PyTorch训练避坑指南:从“能跑通”到“跑得好”的完整路径
一、开篇:从「能跑」到「能跑好」的鸿沟
一句话点睛:搭一个网络跑通不难,难的是让它收敛、稳定、不 OOM。
上一篇(快速入门 PyTorch)里我们用 100 行代码跑通了 y = x 2 y = x^2 y=x2 的拟合。看着 loss 一路下降,曲线完美贴合,那种感觉确实让人上头。
但真到实际项目,你大概率会撞上这几面墙:
- ❌
loss.backward()跑完,模型却越来越笨 → 梯度忘记清零 - ❌
RuntimeError: mat1 and mat2 shapes cannot be multiplied→ 维度没对齐 - ❌
CUDA out of memory→ batch_size 没算对 / 没用no_grad()推理 - ❌ loss 震荡、训练集正确率 99%、测试集 60% → 过拟合 / 没做正则化
- ❌ 训练到一半 loss 突然变成
NaN→ 学习率太大 / 梯度爆炸
这些坑的根源,不在网络结构,而在「训练」本身。本文要讲透的就是这件事——
- 损失函数:怎么衡量「错」
- 数据加载:怎么把数据高效送进模型
- 自动微分(Autograd):
loss.backward()这一行的魔法 - 优化器与学习率调度:梯度算出来之后,参数怎么更新
- 参数初始化:训练开始前,权重长什么样
- 正则化:怎么让模型不"死记硬背"
📝 阅读路线
本文是 PyTorch 系列第 2 篇。前置知识:快速入门 PyTorch(Tensor、nn.Module、训练循环基础)。
二、损失函数:模型"错"了多少?
损失函数衡量的是模型预测值和真实值之间的差距。训练的本质就是最小化这个差距。所以选错损失函数,相当于给模型立了错的目标——再努力也白搭。
损失函数的选择完全取决于任务类型:
| 任务 | 推荐损失 | 备注 |
|---|---|---|
| 回归(连续值) | MAE / MSE / Smooth L1 | 预测房价、温度等 |
| 二分类(是/否) | BCEWithLogitsLoss |
垃圾邮件、疾病诊断 |
| 多分类(互斥类别) | CrossEntropyLoss |
手写数字、ImageNet |
⚠️ 参数顺序约定
PyTorch 所有损失函数的参数顺序都是 先 pred,后 target:loss = loss_fn(output, target) # ✅ 先预测,再真实 loss = loss_fn(target, output) # ❌ 传反了不会报错,但 loss 算的是错的传反了模型也能跑(类型兼容时),但 loss 算的是错的,模型不会收敛。
2.1 回归任务:MAE / MSE / Smooth L1
【MAE(L1Loss)】
平均绝对误差——预测值与真实值之差的绝对值的平均。对异常值不敏感(梯度恒定):
MAE = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
output = torch.randn(5) # 模型预测
target = torch.randn(5) # 真实值
loss = nn.L1Loss()(output, target)
【MSE(MSELoss)】
均方误差——预测值与真实值之差的平方的平均。对异常值敏感(平方会放大误差):
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
loss = nn.MSELoss()(output, target)
💡 MAE vs MSE
特性 MAE MSE 对异常值敏感度 低(梯度恒定为 ±1) 高(平方放大) 梯度特性 远离 0 也不增大 越远离 0 梯度越大 适用场景 数据有较多异常值 数据干净、追求平滑
【Smooth L1Loss】
结合 MAE 和 MSE 的优点——误差小时用 MSE(梯度平滑好优化),误差大时退化为 MAE(防梯度爆炸)。目标检测的回归分支几乎都用它(Faster R-CNN、YOLO):
SmoothL1 ( x ) = { 0.5 x 2 , ∣ x ∣ < 1 ∣ x ∣ − 0.5 , otherwise \text{SmoothL1}(x) = \begin{cases} 0.5 x^2, & |x| < 1 \\ |x| - 0.5, & \text{otherwise} \end{cases} SmoothL1(x)={0.5x2,∣x∣−0.5,∣x∣<1otherwise
loss = nn.SmoothL1Loss()(output, target)
2.2 二分类:BCE 系列
适用于二分类任务(是 / 不是)。衡量两个概率分布的差距。
💡 二分类的输出形状
二分类不是输出 2 个值,而是每个样本只输出 1 个值——表示属于类别 1 的概率 P ( y = 1 ) P(y=1) P(y=1)。 P ( y = 0 ) P(y=0) P(y=0) 由 1 − P ( y = 1 ) 1 - P(y=1) 1−P(y=1) 隐式得到。
L = − 1 n ∑ i = 1 n [ y i log y ^ i + ( 1 − y i ) log ( 1 − y ^ i ) ] L = -\frac{1}{n} \sum_{i=1}^{n} \left[ y_i \log \hat{y}_i + (1 - y_i) \log(1 - \hat{y}_i) \right] L=−n1i=1∑n[yilogy^i+(1−yi)log(1−y^i)]
【两步做法】
先过 Sigmoid 再算 BCE,容易数值不稳定( log ( 0 ) \log(0) log(0) 会爆):
output = torch.randn(5) # 原始 logits
proba = torch.sigmoid(output) # 手动画到 (0, 1)
target = torch.tensor([0., 0., 1., 1., 0.])
loss = nn.BCELoss()(proba, target)
【一步做法(推荐)】
用 BCEWithLogitsLoss,Sigmoid + BCE 合并,内部用 log-sum-exp 技巧数值更稳定:
output = torch.randn(5) # 原始 logits(不过 Sigmoid)
target = torch.tensor([0., 0., 1., 1., 0.])
loss = nn.BCEWithLogitsLoss()(output, target)
💡 推荐写法
日常开发直接用BCEWithLogitsLoss——网络最后输出层不要再加nn.Sigmoid(),让 loss 内部处理。
2.3 多分类:CrossEntropyLoss
适用于多分类任务(类别互斥,如手写数字 0~9、ImageNet 1000 类)。
内部已集成 Softmax,输入是原始 logits,模型最后输出层不要加 nn.Softmax():
CE = − log ( y ^ c ) 其中 c 是正确类别的索引 \text{CE} = -\log(\hat{y}_c) \quad \text{其中 } c \text{ 是正确类别的索引} CE=−log(y^c)其中 c 是正确类别的索引
【target 是类别索引(最常用)】
output = torch.randn(8, 6) # [batch=8, num_classes=6]
target = torch.tensor([1, 0, 5, 4, 2, 3, 0, 5]) # 类别索引(int64)
loss = nn.CrossEntropyLoss()(output, target)
【target 是概率分布(标签平滑/蒸馏)】
target_onehot = torch.zeros(8, 6)
target_onehot[torch.arange(8), target] = 1 # one-hot
loss = nn.CrossEntropyLoss()(output, target_onehot)
📝 CrossEntropyLoss 关键细节
- 已内置 Softmax,模型末尾不要再加
nn.Softmax()- target 通常是类别索引(
torch.int64/ Long 类型)- 也支持概率分布作为 target(标签平滑、知识蒸馏场景)
2.4 损失函数速查表
| 损失函数 | 类名 | 适用场景 | 关键提醒 |
|---|---|---|---|
| 平均绝对误差 | nn.L1Loss() |
回归(抗异常值) | 梯度恒定,收敛慢 |
| 均方误差 | nn.MSELoss() |
回归(平滑优化) | 对异常值敏感 |
| Smooth L1 | nn.SmoothL1Loss() |
回归(目标检测) | MAE + MSE 的结合 |
| 二元交叉熵 | nn.BCELoss() |
二分类 | 需先过 Sigmoid |
| 二元交叉熵(推荐) | nn.BCEWithLogitsLoss() |
二分类 | 内置 Sigmoid,数值稳定 |
| 多分类交叉熵 | nn.CrossEntropyLoss() |
多分类 | 内置 Softmax |
三、数据加载:Dataset 与 DataLoader
把数据送进模型不是"循环里手动取"。PyTorch 提供了两个工具类:
Dataset:定义数据集,负责单条数据的读取(“怎么取一条”)DataLoader:封装 Dataset,自动分 batch、打乱、多线程加载(“怎么分批往外送”)
3.1 自定义 Dataset
必须继承 torch.utils.data.Dataset 并实现两个方法:
| 方法 | 作用 |
|---|---|
__len__() |
返回数据集总大小 |
__getitem__(idx) |
按索引返回单条数据 |
from torch.utils.data import Dataset
class MyDataset(Dataset):
"""自定义数据集:传入一个 list,每条样本是 (特征, 标签)"""
def __init__(self, features, labels):
self.features = features # 特征数据
self.labels = labels # 标签数据
def __len__(self):
# 必须有!告诉 DataLoader 总共有多少条
return len(self.features)
def __getitem__(self, idx):
# 必须有!根据 idx 返回一条数据
x = self.features[idx]
y = self.labels[idx]
return x, y
# 使用
features = [torch.randn(3) for _ in range(100)] # 100 个 3 维特征
labels = [torch.tensor(i % 2) for i in range(100)] # 0/1 标签
dataset = MyDataset(features, labels)
print(dataset[0]) # (tensor([...]), tensor(0)) ← 一条数据
3.2 内置 TensorDataset
当数据已经是 Tensor 时,用 TensorDataset 免去自定义:
from torch.utils.data import TensorDataset
# 100 个样本,3 个特征,二分类
X = torch.randn(100, 3)
y = torch.randint(0, 2, (100,))
dataset = TensorDataset(X, y)
print(dataset[0]) # (tensor([...]), tensor(0)) ← 自动配对
💡
TensorDataset的本质
它就是把多个 Tensor 按第一维对齐打包——索引i同时取每个 Tensor 的第i行。适合"特征和标签都是 Tensor"的场景。
3.3 DataLoader:分批 + 打乱 + 多线程
DataLoader 把 Dataset 包装成可迭代对象,自动完成所有脏活:
from torch.utils.data import DataLoader
loader = DataLoader(
dataset,
batch_size=32, # 每批 32 条
shuffle=True, # 每个 epoch 是否打乱
num_workers=0, # 加载数据的子进程数(0 = 主进程,调试用)
drop_last=False, # 样本数不能被 batch_size 整除时,是否丢弃最后不完整的 batch
pin_memory=False, # GPU 训练时建议 True,加速 CPU→GPU 数据传输
)
# 迭代使用
for batch_idx, (x_batch, y_batch) in enumerate(loader):
# x_batch.shape = [32, 3] ← 自动按 batch 维度堆叠
# y_batch.shape = [32]
print(f"Batch {batch_idx}: x={x_batch.shape}, y={y_batch.shape}")
| 参数 | 说明 | 经验值 |
|---|---|---|
batch_size |
每批样本数 | 32 / 64 / 128 |
shuffle |
是否打乱 | 训练集 True,测试集 False |
num_workers |
数据加载子进程数 | CPU 核心数(Windows 建议 0) |
drop_last |
丢弃最后不完整 batch | 多 GPU 训练时设 True |
pin_memory |
锁页内存 | GPU 训练设 True 加速 |
3.4 标准训练循环里的用法
dataset = TensorDataset(X, y)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for epoch in range(10):
for batch_x, batch_y in loader: # 每次一个 batch
# batch_x: [32, 3] batch_y: [32]
output = model(batch_x)
loss = loss_fn(output, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
⚠️
num_workers > 0在 Windows 上的坑
Windows 下num_workers > 0必须用if __name__ == '__main__':保护,否则会无限递归开新进程(“炸进程”)。Linux/Mac 没这个问题。
四、梯度下降:训练的核心引擎
损失函数衡量了模型的"错",训练的目标就是找到一组参数让损失最小。理论上对损失函数求导、解出导数为 0 的点就行——但深度网络参数动辄百万,这个方程根本解不出来。
梯度下降法(Gradient Descent)就是用迭代方式逼近最小值的核心方法。
4.1 核心思想
梯度 ∇ f \nabla f ∇f 指向函数值增长最快的方向,所以负梯度方向就是下降最快的方向。沿着负梯度迈一小步,函数值就会变小一点:
∇ f ( x 1 , x 2 ) = ( ∂ f ∂ x 1 , ∂ f ∂ x 2 ) \nabla f(x_1, x_2) = \left( \frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2} \right) ∇f(x1,x2)=(∂x1∂f,∂x2∂f)
x 1 ′ = x 1 − η ∂ f ∂ x 1 , x 2 ′ = x 2 − η ∂ f ∂ x 2 x_1' = x_1 - \eta \frac{\partial f}{\partial x_1}, \quad x_2' = x_2 - \eta \frac{\partial f}{\partial x_2} x1′=x1−η∂x1∂f,x2′=x2−η∂x2∂f
其中 η \eta η 是学习率(learning rate),控制每次更新的步长。
⚠️ 学习率的选择
- 过大 → loss 震荡,甚至发散(变成
NaN)- 过小 → 收敛极慢,陷入局部最优
- 通常从 10 − 3 10^{-3} 10−3 到 10 − 1 10^{-1} 10−1 开始试,配合学习率调度器动态调整
4.2 四个核心概念
| 概念 | 含义 | 举例 |
|---|---|---|
| SGD | 随机梯度下降,每次用一小批样本算梯度 | — |
| Batch Size | 每批样本数 | batch_size=64 表示每次用 64 个样本 |
| Iteration | 一次迭代 | 一个 Batch 的前向 + 反向 + 更新 |
| Epoch | 一个周期 | 模型完整遍历一次整个训练集 |
Batch Size 的权衡:
Batch Size = 1:单样本梯度噪声大、不稳定Batch Size = 全体:梯度准但计算量巨大,易收敛到尖锐极小值- Mini-batch(通常 16~512):梯度稳定、计算高效、泛化能力好——实际训练的标准做法
💡 一个具体例子
数据集 2000 个样本,训练 10 个 Epoch,Batch Size=64:每个 Epoch 的 Batch 数 = ceil(2000 / 64) = 32 个(最后一批 8 个) 每个 Epoch 的 Iteration = 32 总 Iteration = 10 × 32 = 320 总处理样本数 = 10 × 2000 = 20000
4.3 SGD 训练伪代码
# SGD 训练伪代码
for epoch in range(num_epochs): # 遍历整个数据集多次
for batch in dataloader: # 每次一个 mini-batch
x, y = batch # 取出一批数据
output = model(x) # 1. 前向传播
loss = loss_fn(output, y) # 2. 算 loss
optimizer.zero_grad() # 3. 清空上次梯度(重要!)
loss.backward() # 4. 反向传播,算梯度
optimizer.step() # 5. 更新参数
💡 为什么叫"随机"梯度下降?
每次选取的 mini-batch 是随机的,因此每次迭代的梯度都是真实梯度的带噪声估计。这个噪声反而有助于跳出局部极小点。
五、自动微分:PyTorch 最性感的部分
终于到了本文的重头戏。
loss.backward() 这一行到底干了什么?梯度是怎么算出来的?动态图又是啥?
这就要从反向传播算法讲起——它是训练深度神经网络的核心算法。
5.1 链式法则:微积分的奠基石
反向传播的数学根基是链式法则(Chain Rule)——复合函数求导的规则。
考虑复合函数 y = f ( g ( x ) ) y = f(g(x)) y=f(g(x)),令 u = g ( x ) u = g(x) u=g(x):
d y d x = d y d u ⋅ d u d x = f ′ ( g ( x ) ) ⋅ g ′ ( x ) \frac{dy}{dx} = \frac{dy}{du} \cdot \frac{du}{dx} = f'(g(x)) \cdot g'(x) dxdy=dudy⋅dxdu=f′(g(x))⋅g′(x)
💡 一句话记忆
链式法则:一个参数的梯度 = 从输出到该参数的路径上所有局部导数的乘积。
神经网络视角
神经网络本质上是一个超大规模复合函数:
a ( 1 ) = W ( 1 ) x + b ( 1 ) , a ( 2 ) = W ( 2 ) σ ( a ( 1 ) ) + b ( 2 ) , y ^ = σ ( a ( 2 ) ) a^{(1)} = W^{(1)}x + b^{(1)}, \quad a^{(2)} = W^{(2)}\sigma(a^{(1)}) + b^{(2)}, \quad \hat{y} = \sigma(a^{(2)}) a(1)=W(1)x+b(1),a(2)=W(2)σ(a(1))+b(2),y^=σ(a(2))
损失 L \mathcal{L} L 关于第一层权重 W ( 1 ) W^{(1)} W(1) 的导数,根据链式法则拆解:
∂ L ∂ W ( 1 ) = ∂ L ∂ y ^ ⋅ ∂ y ^ ∂ a ( 2 ) ⋅ ∂ a ( 2 ) ∂ a ( 1 ) ⋅ ∂ a ( 1 ) ∂ W ( 1 ) \frac{\partial \mathcal{L}}{\partial W^{(1)}} = \frac{\partial \mathcal{L}}{\partial \hat{y}} \cdot \frac{\partial \hat{y}}{\partial a^{(2)}} \cdot \frac{\partial a^{(2)}}{\partial a^{(1)}} \cdot \frac{\partial a^{(1)}}{\partial W^{(1)}} ∂W(1)∂L=∂y^∂L⋅∂a(2)∂y^⋅∂a(1)∂a(2)⋅∂W(1)∂a(1)
关键洞察:模块化
链式法则带来的最大好处是模块化——每一层只关心两件事:
- 自己的局部梯度(forward 时算出)
- 来自上层的梯度信号(backward 时接收)
| 训练阶段 | 每层做什么 |
|---|---|
| 前向传播 | 计算输出 y k = f k ( y k − 1 ) y_k = f_k(y_{k-1}) yk=fk(yk−1),并缓存局部导数 |
| 反向传播 | 接收上游累积梯度,乘以本地局部导数,传递给前一层 |
| 参数更新 | 用累积梯度 × 局部导数算出对参数的梯度 |
这种"局部计算、全局传递"的范式让每一层的实现完全独立——这正是反向传播能规模化的根本原因。
与数值微分的对比
| 方法 | 计算复杂度 | 精确度 | 适用性 |
|---|---|---|---|
| 数值微分 | O ( n 2 ) O(n^2) O(n2) | 近似(截断误差) | 梯度校验 |
| 解析微分(链式 + BP) | O ( n ) O(n) O(n) | 精确 | 实际训练 |
链式法则让梯度计算从 O ( n 2 ) O(n^2) O(n2) 降到了 O ( n ) O(n) O(n),使得训练深层网络成为可能。
5.2 计算图:把代码变成图
计算图就是一个有向无环图——节点是张量或运算操作,边是数据流动方向。考虑最简单的单层神经网络,具有输入 x、参数 w、偏置 b 以及损失函数: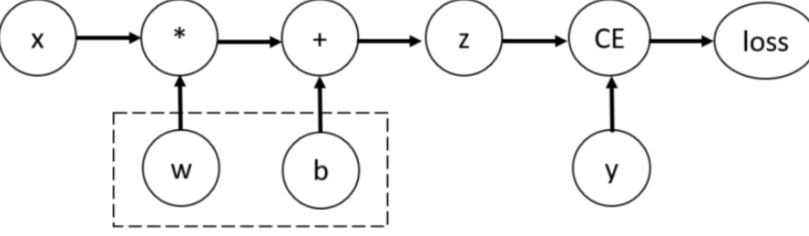
PyTorch 把节点分成两类:
- 叶子节点(Leaf Nodes):用户直接创建的张量,没有
grad_fn。典型代表是weight、bias、输入数据。 - 非叶子节点(Non-leaf Nodes):通过运算产生的中间张量,都有一个
grad_fn指向产生它的运算(如AddBackward0、MulBackward0),反向传播时用来定位上游梯度。
import torch
x = torch.tensor(2.0, requires_grad=True) # 叶子节点
w = torch.tensor(3.0, requires_grad=True) # 叶子节点
y = w * x # 非叶子节点,grad_fn=<MulBackward0>
z = y + 1 # 非叶子节点,grad_fn=<AddBackward0>
print(x.is_leaf, w.is_leaf) # True True
print(y.is_leaf, z.is_leaf) # False False
print(z.grad_fn) # <AddBackward0 object>
| 概念 | 含义 | 说明 |
|---|---|---|
requires_grad |
是否追踪梯度 | 设为 True 才参与反向传播 |
grad_fn |
记录如何计算此张量 | 反向传播时定位上游节点 |
is_leaf |
是否叶子节点 | 用户创建为 True,计算得到为 False |
backward() |
从该节点反向传播 | 标量直接调,向量需传 gradient |
data |
张量的实际数据 | 访问底层存储 |
5.3 动态图 vs 静态图
理解 PyTorch 的计算图,必须先和传统的静态图(TensorFlow 1.x)对比。
静态图(Define-and-Run):先完整定义整个计算流程,再放入 Session 中执行。图一旦构建便固定不变,灵活性差,调试困难。
动态图(Define-by-Run):PyTorch 采用"定义即执行"模式——图是在代码运行时、随着前向传播过程逐步、即时构建的。这意味着:
- 可以直接用 Python 原生的
if/else、for等控制流动态改变网络结构 - 每次前向传播都会生成一张新的计算图
- 调试时可以像普通 Python 代码一样
print中间结果、加断点
# PyTorch:原生 Python 控制流自然地改变图结构
def forward(x, n):
for i in range(n): # 控制流直接参与图构建
x = x * 2 + 1
if n > 5: # 条件分支也不需要特殊 API
x = x.relu()
return x
💡 这就是 PyTorch 能成为学术界主流的原因
研究阶段的"试错成本"低得多——新想法写出来就能跑,能跑就能 debug。TensorFlow 2.x 已经默认采用 Eager(即动态图),并通过
tf.function兼顾静态图优化。但 PyTorch 一直以动态图为第一性原则。
5.4 Autograd:自动微分实战
训练神经网络时,框架会自动构建计算图、跟踪数据流过哪些操作,并通过反向传播算梯度。这就是 Autograd——PyTorch 的自动微分引擎。
import torch
# 定义输入和真实标签
x = torch.tensor([[1.0]])
y_true = torch.tensor([[2.0]])
# 初始化模型参数(requires_grad=True 表示追踪梯度)
w = torch.randn(1, 1, requires_grad=True)
b = torch.randn(1, requires_grad=True)
# 前向传播
z = x * w + b
loss = torch.nn.MSELoss()(z, y_true)
# 反向传播 —— 这一行就是 Autograd 的魔法
loss.backward()
# 查看梯度
print("w.grad =", w.grad) # 损失对 w 的偏导
print("b.grad =", b.grad) # 损失对 b 的偏导
# 检查叶子节点
print("x.is_leaf =", x.is_leaf) # True
print("z.is_leaf =", z.is_leaf) # False(计算得到)
print("loss.is_leaf =", loss.is_leaf) # False
4 种常见用法
【用法 1:标量求导(最常见)】
import torch
x = torch.tensor(2.0, requires_grad=True)
y = x ** 2 + 3 * x + 1
y.backward() # y 是标量,直接调用
print(x.grad) # tensor(7.) → dy/dx = 2x+3 = 7
【用法 2:非标量求导(需传 gradient)】
x = torch.tensor([1.0, 2.0, 3.0], requires_grad=True)
y = x ** 2 # y 是向量
y.backward(gradient=torch.ones_like(y)) # 需要传入「上游梯度」
print(x.grad) # tensor([2., 4., 6.])
非标量反传时必须显式传入 gradient 参数(与 y 同形状),代表"输出端的初始梯度",默认为全 1。
【用法 3:梯度累积(容易踩坑)】
x = torch.tensor(2.0, requires_grad=True)
y1 = x ** 2
y1.backward() # x.grad = 4
y2 = x ** 3
y2.backward() # x.grad = 4 + 12 = 16(累加!)
print(x.grad) # tensor(16.)
❌ 梯度累加器
.grad是累加器而非"覆盖器"——多次backward()的结果会累加。训练循环里必须在loss.backward()之前调用optimizer.zero_grad(),否则梯度会越加越乱,模型不收敛。
【用法 4:保留非叶子节点梯度】
x = torch.tensor(2.0, requires_grad=True)
y = x * 3
z = y * 2
# 显式保留非叶子节点的梯度
y.retain_grad()
z.retain_grad()
z.backward()
print(x.grad) # tensor(6.)
print(y.grad, z.grad) # tensor(2.) tensor(1.)
默认情况下,非叶子节点的梯度在反向传播后会被释放(除非显式
retain_grad())。
5.5 计算图的生命周期
动态图每次前向传播都会新建一张图。如果不管理,内存很快爆掉。PyTorch 通过一系列机制精确控制生命周期。
默认行为:即用即弃
默认情况下,调用 .backward() 后,中间计算图立即被释放(grad_fn 置 None)。这是为了节省内存——绝大多数训练场景下每个 batch 只需要一次反向传播。
如果对已经反传过的同一张图再次调用 .backward(),会报错:
RuntimeError: Trying to backward through the graph a second time
4 种典型控制手段
【手段 1:retain_graph=True(保留图)】
# 某些复杂损失(如梯度惩罚、共享编码器)需要多次反传
loss1 = compute_loss_a(model, x)
loss1.backward(retain_graph=True) # 第一次反传,保留图
loss2 = compute_loss_b(model, x)
loss2.backward() # 第二次反传仍能成功
⚠️ 内存代价
retain_graph=True会把整张中间图留在内存里,只在确实需要时使用。
【手段 2:torch.no_grad()(推理 / 参数冻结)】
# 验证 / 测试阶段
model.eval()
with torch.no_grad(): # 所有运算都不进计算图
for x, y in test_loader:
pred = model(x)
loss = loss_fn(pred, y)
节省显存 + 加速推理,绝大多数情况下这是 eval 循环的标准写法。
【手段 3:tensor.detach()(剥离某个分支)】
# 切断不需要反传的分支(典型场景:冻结预训练 backbone)
frozen_feat = pretrained_backbone(x).detach() # 不参与梯度计算
output = new_head(frozen_feat) # 只需更新 new_head
.detach() 返回一个共享数据但脱离计算图的新张量,常用于迁移学习、RL 中的策略冻结等场景。
【手段 4:requires_grad_(False)(原地关闭追踪)】
# 把叶子节点彻底转为不需要梯度的普通张量
x.requires_grad_(False) # 原地修改
# 等价于 x = x.detach()(但不改变对象身份)
图生命周期的完整流程
[创建叶子节点 requires_grad=True]
↓
[前向传播]
↓
[构建动态计算图]
↓
┌──────────────┐
│ 是否需要多次反传? │
└──────┬───────┘
否 │ 是
↓ │ ↓
loss. │ loss.backward
backward │ retain_graph=True
│ │ │
└────┴────┘
↓
[沿 grad_fn 链逆向求梯度]
↓
[梯度存入 .grad]
↓
[中间图立即释放,grad_fn 置 None]
↓
[optimizer.step 更新参数]
↓
[optimizer.zero_grad(set_to_none=True)]
↓
[下一个 epoch]
5.6 Autograd 常见坑
【坑 1:原地操作破坏计算图】
x = torch.tensor(2.0, requires_grad=True)
y = x.relu()
y.add_(1) # ⚠️ 原地加法,可能破坏图
y.backward() # ❌ RuntimeError
对策:用
y = y + 1替代y.add_(1),让 PyTorch 创建新节点。
【坑 2:忘记 zero_grad】
for epoch in range(10):
for x, y in loader:
loss = model(x, y)
loss.backward() # ⚠️ 梯度累加
optimizer.step()
# 忘记 optimizer.zero_grad(),下次反传时梯度是叠加的
对策:用
optimizer.zero_grad(set_to_none=True)(PyTorch 1.7+),比=0稍快且更省内存。
【坑 3:GPU 张量直接转 numpy】
x = torch.tensor([1.0], device="cuda", requires_grad=True)
x.numpy() # ❌ RuntimeError
对策:先
x.detach().cpu().numpy(),再转 numpy。
【坑 4:in-place 操作与 autograd 版本不匹配】
有些 in-place 操作表面上能跑,但反向传播时会触发:
one of the variables needed for gradient computation has been modified by an inplace operation
对策:默认优先写"非原地"代码,需要极致性能时再分析是否安全。
六、训练循环:从零搭建标准模板
理论说了一堆,是时候把所有零件拼起来。PyTorch 训练的所有任务(CNN、RNN、Transformer),本质上都是下面这 5 行核心循环的无限重复:
for epoch in range(epochs):
pred = model(x) # 1. 前向
loss = loss_fn(pred, y) # 2. 算 loss
optimizer.zero_grad() # 3. 清空梯度
loss.backward() # 4. 反向传播
optimizer.step() # 5. 更新参数
6.1 通用训练模板
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
def train(model, train_loader, val_loader, optimizer, loss_fn, device, epochs=10):
"""标准训练循环:每个 epoch 训练 + 验证一次"""
for epoch in range(epochs):
# ====== 训练阶段 ======
model.train() # 切到训练模式(启用 Dropout/BN 更新)
train_loss = 0
for x, y in train_loader:
x, y = x.to(device), y.to(device) # 数据搬到 device
pred = model(x) # 1. 前向
loss = loss_fn(pred, y) # 2. 算 loss
optimizer.zero_grad() # 3. 清空梯度
loss.backward() # 4. 反向传播
optimizer.step() # 5. 更新参数
train_loss += loss.item()
# ====== 验证阶段 ======
model.eval() # 切到评估模式(关闭 Dropout/BN 更新)
val_loss, correct, total = 0, 0, 0
with torch.no_grad(): # 推理不建图,省显存
for x, y in val_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
val_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).sum().item()
total += y.size(0)
# ====== 打印日志 ======
avg_train = train_loss / len(train_loader)
avg_val = val_loss / len(val_loader)
acc = correct / total
print(f"Epoch {epoch+1:2d} | "
f"train_loss={avg_train:.4f} | "
f"val_loss={avg_val:.4f} | "
f"val_acc={acc:.4f}")
💡 关键 3 个开关
model.train():启用 Dropout、BN 更新滑动统计量model.eval():关闭 Dropout、BN 用滑动均值with torch.no_grad():推理不建计算图,显著省显存三个的完整调用顺序是:训练
model.train(),验证model.eval() + no_grad()。
6.2 完整实战:手写数字二分类
把上面所有内容串起来,做一个手写数字二分类(区分 0 和 1)的完整例子。
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
from torchvision import datasets, transforms
# ============== 1. 准备数据(从 MNIST 取 0 和 1) ==============
transform = transforms.Compose([
transforms.ToTensor(), # [0,255] → [0,1]
transforms.Normalize((0.1307,), (0.3081,)), # 标准化
transforms.Lambda(lambda x: x.view(-1)), # 28x28 → 784
])
# 下载 MNIST(首次会下载,之后从缓存读)
mnist = datasets.MNIST(
root="./data", train=True, download=True, transform=transform
)
# 只取标签为 0 或 1 的样本
mask = (mnist.targets == 0) | (mnist.targets == 1)
mnist.data = mnist.data[mask]
mnist.targets = mnist.targets[mask]
# 划分训练 / 验证
train_set, val_set = torch.utils.data.random_split(mnist, [len(mnist)-2000, 2000])
train_loader = DataLoader(train_set, batch_size=64, shuffle=True)
val_loader = DataLoader(val_set, batch_size=64, shuffle=False)
# ============== 2. 定义模型 ==============
class BinaryClassifier(nn.Module):
"""3 层 MLP,二分类(0 vs 1)"""
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 64),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(64, 1), # 输出 1 个值(P(y=1))
)
def forward(self, x):
return self.net(x)
model = BinaryClassifier()
# ============== 3. 损失 + 优化器 ==============
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
loss_fn = nn.BCEWithLogitsLoss() # 二分类推荐
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-4)
# ============== 4. 训练 ==============
print(f"Device: {device}")
for epoch in range(5):
model.train()
for x, y in train_loader:
x, y = x.to(device), y.to(device).float() # BCE 要 float 类型
pred = model(x) # [batch, 1]
loss = loss_fn(pred.squeeze(1), y) # [batch] vs [batch]
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 验证
model.eval()
correct, total = 0, 0
with torch.no_grad():
for x, y in val_loader:
x, y = x.to(device), y.to(device)
pred = model(x).squeeze(1)
correct += ((pred > 0).float() == y).sum().item()
total += y.size(0)
print(f"Epoch {epoch+1} | val_acc = {correct/total:.4f}")
预期输出:
Device: cuda
Epoch 1 | val_acc = 0.9985
Epoch 2 | val_acc = 0.9990
Epoch 3 | val_acc = 0.9995
Epoch 4 | val_acc = 0.9995
Epoch 5 | val_acc = 0.9995
5 个 epoch 就能在 MNIST 二分类上达到 99.9%+ 的准确率。
💡 代码里几个关键点
pred.squeeze(1):模型输出[batch, 1],BCEWithLogitsLoss 需要[batch]y.float():BCE 系列的 target 必须是 float(pred > 0).float():因为我们没加 Sigmoid,logits > 0 即判为 1with torch.no_grad():验证时不建计算图,省显存
七、参数初始化:训练开始前的「底子」
参数初始化直接影响模型能否收敛以及收敛速度。初始化不当会导致梯度消失 / 爆炸,模型根本训不动。
核心原则:让每层输出的方差保持稳定,避免信号在传播过程中被放大或缩小到零。
import torch.nn.init as init
7.1 常数初始化(仅用于偏置)
init.zeros_(m.bias) # 偏置通常初始化为 0
init.constant_(m.weight, 1) # 权重全相同 → 对称性灾难!
init.eye_(m.weight) # 单位矩阵初始化(仅用于方阵权重)
⚠️ 对称性灾难
权重全设相同值,所有神经元学到同样的特征,模型表达能力归零。
7.2 随机初始化
init.normal_(m.weight, mean=0, std=0.01) # 正态分布,小标准差
init.uniform_(m.weight, -0.1, 0.1) # 均匀分布
简单随机初始化仍会导致梯度消失(方差逐层缩小或放大),所以实际很少单独使用。
7.3 Xavier 初始化(Glorot)
适合 Tanh / Sigmoid 等饱和型激活函数。 核心思想是让每层输出的方差等于输入的方差,反向传播时梯度的方差也保持稳定:
init.xavier_uniform_(m.weight) # 均匀分布版(默认推荐)
init.xavier_normal_(m.weight) # 正态分布版
均匀分布方差 = 2 f a n i n + f a n o u t \frac{2}{fan_{in} + fan_{out}} fanin+fanout2
7.4 He 初始化(Kaiming)
适合 ReLU / PReLU / LeakyReLU 等非饱和型激活函数。 ReLU 会将一半神经元置零导致方差减半,He 初始化通过放大方差来补偿:
init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu') # 默认推荐
init.kaiming_normal_(m.weight, mode='fan_in', nonlinearity='relu')
ReLU 版方差 = 2 f a n i n \frac{2}{fan_{in}} fanin2(比 Xavier 大一倍)
7.5 批量初始化(apply 递归)
通过 model.apply() 递归地对所有层统一应用初始化策略,适合为不同类型的层设置不同规则:
def init_weights(m):
if isinstance(m, nn.Linear):
init.kaiming_uniform_(m.weight) # Linear 用 He
if m.bias is not None:
init.zeros_(m.bias) # bias 全 0
elif isinstance(m, nn.Conv2d):
init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')
model.apply(init_weights)
7.6 快速选择指南
| 激活函数 | 推荐初始化 | 原理 |
|---|---|---|
| ReLU / LeakyReLU / PReLU | He (Kaiming) | 补偿 ReLU 置零导致的方差减半 |
| Tanh / Sigmoid | Xavier (Glorot) | 保持前向/反向方差一致 |
| 无激活 / Linear 输出层 | Xavier 或 He 均可 | — |
| 偏置 bias | 常数 0 | 无特殊需求一律初始化为 0 |
💡 好消息
PyTorch 的nn.Linear、nn.Conv2d等层已经内置了合理的默认初始化(Linear 用 Kaiming、Conv2d 用 Kaiming)。大多数情况下不用手动初始化,模型就能训。手动初始化通常只在复现特定论文时需要。
八、优化器:拿到梯度后,参数怎么更新?
优化器决定"拿到梯度后,参数怎么更新"。PyTorch 在 torch.optim 里内置了所有主流优化器。
8.1 SGD + Momentum(最经典)
Momentum(动量法)会保存历史梯度并给予一定权重,让更新方向更稳定:
v ← α v − η ∇ v \leftarrow \alpha v - \eta \nabla v←αv−η∇
W ← W + v W \leftarrow W + v W←W+v
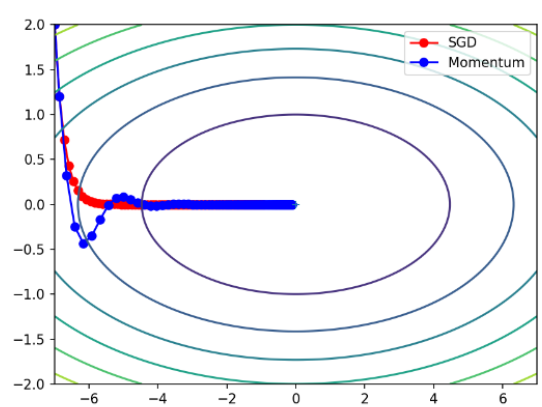
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
8.2 学习率调度器
固定学习率很难同时满足"前期快速下降"和"后期精细收敛"的需求。学习率调度器让 lr 随训练进程动态调整。
【StepLR(等间隔衰减)】
scheduler = optim.lr_scheduler.StepLR(
optimizer, step_size=30, gamma=0.1
) # 每 30 个 epoch,lr 乘以 0.1
【MultiStepLR(指定间隔衰减)】
scheduler = optim.lr_scheduler.MultiStepLR(
optimizer, milestones=[30, 60, 90], gamma=0.1
) # 在 30/60/90 epoch 处衰减
【ExponentialLR(指数衰减)】
scheduler = optim.lr_scheduler.ExponentialLR(
optimizer, gamma=0.99
) # 每个 epoch lr *= 0.99(缓慢下降)
【CosineAnnealingLR(余弦退火)】
scheduler = optim.lr_scheduler.CosineAnnealingLR(
optimizer, T_max=100, eta_min=1e-6
) # 按余弦曲线从初始 lr 平滑降到 eta_min
💡 调度器调用顺序
for epoch in range(epochs): train(...) validate(...) optimizer.step() # 先更新参数 scheduler.step() # 再更新 lr(每个 epoch 调一次)
8.3 自适应优化器
自适应优化器给不同参数不同的学习率——梯度大的参数小步走,梯度小的参数大步走。
【Adagrad(自适应梯度)】
给不同参数不同的学习率,适合稀疏数据(如 NLP 中的词嵌入):
optimizer = optim.Adagrad(model.parameters(), lr=0.01)
【RMSprop】
Adagrad 累积平方梯度会单调递增导致学习率过早降到 0。RMSProp 引入指数加权移动平均(EMA) 逐步遗忘旧梯度:
h ← α h + ( 1 − α ) ∇ 2 h \leftarrow \alpha h + (1-\alpha)\nabla^2 h←αh+(1−α)∇2
W ← W − η 1 h + ϵ ∇ W \leftarrow W - \eta \frac{1}{\sqrt{h} + \epsilon} \nabla W←W−ηh+ϵ1∇
optimizer = optim.RMSprop(model.parameters(), lr=0.001, alpha=0.99)
【Adam(最常用默认)】
Adam = Momentum + RMSprop,同时维护一阶矩(均值) 和二阶矩(方差) 的指数移动平均,几乎是所有深度学习任务的默认起点:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t mt=β1mt−1+(1−β1)gt
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2
m ^ t = m t 1 − β 1 t , v ^ t = v t 1 − β 2 t \hat{m}_t = \frac{m_t}{1 - \beta_1^t}, \quad \hat{v}_t = \frac{v_t}{1 - \beta_2^t} m^t=1−β1tmt,v^t=1−β2tvt
θ t = θ t − 1 − η v ^ t + ϵ m ^ t \theta_t = \theta_{t-1} - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t θt=θt−1−v^t+ϵηm^t
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999))
【AdamW(Transformer 时代标配)】
Adam 中 PyTorch 的 weight_decay 并非严格等价于 L2 正则(会和自适应学习率耦合)。AdamW 把权重衰减与梯度更新解耦,效果更好:
optimizer = optim.AdamW(model.parameters(), lr=0.001, weight_decay=0.01)
💡 推荐:训练 Transformer / 大模型时优先用 AdamW。
8.4 优化器选择速查表
| 优化器 | 适用场景 | 学习率 | 推荐度 |
|---|---|---|---|
| SGD + Momentum | 图像分类(CNN)、追求极致泛化 | 0.01 ~ 0.1 | ⭐⭐⭐ |
| Adam | 通用默认、RNN、稀疏数据 | 1e-4 ~ 1e-3 | ⭐⭐⭐⭐⭐ |
| AdamW | Transformer、大模型迁移学习 | 1e-4 ~ 1e-3 | ⭐⭐⭐⭐⭐ |
| RMSprop | RNN(已逐渐被 Adam 取代) | 1e-4 | ⭐⭐ |
| Adagrad | 稀疏数据(NLP 词嵌入) | 0.01 | ⭐⭐ |
💡 三个关键超参
lr(学习率):最敏感。太大 loss 震荡,太小学得慢。一般从1e-3试起momentum(动量):SGD 专属,常见 0.9。Adam 内部已处理,不需要weight_decay(权重衰减):L2 正则强度,防过拟合。常用1e-4~1e-2
九、正则化:让模型不"死记硬背"
过拟合的本质是模型对训练集拟合太好,反而学不到泛化规律。正则化通过额外约束让模型学到更平滑的规律。
9.1 Batch Normalization(批量标准化)
📝 官方文档:详见 BatchNorm Layers 文档
BN 的核心目的是调整各层的激活值分布使其拥有适当的广度,从而缓解"内部协变量偏移"问题。
插入位置
线性层(全连接层 / 卷积层)之后,激活函数之前:
Linear / Conv2d → BatchNorm → Activation
三大优点
- 使学习快速进行(允许更高的学习率)
- 不那么依赖初始值(对初始值不用那么神经质)
- 抑制过拟合(降低 Dropout 等的必要性)
计算流程
μ = 1 n ∑ i = 1 n x i , σ 2 = 1 n ∑ i = 1 n ( x i − μ ) 2 \mu = \frac{1}{n}\sum_{i=1}^{n} x_i, \quad \sigma^2 = \frac{1}{n}\sum_{i=1}^{n}(x_i - \mu)^2 μ=n1i=1∑nxi,σ2=n1i=1∑n(xi−μ)2
x ^ = x − μ σ 2 + ε , y = γ x ^ + β \hat{x} = \frac{x - \mu}{\sqrt{\sigma^2 + \varepsilon}}, \quad y = \gamma \hat{x} + \beta x^=σ2+εx−μ,y=γx^+β
💡 为什么要 γ \gamma γ、 β \beta β?
标准化后分布被强制为标准正态,会限制网络表达能力。所以允许网络自己学"最合适的分布"。
训练 vs 推理
- 训练时:用当前 batch 的均值和方差做归一化,并更新滑动平均统计量
- 推理时:用训练阶段累积的滑动均值 / 方差,保证结果稳定
PyTorch 实现
通过 torch.nn 下的 _BatchNorm 类实现,针对不同输入形状调用不同子类:
【BatchNorm1d(全连接)】
适用于 (N, C) 或 (N, C, L) 形状的输入。
import torch
from torch import nn
x = torch.randint(0, 10, (5, 3)).float() # 5 样本,3 特征
bn = nn.BatchNorm1d(num_features=3) # num_features = 特征数
y = bn(x)
【BatchNorm2d(图像,最常用)】
适用于 (N, C, H, W) 形状的输入。
x = torch.randn(8, 64, 28, 28) # batch=8,64 通道
bn = nn.BatchNorm2d(num_features=64) # num_features = 通道数
y = bn(x) # shape 不变
【BatchNorm3d(视频)】
适用于 (N, C, D, H, W) 形状的输入。
x = torch.randn(4, 16, 8, 32, 32)
bn = nn.BatchNorm3d(num_features=16)
y = bn(x)
9.2 权值衰减(Weight Decay)
通过在学习过程中对大的权重进行"惩罚",可以有效抑制过拟合。这种方法被称为权值衰减,因为很多过拟合的原因就是权重参数取值过大。
一般对损失函数加上 L2 范数的平方:
L ′ = L + 1 2 ⋅ λ ⋅ ∥ W ∥ 2 2 L' = L + \frac{1}{2} \cdot \lambda \cdot \|W\|_2^2 L′=L+21⋅λ⋅∥W∥22
惩罚项对 W W W 求导得到 λ W \lambda W λW。权重更新公式变为:
W ← ( 1 − η λ ) W − η ∂ L ∂ W W \leftarrow (1 - \eta\lambda)W - \eta \frac{\partial L}{\partial W} W←(1−ηλ)W−η∂W∂L
可见每一步更新时,权重都会先被乘以一个小于 1 的系数——这就是"衰减"的来源。
📝 PyTorch 实现
在 PyTorch 优化器中,默认就是 L2 正则化。通过weight_decay参数控制强度:from torch import optim optimizer = optim.SGD(model.parameters(), lr=0.1, weight_decay=1e-2) # 常用取值:1e-4(轻微)~ 1e-2(较强)
💡 训练 Transformer / 大模型时:用 AdamW 配合
weight_decay=0.01是当前最佳实践。
9.3 Dropout(随机失活)
Dropout 在训练时以概率 p p p 随机关闭神经元(输出置 0),未被关闭的输出以 1 1 − p \frac{1}{1-p} 1−p1 的比例缩放(Inverted Dropout),以保持期望值不变。
- 训练时:随机失活,输出要缩放
- 测试时:不使用 Dropout,所有神经元保持激活,直接推理
每次迭代训练的是结构不同的子网络,最终推理相当于对大量子网络做了模型集成(Ensemble)。
⚠️ 务必切换
model.eval()
推理前必须调用model.eval(),PyTorch 才会自动关闭 Dropout。否则推理结果会有随机性,预测不稳定。
import torch
from torch import nn
x = torch.randint(1, 10, (10,)).float()
dropout = nn.Dropout(p=0.5)
dropout.train() # 训练模式:失活生效
x = dropout(x)
常用取值:
- 全连接层:
p = 0.5 - 卷积层:
p = 0.1 ~ 0.3(卷积层冗余度较低,不宜过大) - RNN:推荐变分 Dropout(Variational Dropout)
9.4 三种正则化方法速查表
| 方法 | 核心思想 | 主要作用 | 位置 | 超参 |
|---|---|---|---|---|
| BatchNorm | 标准化每层输入分布 | 加速训练 + 轻微正则 | 线性层之后,激活函数之前 | eps, momentum |
| 权值衰减 | L2 范数惩罚大权重 | 抑制过拟合 | 优化器层 | weight_decay(λ) |
| Dropout | 训练时随机失活 | 强制冗余 + 隐式集成 | 激活函数之后,线性层之前 | p(失活概率) |
实际工程中三者经常叠加使用:BN + Dropout + 适度 weight_decay 是非常常见的组合。
十、总结
一张图总结
[数据准备]
↓
Dataset + DataLoader
↓
[模型定义] nn.Module → 初始化 → 搬到 device
↓
[损失函数] loss_fn (按任务选)
↓
[优化器] optim (Adam/AdamW 默认)
↓
┌───────────── 训练循环 5 行 ─────────────┐
│ pred = model(x) │
│ loss = loss_fn(pred, y) │
│ optimizer.zero_grad() │
│ loss.backward() ← Autograd 自动求导 │
│ optimizer.step() │
└────────────────────────────────────────┘
↓
[验证] model.eval() + no_grad()
↓
[调优] lr scheduler / 正则化
本文关键 API 速记
| 类别 | API | 一句话 |
|---|---|---|
| 损失 | nn.CrossEntropyLoss() |
多分类(内置 Softmax) |
| 损失 | nn.BCEWithLogitsLoss() |
二分类(内置 Sigmoid) |
| 损失 | nn.MSELoss() / nn.L1Loss() |
回归 |
| 数据 | TensorDataset(X, y) |
Tensor 打包成数据集 |
| 数据 | DataLoader(ds, batch_size, shuffle) |
分批 + 打乱 + 多线程 |
| 自动微分 | loss.backward() |
反向传播,自动算梯度 |
| 自动微分 | tensor.requires_grad=True |
开启梯度追踪 |
| 自动微分 | torch.no_grad() |
推理 / 冻结参数 |
| 优化器 | optim.AdamW(params, lr, weight_decay) |
Transformer 时代标配 |
| 优化器 | optim.lr_scheduler.StepLR(opt, step_size, gamma) |
等间隔衰减 lr |
| 初始化 | init.kaiming_uniform_(m.weight) |
ReLU 用 He |
| 初始化 | init.xavier_uniform_(m.weight) |
Tanh/Sigmoid 用 Xavier |
| 正则化 | nn.BatchNorm2d(num_features) |
卷积后归一化 |
| 正则化 | nn.Dropout(p=0.5) |
全连接后失活 |
| 正则化 | optim.AdamW(..., weight_decay=0.01) |
L2 正则 |
推荐下一步阅读
- 📖 PyTorch Autograd 官方教程 —— 必读原文
- 📖 Decoupled Weight Decay Regularization (Loshchilov & Hutter, 2019) —— AdamW 原始论文
- 📖 CS231n 训练技巧笔记 —— Stanford 经典
- 📖 《深度学习:PyTorch 实战》 —— 国内口碑不错的中文书
如果本文对你有帮助,欢迎点赞、收藏、转发 👍
有任何问题,评论区见!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)