Diff-Palm: Realistic Palmprint Generation with Polynomial Creasesand Intra-Class Variation Controll
Abstract
掌纹识别技术的发展受限于大规模公开数据集的匮乏。以往研究多采用贝塞尔曲线模拟掌纹纹路,并将其作为条件输入至生成对抗网络(GAN)来合成真实感掌纹图像。但这类合成数据集训练得到的识别模型,若不借助真实数据微调,性能会大幅下降,这说明合成掌纹与真实掌纹之间存在明显差距。该问题主要源于两方面:一是掌纹纹路的表征方式精度不足;二是难以在类内差异与身份一致性之间实现平衡。
针对上述问题,本文提出一种基于多项式的掌纹纹路表征方法,构建了更贴合真实纹路分布的生成机制;同时设计了以掌纹纹路为条件的扩散模型,并配套全新的类内差异控制策略。结合本文提出的K 步噪声共享采样策略,该方法能够生成兼具丰富类内差异与高身份一致性的掌纹数据集。
实验结果表明:本文首次实现了仅依靠合成数据集训练、不使用任何真实数据微调的掌纹识别模型,其性能超越了基于真实数据集训练的模型;并且随着合成身份数量的增加,本方法的识别效果还能持续提升。
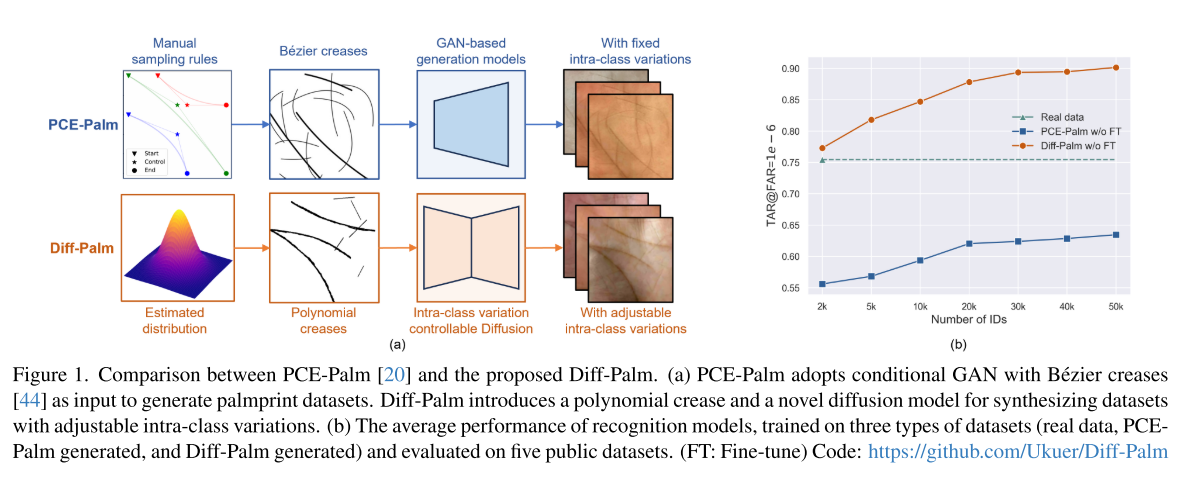
1.Introduction
掌纹识别凭借区分度高、使用便捷、隐私性好等优势,受到了学界的广泛关注。然而,大规模公开数据集的缺失严重制约了该技术的进一步发展。随着生成对抗网络(GAN)、扩散模型等深度生成模型取得突破性进展,利用模型合成数据集、替代人工采集大规模真实数据,已成为识别任务中极具价值的研究方向。
现有的掌纹生成方法(如 RPG-Palm、PCE-Palm)虽已取得不错效果,但依旧需要依靠真实数据微调才能保证识别性能。具体来说,这类方法先用合成数据对识别模型进行预训练,再结合真实数据微调;一旦省略微调步骤,模型性能便会显著下滑,足以证明合成数据与真实数据存在较大鸿沟。
经分析,造成该问题的核心原因有两点: 第一,掌纹纹路表征不准确。现有方法均采用人工设计的贝塞尔曲线模拟掌纹,但贝塞尔曲线的形态与真实掌纹纹路差异较大,且每条贝塞尔曲线仅包含 3 个控制点,表达能力有限,最终导致合成掌纹偏离真实分布。 第二,类内差异与身份一致性难以平衡。现有方案基于条件 GAN 生成图像,仅通过添加简单随机噪声模拟掌纹的类内变化。这种方式会造成合成数据集类内差异过大、身份一致性偏低,最终拉低识别模型效果。
为解决以上问题,本文提出一套全新框架,可生成兼具丰富类内差异与高身份一致性的真实感掌纹数据集,性能优于当前最优方法 PCE-Palm。本文主要思路如下:
- 采用多项式曲线描述掌纹纹路(下称多项式纹路)。具体使用四阶多项式,通过 5 个系数完成参数化表达,大幅拓展纹路的采样空间。基于真实掌纹纹路的统计分析,本文估算出多项式系数服从多元高斯分布,并设计全新采样机制从该分布中提取系数、生成多项式掌纹纹路,有效缩小合成纹路与真实纹路的差距。
- 构建可控制类内差异的条件扩散模型。扩散模型依靠迭代去噪采样生成图像,但该过程的固有随机性会造成同一身份样本的特征不可控,破坏身份一致性。为此,本文提出K 步噪声共享采样策略:在采样阶段,让同一身份的所有样本共用噪声序列,而非各自使用独立噪声。通过调节参数 K,即可灵活控制合成数据的类内差异程度。该采样策略为模块化设计,可直接迁移应用至其他扩散模型。
本文实验统一采用合成数据集训练识别模型,全程不使用真实数据微调,并在公开数据集上完成测试。本文主要贡献总结如下:
- 提出基于多项式曲线的掌纹纹路表征方式,表达能力更强,生成的纹路分布与真实掌纹高度契合。
- 设计搭载 K 步噪声共享采样的类内差异可控扩散模型,以掌纹纹路作为身份条件,可生成类内变化丰富、身份一致性高的掌纹数据集。
- 在开放集实验中首次验证:仅使用本文合成数据训练、不经真实数据微调的识别模型,性能超越基于真实数据训练的模型;同时,提升合成身份数量可进一步优化识别效果。
2. Related Work
2.1 面向生物特征识别的数据生成
随着生成技术不断迭代,各类生成模型已被用于生物特征领域的样本合成,典型方向包括人脸生成、指纹合成等。 在掌纹生成领域,BezierPalm 首次采用贝塞尔曲线表征掌纹纹路,并通过随机采样曲线生成全新身份样本。此后,RPG-Palm 与 PCE-Palm 均以贝塞尔曲线作为身份约束条件,结合生成对抗网络实现掌纹图像生成。尽管这些方法能够产出视觉效果逼真的掌纹图像,但依旧需要利用真实数据进行微调,才能获得理想的识别精度。
2.2 条件扩散模型
扩散模型在众多视觉任务中都取得了优异表现。为实现可控生成,目前主流采用两种条件控制方案: 第一种是嵌入式条件:通常利用预训练模型提取特征嵌入向量,再通过交叉注意力机制将嵌入信息融入 UNet 网络结构。 第二种是通道拼接式条件:将条件图像与待扩散图像在通道维度拼接后输入网络。
本文选取通道拼接式条件扩散模型作为基础框架,该方案能够保证条件图像与生成图像之间具备强关联性。同时,本文还与嵌入式条件模型 IDiff-Face(一款身份可控的人脸生成模型,识别性能突出)开展了对比实验。
2.3 识别方法
深度学习技术极大推动了生物特征识别的发展,在人脸识别任务中,CosFace、ArcFace 等基于间隔损失的算法展现出顶尖能力。同理,研究人员也提出了多种掌纹识别深度学习方法,其中大部分方案采用网络结构优化 + 间隔损失函数的组合形式。 参照 PCE-Palm 的实验设定,本文将 ArcFace 作为掌纹识别的基线模型,以此对比不同生成方法的效果。
3.Method
本章首先介绍多项式掌纹纹路表征方法,利用该方法生成伪掌纹纹路,将其作为生成真实掌纹图像的身份条件;随后提出类内差异可控扩散模型,主要包含掌纹纹路条件扩散模块与 K 步噪声共享采样机制。借助上述模块,能够生成类内差异可调节的掌纹数据集。
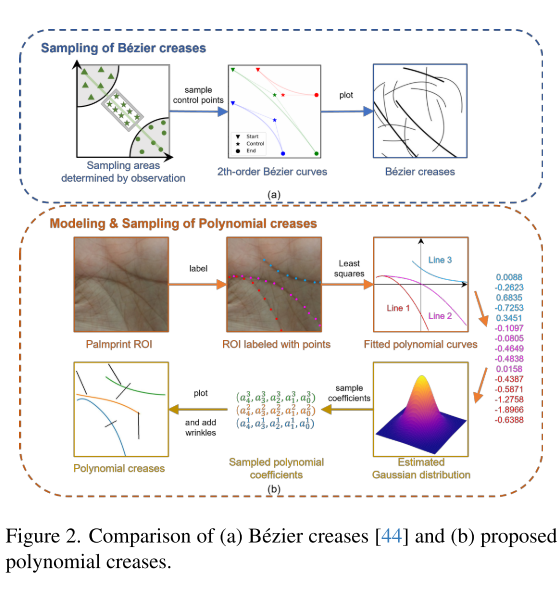
3.1 掌纹纹路的多项式表征
现有掌纹生成模型均以掌纹纹路作为身份控制条件,因此掌纹纹路表征是掌纹生成任务的核心。目前主流方法均采用二阶贝塞尔曲线描述掌纹纹路,其表达式为:
![]()
其中![]() 分别代表曲线的起点、控制点与终点,三者在预设人工区域内随机采样;参数 t 的取值范围为 [0,1],用于确定曲线上的位置。
分别代表曲线的起点、控制点与终点,三者在预设人工区域内随机采样;参数 t 的取值范围为 [0,1],用于确定曲线上的位置。
即便现有生成方法可以合成视觉效果逼真的掌纹图像,但其模拟出的纹路分布与真实掌纹纹路仍存在较大差异,这也是这类方法必须使用真实数据微调的主要原因。
为解决这一问题,本文优化掌纹纹路的表征方式,使其分布更加贴合真实掌纹。为此我们提出多项式纹路表征方案,并通过统计分析求解表征参数的分布规律。本文定义的多项式表达式如下:
![]()
式中![]() 为多项式系数;上标 i (i=1,2,3) 分别对应掌纹的三条主线。
为多项式系数;上标 i (i=1,2,3) 分别对应掌纹的三条主线。
相较于二阶贝塞尔曲线,四阶多项式具备更强的表达能力,能够精准刻画掌纹纹路的平滑形态。同时结合掌纹的生理特征与独特分布规律,采样得到的曲线参数也必须符合真实数据的分布特点。
本文从公开数据集中选取 1000 张掌纹感兴趣区域(ROI)图像,对三条主线逐一点位标注。针对单条纹路,基于 n 个标注点 ![]() ,采用最小二乘法求解多项式系数:
,采用最小二乘法求解多项式系数:
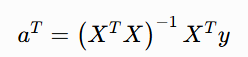
其中 aT 代表系数向量![]() ,y 代表纵坐标向量
,y 代表纵坐标向量 ![]() ,X∈Rn×5 为范德蒙矩阵。利用该公式可依次计算得到三条掌纹主线对应的系数向量 (a1,a2,a3)。
,X∈Rn×5 为范德蒙矩阵。利用该公式可依次计算得到三条掌纹主线对应的系数向量 (a1,a2,a3)。
在计算出所有样本对应的三条主线多项式系数后,我们对系数开展统计分析。可视化结果表明,多项式系数近似服从高斯分布。因此单个系数 aji 的分布可记为:
![]()
其中 μji 为均值,(σ2)ji 为方差。
整条纹路对应的系数向量 ai 服从多元高斯分布:
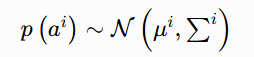
![]() 分别为系数向量的均值向量与协方差矩阵。
分别为系数向量的均值向量与协方差矩阵。
借助该表征方式与拟合得到的分布,平面上形态复杂的掌纹纹路被映射至服从多元高斯分布的参数空间。只需从该统计分布中采样多项式系数,即可通过多项式公式生成三条掌纹主线。
除此之外,本文还统计了每条纹路两个端点(起点 xsi、终点 xei)的坐标分布,并依据统计结果确定多项式纹路的采样范围。最后添加少量随机直线模拟细小皱纹,即可生成完整的伪掌纹纹路图像。
本文进一步设计掌纹纹路相似度控制机制:对拟合得到的高斯分布方差乘以缩放因子 γ2,即从分布 ![]() 中采样系数。当 γ<1 时,生成的掌纹纹路相似度更高;当 γ>1 时,纹路之间的差异会显著增大。
中采样系数。当 γ<1 时,生成的掌纹纹路相似度更高;当 γ>1 时,纹路之间的差异会显著增大。
3.2 基于掌纹纹路的条件扩散模型
扩散模型的训练目标是从随机噪声中还原出原始图像。与由双网络构成、采用对抗损失的生成对抗网络不同,扩散模型包含前向扩散与反向去噪两大过程。
前向扩散过程本质是马尔可夫链,模型在每一步向数据中加入不同方差的高斯噪声;经过总共 T 步扩散后,原始图像会完全退化为纯高斯噪声。前向扩散过程定义为:
![]()
式中 xt、xt−1 分别表示第 t 步、第 t−1 步的数据;βt 为预先设定的方差调度参数,用于控制每一步添加噪声的强度。
反向去噪过程旨在学习前向扩散的逆过程,从第 T 步的高斯噪声开始,逐步恢复出原始图像 x0。研究中训练一个 UNet 网络,用于预测第 t 步的噪声,进而由 xt 推导得到 xt−1。
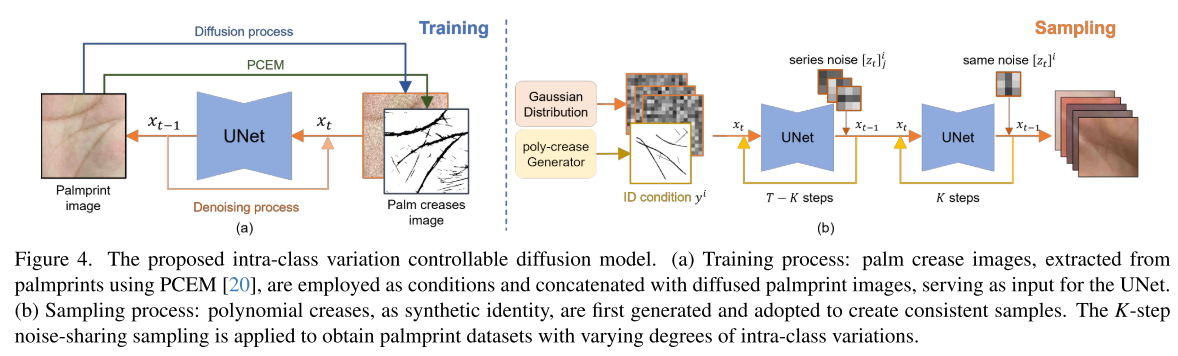
由于本文需要定向生成指定身份的掌纹图像,无条件扩散模型无法满足需求。为约束生成图像的身份,我们将掌纹纹路图像作为条件输入:首先利用掌纹纹路提取模块(PCEM)从真实掌纹图像中提取纹路图,再使用该纹路图控制生成掌纹的身份。
本文选择通道拼接的方式将条件信息融入 UNet 网络:将掌纹纹路图与加噪后的掌纹图像在通道维度拼接,共同作为网络输入。模型训练目标函数如下:
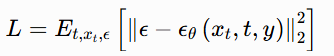
其中 ϵθ 代表参数化网络,y 代表掌纹纹路条件图像。
3.3 K 步噪声共享采样策略
模型训练完成后,通过反向扩散流程生成新样本:从随机高斯噪声出发,迭代调用训练好的去噪网络去除噪声,最终输出合成图像。迭代采样过程公式为:
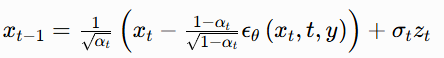
其中![]() 为随采样步数变化的常数,zt 是采样自标准高斯分布的随机噪声。迭代结束后得到的 x0 即为最终合成的掌纹图像。
为随采样步数变化的常数,zt 是采样自标准高斯分布的随机噪声。迭代结束后得到的 x0 即为最终合成的掌纹图像。
现有多数扩散模型依靠文本提示词控制生成结果的多样性,但掌纹图像结构简单,主要由纹路与皮肤区域构成,难以通过文本描述调控样本差异。实验发现,采样过程中每一步添加的随机噪声是生成结果多样性的核心来源,因此可以通过管控同一身份样本的输入噪声,精准控制数据集的类内差异。
为此本文提出 K 步噪声共享采样策略,实现类内差异的灵活调控。假设生成第 i 个身份的第 j 张样本,对应的掌纹纹路条件为 yi,将采样公式改写为:
![]()
式中![]() 为采样自标准高斯分布的随机噪声,直接决定样本的多样性。
为采样自标准高斯分布的随机噪声,直接决定样本的多样性。
本文核心思路为:对于同一个身份下的所有样本,不再使用相互独立的噪声序列,而是在总步数 T 中选取一段连续的 K 步,让所有样本共用同一份噪声。
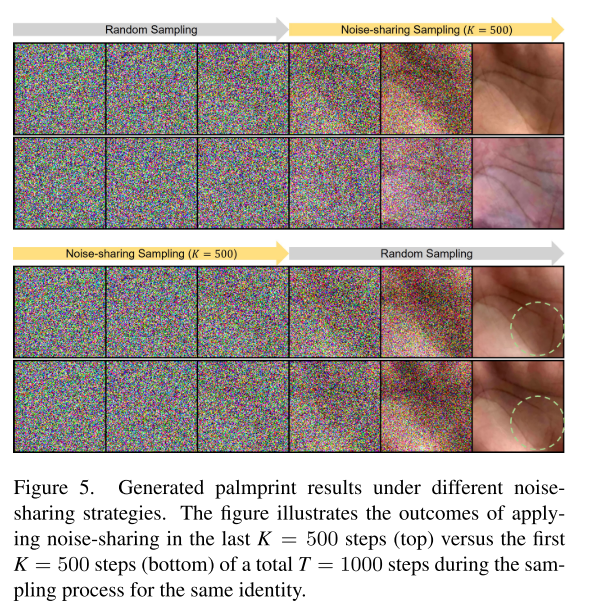
实验发现,将噪声共享机制应用在前 K 步与后 K 步会产生截然不同的效果。以总步数 T=1000、K=500 为例:若在前 K 步启用噪声共享,同一生成身份的图像整体风格统一,但纹路细节差异较大,身份一致性偏弱;若在后 K 步启用噪声共享,图像整体风格更加多样,但纹路细节的一致性显著提升。
该现象说明:在扩散采样过程中,模型会先完成掌纹整体风格的生成,再逐步还原纹理细节。
基于上述结论,本文选择在最后 K 个采样步启用噪声共享。随着参数 K 增大,同一身份样本的纹路一致性会逐步提升,但图像风格的多样性会随之下降。本文针对不同 K 值开展对照实验,以选取最优配置。
此外,该 K 步噪声共享采样属于即插即用模块,可直接迁移应用至其他扩散生成模型中。
4. Experiments
4.1 实验设置
本文采用开放集实验方案开展测试:将每一个公开数据集按照 1:1 的比例划分为训练集与测试集,并且保证训练集与测试集之间无重叠身份。实验采用错误接受率(FAR)固定下的真实接受率(TAR) 作为评价指标,衡量识别模型的性能。
数据集说明
为保证对比公平性,本文未使用任何公开数据集训练生成模型,实验处于更具挑战性的跨数据集场景下。生成模型的训练数据选用一份经网络采集并完成预处理的匿名数据集,共包含 48000 张掌纹图像。各类公开数据集仅用于模型效果评估,同时也作为基线识别模型的训练数据。 本次实验用到的公开数据集包括:CASIA、PolyU、Tongji、MPD、XJTU-UP、IITD 以及 NTU-CP-v1。
生成模型训练配置
本文所使用的条件扩散模型以 UNet 作为主干网络,网络输入为四通道图像,基础通道数设置为 64,共包含 5 个分辨率层级,各层级的通道数倍率依次为 1、1、2、3、4。在最后一个分辨率层级的残差块中加入注意力模块。
训练阶段采用 AdamW 优化器,学习率设为 1e−4,整体训练步数为 3 万步。对网络权重使用指数移动平均(EMA),指数衰减系数为 0.9999。批大小设置为 64,并平均分配至 4 块 GPU 上并行训练。 扩散过程总步数 T=1000,采用线性方差调度方案。在后续对比实验中,默认生成数据集包含 2000 个身份,每个身份生成 20 张样本。
识别模型训练配置
掌纹识别模型基于改进版 ResNet-18 搭建,并选用 ArcFace 损失函数。所有掌纹图像统一缩放至 112×112 分辨率;ArcFace 超参数设置为:间隔系数 m=0.5,尺度系数 s=64。
模型采用随机梯度下降(SGD)优化器训练 20 个轮次,初始学习率为 0.1,动量为 0.9,权重衰减系数为 5e−4。学习率采用阶梯式衰减策略:在第 7 轮和第 15 轮时将学习率缩小为原来的十分之一。 数据增强方面使用 RandAugment,参数配置为 (4,4)。同时对掌纹图像做水平翻转,将训练集身份数量扩充一倍。
识别模型在 4 块 NVIDIA V100 GPU 上训练,批大小为 256。针对不同数据集训练识别模型时,均保持完全一致的超参数。
4.2 实验结果
类内差异效果评估
本文基于 Diff-Palm 分别设置 、、、 生成多组数据集。使用在真实数据上预训练的 ArcFace 模型提取合成样本特征,计算正例匹配分数与负例匹配分数的分布,分数分布对比图与生成样本可视化结果分别如图 6、图 7 所示。
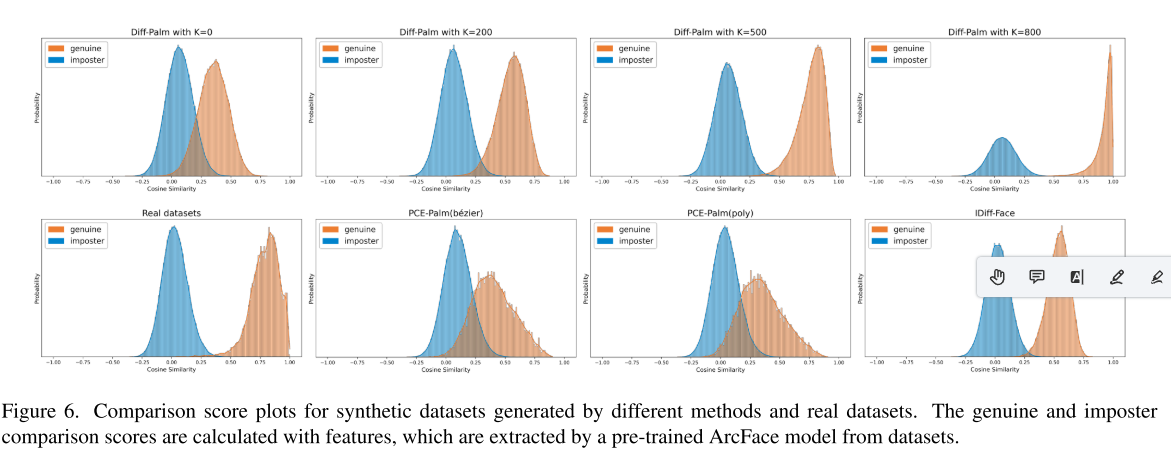

实验现象:随着参数 K 增大,数据集的类内差异逐渐降低,正例分数分布整体右移。结合表 1 的识别结果可知,当 K=500 时,基于该合成数据集训练的识别模型取得最优性能。
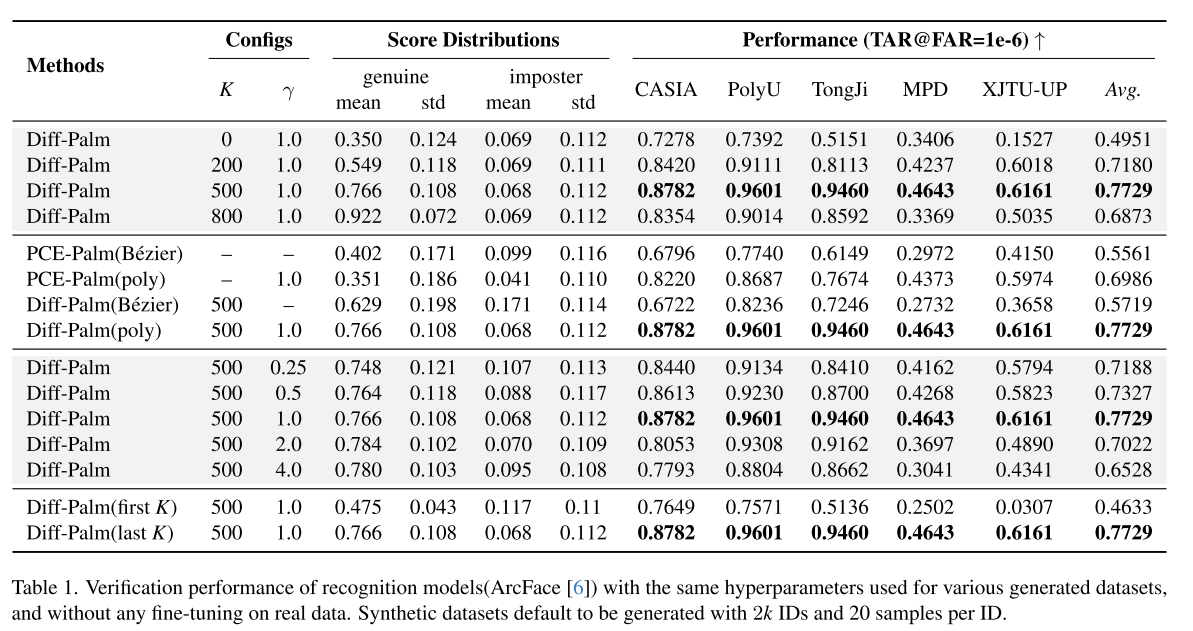
掌纹纹路表征方式对比
本文分别采用贝塞尔纹路与多项式纹路作为条件,对 PCE-Palm 与本文扩散模型进行对照实验。两组实验超参数完全一致,仅纹路表征方式不同。
由实验数据可见,基于多项式纹路的方案性能显著优于贝塞尔纹路。该结果证明:本文提出的多项式纹路表征能够有效缩小合成掌纹与真实掌纹之间的分布差距。
身份一致性、多样性指标评估
本文引用现有研究中的三项指标:身份一致性(Cidentity)、类内多样性(Dintra)、类别独特性(Uclass),对合成数据集进行量化评估,结果如表 2 所示。
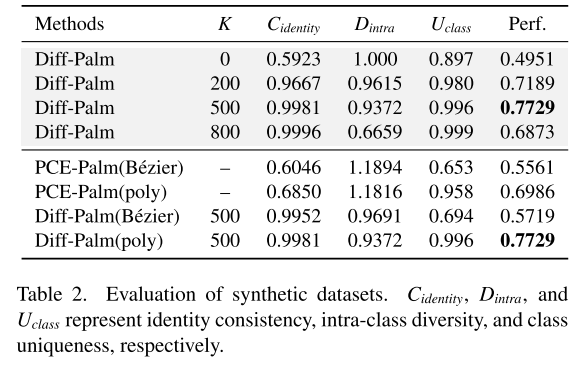
对于本文 Diff-Palm 模型,调整参数 K 会使身份一致性与类内多样性产生此消彼长的权衡关系;当 K=500 时,数据集在两项指标间达到最优平衡,对应识别性能最佳。
对比不同纹路表征方案可以发现:使用贝塞尔纹路会导致数据集的类别独特性明显下降,而多项式纹路可以有效保证类别独特性。 分析可知,本文方法性能突出的原因有两点:一是通过类内差异控制策略,兼顾了身份一致性与类内多样性;二是多项式纹路提升了数据集的类别独特性。反观 PCE-Palm 方法,存在身份一致性差、类别独特性不足的问题,因此识别效果欠佳。上述分析结论也通过 t-SNE 特征可视化结果(图 8)得到验证。相关指标的详细说明见补充材料。

掌纹纹路相似度对识别效果的影响
本文通过设置不同的缩放系数 γ 调整高斯分布方差,生成不同相似度的多项式纹路,进而构建多组合成数据集开展实验(结果见表 1)。
实验表明:当 γ>1 或 γ<1 时,识别性能均出现下降。分析原因:γ>1 会破坏原有真实纹路的分布规律;γ<1 则会增加识别模型的训练难度。该结果也验证了本文所拟合的多项式系数分布具备合理性与有效性。
与真实数据集、其他主流方法对比
本文将七份公开数据集融合,构建包含 2200 个身份、总计 29300 张图像的混合真实数据集作为基线。同时选取当前掌纹生成领域最优方法 PCE-Palm、以及人脸生成领域的 IDiff-Face、Vec2Face 开展对比实验。
所有实验遵循统一规则:仅使用合成数据集训练识别模型,不采用真实数据微调。由表 3 结果可得:
- 本文 Diff-Palm 生成数据训练的模型,在多数公开数据集上超越了纯真实数据训练的模型,平均性能也更优;
- 本文方法的效果大幅领先 PCE-Palm、IDiff-Face、Vec2Face 等对比方法。
此外,本文还补充了真实数据微调实验,与 PCE-Palm 做全面对比,更多细节见补充材料。
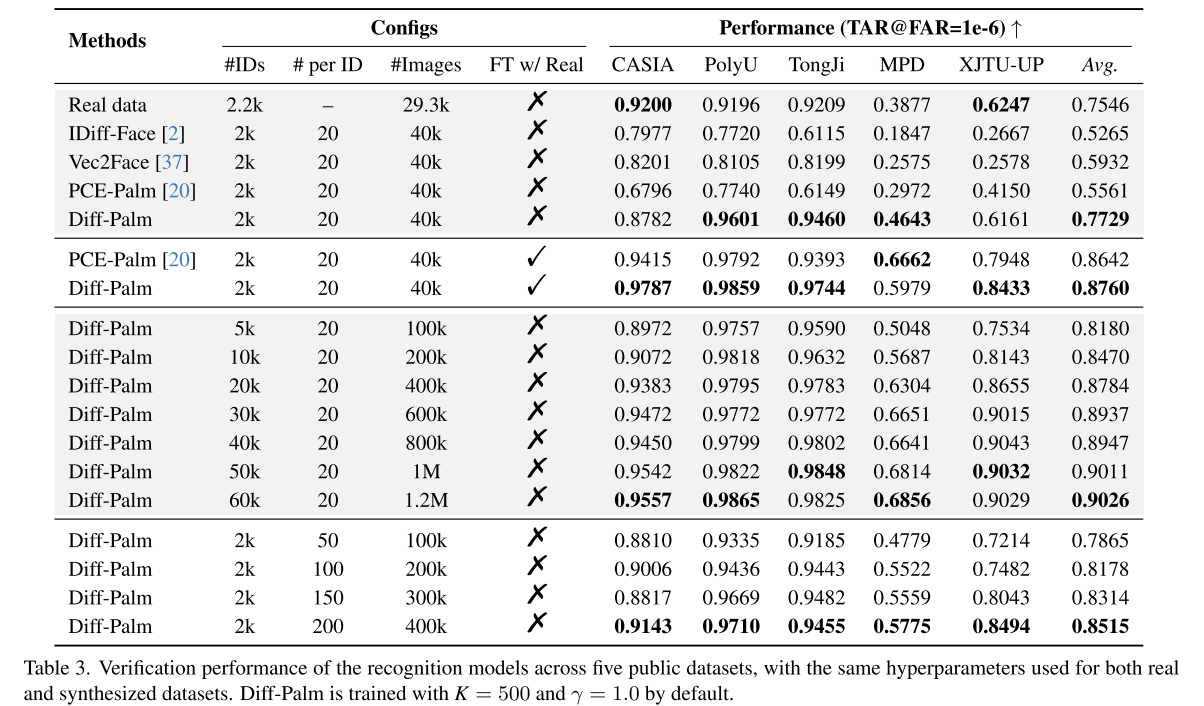
合成身份数量、单身份样本数量的影响
第一组实验:固定每个身份生成 20 张样本,逐步增加合成身份的总数。由表 3 可知,识别模型性能随身份数量增加持续提升,当身份数量达到 6 万时,性能趋于峰值。
第二组实验:固定身份总数不变,逐步增加单个身份对应的样本数量(20 ~ 200 张)。实验结果显示,单身份样本数增加后,识别性能同样稳步提升。
以上两组实验证明,本文方法具备良好的扩展性。
K 步噪声共享采样的消融实验与分析
本文针对两种噪声共享策略(前 K 步共享噪声、后 K 步共享噪声)开展消融实验,结果见表 1。 实验证明:若在前 K 步启用噪声共享,生成数据集的类内多样性会大幅降低,最终识别性能变差。
同时,本文提出的 K 步噪声共享采样为模块化设计,属于即插即用组件,可直接应用于其他基于扩散模型的生成任务。该模块在 IDiff-Face 等模型上的拓展实验结果见补充材料。
第五章 结论
本文提出了一种基于多项式的掌纹纹路表征方法,借助该方法能够生成大规模掌纹数据集,且合成纹路的分布特征与真实掌纹高度吻合。在此基础上,本文设计了一款可调控类内差异的扩散模型,并配套提出简洁高效的K 步噪声共享采样策略。利用该整套方案,可灵活生成类内差异程度不同的掌纹数据集。
实验结果表明,本文所提方法大幅缩小了合成数据与真实数据之间的差距。本研究也首次实现:仅使用本文合成数据集训练、未经过任何真实数据微调的掌纹识别模型,其综合性能超越了依托真实数据集训练得到的模型。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)