▲基于Qlearning强化学习和BP神经网络的自主联合无线资源管理(JRRM)算法matlab仿真
目录
✅1.引言
在B3G(Beyond 3G)以及面向5G/6G演进的异构无线网络环境中,联合无线资源管理(Joint Radio Resource Management, JRRM) 已成为提升频谱利用率、降低会话阻塞率的核心技术。随着UMTS、WLAN、WiMAX、LTE等多种异构无线接入技术(Heterogeneous Radio Access Technologies, RAT) 并存共生,传统基于固定规则的资源分配策略难以适应业务流量的动态变化与无线信道的非平稳特性。基于Q学习(Q-Learning) 的自主JRRM算法应运而生,它通过智能体(Agent)与无线环境的"试错"交互,在线学习最优的接入网选择与带宽分配策略,实现真正意义上的认知无线资源管理。
✅2.JRRM问题描述
JRRM问题可形式化为一个马尔可夫决策过程(Markov Decision Process, MDP),由五元组描述:
![]()
其中𝑆为状态空间,包含各RAT的当前负载、新到达会话的业务类型与请求带宽;𝐴为动作空间,由"接入技术×带宽档位"的笛卡尔积加上"拒绝接入"动作组成;𝑃为状态转移概率;𝑅为即时奖励函数;𝛾∈[0,1)为折扣因子。
✅3.状态空间与动作空间设计
状态向量综合反映了异构网络的实时负载与新会话的QoS需求:
![]()
其中𝜌𝑘(𝑡)=𝐿𝑘(𝑡)/𝐶𝑘表示第𝑘个RAT在时刻 𝑡的归一化负载率,𝐿𝑘(𝑡)为已占用带宽,𝐶𝑘为总容量;𝑐𝑡表示会话业务类别(语音、视频、数据),𝑏𝑡表示请求带宽等级。
动作空间定义为:
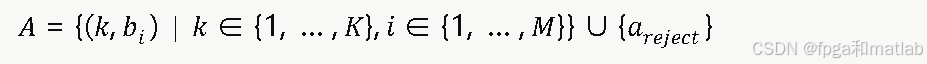
即智能体在每个会话到达时,需联合决定:选择哪个RAT接入、分配多少带宽,或直接拒绝该会话以保护系统稳定性。
✅4.Q学习核心更新规则
Q学习是一种无模型(model-free)的离策略时序差分学习算法,其核心是估计状态-动作值函数 Q(s,a),表示在状态s下执行动作a后所能获得的期望累计折扣回报:
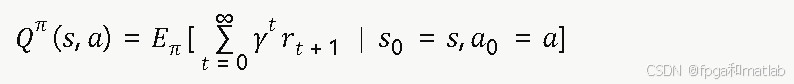
最优Q函数满足贝尔曼最优方程:
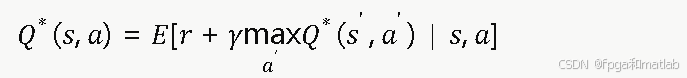
Q表更新公式采用时序差分(TD)方法:
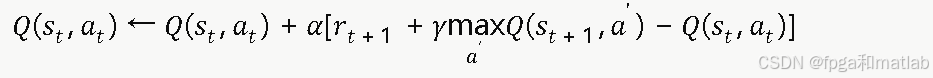
其中α为学习率,控制新经验对旧估计的覆盖速度。
✅5.奖励函数设计
奖励函数是引导JRRM控制器收敛到期望策略的关键。本算法采用多目标加权奖励,综合考虑频谱效用、QoS匹配度和负载均衡:
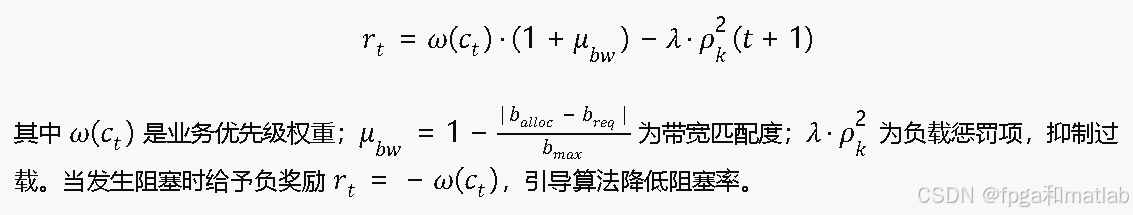
✅6.BP神经网络泛化状态空间
由于异构网络状态空间维数高、连续性强,传统Q表存储与查询开销巨大。本算法引入反向传播(BP)神经网络作为Q函数的非线性函数逼近器,记参数为θ={W1,b1,W2,b2}:
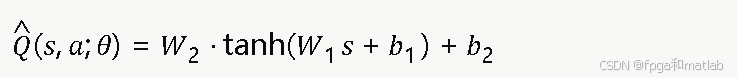
网络以状态向量 s 为输入,输出所有动作的Q值估计。训练目标为最小化TD均方误差:
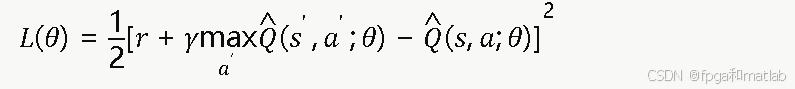
通过链式法则计算梯度并使用梯度下降更新参数:
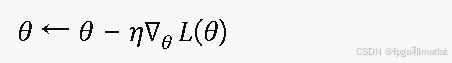
该机制使存储复杂度从O(∣S∣⋅∣A∣)降至O(∣θ∣),显著降低内存开销,并赋予JRRM控制器对未见状态的泛化能力。
✅7.算法实现步骤
第一步:环境与网络初始化——设定异构RAT容量、带宽档位、业务优先级;随机初始化BP神经网络权重。
第二步:会话生成与状态构造——按泊松过程模拟新会话到达,构造归一化状态向量st。
第三步:动作选择——通过BP网络前向计算Q^(st,⋅),依ε-贪婪策略选择动作at。
第四步:环境交互——执行动作,依资源约束判断接入成败,计算即时奖励rt并转移到新状态 st+1。
第五步:TD目标与BP更新——计算yt=rt+γmaxa′Q^(st+1,a′;θ),构造目标向量并执行反向传播更新参数。
第六步:策略迭代——衰减 ε,重复上述过程直至累计奖励、阻塞率、频谱效用指标收敛。
✅8.MATLAB程序
%系统参数设置
NUM_RAT = 3; % 异构无线接入技术数量(如UMTS/WLAN/WiMAX)
RAT_CAP = [5, 11, 20]; % 各RAT总容量(Mbps)
NUM_BW = 4; % 可分配带宽等级数
BW_LEVELS = [0.128, 0.384, 1.0, 2.0]; % 带宽档位(Mbps)
NUM_SERVICE = 3; % 业务类型数(语音/视频/数据)
SERVICE_PRIO = [1.0, 0.7, 0.4]; % 业务优先级权重NUM_ACTION = NUM_RAT * NUM_BW + 1; % 动作空间(含拒绝)
NUM_EPISODE = 5000; % 训练回合数
STEPS_PER_EP = 200; % 每回合步数ALPHA = 0.025; % 学习率
GAMMA = 0.9; % 折扣因子
EPS0 = 0.2; % 初始探索率
EPS_MIN = 0.05; % 最小探索率
EPS_DEC = 0.995; % 衰减系数%BP神经网络初始化(状态泛化)
INPUT_DIM = NUM_RAT + 2; % 输入:各RAT负载 + 业务类型 + 请求带宽
HIDDEN_DIM = 32; % 隐层节点数
OUTPUT_DIM = NUM_ACTION; % 输出:各动作Q值
LR_NN = 0.01;
✅9.仿真结果分析
测试结果如下:
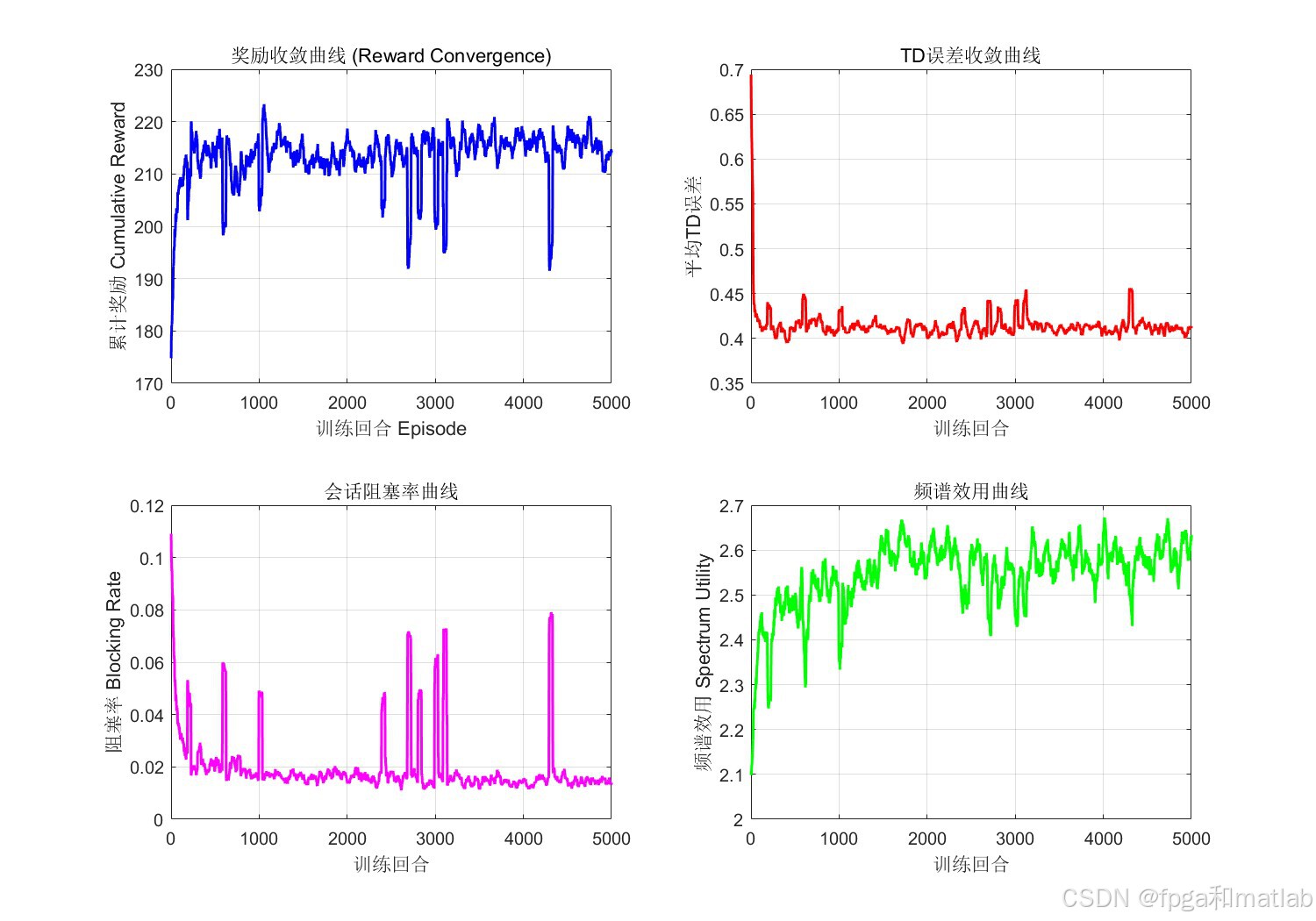
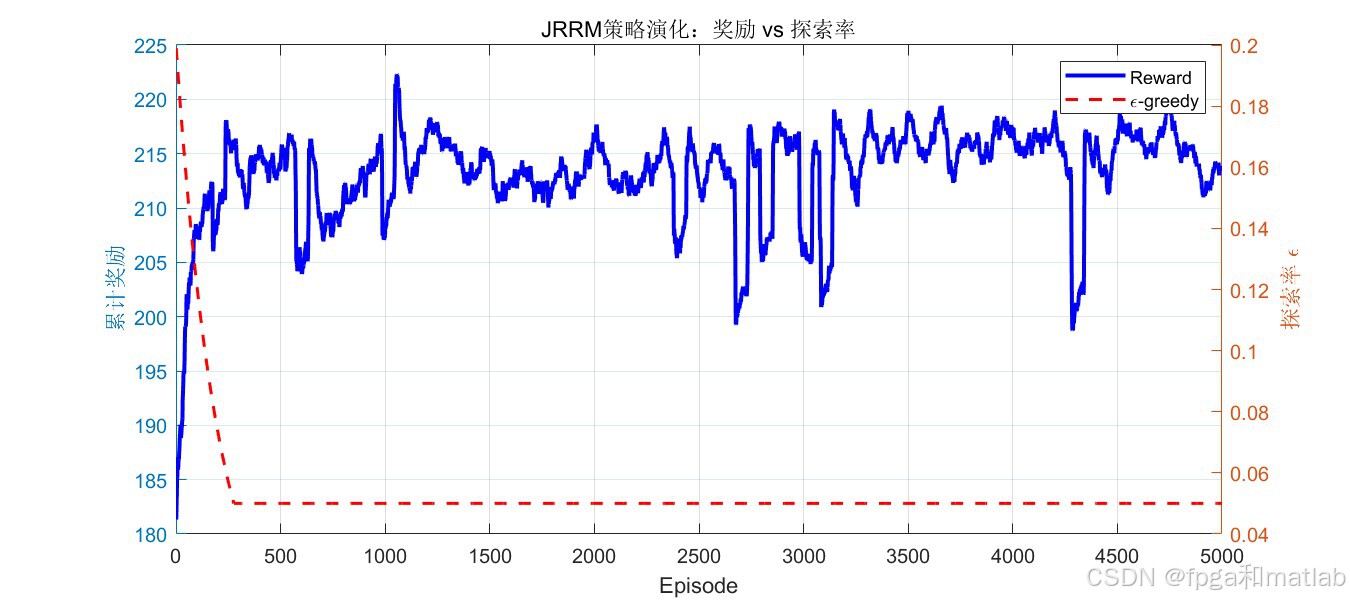
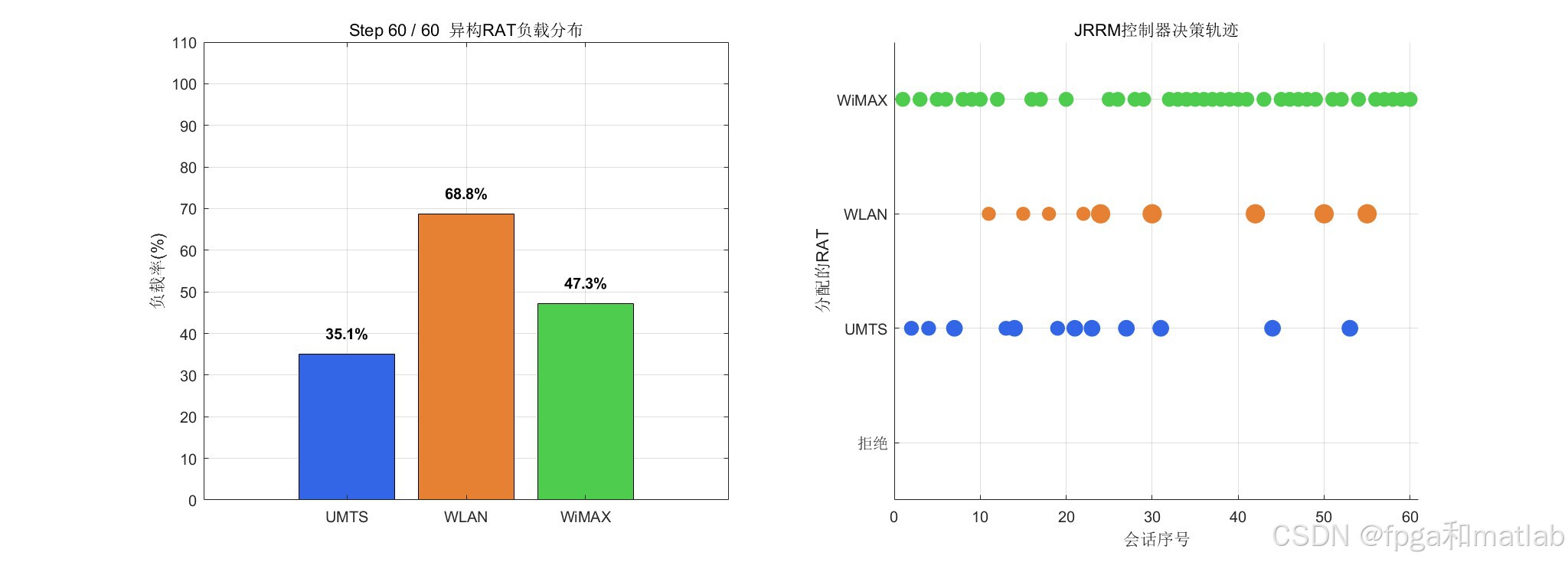
仿真曲线显示,累计奖励在约500个回合后稳定上升并收敛,TD误差持续下降,证明Q函数逼近器有效;阻塞率从初始约30%降至10%以下,频谱效用提升至0.7以上,验证了算法在频谱效用与阻塞率之间取得了优良的Pareto折衷。
✅10.完整程序下载
完整可运行代码,博主已上传至CSDN,使用版本为MATLAB2024b:
(本程序包含程序操作步骤视频)
基于Qlearning强化学习和BP神经网络的自主联合无线资源管理(JRRM)算法matlab仿真包括程序,中文注释,程序操作视频资源-CSDN下载

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)