山东大学创新实训8——RAG 和长期记忆管理
一、从“金鱼”到“史诗”:为什么故事引擎需要记忆
文字冒险游戏的核心魅力在于“连续性”——玩家上午在迷雾森林里与老猎人对话,下午回来继续探索时,NPC 应当记得你们曾聊过什么,而不是像个陌生人一样重新自我介绍。
然而,大语言模型天生是“无状态的”。每次调用 LLM,它看到的只是当前会话的最近几条消息。
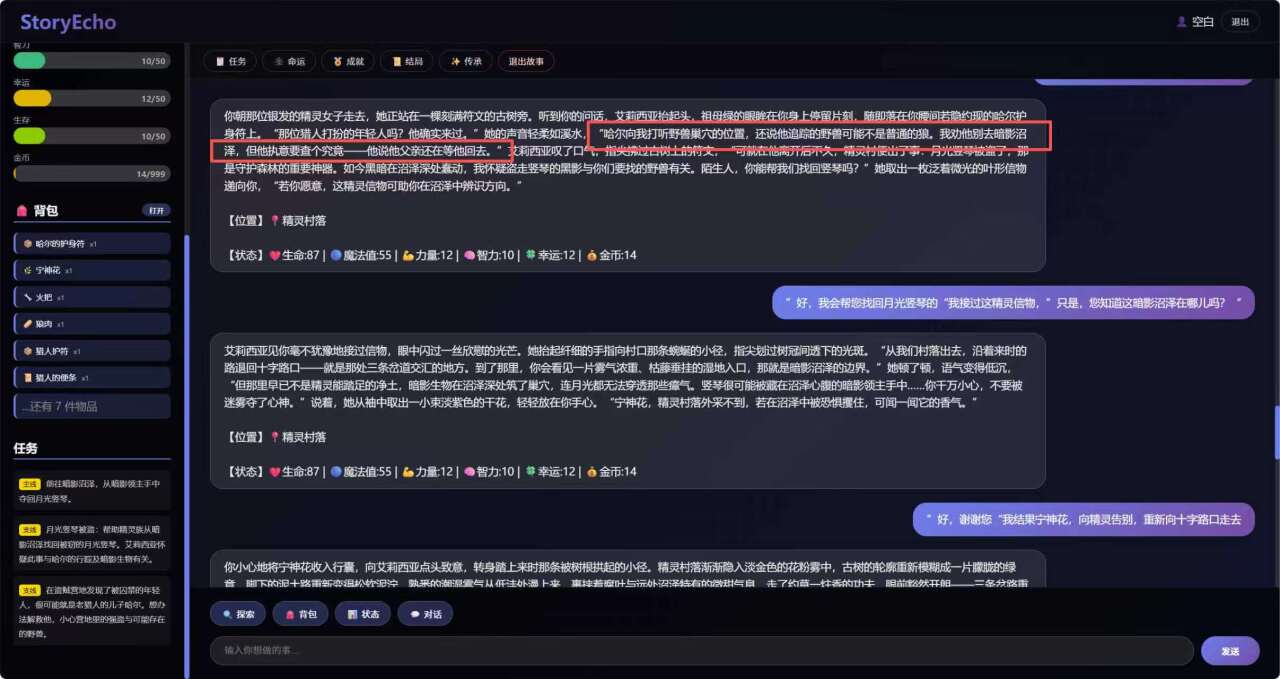
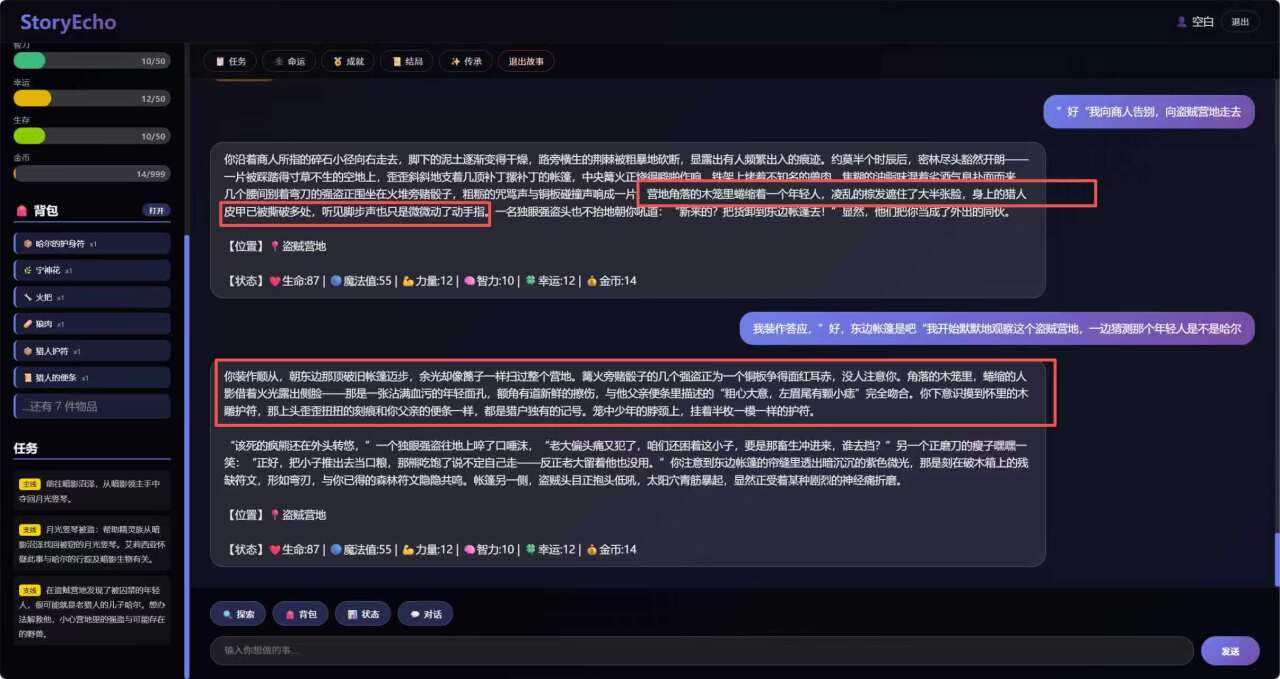
可以从图中看出,哈尔应该在暗影沼泽,但是当对话较长时,LLM就遗忘了,哈尔出现在了盗贼营地。
为了解决这个问题,我设计了 StoryEcho 的记忆管理系统。它不是一个单一的技术方案,而是一套分层递进的记忆架构,包含短期对话压缩、长期向量化记忆、以及结构化 RAG 知识库三个层次。
二、设计思路
我的设计思路是将“记忆”分为三个层次,各自承担不同的职责。
第一层是短期对话历史,直接拼接进提示词,负责保持当前回合的连贯性。我把最近十条消息截取前 200 个字符,确保上下文窗口不被撑爆。
第二层是长期记忆,使用向量数据库。当剧情推进到一定回合,我会调用 LLM 生成剧情摘要,然后将这段摘要连同元数据存入向量数据库。下次玩家行动时,系统会检索与当前情境最相关的历史摘要,拼接到提示词中。
第三层是RAG 知识库,存储的是静态的游戏设定——NPC 的性格特征、任务触发条件、敌人的弱点、结局的达成条件。这些内容在游戏设计阶段就已经确定,不需要 LLM 从零学习。
这个分层设计的好处是:短期记忆保证对话流畅,长期记忆保持剧情连贯,RAG 知识库确保设定不跑偏。三者各司其职,互不干扰。
三、分层初始化与降级策略
MemoryManager使用单例模式确保全局只有一个实例,避免重复初始化向量数据库造成资源浪费。在`__init__`方法中,系统按顺序执行三个关键步骤:配置ONNX Runtime的GPU加速、初始化向量存储、构建RAG文档库。
向量存储的初始化采用了渐进式降级策略。首先尝试加载ChromaDB作为主存储,使用PersistentClient实现数据持久化,数据目录位于数据库路径下的chroma_db文件夹中。创建两个集合时指定了余弦相似度作为距离度量(通过metadata中的"hnsw:space": "cosine"实现),这对于文本语义检索最为合适。如果ChromaDB因依赖缺失或环境问题初始化失败,系统会自动切换到FAISS后备方案。FAISS模式下,系统会检测可用的GPU数量并创建StandardGpuResources对象,将索引迁移到GPU执行相似度搜索以获得更好的性能。如果FAISS也不可用,最后的兜底是SQLite关键词匹配,虽然语义理解能力较弱,但确保了系统在任何环境下都能提供基础的检索功能。
嵌入模型的初始化同样考虑了GPU加速。系统先检测PyTorch的CUDA可用性,如果存在GPU则将SentenceTransformer模型加载到cuda设备上,否则使用CPU。同时通过ONNX Runtime配置CUDAExecutionProvider,设置2GB显存限制并启用cudnn卷积搜索优化,进一步加速向量化过程。
def __new__(cls):
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._initialized = False
return cls._instance
def __init__(self):
if self._initialized:
return
self._initialized = True
self.chroma_client = None
self.embedding_model = None
self.collections = {}
self._use_chroma = False
self._use_faiss = False
# 配置 ONNX Runtime 使用 GPU
if ONNX_AVAILABLE:
self._configure_onnx_runtime()
self._init_vector_store()
self._init_rag_documents()
def _configure_onnx_runtime(self):
"""配置 ONNX Runtime 使用 GPU"""
try:
# 设置 ONNX Runtime 会话选项
self.ort_options = ort.SessionOptions()
self.ort_options.graph_optimization_level = ort.GraphOptimizationLevel.ORT_ENABLE_ALL
# 设置提供者
self.ort_providers = DEFAULT_PROVIDERS
# 如果有 GPU,设置 GPU 设备 ID
if 'CUDAExecutionProvider' in self.ort_providers:
cuda_options = {
'device_id': 0,
'arena_extend_strategy': 'kNextPowerOfTwo',
'gpu_mem_limit': 2 * 1024 * 1024 * 1024, # 2GB
'cudnn_conv_algo_search': 'EXHAUSTIVE',
'do_copy_in_default_stream': True,
}
self.ort_providers = [('CUDAExecutionProvider', cuda_options), 'CPUExecutionProvider']
print("[Memory] ONNX Runtime configured with CUDA GPU")
except Exception as e:
print(f"[Memory] ONNX Runtime configuration failed: {e}")
self.ort_providers = ['CPUExecutionProvider']
def _init_vector_store(self):
"""初始化向量存储"""
# 初始化嵌入模型(配置 GPU)
if EMBEDDING_AVAILABLE:
try:
# 设置设备
import torch
if torch.cuda.is_available():
device = 'cuda'
print(f"[Memory] PyTorch CUDA available, using GPU: {torch.cuda.get_device_name(0)}")
else:
device = 'cpu'
print("[Memory] PyTorch CUDA not available, using CPU")
self.embedding_model = SentenceTransformer(DEFAULT_EMBEDDING_MODEL, device=device)
print(f"[Memory] Loaded embedding model: {DEFAULT_EMBEDDING_MODEL} on {device}")
except Exception as e:
print(f"[Memory] Failed to load embedding model: {e}")
self.embedding_model = None
# 尝试初始化 ChromaDB(配置 GPU 使用)
if CHROMA_AVAILABLE:
try:
# 使用持久化目录
chroma_dir = os.path.join(os.path.dirname(DB_PATH), "chroma_db")
os.makedirs(chroma_dir, exist_ok=True)
# ChromaDB 配置
settings = Settings(
anonymized_telemetry=False,
allow_reset=True
)
self.chroma_client = chromadb.PersistentClient(
path=chroma_dir,
settings=settings
)
self._use_chroma = True
print(f"[Memory] ChromaDB initialized at {chroma_dir}")
# 获取或创建集合
for coll_name in [COLLECTION_RAG, COLLECTION_HISTORY]:
try:
self.collections[coll_name] = self.chroma_client.get_or_create_collection(
name=coll_name,
metadata={"hnsw:space": "cosine"}
)
except Exception as e:
print(f"[Memory] Failed to create collection {coll_name}: {e}")
except Exception as e:
print(f"[Memory] ChromaDB init failed: {e}, using FAISS fallback")
self._use_chroma = False
# 如果 ChromaDB 不可用,使用 FAISS + SQLite 作为后备
if not self._use_chroma:
self._init_faiss_fallback()
def _init_faiss_fallback(self):
"""初始化 FAISS 后备存储(支持 GPU)"""
self._use_faiss = True
self._faiss_embeddings = {}
self._faiss_metadata = {}
# 尝试加载 FAISS(支持 GPU)
try:
import faiss
# 检查是否有 GPU
if hasattr(faiss, 'get_num_gpus'):
gpu_count = faiss.get_num_gpus()
if gpu_count > 0:
print(f"[Memory] FAISS found {gpu_count} GPU(s)")
# 使用 GPU 资源
res = faiss.StandardGpuResources()
self.faiss_gpu_res = res
self.faiss_use_gpu = True
else:
self.faiss_use_gpu = False
else:
self.faiss_use_gpu = False
self.faiss = faiss
print("[Memory] FAISS fallback initialized" + (" with GPU support" if self.faiss_use_gpu else " (CPU only)"))
except ImportError:
print("[Memory] FAISS not available, using simple keyword search")
self.faiss = None
self.faiss_use_gpu = False
def _get_embedding(self, text: str) -> Optional[List[float]]:
"""获取文本的嵌入向量(自动使用 GPU)"""
if self.embedding_model:
try:
# sentence-transformers 会自动使用 GPU(如果可用)
return self.embedding_model.encode(text).tolist()
except Exception as e:
print(f"[Memory] Embedding failed: {e}")
return None
def _init_rag_documents(self):
"""初始化 RAG 知识库文档"""
# 检查是否已初始化
if self._use_chroma:
try:
count = self.collections[COLLECTION_RAG].count()
if count > 0:
print(f"[Memory] RAG already has {count} documents")
return
except Exception:
pass
# 准备文档
documents = self._build_rag_documents()
# 批量添加
for doc in documents:
self.add_document(
collection=COLLECTION_RAG,
text=doc["text"],
metadata=doc["metadata"]
)
print(f"[Memory] Added {len(documents)} RAG documents")四、多源知识库的自动化构建
`_build_rag_documents`方法是整个RAG系统的知识来源,它从八个数据源自动提取信息并转换为结构化文档,将游戏设计数据(NPC、任务、敌人等静态配置)自动转化为LLM可理解的自然语言描述。
具体来说,系统会遍历game_data.py中的NPCS字典,为每个NPC生成包含身份、性格、喜好厌恶、好感度阈值、对话风格的文档。对于主线任务和支线任务,系统提取任务ID、描述、目标列表和奖励信息,其中支线任务还会标注属性需求(如需要力量≥10才能完成某个目标)。敌人数据从story_enemy_catalog中读取,记录敌人的生命值、攻击力、出现区域、遭遇描述和掉落概率。世界观文档内置了奇幻和科幻两个故事线的背景设定,结局数据则包含达成条件和结局叙事文本。此外系统还会尝试加载天赋和成就数据,这些数据虽然不直接参与剧情生成,但为后续的角色养成系统提供了知识基础。
值得注意的是,每个文档都附带丰富的元数据标签,包括category(分类,如npc、quest、enemy)、story_id(所属故事线)、name(实体名称)等。这些元数据在检索时虽然不直接参与向量计算,但在构建上下文时可以用于去重和过滤,避免同一段知识被重复注入LLM。
def _build_rag_documents(self) -> List[Dict]:
"""构建 RAG 文档列表"""
documents = []
# 1. 世界观文档
documents.extend([
{
"text": """
【迷雾森林世界观】
远古时代,生命之树生长在森林深处,守护着整片大陆的生命力。
三位远古守护者誓言保护生命之树永不衰落。
但一次意外的黑暗入侵改变了一切——其中一位守护者被黑暗力量腐蚀,化为暗影领主,试图用暗影吞没生命之树。
生命之树节节败退,其力量不断被黑暗侵蚀,森林日渐衰落。
精灵族、人类冒险者都在积极寻找能够拯救森林的英雄。
""",
"metadata": {"category": "worldview", "story_id": "fantasy_001", "title": "迷雾森林世界观"}
},
{
"text": """
【赛博世界观】
2077年,新东京市。你是一名记忆被植入的义体人,醒来时发现自己躺在废弃的实验舱中。
一个神秘的声音告诉你:你是第7号实验体,你的记忆是假的,但你有能力改变这座城市的命运。
高级AI研究所发现了远古的生命源质库。但一个失控的AI实验导致黑暗代码入侵,
生命源质库的核心系统开始衰落。只有通过重启系统、击败黑暗代码或与其达成协议,才能拯救整个研究所。
""",
"metadata": {"category": "worldview", "story_id": "scifi_001", "title": "赛博世界观"}
}
])
# ========== 2. NPC 信息(从 game_data.NPCS 读取)==========
try:
from .game_data import NPCS
for name, data in NPCS.items():
doc_text = f"""
【NPC】{name}
身份: {data.get('id', '')}
性格: {data.get('character_trait', '经验丰富')}
喜好: {', '.join(data.get('likes', []))}
厌恶: {', '.join(data.get('dislikes', []))}
初始好感: {data.get('initial_affinity', 0)}
所在位置: {data.get('location', '未知')}
【好感度阈值】
"""
thresholds = data.get('affinity_thresholds', {})
for affinity, narrative in thresholds.items():
doc_text += f"- 好感度 {affinity}: {narrative}\n"
doc_text += f"""
【对话风格】{data.get('dialogue_style', '自然对话')}
【问候语】{data.get('dialogue', {}).get('greeting', '你好。')}
【告别语】{data.get('dialogue', {}).get('farewell', '再见。')}
"""
documents.append({
"text": doc_text,
"metadata": {"category": "npc", "name": name, "story_id": "fantasy_001"}
})
except Exception as e:
print(f"[Memory] 加载 NPC 数据失败: {e}")
# ========== 3. 主线任务 ==========
try:
from .game_data import MAIN_QUESTS
for qid, quest in MAIN_QUESTS.items():
doc_text = f"""
【主线任务】{quest.get('name')}
任务ID: {qid}
描述: {quest.get('description')}
【任务目标】
"""
for obj in quest.get('objectives', []):
doc_text += f"- {obj.get('description')}\n"
doc_text += f"""
【任务奖励】
经验: {quest.get('rewards', {}).get('exp', 0)}
金币: {quest.get('rewards', {}).get('gold', 0)}
物品: {quest.get('rewards', {}).get('item', '无')}
"""
documents.append({
"text": doc_text,
"metadata": {"category": "quest", "type": "main", "quest_id": qid, "story_id": "fantasy_001"}
})
except Exception as e:
print(f"[Memory] 加载主线任务失败: {e}")
# ========== 4. 支线任务 ==========
try:
from .game_data import SIDE_QUESTS
for qid, quest in SIDE_QUESTS.items():
doc_text = f"""
【支线任务】{quest.get('name')}
任务ID: {qid}
触发NPC: {quest.get('trigger_npc', '无')}
触发条件: {quest.get('trigger_condition', '到达指定地点')}
描述: {quest.get('description')}
【任务目标】
"""
for obj in quest.get('objectives', []):
need_info = ""
if obj.get('need_strength'):
need_info = f" (需要力量≥{obj['need_strength']})"
elif obj.get('need_agility'):
need_info = f" (需要敏捷≥{obj['need_agility']})"
elif obj.get('need_intelligence'):
need_info = f" (需要智力≥{obj['need_intelligence']})"
doc_text += f"- {obj.get('description')}{need_info}\n"
doc_text += f"""
【任务奖励】
经验: {quest.get('rewards', {}).get('exp', 0)}
金币: {quest.get('rewards', {}).get('gold', 0)}
物品: {quest.get('rewards', {}).get('item', '无')}
"""
documents.append({
"text": doc_text,
"metadata": {"category": "quest", "type": "side", "quest_id": qid, "story_id": "fantasy_001"}
})
except Exception as e:
print(f"[Memory] 加载支线任务失败: {e}")
# ========== 5. 结局数据 ==========
try:
from .game_data import ENDINGS
for eid, ending in ENDINGS.items():
doc_text = f"""
【结局】{ending.get('name')}
结局ID: {eid}
类型: {ending.get('type', 'main')}
条件: {ending.get('condition', '特定条件')}
描述: {ending.get('description', '')}
【结局叙事】
{ending.get('ending_text', '')[:500]}
"""
documents.append({
"text": doc_text,
"metadata": {"category": "ending", "ending_id": eid, "story_id": "fantasy_001"}
})
except Exception as e:
print(f"[Memory] 加载结局数据失败: {e}")
# ========== 6. 敌人数据 ==========
try:
from .story_enemy_catalog import FANTASY_001_ENEMIES
for enemy in FANTASY_001_ENEMIES:
doc_text = f"""
【敌人】{enemy.get('name')}
敌人ID: {enemy.get('enemy_id')}
分类: {enemy.get('category')}
等级: {enemy.get('tier')}
基础生命: {enemy.get('base_hp')}
基础攻击: {enemy.get('base_attack')}
默认难度: {enemy.get('default_difficulty')}
【出现区域】
{', '.join(enemy.get('nodes', []))}
【遭遇描述】
{enemy.get('encounter_text', '')}
【掉落物品】
"""
for loot in enemy.get('loot', []):
doc_text += f"- {loot.get('item')} (概率: {loot.get('chance', 0)*100:.0f}%)\n"
documents.append({
"text": doc_text,
"metadata": {"category": "enemy", "enemy_id": enemy.get('enemy_id'), "story_id": "fantasy_001"}
})
except Exception as e:
print(f"[Memory] 加载敌人数据失败: {e}")
# ========== 7. 天赋数据(可选)==========
try:
from .character_data import TALENTS_DATA
for story_id, talents in TALENTS_DATA.items():
for talent in talents:
doc_text = f"""
【天赋】{talent.get('name')}
天赋ID: {talent.get('talent_id')}
稀有度: {talent.get('rarity')}
描述: {talent.get('description')}
解锁条件: {talent.get('unlock_condition')}
效果: {talent.get('effects')}
"""
documents.append({
"text": doc_text,
"metadata": {"category": "talent", "story_id": story_id}
})
except Exception as e:
print(f"[Memory] 加载天赋数据失败: {e}")
# ========== 8. 成就数据(可选)==========
try:
from .character_data import STORY_ACHIEVEMENTS_DATA
for story_id, achievements in STORY_ACHIEVEMENTS_DATA.items():
for ach in achievements:
import json
doc_text = f"""
【成就】{ach.get('name')}
成就ID: {ach.get('story_achievement_id')}
分类: {ach.get('category')}
描述: {ach.get('description')}
条件: {json.dumps(ach.get('condition', {}), ensure_ascii=False)}
"""
documents.append({
"text": doc_text,
"metadata": {"category": "achievement", "story_id": story_id}
})
except Exception as e:
print(f"[Memory] 加载成就数据失败: {e}")
return documents除了从 `game_data.py`、`story_enemy_catalog` 等代码模块中批量提取知识外,`_build_rag_documents` 方法还支持加载手工编写的结构化知识文件,用于补充 LLM 不易自动推理的细节设定。
knowledge.json 文件,定义了以下三类关键信息:物品说明,NPC 关系,隐藏结局条件。
[
{
"title": "重要物品说明",
"category": "item",
"text": "月光竖琴是精灵族最古老的神器,由生命之树的枝干制成。琴弦由月见藤编织,只在满月时发出最纯净的声音。它拥有净化黑暗、沟通自然的力量。",
"keywords": ["月光竖琴", "精灵", "神器"]
},
{
"title": "关键NPC关系",
"category": "relationship",
"text": "老猎人曾是王国最强的猎人,他的儿子哈尔在一次森林探险中失踪。老猎人与精灵族有旧交,年轻时曾救过一位精灵长老。",
"keywords": ["老猎人", "哈尔", "关系"]
},
{
"title": "隐藏结局条件",
"category": "ending",
"text": "真正的和平结局需要:1) 完成净化之泉支线,2) 帮助盗贼解除控制,3) 与暗影好感度≥50,4) 智力≥30,5) 在最终战斗中选择谈判而非攻击。",
"keywords": ["隐藏结局", "和平结局", "条件"]
}
]`worldview.md` 文档则提供了完整的世界观背景,包括森林的起源、三大守护者、暗影领主的堕落过程、精灵族历史等。这些内容会被转换为向量文档,与 `knowledge.json` 中的条目一起存入 ChromaDB 或 FAISS 中,供剧情引擎在运行时检索。
# backend/rag_documents/worldview.md
## 迷雾森林的传说 - 详细世界观
### 森林的起源
迷雾森林是远古时期生命之树坠落的一片叶子所化。传说中,生命之树是宇宙生命力的源泉,它的每一片叶子都化作了一片森林。
### 三大守护者
1. **艾尔文(智慧守护者)** - 掌握森林的知识与记忆,居住在精灵圣殿
2. **布鲁诺(力量守护者)** - 守护森林的物理边界,抵挡外敌入侵
3. **塞拉斯(平衡守护者)** - 维持森林的光暗平衡,后被黑暗腐蚀成为暗影领主
### 暗影领主的堕落
塞拉斯在一次与深渊魔王的战斗中受了重伤,黑暗能量侵入他的灵魂。虽然战斗胜利,但他再也无法摆脱黑暗的侵蚀。最终,他成为了暗影领主,试图用黑暗吞没生命之树。
### 精灵族的历史
精灵族是生命之树的第一批守护者。他们从生命之树的汁液中诞生,拥有与自然沟通的能力。精灵公主艾莉西亚是现任精灵族的领袖,她的母亲在上一场暗影战争中牺牲。通过融合 代码配置 + JSON 结构化知识 + Markdown 世界观文本三种来源,RAG 系统既保证了游戏机制的正确性,也保留了叙事的深度与一致性。
五、检索与上下文注入的双通道设计
检索逻辑由`retrieve`方法实现,它优先使用ChromaDB的query接口进行语义搜索。ChromaDB内部使用HNSW(层次化可导航小世界)算法构建索引,检索时间复杂度为O(log N),适合实时游戏场景。返回结果时,系统将距离(distances)转换为相似度分数(1 - distance),方便上层判断相关性。
def retrieve(self, collection: str, query: str, k: int = 3) -> List[Dict[str, Any]]:
"""检索最相关的文档"""
if not query:
return []
results = []
# ChromaDB 检索
if self._use_chroma and collection in self.collections:
try:
response = self.collections[collection].query(
query_texts=[query],
n_results=k
)
if response and response.get('documents'):
for i, doc in enumerate(response['documents'][0]):
meta = response.get('metadatas', [[]])[0][i] if response.get('metadatas') else {}
results.append({
"text": doc,
"metadata": meta,
"score": 1 - (response.get('distances', [[]])[0][i] if response.get('distances') else 0)
})
return results
except Exception as e:
print(f"[Memory] ChromaDB retrieval failed: {e}")
# FAISS 检索(支持 GPU)
if self._use_faiss and self._faiss_embeddings:
query_embedding = self._get_embedding(query)
if query_embedding is not None and self.faiss:
try:
embeddings_list = list(self._faiss_embeddings.values())
if embeddings_list:
embeddings_array = np.array(embeddings_list).astype('float32')
# 使用 GPU 索引(如果可用)
if hasattr(self, 'faiss_use_gpu') and self.faiss_use_gpu:
# 创建 GPU 索引
index = self.faiss.index_factory(embeddings_array.shape[1], "Flat", self.faiss.METRIC_INNER_PRODUCT)
gpu_index = self.faiss.index_cpu_to_gpu(self.faiss_gpu_res, 0, index)
gpu_index.add(embeddings_array)
index_to_use = gpu_index
else:
index = self.faiss.IndexFlatIP(embeddings_array.shape[1])
index.add(embeddings_array)
index_to_use = index
query_vec = np.array([query_embedding]).astype('float32')
scores, indices = index_to_use.search(query_vec, min(k, len(embeddings_list)))
doc_ids = list(self._faiss_embeddings.keys())
for score, idx in zip(scores[0], indices[0]):
if idx >= 0 and idx < len(doc_ids):
doc_id = doc_ids[idx]
doc_data = self._faiss_metadata.get(doc_id, {})
results.append({
"text": doc_data.get("text", ""),
"metadata": doc_data.get("metadata", {}),
"score": float(score)
})
except Exception as e:
print(f"[Memory] FAISS retrieval failed: {e}")
# SQLite 关键词检索(后备)
if not results:
results = self._sqlite_keyword_search(collection, query, k)
return results如果ChromaDB不可用,FAISS后备方案会动态创建索引。对于GPU环境,系统使用index_factory创建Flat索引,然后通过index_cpu_to_gpu迁移到GPU;CPU环境则直接使用IndexFlatIP(内积索引)。这种设计在文档数量较少时性能足够,且实现简单。
在上下文构建环节,`build_rag_context`和`build_history_context`两个函数分别处理知识库检索和历史记忆检索,形成了双通道的上下文增强。`build_rag_context`将用户输入、故事ID和当前节点名拼接成查询语句,检索后通过seen_categories集合对同类文档去重,截取前300字符生成知识库参考块。`build_history_context`则先获取最近8回合的剧情摘要,再通过向量检索召回与当前查询语义相关的历史片段,两者合并后按回合倒序排列。这种混合策略既保证了近期记忆的权重,又能召回早期但语义相关的重要剧情节点。
def build_rag_context(state: Dict, user_input: str) -> str:
"""构建 RAG 上下文块(供 story_engine 调用)"""
manager = get_memory_manager()
story_id = state.get("story_id", "fantasy_001")
current_node = state.get("current_node", "")
query = f"{user_input} {story_id} {current_node}"
documents = manager.retrieve(COLLECTION_RAG, query, k=3)
if not documents:
return ""
context_parts = ["\n【知识库参考】"]
seen_categories = set()
for doc in documents:
text = doc.get("text", "")
meta = doc.get("metadata", {})
category = meta.get("category", "")
category_key = f"{category}_{text[:50]}"
if category_key in seen_categories:
continue
seen_categories.add(category_key)
if text and len(text) > 20:
snippet = text[:300] + "..." if len(text) > 300 else text
context_parts.append(f"- {snippet}")
return "\n".join(context_parts) if len(context_parts) > 1 else ""
def build_history_context(state: Dict, user_input: str) -> str:
"""构建历史记忆上下文块"""
manager = get_memory_manager()
session_id = state.get("session_id") or state.get("user_id", "")
if not session_id:
return ""
query = f"{user_input} {state.get('current_node', '')}"
history = manager.retrieve_history(session_id, query, k=3, recent_turns=8)
if not history:
return ""
context_parts = ["\n【剧情回顾】"]
for item in history:
text = item.get("text", "")
meta = item.get("metadata", {})
turn = meta.get("turn", "")
if text:
clean_text = text.replace("[回合", "").replace(f"回合 {turn}]", "").strip()
if len(clean_text) > 200:
clean_text = clean_text[:200] + "..."
context_parts.append(f"• {clean_text}")
return "\n".join(context_parts) if len(context_parts) > 1 else ""六、长期记忆的生命周期管理
长期记忆系统通过`add_summary`方法实现,在每5个回合后由story_engine触发。该方法会调用LLM生成当前剧情的摘要(限制150字以内),然后执行双写操作:一方面通过add_document将摘要存入ChromaDB的history_summaries集合,同时写入SQLite的session_summaries表作为冗余备份。摘要文本格式化为"[回合 N] 摘要内容",元数据中记录了session_id、turn、timestamp和context(当前场景和节点信息)。
def add_summary(self, session_id: str, turn: int, summary: str, context: Dict = None) -> None:
"""添加剧情摘要到长期记忆"""
if not summary or len(summary) < 30:
return
metadata = {
"session_id": session_id,
"turn": turn,
"timestamp": datetime.now().isoformat(),
"context": json.dumps(context or {})
}
doc_text = f"[回合 {turn}] {summary}"
self.add_document(COLLECTION_HISTORY, doc_text, metadata)
self._store_summary_to_sqlite(session_id, turn, summary, metadata)检索历史时,`retrieve_history`方法体现了精心设计的融合策略。它先调用`_get_recent_summaries`从SQLite获取最近N条摘要(默认10条),这些摘要按turn降序排列,score设为1.0表示高置信度。然后进行向量检索,将召回的历史摘要与已有结果基于text去重后追加。最终结果按回合数降序排序并截取k+2条(比请求多2条以提供更丰富的上下文)。这种设计确保了LLM既能获得最近的剧情进展,又能通过语义匹配找到关键的历史事件。
def retrieve_history(self, session_id: str, query: str, k: int = 3, recent_turns: int = 10) -> List[Dict]:
"""检索历史摘要(结合向量检索和最近上下文)"""
results = []
recent_summaries = self._get_recent_summaries(session_id, recent_turns)
results.extend(recent_summaries)
if query:
vector_results = self.retrieve(COLLECTION_HISTORY, query, k)
existing_texts = {r.get("text") for r in results}
for vr in vector_results:
if vr.get("text") not in existing_texts:
results.append(vr)
results.sort(key=lambda x: x.get("metadata", {}).get("turn", 0), reverse=True)
return results[:k + 2]七、与剧情引擎的集成逻辑
在story_engine.py的`_build_user_prompt`方法中,系统通过调用`build_rag_context`和`build_history_context`将检索到的知识注入LLM的提示词。注入位置在用户行动描述、动态上下文、任务进度之后,但在具体剧情回顾之前。先让LLM了解当前场景和任务,再提供知识库参考(世界观、NPC信息等),最后回顾历史剧情,形成从静态知识到动态记忆的递进。
def _build_user_prompt(self, state: StoryState, template: Dict, history_text: str) -> str:
"""构建用户提示词(增强版,包含 RAG 和记忆)"""
last_action = self._get_last_user_action(state)
user_id = state.get("user_id", "anonymous")
active_quests = self.quest_manager.get_active_quests_for_prompt(user_id)
current_node = state.get("current_node", "node_entrance")
# 获取 RAG 上下文
rag_context = build_rag_context(state, last_action) if MEMORY_AVAILABLE else ""
# 获取历史记忆上下文
history_context = build_history_context(state, last_action) if MEMORY_AVAILABLE else ""
return f"""【玩家行动】{last_action}
{self.dynamic_provider.get_current_context(state)}
{self.dynamic_provider.get_main_quest_progress(state)}
{active_quests}
{self.dynamic_provider.get_node_info(current_node, state)}
{self._recent_combat_hint(state)}
{self._build_combat_pending_hint(state)}
{self._item_use_hint()}
{rag_context}
{history_context}
【剧情回顾】
{history_text[-800:] if history_text else "游戏刚开始"}
请根据玩家行动续写剧情,推动任务进度,并在合适时触发支线任务。严格输出 JSON。"""此外,MemoryManager还提供了`get_full_history`和`clear_session_history`等辅助方法,用于调试和会话管理。在实际运行中,系统会检测是否成功导入memory_manager模块,如果不可用则提供空的上下文构建函数作为降级,确保剧情引擎在无记忆支持时仍能正常运行。
八、性能优化
系统利用ONNX Runtime为嵌入模型提供GPU加速。在检测到CUDAExecutionProvider可用时,会设置2GB的GPU显存限制并启用cudnn卷积搜索优化,SentenceTransformer模型会被加载到cuda设备上。ChromaDB本身不直接使用GPU,但其底层的HNSW索引在CPU上运行性能已足够,真正耗时的向量化过程由GPU加速的嵌入模型完成。此外,系统还实现了简单的文档去重逻辑,避免同一段知识在单次请求中被重复注入LLM上下文,有效控制了Token消耗。
九、效果展示
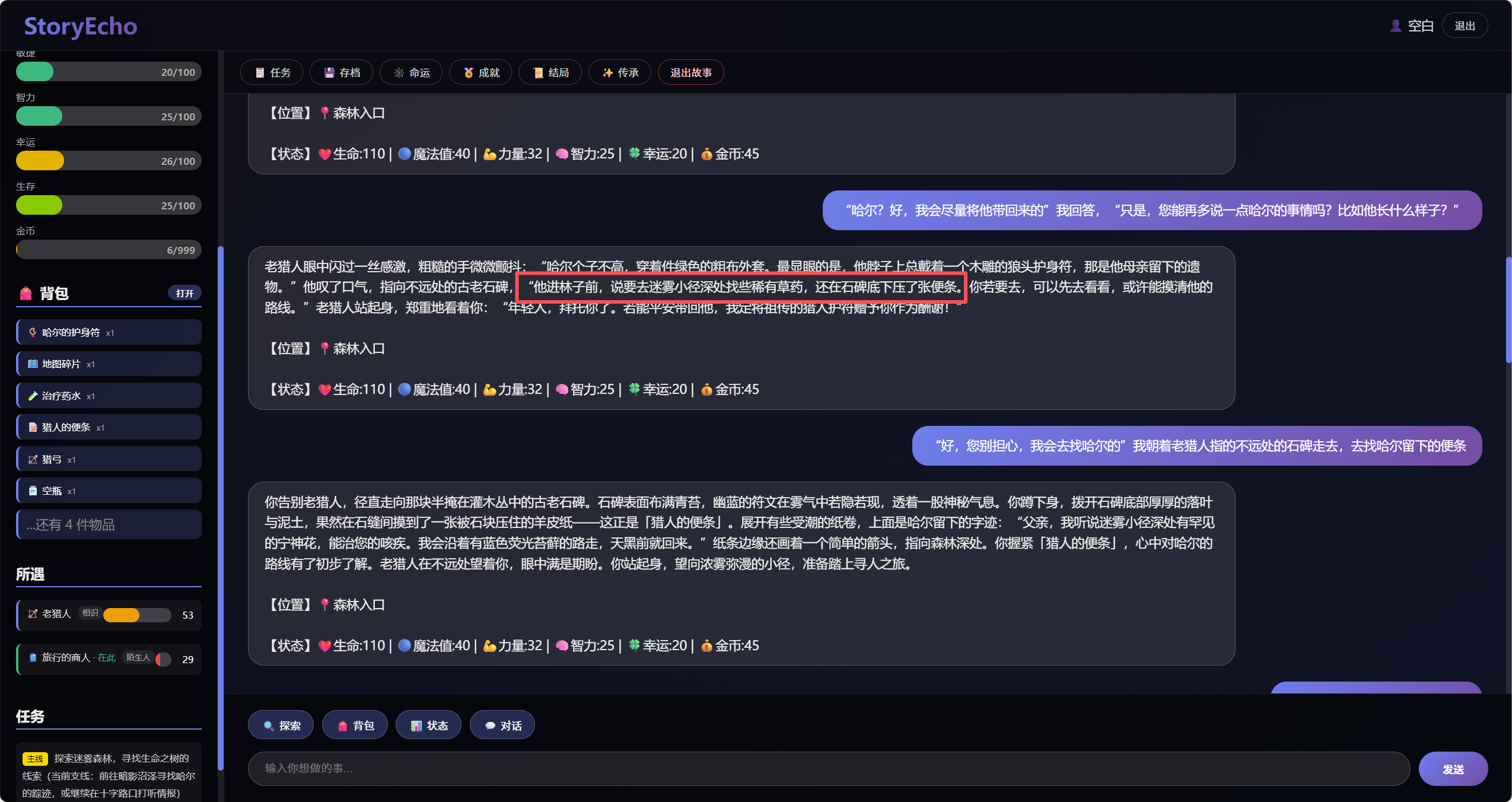
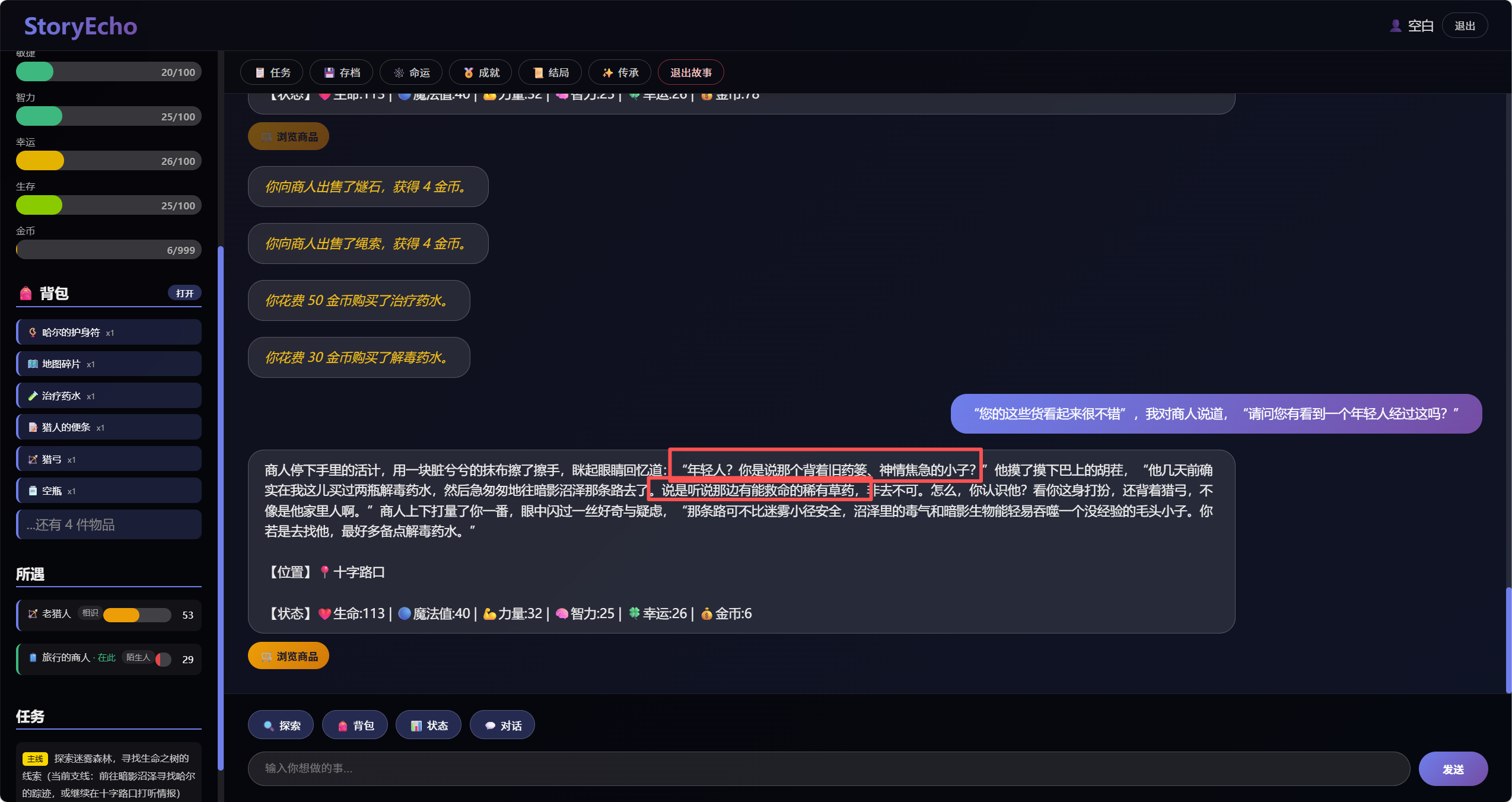
可以看出在刚进入游戏时,老猎人告诉我他儿子是去找草药的,等对话到后面,向商人询问时,商人也说有个年轻人是去找草药的,和前文大模型回复的故事情节一致,说明实现了长期记忆功能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)