从推理链到可验证子问题,强化学习终于开始学会“怎么分锅”
论文 / 来源:From Reasoning Chains to Verifiable Subproblems: Curriculum Reinforcement Learning Enables Credit Assignment for LLM Reasoning
原文:https://arxiv.org/abs/2605.22074
一句话先看懂:它不是在教模型更会“想”,而是在教它把一大串推理拆成能被验证的小步,然后把奖励更准确地打回去。
这篇工作最有价值的地方,不是又把“推理能力”喊了一遍,而是把一个一直很难落地的问题讲透了:如果模型的答案对了,奖励到底该归到哪一步? 以前很多 RLVR 做法都太粗,最后只能看整段结果,训练信号又稀又慢。作者换了一个更细的切法,把推理链拆成能验证的子问题,再把奖励分摊回具体的步骤上。 说白了,它想解决的不是“模型会不会答”,而是“模型到底有没有学到那一步该学的东西”。
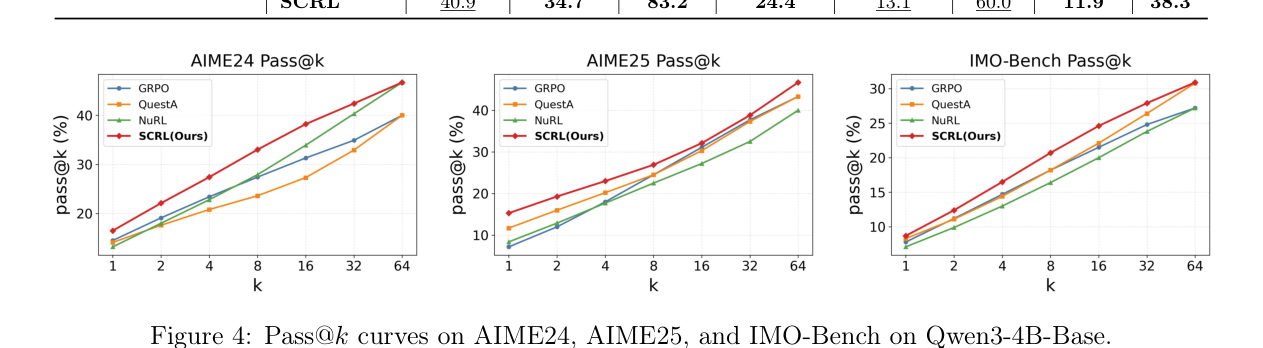
这类题我会优先把原论文首图贴进来,先用一张图把问题摆在桌面上。

论文速读
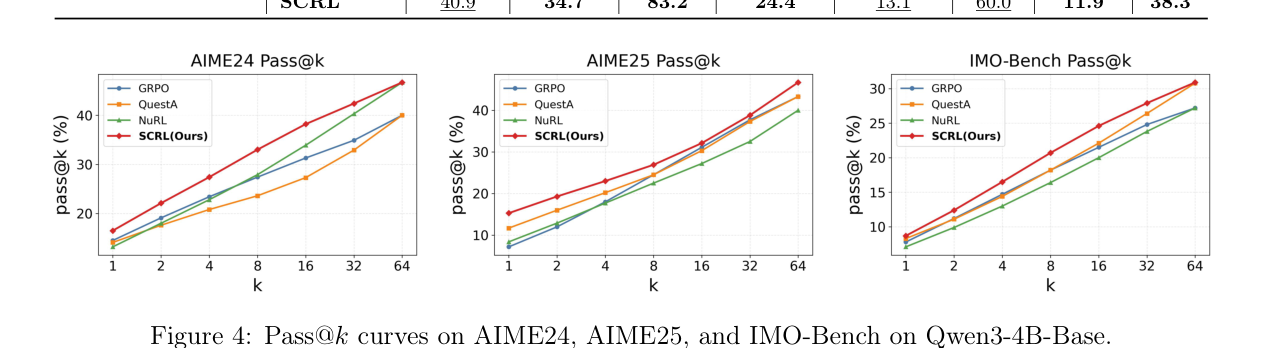
这篇 paper 一共三层意思。 第一层是问题定义。作者先说明,推理强化学习最难的不是奖励函数长什么样,而是奖励太晚、太稀,训练很容易只学到表面分数。 第二层是方法。它把原本整条推理链拆成可验证子问题,再把课程式训练和更细粒度的信用分配接起来,让模型先学会局部正确,再学会全局正确。 第三层是结论。这样的训练方式在多个数学推理基准上都更稳,尤其对复杂题更有效,因为它把“正确答案”变成了“可持续推进的中间步骤”。
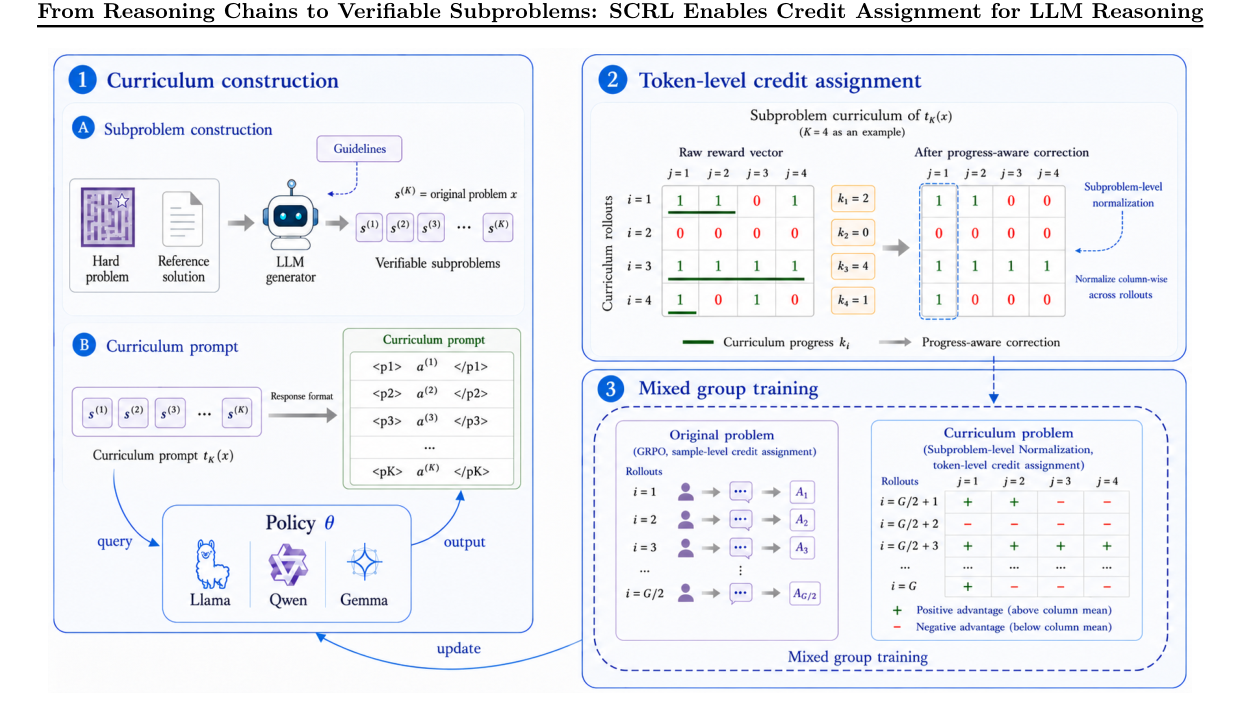
它真正解决的是什么问题?
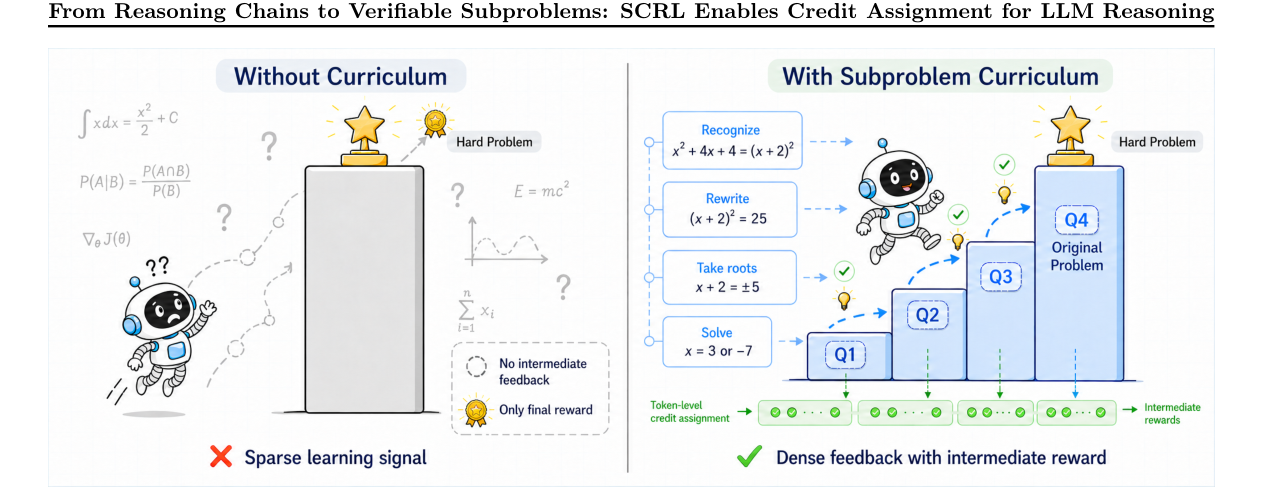
RLVR 最大的老问题,其实是奖励太晚。 题目对了,模型拿到正反馈;题目错了,模型拿到负反馈。听起来很简单,但一旦题目长、推理链长、探索空间大,整条轨迹里到底是哪一步有贡献,就会变得很模糊。 结果就是,模型可能学到了“最后怎么凑对”,却没学到“中间怎么走对”。这也是很多推理模型看起来越来越会写过程,但真正遇到新题还是会卡住的原因。 这篇论文不是把这个问题包装得更漂亮,而是直接承认:如果你不把信用分配拆细,强化学习就会一直很吃亏。
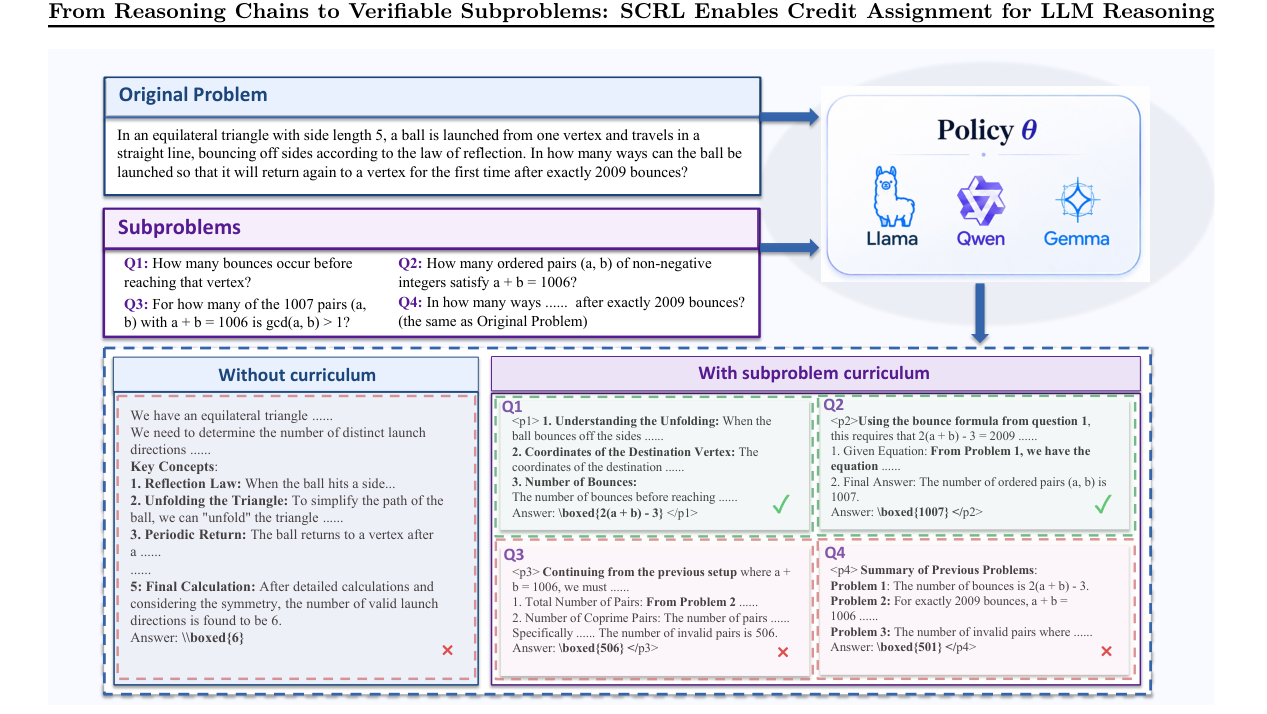
它是怎么做的?
作者做的事情可以概括成两步。 第一步,是从参考推理链里抽出可验证子问题,把长链路变成一串可以逐步检查的小任务。这样一来,训练时不再只盯着最终答案,而是能看到“这一步到底有没有推进”。 第二步,是把课程强化学习接进来。先让模型在更容易验证的子问题上建立稳定信号,再逐步推向完整推理链。这样做的好处是,模型不会一上来就被最难的长链路淹没。 更关键的是,它不是单纯加样本,而是把奖励和优势的归因方式一起改了。奖励不再平均撒,模型更容易知道,哪一段推理是真在帮忙。
对开发者和企业意味着什么?
对开发者来说,这篇论文最直接的启发是,推理能力训练不能只看“答对率”。 你还得看训练信号是不是太晚、是不是太粗、是不是把真正有价值的步骤冲掉了。长推理、复杂推理、可验证任务,未来很可能都要更重视中间步骤的可检查性。 对企业来说,这意味着推理型产品的优化方向会变得更工程化。不是简单堆更多数据,而是要把任务拆对,把验证做细,把奖励链路接准。谁先把这套闭环做顺,谁就更容易把推理能力做成稳定能力。
如果你觉得多模型切换 Q、工具订阅的流程太繁琐,也可以试试我们的「胜算云」平台,一站式搞定AI创作与开发相关需求。官网:https://www.shengsuanyun.com/?from=CH_5VQOF8WB

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)