智能提取 + 自定义提取 - 确保精准非结构化文档数据提取
在日常工作中,你是否经常遇到这些场景:
- 收到几十份发票,需要手动逐张录入发票号、金额、日期……
- 客户的合同堆积如山,关键条款只能一份份翻阅摘录
- 报关单、订单、保单等文档格式不一,人工提取费时费力还容易出错
这些重复性的数据录入工作,不仅消耗大量人力,还极易因疲劳导致差错。ComPDF AI 的 智能文档抽取 功能,正是为解决这类痛点而生——基于语义理解、NLP 及 Key-Value Pair(KVP)技术,精准识别并抓取文档关键信息,高效转化为结构化数据。
为什么要关注非结构化文档的数据提取?
据 IBM 统计,企业生成的数据中约 80%~90% 为非结构化数据——PDF 文件、Word 文档、邮件、扫描件、图片等。这些数据虽然信息丰富,但由于没有预定义的格式和 schema,无法像数据库中的结构化数据那样直接用于分析和处理。
传统做法是人工录入,效率低、易出错。而 OCR(光学字符识别) 虽然能识别图片中的文字,但只能"看到"字符,无法理解内容的含义和上下文关系。
从传统 OCR 到 AI 驱动的智能文档处理(IDP),核心区别在于:
| 对比维度 | 传统 OCR | AI 智能提取 |
|---|---|---|
| 工作方式 | 文字识别 | 语义理解 + 关键信息定位 |
| 输出内容 | 纯文本/可搜索 PDF | 结构化键值对(KVP) |
| 上下文理解 | 无 | 基于 NLP 理解文档语境 |
| 版式适配 | 依赖固定模板 | 灵活适配不同排版 |
| 输出格式 | TXT/Word | JSON/Excel/CSV |
| 系统集成 | 需二次开发 | 直连 RPA/ERP/CRM |
ComPDF AI 的智能文档抽取正是 AI 驱动的 IDP 解决方案,而非简单的 OCR 工具。
两种提取方式,覆盖标准与特殊文档
AI 驱动的文档数据精准提取,通常遵循以下标准化流程,确保AI自动化数据提取的准确性:
-
文档接入:上传 PDF、图片、扫描件等多种格式文件
-
自动分类:AI 识别文档类型(发票、合同、订单等),自动匹配或推荐模板
-
智能提取:基于 NLP + KVP 技术,精准定位并提取关键字段
-
人工核对:提供可视化校验界面,用户可编辑修正提取结果
-
数据输出:导出为 JSON / Excel / CSV,或直接推送至业务系统
ComPDF AI 的智能文档抽取功能完整覆盖上述流程,从上传到输出结构化数据,全程高效闭环。
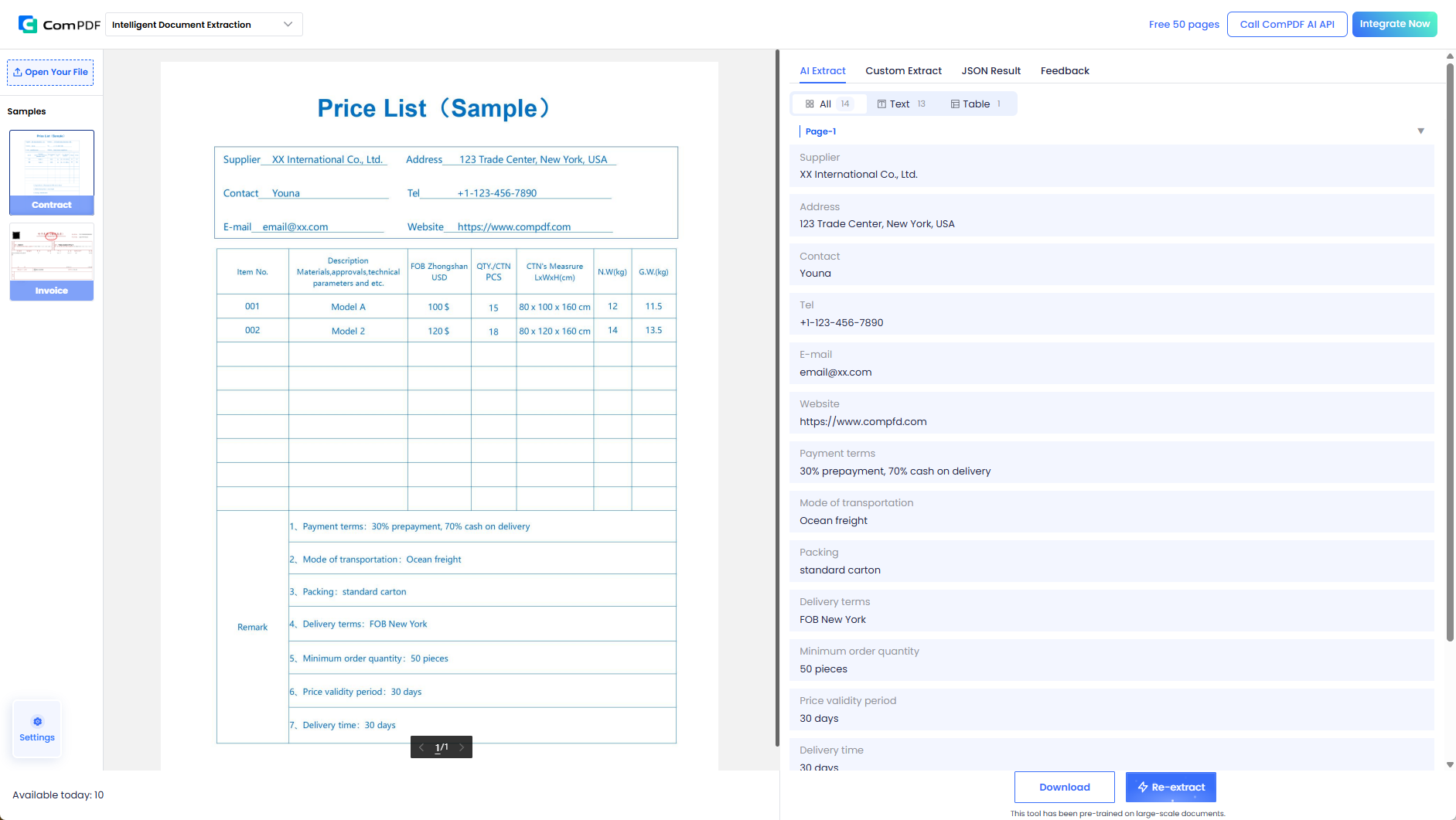
1. 智能提取:上传即用,AI 自动识别
智能文档抽取的核心在于开箱即用。你只需:
步骤 1:进入智能文档抽取
从 ComPDF AI 首页或左侧边栏点击「智能文档抽取」,即可进入功能页面。左侧模板列表中,系统内置了订单和发票两种常用模板,覆盖大部分商务场景。
步骤 2:上传文件并自动提取
上传一份或多份文件后,系统会根据你选择的模板自动执行提取。如果未选择任何模板,系统会智能识别文件类型,匹配最合适的模板进行提取——无需手动配置,真正实现"上传即用"。
步骤 3:核对与确认
提取完成后,点击「去核对」进入核对页面。左侧为原始文件,右侧为提取的结构化数据,左右对照一目了然。你还可以直接编辑修正,或添加新字段。确认无误后,可一键下载为 JSON、Excel 或 CSV 格式,直接对接企业系统。
适用场景:发票识别录入、订单信息归档、保单关键字段提取、证件信息采集等标准化文档的数据自动化处理。
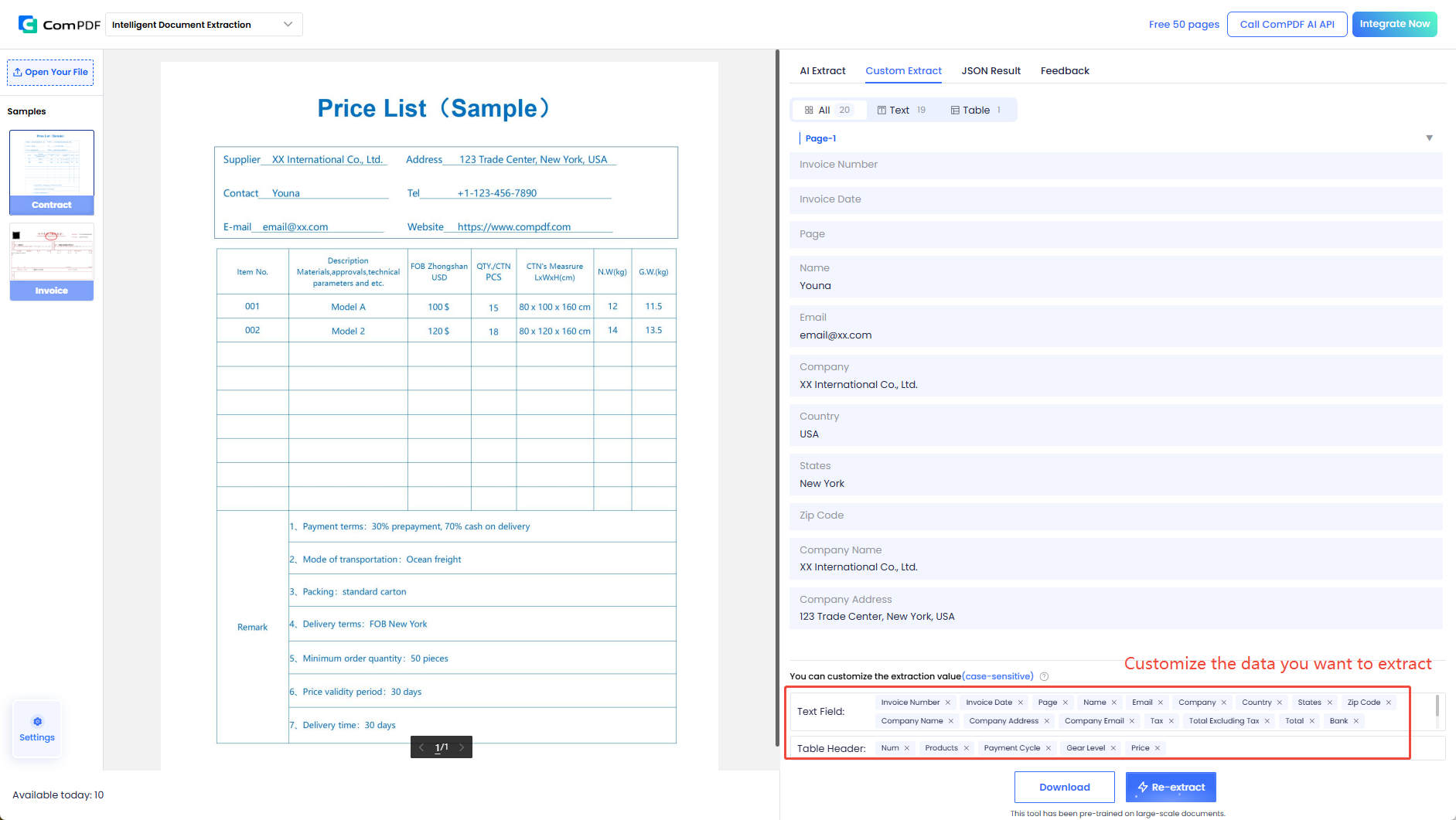
2. 自定义提取:灵活配置,应对非标文档
如果你的文档类型比较特殊(如内部报表、特定格式的合同、行业专用单据等),ComPDF AI 也支持自定义模板——点击「选择模板」→「新增模板」,即可根据自己的需求配置提取字段。
通过自定义模板,你可以:
- 指定要提取的键值对字段:如合同编号、签约日期、甲方名称、金额等
- 灵活适配不同版式:即使同一类文档排版不同,也能准确提取
- 团队共享:创建的模板可复用,团队成员一键调用
自定义模板让 ComPDF AI 不仅是"标准文档提取器",更能适应各行各业特殊需求——无论是物流行业的提单、金融行业的对账单、医疗行业的病历摘要、还是法律行业的卷宗材料,都可以通过自定义模板精准提取所需信息。
提取后的数据,还能这样用
提取出的结构化数据(JSON/Excel/CSV)可以:
- 无缝对接 RPA、ERP、CRM 等系统,实现数据自动录入
- 作为数据中台输入源,支撑后续分析与决策
- 批量导出归档,建立可检索的结构化数据库
- 为 AI 大模型提供高质量语料,支持 RAG(检索增强生成),让知识库问答更加精准
为什么选择 ComPDF AI?——传统 OCR 与 AI 智能提取的对比
| 对比维度 | 传统 OCR | ComPDF AI 智能提取 |
|---|---|---|
| 工作方式 | 文字识别(只“看”字符) | 语义理解 + 关键信息定位 |
| 输出内容 | 纯文本 / 可搜索 PDF | 结构化键值对(KVP) |
| 上下文理解 | 无 | 基于 NLP 理解文档语境 |
| 版式适配 | 依赖固定模板 | 灵活适配不同排版 |
| 输出格式 | TXT / Word | JSON / Excel / CSV |
| 系统集成 | 需二次开发 | 可便捷对接 RPA / ERP / CRM |
结语
从传统 OCR 到 AI 驱动的智能文档处理,从人工逐字录入到机器自动提取,从标准化模板到自定义配置——ComPDF AI 让企业非结构化文档的数据提取变得简单、精准、高效。在这个数据驱动的时代,把重复劳动交给 AI,把时间还给更有价值的工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)