic.claude-sonnet-4-20250514-v1:0"</span>
<span style="color:#5f6364">}</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"prompt_id"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#5f6364">{</span>
<span style="color:#c92c2c">"DataType"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"String"</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"StringValue"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"6CT88W3MWT"</span>
<span style="color:#5f6364">}</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"prompt_version"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#5f6364">{</span>
<span style="color:#c92c2c">"DataType"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"String"</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"StringValue"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"1"</span>
<span style="color:#5f6364">}</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"s3_location"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#5f6364">{</span>
<span style="color:#c92c2c">"DataType"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"String"</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"StringValue"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"s3://ondemand-data-pipeline-bucket-111111111/Winkler_2024-06-05_N_C42758_V_OPR.pdf"</span>
<span style="color:#5f6364">}</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"system_prompt_id"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#5f6364">{</span>
<span style="color:#c92c2c">"DataType"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"String"</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"StringValue"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"R2NFLXFXOJ"</span>
<span style="color:#5f6364">}</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"system_prompt_version"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#5f6364">{</span>
<span style="color:#c92c2c">"DataType"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"String"</span><span style="color:#5f6364">,</span>
<span style="color:#c92c2c">"StringValue"</span><span style="background-color:rgba(255, 255, 255, 0.5)"><span style="color:#a67f59">:</span></span> <span style="color:#2f9c0a">"1"</span>
<span style="color:#5f6364">}</span>
<span style="color:#5f6364">}</span></code></span>- 使用上述 AWS CLI 示例,通过替换队列名称创建 shell 脚本 send2queue.sh 并执行它。您将看到一条消息发送到您的 SQS 队列ondemand-data-pipeline-queue.fifo。
- 队列消息将触发 Lambda 函数ondemand-data-pipeline-queue-processor。
- 在 Amazon CloudWatch 中查看 Lambda 日志,日志组为/aws/lambda/ondemand-data-pipeline-queue-processor。
- 检查 DynamoDB ondemand-data-pipeline-table表中的 Amazon Bedrock 推理输出。Winkler County 示例的该列中的 JSON 结果
model_response应如下所示:
<span style="color:#333333"><code class="language-json">[
{
"tract": 1,
"state": "Texas",
"county": "Winkler",
"abstract": "A-1239",
"survey": "PSL Survey",
"section": "8",
"range_block": "B2",
"quarter": "N/2 of N/2"
},
{
"tract": 2,
"state": "Texas",
"county": "Winkler",
"abstract": "A-1239",
"survey": "PSL Survey",
"section": "8",
"range_block": "B2",
"quarter": "N/2 of S/2"
},
{
"tract": 3,
"state": "Texas",
"county": "Winkler",
"abstract": "A-1240",
"survey": "PSL Survey",
"section": "9",
"range_block": "B2",
"quarter": "S/2 of N/2"
},
{
"tract": 4,
"state": "Texas",
"county": "Winkler",
"abstract": "A-1240",
"survey": "PSL Survey",
"section": "9",
"range_block": "B2",
"quarter": "S/2 of S/2"
}
]</code></span>清理
清理资源:
- 登录 AWS 管理控制台
- 导航至 CloudFormation 服务
- 在 CloudFormation 控制面板中,找到并选择要删除的堆栈。
- 选择页面顶部的“删除”按钮
- 出现提示时确认删除
CloudFormation 会按正确的顺序自动删除作为堆栈一部分创建的资源,并适当处理依赖关系。
删除 CloudFormation 堆栈不会删除 S3 存储桶和 DynamoDB,因为它们的删除策略设置为保留,以防止数据丢失。要删除这些资源,请转到 AWS 管理控制台中各个服务的页面并进行删除。
结论
本文介绍的按需和批量 Amazon Bedrock 推理管道解释了如何根据时间敏感性和数据量动态处理文档。在决定使用哪种管道时,您还应该考虑成本因素。我们的测试表明,与按需管道相比,批量管道的 Amazon Bedrock 成本降低了 50%。
该解决方案的另一个关键特性是能够指定大型语言模型(用于按需管道)并在单个文档级别进行提示,从而使这些管道能够支持各种类型的智能文档处理。
通过使用 Python 的多进程模块启用并行性,批量推理管道的两个 Lambda 函数可以在 15 分钟内处理 1,000 个文档。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)