Loop Engineering 与 Harness Engineering:AI 工程范式的完整演进
1. 起源与背景:从 Prompt 到 Loop 的四阶段演进
2022 到 2026 年,AI 工程实践经历了四次清晰的范式跃迁。每一次跃迁都将"人在系统中的角色"向更高的抽象层推进,同时将更多的执行细节交给基础设施。这四个阶段分别由不同的关键人物在不同时间点推动进入大众视野:
- 2022~2024:Prompt Engineering,核心问题是"我该对模型说什么"。
- 2025 年 6 月:Context Engineering,由 Shopify CEO Tobi Lütke 推动流行,核心问题变成"该给模型看什么信息"。
- 2026 年 2 月:Harness Engineering,由 Mitchell Hashimoto(HashiCorp 创始人)在博客文章 “My AI Adoption Journey” 中首次系统提出,核心问题升级为"该围绕模型造什么系统"。
- 2026 年 6 月:Loop Engineering,由 Boris Cherny(Claude Code 创造者)演讲 + Peter Steinberger 推文 + Addy Osmani 博客三点共振引爆,核心问题变成"怎么让这个系统自己跑起来"。
下图展示了这条完整的演进路线,每个阶段对应着人机协作抽象层级的一次提升:
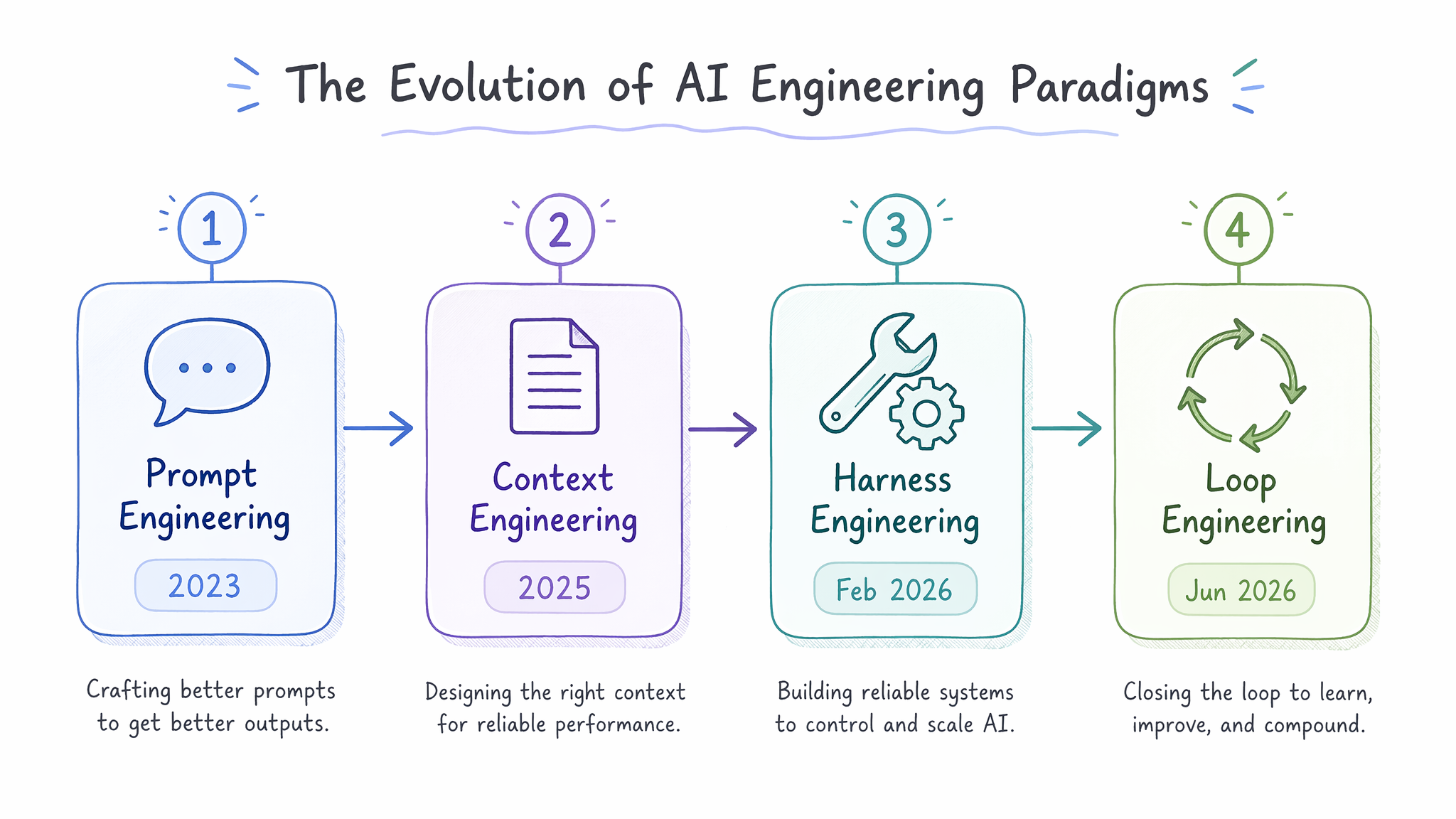
演进路线解读:
- Prompt Engineering(2022~2024):人逐条编写指令,模型单轮响应。核心技巧是 few-shot、chain-of-thought、system prompt 模板化。人是"打字员"——每次交互都需要人触发。开发者的工作量线性于任务数量:10 个任务需要 10 次手动 prompt。
- Context Engineering(2025):重点转向"如何把正确的上下文喂给模型"。出现了
CLAUDE.md、AGENTS.md、VISION.md等持久化上下文文件,把项目约定、架构规则、代码规范存在磁盘上,模型每次启动自动加载。人的角色升级为"上下文策展人"。Anthropic 2025 年 9 月正式发布 Context Engineering 最佳实践。 - Harness Engineering(2026 年 2 月):重点从"信息输入"扩展到"整个运行环境"。不仅管上下文,还管工具集成、输出验证、错误处理、重试逻辑、权限边界。人的角色变成"系统架构师"——造一辆车(发动机、刹车、安全气囊都装好)。
- Loop Engineering(2026 年 6 月):在 Harness 之上加了一层"自驱动能力"——系统不再等人按启动键,它自己发现工作、执行、验证、记忆、进入下一轮。人的角色变成"循环架构师"——给车装上自动驾驶。
关键转变:Prompt Engineering 的 ROI 是"一次交互的质量";Context Engineering 的 ROI 是"跨交互的一致性";Harness Engineering 的 ROI 是"单次运行的可靠性";Loop Engineering 的 ROI 是"无人值守的持续产出"。
2. Harness Engineering:模型之外的一切
2.1 最原始的定义
2026 年 2 月 5 日,Mitchell Hashimoto 在其博客文章 “My AI Adoption Journey” 中写道自己日常工作的模式变化——"always have an agent running"占到每天 10~20% 的时间,而他的核心工作变成了"engineer the harness"来防止 Agent 重复同样的错误。虽然他没有给出一个标准化的学术定义,但他的实践描述催生了这个概念的广泛讨论。
两周内,Martin Fowler(Thoughtworks 首席科学家,《重构》作者)在 2026 年 4 月 2 日发表了长文 “Harness Engineering for Coding Agent Users”,给出了最被广泛引用的定义框架:
“Agent = Model + Harness.”
“Harness means everything in an AI agent except the model itself.”
OpenAI 在 2026 年 2 月 11 日也发表了官方文章 “Harness Engineering: Leveraging Codex in an Agent-first World”,从平台方视角确认了这个概念。
Firecrawl 团队进一步归纳了实践原则:
“Harness engineering treats every agent failure as an engineering problem to permanently fix, rather than a prompt to retry.”
这是一个非常重要的态度转变——以前 Agent 出错了,你改 prompt 重试;现在 Agent 出错了,你修改 harness 的结构,确保这类错误结构性地不可能再发生。
2.2 Harness 的双层架构
MindStudio 团队将 Harness 分为内层和外层两个部分。Martin Fowler 则用控制论语言将其描述为 Guides(前馈控制) 和 Sensors(反馈控制)。下图展示了这个双层结构:
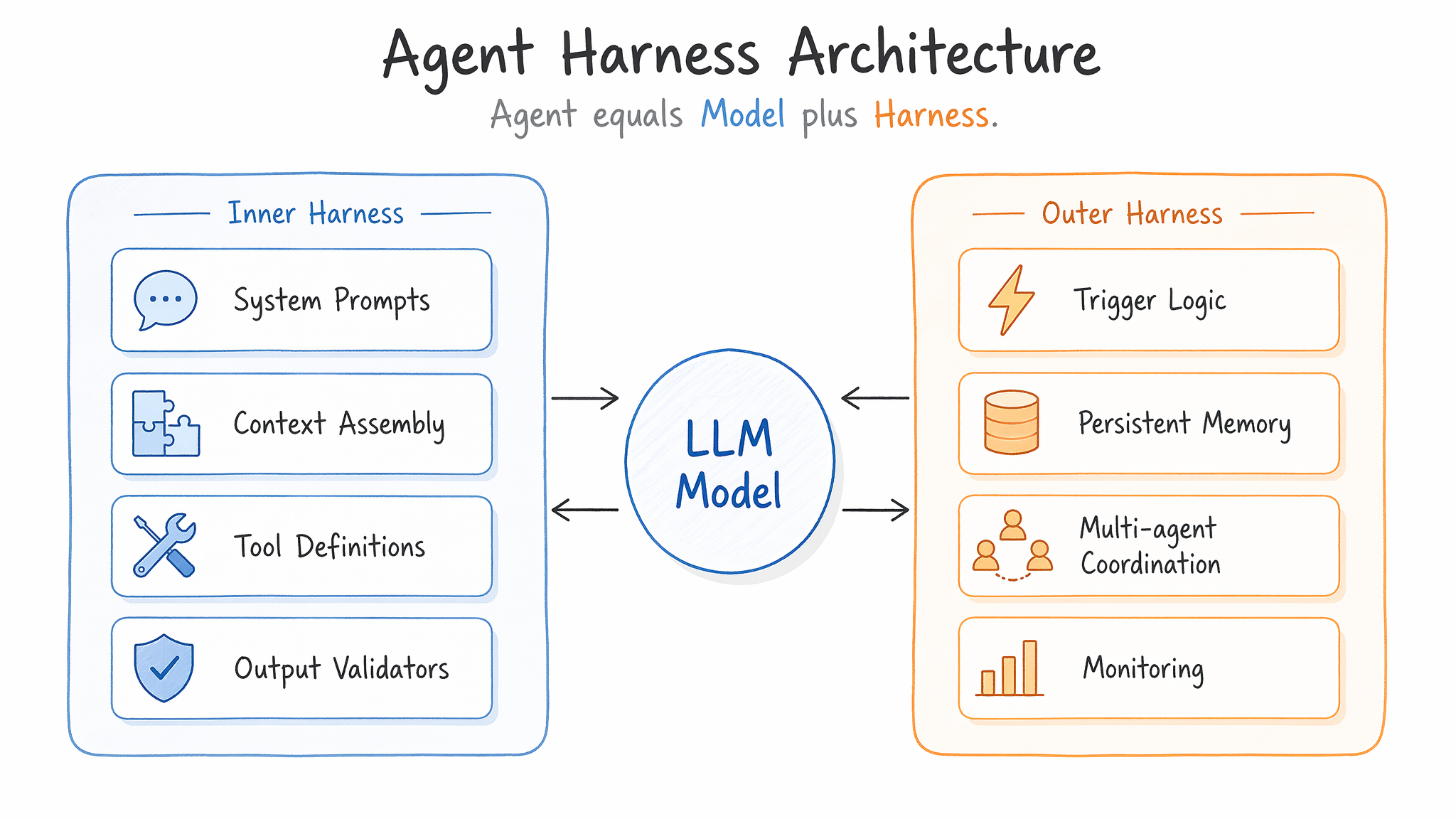
Inner Harness(内层 Harness)——直接包裹模型的组件:
- System Prompts:定义 Agent 的角色、行为边界、输出格式要求。不同于简单的 prompt engineering,harness 里的 system prompt 是可版本化、可 diff、可 CI 测试的工程产物。
- Context Assembly:上下文组装逻辑——决定把项目中哪些文件、哪些历史对话、哪些外部数据喂进 context window。这是 Context Engineering 的成果被 Harness 正式编码的位置。
- Tool Definitions:Agent 可以调用哪些工具、每个工具的 schema 是什么、调用频率限制是多少。工具集是 Harness 赋予 Agent 能力的核心方式。
- Output Validators:对模型输出的结构化校验——JSON schema 验证、安全规则检查(如"不能 rm -rf")、业务逻辑断言(如"PR title 必须以 feat:/fix: 开头")。
- Retry Logic:模型输出不合格时的重试策略——最大重试次数、退避策略、是否换 model、是否追加 error context。
Outer Harness(外层 Harness)——管理 Agent 运行生命周期的组件:
- Trigger Logic:什么事件触发 Agent 启动——cron、webhook、CI failure、人工命令。
- Routing:多 Agent 场景下,哪个任务分配给哪个 Agent。
- Persistent Memory:跨 session 的状态存储——
MEMORY.md、向量数据库、结构化 TODO 列表。 - Multi-agent Coordination:Agent 之间如何协作——共享 worktree、消息传递、锁机制。
- Monitoring & Observability:Agent 运行的日志、token 消耗、成功率、延迟指标。
# 一个完整 Harness 的配置示例(概念性)
harness:
inner:
system_prompt: ./prompts/engineer.md
context:
always_include: [CLAUDE.md, AGENTS.md, src/architecture.md]
dynamic: {strategy: "relevant_files", max_tokens: 8000}
tools: [read_file, write_file, bash, grep, git]
validators:
- type: json_schema
schema: ./schemas/tool_output.json
- type: security_rules
rules: [no_rm_rf, no_force_push, no_env_read]
retry: {max_attempts: 3, backoff: exponential}
outer:
trigger: {type: cron, schedule: "0 9 * * *"}
memory: {backend: file, path: ./MEMORY.md}
monitoring: {log_level: info, token_budget: 100000}
2.3 Martin Fowler 的控制论视角
Martin Fowler 用**控制论(Cybernetics)**的框架来理解 Harness。他把 Harness 的组件分为两类:
- Guides(前馈/Feedforward):在 Agent 执行之前提供方向。包括 coding conventions 文件、architecture decision records、structural tests(如"所有 API endpoint 必须有对应的 integration test")。Guides 的作用是"预防性地减少错误空间"。
- Sensors(反馈/Feedback):在 Agent 执行之后检测偏差。包括 linters、mutation testing、AI judges(用另一个 LLM 来评估输出质量)、type checker。Sensors 的作用是"事后发现并纠正偏差"。
这个分类方式揭示了 Harness Engineering 的深层逻辑:它不是简单的"给 Agent 加规则",而是设计一个控制系统——通过前馈减少错误发生的概率,通过反馈在错误发生后及时纠正。好的 Harness 让 Agent 在一个"高护栏、窄车道"的环境中运行,自由度刚好够完成任务,但不够犯严重错误。
关键洞察:Harness Engineering 的核心隐喻是"Agent 的运行环境不是一个空旷的平原,而是一条有护栏的高速公路"。你造的不是 Agent 本身(那是模型厂商的事),你造的是这条高速公路——路面(工具)、护栏(验证器)、导航系统(上下文)、加油站(记忆)、收费站(权限边界)。
3. Harness vs Loop:到底什么区别?
这是社区争论最激烈的话题。在深入调研后,结论如下:Harness 是 Loop 的实现基础;Loop 是 Harness 加上自驱动能力后的运行状态。二者不是替代关系,而是层叠关系。下图用一个直观的比喻展示了这种关系:
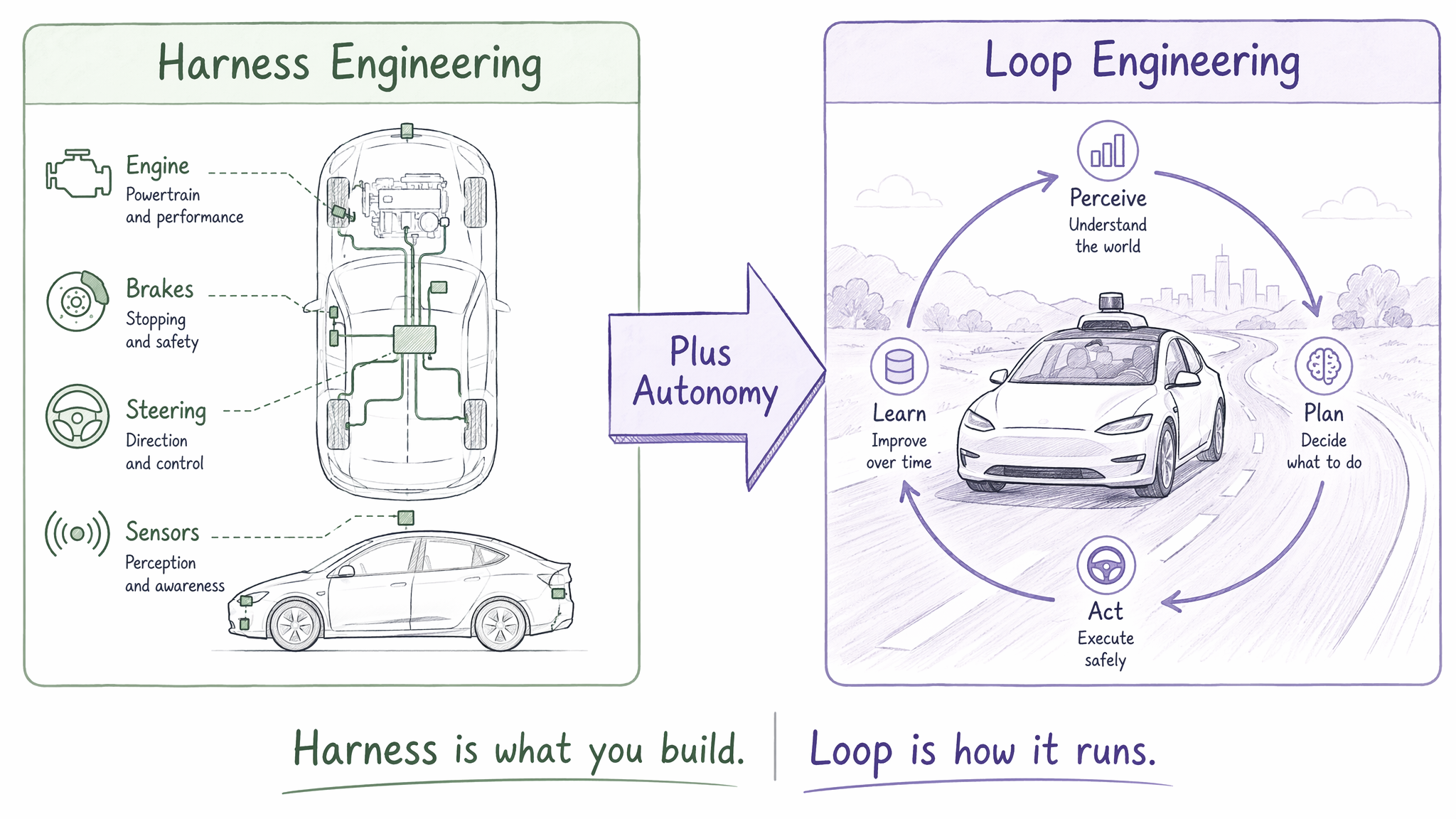
结构性对比:
| 维度 | Harness Engineering | Loop Engineering |
|---|---|---|
| 核心问题 | “围绕模型该造什么系统?” | “怎么让这个系统自己跑起来?” |
| 首次提出 | Mitchell Hashimoto, 2026 年 2 月 5 日 | Boris Cherny / Peter Steinberger, 2026 年 6 月 |
| 系统性文章 | Martin Fowler, 2026 年 4 月 2 日 | Addy Osmani, 2026 年 6 月 7 日 |
| 关注焦点 | 基础设施设计(工具、验证、权限、重试) | 自治循环设计(触发、终止、记忆、并行) |
| 人的角色 | 系统架构师(造车) | 循环架构师(给车装自动驾驶) |
| 运行模式 | 按需触发,人按"启动" | 自驱动,cron/event 触发后自主循环 |
| 隐喻 | 造一辆装备精良的车 | 让这辆车自动驾驶 |
| 没有它会怎样 | Agent 在空旷平原上乱跑 | Agent 需要人每次手动启动 |
为什么社区经常把它们混为一谈?
因为在实践中,你不可能只有 Harness 而没有 Loop,也不可能只有 Loop 而没有 Harness。一个"能自己跑的 Agent"必然需要工具、验证、权限、记忆这些 Harness 组件;同时一个"装备精良的 Harness"自然会演化出自动触发和循环的需求——谁想每次手动按启动键呢?
bits-bytes-nn 的演进分析文章直接指出:
“Loop engineering is not a distinct era; it refers to the agent’s execution cycle controlled by the harness.”
也就是说,Loop 是 Harness 控制下的运行时行为。Harness 定义了"车怎么造",Loop 定义了"车怎么开"。你写的 AGENTS.md 是 Harness 的一部分;你设置的 cron job + /goal 终止条件是 Loop 的一部分。但它们作用于同一个 Agent 系统。
一个更精确的表述:
“Prompting is about how we ask. Context engineering is about what we show. Harness engineering is the broader discipline that decides the full operating environment in which the model works. Loop engineering is the specific pattern of making that environment self-driving.”
如果用软件工程的类比:Harness Engineering 对应"系统架构设计",Loop Engineering 对应"部署为 daemon/cron service"。你先要有一个设计良好的系统(Harness),然后才能让它以无人值守的方式运行(Loop)。
4. 核心定义:什么是 Loop Engineering
在理解了 Harness 的基础后,Loop Engineering 的定义就更清晰了。Addy Osmani 给出的定义:
“Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead.”
Mem0 团队从工程角度进一步定义:
“Loop engineering is the practice of designing, implementing, and tuning the control loop that governs how an AI agent interacts with its environment over time.”
本质上,Loop Engineering 是在 Harness 之上加了一层自驱动控制——它让 Harness 不再需要人来每次按"开始",而是自己发现工作、执行工作、观测结果、更新记忆、进入下一轮。这个反馈环的每一轮包含 6 个阶段。下图展示了这个生产级 Agent Loop 的 6 阶段架构:
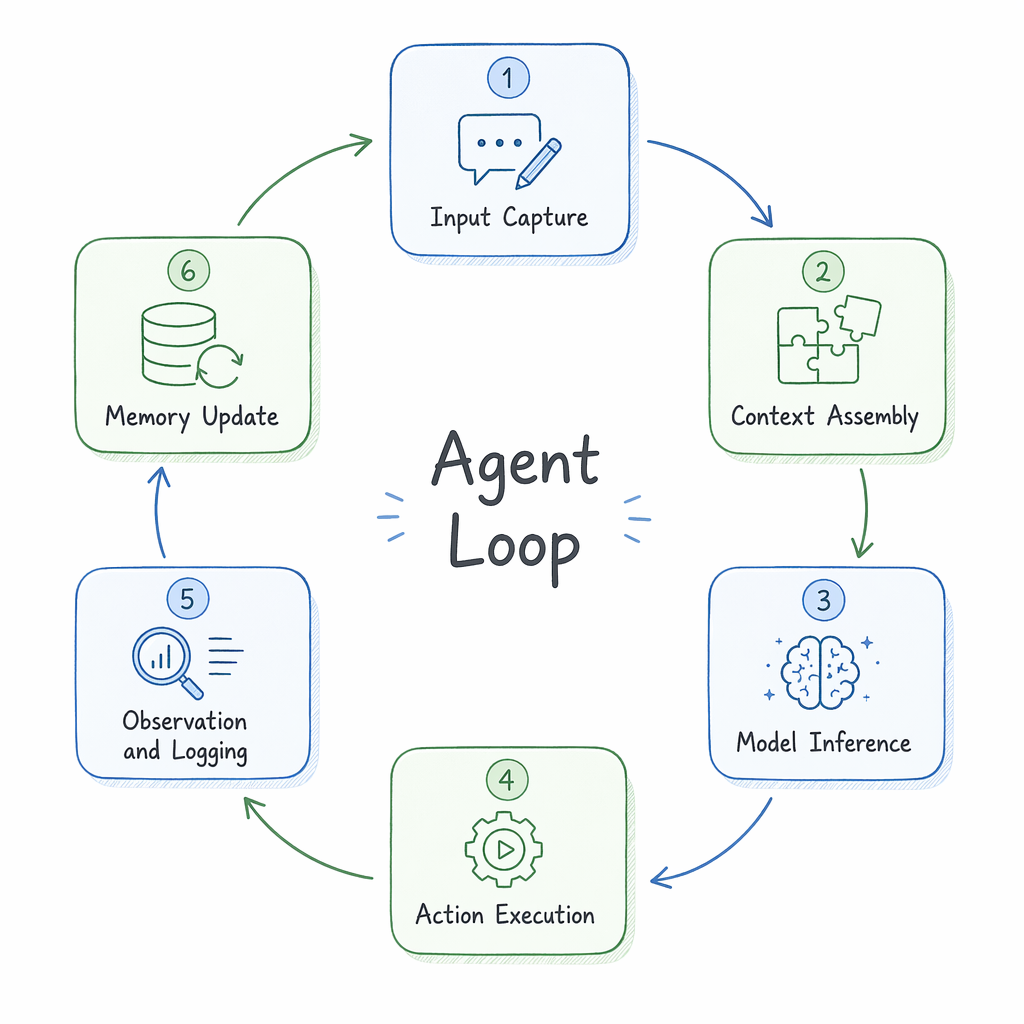
6 阶段逐项解读(结合上图中的每个节点):
- Input Capture(输入捕获):Loop 的触发点。可以是定时任务(cron 触发发现新 issue)、事件监听(CI 失败通知)、或上一轮 Loop 的输出(“还有 3 个文件未处理”)。核心是让 Loop 自己找到"下一件要做的事",而不是等人来告诉它。这一步属于 Outer Harness 的 Trigger Logic。
- Context Assembly(上下文组装):根据当前任务从磁盘文件(
CLAUDE.md、VISION.md、项目代码)、向量索引、或上一轮的 summary 中提取相关上下文。关键设计决策:记忆存磁盘不存 context window——因为模型每次 run 之间会完全遗忘。这一步属于 Inner Harness。 - Model Inference(模型推理):将组装好的 context 连同 task description 发给 LLM,获取结构化输出(tool call、code patch、decision)。区别于传统 Prompt Engineering——prompt 是 Harness 自动生成的,不是人写的。
- Action Execution(动作执行):Agent 根据模型输出执行实际动作——写文件、跑测试、调 API、开 PR。这里需要 Harness 的 tool definitions 和 sandbox 隔离来确保安全。
- Observation & Logging(观测记录):捕获 action 的结果——测试通过了吗?CI 绿了吗?API 返回了什么?将结果结构化记录。这一步对应 Harness 中的 Sensors。
- Memory Update(记忆更新):将本轮学到的信息写回持久存储——更新 todo list、标记 issue 为 resolved、在
MEMORY.md中追加经验。属于 Outer Harness 的 Persistent Memory。
设计取舍:为什么是 6 阶段而不是简单的"think → act"二步?因为如果不显式分离"组装上下文"和"更新记忆",Agent 会陷入两种退化:一是每轮都从零开始理解项目(没有记忆),二是 context window 爆满导致遗忘关键信息(没有主动裁剪)。6 阶段结构让每一步都可独立调试、优化、添加 Harness 组件。
5. 五大构建模块:Loop 的组成零件
Addy Osmani 在框架中提出了 Loop 的五大构建模块(Five Pieces)——它们既是 Harness 的组件,也是 Loop 自驱动所依赖的积木。下图展示了这五个模块的分工和定位:
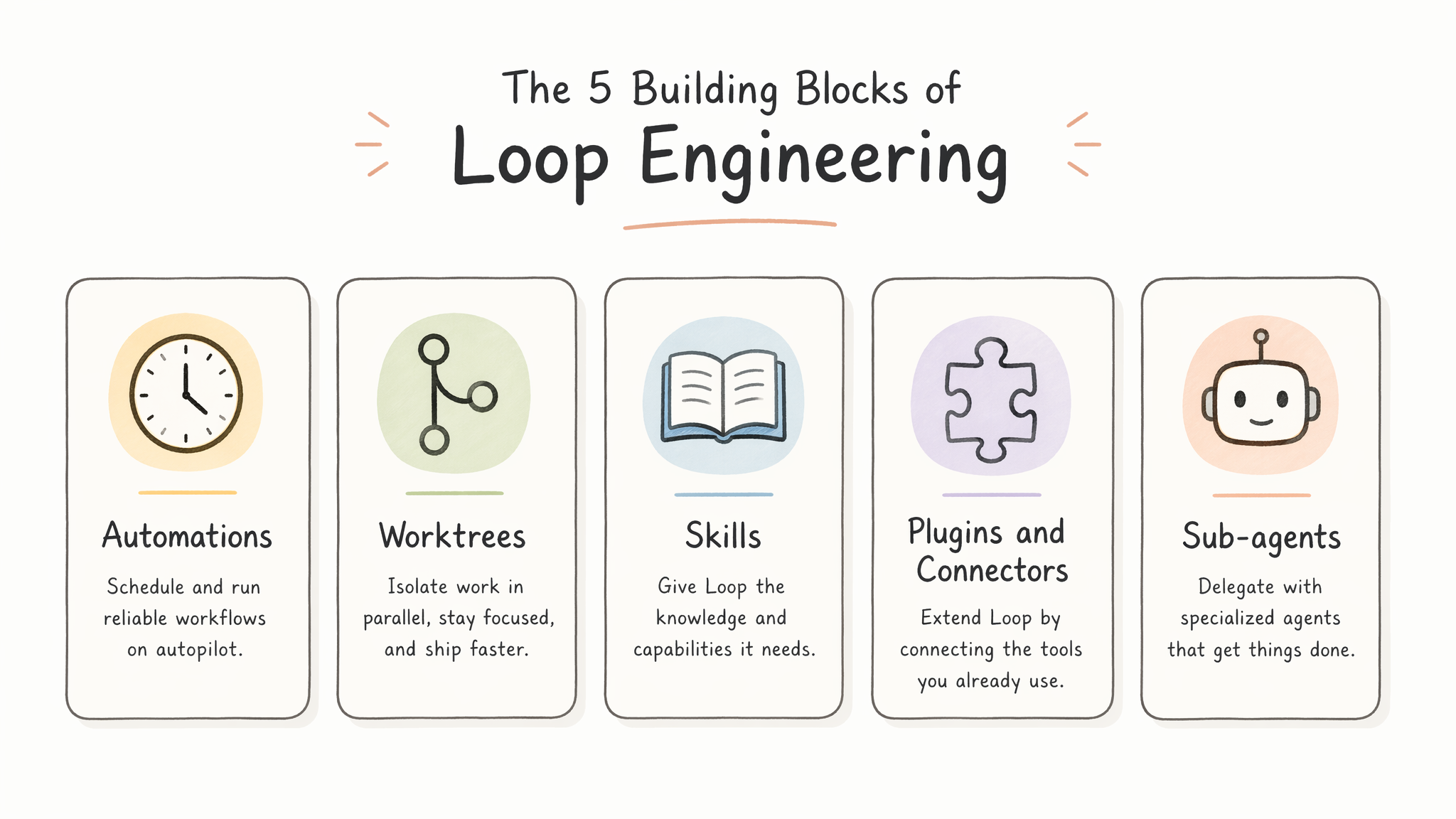
五大模块逐一剖析:
-
Automations(自动化触发器):定义 Loop 何时启动、以什么频率运行、达到什么条件停止。典型实现是
/goal命令——设定一个"run-until-done"的目标条件(如"所有 CI 测试通过"),系统自动循环直到满足或超时。这是 Loop 区别于 Harness 的关键组件——Harness 可以没有 automation(手动触发),但 Loop 必须有。 -
Worktrees(工作隔离):使用
git worktree或内置文件隔离机制,确保多个并行 Agent 不会在同一文件上冲突。每个 Agent 在自己的 worktree 中执行修改,完成后通过 PR 合入主分支。这属于 Harness 中的基础设施组件。 -
Skills(技能文件):即
SKILL.md类的项目约定文档。存储团队的编码规范、架构规则、部署流程等隐性知识。Agent 启动时加载这些文件,确保生成的代码符合团队约定。这属于 Harness 的 Guides(前馈控制)——在 Agent 执行前提供方向。 -
Plugins/Connectors(外部连接器):通过 MCP(Model Context Protocol)等协议让 Agent 能与外部系统交互——Linear 看任务、Slack 发通知、GitHub 开 PR。这属于 Harness 的 Tool Definitions。
-
Sub-agents(子代理):将大任务拆分给不同角色的专用 Agent。典型模式是在
.codex/agents/或.claude/agents/目录下定义多个 agent 配置(TOML/JSON),分别指定 explorer、implementer、verifier 等角色。
# .claude/agents/verifier.toml 示例
[agent]
name = "verifier"
role = "Code review and test execution"
tools = ["bash", "read_file", "grep"]
system_prompt = """
You are a code reviewer. Run tests, check for regressions,
and report pass/fail with specific line references.
Never modify files directly.
"""
模块间的协作关系:一个典型的生产 Loop 把五大模块串联——Automation 定时触发 → 在隔离的 Worktree 中启动 Sub-agent → Sub-agent 加载 Skills 理解项目约定 → 通过 Connector 从 Linear 拉取 issue → 实现代码 → 另一个 Sub-agent(verifier)review → 通过 Connector 开 PR 并通知 Slack。这里面前四个模块(Worktrees/Skills/Connectors/Sub-agents)都是 Harness 组件,只有 Automation 是 Loop 特有的——它让整个流水线自动运转。
6. Maker-Checker 分离:Loop 的质量保障模式
Boris Cherny 和 Addy Osmani 都强调了一个关键设计模式:写代码的 Agent 和验证代码的 Agent 必须分离。这被称为 Maker-Checker Split(制造-检验分离),其动机来自金融行业的"四眼原则"。在 Martin Fowler 的 Harness 框架里,这对应于 Sensors 和 Guides 的分离——Maker 受 Guides 指导,Checker 充当 Sensor 检测偏差。下图展示了这种双 Agent 互检的工作模式:
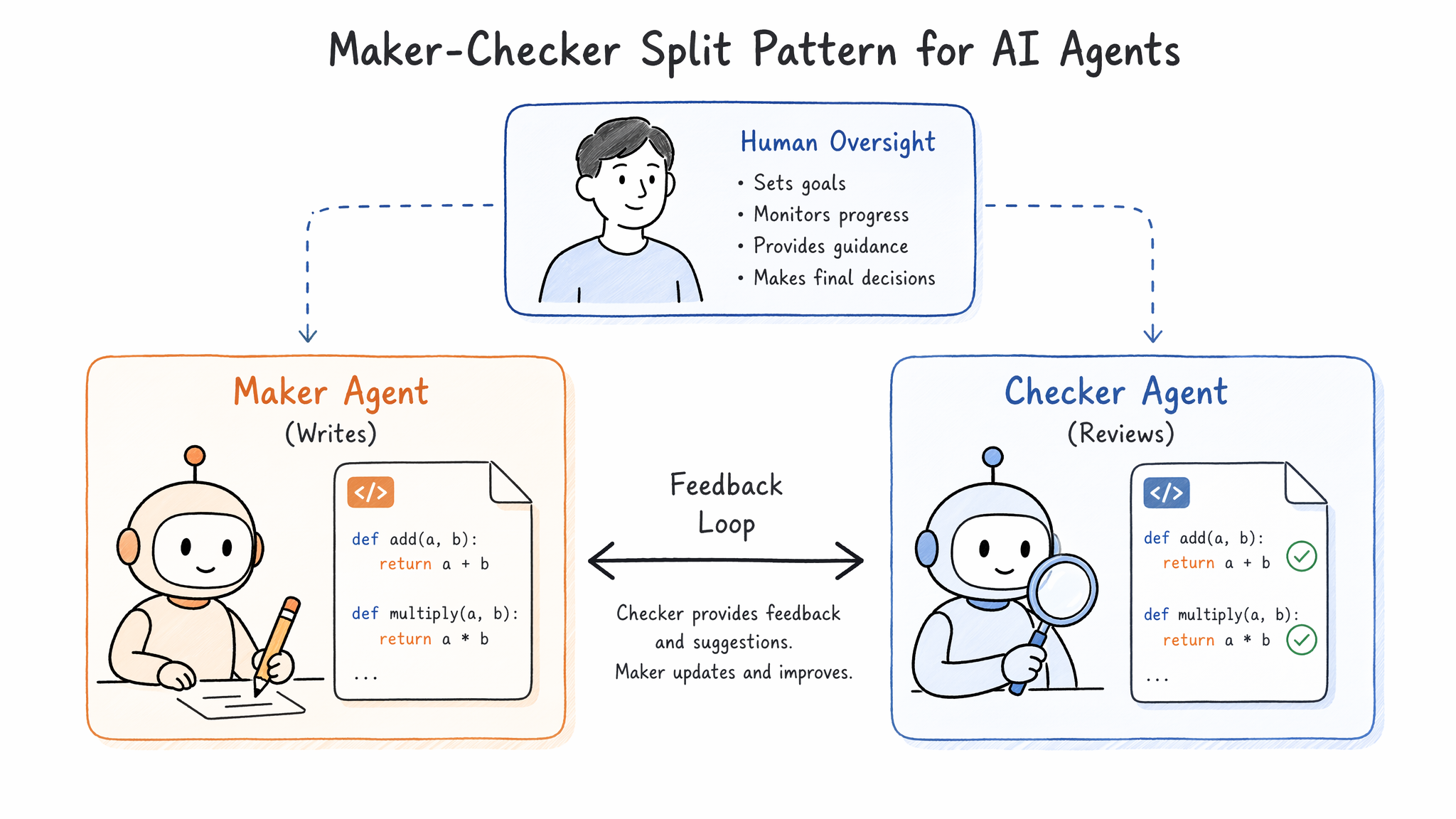
Maker-Checker 工作流详解:
- Maker Agent:负责"做"——读取 issue 描述 → 理解需求 → 编写代码 → 提交到 worktree 的 feature branch。它有
write_file、bash(用于运行 build)等写权限,但不能自己合入主分支。Harness 通过 tool 白名单约束了它的能力边界。 - Checker Agent:负责"验"——拉取 Maker 的 diff → 运行完整测试套件 → 静态分析 → 逐行 review。它有
read_file、bash(只用于跑测试)、grep等只读 + 测试权限,没有 write_file 权限。这是 Harness 的权限边界在起作用。 - 反馈路径:Checker 发现问题时,将具体的 line-level comment 写回给 Maker,Maker 修复后重新提交。这个内循环可能跑 2~3 轮——这就是一个微型 Loop。
- 人的兜底:当反复 3 轮仍未达成一致,Loop 升级给人类审阅。
# 伪代码:Maker-Checker Loop 的核心逻辑
MAX_ITERATIONS = 3
for i in range(MAX_ITERATIONS):
patch = maker_agent.implement(issue, feedback=checker_feedback)
result = checker_agent.review(patch, test_suite=project_tests)
if result.approved:
open_pull_request(patch)
break
else:
checker_feedback = result.comments # 传回下一轮
else:
escalate_to_human(issue, patch, result.comments)
设计取舍:为什么不让一个 Agent 自检?实验表明,同一个 LLM 实例倾向于对自己的输出"自圆其说"。分离后,Checker 没有"沉没成本偏差"。另一个好处是 Harness 层面的权限最小化——Checker 物理上没有写文件的能力,即使被 jailbreak 也无法篡改代码。
7. 并行 Loop 工作流:Boris Cherny 的实战模式
Boris Cherny 在演讲中展示了他的日常工作方式:同时运行 5 个终端实例,每个终端里跑一个 Claude Code 的 agent loop,各自处理不同的任务。它们共享一个 CLAUDE.md 文件作为全局语义记忆(这是 Harness 的 Persistent Memory 组件),避免 context window 溢出。人的角色从"写 prompt"变成了"运维 5 条 pipeline"。下图展示了这种并行 Loop 的架构:
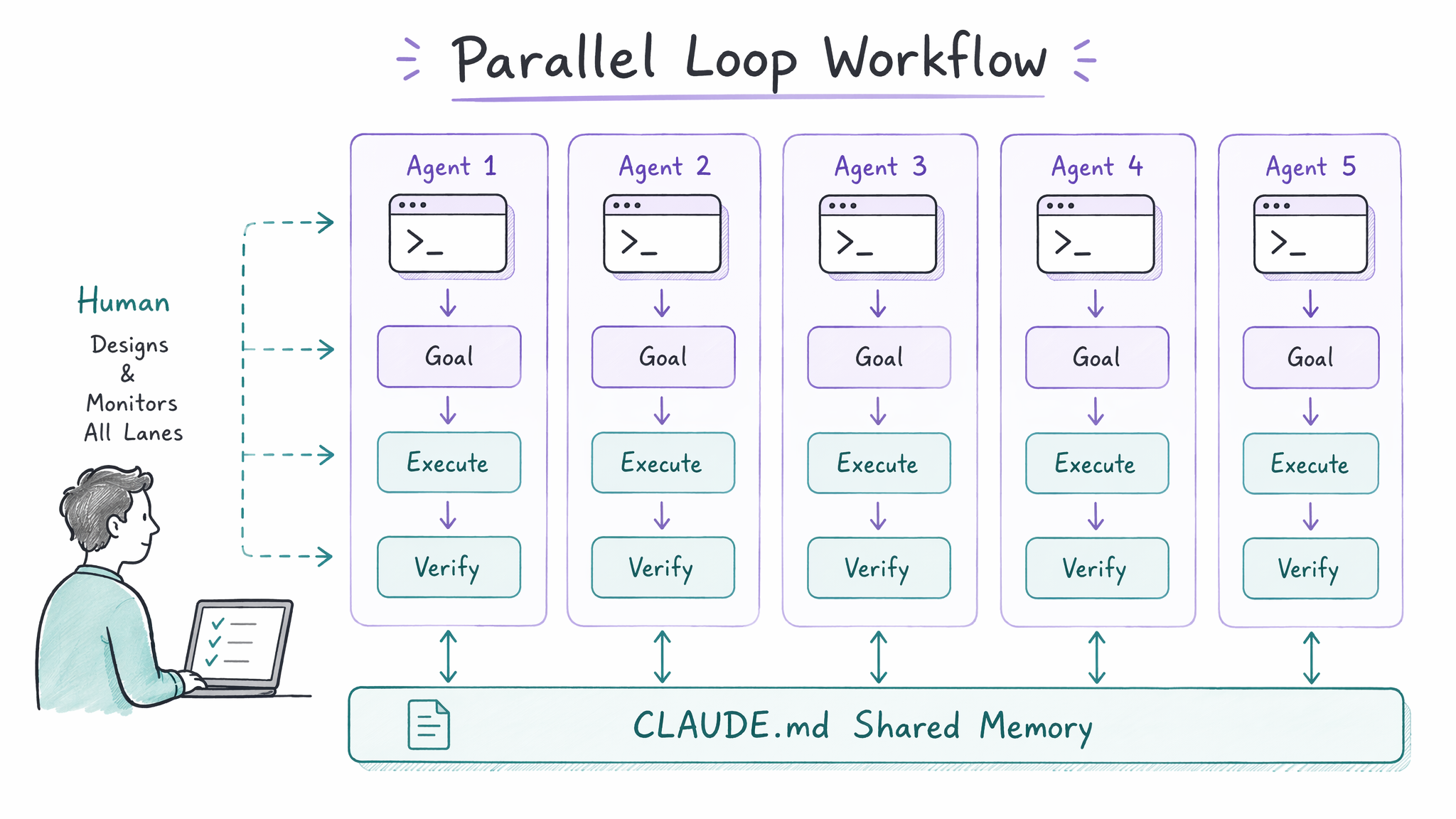
并行模式的关键设计要素:
- CLAUDE.md 作为共享记忆层:Addy Osmani 明确指出"The model forgets everything between runs so the memory has to be on disk and not in the context"。这个文件是 Harness 的 Persistent Memory 组件被所有 Loop 共享的实例。
- Worktree 物理隔离:5 个 Agent 分别在 5 个 git worktree 中工作,互不干扰。这是 Harness 的基础设施隔离在 Loop 并行化场景下的具体应用。
- Goal-driven 终止条件:每个 Agent 被赋予一个明确的
/goal。达到 goal 后自动停止。如果 30 分钟内没有进展,超时退出并报告现状。终止条件是 Loop 的核心——没有它,Harness 再完善也只能人工停止。 - 人作为交通管制员:人不参与具体的代码编写,而是负责分配任务、监控异常、做最终 merge 决策。
# Boris Cherny 的典型 session 示例
# Terminal 1: 修复认证 bug
claude --goal "Fix failing auth tests in test_auth.py" --worktree fix-auth
# Terminal 2: 重构 API 层
claude --goal "Refactor /api/v2 endpoints per RFC-42" --worktree refactor-api
# Terminal 3: 文档更新
claude --goal "Update API docs to match current implementation" --worktree docs-sync
# Terminal 4: 依赖升级
claude --goal "Upgrade React to v19, fix all type errors" --worktree deps-upgrade
# Terminal 5: Performance 优化
claude --goal "Reduce cold start time below 200ms" --worktree perf-coldstart
关键技巧:防止"Intent Debt"。如果只给 Agent 一句"fix the bug",它会自己猜测项目的上下文和约定——这就是 Intent Debt。解决方案是 Harness 层面的:把所有隐性知识编码进 CLAUDE.md 和 skill 文件中(Harness 的 Guides),Agent 无需猜测就能理解项目约定。
8. 三大风险:Loop 的反噬隐患
Loop Engineering 不是银弹。Addy Osmani 在文章中特别警告了三个可能反噬开发者的风险。当 Loop 越来越自主时,人类面临的真正危险不是 Agent 做错事,而是人自己退化。下图将这三个风险概念可视化:
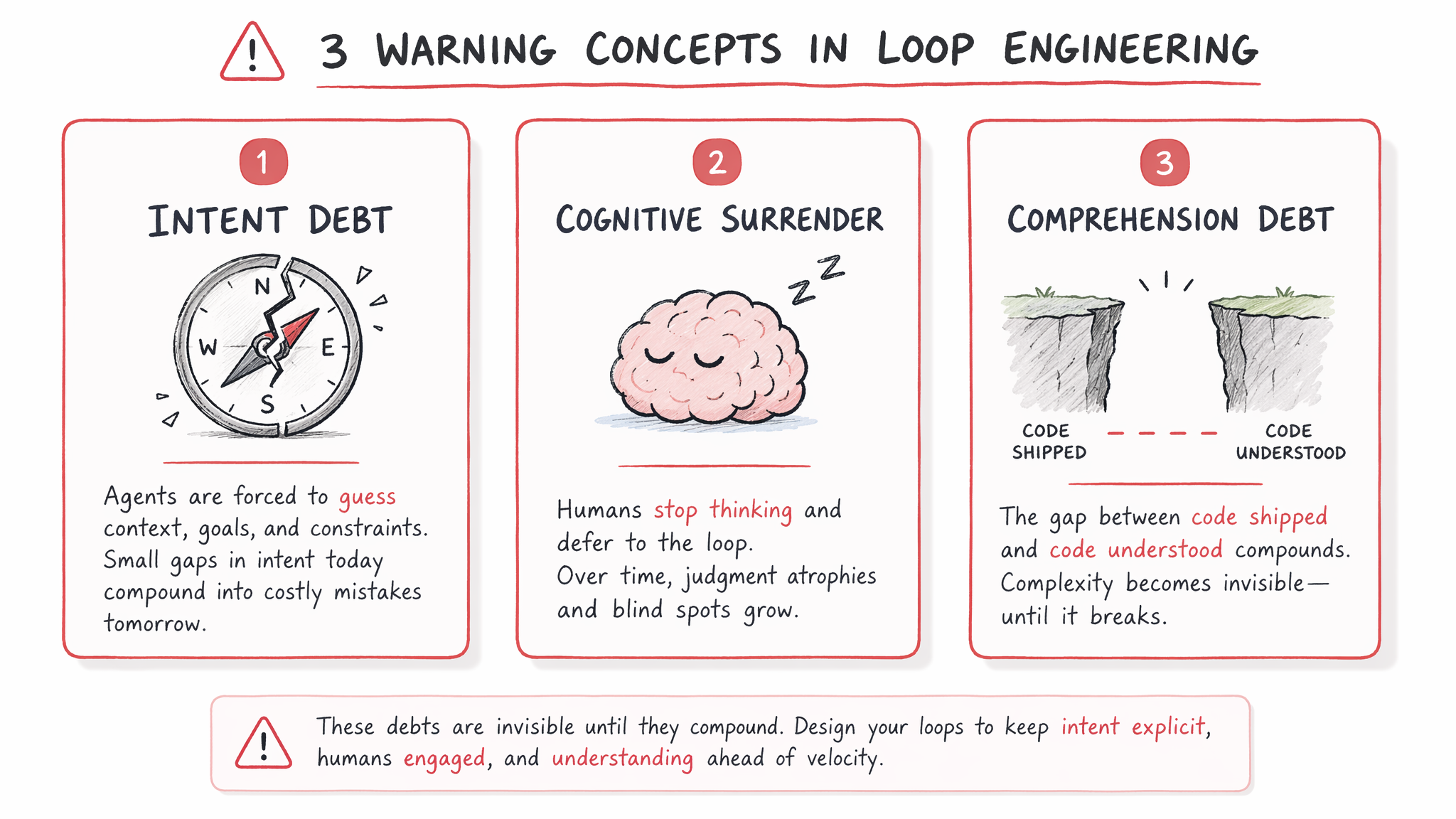
三大风险逐项剖析:
-
Intent Debt(意图负债):当 Agent 缺乏明确的项目上下文时,它不会停下来问你——它会猜测。每次猜测都累积一笔"负债"。对策是 Harness 层面的:用
VISION.md编码项目长期目标,用CLAUDE.md编码规范和架构边界,用 skill 文件编码特定流程。这本质上是"Harness 不够完善导致 Loop 产出偏差"——好的 Harness 是防止 Intent Debt 的根本手段。 -
Cognitive Surrender(认知投降):当 Loop 稳定运行了几周,你开始"不再有自己的技术观点"。Addy Osmani 的原话是:“The danger is stopping having an opinion when loops run autonomously.” 对策:定期强制自己做 design review,对每个 PR 回答"如果这是一个人写的我会不会同意"。这个风险是 Loop 特有的——Harness 不会导致 Cognitive Surrender,因为 Harness 需要你手动触发,你还在 loop 里。
-
Comprehension Debt(理解负债):Loop 可以一天帮你 ship 20 个 PR,但你真正理解其中几个?代码库里有 30% 的代码你从未仔细看过。对策:设定"理解率门槛"——每天至少花 1 小时读 Agent 产出的代码;对关键路径坚持 manual review。同样是 Loop 特有风险——只有自动化运行的系统才会产出你来不及理解的大量代码。
Addy Osmani 的总结忠告:
“Build the loop. But build it like someone who intends to stay the engineer, not just the person who presses go.”
9. 总结:一张图看清全貌
最终,这四个"Engineering"并非互相替代,而是层层叠加的——每一层都依赖内层的存在,但各自关注不同维度的工程问题。下图用嵌套结构展示了这种层叠关系:
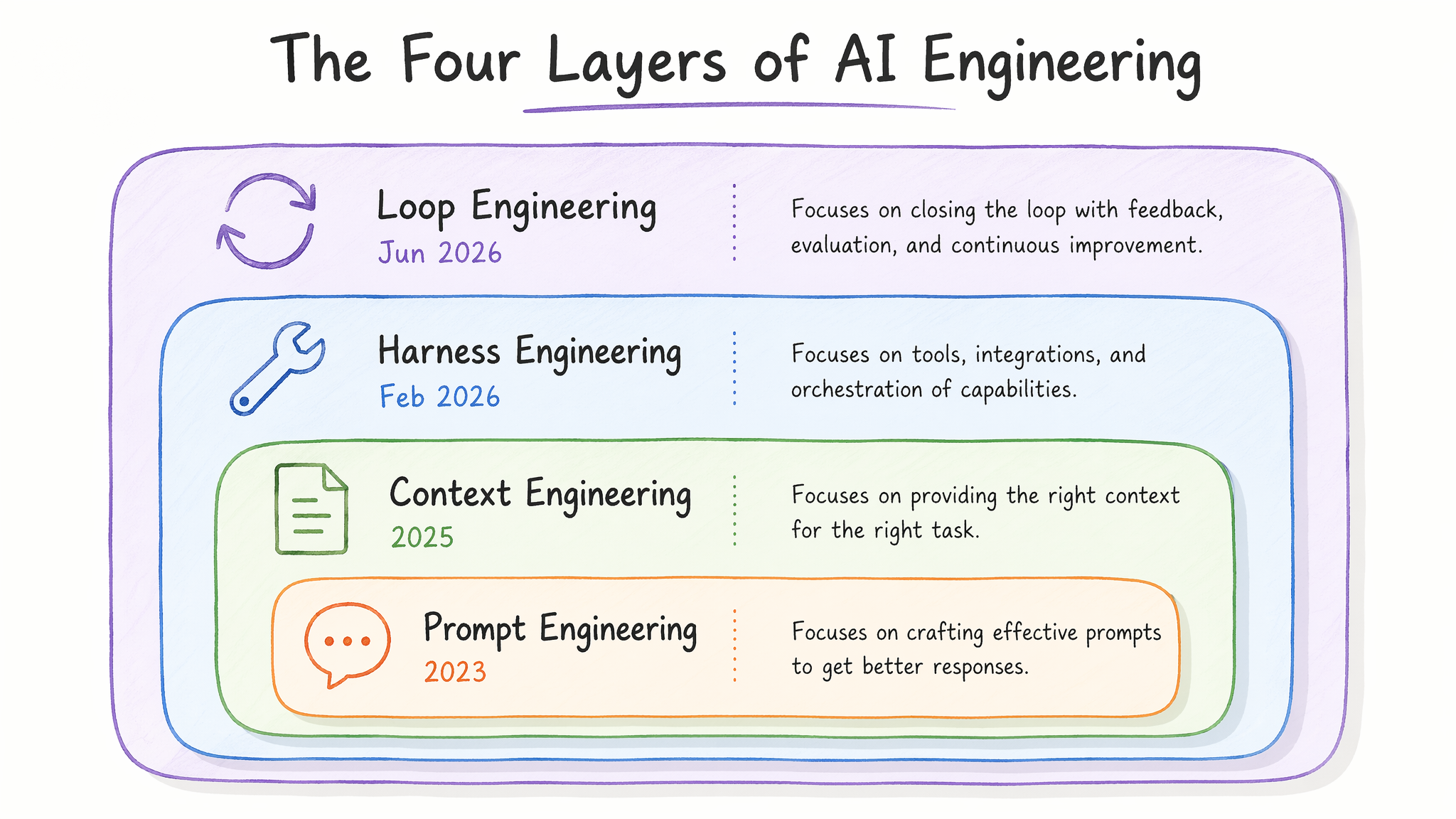
层叠关系逐层解读:
- 最内层 · Prompt Engineering(2023):定义了"你对模型说什么"——few-shot、chain-of-thought、指令措辞。这是所有后续层级的基础:没有好的 prompt 设计,再多的 Harness 和 Loop 也只会放大低质量输出。但 Prompt 本身不解决"信息从哪来"和"系统怎么跑"的问题。
- 第二层 · Context Engineering(2025):定义了"模型看到什么信息"——
CLAUDE.md、向量检索、上下文裁剪策略。Prompt 只影响单次交互的质量,Context 影响的是跨交互的一致性和完整性。它是 Harness 中 Context Assembly 组件的前身。 - 第三层 · Harness Engineering(2026.02):定义了"系统怎么造"——工具集、验证器、权限边界、重试逻辑、监控系统。这一层不关心"系统是否自动运行",只关心"当系统运行时,它是否可靠、安全、可控"。Mitchell Hashimoto 的核心贡献是把这个层级的思考显式化了。
- 最外层 · Loop Engineering(2026.06):定义了"系统怎么自己跑"——自动触发、目标驱动、记忆持久化、并行调度。这一层假设 Harness 已经存在且可靠,它的工作是在 Harness 之上加自驱动能力。Boris Cherny 的贡献是展示了 Loop 在真实工作中的形态:5 个终端、共享记忆、goal 驱动、自动终止。
你不需要在 Harness Engineer 和 Loop Engineer 之间"选一个"——你需要的是先做好 Harness(可靠的基础设施),再在其上加 Loop(自主运行的能力)。没有 Harness 的 Loop 就是一辆没装刹车的自动驾驶车——它会自己跑,但无法保证不撞墙。没有 Loop 的 Harness 就是一辆停在车库里的好车——装备精良,但需要你每次亲自开。
真正的 AI 工程师在 2026 年做的事:造一辆装备精良的车(Harness),然后让它自动驾驶(Loop),同时确保自己还记得怎么开车(防 Cognitive Surrender)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 13
13 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)