零基础AI开发入门指南:从虚拟机装Linux、掌握终端命令到跑通第一个大模型
前言
是不是想入门AI大模型开发,一搜教程全是「先装Linux系统」「准备8卡A100显卡」,还没开始就被硬件门槛和环境搭建劝退?别慌——这篇博客是专门给零基础小白整理的AI开发最短入门路径:不用拆主机装双系统怕丢数据,不用花几万买专业显卡,跟着走完「虚拟机装Linux→掌握必备终端命令→跑通第一个大模型demo」的全流程,你也能跨进AI开发的大门。
虚拟机安装
VMware WorkStation下载地址: https://www.vmware.com/cn/products/workstation-pro.html
VMware安装后的验证
快捷键:win + r 打开运行窗口
输入:ncpa.cpl回车,可以看到自己电脑的网络适配器

当安装完成后,确认有VMnet1 好VMnet8 2个虚拟网卡
Ubuntu系统安装流程
ubuntu-20.04.6-desktop-amd64.iso系统安装光盘下载地址:https://releases.ubuntu.com/20.04/
打开VMware,点击新建虚拟机

自行输入用户名和密码
安装过程中完全自动化,无需干扰
安装后拍摄快照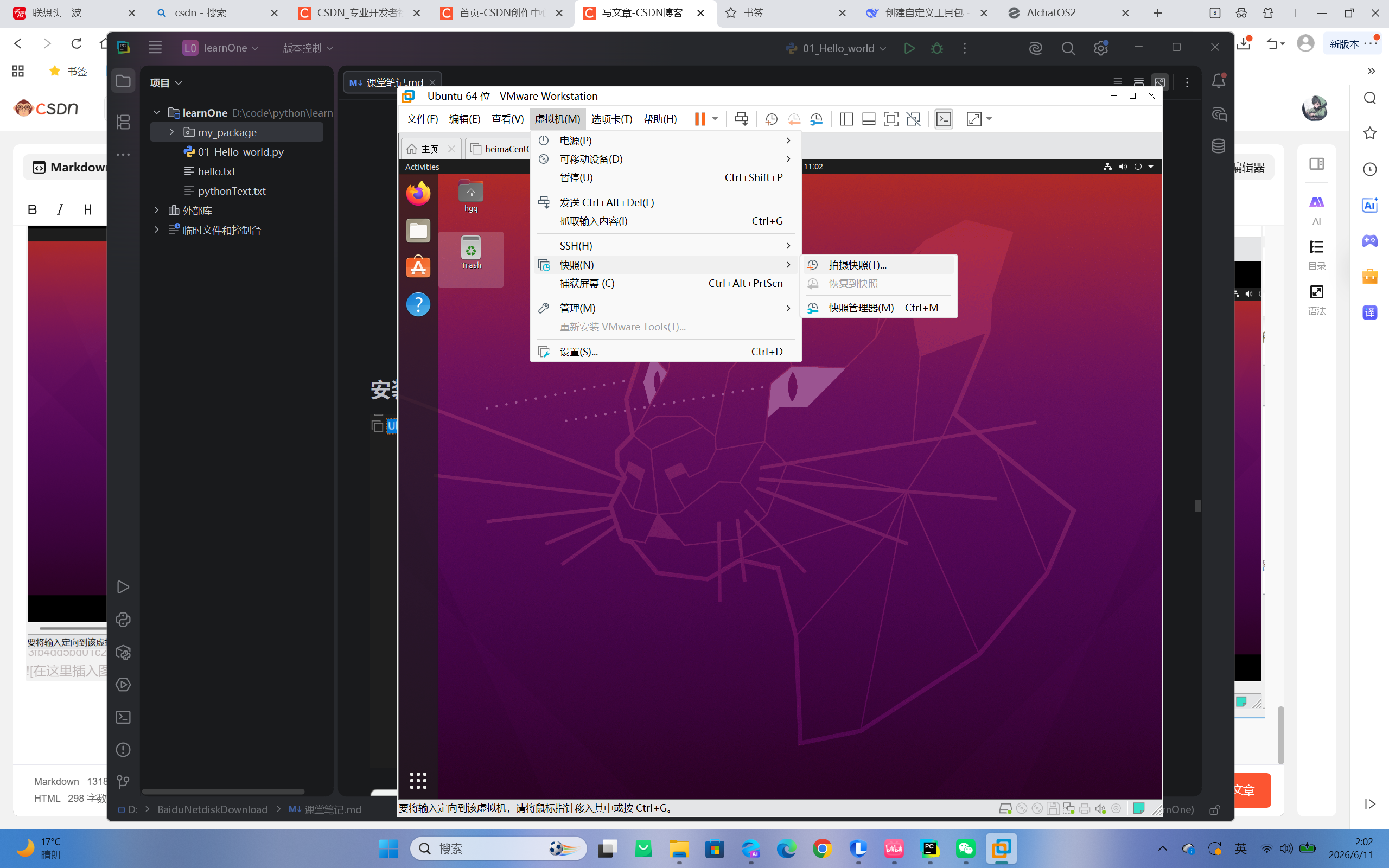
设置好后,后续有问题可以随时回退
检查是否联网
右键点击Open in Terminal
输入命令:ip addr 可以看到虚拟机的IP地址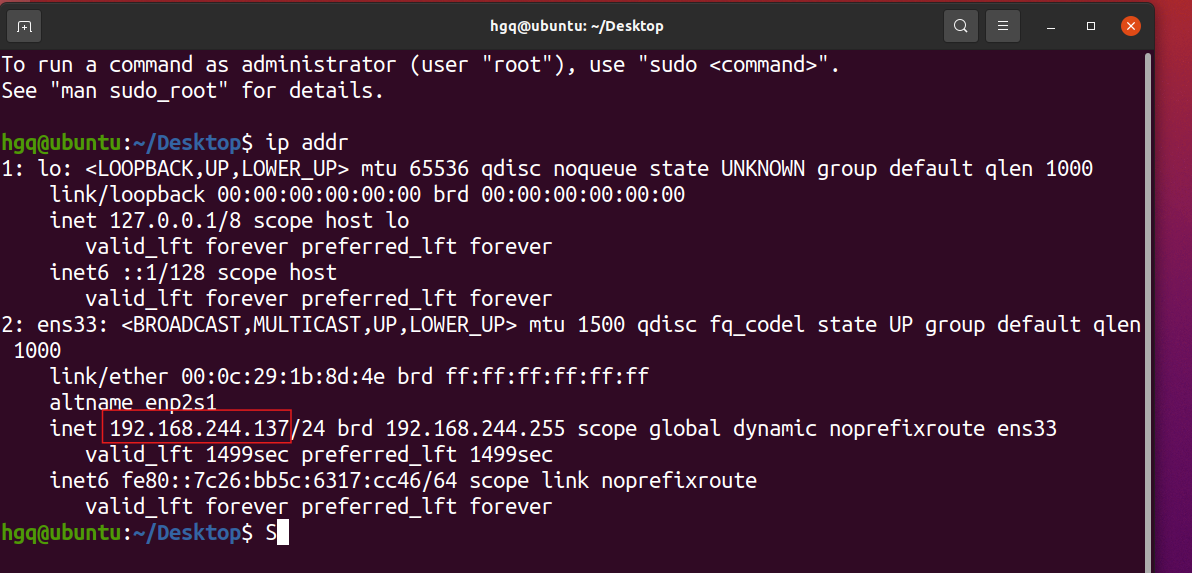
或者执行命令:ping baidu.com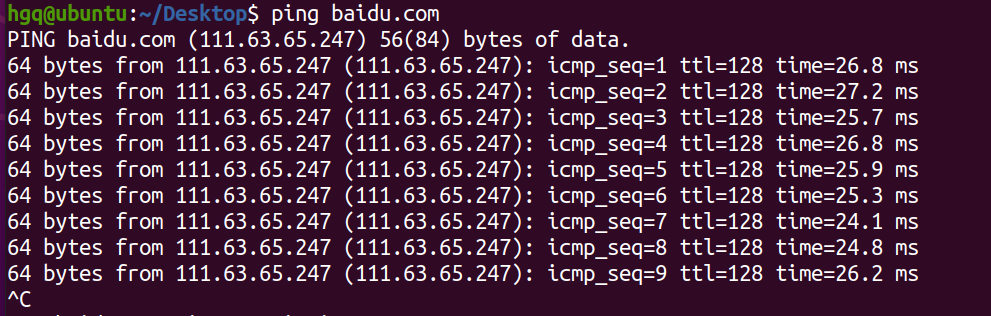
表示网络连接正常
通过MobaXtem进行远程连接到linux
打开终端
输入命令:
sudo apt install openssh-server

此时输入密码即可。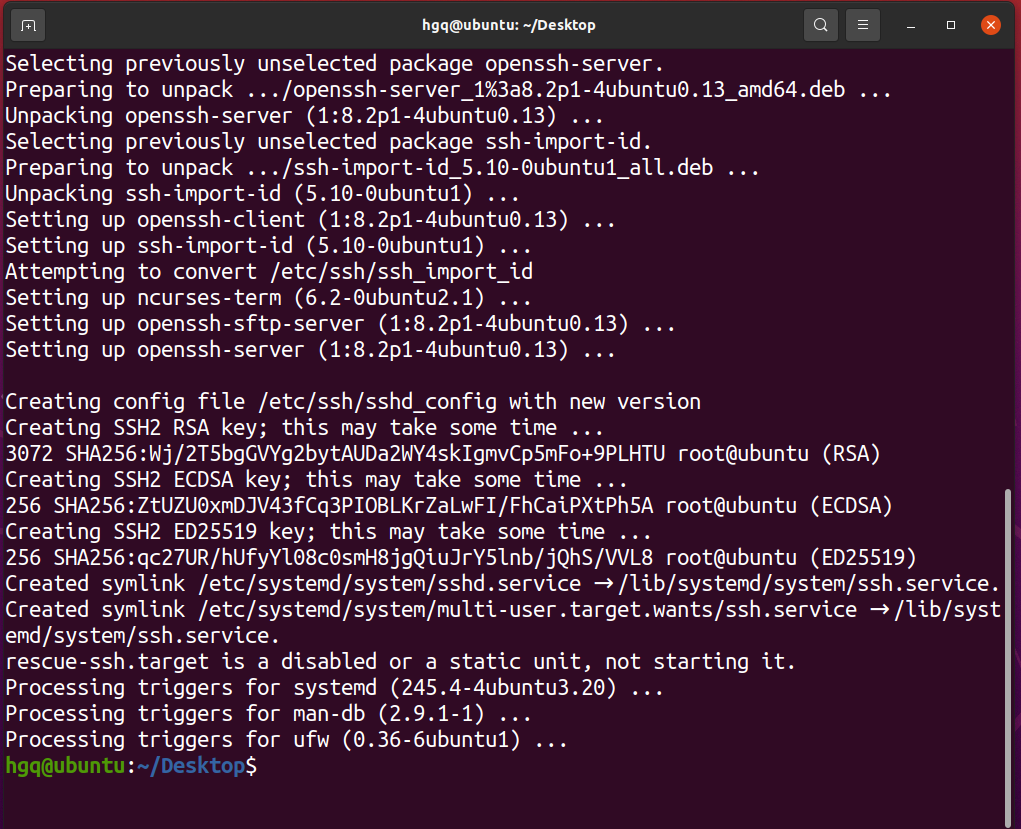
安装完成

选择ssh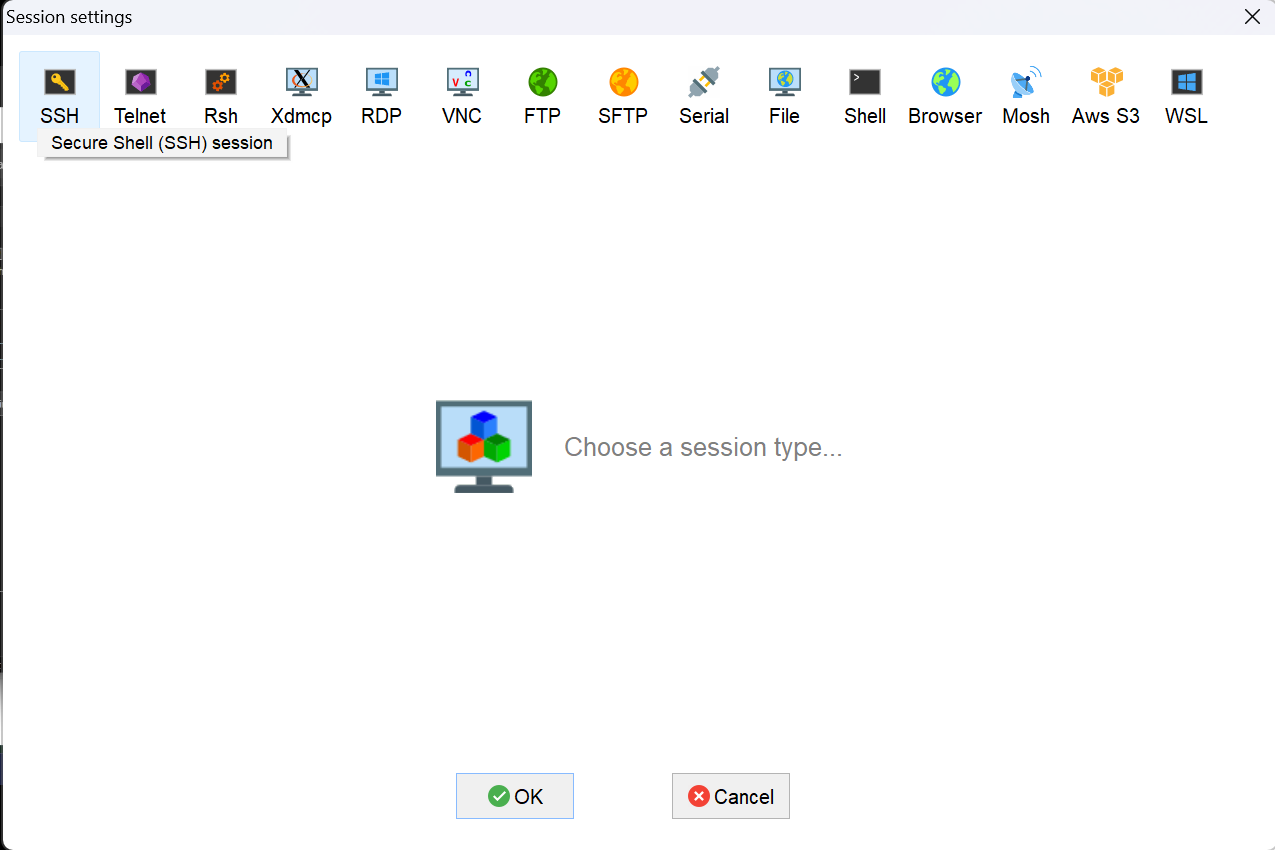
输入对应的ip地址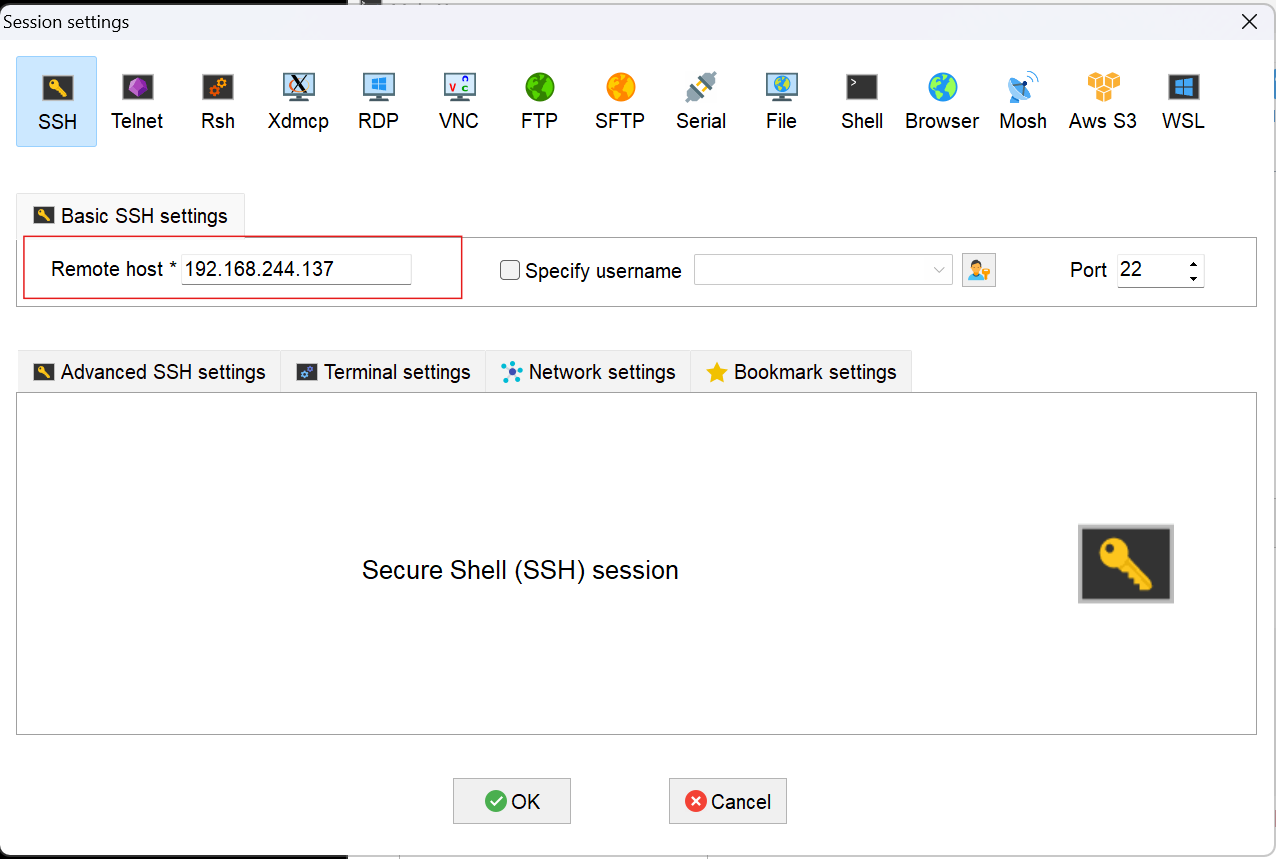
输入对应的用户名
连接后输入密码即可
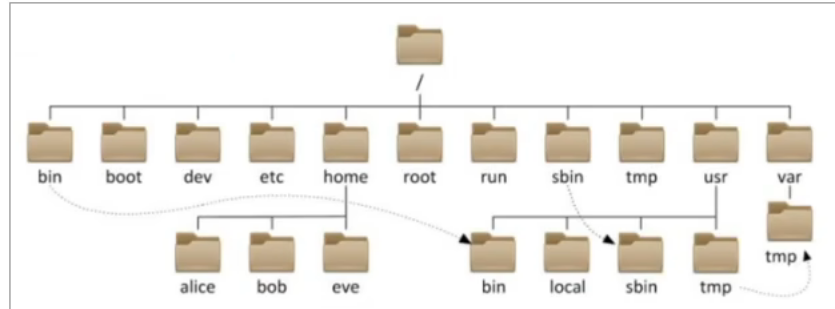
Linux目录结构
Linux的目录结构是一个树型结构Windows系统可以拥有多个盘符,如C盘、D盘、E盘
Linux没有盘符这个概念,只有一个根目录/,所有文件都在它下面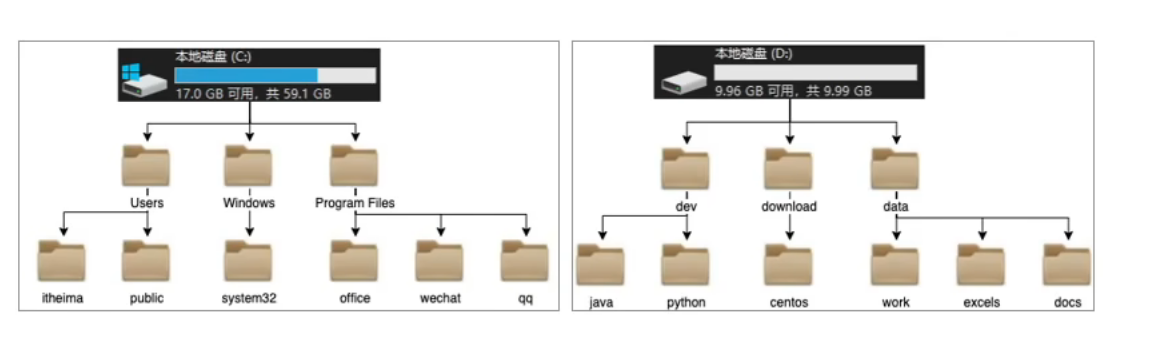
在Linux系统中,路径之间的层级关系,使用:/来表示来表示
在Windows系统中,路径之间的层级关系,使用:\
基础命令
命令基础格式

- command 命令本体,必写
- options可选选项,控制命令的细节
- parameter,可选参数,控制命令的指向目标
ls命令
ls [-a -l -h] [参数]
参数的作用
决定ls命令要查看的目标
ls / 查看根目录内容
ls /usr 查看/usr目录内容
-a选项
查看全部文件,包括隐藏文件,都显示
在Linux中以.开头的文件是隐藏文件和隐藏文件夹
-l选项
以列表形式查看内容
不用-l 以平铺形式查看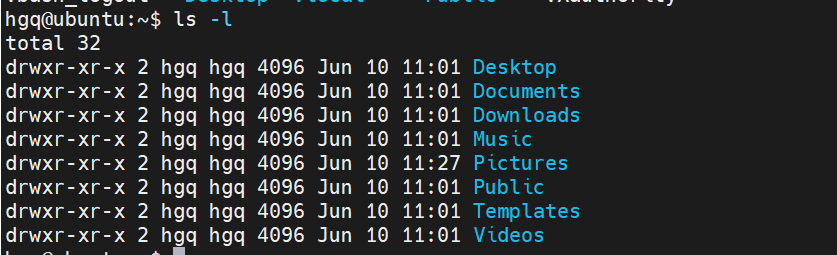
-h选项
以更容易理解的方式显示文件大小(以K M G为单位)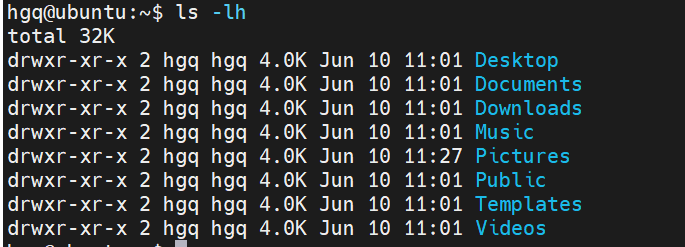
HOME目录
在Linux系统中每一个用户都有的专属文件夹,有全部操作权限
默认路径是:/home/用户名
比如用户名:caoyu则路径是:/home/caoyu
隐藏文件
以.开头的文件和文件夹是默认隐藏的需要用ls -a 的模式查看
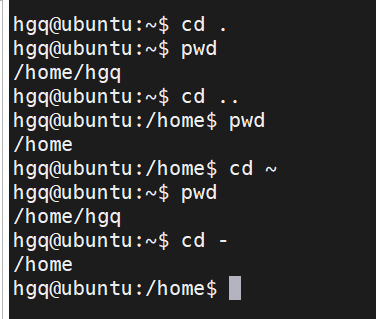
cd命令
更改工作目录
语法:
cd 路径
- 绝对、相对路径都可以
- cd命令无需选项,只有参数,表示要切换到哪个目录下
- cd命令直接执行,不写参数,表示回到用户的HOME目录
pwd命令
终端软件当前所在的目录,可以通过pwd 命令查看
语法:
pwd
没有选项、没有参数
终端软件当前所在的目录,可以通过pwd 命令查看

相对、绝对路径
- 相对:以当前所在文件夹为路径起点
- 绝对:以根目录所在文件夹为路径起点
路径符号
- . , 当前目录
- … ,上一级目录
- ~ ,用户的家目录
- – ,上一次的目录
mkdir命令
语法:
mkdir [-p] 路径
功能:创建指定文件夹
-p 连续创建多层级的文件夹,如mkdir -p test/hello/numOne
touch
功能:创建空文件
语法:
touch 文件路径
- touch命令无选项,参数必填,表示要创建的文件路径,相对、绝对、特殊路径符均可以使用
cat
功能:查看文件内容
语法:
cat 文件路径
more
功能:查看文件内容
语法:
more 文件路径
- 可以翻页查看,按空格翻页,按q 退出查看
more命令同样可以查看文件内容,同cat不同的是:
- cat是直接将内容全部显示出来
- more支持翻页,如果文件内容过多,可以一页页的展示
cp
功能:复制文件和文件夹
语法:
cp -r 参数1 参数2
- -r 选项用于文件夹复制
- 参数1 被复制的
- 参数2 要复制去的地方
mv
功能:移动文件和文件夹(Windows中的剪切)
语法:
mv 参数1 参数2
- 参数1 被移动的
- 参数2 要移动去的地方 如果不存在则改名
- 不需要-r 选项
rm
功能:删除文件和文件夹
语法:
rm [-r -f] 参数1 参数2 ... 参数N
- 参数,被删除的文件或文件夹
- -r 删除文件夹用
- -f 强制删除(不提示,直接删除)
可以写rm -rf *.txt * 表示通配符,表示 删除全部以.txt结尾的
注意,不要以root用户执行:rm -rf /*
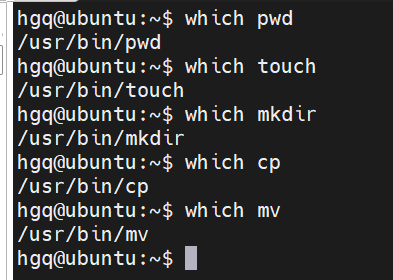
which
功能:查看在Linux系统中所有可执行的命令的文件本地所在。
在Linux系统中执行的命令,本身是一个程序,即一个程序文件。
语法
which 命令
find
功能:查找符合条件的文件所在
按文件名
语法:
find 起始路径 -name "被查找的文件名"
起始路径如果是/ 表示全盘搜索。
这样需要管理权限,即root权限。
可以通过执行:
- sudo su - 切换到root管理员用户去执行,
- 或sudo find … 在find命令前加入sudo临时获得管理员权限
被查找的文件名,支持通配符,如:
- find / -name “test*” 是在全盘搜索,以test开头的文件
- find / -name “*test” 搜索以test 结尾的文件
- find / -name “test” 搜索包含test 的文件
即,* == 任何 的结果都是True
按文件大小
语法:
find 起始路径 -size +|-n(k|M|G)
- +表示大于,- 表示小于
- n表示数字
- k M G 表示大小单位,k KB M MB G GB
示例
- +10k 大于10KB
- -10M 小于10MB
- +1G 大于1G
切换root用户
语法:
sudo su -
然后输入密码即可
grep
功能:在指定的内容(输入)中过滤包含关键字的行(仅保留包含关键字的行)
语法:
grep [-n] "关键字" 文件路径
- -n 显示过滤后的内容,在原始输入内容中的行号
示例:
- grep hello a.txt 在a.txt文件中,过滤hello关键字(仅保留包含hello关键字的行)
- grep -n hello a.txt 在a.txt文件中,过滤hello关键字(仅保留包含hello关键字的行),并显示行号
一般搭配管道符使用,如:ls /usr/bin | grep gst 查看/usr/bin下,带有gst关键字的内容
wc
功能:用来统计输入中的如:字节数量、字符数量、单词数量、行数量
语法:
wc [-c -m -l -w] 输入内容
- -c 统计字节
- -m 统计字符
- -l 统计行
- -w 统计单词数
如果不提供选项,则wc本身统计:字节、单词、行数
一般搭配管道符使用
管道符
功能:将管道符的左侧的结果,作为管道符右侧程序的输入。管道符本身是:
|
示例
ls -l /usr/bin | wc -l 将ls -l /usr/bin的结果作为wc命令的输入,含义就是:
- 统计/usr/bin文件夹下的内容数量
管道符可以写多个,如下:
ls -l /usr/bin | grep python | wc -l
- 将ls -l /usr/bin的结果作为grep python 的输入
- 将ls -l /usr/bin | grep python的结果作为wc -l的输入
- 含义:统计/usr/bin 下带有python关键字的内容的数量
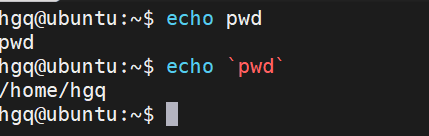
echo
功能:和Python的print一样,将内容输出到屏幕中。
语法:
echo 内容
反引号 `
在Linux中,被`包围的内容,将作为命令去执行。
如:
- echo pwd 将输出pwd字样
- echo
pwd# 将输出pwd运行的结果,即当前所在工作目录
重定向符
重定向符:>和>>
- (>),将左侧命令的结果,覆盖写入到符号右侧指定的文件中
- (>>),将左侧命令的结果,追加写入到符号右侧指定的文件中
如果右侧提供的文件不存在,则新建
tail
功能:查看文件尾部或跟踪文件更改
语法:
tail [-f | -num] 文件路径
- -f 表示持续跟踪文件更改,如需退出按ctrl + c退出
- -num 表示查看文件尾部多少行,默认是-10
apt命令
Linux系统的应用商店,在命令行模式下是:apt命令
通过这个命令可以联网安装软件
语法:
apt install || remove 程序名 [-y]
必须联网
- install 安装程序
- remove 删除程序
- -y可选,表示不要提示直接执行
此命令需要root权限,普通用户无权执行。
解决方式:
通过sudo su - 切换到root用户执行
通过sudo apt install xxx 以root权限执行这个命令
- sudo 表示不切换用户,但是此命令以root身份执行
Vim编辑器
vi\vim是visualinterface的简称,是Linux中最经典的文本编辑器同图形化界面中的文本编辑器一样,vi是命令行下对文本文件进行编辑的绝佳选择。vim是vi的加强版本,兼容vi的所有指令,不仅能编辑文本,而且还具有shell程序编辑的功能,可以不同颜色的字体来辨别语法的正确性,极大方便了程序的设计和编辑性。
VI编辑器是命令行下面的类似文本编辑器的程序,可以在命令行下完成文件的编辑。
有3个工作模式:
- 命令模式,可以输入各类快捷指令,如删除行、跳转光标等等
- 输入模式,可以正常输入你想要的内容,即开始编辑文件
- 底线命令模式,可以完成对整个文件的控制,如保持、退出等
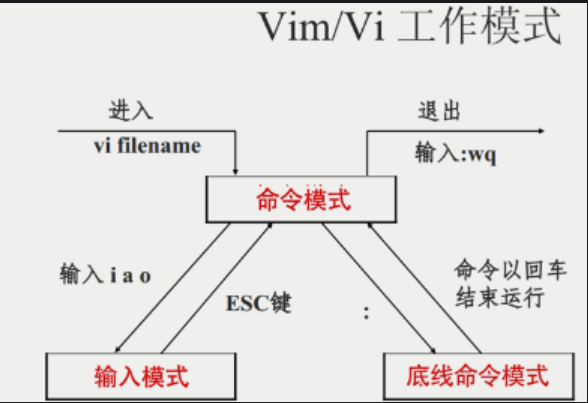
语法:
vi 文件路径
vim 文件路径
如果文件路径表示的文件不存在,那么此命令会用于编辑新文件
如果文件路径表示的文件存在,那么此命令用于编辑已有文件
命令模式
当进入vi编辑器,就是命令模式,此模式下可以通过快捷键完成对文件内容的控制,如下: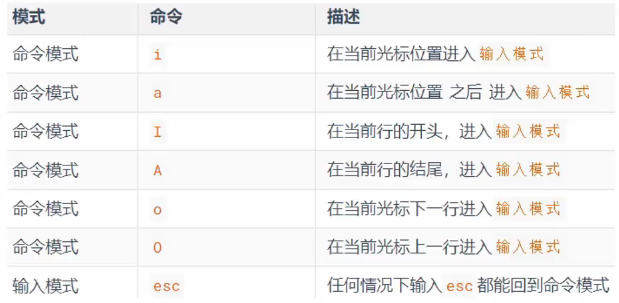
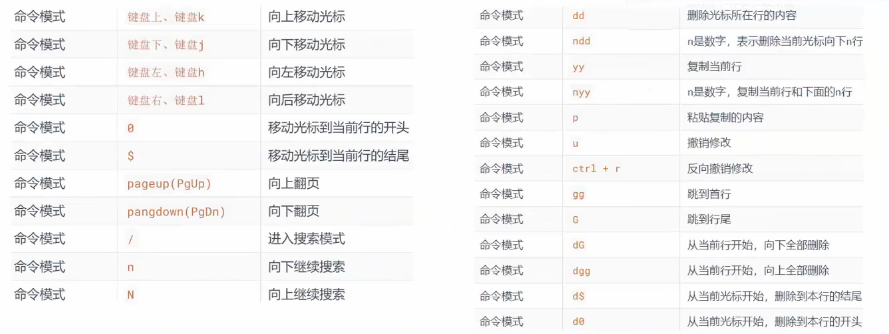
输入模式
输入模式可以在这个模式下正常编写内容
如果要进入输入模式,必须在命令模式下,通过快捷键进入:
- i 在当前光标位置,开始编辑
- o 在光标下一行开启新行进行编辑
- O 在光标上一行开启新行进行编辑
- a在光标右侧开始编辑
- A 在光标所在行的尾部开始编辑
一般就用:i 立刻编辑 或 o 下一行开始编辑
AI大模型开发
大模型,一般也称为"大语言模型”,是一种基于深度学习技术训练出来的人工智能系统,主要用于处理和生成人类语言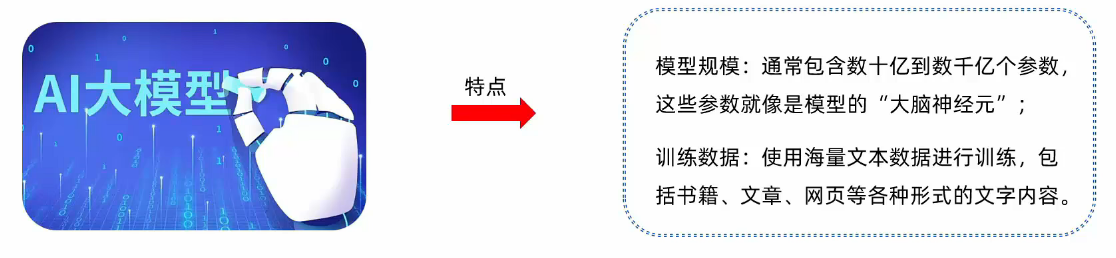
深度学习就是用层数较多(深)的人工神经网络从数据中学习输入与输出之间映射关系的算法,而人工神经网络是受生物神经网络的结构和功能启发下设计的计算模型。
用深度学习训练得到的网络就叫深度神经网络,它可以简单的看成一个函数,能够完成任何输入到输出的转换。
比如:
我们可以用它玩成语补全的游戏,输入成语的前三个字,让网络输出最后一个字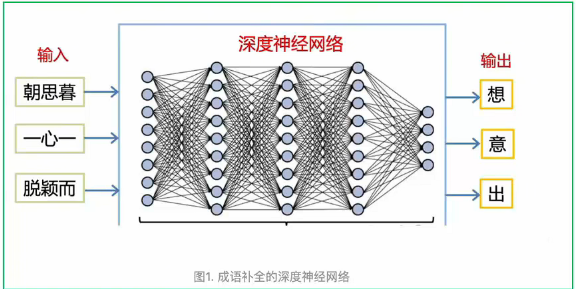
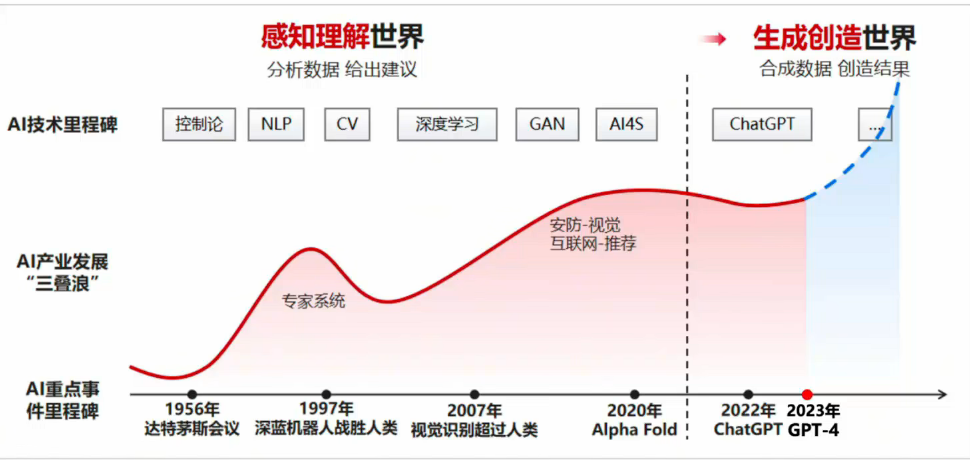
大模型核心运行机制
预训练大(语言)模型主要是基于深度学习技术所研发,其核心开发的过程比较深奥,我们以简化的视角去理解大模型是如何训练出来的。
大模型的实现原理可以简单归纳为:三步走
"学会说话”
利用深度神经网络来训练语言模型,先收集尽可能多的文本,每次随机抽一段上文,让模型学会接着往下“背诵”
由于看过和背过的文字实在是太多了(实际训练使用了几乎所有能从各种渠道获得的文字和图书资源)模型就可以像模像样地说话了。
“理解意图”
简单的说就是理解用户的需求是什么。
自然语音(人类语音)是非结构化的,以中文为例,同样的含义可以有不同的说法。通过训练,让大模型可以准确的识别用户的意图。并基于“给上文、补下文”的形式完成回答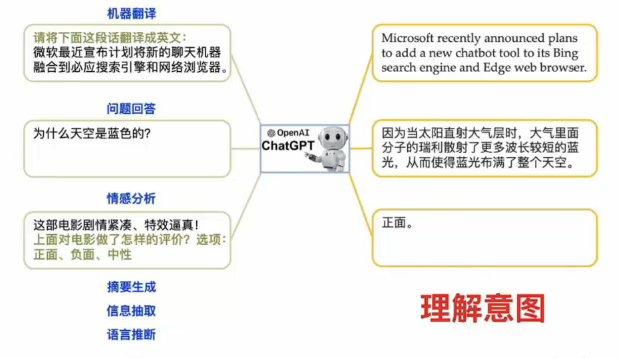
反馈择优”
对于某些问题,模型可能会生成带有偏见、歧视或者令人不适的回答。另外,之前提到过对于同一个问题,模型能够生成多个不同的回答。
这一步中我们让人们对同一问题的不同回答进行排序然后采用强化学习算法进一步调整模型,使输出回答更符合人们的期望。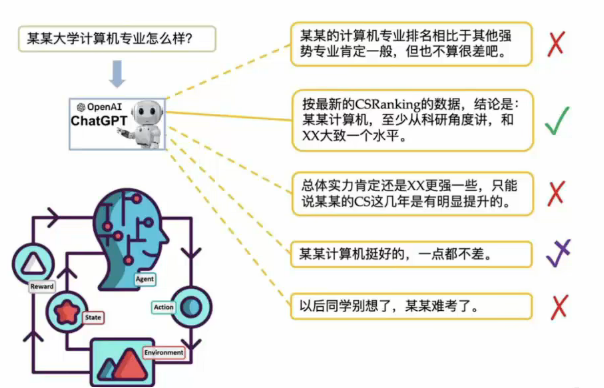
Deepseek和蒸馏模型

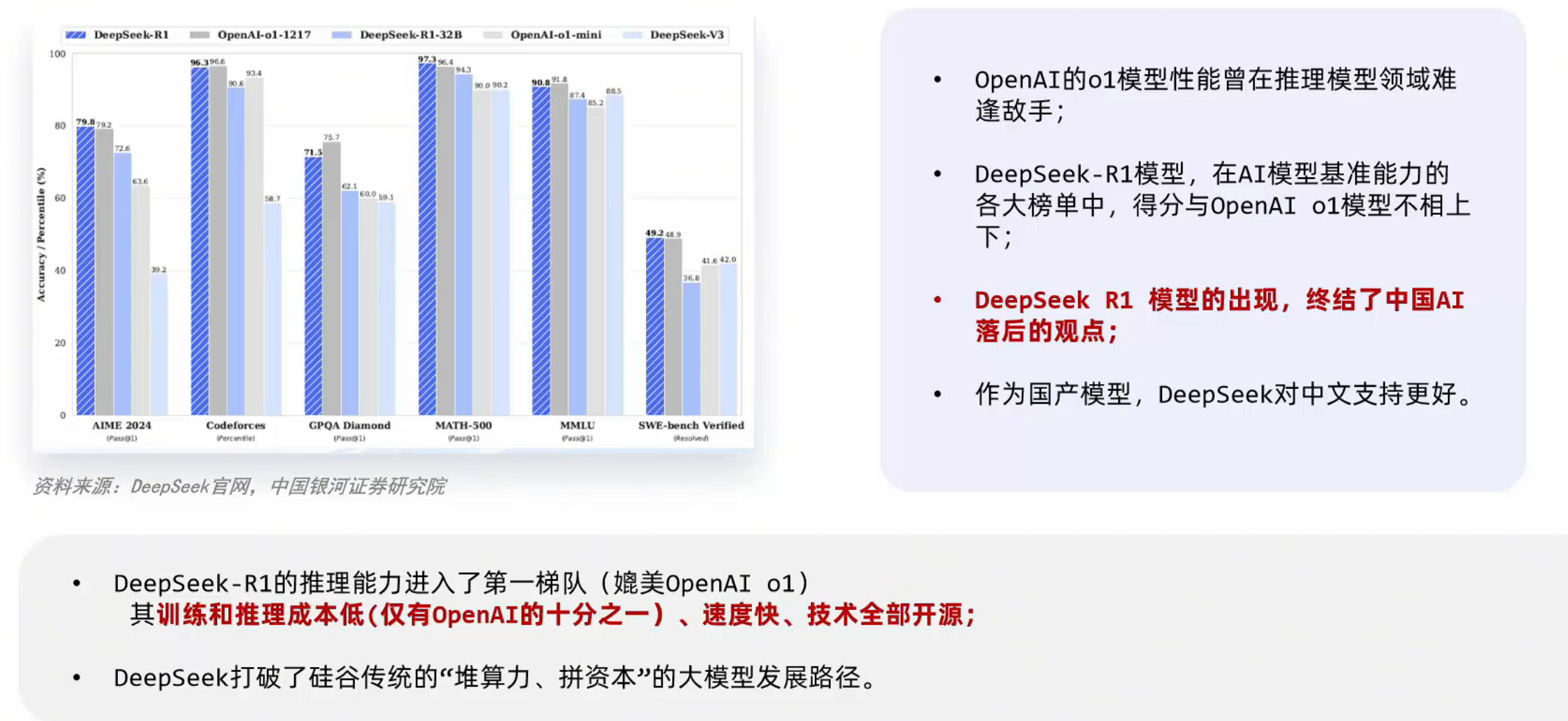
很多的大模型是开源的,以deepseek为例,其r1模型就是开源的,任何人都可以下载得到它的模型。https://github.com/deepseek-ai/DeepSeek-R1
大模型的运行需要极高的硬件资源,通常都是服务器集群并挂载数量众多的GPU(显卡)。
为了满足低性能设备的运行,可以对大模型进行蒸馏。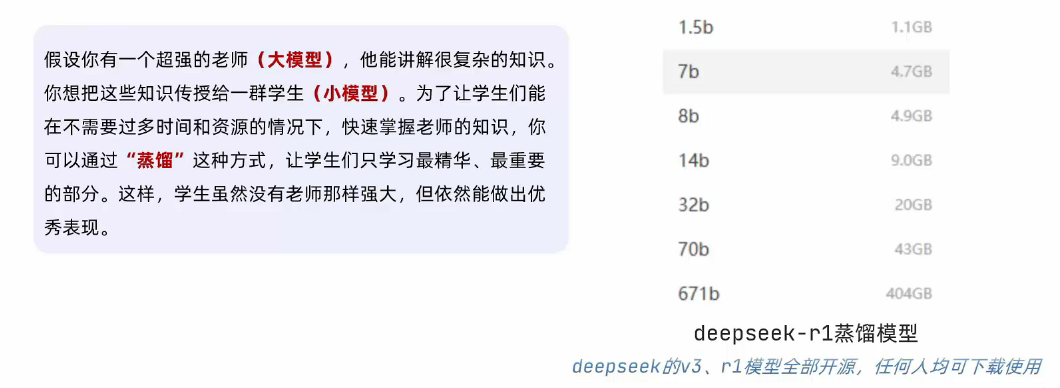
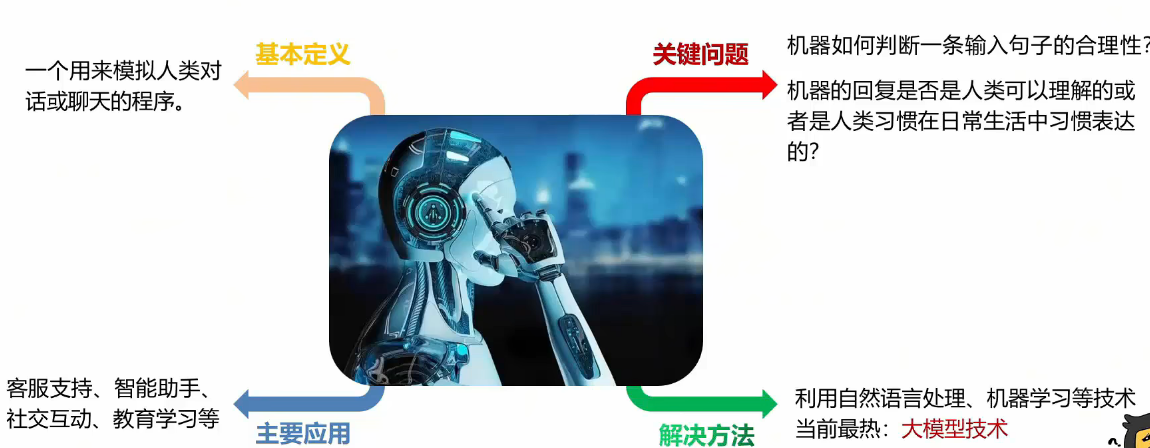
聊天机器人的特点
1.自然语言理解(NLP):能够理解用户输入自然语言,并从中提取意图和关键信息。
2.对话管理:通过对话引擎维持对话的连贯性,根据上下文生成合适的回答。
3.个性化交互:可以根据用户的历史记录和偏好提供定制化的回答。
4.多功能性:除了聊天,还可以执行任务,如查询信息、预订服务、提供帮助等。
应用场景:
1.客户服务:在电商、金融等领域,自动解答用户问题,提供24*7的客户支持。
2.娱乐:一些聊天机器人可以与用户进行趣味对话,提供娱乐体验。
3.教育:用于语言学习、知识问答等教育场景。
4.智能家居:控制家电设备,如灯光、空调等。
5.医疗健康:提供健康咨询、预约挂号等服务。
常见聊天机器人:
DeepSeek
由杭州深度求索人工智能基础技术研究有限公司研发,其核心优势在于性能卓越、低成本开发和开源策略
Kimi智能助手
由月之暗面科技有限公司开发,支持超长上下文(最高200万汉字),适合长文本处理和复杂对话。
通义千问
阿里云推出的人工智能助手,适合办公场景,提供高效的信息处理能力。讯飞星火
科大讯飞出品,支持语音输入和语音朗读回复,适合语音交互场景。
豆包
字节跳动推出,支持抖音和今日头条的内容信息获取,适合内容创作和信息检索。
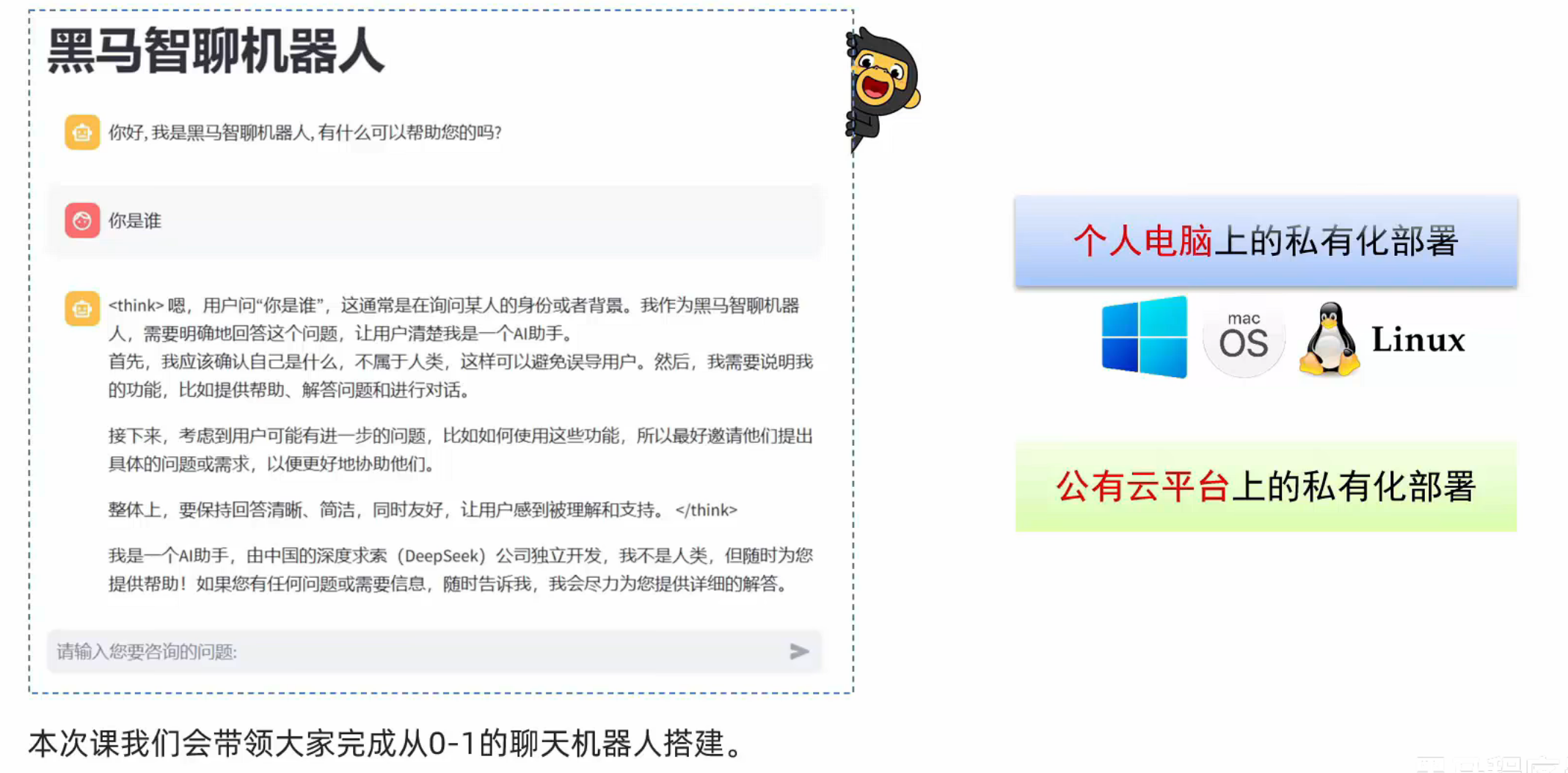
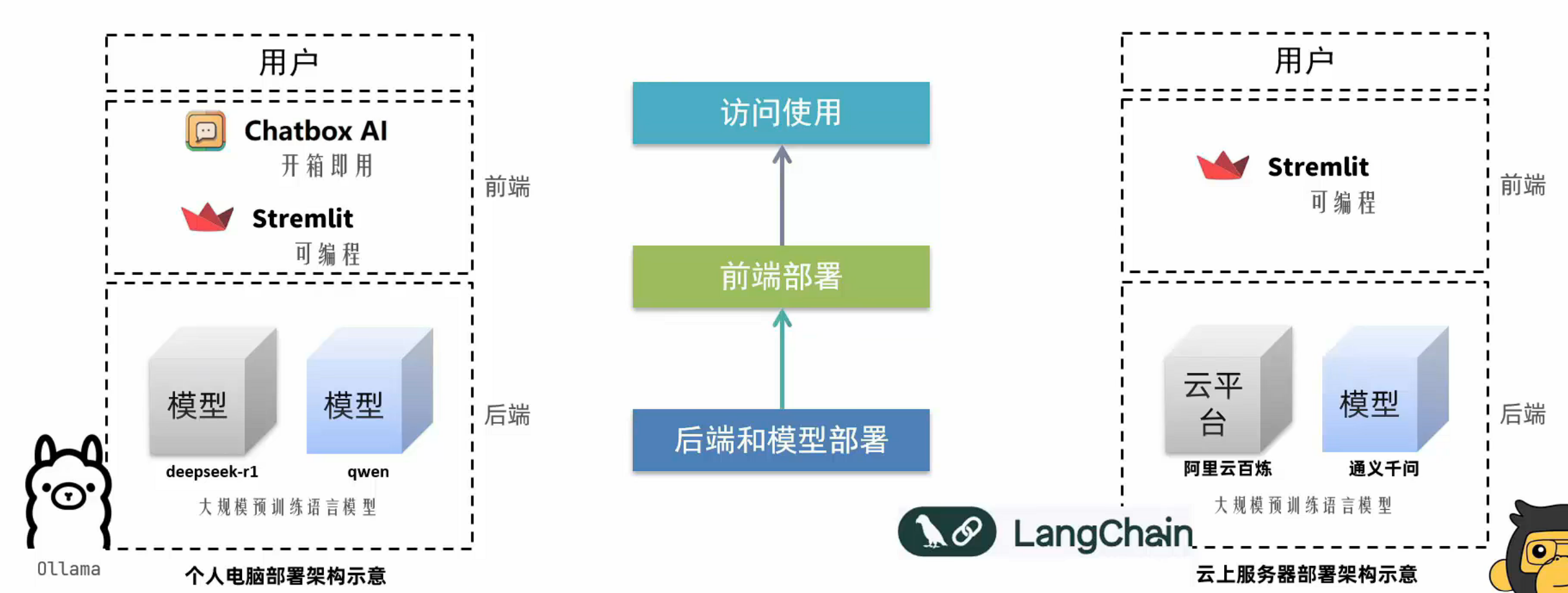
个人电脑智聊机器人技术架构
总结
AI大模型不是只有顶尖 researcher 才能碰的东西,现在它已经是每个开发者都能用的生产力工具。你跨出的这第一步,已经超过了90%还在观望的人。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)