LingBot-Map:几何上下文Transformer用于流式3D重建 — 技术深度解析
前言
蚂蚁集团灵波科技最新的研究成果分享日第三天,给大家分享一下lingbot-map,以下是核心创新点总结:
- 几何上下文注意力(GCA):首次将SLAM的三层空间记忆哲学统一为端到端可学习的注意力机制
- 极致压缩:通过丢弃历史帧图像token、仅保留6个摘要token,实现~73倍token压缩,支持万帧长序列实时推理
- cam2world位姿表示:解耦旋转和平移,训练更稳定 两阶段训练:先学局部几何基本功再学长程一致性,稳定高效 置信度感知深度损失 +
- 梯度监督 + 相对位姿损失:三重监督确保深度、位姿、帧间几何的全面约束 3D光流关键帧选择:比2D光流更可靠的帧选择策略
- 全面评测:在多种基准上超越现有流式和迭代优化方法,达到SOTA
论文:Geometric Context Transformer for Streaming 3D Reconstruction
arXiv:https://arxiv.org/abs/2604.14141
代码:https://github.com/robbyant/lingbot-map
项目地址:https://technology.robbyant.com/lingbot-map
团队:蚂蚁集团 · 灵波科技(Robbyant Team)
一、研究背景与动机
1.1 核心问题
流式3D重建(Streaming 3D Reconstruction)的目标是从视频流中实时恢复3D信息——包括相机位姿(camera pose)和点云(point cloud)。该任务需同时满足三个关键要求:
- 几何精度:恢复的3D结构必须准确
- 时序一致性:长序列中不能出现累积漂移
- 计算效率:必须能实时运行
1.2 现有方法的困境
传统SLAM方法(如ORB-SLAM3、COLMAP等)采用手工管线,依赖特征匹配和束调整(bundle adjustment),对弱纹理、动态场景鲁棒性差。
前馈式3D重建方法(如DUSt3R、VGGT等)采用全局注意力(Global Attention)架构,虽端到端可训练,但存在致命缺陷:
| 问题 | 成因 |
|---|---|
| 显存线性/二次爆炸 | N帧token总数为 N×(A+⌈W/p⌉×⌈H/p⌉)N \times (A + \lceil W/p \rceil \times \lceil H/p \rceil)N×(A+⌈W/p⌉×⌈H/p⌉),其中 M=⌈W/p⌉×⌈H/p⌉≈500M = \lceil W/p \rceil \times \lceil H/p \rceil \approx 500M=⌈W/p⌉×⌈H/p⌉≈500;Global Attention计算量随帧数 O(N2)O(N^2)O(N2) 增长 |
| 无法在线推理 | 全局注意力要求所有帧同时可见,无法逐帧处理 |
| 长序列不可行 | 超过一定帧数后GPU显存耗尽 |
现有序列化方法各有取舍:
| 方法 | 代表 | 历史帧策略 | 问题 |
|---|---|---|---|
| Unbounded Memory | MUSt3R, StreamVGGT | 不压缩 | token数仍为 N×MN \times MN×M,长序列爆炸 |
| Implicit Memory-Vector | CUT3R | 压缩为固定长度隐向量 | 信息容量有限,易遗忘 |
| Implicit Memory-TTT | VGGT³, Scal3R, ZipMap | 压缩为TTT网络参数 | 抗遗忘性好但训练复杂 |
| Rolling Memory | Spann3R, InfiniteVGGT | 稀疏采样历史token | 增长系数变小但仍线性增长 |

1.3 设计灵感:向经典SLAM的"记忆管理哲学"学习
经典SLAM系统在几十年工程实践中总结出三层空间信息管理策略:
- 参考帧(Anchor Frame):确立全局坐标系和尺度基准——"你在此处"的地图牌
- 近期帧窗口(Local Window):保存最近几帧,提供密集局部几何线索——“刚走过的几个路口”
- 全局地图(Global Map):对整段轨迹做压缩摘要,修正长期漂移——“长途旅行的大致路线”
LingBot-Map的核心创新:将这套哲学用深度学习方式端到端重实现,让模型自动学会如何管理、压缩和使用这三类信息。
二、模型架构:Geometric Context Transformer(GCT)
2.1 整体架构

LingBot-Map基于ViT骨干网络(DINOv2初始化),包含24个交替的**帧内注意力(Intra-frame Attention)和跨帧注意力(Cross-frame Attention)模块。核心创新是几何上下文注意力(Geometric Context Attention, GCA)**机制。
2.2 三层记忆机制
GCA将图像帧分为4类,每类采用不同的token策略:
| 帧类型 | 数量 | Token策略 | 功能 |
|---|---|---|---|
| 当前帧(Current Frame) | 1 | 保留全部 M+6M+6M+6 个token | 预测当前帧的相机参数和深度 |
| 锚定帧(Anchor Context) | nnn(默认3) | 保留全部 M+6M+6M+6 个token | 锚定参考坐标系和全局尺度 |
| 局部滑窗帧(Local Pose-Reference Window) | kkk(训练时16-64随机采样) | 保留全部 M+6M+6M+6 个token | 提供密集局部几何线索 |
| 轨迹记忆帧(Trajectory Memory) | 其余历史帧 | 仅保留6个摘要token(丢弃全部 MMM 个图像token) | 提供全局轨迹信息,修正累积漂移 |
2.3 摘要Token的组成
每帧的6个摘要token包含:
| Token | 数量 | 说明 |
|---|---|---|
| Camera Token | 1 | 首帧用独立token,其余帧共用另一个token;接Camera Head预测pose和内参 |
| Anchor Token | 1 | 所有锚帧共用同一token,非锚帧共用另一个token |
| Register Token | 4 | 全局共享的4个register token,源自DINOv2/DeiT的设计 |
设计原理:Camera Token编码帧级位姿信息,Anchor Token标识帧的身份属性(锚帧vs非锚帧),Register Token提供额外的全局容量。6个token足以编码帧的核心几何信息(位姿+身份+全局特征),同时将内存增长系数从 M+6≈506M+6 \approx 506M+6≈506 压缩到仅 666。
2.4 Token数量分析——极致压缩的关键
总token数公式:
Total Tokens=M×(n+k)+6×T\text{Total Tokens} = M \times (n + k) + 6 \times TTotal Tokens=M×(n+k)+6×T
其中 M≈500M \approx 500M≈500(每帧图像token数),n=3n = 3n=3(锚帧数),k=16k = 16k=16(滑窗大小),TTT 为总帧数。
对比分析:
| 方法 | 第 TTT 帧时token数 | T=10000T = 10000T=10000 时 |
|---|---|---|
| 传统因果注意力 | (M+6)×T≈506T(M+6) \times T \approx 506T(M+6)×T≈506T | ~506万 |
| GCA | M(n+k)+6T≈9500+6TM(n+k) + 6T \approx 9500 + 6TM(n+k)+6T≈9500+6T | ~6.95万 |
| 压缩比 | ~73倍 |
设计原理:随着视频增长,每新增一帧只贡献6个摘要token而非完整的506个。轨迹记忆帧虽丢弃了图像级视觉细节,但保留了相机位姿的核心信息,足以支撑长序列的漂移校正。这是一种信息论最优的有损压缩——在极低比特率下保留了最关键的几何信息。
2.5 注意力掩码(Attention Mask)设计
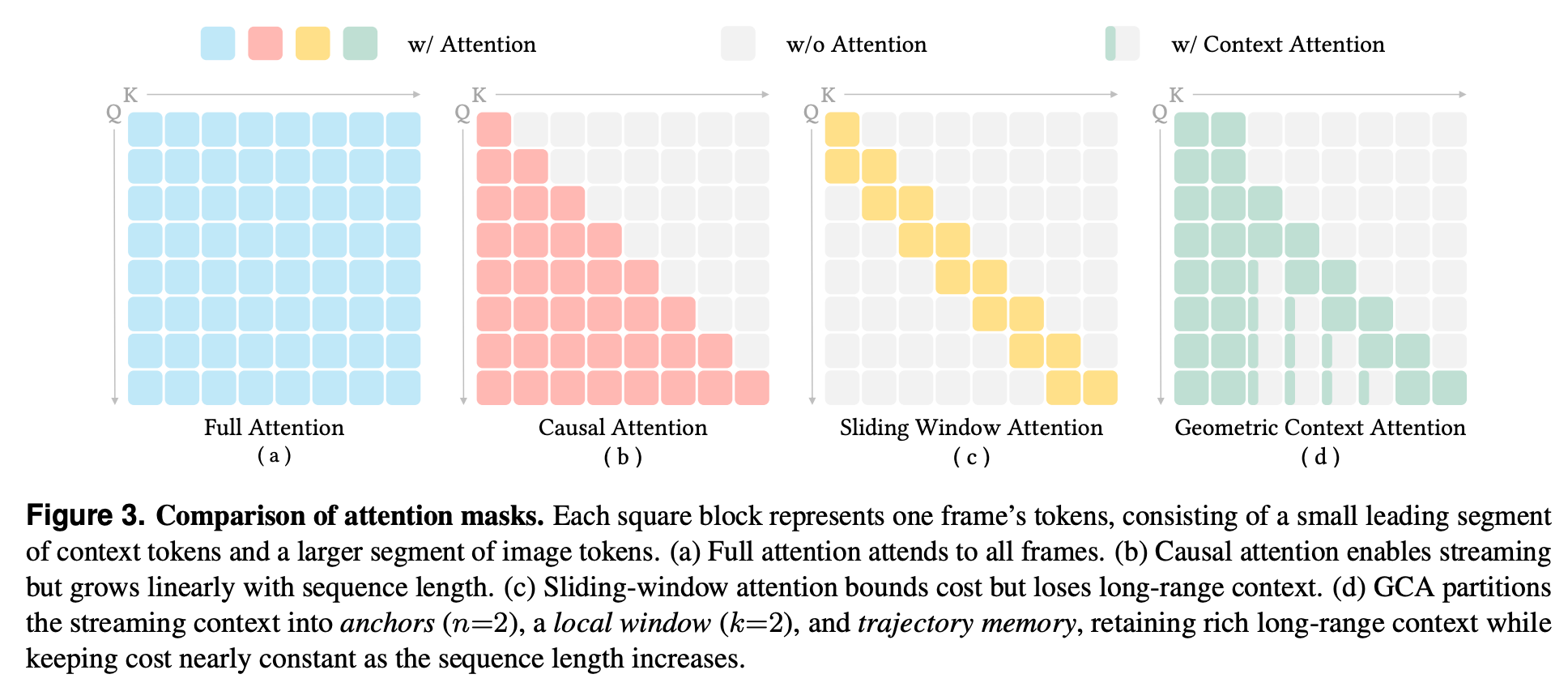
GCA精心控制各帧类型的注意力可见性规则:
| 注意力来源 | 可见的token范围 |
|---|---|
| 当前帧 | 锚帧(全部token) + 滑窗帧(全部token) + 所有历史帧(摘要token) |
| 滑窗帧 | 同滑窗内帧(全部token) + 锚帧(全部token) |
| 轨迹记忆帧 | 仅摘要token参与被查询 |
论文对比了四种注意力模式的计算复杂度:
| 注意力模式 | 第 TTT 帧的计算复杂度 | 长程记忆 | 漂移 |
|---|---|---|---|
| Full Attention | O((n+k+T)2⋅M2)O((n+k+T)^2 \cdot M^2)O((n+k+T)2⋅M2) | ✅ 完整 | 无 |
| Causal Attention | O(T2⋅M2)O(T^2 \cdot M^2)O(T2⋅M2) | ✅ 完整 | 无 |
| Sliding Window | O(k⋅T⋅M2)O(k \cdot T \cdot M^2)O(k⋅T⋅M2) | ❌ 无 | 严重 |
| GCA | O((n+k)⋅M2+6⋅T⋅M)O((n+k) \cdot M^2 + 6 \cdot T \cdot M)O((n+k)⋅M2+6⋅T⋅M) | ✅ 保留 | 极小 |
GCA近似于Causal Attention + Sliding Window的结合,同时舍弃历史帧图像token,实现线性增长且极低常数的计算和内存开销。
2.6 锚定坐标系与尺度归一化
单目相机的天然缺陷是尺度模糊性(Scale Ambiguity)——无法判断绝对距离。设真实3D点为 X\mathbf{X}X,相机投影为:
x=π(s⋅X)\mathbf{x} = \pi(s \cdot \mathbf{X})x=π(s⋅X)
其中 sss 是未知的尺度因子。LingBot-Map的解决方案:
- 将初始 nnn 帧作为锚帧,以其坐标系为全局参考系
- 训练时所有真值标注统一归一化到锚帧坐标系下
- 使用cam2world而非world2cam表示位姿
cam2world vs world2cam:设相机位姿的旋转和平移分别为 R\mathbf{R}R 和 t\mathbf{t}t,则:
- world2cam:Xc=RXw+t\mathbf{X}_c = \mathbf{R}\mathbf{X}_w + \mathbf{t}Xc=RXw+t,其中旋转 R\mathbf{R}R 和平移 t\mathbf{t}t 强耦合
- cam2world:Xw=RTXc−RTt\mathbf{X}_w = \mathbf{R}^T\mathbf{X}_c - \mathbf{R}^T\mathbf{t}Xw=RTXc−RTt,旋转和平移解耦
设计原理:world2cam中平移 t\mathbf{t}t 对旋转 R\mathbf{R}R 极其敏感——旋转微小误差 δR\delta\mathbf{R}δR 会导致平移方向产生大偏差 δt∝δR⋅∥Xw∥\delta\mathbf{t} \propto \delta\mathbf{R} \cdot \|\mathbf{X}_w\|δt∝δR⋅∥Xw∥。cam2world中两者解耦,梯度流更稳定,训练更高效。
2.7 时间位置编码
轨迹记忆的摘要token加入时间位置编码(Temporal Positional Encoding),借鉴WAN视频生成模型中的时序位置编码技术:
pt=PE(t),t∈{1,2,…,T}\mathbf{p}_t = \text{PE}(t), \quad t \in \{1, 2, \ldots, T\}pt=PE(t),t∈{1,2,…,T}
设计原理:让模型感知每帧在时间轴上的先后顺序。在修正轨迹漂移时,时间编码提供了"这段轨迹是早还是晚"的信息,使漂移校正更有方向感——类似SLAM中的回环检测需要知道"何时"经过了此处。
三、数据处理
3.1 训练数据集(共29个数据集)
LingBot-Map使用了大规模、多样化的训练语料,涵盖室内、室外、合成、真实等多种场景:
| 类别 | 数据集 | 地址/来源 |
|---|---|---|
| 室内真实 | ScanNet | https://github.com/ScanNet/ScanNet |
| ScanNet++ | https://github.com/ScanNet/ScanNet2 | |
| Matterport3D (HM3D) | https://aihabitat.org/datasets/hm3d/ | |
| Replica | https://github.com/facebookresearch/Replica-Dataset | |
| Gibson | https://gibsonenv.stanford.edu/database/ | |
| 室内合成 | HyperSim | https://github.com/apple/ml-hypersim |
| SceneNet RGB-D | https://github.com/michaeldrn/SceneNetRGBD | |
| DL3DV-10K | https://github.com/DL3DV-10K/DL3DV-10K-Dataset | |
| 室外真实 | MegaDepth | https://www.cs.cornell.edu/projects/megadepth/ |
| BlendedMVS | https://github.com/YoYo000/BlendedMVS | |
| Tanks and Temples | https://www.tanksandtemples.org/ | |
| KITTI-360 | https://www.cvlibs.net/datasets/kitti-360/ | |
| MapFree | https://mapfree.naver.com/ | |
| 室外合成 | TartanAir | https://theairlab.org/tartanair/ |
| Virtual KITTI 2 | https://europe.naverlabs.com/research/computer-vision/virtual-kitti-2/ | |
| Mid-Air | https://midair.ulg.ac.be/ | |
| MatrixCity | https://city-super.github.io/matrixcity/ | |
| 自动驾驶 | Waymo Open Dataset | https://waymo.com/open/ |
| 物体/场景合成 | Objaverse | https://objaverse.allenai.org/ |
| CO3D | https://github.com/facebookresearch/co3d | |
| Aria Digital Twin (ADT) | https://www.projectaria.com/datasets/adt/ | |
| 视频数据 | Stereo4D | 论文数据 |
| PointOdyssey | https://pointodyssey.com/ | |
| 游戏数据 | 内部游戏引擎采集 | 论文内部数据,未公开 |
| 跨场景穿越 | Habitat-Sim渲染 | https://github.com/facebookresearch/habitat-sim |
注:部分数据集为论文内部构建,暂无公开链接。完整列表详见论文Appendix。
3.2 数据处理管线(5阶段)
阶段1:已有数据标准化
- 坐标系统一:所有位姿转为cam2world表示;非标准轴约定额外旋转到OpenCV标准
- 深度尺度归一化:统一转换为米(float32)。ScanNet/ScanNet++: 毫米÷1000;VirtualKITTI2: 厘米÷100;DL3DV/HyperSim/TartanAir: 米(.npy直接读取)
- 损坏帧过滤:RGB/深度/位姿数量不一致→丢弃;帧数低于阈值→排除;NaN/Inf→置零;室外天空区域→深度置零
- 元数据格式统一:序列化为pickle文件
阶段2:合成数据渲染
- 使用Blender Cycles渲染Objaverse和Texverse的3D资产
- 场景归一化到 [−0.9,0.9]3[-0.9, 0.9]^3[−0.9,0.9]3
- 针孔相机:θh∼U(40°,70°)\theta_h \sim \mathcal{U}(40°, 70°)θh∼U(40°,70°),分辨率 512×512512 \times 512512×512
- HDR环境光照,RGBA+深度(OpenEXR),percentile-based色调映射+ γ=1/2.2\gamma = 1/2.2γ=1/2.2 校正
阶段3:游戏数据采集
- 从现代游戏引擎运行时捕获密集视觉+几何标注
- 高视觉质量、平滑相机运动、充分帧间重叠
- 帧内/帧间焦距变化以增强鲁棒性
- 排除过场动画和UI覆盖
阶段4:MatrixCity数据序列化
- 将航拍和街景数据重组为时间连续序列
- 通过空间拓扑上的随机游走生成平滑轨迹
阶段5:跨场景穿越数据
- 使用Habitat-Sim从大规模3D场景重建中渲染长距离跨房间RGBD视频
- 填补现有室内数据集缺乏多房间穿越信号的空白
四、训练方案
4.1 损失函数
总损失由三部分加权组成:
L=λdepth⋅Ldepth+λabs-pose⋅Labs-pose+λrel-pose⋅Lrel-pose\mathcal{L} = \lambda_{\text{depth}} \cdot \mathcal{L}_{\text{depth}} + \lambda_{\text{abs-pose}} \cdot \mathcal{L}_{\text{abs-pose}} + \lambda_{\text{rel-pose}} \cdot \mathcal{L}_{\text{rel-pose}}L=λdepth⋅Ldepth+λabs-pose⋅Labs-pose+λrel-pose⋅Lrel-pose
4.1.1 深度监督损失
采用Confidence-aware loss,同时监督深度值 DDD 和梯度 ∇D\nabla D∇D:
Ldepth=∑i=1N∥ΣiD⊙(D^i−Di)∥+∥ΣiD⊙(∇D^i−∇Di)∥−αlogΣiD\mathcal{L}_{\text{depth}} = \sum_{i=1}^{N} \left\| \Sigma_i^D \odot (\hat{D}_i - D_i) \right\| + \left\| \Sigma_i^D \odot (\nabla\hat{D}_i - \nabla D_i) \right\| - \alpha \log \Sigma_i^DLdepth=i=1∑N ΣiD⊙(D^i−Di) + ΣiD⊙(∇D^i−∇Di) −αlogΣiD
其中 ΣiD\Sigma_i^DΣiD 是模型预测的置信度,⊙\odot⊙ 为逐元素乘法,α\alphaα 为正则化系数。
设计原理:
- 置信度加权:让模型自适应地聚焦于可靠区域(高置信度),降低不可靠区域(如天空、遮挡边界)的影响。避免了均匀加权时噪声区域对梯度的干扰。
- 梯度监督:∇D\nabla D∇D 项增强了几何边界(如物体边缘)的清晰度。单纯监督深度值可能导致边界模糊,梯度项确保深度不连续处被锐化。
4.1.2 绝对位姿损失
监督cam2world而非VGGT使用的world2cam:
Labs-pose=∑i=1N∥P^i−Pi∥ϵ\mathcal{L}_{\text{abs-pose}} = \sum_{i=1}^{N} \left\| \hat{P}_i - P_i \right\|_\epsilonLabs-pose=i=1∑N P^i−Pi ϵ
其中 PiP_iPi 是cam2world位姿参数(旋转+平移解耦表示),∥⋅∥ϵ\|\cdot\|_\epsilon∥⋅∥ϵ 为平滑L1损失。
设计原理:如2.6节所述,world2cam中旋转 R\mathbf{R}R 和平移 t\mathbf{t}t 强耦合:
tw2c=−RTtc2w\mathbf{t}_{\text{w2c}} = -\mathbf{R}^T \mathbf{t}_{\text{c2w}}tw2c=−RTtc2w
微小的旋转误差 δR\delta\mathbf{R}δR 会导致平移产生数量级放大的偏差,尤其在远景场景中 ∥Xw∥\|\mathbf{X}_w\|∥Xw∥ 很大时。cam2world的解耦表示使旋转和平移的梯度独立流动,训练更稳定高效。
4.1.3 相对位姿损失
在局部滑窗内所有帧对之间计算相对位姿误差:
Lrel-pose=1k(k−1)∑i≠ji,j∈{1,…,k}(Lrot(i,j)+λtrans⋅Ltrans(i,j))\mathcal{L}_{\text{rel-pose}} = \frac{1}{k(k-1)} \sum_{\substack{i \neq j \\ i,j \in \{1,\dots,k\}}} \left( \mathcal{L}_{\text{rot}}(i,j) + \lambda_{\text{trans}} \cdot \mathcal{L}_{\text{trans}}(i,j) \right)Lrel-pose=k(k−1)1i=ji,j∈{1,…,k}∑(Lrot(i,j)+λtrans⋅Ltrans(i,j))
其中旋转损失和平移损失分别为:
Lrot(i,j)=∥log(R^ijTRij)∥,Ltrans(i,j)=∥t^ij−tij∥\mathcal{L}_{\text{rot}}(i,j) = \left\| \log(\hat{\mathbf{R}}_{ij}^T \mathbf{R}_{ij}) \right\|, \quad \mathcal{L}_{\text{trans}}(i,j) = \left\| \hat{\mathbf{t}}_{ij} - \mathbf{t}_{ij} \right\|Lrot(i,j)= log(R^ijTRij) ,Ltrans(i,j)= t^ij−tij
R^ij\hat{\mathbf{R}}_{ij}R^ij 和 Rij\mathbf{R}_{ij}Rij 分别是预测和GT的帧 iii 到帧 jjj 的相对旋转。
设计原理:相对位姿损失为滑窗内的帧间几何关系提供直接监督。绝对位姿损失只约束每帧在全局坐标系下的位姿,而相对位姿损失额外约束了帧与帧之间的相对几何——这减少了短距离内的累积误差,确保局部轨迹的精确性。
4.2 两阶段训练策略
| 阶段 | 模型结构 | 训练帧数 | 输入类型 | 训练开销 | 目的 |
|---|---|---|---|---|---|
| Stage 1 | 离线模型,Global Attention | 2-24 views | 有序+无序 | 160k iters, ~21,500 GPU hrs | 学习可靠的局部几何估计 |
| Stage 2 | 在线模型,Global Attn→GCA,滑窗16-64随机 | 24-320 views逐步递增 | 有序 | 160k iters, ~15,360 GPU hrs | 学习全局一致性和流式推理 |
总训练开销:~36,860 GPU hours
为什么需要两阶段?
Stage 1先用短序列、全局注意力训练,让模型先掌握单帧到多帧的几何推理基本功(深度估计、位姿预测),不被GCA的复杂注意力模式干扰。这一阶段使用无序和有序数据混合训练,增强模型对任意视角组合的鲁棒性。
Stage 2再引入GCA机制和长序列,让模型逐步学会流式推理和长程一致性。训练帧数从24逐步增加到320,滑窗大小从16到64随机采样。逐步增加序列长度的策略(curriculum learning)确保模型能稳定适应越来越长的输入。
4.3 训练超参数
| 参数 | 设置 |
|---|---|
| ViT骨干 | DINOv2 ViT-Large预训练 |
| Transformer层数 | 24层交替帧内/跨帧注意力 |
| 优化器 | AdamW |
| 学习率调度 | 10−610^{-6}10−6 预热→ 2×10−42 \times 10^{-4}2×10−4 →余弦退火 |
| 输入分辨率 | 518×378518 \times 378518×378 |
| 锚帧数 nnn | 3 |
| 滑窗大小 kkk | 训练时 {16,17,…,64}\{16, 17, \ldots, 64\}{16,17,…,64} 随机采样 |
| 数据增强 | 亮度、对比度、饱和度、色相随机扰动;随机缩放裁剪 |
| 深度损失正则 α\alphaα | 见论文Appendix |
| 位姿损失权重 λabs-pose,λrel-pose,λtrans\lambda_{\text{abs-pose}}, \lambda_{\text{rel-pose}}, \lambda_{\text{trans}}λabs-pose,λrel-pose,λtrans | 见论文Appendix |
4.4 ViT骨干:DINOv2预训练
设计原理:DINOv2通过自监督的蒸馏目标学习视觉表征,其特征天然编码了语义和几何的对应关系——相似的视觉模式(如不同视角下的同一物体)在特征空间中彼此靠近。这种特性对3D重建中的特征匹配、深度估计等任务具有极佳的迁移性,远优于ImageNet分类预训练。
五、推理策略
5.1 关键帧选择
并非所有帧都添加到记忆中。系统根据光流阈值选取关键帧:
is_keyframe(t)={Trueif flow(It,Itprev)>τflowFalseotherwise\text{is\_keyframe}(t) = \begin{cases} \text{True} & \text{if } \text{flow}(I_t, I_{t_{\text{prev}}}) > \tau_{\text{flow}} \\ \text{False} & \text{otherwise} \end{cases}is_keyframe(t)={TrueFalseif flow(It,Itprev)>τflowotherwise
光流计算方式:利用推理得到的pose和depth直接计算相对于最近关键帧的光流,而非传统2D光流跟踪:
u(x)=π(Rtπ−1(x,Dt(x))+tt)−x\mathbf{u}(\mathbf{x}) = \pi\left(\mathbf{R}_t \pi^{-1}(\mathbf{x}, D_t(\mathbf{x})) + \mathbf{t}_t\right) - \mathbf{x}u(x)=π(Rtπ−1(x,Dt(x))+tt)−x
设计原理:3D光流比2D光流跟踪更准确——它直接利用已恢复的3D几何信息,在遮挡、弱纹理等退化情况下仍能可靠计算运动量。
5.2 两种推理模式
| 模式 | 支持帧数 | 原理 | 优缺点 |
|---|---|---|---|
| Direct Output Mode | ~3000帧 | 常规序列化推理,历史帧不断累积 | 简单但有累积误差 |
| Visual Odometry Mode | 理论无限 | 分段推理+重叠帧Sim(3)对齐 | 支持超长序列,但存在子图匹配误差 |
Visual Odometry Mode的Sim(3)对齐流程:
- 将长视频分为多个重叠段(相邻段有 ooo 帧重叠)
- 每段独立推理得到子地图
- 利用相邻段的重叠帧,求解最优相似变换 Sim(3)\text{Sim}(3)Sim(3):(s,R,t)(s, \mathbf{R}, \mathbf{t})(s,R,t)
mins,R,t∑i∈overlap∥sRXi(1)+t−Xi(2)∥2\min_{s, \mathbf{R}, \mathbf{t}} \sum_{i \in \text{overlap}} \left\| s\mathbf{R}\mathbf{X}_i^{(1)} + \mathbf{t} - \mathbf{X}_i^{(2)} \right\|^2s,R,tmini∈overlap∑ sRXi(1)+t−Xi(2) 2
- 将所有子图对齐到统一坐标系
5.3 推理性能
| 指标 | 数值 |
|---|---|
| 分辨率 | 518×378518 \times 378518×378 |
| 处理速度 | ~20 FPS |
| 最大序列长度 | 10,000+帧稳定运行 |
| GPU显存 | 相比全注意力方案降低~73倍 |
六、实验结果

6.1 评测基准
| 类别 | 数据集 | 评测指标 |
|---|---|---|
| 室内 | ScanNet, ScanNet++, Replica | ATE, RPE, 深度误差 |
| 室外 | MegaDepth, KITTI-360 | ATE, RPE |
| 大规模 | TartanAir, MatrixCity | ATE, RPE |
| 边缘情况 | MapFree | 位姿精度 |
6.2 消融实验
三层记忆缺一不可:
| 配置 | ATE↓ | RPE↓ |
|---|---|---|
| 完整GCA | ✓ | ✓ |
| 去掉锚帧 | ✗ | 坐标系漂移严重 |
| 去掉滑窗 | ✗ | 局部精度显著下降 |
| 去掉轨迹记忆 | ✗ | 长序列累积漂移大增 |
GCA vs 其他注意力模式:
| 注意力模式 | 精度 | Token数(T=10000) |
|---|---|---|
| Full Attention | 最高 | ~506万 |
| Causal Attention | ~GCA持平 | ~506万 |
| Sliding Window | 局部好、长程差 | ~8万 |
| GCA | ≈Causal | ~6.95万 |
GCA以Causal Attention约1/73的token数量达到了几乎相同的精度。
七、局限性与未来方向
7.1 局限性
- 摘要token仅6个/帧,对超长序列(数万帧)可能丢失细粒度几何细节
- 不执行test-time optimization,在困难场景下无法进一步提升
- 主要针对静态场景,动态场景支持有限
7.2 未来方向
- 引入束调整(bundle adjustment)优化和显式回环检测
- 扩展到动态场景
- 融合多模态输入(LiDAR、IMU)
- 作为下游任务骨干(新视角合成、导航等)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)