GLM5-744B 模型结构拆解和昇腾profilling分析
作者:昇腾实战派
知识地图:https://blog.csdn.net/Lumos_Lovegood/article/details/161455142
背景概述
GLM-5 是智谱AI推出的第五代大语言模型,采用混合专家(MoE)架构,约 7450 亿总参数,256 个专家、每 token 激活 8 个(稀疏率 5.9%。GLM总共有744B参数,40B的激活参数。
| 维度 | 参数值 | 说明 |
|---|---|---|
| 模型类型 | glm_moe_dsa | GLM 混合专家模型,带动态稀疏注意力 |
| 隐藏层维度 | 6,144 | 模型主干宽度 |
| 层数 | 78 | Transformer 层总数 |
| 注意力头数 | 64 | 多头注意力机制的头数 |
| 前馈层维度 | 12,288 | 稠密层的前馈网络大小 |
| 词汇表大小 | 154,880 | 支持约 15.5 万个 token |
| 最大序列长度 | 202,752 | 约 20 万 token,超长上下文能力 |
| 精度 | bfloat16 | 训练 / 推理使用的数值精度 |
本文对GLM5-744B 模型结构进行了拆解,并以Atlas 800I A3混部的GLM5为例,分析其profiling特征。
硬件设备信息:Atlas 800I A3推理服务器
2. 智谱模型结构介绍
本文以GLM5模型结构为例,讲GLM5进行可视化处理,如图1所示
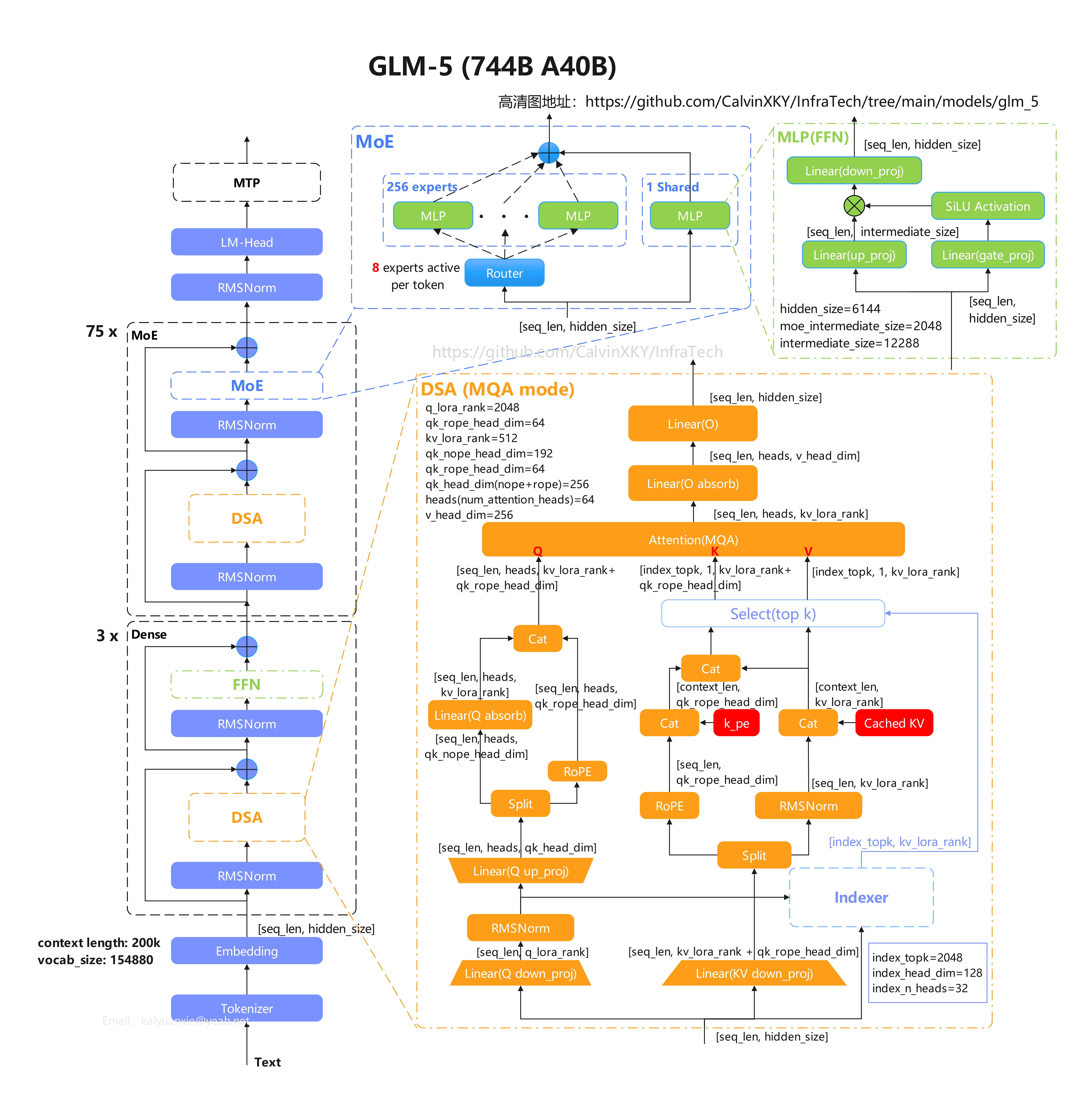
图中模型共有78层,其中dense层三层,Moe层75层。
已知Hiddensize=6144,num_attention_heads=64,head_dim=256,q_lora_rank = 2048,index_topk = 2048。
2.1 DSA层
输入shape:如图1所示,输入在经过一个RMSnorm后的shape为[B,S,6144]
进入attention前:
Query
Query经过Linear后会经过下投影降维到q_lora_rank,此时的shape为[B,S,2048]。在经过一个上投影和RMSNorm后升维成[B,S,64*256]。此时的Query会被split成两部分。用作内容的部分shape为[B,S,64*192],其中64代表head_dim,192代表qk_nope_head_dim。用作位置的部分shape为[B,S,64*64],其中前一个64代表head_dim,后一个64代表qk_rope_head_dim。用作内容的部分的再经过Q absorb残差吸收线性变幻后shape为[B,S,64*512],其中64代表head_dim,512代表 kv_lora_rank,它会和经过位置编码的部分进行拼接,最终shape为[B,S,64*576],其中576为qk_rope_head_dim+kv_lora_rank。
key value
key value经过Linear后会经过下投影降维到kv_lora_rank+qk_rope_head_dim,此时的shape为[B,S,576]。此时kv会被分离成用作位置的shape和用作内容的shape。在和历史KV cache拼接后和位置编码后的位置信息进行拼接,得到了[B,S,576]。在这里我们会利用indexer对得到的所有KV做筛选,只保留top k 2048个KV值,丢弃剩下的KV值,最后我们会得到k值的shape为[B, 2048,1,576],其中2048为index_topk,576为qk_rope_head_dim+kv_lora_rank。由于使用的是MQA结构,所以K和V的头数为1。
进入attention后:
在完成attention计算后的shape为[B,S,64,2048],其中64是num_attention_heads, 2048是index_topk。在经过两个线性化层后,最终shape为[B,S,hidden_size]
2.2MOE层
- 路由打分
- 输入:来自注意力层的 hidden states
- 门控网络计算每个专家的分数(logits)→ Softmax 得到概率
- 选出 Top-K 个专家(GLM5 的 K 为8)
- 专家计算(稀疏激活)
- 只把当前 token 送给 被选中的 K 个专家 做前向
- 同时有一个共享专家不参与路由选择,必须经过
- 其他专家不参与计算
- 加权合并
- 用门控输出的概率做权重,把 K+1 个专家的结果加权相加
- 作为 MoE 层输出,传给下一层
Moe层的所有shape,包括输入到输出,都是 [B,S,hidden_size] ,只有这样才可以做加权相加。
2.3 FFN层
FFN(x)=down(Swish(gate(x))⊙up(x))
FFN层输入[B,S,6144],6144hidden_size,是会升维成[B,S,12288],其中12288是2*hidden_size,同时在另一边,gate 对每一个维度输出一个 0~1 左右的权重, 然后逐元素相乘:Swish(gate)⊙up(x)。得到结果后,最终降维到[B,S,6144]输出,
3. DSA(MLA)流程与源码解析
首先,一句话简介 DSA = MLA(MQA + lora) + Lightning Indexer + Top‑k
DSA计算逻辑可以分为8个部分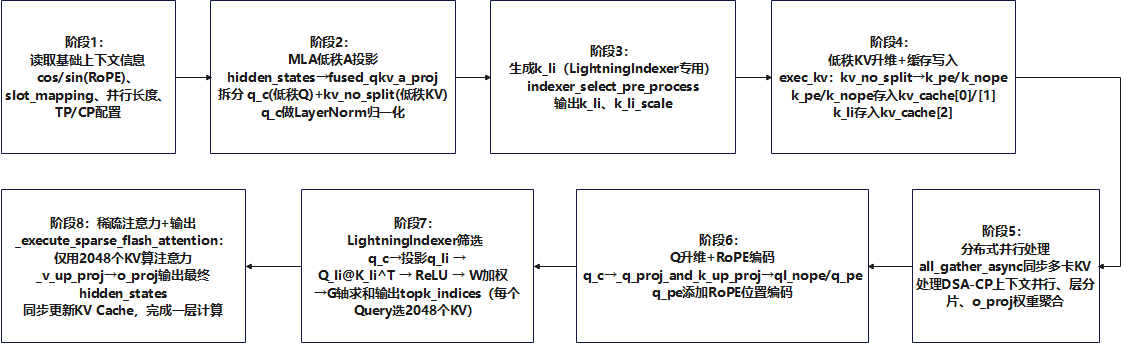
3.1 阶段1,DSA初始化
SFA的QKV初始化主要在AscendSFAImpl类,SFA会获取MLA给定的参数:
self.num_heads = num_heads # 注意力头的总数(Q总头数,如64)
self.head_size = head_size # 每个头的维度大小(如128)
self.scale = float(scale) # 注意力缩放因子 1/sqrt(head_dim)
self.num_kv_heads = num_kv_heads # KV的头数(GQA模式,比Q头少,如8)
self.kv_cache_dtype = kv_cache_dtype # KV Cache存储的数据类型(fp16/int8等)
self.q_proj = kwargs["q_proj"] if self.q_lora_rank is None else kwargs["q_b_proj"] # Q投影层,MLA低秩分支使用q_b_proj
self.fused_qkv_a_proj = kwargs.get("fused_qkv_a_proj") # MLA低秩A投影(QKV共享)
self.kv_b_proj = kwargs["kv_b_proj"] # KV的升维B投影层
self.o_proj = kwargs["o_proj"] # 注意力输出投影层
self.indexer = kwargs["indexer"] # DSA稀疏索引器(LightningIndexer)
self.kv_a_proj_with_mqa = kwargs.get("kv_a_proj_with_mqa") # 支持GQA/MQA的KV低秩A投影
self.kv_a_layernorm = kwargs.get("kv_a_layernorm") # KV低秩特征的LayerNorm归一化
self.q_a_layernorm = kwargs.get("q_a_layernorm") # Q低秩特征的LayerNorm归一化
self.num_queries_per_kv = self.num_heads // self.num_kv_heads # GQA:1个KV对应几个Q头
self.tp_size = get_tensor_model_parallel_world_size() # 张量并行总卡数
self.tp_rank = get_tp_group().rank_in_group # 当前卡的TP并行组内编号
3.2 阶段2,MLA 低秩 QKV 投影
q_c 代表Q 低秩特征(Query Low-Rank Feature),kv_no_split代表未拆分的 KV 低秩特征(KV Low-Rank Feature),这一阶段主要为了获取这两个值。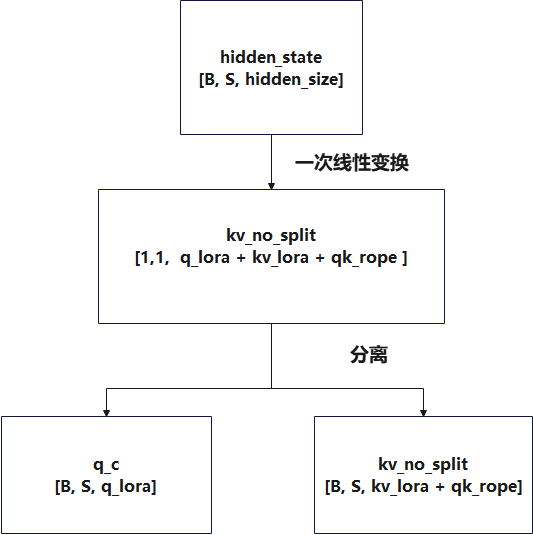
qkv_lora = self.fused_qkv_a_proj(hidden_states)[0]
q_c, kv_no_split = qkv_lora.split([self.q_lora_rank, self.kv_lora_rank + self.qk_rope_head_dim], dim=-1)
q_c = self.q_a_layernorm(q_c)
3.3 阶段3,生成 k_li(Indexer 用的轻量 Key)
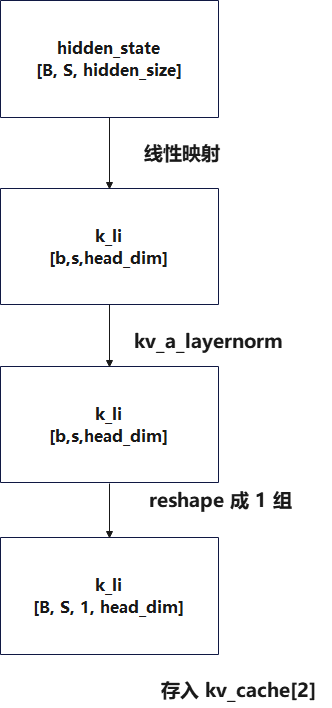
相关代码
k_li, k_li_scale = self.indexer_select_pre_process(x=hidden_states, cos=cos, sin=sin)
k_li, _ = self.wk(x) # [b,s,7168] @ [7168,128] = [b,s,128]
k_li = self.k_norm(k_li).unsqueeze(1)
k_li = k_li.view(-1, 1, self.head_dim)
3.4 阶段4,生成完整 KV 并写入 KV Cache
- 把低秩 KV → 升维成存入kvcache的 KV,并最终用于SFA计算
- 存入 kv_cache [0] 和 kv_cache [1]
- K_nope
- K_pe(带 RoPE)
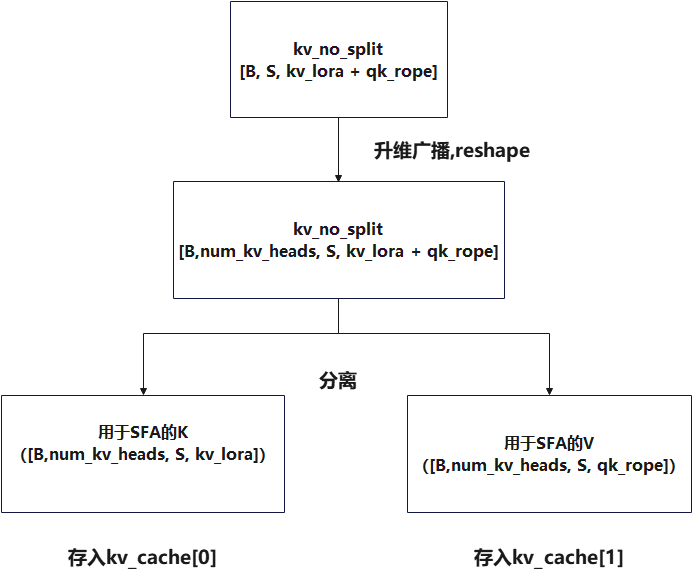
相关代码
k_pe, k_nope = self.exec_kv(kv_no_split, cos, sin, kv_cache, slot_mapping, attn_metadata)
def exec_kv(
self,
kv_no_split: torch.Tensor,
cos: torch.Tensor,
sin: torch.Tensor,
kv_cache: tuple,
slots: torch.Tensor,
attn_metadata: M,
):
B = kv_no_split.shape[0]
N = self.num_kv_heads
S = 1
# npu_kv_rmsnorm_rope_cache needs [B, N, S, D]
kv_no_split = kv_no_split.view(B, N, S, self.kv_lora_rank + self.qk_rope_head_dim)
cache_mode = "PA"
if self.enable_dsa_cp: ...
else:
torch_npu.npu_kv_rmsnorm_rope_cache(
kv_no_split,
self.kv_a_layernorm.weight, # type: ignore[union-attr]
cos,
sin,
slots.to(torch.int64),
kv_cache[1],
kv_cache[0],
epsilon=self.kv_a_layernorm.variance_epsilon, # type: ignore[union-attr]
cache_mode=cache_mode,
)
return None, None
)
3.5 阶段5,多卡并行(TP/CP)处理
fused_kv_no_split, kv_ag_handle = all_gather_async(...)
3.6 阶段6,Q 升维 + RoPE 位置编码
ql_nope, q_pe = self._q_proj_and_k_up_proj(q_c)
q_pe = self.rope_single(q_pe, cos, sin)
3.7 阶段7 LightningIndexer 核心计算
在这一步骤中,我们会调用在阶段获取之前存在kv cache中的k_li,并且生成新的q_li计算他们的相关性。
3.7.1 LightningIndexer核心计算理论
LightningIndexer基于一系列操作得到每一个 token 对应的 Top- k k k 个位置。对于某个 token 对应的 Index Query Q i n d e x ∈ R g × d Q_{index}\in\R^{g\times d} Qindex∈Rg×d,给定上下文 Index Key K i n d e x ∈ R S k × d , W ∈ R g × 1 K_{index}\in\R^{S_{k}\times d},W\in\R^{g\times 1} Kindex∈RSk×d,W∈Rg×1,其中 g g g 为 GQA 对应的 group size(此处为64), d d d 为每一个头的维度(此处为128), S k S_{k} Sk 是上下文的长度,LightningIndexer的具体计算公式如下:
Top- k { [ 1 ] 1 × g @ [ ( W @ [ 1 ] 1 × S k ) ⊙ ReLU ( Q i n d e x @ K i n d e x T ) ] } \text{Top-}k\left\{[1]_{1\times g}@\left[(W@[1]_{1\times S_{k}})\odot\text{ReLU}\left(Q_{index}@K_{index}^T\right)\right]\right\} Top-k{[1]1×g@[(W@[1]1×Sk)⊙ReLU(Qindex@KindexT)]}
可拆分为如下计算流程:
- 计算矩阵乘法: S = Q i n d e x @ K i n d e x T S = Q_{index}@K_{index}^T S=Qindex@KindexT;【* Q_index @ K_index.T:算相关性(我和谁关系好)】
- 计算激活函数: S ′ = ReLU ( S ) S'=\text{ReLU}(S) S′=ReLU(S);【* ReLU:去掉负分(只看正面关系)】
- 计算广播乘法: S W = ( W @ [ 1 ] 1 × S k ) ⊙ S ′ S_W=(W@[1]_{1\times S_{k}})\odot S' SW=(W@[1]1×Sk)⊙S′;【* W 加权:重要的人分数翻倍(VIP 加成)】
- 沿G轴进行Reduce操作: S c o r e = [ 1 ] 1 × g @ S W Score=[1]_{1\times g}@ S_W Score=[1]1×g@SW;【* 求和:多头合并成最终排名(所有头数值加起来)】
- 对 S c o r e Score Score 进行 Top- k \text{Top-}k Top-k 计算,即获取数值排序前 k k k 个的结果,并返回其对应的 Index,【* Top-k:选出最重要的 2048 个位置(选分最高的)】

3.7.2 indexer打分整体梳理
q_li和q_c本质上上一样的,q_c 是 “低秩压缩特征”,不能直接打分;必须投影成 q_li,才能和 k_li 维度对齐、多头对齐、空间对齐,完成相似度计算。
获取方法:
- 输入 q_c → 变成 q_li
- 从 kv_cache[2] 取 k_li (来自步骤三)
indexer_select_post_process关键代码如下
def indexer_select_post_process(self, x, q_c, kv_cache, attn_metadata, ...):
# 准备query
q_li = self.wq_b(q_c) # [b,s,1536] @ [1536,64*128] = [b,s,64*128]
q_li = rope_forward_triton_siso(q_li, cos, sin)
# 调用lightning_indexer进行稀疏选择
topk_indices = torch.ops._C_ascend.npu_lightning_indexer(
query=q_li,
key=kv_cache[2], # 使用预处理结果
weights=weights,
...
)
return topk_indices
3.8 阶段8 执行稀疏注意力 SFA
只使用 top2048 个 KV 计算注意力
核心的稀疏注意力计算在 _execute_sparse_flash_attention_process() 方法中实现 sfa_v1.py:1042-1065 :
def _execute_sparse_flash_attention_process(
self, ql_nope, q_pe, kv_cache, topk_indices, attn_metadata, actual_seq_lengths_query, actual_seq_lengths_key
):
block_table = attn_metadata.block_table
kv = kv_cache[0]
key_rope = kv_cache[1]
attn_output = torch.ops._C_ascend.npu_sparse_flash_attention(
query=ql_nope,
key=kv,
value=kv,
sparse_indices=topk_indices,
scale_value=self.scale,
sparse_block_size=1,
block_table=block_table,
actual_seq_lengths_query=actual_seq_lengths_query,
actual_seq_lengths_kv=actual_seq_lengths_key,
query_rope=q_pe,
key_rope=key_rope,
layout_query="TND",
layout_kv="PA_BSND",
sparse_mode=3,
)
return attn_output
4.Moe结构
GLM5的moe结构使用的是标准MOE结构,不分组,不添加额外分数加权,这部分可以参考之前Qwen的moe结构,不再额外赘述。(Qwen3.5 MoE模型结构拆解 - WIKI)
4.1 Moe结构transformers实现
transformers仓实现源码:
class DeepseekV3MoE(nn.Module):
"""
A mixed expert module containing shared experts.
"""
def __init__(self, config):
super().__init__()
self.config = config
self.experts = DeepseekV3NaiveMoe(config)
self.gate = DeepseekV3TopkRouter(config)
self.shared_experts = DeepseekV3MLP(
config=config, intermediate_size=config.moe_intermediate_size * config.n_shared_experts
)
self.n_routed_experts = config.n_routed_experts
self.n_group = config.n_group
self.topk_group = config.topk_group
self.norm_topk_prob = config.norm_topk_prob
self.routed_scaling_factor = config.routed_scaling_factor
self.top_k = config.num_experts_per_tok
def forward(self, hidden_states):
residuals = hidden_states
orig_shape = hidden_states.shape
router_logits = self.gate(hidden_states)
topk_indices, topk_weights = self.route_tokens_to_experts(router_logits)
hidden_states = hidden_states.view(-1, hidden_states.shape[-1])
hidden_states = self.experts(hidden_states, topk_indices, topk_weights).view(*orig_shape)
hidden_states = hidden_states + self.shared_experts(residuals)
return hidden_states
┌──────────────────────────────┐
│ 输入 hidden_states │
│ [b, s, d] │
└──────────────┬───────────────┘
│
▼
┌──────────────────────────────┐
│ Reshape 压扁维度 │
│ [b*s, hidden_dim] │
└──────────────┬───────────────┘
│
┌───────┴───────┐
│ │
▼ ▼
┌──────────────┐ ┌───────────────────┐
│ 路由Gate模块 │ │ 共享专家SharedExpert │
│ DeepseekV3 │ │ 全局所有Token都走 │
│ TopkRouter │ │ 独立MLP计算 │
└──────┬───────┘ └──────────┬──────────┘
│ │
▼ │
┌────────────────────────┐ │
│ 分组路由逻辑 │ │
│ 1.专家分 n_group 组 │ │
│ 2.选 topk_group 个组 │ │
│ 3.组内选 top_k 个专家 │ │
│ 4.输出专家索引+路由权重 │ │
└──────┬─────────────────┘ │
│ │
▼ │
┌──────────────────────────────┐
│ 稀疏专家 Experts 计算 │
│ DeepseekV3NaiveMoe │
│ 按选中专家分流、MLP推理 │
│ 路由权重加权聚合输出 │
└──────────────┬───────────────┘
│
▼
┌──────────────────────────────┐
│ 稀疏输出 + 共享输出 相加融合 │
└──────────────┬───────────────┘
│
▼
┌──────────────────────────────┐
│ Reshape 还原维度 │
│ [b, s, d] │
└──────────────┬───────────────┘
│
▼
┌──────────────────────────────┐
│ MoE 模块输出 │
└──────────────────────────────┘
forward 流程:
gate(x) → weights(8个专家的权重)、indices(8个专家的编号)
遍历本卡负责的专家,对路由到该专家的 token 调用 expert(x[idx]) * weights[idx],累加到 y
shared_experts(x) → z(对所有 token 都计算)
多卡时 all_reduce(y) 汇总路由专家输出
返回 y + z
5. 关键算子分析
5.1. 算子总览
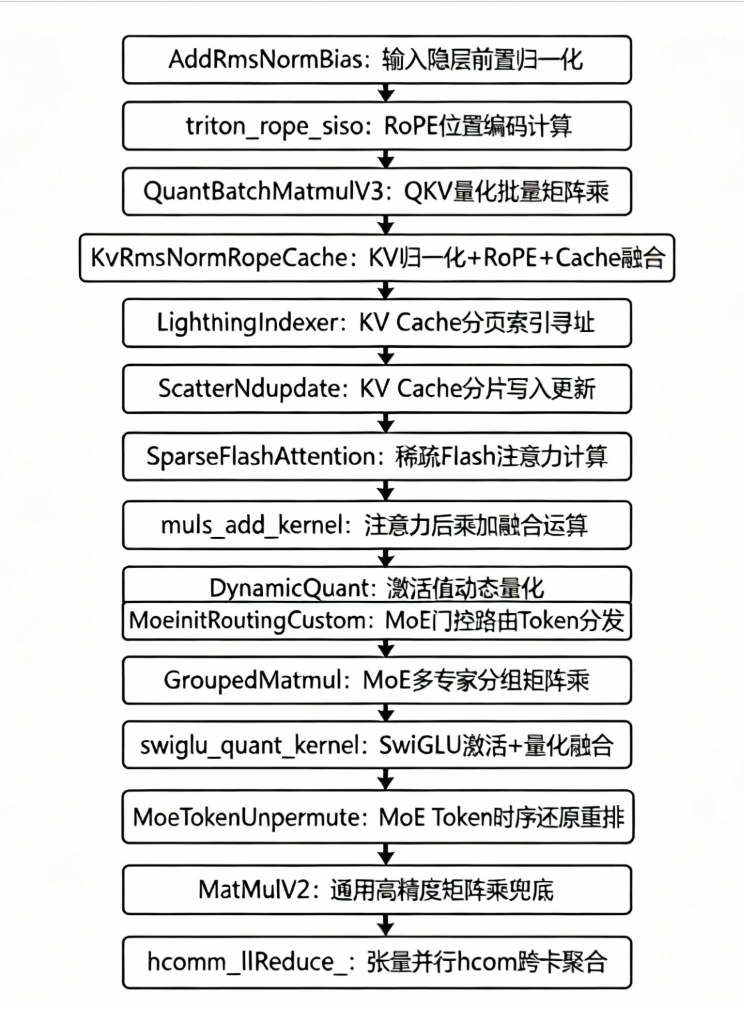
下面给出单个decode过程算子分析图,可以参考
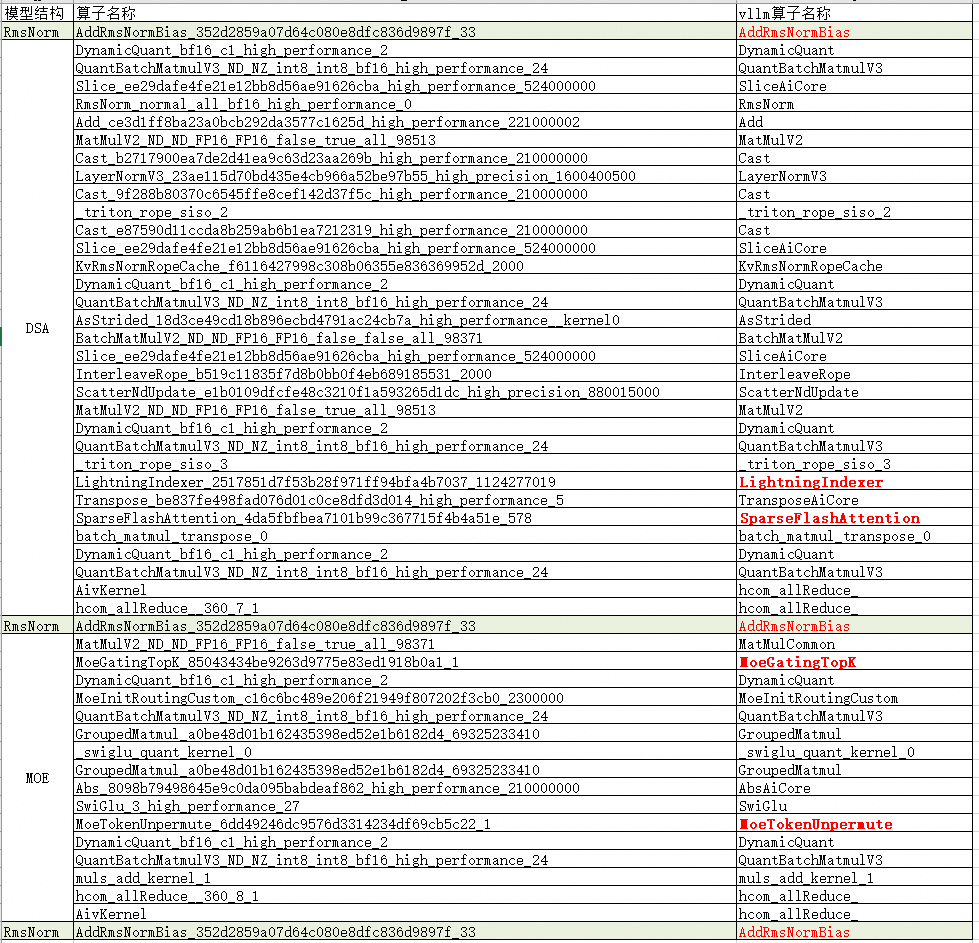
5.2. 关键算子归档
所有算子通过torch_binding.cpp注册到PyTorch框架中
| profiling算子名称 | 算子功能 | 算子代码实现 | 算子注册调用 |
|---|---|---|---|
| MoeGatingTopK | 在MOE架构中从所有计算结果分组里挑选前Topk个专家 | 点我查看 | 点我查看 |
| aclnnMoeInitRoutingCustom_MoeInitRoutingCustom_MoeInitRoutingCustom | 将输入token按专家索引展开,为后续分发做准备 | 点我查看 | 点我查看 |
| MoeDistributedDispatchV2(已合入MOE融合算子) | 将token分发到对应的专家rank,同时处理量化和通信优化 | 点我查看 | 点我查看 |
| MoeDistributedCombineV2(已合入MOE融合算子) | 将分散在各rank的结果按照原始的topk权重进行加权合并,还原回token的原始顺序 | 点我查看 | 点我查看 |
| LightningIndexerVllm | 稀疏索引计算,接受QKV并通过权重加权的相似度计算找出最重要的稀疏块索引 | 点我查看 | 点我查看 |
| SparseFlashAttention | 稀疏注意力计算,利用第一阶段生成的稀疏索引,计算被选中的重要块 | 点我查看 | 点我查看 |
| MoeTokenUnpermute | Moetoken重排 | 点我查看 | [点我查看]( vllm-ascend/vllm_ascend/ops/fused_moe/token_dispatcher.py at main · vllm-project/vllm-ascend (github.com)) |
5.3 lightning_indexer和SFA算子tilling和pipline分析
6. profilling分析
以下是一个Atlas 800I A3混部的GLM5profilling分析,场景为长序列, 128k输入,1k输出,mtp3,chunkedprefill
6. 1总体概览
从最大维度看,当前profilling采集到了两轮prefill和多轮decode。可以看到,模型主要的耗时都在prefill阶段(长序列瓶颈主要在prefill侧)
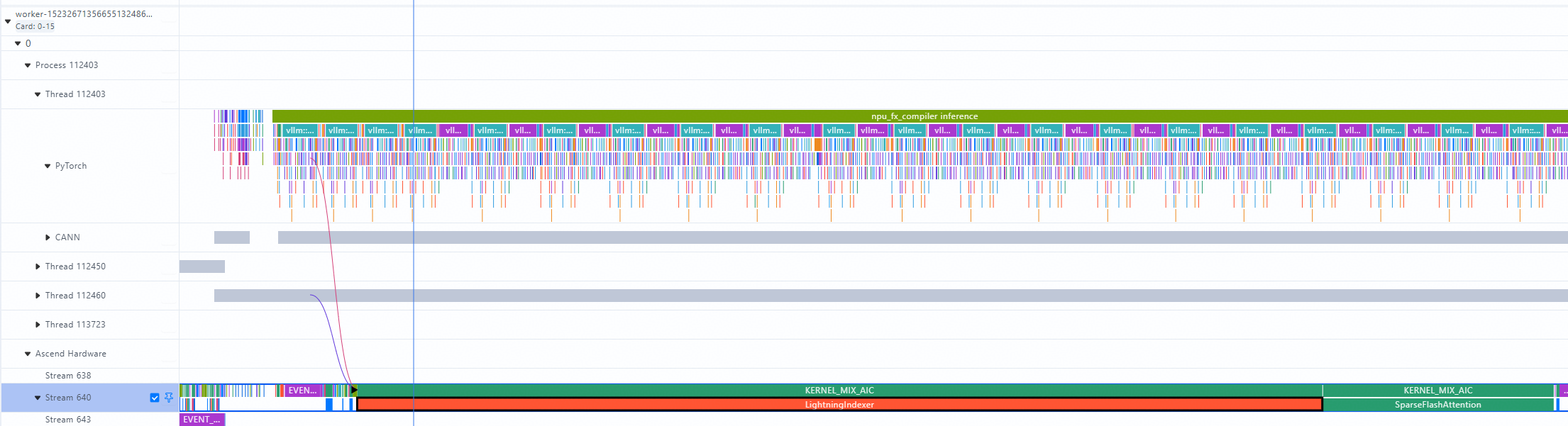
6. 2decode侧分析
我们可以尝试把单个decode打开看
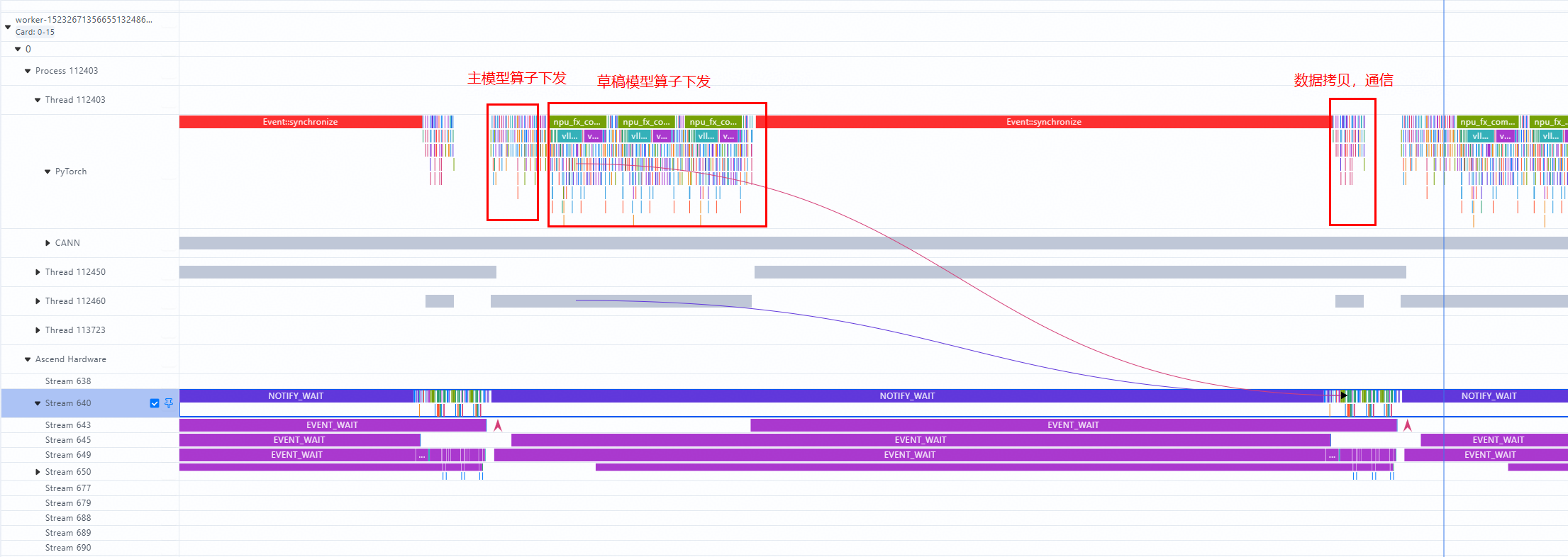
6. 3 prefill侧分析
我们也可以尝试把单个prefill打开看
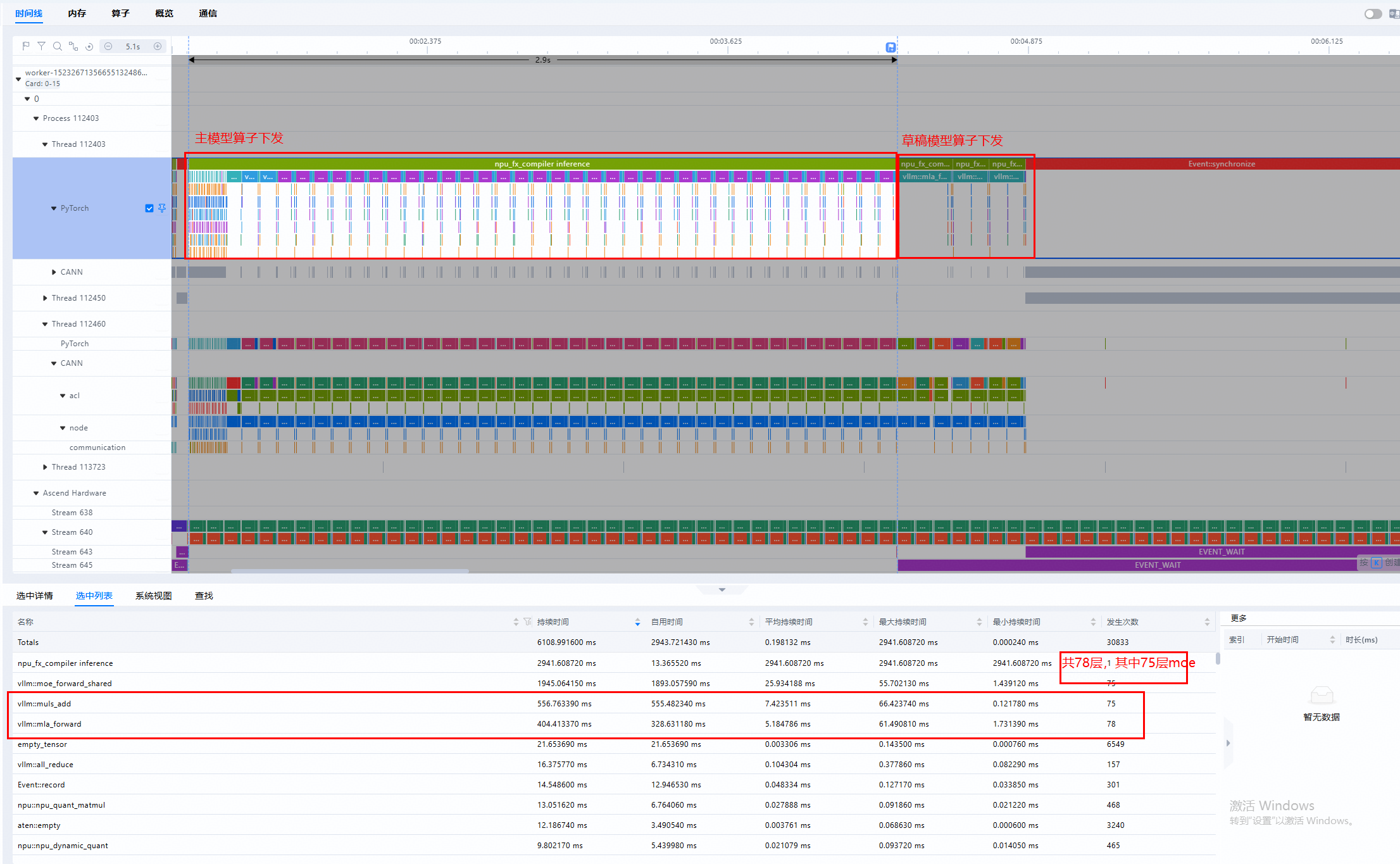

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)