基于机器学习算法的外卖评论分析与可视化系统
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主。
外卖评价不是简单的几句好坏反馈,里面藏着用户对口味、速度、包装、服务、价格的真实态度。店铺每天都在接收大量评论,如果只靠人工翻看,很容易漏掉共性问题,也很难把差评背后的原因整理成可以执行的改进方向。这个系统要做的事很直接:把美团外卖评论采集下来,经过清洗、分词、主题提取和情感识别之后,用图表和词云把用户关注点展示出来,让商家能够快速看懂问题,也让学生项目具备更完整的工程展示效果。
整个项目不是单独跑一个模型,而是把数据采集、文本预处理、主题挖掘、情感分类、结果可视化、用户登录与权限管理串成了一条完整链路。前面有爬虫和数据库,后面有 Flask 页面展示,中间又加入 TF-IDF、UMAP、LDA、BERT-wwm 等算法模块,整体更像一个可运行、可展示、可扩展的小型评论分析平台。
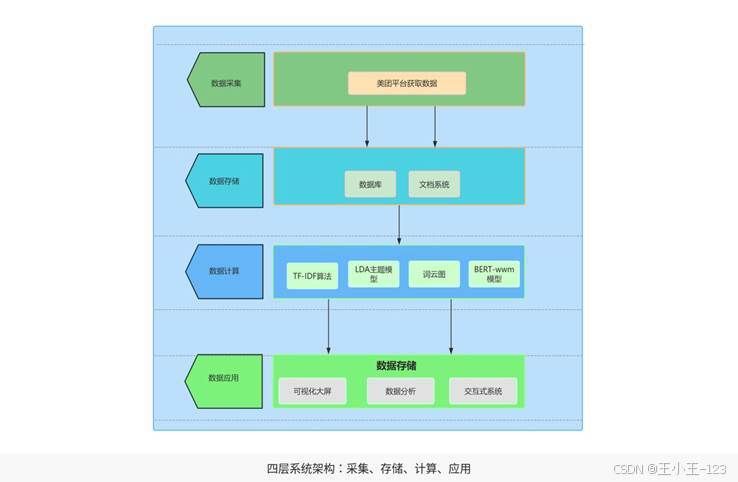
图1 系统整体架构展示
一、项目背景:评论数据要从“看得见”变成“看得懂”
外卖平台的评价数据增长很快,一条评论往往同时包含口味、配送、服务、包装、价格等多个信号。对普通消费者来说,评论可以辅助点餐;对商家来说,评论更像一份连续更新的经营反馈。项目选择外卖评论作为分析对象,主要是因为这个场景数据量大、文本口语化明显、情感表达直接,非常适合做文本挖掘和可视化展示。
系统围绕“采集数据 - 清洗文本 - 提取主题 - 判断情绪 - 页面展示”展开。数据端从外卖平台评论入手,算法端负责把碎片化评论转换成主题和情感结果,展示端则用词云、指标图、聚类图、混淆矩阵和用户管理页面来体现系统效果。这样既能展示自然语言处理能力,也能体现 Web 系统开发和数据库设计能力。
项目比较适合用作数据科学、大数据技术、人工智能应用、Python Web 开发等方向的综合实践。它的亮点在于:不是只停留在“评论分词”和“画一张词云”,而是加入了 LDA 主题模型和 BERT-wwm 情感分类,并把结果接入系统页面,形成了相对完整的数据应用闭环。
二、技术路线:从原始评论到可视化看板
项目技术路线可以拆成四个层次。第一层是数据采集,主要负责获取店铺、用户、评分、评论内容、评论时间、配送满意度、菜品满意度等字段;第二层是数据存储,使用 XLS/CSV 作为中间文件,并将清洗后的数据导入 MySQL;第三层是数据计算,完成中文分词、停用词过滤、TF-IDF 权重计算、LDA 主题挖掘、UMAP 降维和 BERT-wwm 情感分类;第四层是数据应用,通过 Flask、Pandas、WordCloud、PyLDAvis 等工具完成页面渲染和结果展示。
采集环节主要采用 Python 爬虫思路,结合请求头、代理、异常重试、分页解析等策略来提高稳定性。部分需要模拟浏览器行为的场景,可以使用 Selenium 辅助处理。获取到的数据会先进入结构化整理阶段,再进入模型分析阶段,避免原始网页文本直接进入模型造成噪声过大。
文本处理部分使用 jieba 对中文评论进行分词,并结合外卖领域词典和哈工大停用词表去除无意义词汇。清洗后的文本再使用 TF-IDF 计算词项权重,帮助筛出更能代表评论主题的关键词。为了观察评论文本在语义空间中的分布,项目还加入 UMAP 降维和 HDBSCAN 聚类展示,让文本从高维向量变成直观的二维分布图。
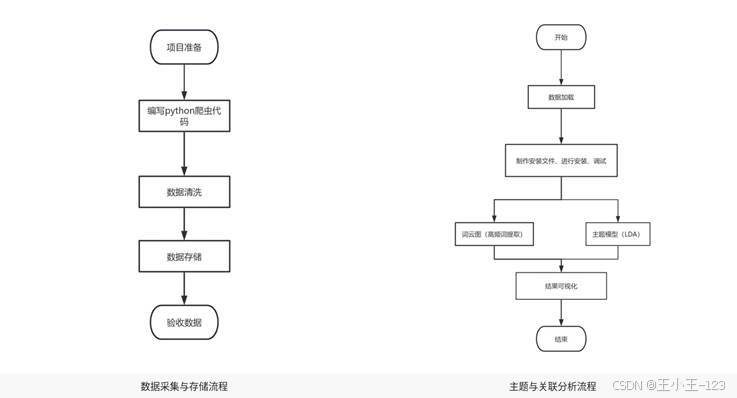
图2 数据采集、存储与主题分析流程
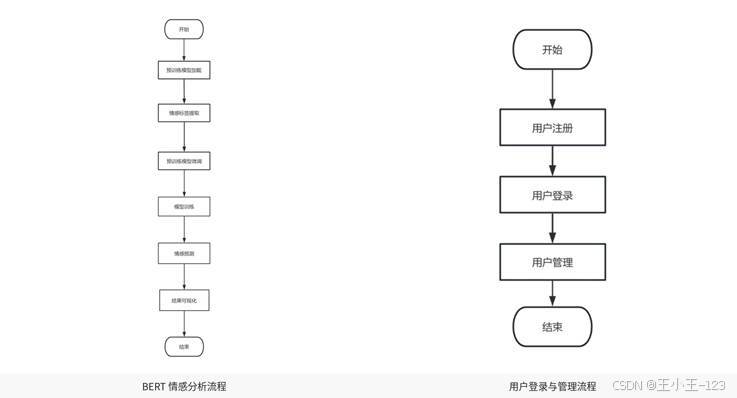
图3 情感分析与系统管理流程
三、数据采集与预处理:把杂乱评论整理成可分析数据
外卖评论最麻烦的地方在于文本短、口语化强、错别字和重复词多。比如“味道还行”“送得太慢”“包装不错”“一点都不值”这些评论看起来很简单,但真正做模型分析时,需要先统一格式、去掉无效字符、处理空值,再进行分词和停用词过滤。项目中使用 pandas 读取和整理数据,结合正则表达式处理异常内容,将时间、评分、满意度、店铺类型等字段统一成后续可以分析的格式。
预处理不是可有可无的一步。评论文本如果没有清洗,词云会被大量无效词占据,主题模型也容易把“哈哈”“这个”“就是”等词当作高频主题。项目中先进行缺失值处理,再对评论内容进行分词,保留更有业务含义的词语,例如“好吃”“太慢”“准时”“包装”“份量”“差评”等。这样后面的 LDA 主题模型和 BERT 情感分类才能更稳定地工作。
从数据展示角度看,预处理结果可以让读者一眼看到项目不是凭空分析,而是有完整的数据输入和处理链路。原始数据表展示了评论字段结构,分词结果展示了清洗前后的文本变化,这类图片非常适合放在项目展示页中,能快速证明系统数据来源和处理过程是完整的。
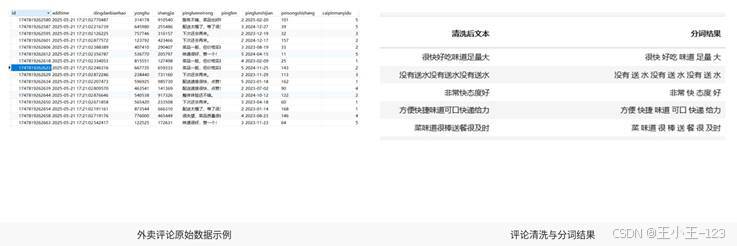
图4 评论数据与分词结果展示
四、LDA 主题挖掘:从好评和差评中拆出用户关注点
评论分析不能只看正负面比例,还要知道用户为什么满意、为什么不满意。项目使用 LDA 主题模型对评论进行主题挖掘,把大量评论拆分成多个潜在主题。好评部分提取了 5 类主题,主要集中在味道、速度、份量、价格和态度;差评部分提取了 4 类主题,主要集中在味道、速度、份量和服务态度。
好评主题中,“不错、棒棒、好喝、喜欢、新鲜、挺好吃”等词说明用户对餐品口味和整体体验较为敏感;“太快、速度、提前、准时”等词说明配送效率会直接影响好评;“包装、好多、给力、太少”等词可以反映份量与包装体验;“性价比、优惠、平价、便宜”等词可以帮助商家判断价格策略;“谢谢、贴心、感谢、给力”等词则指向骑手和店铺服务。
差评主题更容易暴露问题。比如“难吃、垃圾、不好、恶心”这类词对应餐品质量;“小时、分钟、超时、准时”对应配送时效;“好少、半个、一点、太少”对应份量不足;“失望、差评、不值、不好”对应用户整体不满。把这些词拆成主题之后,商家可以更快定位问题,不需要从上千条评论里逐条翻找。

图5 好评 LDA 主题词云组合

图6 差评 LDA 主题词云组合
五、BERT-wwm 情感分析:让评论自动分成正负倾向
主题模型负责回答“大家在讨论什么”,情感模型负责回答“大家态度如何”。项目使用中文 BERT-wwm 模型完成情感分类。BERT-wwm 的优势在于能够结合上下文理解句子,不只是简单匹配情感词。例如“这次终于不慢了”和“这次又慢了”都出现了“慢”,但表达的态度完全不同,预训练模型更适合处理这类语义差异。
模型训练阶段会先加载中文预训练权重,再将处理后的评论文本转换成模型可识别的输入格式。为了保证输入长度统一,文本会经过截断和填充处理。预测阶段使用 PyTorch 推理接口输出分类结果,再统计正负评论比例、置信度和各类指标。项目中的模型整体准确率约为 88.53%,ROC 曲线下的 AUC 约为 0.893,说明模型具备比较稳定的区分能力。
从分类指标看,负面类别的 Precision 约为 95.35%,Recall 约为 87.03%,F1 约为 91.00%;正面类别的 Precision 约为 77.94%,Recall 约为 91.52%,F1 约为 84.19%。这说明模型对负面评论判断更谨慎,对正面评论召回能力较强。对于实际业务展示来说,准确率、混淆矩阵、ROC 曲线和预测占比图都能很好地支撑项目可信度。
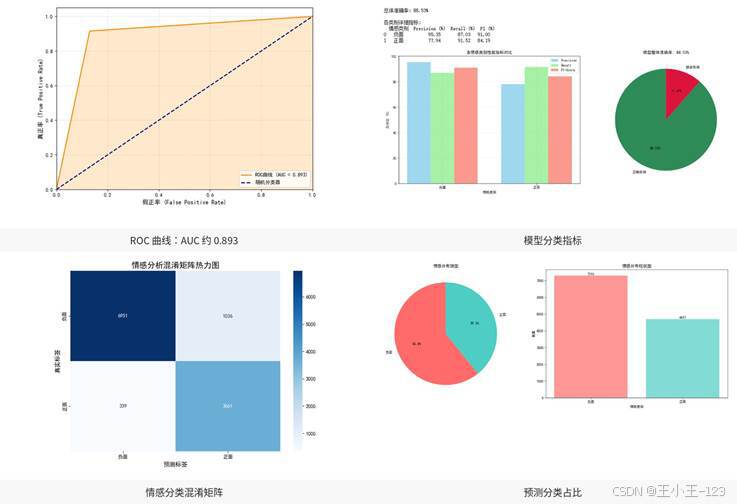
图7 BERT-wwm 情感分类模型评估结果
六、可视化展示:让结果更适合呈现和传播
可视化是这个项目的展示重点。单纯把模型结果输出成 CSV 文件,读者很难直观看到效果;换成词云、主题图、聚类图和仪表图之后,项目完成度会明显提升。系统中总评论词云用于观察整体高频词,好评词云用于展示用户满意点,差评词云用于暴露用户吐槽点,正负相关主题词云则进一步区分不同情绪下的关键词分布。
UMAP 降维图可以把文本向量压缩到二维空间,帮助观察评论之间的相似关系。配合 HDBSCAN 聚类后,评论会呈现出一定的群聚结构,这对于解释“为什么某些评论属于同一类体验”比较有帮助。虽然这部分不需要把算法细节完全展开,但放在项目展示中能体现文本挖掘不只做了词频统计,还涉及语义空间建模。
仪表图、置信度分析图、主题一致性曲线等图表适合放在结果展示部分。它们的作用不是堆技术名词,而是让用户快速理解系统输出是否稳定、模型判断是否集中、主题提取是否具有一定一致性。对学生项目来说,这类图可以显著增强页面和论文成果的视觉表现力。

图8 评论词云与情绪主题展示
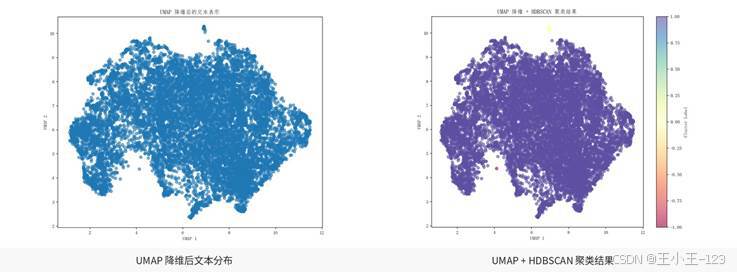
图9 UMAP 降维与 HDBSCAN 聚类展示
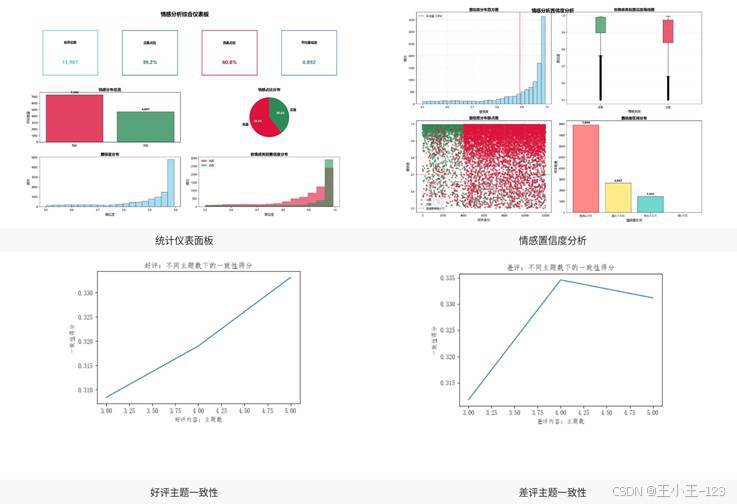
图10 仪表图、置信度和主题一致性展示
七、系统功能:不仅有算法,也有可操作页面
这个系统的展示价值还体现在 Web 端功能上。项目采用 Flask 搭建后端服务,通过页面完成注册、登录、用户管理、数据展示和结果查询等功能。管理员可以查看用户信息,并进行基础维护;普通用户可以通过系统页面查看评论分析结果。这样的设计让项目从“算法脚本”升级为“可使用系统”,更符合毕业设计和实战项目的呈现方式。
数据库设计围绕用户、管理员和外卖评论数据展开。用户表保存用户名、密码、创建时间、性别等基础信息;评论表保存评论时间、菜品满意度、配送满意度、评论类型、用户性别、用户年龄、商家类型、用户 ID、店铺 ID、订单价格和评论内容等字段;管理员表用于管理权限和后台操作。通过主键、外键和索引设计,可以保证数据查询和系统管理更加清晰。
权限控制采用 RBAC 思路,普通用户和管理员拥有不同操作范围。系统通过 Session 保存用户状态,并设置有效期,避免长期登录带来的安全风险。管理员访问后台时会经过角色判断,普通用户无法直接访问管理接口。这样一来,项目不仅有数据分析功能,也具备基础的账号体系和安全控制。
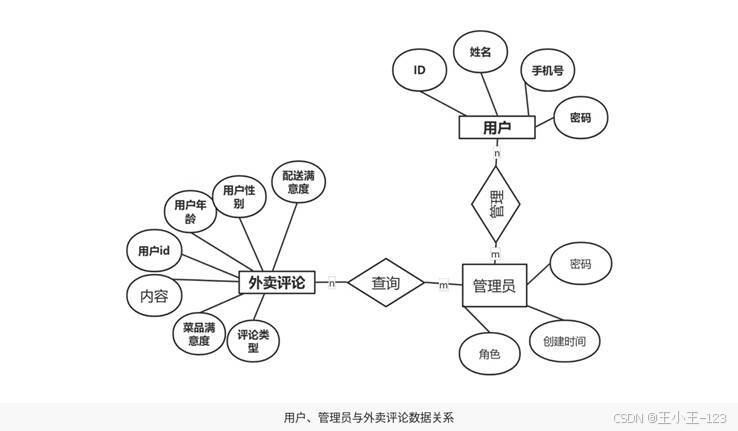
图11 数据库 E-R 关系设计
图12 注册、登录与用户管理界面展示
八、测试效果:核心功能基本达到展示要求
系统测试覆盖了数据爬取、文本清洗、分词去停用词、主题建模、情感分类、词云生成、用户注册、登录、用户管理和权限控制等模块。测试结果显示,爬虫在模拟反爬机制下能够通过代理和重试机制提高采集稳定性,数据采集成功率约 98%,平均响应时间小于 3 秒。
文本处理方面,清洗后有效词汇保留率约 95%,分词准确率约 97%,UMAP 降维后的文本分布与人工标注情感倾向吻合度超过 90%。情感分类方面,BERT-wwm 模型准确率达到约 89%,能够满足项目展示和基础分析需求。可视化页面加载速度小于 2 秒,交互过程较为流畅。
高并发场景下,系统模拟 500 用户同时调用情感分析接口,吞吐量稳定在 100TPS 左右,没有出现明显响应超时或数据丢失。测试用例通过率约 97.5%,未通过项主要来自极端网络环境下的偶发爬取失败,后续可继续通过代理池、异步队列和任务监控进行优化。
九、项目亮点与可拓展方向
第一,链路完整。项目从数据采集开始,经过清洗、建模、可视化和系统管理,形成了比较完整的数据挖掘应用流程,适合展示工程能力。第二,技术组合丰富。项目同时使用了 TF-IDF、LDA、UMAP、HDBSCAN、BERT-wwm、Flask、MySQL 等技术点,覆盖文本挖掘、机器学习、深度学习和 Web 开发多个方向。第三,结果直观。词云、聚类图、ROC 曲线、混淆矩阵、仪表图和前端页面都能直接展示效果,适合项目汇报、答辩和线上宣传。
后续如果继续完善,可以从三个方向升级:一是加入多平台评论数据,比如饿了么、抖音团购、本地生活平台等,增强数据覆盖面;二是加入更细粒度的情感标签,把“口味差”“配送慢”“包装破损”“份量少”等问题自动分类;三是增加商家看板功能,按店铺、时间、评分、品类生成运营报告,让系统更接近真实商业应用。
如果用于学生项目展示,建议重点突出“算法 + 系统”的组合,不必把所有参数和源码细节都写出来。展示层面放出数据表、流程图、词云图、模型指标和页面效果即可;完整代码、训练文件、数据库脚本、部署步骤可以作为资源包单独说明。这样既能让读者快速看到效果,也能保留项目资料的完整性。
十、总结
这套外卖评论分析与可视化系统围绕真实消费场景展开,把非结构化评论转换成可以阅读、可以对比、可以展示的数据结果。它既能看到用户喜欢什么,也能看到用户不满意什么;既有 LDA 主题挖掘,也有 BERT-wwm 情感分类;既能输出模型指标,也能通过 Flask 页面进行系统化呈现。整体来说,项目结构清晰、技术点完整、图表展示丰富,适合用于毕业设计、课程实训、项目汇报和二次开发。
对外卖商家来说,评论分析可以帮助发现服务短板;对平台来说,它可以辅助评价体系优化;对学生来说,它是一个很适合练习数据采集、自然语言处理、模型评估和 Web 可视化的综合项目。只要继续补充数据规模、优化模型细节、完善部署流程,就可以进一步扩展成更成熟的评论智能分析平台。
每文一语
善于把复杂问题拆成清晰流程,项目就会从想法一步步变成作品。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)