ELI5:让机器学习模型说出判断理由
ELI5:让机器学习模型说出判断理由
eli5 在 GitHub 上有 328 Star。
这是一个 Python 库,核心就干一件事,解释机器学习分类器的预测结果,把模型内部的判断逻辑摊开来给你看。
1、这库能解决什么问题
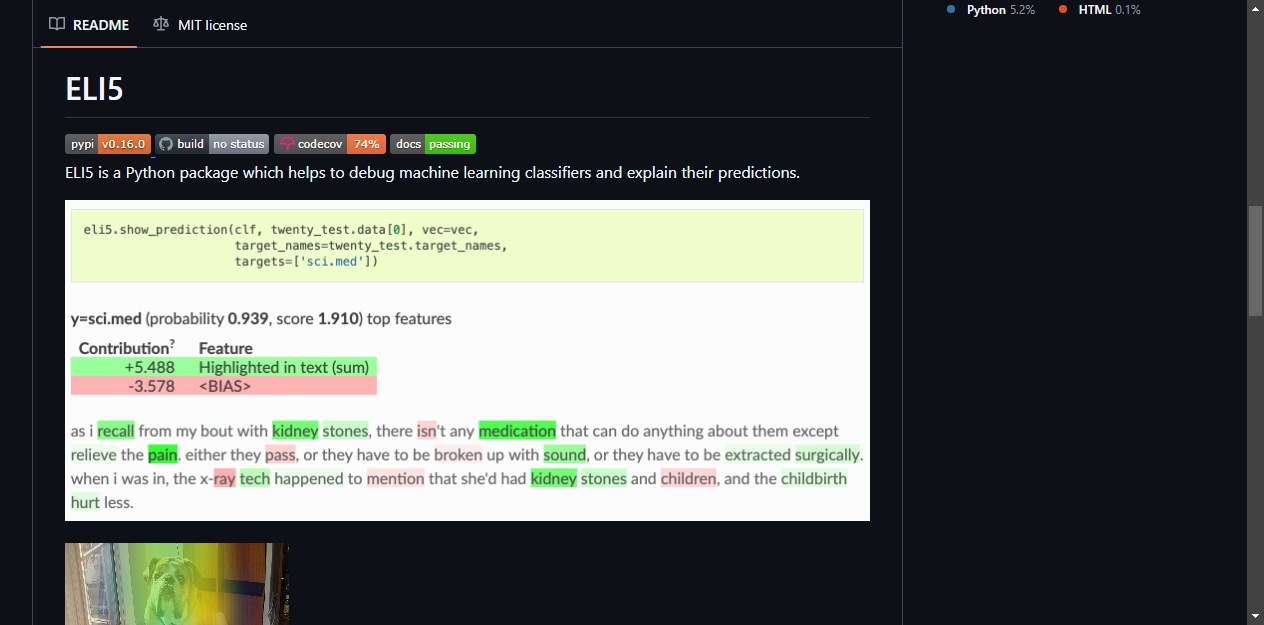
模型训练完,测试集准确率上去了,但很多时候你并不清楚它内部在做什么。哪个特征的权重最高?为什么这条样本被分到了 A 类而不是 B 类?文本分类里具体是哪些词推动了预测往某个方向走?
ELI5 就是来解决这类问题的。它可以展示模型权重、解释单条预测结果、高亮文本数据中的关键特征,还能把决策树绘制成 SVG 图形。如果你用的是 scikit-learn 的 Pipeline,它也能逐层拆解,帮你定位问题出在哪一环。
2、支持的机器学习框架
覆盖面相当广。scikit-learn 的线性分类器和回归器、决策树、树类集成模型都能解释权重和预测,Pipeline 和 FeatureUnion 也兼容,还能还原 HashingVectorizer 的哈希过程。Keras 的图像分类器可以通过 Grad-CAM 做可视化解释,直接看到模型关注的是图像的哪些区域。xgboost、LightGBM、CatBoost 的特征重要性和单条预测解释都内置了。此外还有 lightning 的分类器和回归器、sklearn-crfsuite 的 CRF 模型,以及 OpenAI Python 客户端的 LLM 预测解释。
3、黑盒模型也有办法
不是所有模型都方便直接拆解内部结构。ELI5 提供了 TextExplainer,基于 LIME 算法解释任意文本分类器的预测逻辑。置换重要性方法可以给任何黑盒估计器计算特征重要性,不需要知道模型内部的具体实现。这两个工具在模型不可解释的场景下比较实用。
4、输出格式很灵活
解释内容和展示格式是分离设计的。你可以拿到纯文本在控制台查看,生成 HTML 嵌入 Jupyter 笔记本或网页面板,导出 pandas.DataFrame 做进一步处理,或者输出 JSON 格式自行做前端渲染。这种分离意味着你可以根据场景选最合适的呈现方式,不会因为格式问题卡壳。
5、适合谁用
做模型可解释性研究的人、需要向业务方说明模型判断依据的数据科学家、在调试特征工程环节的开发者、做 RAG 或 LLM 应用需要解释模型输出的工程师,都可以把这个库纳入工具箱。
MIT 协议开源。
输出的工程师,都可以把这个库纳入工具箱。
MIT 协议开源。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)