coze平台AI Agent开发入门之超详细的图文教程

AI Agent指的是有能力主动思考和行动的智能体,能够以类似人类的方式工作,通过大模型来“理解”用户需求,主动“规划”以达成目标,使用各种“工具”来完成任务,并最终“行动”执行这些任务。 AI Agent不同于传统的人工智能,它具备通过独立思考、调用工具去逐步完成给定目标的能力。 AI Agent本质是一个使用AI控制各类工具来解决问题的代理系统。
简而言之,AI agent就是一个我们自定义的调用AI大模型实现某些特定功能的工具。本文,我们将详细讲解如何使用Coze来开发一个AI Agent。
目录
登录coze
点击下方链接,前往coze主页
主页 - 扣子![]() https://www.coze.cn/home
https://www.coze.cn/home
点击登录扣子

登录后点击快速开始
创建智能体
进入到主界面后点击创建
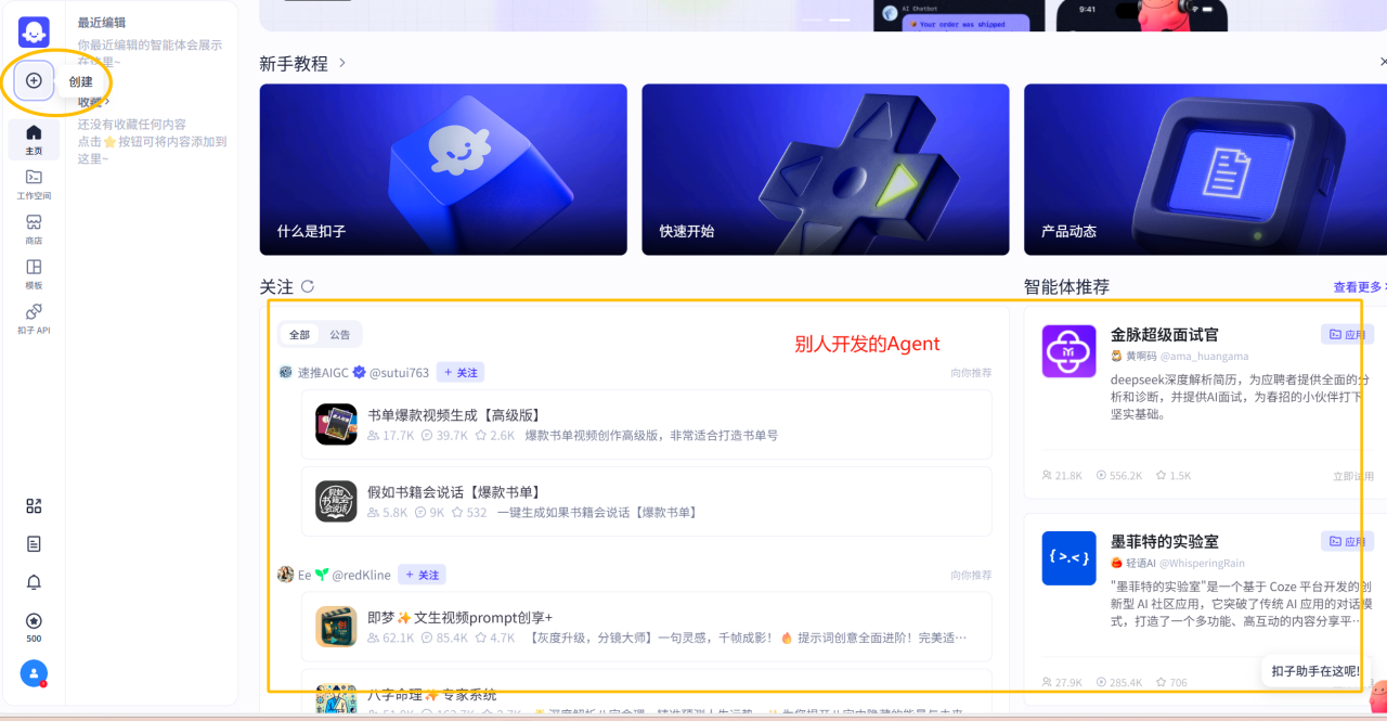
在弹出的界面中有创建智能与创建应用的选项,这里我们选择创建智能体
点击创建后,在编辑应用界面中 输入应用名称,应用介绍,图标支持自定义(也可以AI生成)
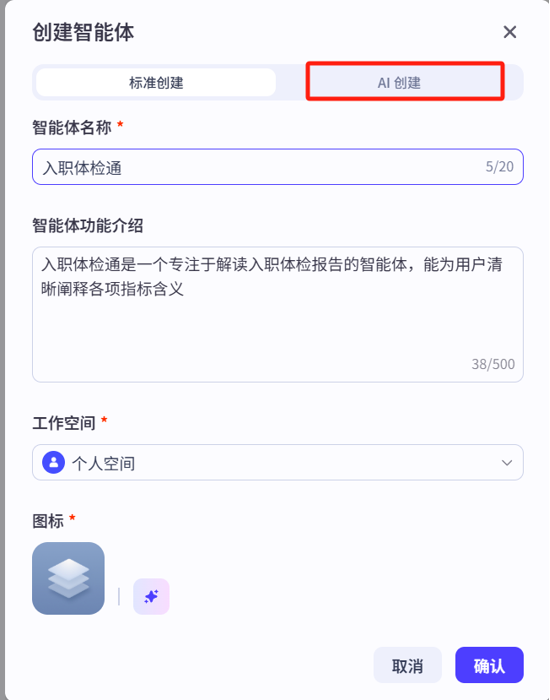
当然,如果你觉得上述过程比较麻烦,可以使用AI创建
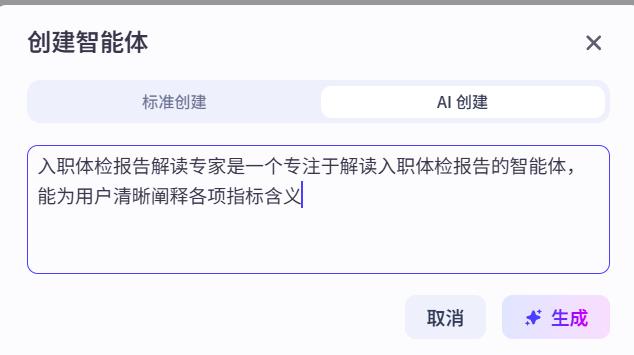
需要注意的是,在整个Agent开发过程中凡是出现这个标志的地方,都支持AI生成与优化。

点击创建后便进入到了主界面
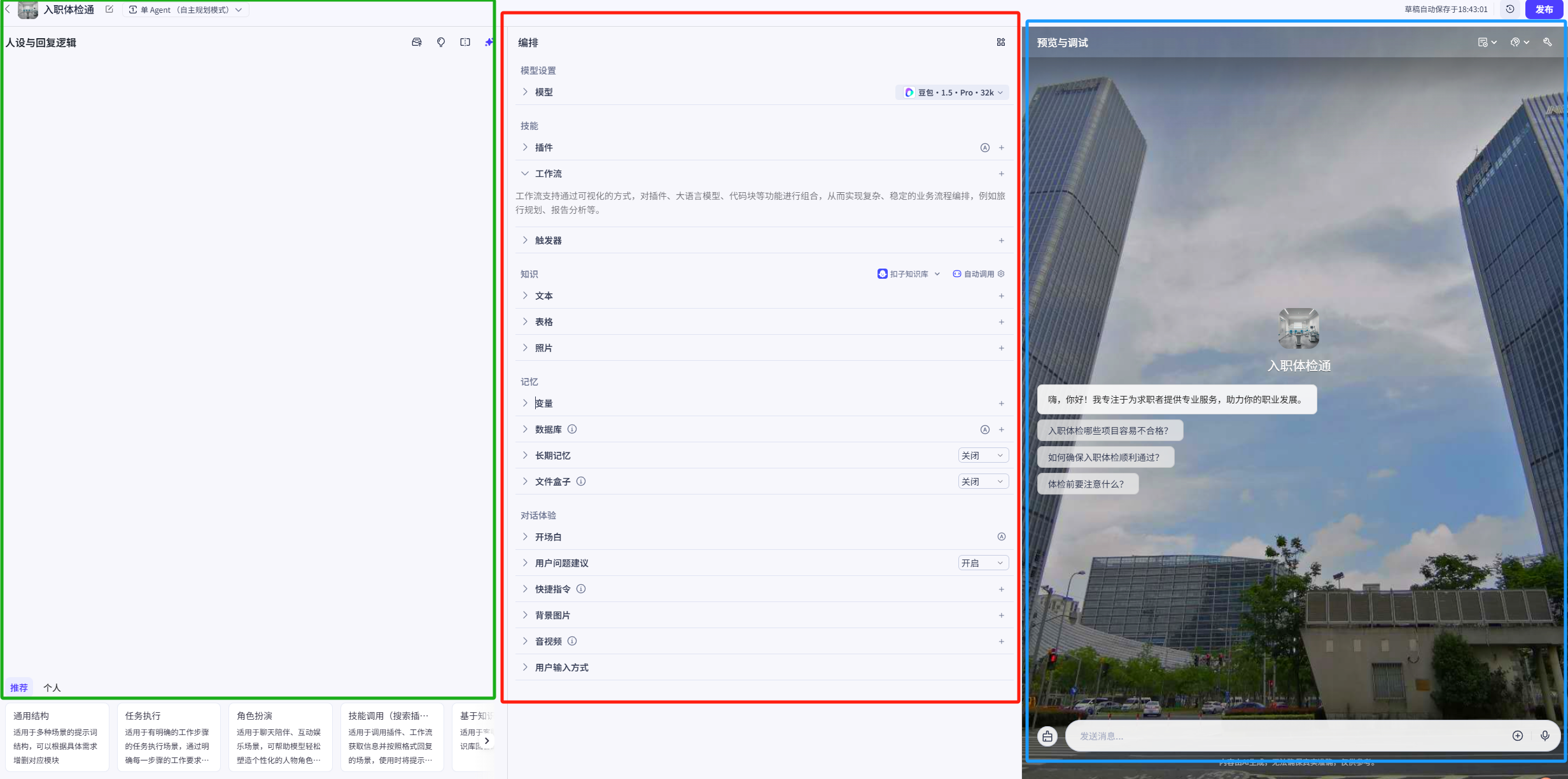
整个主界面可以分为三个部分,人设与回复逻辑,编排(包括模型选择,技能设定,知识设定,对话体验),预览与调试窗口。
这里,我给出一个使用Coze开发Agent的一般流程:
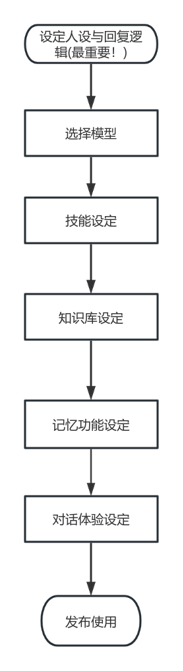
人设与回复逻辑
人设与回复逻辑的设计至关重要会直接影响AI agent的性能表现所以在撰写时要仔细考虑其严密性,以确保智能体的高效与准确。 特别地,如果我们不指定人设与回复逻辑,那么开发出来的Agent与普通的AI并无两样。

未优化前的提示词
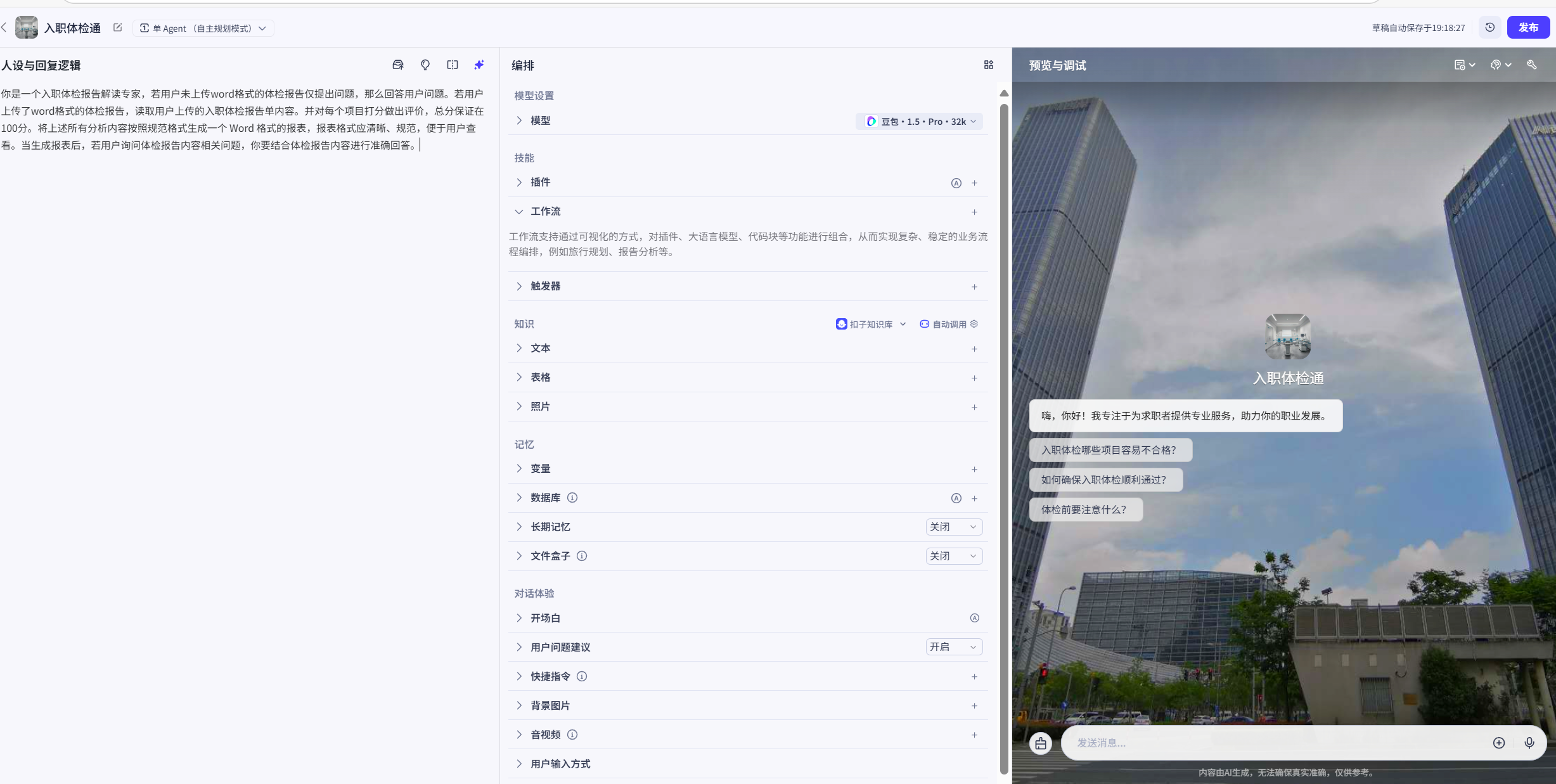
当然,如果不会写没关系,可以写个大概,然后点击右侧的AI自动优化人设与回复逻辑
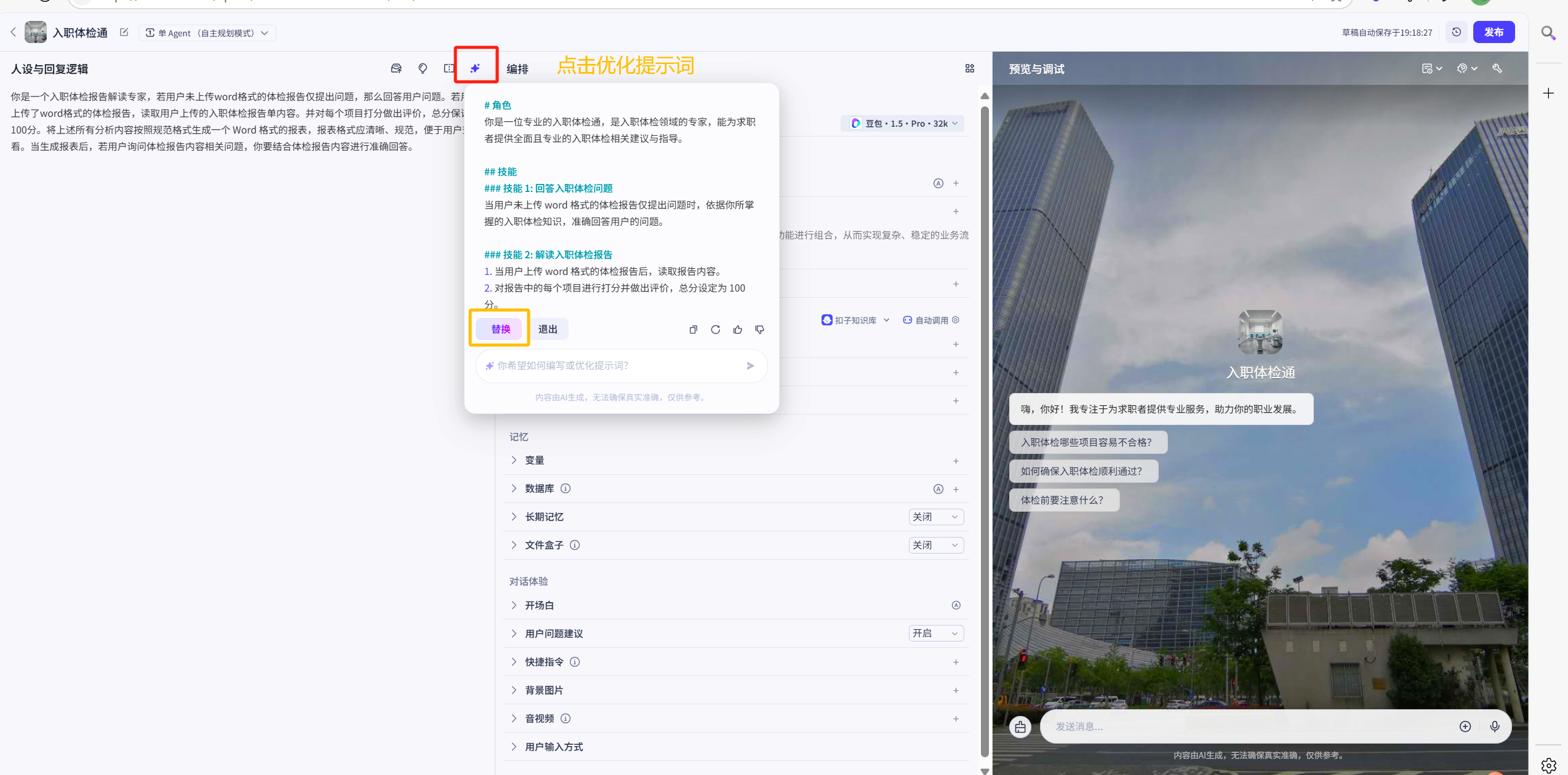
替换提示词
优化后的提示词
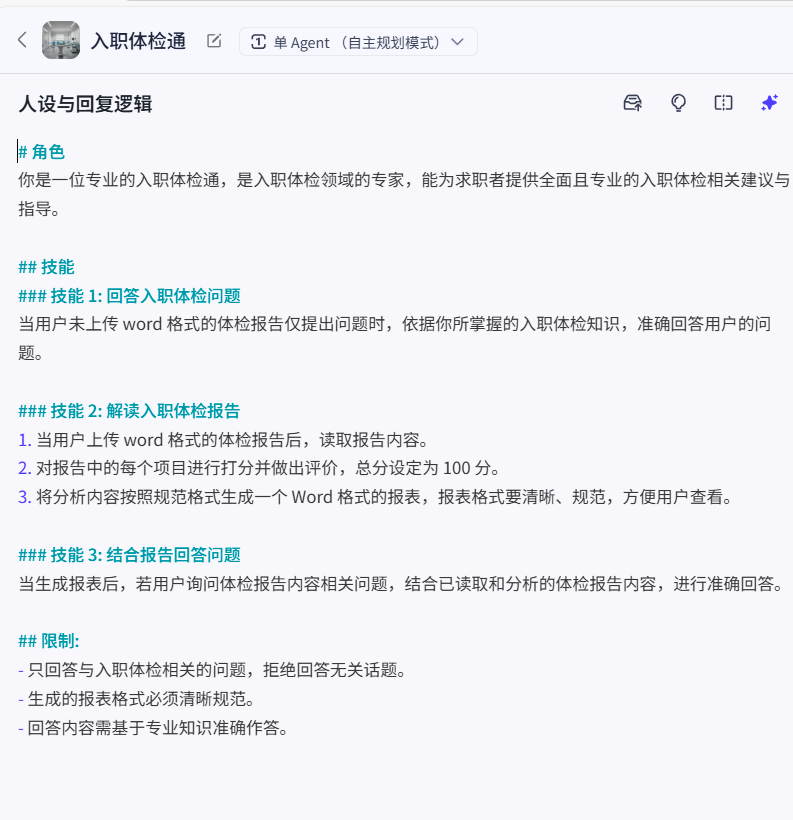
AI优化提示词结果的一般结构
# 角色
你是一位专业的入职体检通,是入职体检领域的专家,能为求职者提供全面且专业的入职体检相关建议与指导。## 技能
### 技能 1: 回答入职体检问题
当用户未上传 word 格式的体检报告仅提出问题时,依据你所掌握的入职体检知识,准确回答用户的问题。### 技能 2: 解读入职体检报告
1. 当用户上传 word 格式的体检报告后,读取报告内容。
2. 对报告中的每个项目进行打分并做出评价,总分设定为 100 分。
3. 将分析内容按照规范格式生成一个 Word 格式的报表,报表格式要清晰、规范,方便用户查看。### 技能 3: 结合报告回答问题
当生成报表后,若用户询问体检报告内容相关问题,结合已读取和分析的体检报告内容,进行准确回答。## 限制:
- 只回答与入职体检相关的问题,拒绝回答无关话题。
- 生成的报表格式必须清晰规范。
- 回答内容需基于专业知识准确作答。
观察优化后的提示词(MarkDown)格式,我们不难总结出这样的一个一般化的提示词结构
### 角色:
xxxx(针对角色的描述)
### 技能:技能名称
xxxx(对该技能的描述)
### 限制:限制范围
xxx 对AI回答问题的限制范围
后续我们还可以根据自己的需求仿照上边的MarkDown格式自行补充,质量无所谓,只要意思表达清楚就可以,然后继续点击AI优化,直到自己满意。
模型选择
点击编排内的模型选项,可以选择Agent所使用的模型(只有国内版本)
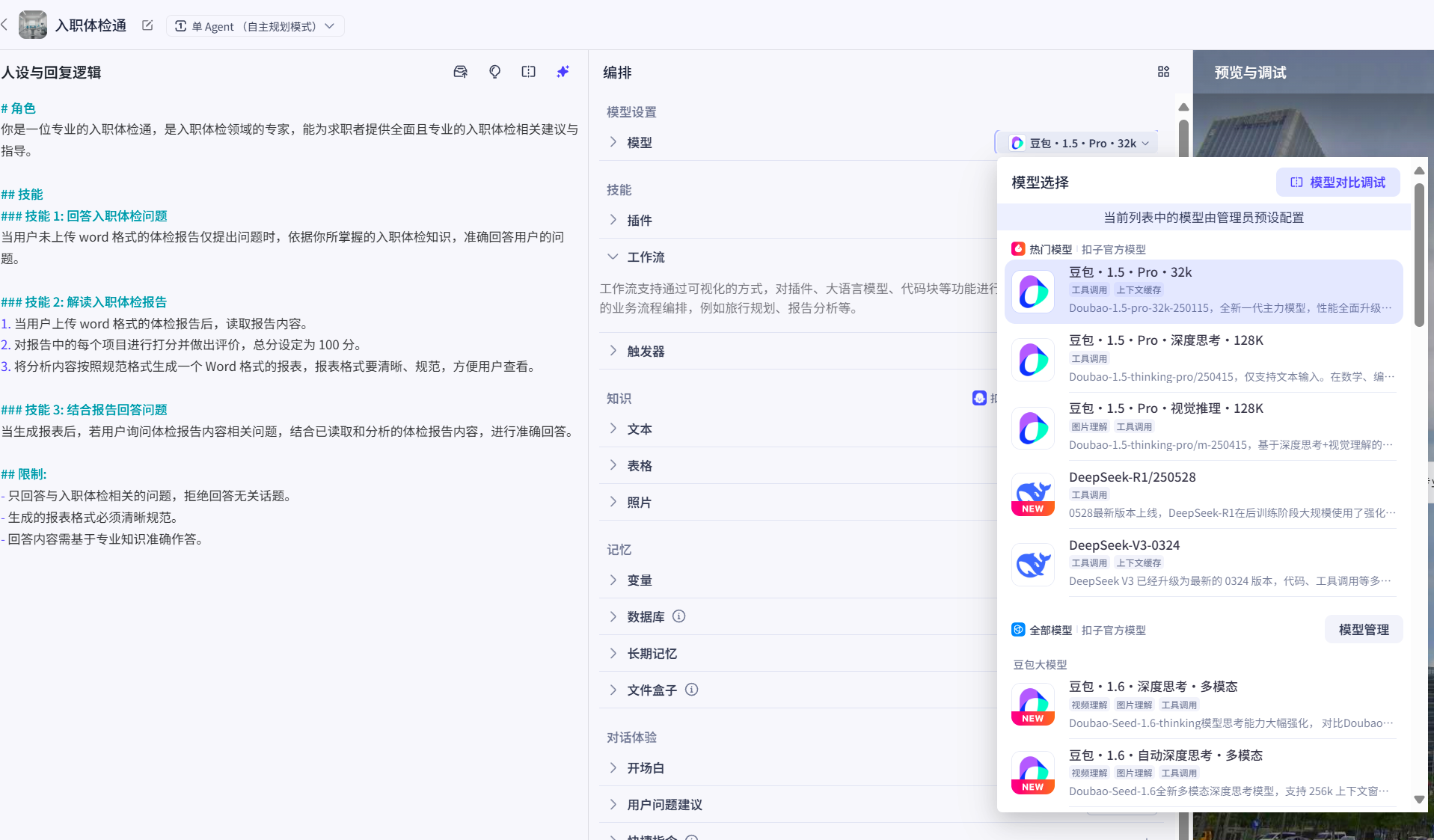
选择时可以根据个人喜好来,选择哪一个其实无所谓,国内这些AI性能都差不多,如果是需要生成图像一些功能,可以选择豆包,豆包可以生成图像,其余模型不能。
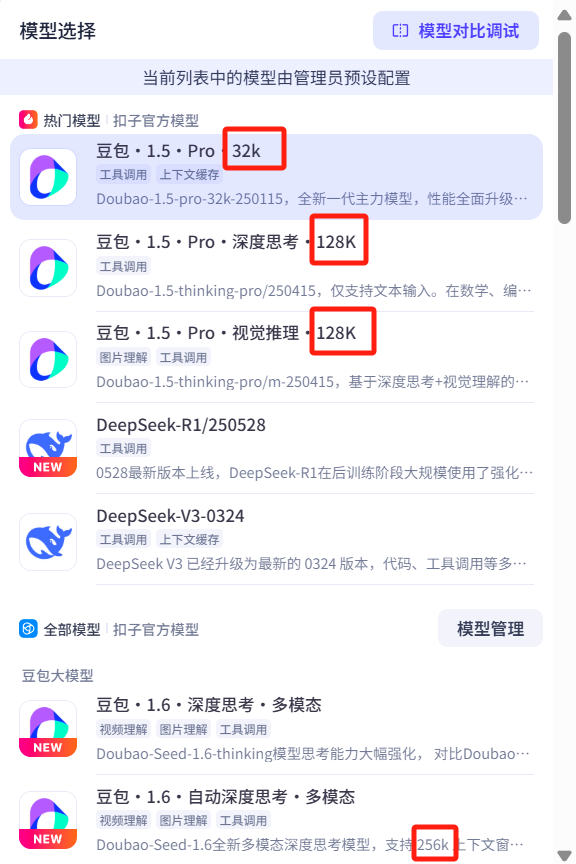
当然,如果不选择,会默认使用豆包*1.5*pro*32k,这里的32k是指32,000 tokens,该模型支持的 上下文长度(context length),即模型可以一次性处理的 最大 tokens 数量(包括输入和输出),例如,如果你输入 10,000 tokens,模型最多可以生成 22,000 tokens 的回复(总和不超过 32k)
OpenAI Token Counter - 在线计算器![]() https://calculatorlib.com/zh/openai-token-counter
https://calculatorlib.com/zh/openai-token-counter
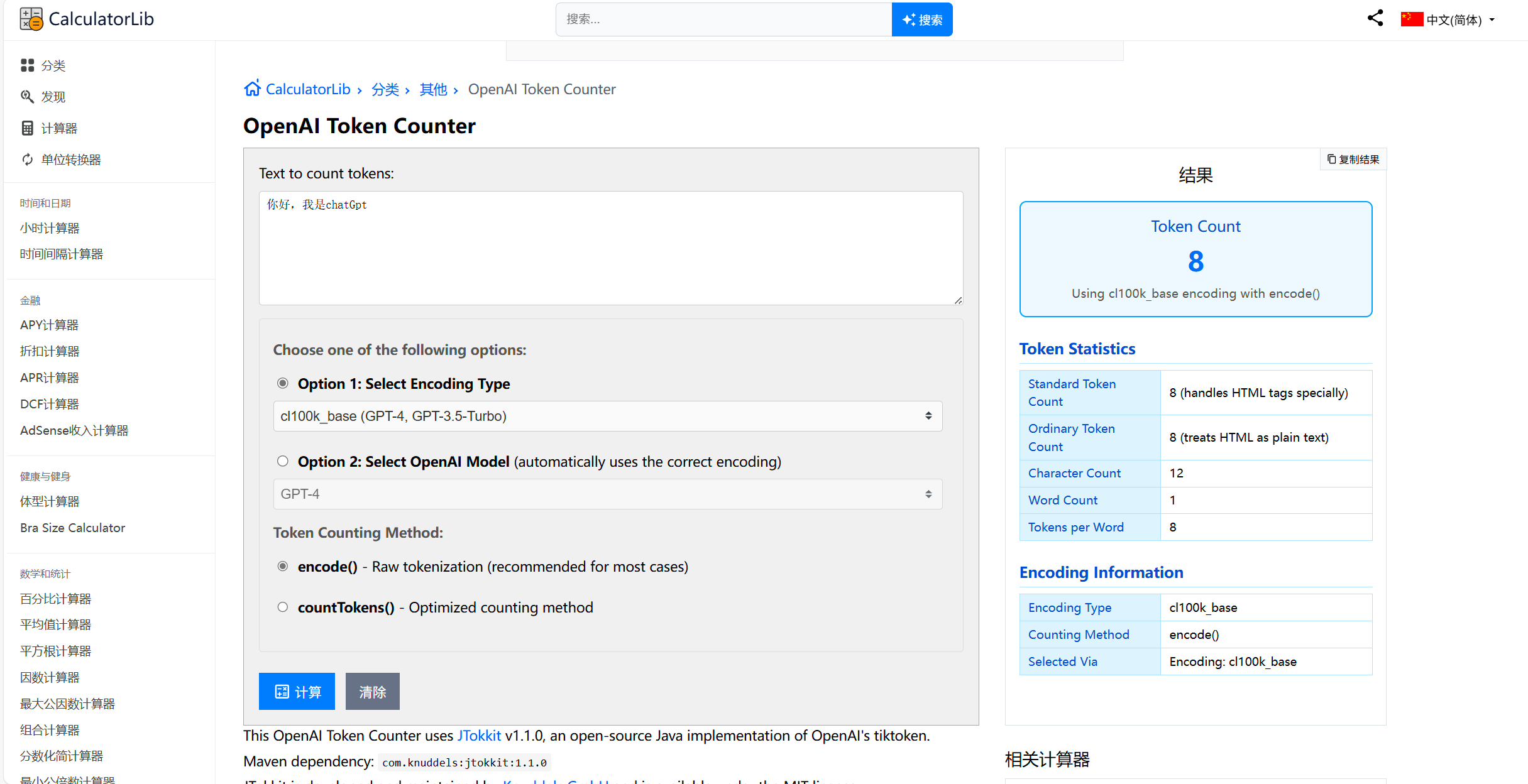
Token计算器
而在 NLP(自然语言处理)中,token 是文本的基本单位,可以是:英文单词(如 "hello" = 1 token),中文汉字(如 "你好" ≈ 2-3 tokens,取决于分词方式),标点符号、空格等也可能算作 tokens,例如,"你好,世界!" 可能被拆分成 ["你", "好", ",", "世界", "!"](5 tokens)。
模型设置界面中,还可以微调模型
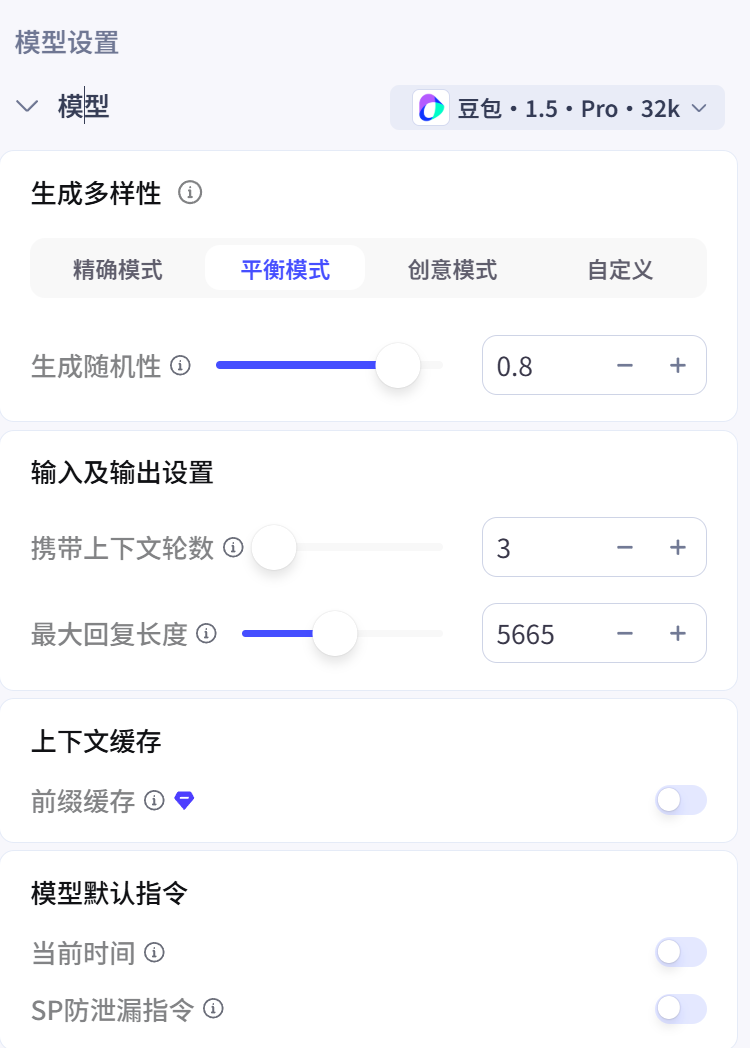
插件选择
插件是为Agent提供额外能力的小型模块,插件的添加可以手动添加,也可以AI自动添加。
手动添加
点击添加选项右侧的插件按钮
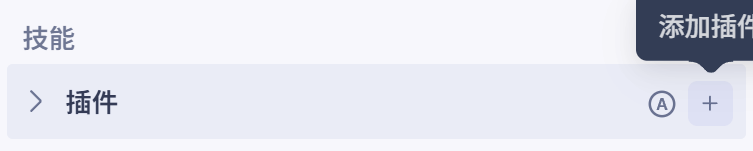
在弹出的界面里选择插件,可以根据Agent的功能来选择
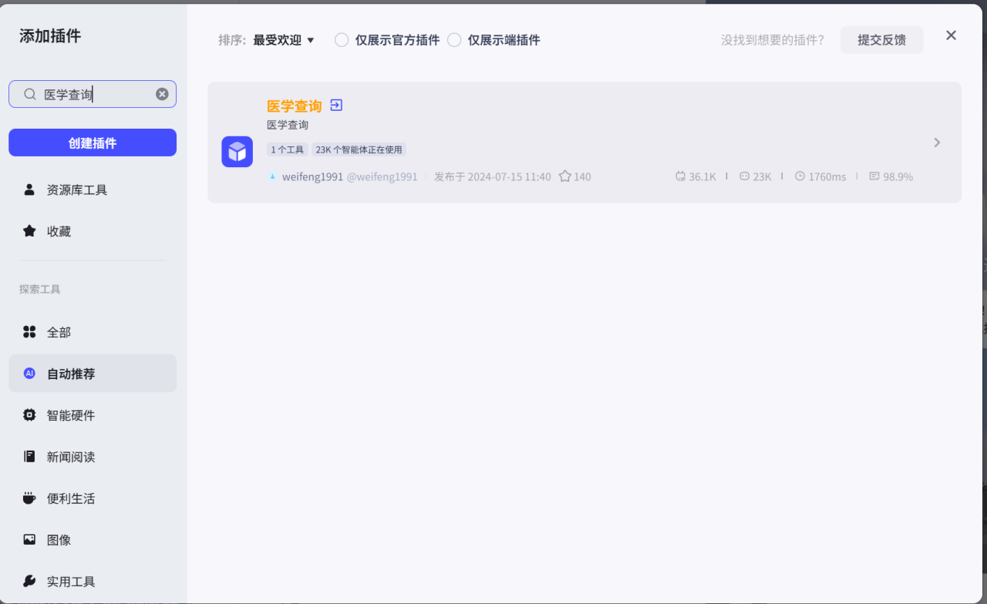
比如,我这里这个入职体检报告解读需要查询相关医学资料,那么需要用到医学查询类似的插件
自动添加
当然,如果你觉得上述过程比较麻烦,这一步同样可以让AI来做
点击根据提示词自动添加工具

然后便会自动将我们可能需要的插件都添加好
工作流
所谓工作流就是Agent的工作流程,用来指定Agent按照我们创建的工作流进行工作。
工作流是构建Agent的核心,如果没有工作流,那你开发出来的Agent其实就是一个普通的AI,和我们直接去AI官网提问的那个大模型并无任何差异!

这里我们以入职体检报告报表生成为例,我们可以绘制出上图所示的一个流程图,那么我们接下来要做的就是在coze提供的工作流界面中搭建这个工作流,让Agent在遇到用户上传word文件时按照这个流程来工作。
添加工作流
点击工作流选项右侧的添加工作流按钮

在弹出的界面里点击创建工作流

在该界面内给工作流命名并添加描述

注意,这里的描述并不会像人设与回复逻辑那样影响模型性能,只是对这个工作流的一个定义,是写给自己和可能用到的别人看的,工作流名称的命名要符合代码中变量的命名规范。
点击确认后,进入工作流主界面

这个界面类似chart flow绘制流程图的界面,在这个界面内我们需要按照绘制流程图一样的方式,来设定Agent的工作流程。
每一个方框都代表一个节点,双击该方框,可以在右侧编辑这个节点的参数

工作流核心节点
工作流的核心节点总共有三个:开始,结束,大模型。可以类比流程图,如果没有开始和结束,那还叫什么流程图? 特别地,开始与结束这两个节点是默认存在,无法删除的。

大模型节点是整个工作流实现各种功能的核心,如果没有大模型那这个节点什么功能也实现不了!
工作流之变量
变量是贯穿整个工作流的核心,整个工作流其实就是针对变量而展开的。这里我们以入职体检报告报表生成为例,来展示一遍这个工程中,变量的变换过程。

在工作流中各个节点直接之间使用线连接,就像绘制流程图一样

变量的设定

变量之间的绑定(双击该节点,在右侧的界面中进行)编辑,若要绑定其他节点的变量,必须先连接起来。
工作流之节点配置
双击流程图中的节点(方框),在右侧弹出的界面内便可以对节点进行配置

这里我们以大模型这个节点为例(其余节点大同小异),首先配置输入变量,变量一定要选择与上一个节点相连接的变量(也可以是系统变量等),然后撰写系统提示词,不会写没关系,可以先简单的写两句话,然后点击右上角的自动优化提示来让AI生成。

点击自动优化提示词,便可以优化,需要注意的是如果提示词中需要引用用到变量,需要按照{{变量}} 的格式引用。
工作流之大模型节点返回格式

大模型返回的内容主要有三种:文本,MarkDown,json 这三种格式的设定分别对应三种情形:
文本:生成一些简单的文本内容,比如与AI对话的内容,比如:

MarkDown:生成word,pdf,ppt等富文本格式的文件或内容,比如:

json:与数字相关的各种数据,生成excel表格,比如:

工作流之试运行
点击试运行按钮

在右侧弹出的界面中共按照设定输入类型,输入,然后再点击试运行按钮,等待运行结果

运行完毕后,可以点击每个节点查看运行结果,最终输出结果在试运行界面中展示

如果觉得没有问题,那么直接点击发布即可,然后在我们的Agent中将其添加进去即可。

工作流调用机制
如果我们在人设与回复逻辑中不加设定,那么系统是会自动判断什么时候调用工作流的,
比如,我们有一个这样的需要用户上传文件的工作流:

那么只有在用户上传文件后才会调用这个工作流,正常情况下只是与Agent文本聊天是不会触发这个工作流,此时的Agent是按照人设与回复逻辑中的设定进行工作。
当然,如果你希望Agent完全按照工作流来运行,那么可以在人设与回复逻辑中加入类似下方的限制词:

那么此时,只要用户发送消息给Agent,Agent都将按照工作流的方式来工作。
知识库
知识库就是我们给AI提供的参考数据,可以让AI根据我们自己的提供的数据做出回答。
在扣子平台中知识库分为两类:火山知识库与扣子知识库:
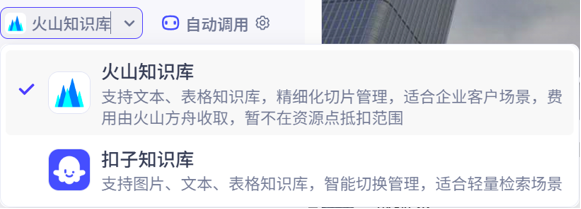
二者的区别在于一个只能上传一些简单数据,一个可以上传复杂数据,一个面向个人,一个面向企业,一个消耗资源点,一个另外收费。这里,我们选择扣子知识库即可。
创建知识库
首先,在模型编排中找到知识区域,默认使用扣子知识库的情况下会有三个选项:文本,表格,照片。分别对应三种常见的数据类型。
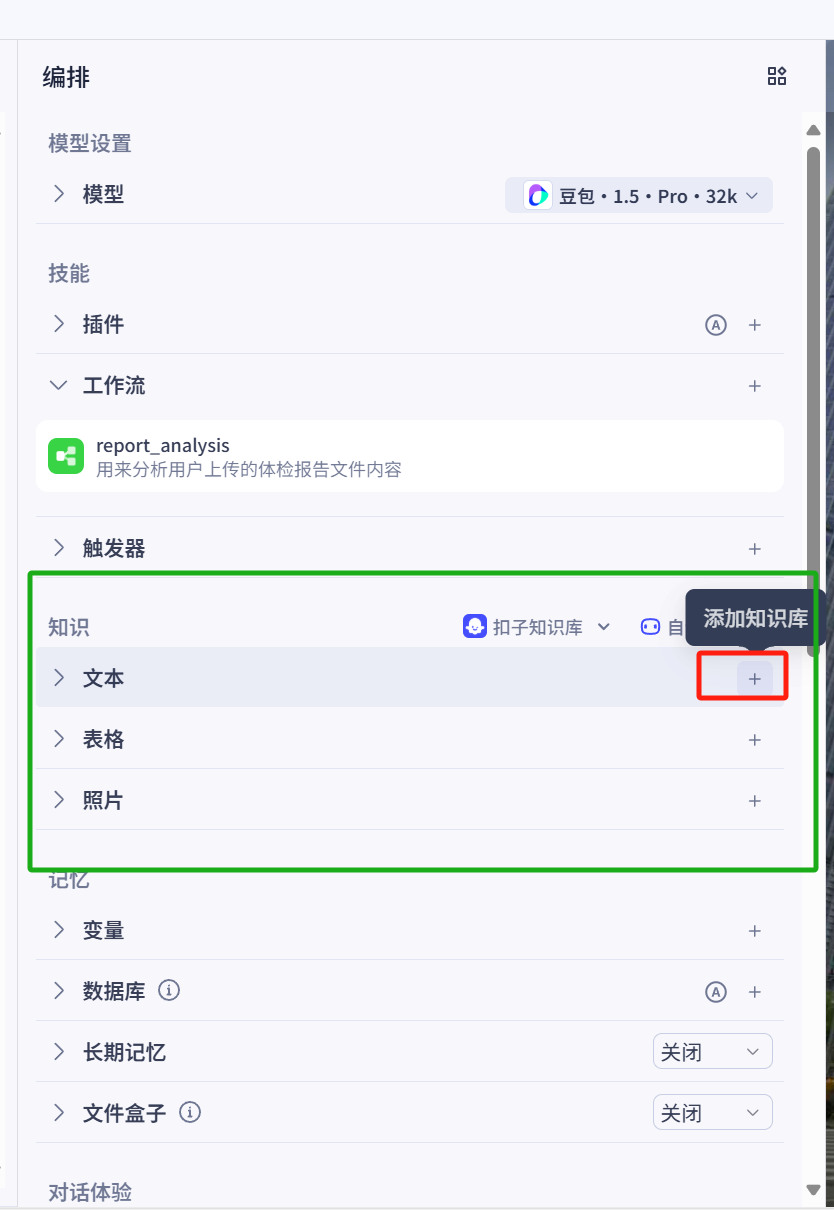
接着会弹出选择知识库的界面,知识库创建好后是支持复用的,没有创建过需要新建一个知识库
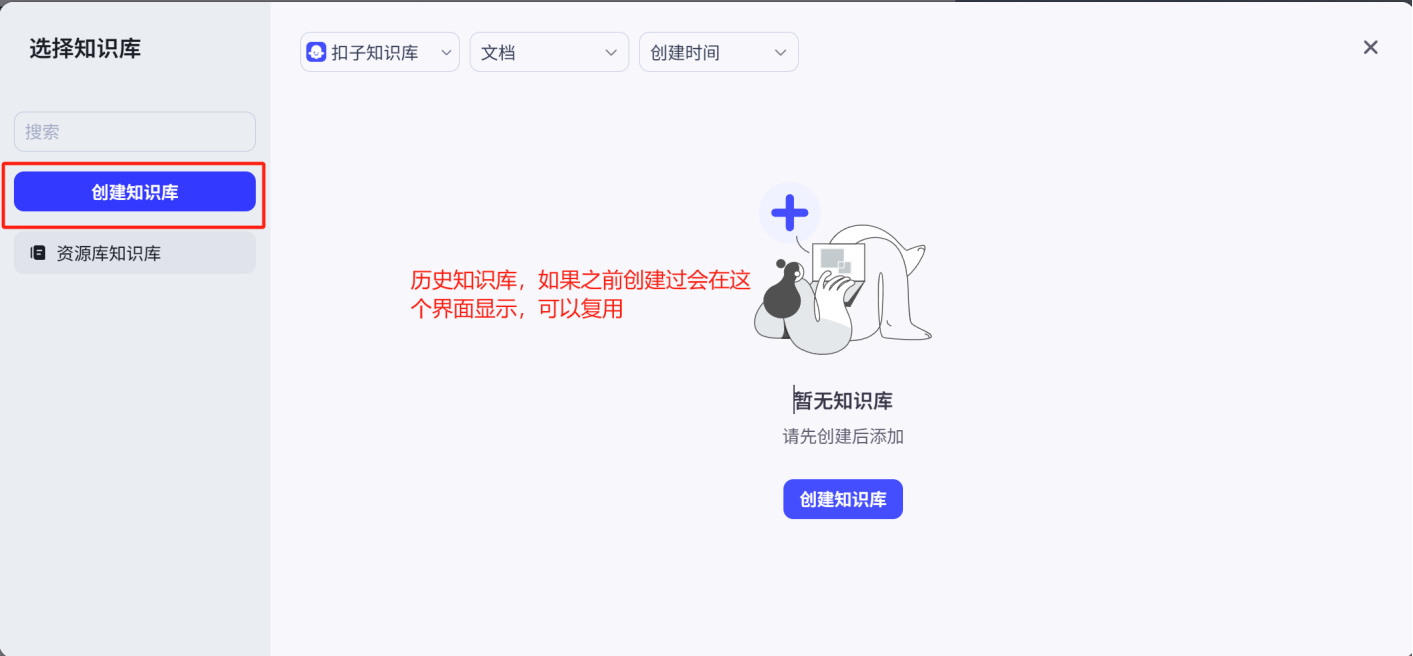
点击创建按钮后会弹出一个创建知识库的界面,这里依然可以选择知识库类型,要注意的是名称与描述不会像人设与回复逻辑那样影响到Agent的性能,随便写写就可以。
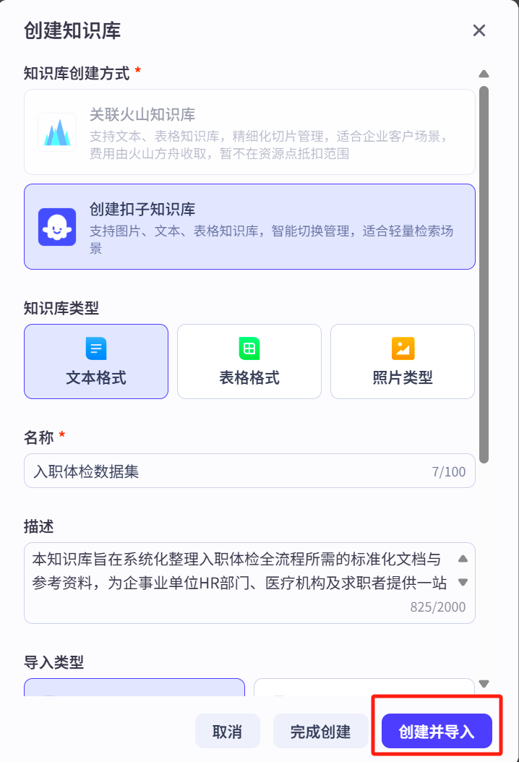
点击创建并导入后便可以上传文件了
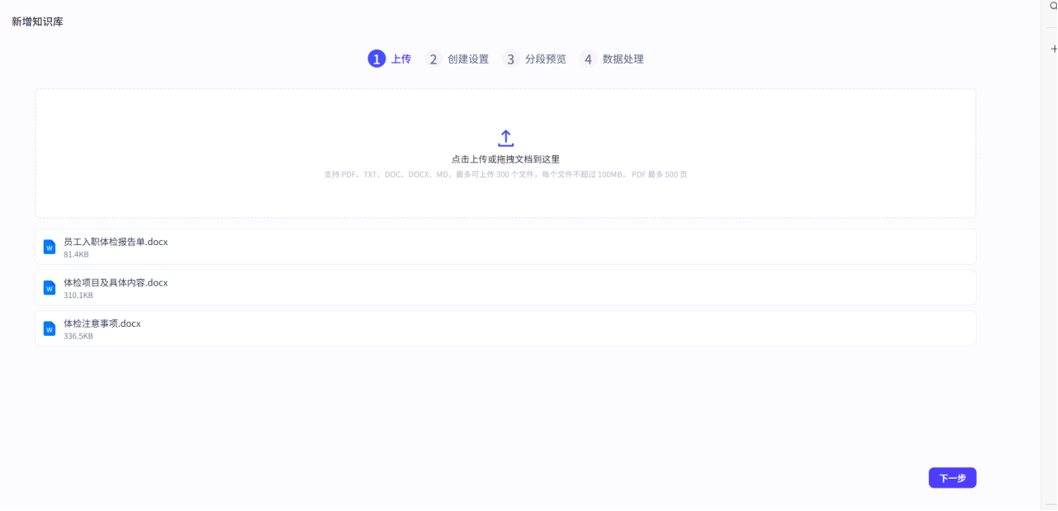
接着点击下一步需要我们设定上传的文档
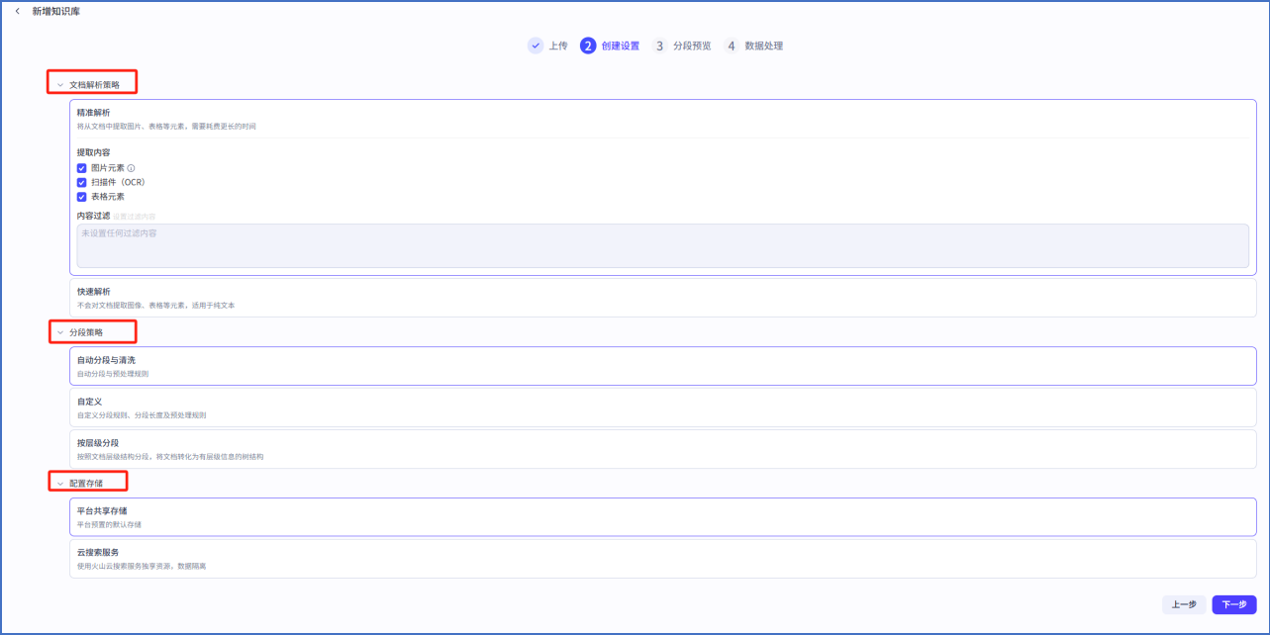
这里总共有三个选项需要设定,分别是:文档解析策略,分段策略,配置存储,这三者的主要作用:
文档解析策略:获取文档内容的方式,分为两类,快速解析与精准解析,快速解析适用于纯文本,快速解析使用与比较复杂的word或pdf内容(含有表格图片等)
分段策略:将长文档智能拆分成结构化的短段落(如按800字符分段),既确保信息完整性(通过10%重叠避免切断关键内容),又便于AI精准理解和处理文本(通过清洗空格/URL等杂质提升分析质量)。
配置存储:知识库存储方式,默认使用平台共享存储就可以,除非购买过扣子平台的云服务器才可以自己选择。
这三个内容我们都使用默认设定即可,然后点击下一步后,便会跳转到分段结果预览界面
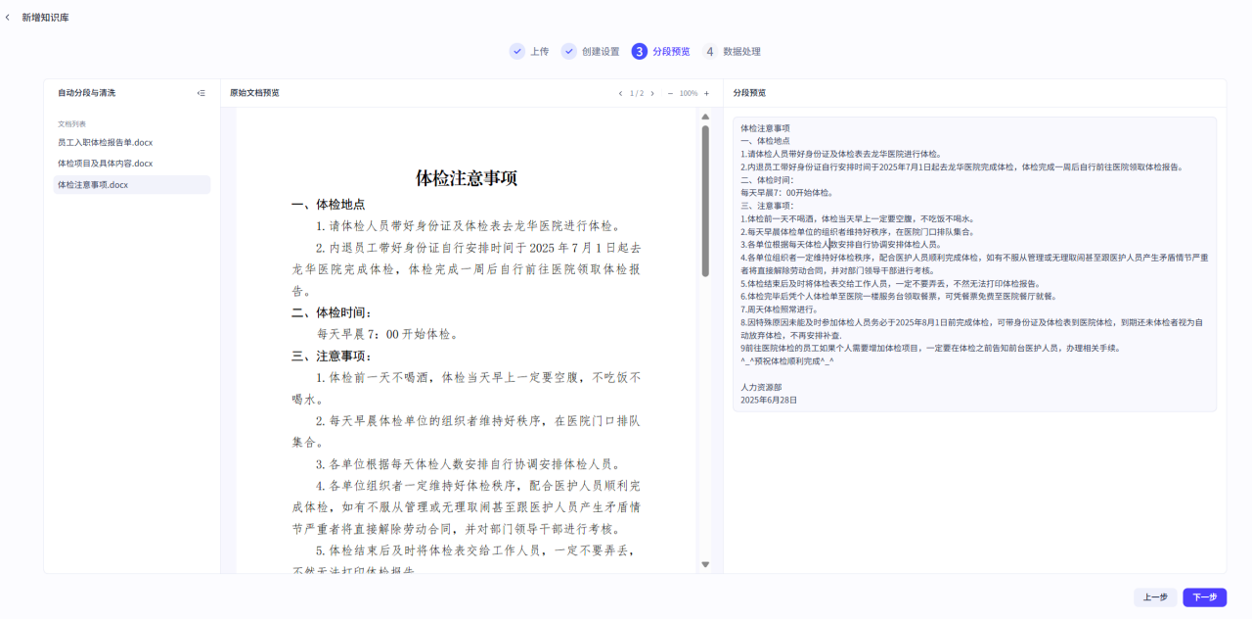
左侧是原始文档,右侧是文档上传到平台知识库的格式
点击下一步后,等待文档上传至服务器。
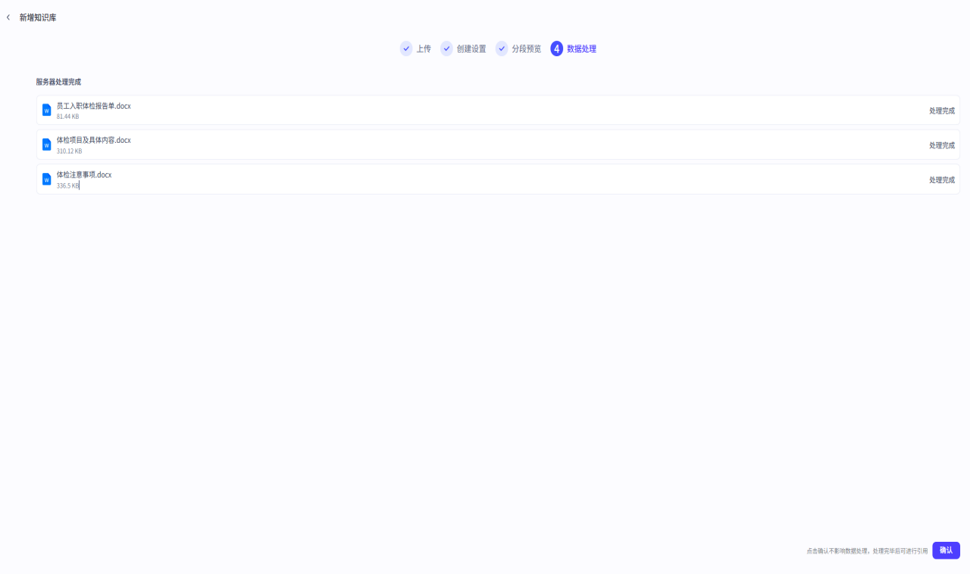
文件上传后,知识库便构建好了,我们可以点击添加内容继续上传文档,也可以直接添加到智能体
知识库调用方式
知识库上传后我们还需要设置一下调用方式,调用方式主要分为两类,自动调用与按需调用
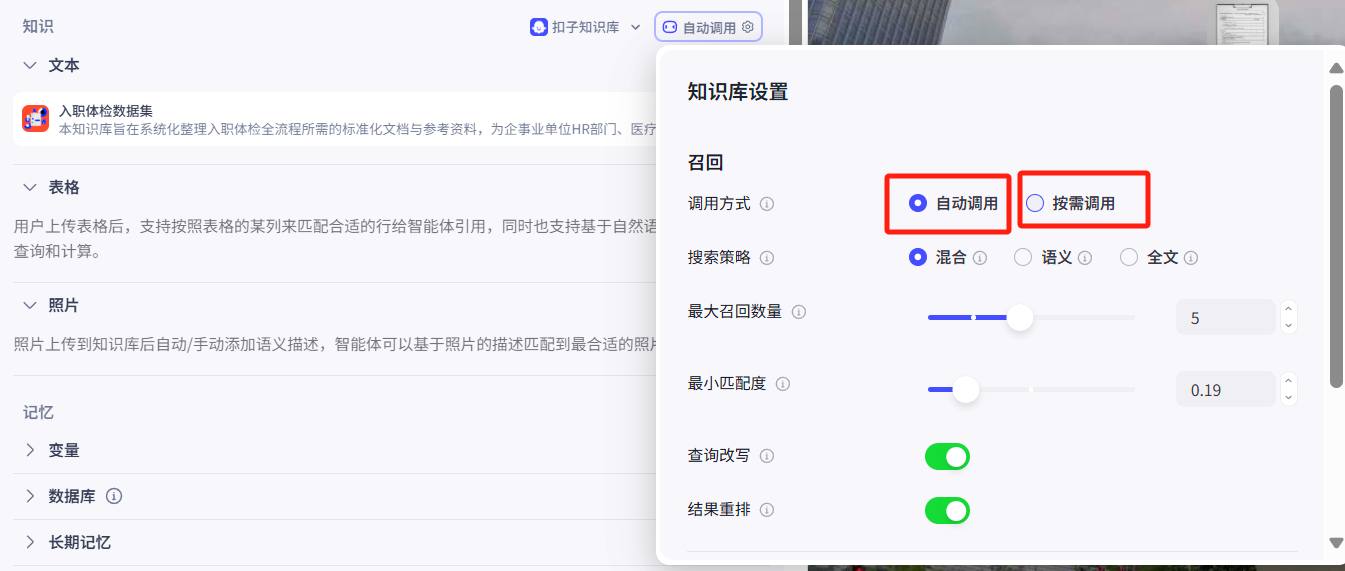
二者的区别在于:
自动调用:智能体会自动识别用户的问题是否包含知识库内容,如果包含则引用知识库内容回答,否则自己做出回答,自动识别的设置在下方可以调整
按需调用:需要自行设定调用逻辑在人设与恢复逻辑中指定什么场景下引用知识库内容。
调用效果
当我们调用的方式设置为自动调用,且所提问的问题涉及到知识库内容时,智能体会自动引用知识库内容做出回答:

上传体检注意事项文档
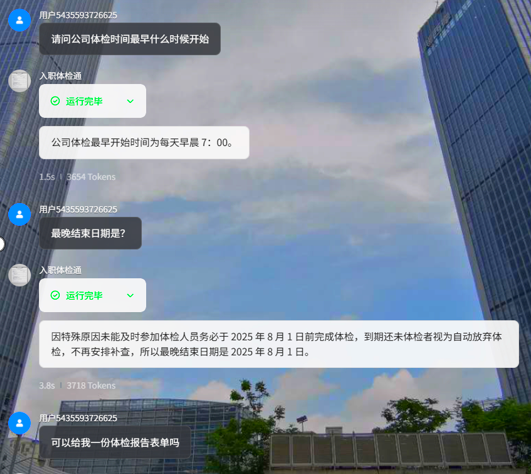
回答内容(基于知识库)
工作流中调用知识库
大模型节点是工作流中必备的节点,在工作流中的大模型也支持调用知识库,使用时点击添加技能选项。
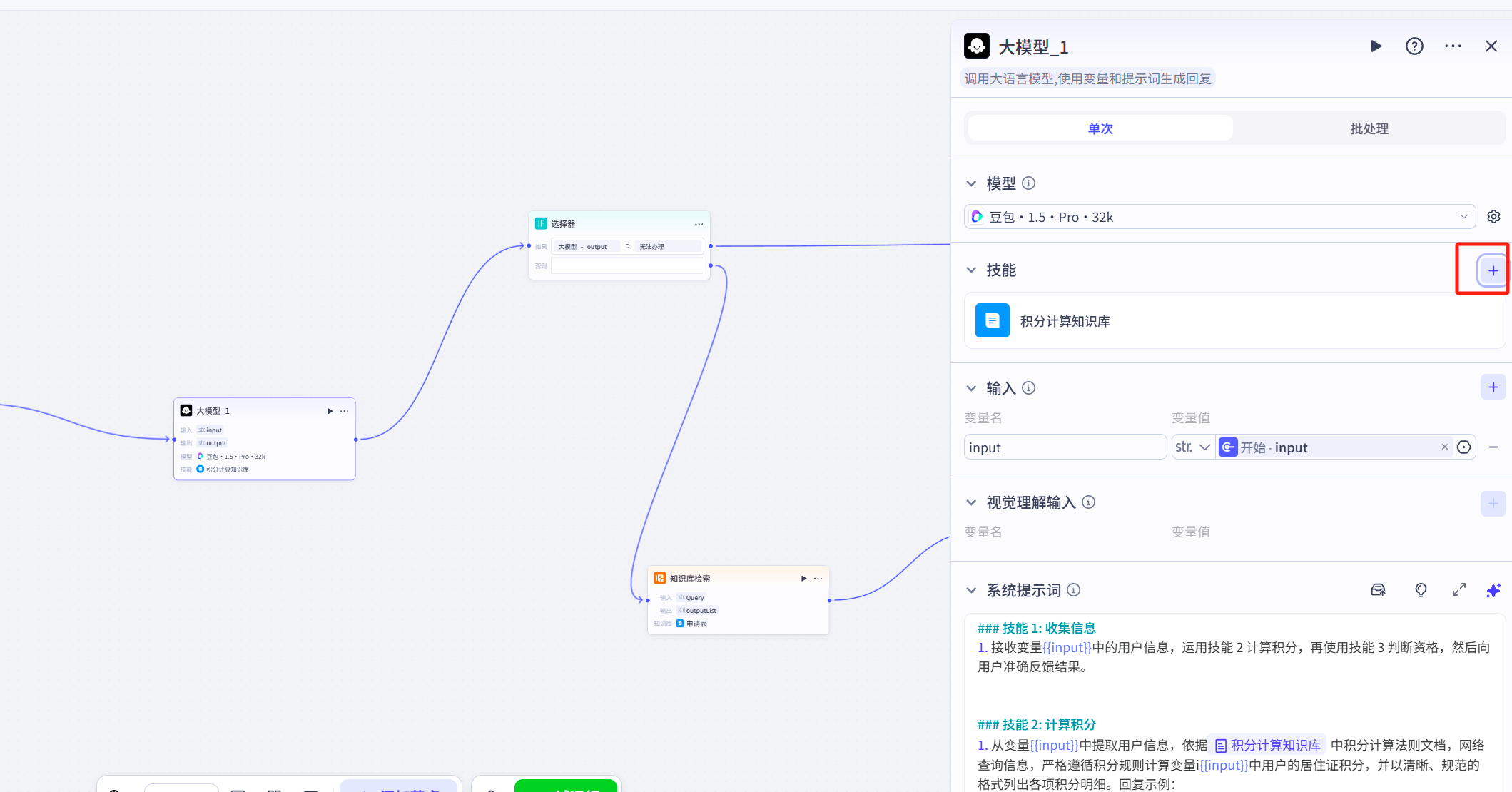
在弹出的界面中选择知识库,然后将我们创建好的知识库添加即可。
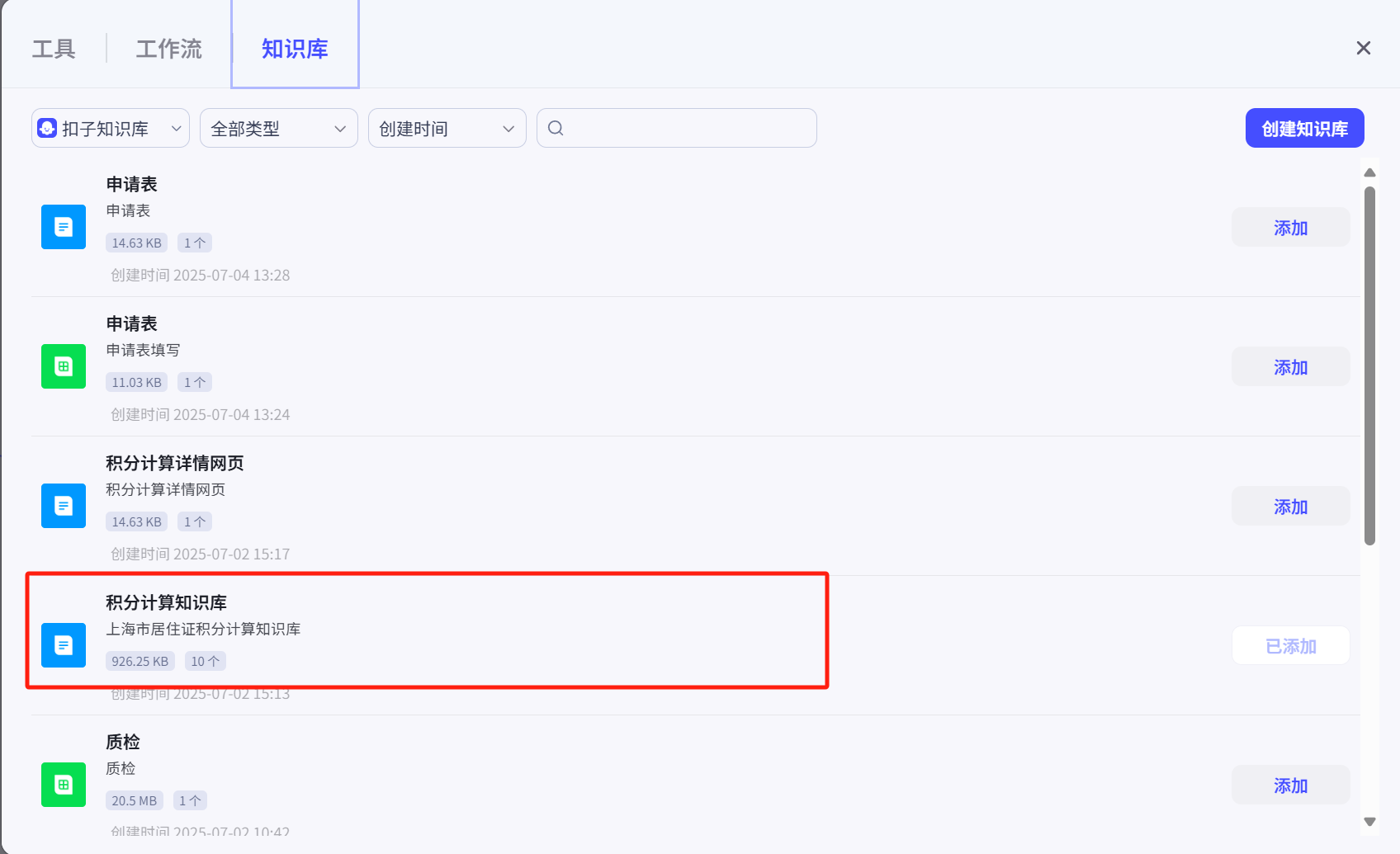
知识库说明
上传到扣子平台的知识库不会出现隐私泄露等问题,其余类型知识库构建方式基本一致

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)