多模态记忆现在还远没到能放心托付的时候
论文:MemLens: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models 原文:https://arxiv.org/abs/2605.14906 一句话先看懂:专门把图像证据、多轮会话和跨 session 记忆拉到一起测,结果是很多看起来很强的 LVLM,其实离稳还差得远。

现在不少多模态模型都在讲长期记忆,讲得很像已经快成熟了。
但你只要把问题问得更细一点,比如跨会话还记不记得、图像细节能不能留下来、时间顺序会不会乱掉,答案就没那么乐观了。MemLens 做的,就是把这层窗户纸捅破。
论文速读
这篇 paper 最值得看的地方,不是它又做了一个多模态 benchmark,而是它把很多演示里被糊过去的问题,拆成了能一项项追责的记忆任务。
前半篇先把比较对象摆平,不只测长上下文 LVLM,也把外挂记忆 agent 拉进来同台对比。中间重点看跨会话、跨 session、图像细节、时间顺序这些最容易“看着像记住了,实际上没记住”的环节。
后半篇实验很扎心,很多看起很强的模型,一旦把文字提示红利拿掉,或者把会话拉长、把图像证据变复杂,性能就会掉得很明显。论文想说明的不是谁第一,而是这条赛道离“可放心托付”还早。
所以它最后留下的结论很实在,多模态长期记忆现在最缺的不是叙事,而是更严格的验收尺子。
这篇论文到底解决了什么问题
过去大家很容易把长上下文 LVLM 和外挂记忆 agent 分开看,谁都说自己更适合长期任务,但很少有人把这两路方法放到同一张桌子上,系统地测。
更麻烦的是,不少所谓记忆能力,其实偷偷吃了文本提示的红利。你以为模型记住了图像,结果它只是顺着文字把题蒙对了。只要评测不把这层剥开,记忆能力就很容易被高估。
MemLens 抓的就是这个漏洞。它不只问模型能不能回忆,还问它回忆的到底是视觉证据、会话状态,还是被文字牵着走的表面答案。
所以这篇论文要解决的,首先是测量问题。尺子不对,后面的能力判断就都会跑偏。

它的方法,为什么值得看
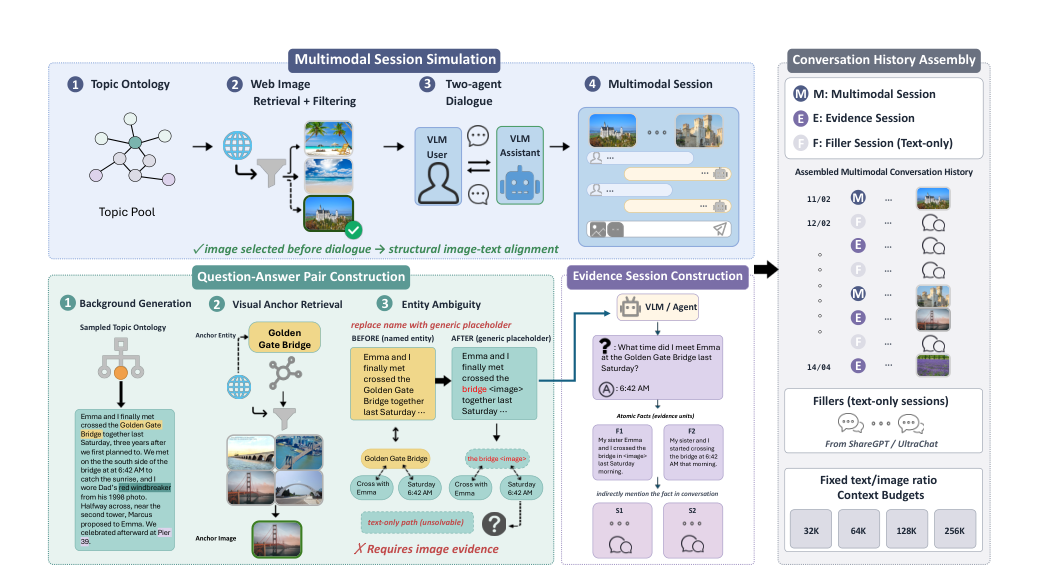
MemLens 的设计很扎实,589 个问题覆盖信息提取、多 session 推理、时间推理、知识更新和拒答能力,还专门验证这些题是不是真的依赖图像证据。
这一步特别重要。因为一旦你不区分“图像真被记住了”还是“文字把答案带出来了”,整个评测就会很虚。作者做的事情,本质上是在给多模态长期记忆补一把更像样的尺子。
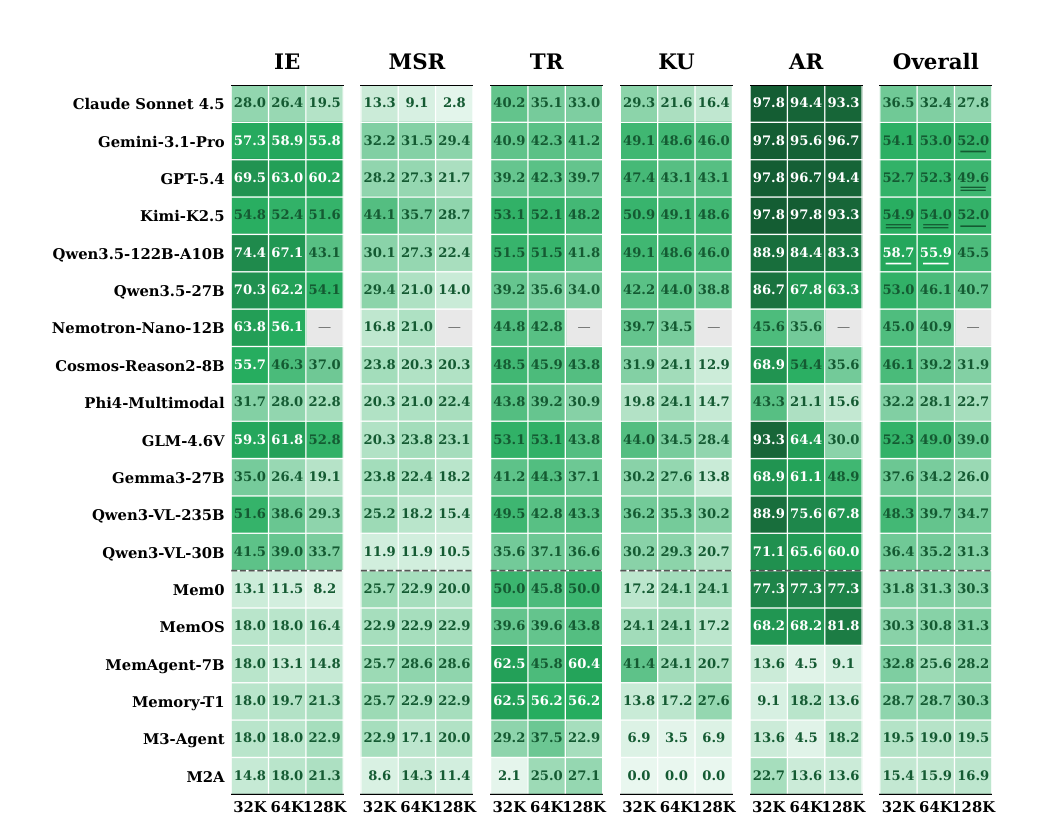
更关键的是,它不是只看一类模型。长上下文路线和外挂记忆路线都被放进来了,于是你能更清楚看到两者的 trade-off,一个更依赖上下文承载,一个更依赖记忆压缩,但两边都远没稳到能放心交付。
这让论文的价值不只是测分,而是帮大家把路线图也看清了。
这件事会怎么影响开发者和企业
对开发者来说,这篇论文很像一盆冷水。别因为模型能读图、能多轮对话、能扩上下文,就默认它已经有可靠的长期多模态记忆。
真正一上业务,错往往就出在这些“以为它记住了”的地方。你要做的是把视觉证据、会话状态、外部检索和长期存储分层设计,而不是把它们都混在一个模型窗口里赌运气。
对企业来说,这意味着多模态长期助手大概率还是混合架构路线,不会是单纯扩窗,也不会是单纯外挂记忆库。谁能把视觉证据、会话历史和检索状态协同好,谁才更接近可用。
所以 MemLens 的启发很明确,长期多模态记忆现在拼的不是 demo,而是系统设计和严格评测。
如果你觉得多模型切换 Q、工具订阅的流程太繁琐,也可以试试我们的「胜算云」平台,一站式搞定AI创作与开发相关需求。官网:https://www.shengsuanyun.com/?from=CH_5VQOF8WB

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)