理论融入行业实践:基于Hermes打造服饰电商垂直AI Agent
我最近一周花了20亿Token指挥Hermes Agent弄了个开源项目:github.com/pmshaw2045-ops/zhijing-agent
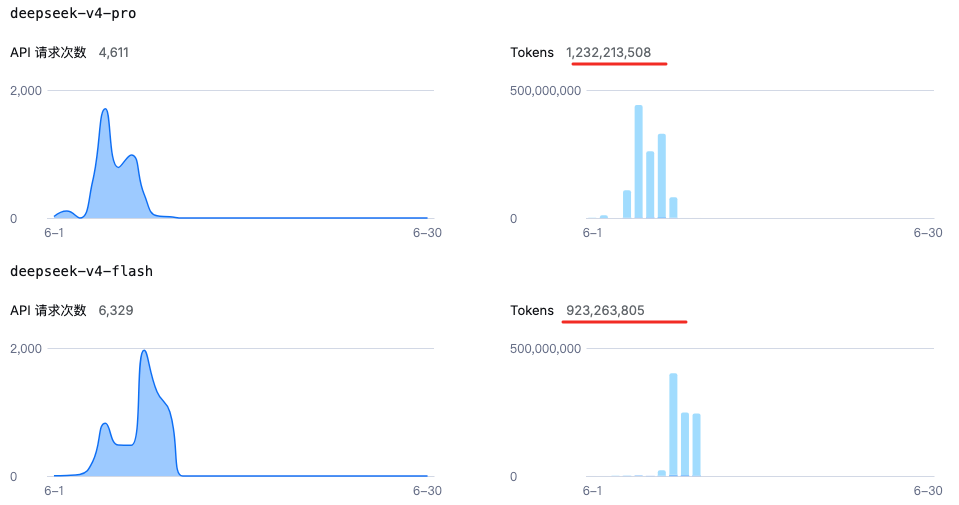
Token主要消耗是在优化技术架构、修复前期留下的技术债,为后续的进一步能力增强打好基础。
这是一款面向服饰电商行业运营人员的AI Agent产品MVP版本,用LLM驱动Agent Pipeline自动化完成选品分析、竞品对标、趋势洞察等专业分析任务,并输出结构化可视化报告。
诚实的说,这个项目对行业的贡献不在发明了什么新东西,而在于把Agent工程的最佳实践做了一个完整、诚实、可复现的垂直落地。 它肯定不是下一个LangChain或AutoGPT那个级别的行业级作品,但我觉得它比市面上很多Agent开源项目更认真、更有参考价值!
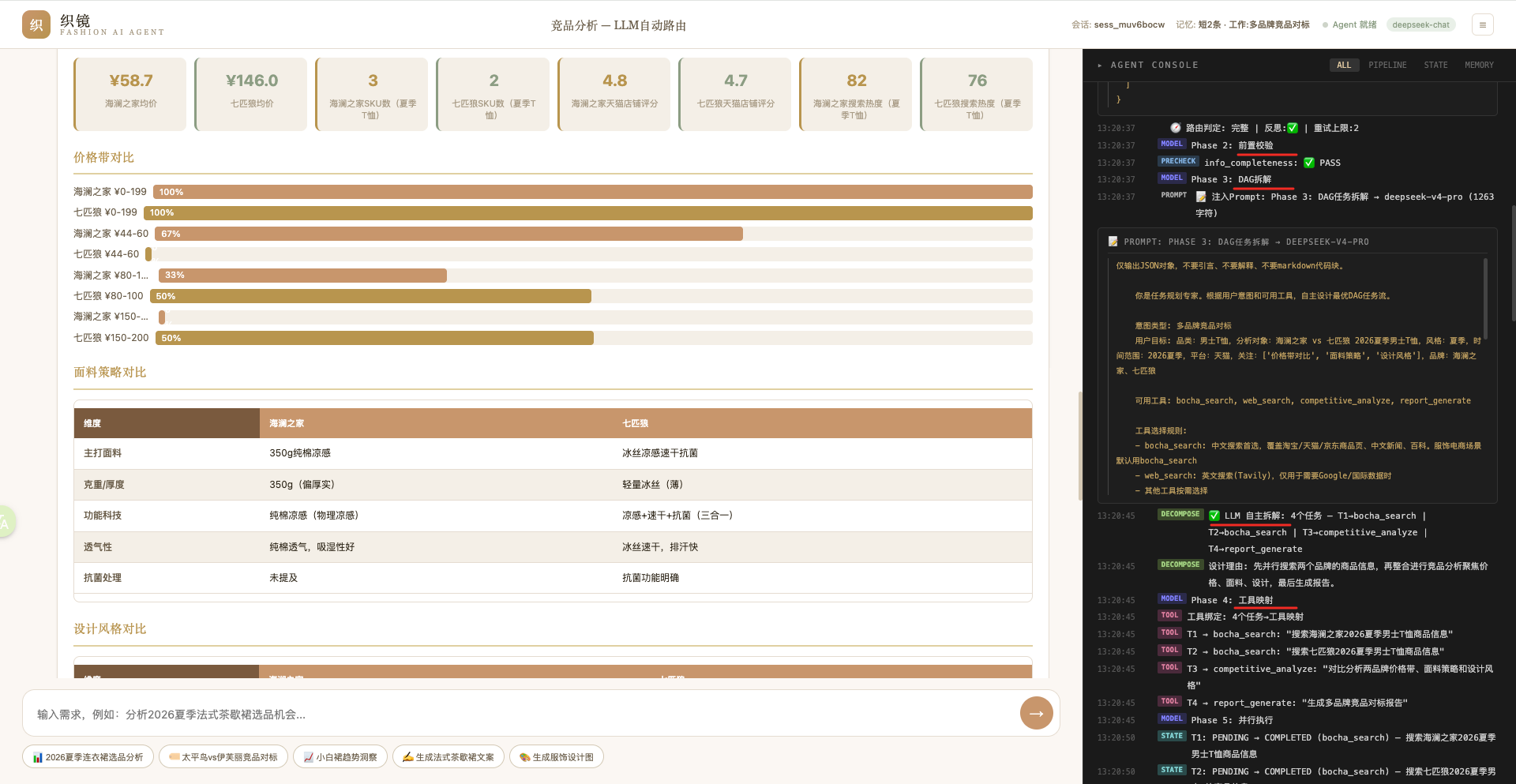
一、产品价值
服饰电商选品是一个真实的痛点:传统流程是运营手动搜数据、拉Excel、凭经验判断,织镜把这个流程从「3天调研 👉 Excel报告」压缩到「30秒自然语言 👉 结构化报告」;
另外还额外支持基于服装设计师自然语言描述的设计想法去生成线稿图、实拍图、模特上身图,辅助服饰类电商商家快速、高效开品。、
产品当前处于技术demo到MVP的过渡区,主要证明技术可行(真LLM驱动、真全自动),离运营每天必用还有差距,主要是当前数据源比较匮乏;不过我觉得瑕不掩瑜,后续持续介入三方数据API就能显著提升报告质量。
📌 产品核心能力总结如下:
|
意图类型 |
功能 |
典型输入 |
复杂度 |
|
单品选品分析 |
市场数据 + 价格带 + 趋势 + 竞品格局 |
"分析2026夏季法式茶歇裙选品机会" |
COMPLEX |
|
多品牌竞品对标 |
双品牌对比 + SWOT + 差异化机会 |
"太平鸟和伊芙丽连衣裙竞品对标" |
COMPLEX |
|
品类趋势洞察 |
面料/廓形/色彩趋势 |
"2026夏季连衣裙流行趋势" |
MEDIUM |
|
商品文案生成 |
多平台电商文案 |
"生成法式茶歇裙淘宝标题" |
SIMPLE |
|
定价策略分析 |
价格带分布 + 成本利润测算 |
"连衣裙在天猫的定价策略" |
MEDIUM |
|
上新排期建议 |
季节曲线 + 大促日历 + 最佳窗口 |
"夏季连衣裙上新排期建议" |
MEDIUM |
|
文生图 |
真实产品摄影图/设计线稿 |
"法式碎花茶歇裙产品摄影图" |
SIMPLE |
二、产品差异化
✅ 全LLM驱动:从意图识别到DAG拆解到报告生成,不依赖固定模板或规则引擎;
由LLM根据意图类型、可用工具列表、当前数据上下文自主设计执行计划
✅ Provider无关:LLM和搜索均支持任意提供商(DeepSeek/OpenAI/兼容 API),用户通过配置文件切换,不改代码;
✅ 反思修正闭环:报告生成后自动评分,低于7分触发重试修正(最多2次),保留最高分版本;
✅ 工作记忆系统:五层记忆架构 + RAG 语义检索(工作/短期/主题/分析/长期 + 语义检索),滑动窗口 + 递归摘要 + 同义词桥接;
✅ 语义检索(RAG):LLM embedding 👉 SQLite向量存储 → 余弦相似度排序,三层兜底(语义→同义词→关键词);
后续可以单独走Embedding模型并接入向量数据库,当下控制成本,从简了~
✅ 可视化报告:JSON结构化数据 👉 前端渲染引擎 👉 包含指标卡片、柱状图、SWOT 矩阵、品牌对比卡、洞察框等9种组件;
LLM输出结构化JSON后前端9种模板函数渲染,这种处理方式可以根除LLM类名幻觉
三、Agent Pipeline
Phase 0: 多轮对话检测 → Scenario识别 + 查询增强
Phase 1: LLM意图识别 → 7种意图判定 + IntentRegistry路由
Phase 2: 前置校验 → 信息完整性检查 + 实体提取 + 澄清交互
Phase 3: LLM DAG拆解 → 自主设计执行计划(json_mode)
Phase 4+5: 工具映射 → ToolRegistry + ParallelExecutor并行执行
Phase 6: JSON报告生成 → 6策略路由 → LLM输出JSON → 前端渲染
Phase 7: 反思修正 → 质量评分 < 7自动重试,最多2次
SSE事件流: intent → precheck → decompose → execute → report → reflect
→ quality_review → memory_search → result → summary → done四、有参考价值的几个设计
1️⃣ IntentRegistry作为 SSOT(Single Source of Truth)
我觉得这是项目中最值得行业参照的模式,不是用if-else路由意图,不是每个模块各自维护意图列表,而是把意图的「元数据」集中在registry里,衍生逻辑(工具过滤、校验规则、DAG模板)全部从registry推导
intent_registry.py # 加一个新意图只需要10行
INTENT_REGISTRY["copy"] = {
"mode": "copy",
"name": "商品文案生成",
"relevant_tools": ["bocha", "web", "report"], # 自动过滤工具
"precheck": ["require_analysis_object"], # 自动校验规则
"dag": {"tasks": [...]}, # fallback模板兜底
}2️⃣ LLM自主DAG拆解
这是项目最核心的架构决策,大多数Agent框架(LangChain、CrewAI、AutoGen)本质上是固定Workflow编排器,定义A→B→C的链然后执行。织镜的做法是:
意图 + 工具列表 + 规则 → LLM自主设计DAG → 执行
↓ LLM输出非JSON时
fallback到注册模板这不是为了炫技的过度设计,意图是「选品分析」时用户可能想先看价格,也可能是先看趋势。固定的Workflow不可能覆盖所有场景,LLM自主拆解才是相对更好方向。
3️⃣ 反思修正闭环的质量门禁
目前从数据一致性 + 目标对齐 + 可落地性这三个维度对LLM生成报告评分,不达标打回重新生成(评审结果注入Prompt)。这个设计本身不新奇,很多论文在讲,但在实际代码里真正落地的似乎不是很多;
生成报告 → 三维审查评分
↓ < 7分
触发纠正 → 重新评分(最多2次,保留最高分)
# 当前数据元不丰富,不限制重试下去意义不大,而且
# Agent Loop本身也需要控制最大循环次数,要不然掏空你家底没商量4️⃣ 工具返回结果裁剪、提炼后注入Prompt
这么做的原因不只是token节省,因为LLM 理解自然语言的语义密度高于JSON(同样的token预算,自然语言传达的信息更丰富),而且JSON的结构符号({ " , null)不仅消耗token还不贡献信息,转自然语言后会自动屏蔽掉;
5️⃣ 多轮对话意图与上下文管理
这主要是常识解决用户和工具多轮聊天时的上下文继承、意图切换、实体增量更新问题,核心目标是让连续追问自动聚焦同一意图,不仅不用用户重复输入完整需求,还能减少LLM重复调用,降低token成本。
用户输入 → Phase 0: 场景检测
├─ NEW_QUERY → Phase 1: LLM识别意图 ← 简单规则prompt
└─ FOLLOWUP_*
├─ 提取到实体(changes非空)
│ ├─ 含intent_type → Phase 1: LLM识别(意图切换路径)
│ └─ 无intent_type → 跳过Phase 1,继承上次intent
│ ↓
│ Phase 1.2: merge_goal(changes) → goal已含"泡泡袖"
│ ↓
│ Phase 3: decompose → 搜索 → report
│ 全部自然聚焦到 "泡泡袖连衣裙" 的选品分析
└─ 未提取到实体 → Phase 1: LLM识别(prompt兜底)五、当前限制
❌ 数据源为通用网页搜索(博查 + Tavily),非结构化,缺少电商API获取精确价格/销量数据(多多、万邦考虑中);
❌ 单租户架构,不支持SaaS多客户隔离;
❌ 无用户认证系统(仅API Token保护);
❌ 无CI/CD流程(仅 GitHub Actions 测试,未配置自动部署),需手动部署。
六、后续规划
|
优先级 |
方向 |
状态 |
目标 |
|
P0 |
电商结构化数据源 |
进行中 |
接入多多API、万邦数据等获取精确价格/销量 |
|
P1 |
工具注册层抽象 |
进行中 |
合并AVAILABLE_TOOLS 到 ToolRegistry,为Skills/MCP铺路 |
|
P2 |
Skills系统 |
待启动 |
SKILL.md 声明 + 动态加载 |
|
P3 |
MCP客户端 |
待启动 |
接入外部工具生态 |
|
P3 |
多租户 |
待启动 |
SaaS化 |
感兴趣的朋友可以去克隆下来瞅瞅,欢迎大家交流学习~
# 1. 克隆
git clone https://github.com/pmshaw2045-ops/zhijing-agent.git
cd zhijing-agent
# 2. 配置密钥(支持任意 OpenAI 兼容 API)
cp .env.example .env
# 编辑 .env,至少填入 LLM_API_KEY(详细配置说明见 docs/config_guide.md)
# 3. 安装依赖
pip install -r backend/requirements.txt
# 4. 启动
python3 -m uvicorn backend.server:app --host 0.0.0.0 --port 8899
# 5. 打开浏览器
open http://localhost:8899(本文完)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)