Vue 102 ,AI 大模型流式输出踩坑实录:Markdown 不换行、符号裸露的真相( AI大模型流式输出前端渲染混乱 )
目录
前言
一、问题背景
1.1 需求长什么样
1.2 第一版实现
1.3 糊成一坨具体是什么样
二、排查过程(含两次错误判断)
2.1 第一次误判:以为是 markdown-it 配置问题
2.2 第二次误判:以为是流式渲染时机问题
2.3 关键一步:把每个分片原样打出来
2.4 定位根因:SSE 协议把换行吃掉了
三、解决方案
3.1 治本:后端对内容做 JSON 序列化
3.2 前端的 SSE 解析要写对
3.3 渲染策略:整体渲染,别对分片单独渲染
3.4 对比:问题解决前后效果对比图
四、注意事项与避坑清单
五、本文总结
六、更多操作

前言
最近在做大模型对话这个需求,我以为最难的部分是流式输出的打字机效果,结果真正把我卡住的,是一个看起来特别 "小" 的问题 ——AI 返回的内容在页面上糊成了一大坨。
标题不换行、列表项首尾相连、加粗 的星号直接裸露在文字里、表格的竖线散落得到处都是。整个回答堆成密密麻麻的一整段,没有任何排版结构。
一开始我笃定是前端 Markdown 渲染的问题,围着 markdown-it 的配置改了一天,又写了一堆正则去 "修复"文本,折腾了三天,效果时好时坏。直到我把每一个数据分片打印出来,才发现问题压根不在前端—— 是后端在 SSE 传输时把换行符给丢了。
这篇文章我想完整复盘这次排查,包括我中途几个错误的判断方向。因为我相信,比起直接给一个能用的方案,把 "怎么一步步确认问题真正出在哪" 讲清楚,更有参考价值。技术栈是 Vue3 + markdown-it,但思路和具体技术无关,React 同样适用。
SSE 流式返回的 Markdown 全糊在一起,我是怎么一步步定位到后端的 / 前端接大模型流式输出踩坑实录:Markdown 不换行、符号裸露的真相 / AI 大模型流式输出在前端 Markdown 渲染成一坨?我排查了很久,最后发现根本不在前端

一、问题背景
1.1 需求长什么样
业务侧要在一个管理系统里嵌一个 AI 问答助手,交互形态参考主流的对话产品:用户提问,AI 的回答逐字蹦出来,带打字机效果,回答内容支持 Markdown 格式(标题、列表、表格、代码块这些)。
后端提供的是一个 SSE(Server-Sent Events)流式接口,POST 请求,multipart/form-data 提交(因为要支持带文件提问)。响应是标准的 SSE 事件流,大致长这样:
event:session
data:5c7d9a0af2a141a0b1e6247f8537a168
event:message
data:你好
event:message
data:!我是信息化项目管理系统的
event:message
data:AI 分析助手
event:end
data:[DONE]
session 事件返回会话 ID,message 事件是一个个文本片段,end 表示结束。前端要做的,就是把这些 message 片段拼起来,渲染成带格式的回答。
1.2 第一版实现
因为是 POST + multipart,原生的 EventSource 用不了(它只支持 GET,也没法带 body),所以我用 fetch 拿到 ReadableStream,自己解析 SSE。核心逻辑就是边读边拼,每拼一段就丢给 markdown-it 重新渲染一次:
const reader = response.body.getReader()
const decoder = new TextDecoder('utf-8')
let buffer = ''
while (true) {
const { done, value } = await reader.read()
if (done) break
buffer += decoder.decode(value, { stream: true })
const lines = buffer.split('\n')
buffer = lines.pop() ?? ''
for (const line of lines) {
if (line.startsWith('data:')) {
const text = line.slice(5)
if (text === '[DONE]') continue
markdownText.value += text // 拼接
}
}
}
模板里直接 v-html 渲染:
<div v-html="md.render(markdownText)"></div>
逻辑上没毛病。但跑起来,回答就是糊成一坨的。
1.3 糊成一坨具体是什么样
我把实际渲染出来的效果贴一下,大概是这种感觉(已脱敏):
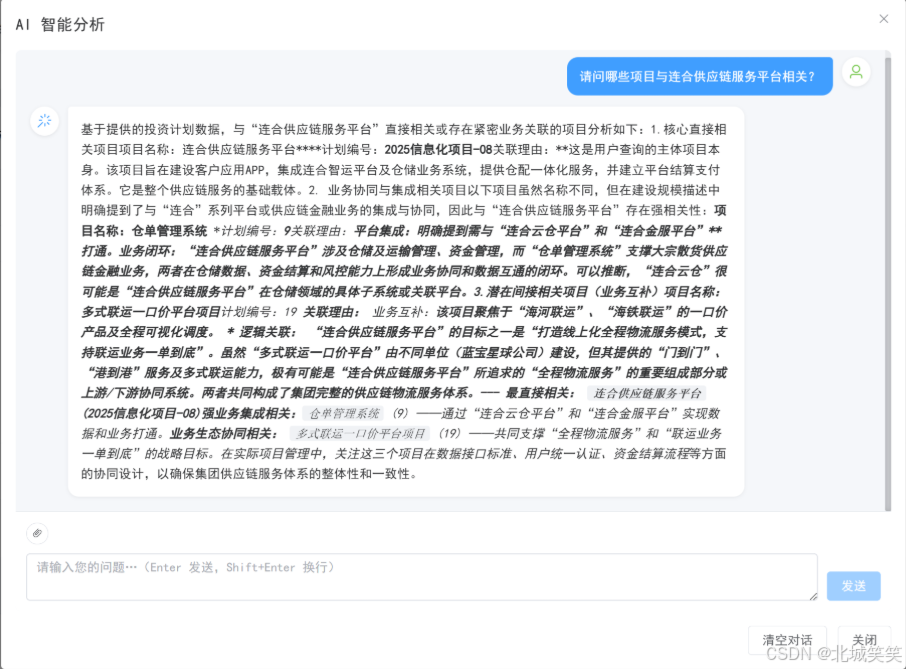
你看,# 后面紧跟着标题文字,标题和正文之间没有断开;** 这种加粗标记直接以纯文本形式露出来;列表项 -项目申请 和前面的内容黏在一起。markdown-it 收到这么一串东西,自然解析不出任何结构,原样吐出来了。
二、排查过程(含两次错误判断)
这部分是我觉得最值得写的。因为我前两个方向都判断错了,走了不少弯路,但这些弯路恰恰是定位问题的必经之路。
2.1 第一次误判:以为是 markdown-it 配置问题
最直觉的反应:渲染不对,那肯定是渲染器的问题。
我翻了 markdown-it 的文档,把 breaks、html、linkify 这些选项挨个试了一遍。breaks: true 能让单个换行符渲染成 <br>,我寻思是不是这个没开。开了之后……没用,还是糊的。
这时候我应该警觉的:如果文本里压根没有换行符,那 breaks 开不开都没意义。但当时我没往这想,反而怀疑是不是 markdown-it 版本有 bug,甚至去翻了 issue。
这是第一个教训:渲染器是个纯函数,输入确定,输出就确定。在怀疑渲染器之前,应该先确认喂给它的输入到底长什么样。 我跳过了这一步,直接怀疑工具,方向就偏了。
2.2 第二次误判:以为是流式渲染时机问题
冷静了一下,我换了个思路:是不是因为流式过程中,每来一个分片就渲染一次,分片把 Markdown 语法切碎了?
比如 **加粗** 这五个字符,可能被切成 **加 和 粗** 两个分片。渲染第一个分片时,markdown-it 看到落单的 **,当然没法配对成加粗。
这个判断……其实有一半是对的,分片确实会切碎语法。于是我改成了"流式过程纯文本展示,流结束后再整体渲染一次"。改完之后,流式中间确实是纯文本了,但流结束后的最终渲染,依然是糊的。
这下我懵了。最终渲染是对完整文本做的,不存在切碎问题,怎么还是糊的?
但也正是这次失败,把我逼到了唯一正确的方向上:问题不在渲染时机,而在那段"完整文本"本身就是错的。 我必须去看看,拼接出来的完整文本,到底是什么。
2.3 关键一步:把每个分片原样打出来
我在解析 SSE 的地方加了个临时的调试面板,把每一个 data: 分片,原封不动地(包括空字符串)push 进一个数组,渲染到页面上,每个分片单独一行,用 JSON.stringify 包起来,这样空格、空串、特殊字符都能看清。
// 临时调试用
const debugChunks = ref([])
// 在拿到每个 chunk 的地方
debugChunks.value.push(chunk)
<div v-for="(c, i) in debugChunks" :key="i">
[{{ i }}] {{ JSON.stringify(c) }}
</div>
这一打,真相就出来了。我截取一段当时的输出:
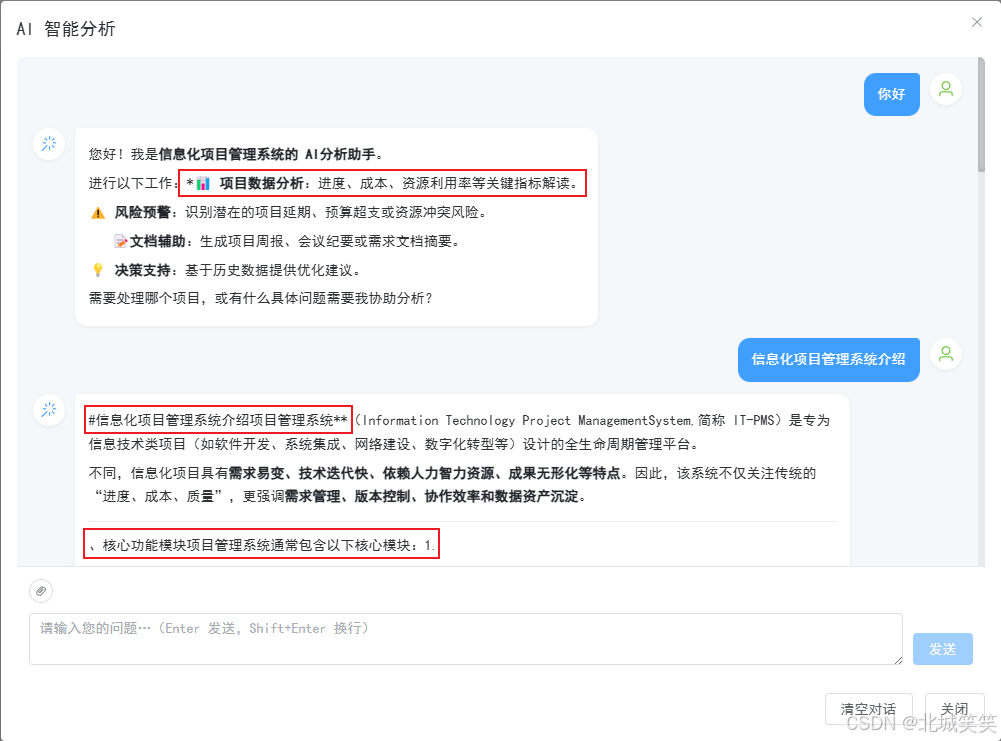
[0] "#"
[1] "信息化项目管理系统"
[2] "介绍"
[3] "项目管理系统**("
[4] "Information Technology Project Management"
[5] "System)"
[6] "是一套专门用于规划"
[7] "、执行、监控"
...
看出问题了吗?每一个分片都是纯文字,没有任何一个分片里包含 \n 换行符。 一个都没有。
# 是一个独立分片,紧接着 信息化项目管理系统 又是一个分片,它俩之间本该有一个换行(Markdown 标题语法 # 标题 之后需要换行才能结束标题),但这个换行符消失了。所有本该存在的 \n 全都不见了。
把这些分片首尾相接拼起来,得到的就是那一串没有任何换行的文本。markdown-it 拿到一串没换行的东西,凭什么解析出标题、列表、表格?它做不到,也不该做到。
2.4 定位根因:SSE 协议把换行吃掉了
为什么换行符会消失?这得从 SSE 协议本身说起。
SSE 是基于文本行的协议,它用 \n(或 \r\n)作为字段的分隔符。一条消息的格式是:
data:这是内容\n
\n
data: 后面跟内容,然后一个 \n 表示这个字段结束,再一个空行 \n 表示整条消息结束。
问题就在这儿:如果你要传的内容本身就包含 \n,直接塞进 data: 后面,这个 \n 会被 SSE 协议当成字段分隔符处理掉,而不是当成内容的一部分。
换句话说,后端如果这么干:
data:第一行\n第二行\n
SSE 在解析的时候,会把它理解成"data 字段是『第一行』,然后字段结束了",后面的第二行要么被忽略,要么被错误处理。内容里的换行,就这么被协议吃掉了。
我们后端当时就是直接把大模型输出的文本(带 Markdown 换行的)塞进 data: 转发出来,换行符在传输过程中全部丢失。前端收到的,自然是一堆没有换行的碎片。
所以这压根不是前端的锅。 前端能做的只有拼接,后端没给的换行,前端凭空变不出来。我前面三天写的那些正则"修复",本质上是在猜——猜哪里该有换行,靠标点、靠 # 开头、靠中文句号去补。但分片是随机切割的,# 可能单独成片,也可能跟后面的字黏在一起,规则永远覆盖不全,所以效果才会时好时坏。
三、解决方案
定位到是后端问题之后,方案就清晰了。这里我把前端兜底和后端根治两条路都讲一下,因为现实里你不一定能立刻推动后端改。
3.1 治本:后端对内容做 JSON 序列化
最干净的解法,是后端在把内容塞进 data: 之前,先做一次 JSON 序列化。
JSON 字符串里的换行符会被转义成字面量 \n(两个字符:反斜杠 + n),而不是真正的换行字节。这样一来,data: 后面就是一行完整的、不含真实换行的 JSON,SSE 传输不会破坏它。前端收到后 JSON.parse 一下,转义的 \n 自动还原成真正的换行。
后端改完之后,SSE 长这样:
event:message
data:{"content":"## 核心功能\n\n这是正文"}
前端解析就多一步 JSON.parse:
function parseMessageContent(data) {
if (!data) return ''
try {
const parsed = JSON.parse(data)
if (typeof parsed?.content === 'string') {
return parsed.content // 换行符已正确还原
}
} catch (e) {
// 兼容旧版:后端直接返回纯文本时,原样返回
}
return data
}
注意我这里 try-catch 做了兼容:JSON 解析失败就退回当作纯文本。这样新旧两种后端格式都能吃,灰度切换的时候不会出事。
3.2 前端的 SSE 解析要写对
后端格式对了,前端的 SSE 解析也得跟上。这里有几个容易写错的点。
第一,要按 SSE 规范一行行解析字段,不能想当然。一条消息可能有多个 data: 行(SSE 允许),它们应该用 \n 拼接。完整的解析逻辑:
function parseSSEBlock(block, onChunk, onSession) {
const lines = block.replace(/\r\n/g, '\n').replace(/\r/g, '\n').split('\n')
let currentEvent = 'message'
const dataLines = []
for (const line of lines) {
if (!line || line.startsWith(':')) continue // 空行和注释行跳过
const colonIndex = line.indexOf(':')
const field = colonIndex === -1 ? line : line.slice(0, colonIndex)
let value = colonIndex === -1 ? '' : line.slice(colonIndex + 1)
if (value.startsWith(' ')) value = value.slice(1) // 去掉冒号后的一个空格
if (field === 'event') {
currentEvent = value.trim() || 'message'
} else if (field === 'data') {
dataLines.push(value)
}
}
const currentData = dataLines.join('\n')
switch (currentEvent) {
case 'session':
if (currentData) onSession(currentData)
break
case 'message':
if (currentData !== '[DONE]') onChunk(parseMessageContent(currentData))
break
case 'end':
break
case 'error':
throw new Error(currentData || 'AI 服务返回错误')
}
}
第二,事件块要按空行分隔。SSE 用一个空行(连续两个 \n)来分隔不同的事件块,读流的时候要按 \n\n 切:
const blocks = buffer.split(/\n\n|\r\n\r\n/)
buffer = blocks.pop() ?? '' // 最后一块可能不完整,留到下次
for (const block of blocks) {
if (!block.trim()) continue
parseSSEBlock(block, onChunk, onSession)
}
第三,流读完后别忘了 flush。TextDecoder 用 { stream: true } 解码时会缓存不完整的多字节字符(中文很容易踩这个),读到 done 之后要再 decode() 一次把残留刷出来,否则结尾的中文可能乱码或丢失:
buffer += decoder.decode() // flush 残留字节
if (buffer.trim()) parseSSEBlock(buffer, onChunk, onSession)
3.3 渲染策略:整体渲染,别对分片单独渲染
最后是渲染。一个核心原则:永远对"拼接后的完整文本"做渲染,不要对单个分片渲染。
把所有 message 分片拼进同一个变量,用 computed 包一层,每次拼接自动触发整体重渲染:
const markdownText = ref('')
// computed 整体渲染,不对单个 chunk 渲染
const renderedHtml = computed(() => {
return sanitize(md.render(markdownText.value))
})
// 拿到分片时只管拼
onChunk((chunk) => {
markdownText.value += chunk
})
为什么强调这点?因为就算后端把换行修对了,如果你还是"来一片渲染一片",分片切碎语法的老问题(比如 ** 被切成两半)还是会让流式过程中的画面闪烁、符号短暂裸露。对完整文本整体渲染,markdown-it 每次拿到的都是语法完整(或接近完整)的文本,渲染结果就稳定。
markdown-it 的初始化我贴一下,顺手把代码高亮和 XSS 过滤也带上:
import MarkdownIt from 'markdown-it'
import hljs from 'highlight.js'
import xss from 'xss'
const md = new MarkdownIt({
html: false, // 不信任原始 HTML
linkify: true, // 自动识别链接
breaks: true, // 单换行也转 <br>,大模型换行更自然
highlight(code, lang) {
if (lang && hljs.getLanguage(lang)) {
return `<pre><code class="hljs">${hljs.highlight(code, { language: lang }).value}</code></pre>`
}
return `<pre><code class="hljs">${md.utils.escapeHtml(code)}</code></pre>`
},
})
// v-html 渲染大模型输出,一定要过滤
const sanitize = (html) => xss(html)
3.4 对比:问题解决前后效果对比图
AI 大模型返回的内容后,前端使用 Markdown 渲染,糊成一坨,标题、换行、列表、加粗全部失效,#、** 等符号直接以纯文本裸露。中途我尝试用正则在前端硬补换行,也只能修复到勉强能看的程度,边界情况依旧频频翻车
后端改为 JSON 序列化,前端对"拼接后的完整文本"整体渲染之后的效果。标题分级、段落间距、列表层级都正确呈现
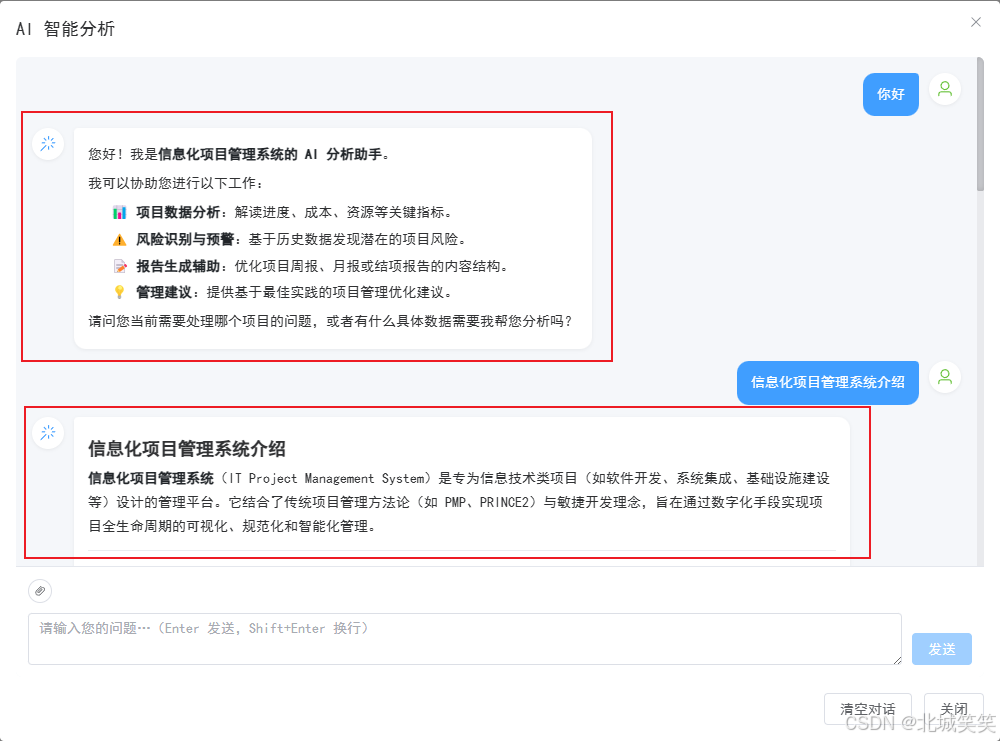
表格同样能正常规整渲染,表头、分割线、单元格对齐无误
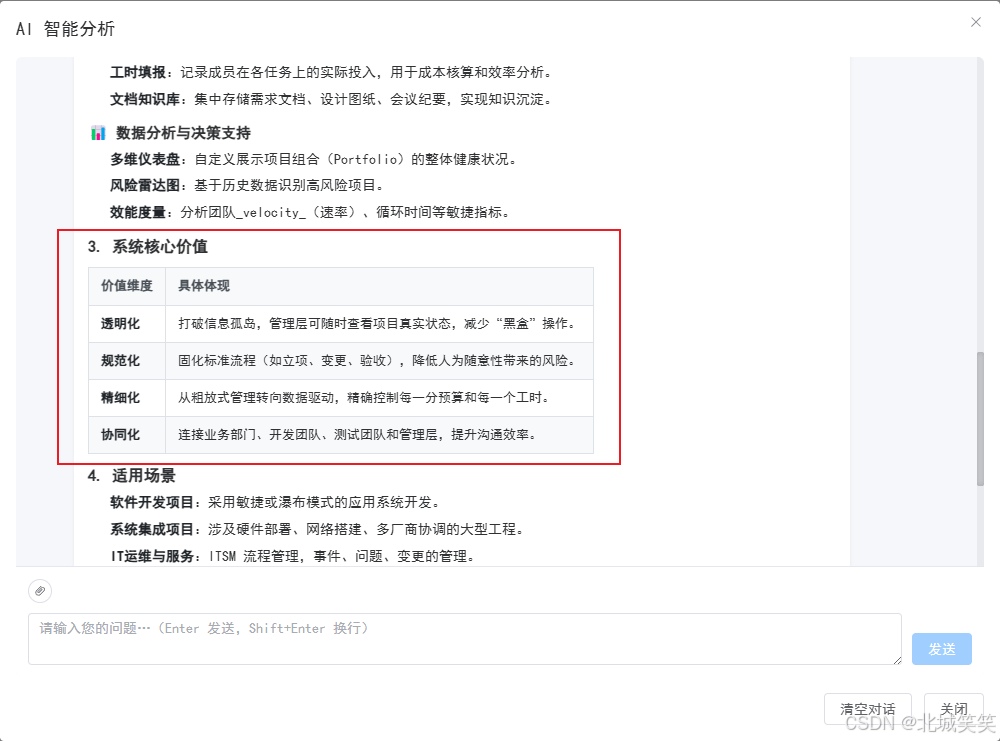
四、注意事项与避坑清单
按重要性排几条,都是这次实打实踩过的。
第一,调试 IO 问题,先看原始数据再看代码。 这次最大的弯路就是没第一时间把原始分片打出来,先去怀疑渲染器、怀疑时机。"输入 → 处理 → 输出"的链路一旦出问题,最快的定位永远是先确认输入长什么样,一个 JSON.stringify 能省下好几天。
第二,别用前端正则去"猜"换行。 分片是模型随机吐出来的,切割点完全不可控,靠标点、靠 # 开头补换行的规则不可能穷举所有情况,上线后一定会在某些回答上翻车。能让后端给准确数据,就别在前端硬凑。
第三,v-html 渲染大模型输出,XSS 过滤不能省。 模型输出本质是不可信内容,万一吐出 <script> 或被提示词注入,直接 v-html 就是漏洞。用 xss 或 DOMPurify 过一道即可。
第四,手写 fetch 解析 SSE,有两个坑必踩。
一是中文乱码——
TextDecoder用{ stream: true }时多字节字符会跨分片缓存,读完要decoder.decode()空调一次 flush,否则结尾中文丢字、乱码;二是鉴权头——流式接口绕过了 axios 拦截器,拦截器里自动加的头(比如我们项目放在
X-Access-Token的 token)都得手动补齐,顺手写成Bearer就 401 了。嫌麻烦可以直接上@microsoft/fetch-event-source,SSE 解析和重连都帮你封好了。
第五,留一个兼容退路。 像 parseMessageContent 那样,JSON 解析失败就退回纯文本。后端格式升级、灰度、回滚时前端都不用跟着改,这个 try-catch 就是保险。
五、本文总结
把整件事从头到尾捋一遍。
遇到的问题很直观:对接大模型的 SSE 流式问答,AI 的回答在页面上糊成密不透风的一整段——标题不换行、列表黏连、** 星号裸露、表格竖线散落,Markdown 该有的排版结构一个都没渲染出来。现象出在页面上,干渲染的是前端,所以我一口咬定是前端的问题。
排查和解决的过程,我走了两个错误方向才摸到正路。
- 先是怀疑 markdown-it 配置不对,把
breaks、html这些选项挨个试了个遍,没用;- 又怀疑是流式渲染时机问题,改成"流结束后整体渲染",最终结果还是糊的。
直到我把每个 SSE 分片用 JSON.stringify 原样打到页面上,才看清真相——所有分片全是纯文字,没有一个包含 \n 换行符。根因是 SSE 协议拿 \n 当字段分隔符,后端把带换行的文本直接塞进 data:,换行在传输中被协议吃掉了。这压根不是前端的锅。最终方案是后端对每个片段做 JSON 序列化({"content":"..."}),让换行符以转义形式 \n 安全穿过 SSE,前端 JSON.parse 还原;前端再配合规范的 SSE 解析、TextDecoder flush、对完整文本整体渲染,问题彻底解决。
下次怎么直接绕过这个坑。
如果再做类似的流式对接,我会在写一行渲染逻辑之前,先干两件事:
- 一是开工就把后端返回的原始分片打出来看一眼,确认换行符到底在不在——这一眼能直接跳过我这次走的全部弯路;
- 二是跟后端把"带格式文本怎么过 SSE"约定清楚,要么 JSON 序列化、要么 base64,别让它裸奔。只要这两点提前确认,糊成一坨的问题根本不会发生,也就不用在前端写那些靠标点猜换行、永远补不全的正则去擦屁股。
一句话——IO 链路出问题,第一步永远是看原始数据,而不是改处理代码;输出端的异常,源头常常在输入端。
回头看,这个问题的技术含量其实不高,难就难在"它看起来太像前端问题了"。糊成一坨的是页面,渲染 Markdown 的是前端,第一反应永远是往自己身上找原因。但 IO 链路的问题,源头可能在任何一环,光盯着输出端使劲,是使不到点子上的。把原始分片打出来的那一刻,三天的纠结瞬间就清晰了。
六、更多操作
更多前端实战内容,请看,Vue 个人专栏
本文属于 Vue 企业级实战系列,持续更新 Vue2/Vue3、工程化、性能优化、跨域解决方案等干货,欢迎关注我的 CSDN 专栏:
👉 Vue Develop 实战专栏![]() https://blog.csdn.net/weixin_65793170/category_12116741.html
https://blog.csdn.net/weixin_65793170/category_12116741.html
如果本文对你有帮助,欢迎点赞、收藏、评论,你的支持是我持续输出实战干货的动力!
如果你在项目中也遇到类似问题,欢迎留言交流,分享你的场景与解决方案。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)