Claude深夜炸场,连夜放出两款传说级模型!AI赛道迎来了大变天
前几天,Claude重磅发布了两款神话级模型ClaudeFable 5和ClaudeMythos5。
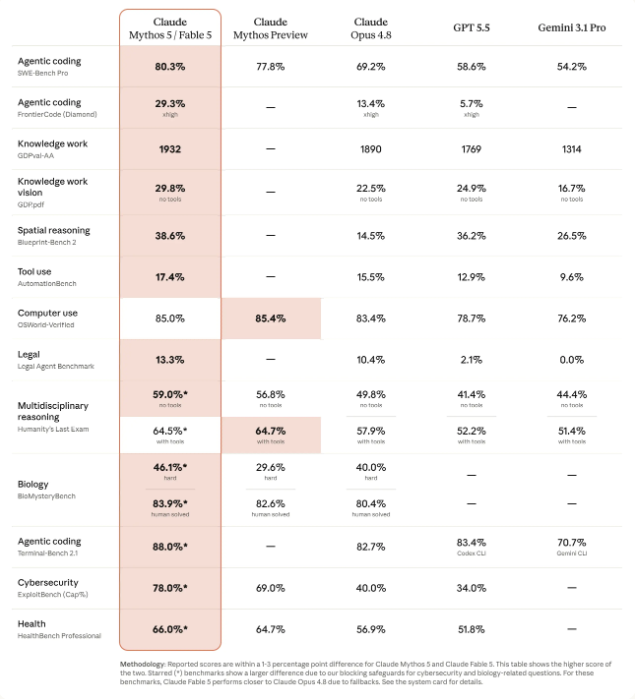
根据这几个模型之间的对比,我们可以从以下这几个维度得出这些结论:
1、编程任务
Fable 5 在真实世界编程任务(SWE-Bench Pro)上领先近 11个百分点,远超所有竞品。
在“极端难度”代码生成(FrontierCode Diamond)中,Fable 5 达到 29.3%,是 Opus 的 2.2倍,GPT-5 的 5倍以上。
Terminal-Bench 2.1 显示 Fable 5 能完成更复杂的终端操作链式任务(如多步骤脚本执行+调试),得分高达 88%,接近人类专家水平。
2、综合知识推理任务
在综合知识推理任务(GDPval-AA)中,Fable 5 得分为 1932,略高于 Opus(1890),显著优于竞品。
在“无工具辅助”的PDF文档阅读理解(GDPpdf)中,Fable 5 表现最佳(29.8%),说明其原生视觉解析能力更强,无需调用外部OCR或解析器即可处理复杂排版文档。
3、空间推理与工具使用
空间推理方面,Fable 5 以 38.6% 大幅领先第二名的 GPT-5(36.2%),尤其在几何变换、路径规划等场景下表现稳定。
工具调用能力虽绝对值不高(17.4%),但相比 Opus(15.5%)仍有提升,且远胜 Gemini(9.6%)。值得注意的是,Fable 5 在“带工具”的多轮交互中效率更高(见下文Multidisciplinary reasoning部分)。
4、法律代理相关
在法律代理任务中,Fable 5 得分 13.3%,是 Opus 的 1.28倍,GPT-5 的 6倍多,甚至碾压 Gemini(0%)。这表明其在合同审查、法规检索、案例匹配等领域具备行业级专业能力。
5、相关专业知识
在“Hard”生物学谜题中,Fable 5 达 46.1%,较 Opus 提升 6.1个百分点。
在“Human Solved”类别中,Fable 5 达到 83.9%,接近人类专家水平(82.6%~80.4%区间),说明其科学推理已达可信赖程度。
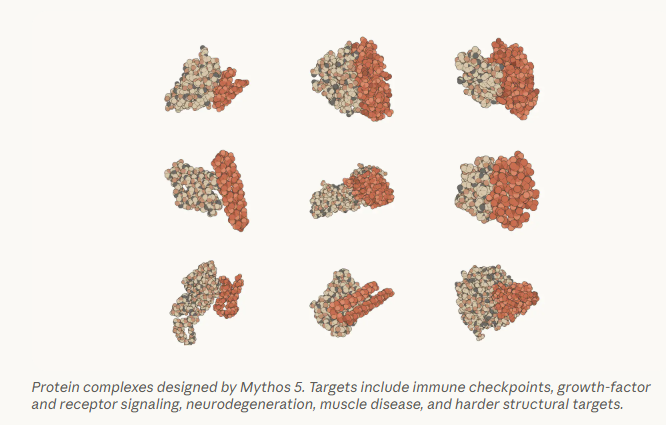
内部蛋白质设计专家利用 Mythos 5 将药物设计流程提速约十倍,在无人协助下独立完成从靶点选择到故障恢复的全链路工作,并在14个蛋白靶点中成功产出9个强效候选分子。也就是说在仅配备蛋白质设计和生物信息学工具、无人类协助的情况下,模型表现达到甚至超越熟练的人类操作员水平。
总结:
超长自主性:两款模型均具备比以往任何 Claude 模型更长的自主工作时长,能够处理需要长时间连续推理和执行的复杂任务。
多维能力增强:除软件工程外,模型在以下领域也实现了显著提升:
- 知识工作:复杂文档理解与推理
- 视觉能力:图表解读与界面还原
- 记忆能力:长上下文保持与跨会话信息整合
- 生命科学研究:假设生成、实验设计与数据分析
定价
两款模型的定价均为:每百万个输入 token 10 美元,每百万个输出 token 50 美元。开发者可通过 Claude API 使用 claude-fable-5。所以

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)