YOLO26 全网独家改进创新:CVPR 2025 LSNet 大核小核主干,引入 See Large, Focus Small 机制!
YOLO26 全网独家改进创新:CVPR 2025 LSNet 大核小核主干,引入 See Large, Focus Small 机制!
购买相关资料后畅享一对一答疑!
微信公众号:Ai计算机视觉
畅享超多免费持续更新且可大幅度提升文章档次的纯干货工具!
本文将 CVPR 2025 LSNet: See Large, Focus Small 的核心思想融入 YOLO26 主干,形成
YOLO26-LSNetBackbone。
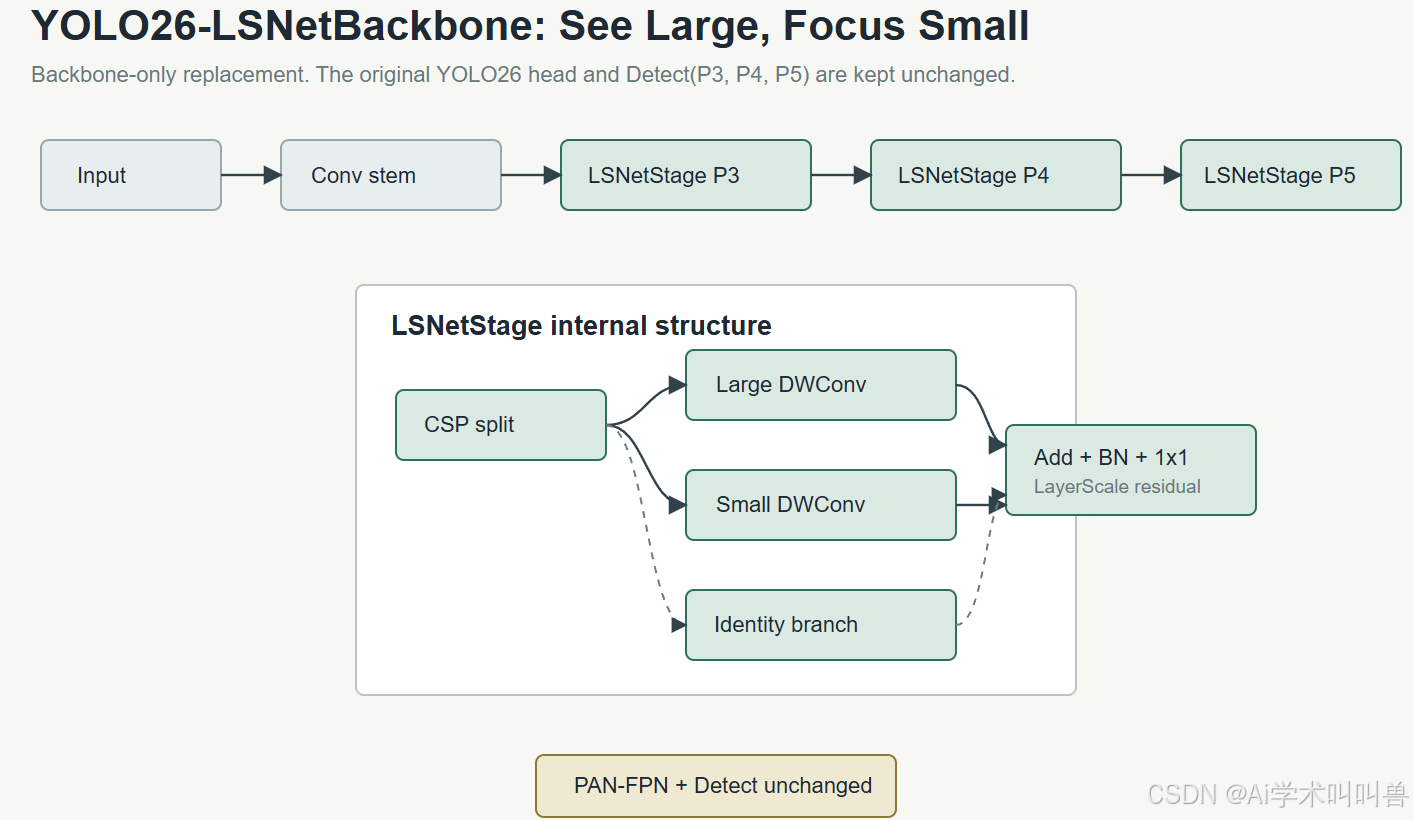
本改进不是简单替换一个卷积,而是将 LSNet 中“大范围感受野 + 小范围细节聚合”的设计重新封装为适配 YOLO26 的LSNetStage,用于替换原主干中的 C3k2 stage。检测头、PAN-FPN、Detect(P3/P4/P5) 全部保持不变,便于消融实验和论文复现。
1. 原文摘要翻译和介绍的翻译总结提炼
1.1 论文与代码出处
论文名称:LSNet: See Large, Focus Small
会议:CVPR 2025
论文页面:https://openaccess.thecvf.com/content/CVPR2025/html/Wang_LSNet_See_Large_Focus_Small_CVPR_2025_paper.html
1.2 摘要翻译式提炼
LSNet 的核心目标是解决轻量视觉主干中的两类矛盾:一方面,网络需要足够大的感受野来理解目标与背景之间的上下文关系;另一方面,网络又必须保留局部纹理、边缘与小目标细节。传统小卷积堆叠虽然稳定,但扩大感受野的效率不高;直接引入大核卷积虽然能看到更大范围,却可能增加计算压力并稀释局部细节。LSNet 提出 “See Large, Focus Small” 的结构思想,通过大核分支观察全局空间关系,通过小核分支保留局部精细响应,从而提升轻量模型在分类、检测和分割任务中的表达能力。
1.3 引言总结提炼
论文的引言部分强调,轻量主干网络不能只追求参数少和速度快,还要考虑空间建模能力。目标检测任务中,目标尺度变化、背景干扰、小目标边界模糊等问题非常常见。如果主干 stage 只依赖固定的局部卷积,模型很容易出现“看不远”或“看大范围时丢细节”的问题。LSNet 的价值在于,它提供了一种 CNN 友好的大/小感受野协同方式,不需要复杂的 Transformer 注意力矩阵,也不依赖额外序列建模库,非常适合嵌入 YOLO26 这类实时检测框架。
2. 为什么要融合(写作的切入点哈)
2.1 为什么 YOLO26 适合融合 LSNet
YOLO26 原主干结构中,C3k2 是主要特征提取 stage:
Conv(P1/2) -> Conv(P2/4) -> C3k2 -> Conv(P3/8)
-> C3k2 -> Conv(P4/16) -> C3k2
-> Conv(P5/32) -> C3k2 -> SPPF -> C2PSA
原 C3k2 的优势是结构轻、训练稳定、速度快;不足是单个 stage 内的空间感受野仍以局部卷积为主。对复杂检测任务而言,它可能在以下场景中受限:
| 检测问题 | 原 YOLO26 可能的不足 | LSNet 融合后的补充 |
|---|---|---|
| 小目标边缘弱 | 局部纹理容易被深层下采样削弱 | 小核分支强化局部细节 |
| 背景干扰强 | 单纯局部卷积难以区分目标与大背景 | 大核分支扩大上下文范围 |
| 多尺度目标共存 | 固定卷积感受野适配性有限 | 大核 + 小核并行兼顾尺度变化 |
| 轻量部署需求 | Transformer 类模块成本较高 | 深度卷积结构更部署友好 |
2.2 融合策略
本文采用 只替换主干 C3k2,不改变检测头 的方式:
原 YOLO26: C3k2
改进 YOLO26: LSNetStage
替换后的 yaml 文件:
ultralytics/cfg/models/26/yolo26-LSNetBackbone.yaml
2.3 LSNetStage 核心结构
输入 x
├── 1x1 Conv 分支 A
│ └── LSConvBlock
│ ├── Large depthwise convolution
│ ├── Small depthwise convolution
│ ├── BN + SiLU
│ ├── 1x1 channel mixer
│ └── LayerScale residual
└── 1x1 Conv 分支 B
Concat(A, B) -> 1x1 Conv -> 输出
2.4 关键代码解释
class LSConvBlock(nn.Module):
定义 LSNet 的核心卷积块。它不是完整照搬论文网络,而是抽取 LSNet 中最适合 YOLO 主干的“大核 + 小核”思想。
self.large = nn.Conv2d(channels, channels, large_kernel, padding=large_kernel // 2, groups=channels, bias=False)
大核深度卷积负责扩大感受野。groups=channels 表示 depthwise convolution,可以显著减少参数量和计算量。
self.small = nn.Conv2d(channels, channels, small_kernel, padding=small_kernel // 2, groups=channels, bias=False)
小核深度卷积负责保留局部纹理、边缘和小目标细节。
y = self.bn(self.large(x) + self.small(x))
将大核分支和小核分支相加,然后用 BN 稳定分布,避免两个空间分支响应尺度不一致。
return x + self.scale(y)
用残差方式输出,并通过 LayerScale 控制新增分支在训练初期的影响,减少训练震荡。
class LSNetStage(nn.Module):
定义 YOLO26 可解析的 stage 级模块。它的构造函数是 LSNetStage(c1, c2, n, ...),可以被 tasks.py 自动解析。
self.cv1 = Conv(c1, hidden, 1, 1)
self.cv2 = Conv(c1, hidden, 1, 1)
构建 CSP 双分支。主分支进入 LSConvBlock,旁路分支保留原始稳定特征。
self.cv3 = Conv(hidden * 2, c2, 1, 1)
两条分支拼接后压回目标通道数,保证输出通道与 YOLO26 后续层匹配。
3. 整合三种融合方法总览
3.1 YOLO26-LSNetBackbone 网络结构图
3.2 yaml 改动
原 YOLO26:
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 2, C3k2, [512, True]]
- [-1, 2, C3k2, [1024, True]]
LSNet 改进:
- [-1, 2, LSNetStage, [256, 0.50, 7, 3, 2.0]]
- [-1, 2, LSNetStage, [512, 0.50, 7, 3, 2.0]]
- [-1, 2, LSNetStage, [512, 0.50, 9, 3, 2.0]]
- [-1, 2, LSNetStage, [1024, 0.50, 9, 3, 2.0]]
参数说明:
| 参数 | 含义 |
|---|---|
256/512/1024 |
stage 输出通道 |
0.50 |
CSP 隐藏通道比例 |
7/9 |
大核卷积核大小 |
3 |
小核卷积核大小 |
2.0 |
channel mixer 扩展比例 |
3.3 验证结果
| 模型 | 参数量 | stride | 前向 |
|---|---|---|---|
| YOLO26-LSNetBackbone | 2,431,112 | [8,16,32] |
通过 |
训练命令:
yolo detect train model=ultralytics/cfg/models/26/yolo26-LSNetBackbone.yaml data=your_data.yaml imgsz=640 epochs=100 batch=16
4. 创新点表述(仅供参考,可举一反三)
本文提出一种面向 YOLO26 的 LSNet 主干增强方法。该方法将 LSNet 中 “See Large, Focus Small” 的大/小感受野协同思想引入 YOLO26 主干 C3k2 阶段,通过大核深度卷积分支扩大上下文感受野,通过小核深度卷积分支保留局部纹理细节,并采用 CSP 旁路和 LayerScale 残差抑制训练初期的特征分布扰动。该设计在不改变 PAN-FPN 检测头和输出尺度的前提下,提高了主干对多尺度目标、弱边缘目标和复杂背景的表征能力。
可以写成论文贡献点:
- 提出 LSNetStage,将大核全局观察与小核局部聚焦机制融入 YOLO26 主干。
- 采用 CSP 双分支保留稳定特征旁路,降低新增卷积分支对训练稳定性的影响。
- 在保持 Detect(P3/P4/P5) 输出不变的情况下增强主干多尺度空间建模能力,便于与原 YOLO26 进行公平消融。
5. 原网络和融合后特点对比
| 项目 | 原 YOLO26 | YOLO26-LSNetBackbone |
|---|---|---|
| 主干模块 | C3k2 | LSNetStage |
| 感受野 | 以局部卷积为主 | 大核 + 小核协同 |
| 小目标细节 | 依赖浅层特征 | 小核分支增强 |
| 上下文建模 | 中等 | 更强 |
| 部署友好性 | 高 | 高 |
| 训练风险 | 低 | 低 |
写在最后
学术因方向、个人实验和写作能力以及具体创新内容的不同而无法做到一通百通,关注UP:Ai学术叫叫兽
在所有B站资料中留下联系方式以便在科研之余为家人们答疑解惑,本up主获得过国奖,发表多篇SCI,擅长目标检测领域,拥有多项竞赛经历,拥有软件著作权,核心期刊等经历。
因为经历过所以更懂小白的痛苦!
因为经历过所以更具有指向性的指导!
祝所有科研工作者都能够在自己的领域上更上一层楼!
微信公众号:Ai计算机视觉

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献74条内容
已为社区贡献74条内容

所有评论(0)