贝尔曼方程的原理与在强化学习的应用
目录
3.最优动作价值Q∗(s,a)贝尔曼最优方程(最优策略π∗)
1.引言
在强化学习马尔可夫决策过程框架中,环境由五元组(S,A,P,R,γ)定义:S为有限状态集合,A为动作集合,P(s′,r∣s,a)是状态转移与奖励联合概率,R为即时奖励函数,γ∈[0,1]为折扣因子;智能体策略π(a∣s)代表在状态s下选取动作a的条件概率,所有价值函数、贝尔曼方程都建立在这套MDP标准框架之上。
2.动作价值函数Qπ(s,a)的贝尔曼期望方程
状态价值Vπ(s)的物理含义:智能体从状态s出发,持续遵循策略π执行后续所有动作,能获得的长期累积期望回报。无限折扣累积回报定义为:
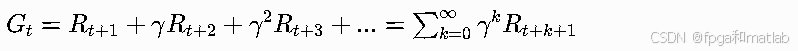
取数学期望得到状态价值原始表达式:
![]()
期望下标Eπ代表整个轨迹的动作采样、状态转移全部服从策略π与环境转移概率P。
动作价值Qπ(s,a)物理含义:在状态s主动选定动作a,后续全程遵循策略π,所能获得的长期期望累积回报。其原始期望定义为:
![]()
同理做回报递归拆分Gt=r+γGt+1,代入期望并逐层展开概率求和: 选定动作a后,环境按p(s′,r∣s,a)发生状态转移,到达s′后再按策略π选择后续所有动作,因此下一阶段的价值是状态价值Vπ(s′)。
最终推导得到动作价值贝尔曼期望方程:
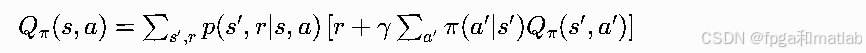
贝尔曼期望方程的核心应用场景是策略评估:给定任意固定策略π,迭代求解每一个状态对应的Vπ(s)或Qπ(s,a),量化该策略下智能体能拿到的长期回报数值,以此判断策略优劣。
3.最优动作价值Q∗(s,a)贝尔曼最优方程(最优策略π∗)
贝尔曼期望方程只能评估已有策略,无法自动优化策略;而贝尔曼最优方程引入最大化算子max,抛弃固定策略概率加权,直接在每个状态、每个动作上选择能带来最大长期回报的决策,求解全局最优价值函数与最优策略。
最优动作价值Q∗(s,a)=maxπQπ(s,a),代表在状态s执行动作a后,后续全程采用最优策略能获得的最大长期累积回报。 执行动作a后,环境发生状态转移抵达s′,后续直接选取最优动作,对后续动作a′做最大化操作,最终公式:
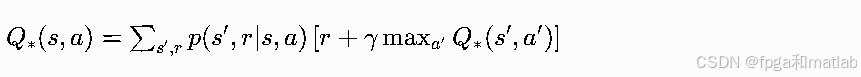
4.贝尔曼方程在强化学习算法中的实现步骤
强化学习经典范式“策略迭代、值迭代、Q-learning、DQN”全部依托贝尔曼方程迭代更新,下面逐个拆解每一步数学公式、执行逻辑、贝尔曼方程的嵌入位置。我们以比较熟悉的Q-learning算法为例进行说明。
值迭代、策略迭代是有模型算法,需要提前完整知晓环境转移概率p(s′,r∣s,a);而现实自动驾驶、游戏 AI 等场景无法获取环境精确转移模型,此时采用无模型强化学习,直接用环境交互采样样本拟合贝尔曼最优方程,Q-learning 是代表算法。
步骤1:初始化
构建Q表格Q(s,a),所有状态-动作对(s,a)初始值置0;设定γ、学习率α、探索率ε;初始化智能体起始状态s。
步骤2:动作采样
以ε概率随机选取动作探索未知动作,1−ε概率贪心选取当前Q值最大的动作:
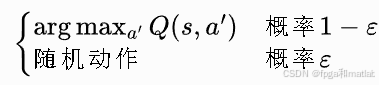
步骤3:环境交互采样单步样本
在状态s执行动作a,环境返回下一状态s′、即时奖励r、终止标记done。
步骤4:Q值单步更新
无模型场景下没有环境转移概率,直接用单条采样样本代替期望求和,构造时序差分更新公式:
![]()
公式中r+γmaxa′Q(s′,a′)是贝尔曼最优方程的单样本估计目标值,Q(s,a)是旧估计值,二者差值为时序差分误差,乘以学习率α小幅修正Q表格。
Q-learning不依赖环境模型,直接用采样样本拟合最优动作贝尔曼方程,时序差分更新的目标项完全来自Q∗(s,a)递归形式,是贝尔曼方程从 “有模型理论公式” 落地到 “无模型工程实现” 的关键算法。
5.贝尔曼期望方程的python实现
固定策略:每个状态永远向右走,迭代求解Vπ(s)。对应数学公式:
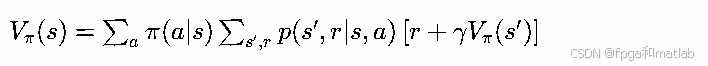
import numpy as np
# 1. 环境参数
GRID_SIZE = 4
STATE_NUM = GRID_SIZE * GRID_SIZE
ACTIONS = [(-1,0), (1,0), (0,-1), (0,1)] # 上、下、左、右
gamma = 0.9
theta = 1e-6 # 收敛阈值
terminal_state = 15
# 坐标转状态编号
def pos2state(row, col):
return row * GRID_SIZE + col
# 状态编号转坐标
def state2pos(s):
row = s // GRID_SIZE
col = s % GRID_SIZE
return row, col
# 环境转移函数:确定性转移,返回 (下一状态, 即时奖励)
def env_step(s, a):
if s == terminal_state:
return terminal_state, 0.0
r, c = state2pos(s)
dr, dc = ACTIONS[a]
nr = max(0, min(r + dr, GRID_SIZE-1))
nc = max(0, min(c + dc, GRID_SIZE-1))
s_next = pos2state(nr, nc)
reward = 0.0 if s_next == terminal_state else -1.0
return s_next, reward
# ----------------------
# 固定策略:所有状态都选「向右」,动作索引3
# π(a|s):向右概率=1,其余动作=0
# ----------------------
def policy_pi(s):
pi = np.zeros(4)
pi[3] = 1.0
return pi
# 贝尔曼期望方程迭代求解 Vπ(s)
def policy_evaluation():
V = np.zeros(STATE_NUM) # 初始化状态价值
while True:
delta = 0.0
V_new = np.zeros_like(V)
for s in range(STATE_NUM):
if s == terminal_state:
V_new[s] = 0.0
continue
pi_a = policy_pi(s)
v_sum = 0.0
for a in range(4):
prob_a = pi_a[a]
if prob_a == 0:
continue
# 确定性环境 p=1,不用遍历概率分布
s_next, r = env_step(s, a)
v_sum += prob_a * (r + gamma * V[s_next])
V_new[s] = v_sum
delta = max(delta, abs(V_new[s] - V[s]))
V = V_new
if delta < theta:
break
return V
# 运行策略评估
V_pi = policy_evaluation()
print("===== 贝尔曼期望方程 | 固定策略状态价值 Vπ =====")
print(V_pi.reshape(GRID_SIZE, GRID_SIZE).round(2))基于最优贝尔曼方程:
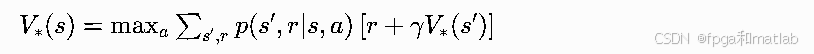
def value_iteration():
V = np.zeros(STATE_NUM)
while True:
delta = 0.0
V_new = np.zeros_like(V)
for s in range(STATE_NUM):
if s == terminal_state:
V_new[s] = 0.0
continue
max_q = -np.inf
# 遍历所有动作,取最大值max_a
for a in range(4):
s_next, r = env_step(s, a)
q_val = r + gamma * V[s_next]
if q_val > max_q:
max_q = q_val
V_new[s] = max_q
delta = max(delta, abs(V_new[s] - V[s]))
V = V_new
if delta < theta:
break
return V
V_star = value_iteration()
print("\n===== 贝尔曼最优方程 | 最优状态价值 V* =====")
print(V_star.reshape(GRID_SIZE, GRID_SIZE).round(2))最优动作价值贝尔曼方程:
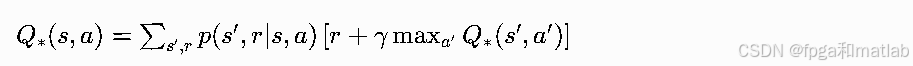
def q_value_iteration():
Q = np.zeros((STATE_NUM, 4))
while True:
delta = 0.0
Q_new = np.zeros_like(Q)
for s in range(STATE_NUM):
if s == terminal_state:
Q_new[s, :] = 0.0
continue
for a in range(4):
s_next, r = env_step(s, a)
# max_{a'} Q(s',a')
max_next_q = np.max(Q[s_next, :])
Q_new[s,a] = r + gamma * max_next_q
delta = max(delta, abs(Q_new[s,a] - Q[s,a]))
Q = Q_new
if delta < theta:
break
return Q
Q_star = q_value_iteration()
print("\n===== 最优动作价值Q*(每个状态最优动作索引) =====")
best_action = np.argmax(Q_star, axis=1).reshape(GRID_SIZE, GRID_SIZE)
act_map = {0:"↑",1:"↓",2:"←",3:"→"}
for row in best_action:
print([act_map[i] for i in row])无模型单步贝尔曼更新,不用环境转移概率,用交互样本做贝尔曼目标更新:
![]()
def q_learning(episodes=5000, lr=0.1, eps=0.1):
Q = np.zeros((STATE_NUM, 4))
for ep in range(episodes):
s = 0 # 每轮从起点0出发
while s != terminal_state:
# ε-greedy选动作
if np.random.rand() < eps:
a = np.random.randint(4)
else:
a = np.argmax(Q[s])
s_next, r = env_step(s, a)
# 贝尔曼时序差分更新
td_target = r + gamma * np.max(Q[s_next])
td_error = td_target - Q[s,a]
Q[s,a] += lr * td_error
s = s_next
return Q
Q_learn = q_learning()
print("\n===== Q-learning收敛后最优动作策略 =====")
best_act_learn = np.argmax(Q_learn, axis=1).reshape(GRID_SIZE, GRID_SIZE)
for row in best_act_learn:
print([act_map[i] for i in row])
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)