【负荷预测】基于BiGRU-Attention的负荷预测研究附Python代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。
🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室
👇 关注我领取海量matlab电子书和数学建模资料
🍊个人信条:做科研,博学之、审问之、慎思之、明辨之、笃行之,是为:博学慎思,明辨笃行。
🔥 内容介绍
一、引言
在现代电力系统的运行与规划中,准确的负荷预测是确保电力可靠供应、优化资源分配以及保障系统稳定运行的关键环节。传统的负荷预测方法在应对电力负荷复杂多变的特性时,往往力不从心。而基于双向门控循环单元(BiGRU)与注意力机制(Attention)相结合的模型,为负荷预测领域带来了新的曙光。它能够深度挖掘负荷数据中的潜在模式与特征,有效提升预测的准确性与可靠性。
二、相关技术原理
- 双向门控循环单元(BiGRU)
- GRU 基础
:门控循环单元(GRU)是循环神经网络(RNN)的改进版本,旨在克服传统 RNN 在处理长序列数据时面临的梯度消失或梯度爆炸问题。GRU 通过引入重置门(Reset Gate)和更新门(Update Gate),巧妙地控制信息在时间序列中的流动。重置门决定了如何将新输入信息与过去的隐藏状态相结合,更新门则掌控着过去隐藏状态信息的保留程度。其核心计算过程如下:
- GRU 基础

-
- BiGRU 拓展
:双向门控循环单元(BiGRU)由前向 GRU 和后向 GRU 并行组成。前向 GRU 按时间顺序处理输入序列,后向 GRU 则逆序处理。这使得 BiGRU 能够同时捕捉到序列数据中过去和未来的信息,对于具有时间序列特性的负荷数据而言,能够更全面、深入地学习到其中的依赖关系与特征模式。例如,在负荷预测场景中,BiGRU 不仅可以依据过去的负荷值来推断未来趋势,还能从未来的负荷变化中获取有用信息,从而显著提升预测的准确性。
- BiGRU 拓展
- 注意力机制(Attention)
- 原理
:注意力机制模拟人类注意力的聚焦方式,使模型能够自动关注输入数据中对当前任务最为关键的部分。在负荷预测中,并非所有历史负荷数据对预测未来时刻的负荷都具有同等重要性。注意力机制通过计算输入序列中每个元素的权重,动态地分配模型对不同元素的关注程度。具体实现过程通常包括计算注意力分数(常用点积、多层感知机等方法),然后利用 Softmax 函数将分数转化为概率分布作为权重,最后依据权重对输入进行加权求和,得到带有注意力的输出。
- 作用
:在负荷预测模型中引入注意力机制,能够引导模型聚焦于与预测任务紧密相关的历史负荷数据片段,突出关键信息的影响力,从而提高预测的精度。例如,在特殊事件(如节假日、大型活动)发生前后,相关时段的负荷数据对预测未来负荷更为关键,注意力机制可以增强对这些时段数据的关注度,使模型能够更好地捕捉到这些特殊模式对负荷的影响。
- 原理
三、基于 BiGRU - Attention 的负荷预测模型构建
- 数据预处理
- 数据收集
:广泛收集历史电力负荷数据,同时考虑可能对负荷产生影响的各种相关因素,如温度、湿度、工作日 / 休息日、节假日等气象和日历信息。这些多源数据能够为模型提供更丰富的上下文信息,有助于提升预测的准确性。
- 数据清洗
:仔细检查并妥善处理数据中的缺失值与异常值。对于缺失值,可以采用均值填充、中位数填充、基于时间序列模型的插补等方法进行填补;对于异常值,运用统计方法或机器学习算法进行识别与修正,确保数据的质量与可靠性。
- 数据归一化
:将负荷数据以及相关影响因素数据进行归一化处理,将其映射到 [0, 1] 或 [-1, 1] 区间。归一化能够加速模型的收敛速度,并避免因数据尺度差异过大而导致的数值问题,提升模型的训练效果。
- 数据收集
- 模型结构
- 输入层
:将经过预处理的负荷数据及相关影响因素数据按照时间序列的顺序组织成输入序列,作为模型的输入。这样的输入方式能够让模型充分利用数据的时间序列特性进行学习。
- BiGRU 层
:输入序列进入 BiGRU 层,前向 GRU 和后向 GRU 分别对序列进行处理,捕捉负荷数据在时间维度上的前后向依赖关系,输出包含丰富时间序列特征的隐藏状态。这一层能够有效地挖掘负荷数据中的长期依赖信息,为后续的预测提供有力支持。
- 注意力层
:BiGRU 层的输出被送入注意力层,该层计算每个时间步的注意力权重,对隐藏状态进行加权求和,突出关键时间步的特征。通过注意力机制,模型能够更加关注对预测结果影响较大的历史数据部分,从而提升预测的准确性。
- 全连接层
:注意力层的输出经过全连接层,将高维特征映射到一维空间,得到预测的负荷值。全连接层能够对前面提取的特征进行综合处理,形成最终的预测结果。
- 输出层
:全连接层的输出作为模型的最终预测值,通过损失函数(如均方误差损失函数)与真实负荷值进行比较,用于模型训练过程中的参数更新,以不断优化模型的预测性能。
- 输入层
- 模型训练
- 选择优化器
:通常选用随机梯度下降(SGD)及其变体,如 Adagrad、Adadelta、Adam 等优化器,来调整模型的权重参数,使损失函数最小化。这些优化器在处理大规模数据和复杂模型时具有较好的性能和收敛速度。
- 设置训练参数
:确定训练的轮数(epoch)、批量大小(batch size)等参数。合适的训练参数能够平衡模型的训练速度与准确性,避免过拟合或欠拟合现象的发生。
- 训练过程
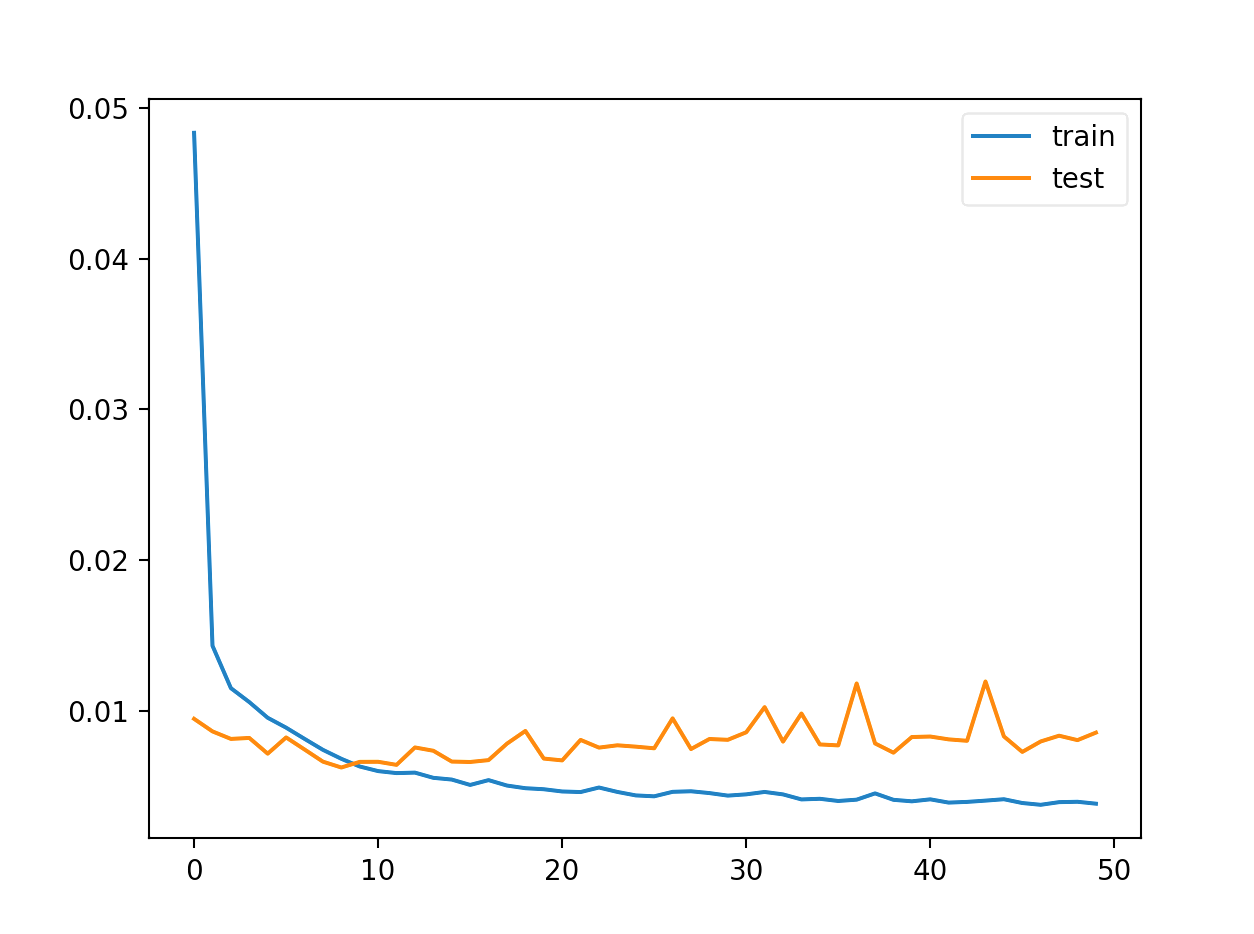
:将预处理后的数据划分为训练集、验证集和测试集。在训练过程中,模型通过前向传播计算预测值,通过反向传播计算损失函数对权重的梯度,利用优化器更新权重,不断迭代以降低损失函数值。验证集用于监控模型的泛化能力,防止过拟合。当验证集上的损失不再下降或达到预设的训练轮数时,停止训练。
- 选择优化器
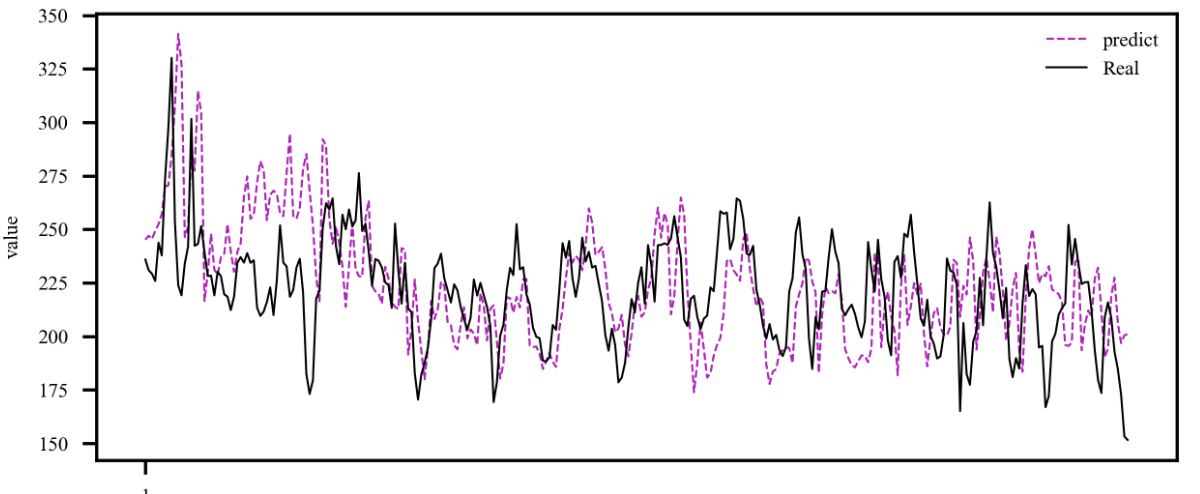
⛳️ 运行结果
🔗 参考文献
[1]包广斌,张瑞,彭璐,等.基于BO-BiGRU-Attention短期电力负荷预测[J].计算机技术与发展, 2024(5).
🍅更多免费数学建模和仿真教程关注领取

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)