从零开始搭建大数据处理实战环境
一、数据集说明
YU.csv
通过网盘分享的文件:YU.csv
链接: https://pan.baidu.com/s/1sSrx5xGe8Lq9-MuHA4I00Q 提取码: f749
操作手册
通过网盘分享的文件:文件
链接: https://pan.baidu.com/s/1Y3ubq9LohbVEPibKHOjASQ 提取码: 7j6p
二、序言
(一)前置配置
(二)操作手册
VMware安装CentOS7详细步骤
这里以CentOS为例:
通过网盘分享的文件:VMware安装CentOS7详细步骤.pdf
链接: https://pan.baidu.com/s/1_YfeqR1Zzjdv9rqp3RxuvA 提取码: trp3
环境搭建与虚拟机配置
其中含有各个APP配置流程和版本,其中Windows中安装jdk1.8版本,否则导包时会出现JDK和HADOOP中JDK不兼容的状况。
虚拟机环境问题排查与解决方案
如果遇到报错,可以参考以下文档解决
通过网盘分享的文件:虚拟机环境问题排查与解决方案.pdf
链接: https://pan.baidu.com/s/1uRQjDus4MjjNbOPtCsalXg 提取码: rjdb
三、大数据处理
(一)数据清洗
1.数据源字段说明
YU.csv ,源数据共有19085条记录,12个字段。
| 字段 | 类型 | 代码中字段名称 |
| 商店ID |
string
|
store_id
|
| 门店所在城市 |
string
|
city
|
| 性别群体 |
string
|
gender
|
| 年龄群体 |
string
|
age
|
| 产品类别 |
string
|
category
|
| 客户数量 |
string
|
customers_cnt
|
| 销售金额 |
string
|
sales_price
|
| 订单数量 |
string
|
order_cnt
|
| 购买的产品数量 |
string
|
product_cnt
|
| 成本 |
string
|
cost
|
| 单价 |
string
|
price
|
| 订单日期 |
string
|
order_date
|
2.上传数据到HDFS
hadoop fs -mkdir -p /user/hive/warehouse/ods.db
hadoop fs -mkdir -p /user/hive/warehouse/dwd.db
hadoop fs -mkdir -p /user/hive/warehouse/ads.db由此可见,我们建立了ODS层、DWD层和ADS层,数仓的基本架构。
上传csv文件到HDFS的ODS层中
hadoop fs -put YU.csv /user/hive/warehouse/ods.db/PS:/user/hive/warehouse/ 目录是HIVE默认存储目录,自己可以在运行该代码前查看一下自己HIVE的配置目录是否和这个不一样,一般在hive-set.xml中有,如没有说明,系统默认为该目录,本地目录中如果没有是正常现象,HDFS目录是虚拟的,和虚拟机本地目录无关。
验证上传成功
hadoop fs -ls /user/hive/warehouse/ods.db/
hadoop fs -cat /user/hive/warehouse/ods.db/YU.csv | head -5

(二)HIVE分析
1.启动HIVE并创建ODS数据库
cd ~
hive下面命令将在HIVE的shell界面中执行
创建ODS数据库
CREATE DATABASE IF NOT EXISTS ods;
USE ods;2.创建ODS外部表
CREATE EXTERNAL TABLE ods.ods_uniqlo_info (
store_id string COMMENT '商店ID',
city string COMMENT '门店所在城市',
gender string COMMENT '性别群体',
age string COMMENT '年龄群体',
category string COMMENT '产品类别',
customers_cnt string COMMENT '客户数量',
sales_price string COMMENT '销售金额',
order_cnt string COMMENT '订单数量',
product_cnt string COMMENT '购买的产品数量',
cost string COMMENT '成本',
price string COMMENT '单价',
order_date string COMMENT '订单日期'
)
-- 指定字段分隔符为逗号(CSV格式)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
-- 指定数据文件在HDFS上的位置
LOCATION '/user/hive/warehouse/ods.db/'
-- 跳过CSV第一行表头
TBLPROPERTIES ('skip.header.line.count'='1');注意LOCATION后面的文件目录不能为YU.csv这类的具体目录,需要指定装在数据源的文件夹路径。
3.验证ODS数据
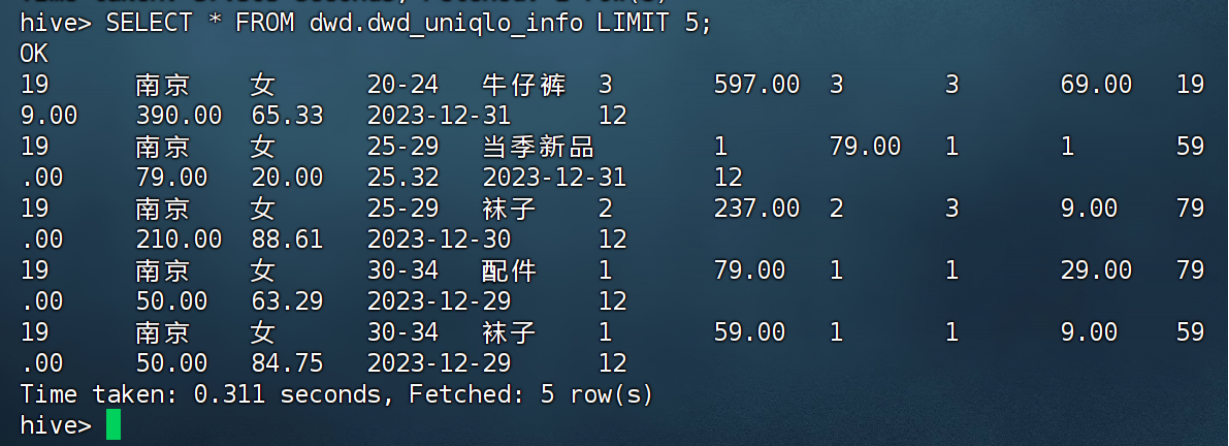
SELECT * FROM ods.ods_uniqlo_info LIMIT 5;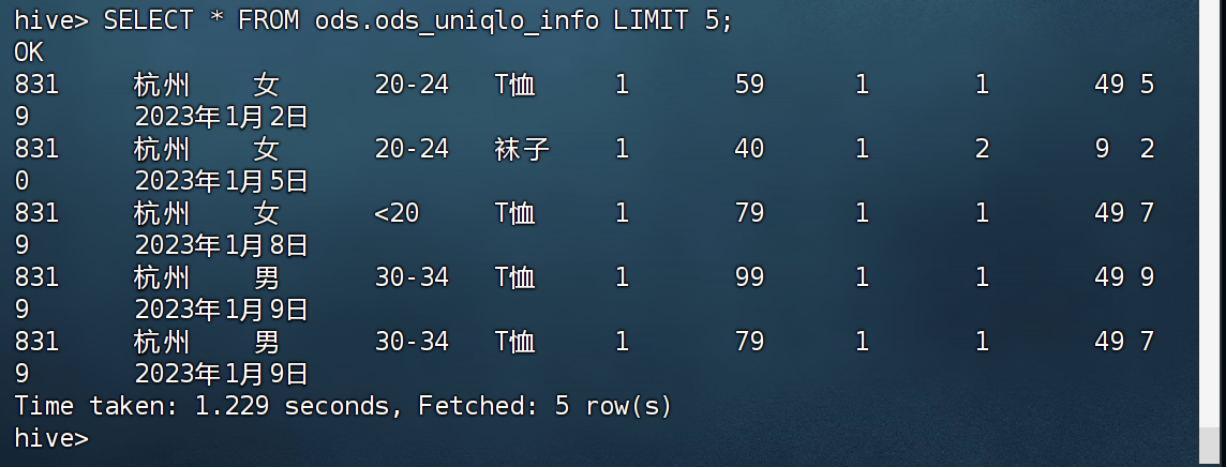
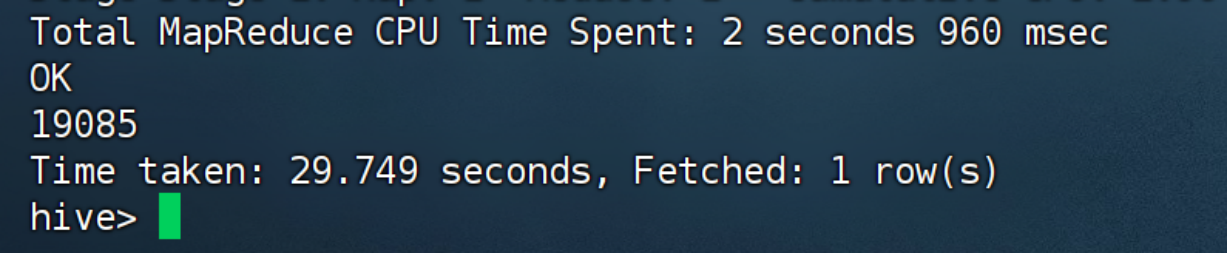
查看数据总量
SELECT COUNT(*) FROM ods.ods_uniqlo_info;应返回 19085
4.DWD层-MapReduce数据清洗
1.创建Maven项目
以下在IDEA中操作
新建,com.bigdata,设置java版本,设置成1.8(文档中使用的17,在导包后会与HADOOP中java版本冲突)。
编辑pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bigdata</groupId>
<artifactId>bigdata</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!-- Hadoop客户端依赖,提供MapReduce编程接口 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.6</version>
</dependency>
<!-- Apache Commons Lang3,提供字符串工具方法 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
<version>3.12.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- Maven打包插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.3.0</version>
<configuration>
<archive>
<manifest>
<!-- 指定主类,这样可以直接用hadoop jar运行 -->
<mainClass>com.bigdata.DataCleanMapReduce</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
</plugins>
</build>
</project>5.编写MapReduce数据清洗程序
package com.bigdata;
import org.apache.commons.lang3.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.text.DecimalFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/**
* 数据清洗MapReduce程序
* 功能:读取ODS层原始CSV数据,清洗后输出到DWD层
* 清洗规则:
* 1. 过滤表头和异常数据
* 2. 年龄字段标准化
* 3. 计算利润和利润率
* 4. 日期格式转换和月份提取
*/
public class DataCleanMapReduce {
// 输入路径:ODS层的CSV文件
private static String in = "/user/hive/warehouse/ods.db/YU.csv";
// 输出路径:DWD层的清洗后数据目录
private static String out = "/user/hive/warehouse/dwd.db/dwd_uniqlo_info";
/**
* 程序入口:配置并启动MapReduce作业
*/
public static void main(String[] args) throws IOException, InterruptedException,
ClassNotFoundException {
// 设置Hadoop用户为root,避免权限问题,可根据自己集群配置情况设置
System.setProperty("HADOOP_USER_NAME", "root");
// 创建Hadoop配置对象
Configuration config = new Configuration();
// 检查输出目录是否存在,存在则删除(MapReduce要求输出目录不能预先存在)
checkFileExits(config, new Path(out));
// 创建MapReduce作业
Job job = Job.getInstance(config);
// 设置主类,用于查找JAR包
job.setJarByClass(DataCleanMapReduce.class);
// 设置Mapper类
job.setMapperClass(TextMapper.class);
// 设置输出类型:键为NullWritable(不需要键),值为Text(一行文本)
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// 设置输入输出路径
FileInputFormat.setInputPaths(job, new Path(in));
FileOutputFormat.setOutputPath(job, new Path(out));
// 提交作业并等待完成
job.waitForCompletion(true);
}
/**
* 自定义Mapper类:逐行读取CSV数据,进行清洗转换
* 输入:LongWritable(行偏移量), Text(一行文本)
* 输出:NullWritable(空键), Text(清洗后的一行文本)
*/
public static class TextMapper extends Mapper<LongWritable, Text, NullWritable, Text> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text,
NullWritable, Text>.Context context)
throws IOException, InterruptedException {
try {
// 跳过第一行(表头),key.get()==0表示第一行
if (key.get() == 0) {
return;
}
// 将一行文本按逗号分割成字段数组
String lines = value.toString();
String[] line = lines.split(",");
// 过滤列数不等于12的异常数据
if (line.length != 12) {
return;
}
// 按顺序提取12个字段
String storeId = line[0]; // 商店ID
String city = line[1]; // 门店所在城市
String gender = line[2]; // 性别群体
String age = line[3]; // 年龄群体
String category = line[4]; // 产品类别
String customersCnt = line[5]; // 客户数量
String salesPrice = line[6]; // 销售金额
String orderCnt = line[7]; // 订单数量
String productCnt = line[8]; // 购买的产品数量
String cost = line[9]; // 成本
String price = line[10]; // 单价
String orderDate = line[11]; // 订单日期
// 过滤商店ID为空的记录
if (StringUtils.isEmpty(storeId)) {
return;
}
// 1. 年龄字段标准化:<20 → 1-20,>=60 → 60及以上
String convertAge = convertAge(age);
// 2. 计算利润:销售金额 - 产品数量 × 成本
String profit = calculateProfit(salesPrice, productCnt, cost);
// 3. 计算利润率:(利润 / 销售金额) × 100
String profitRate = calculateProfitRate(salesPrice, profit);
// 4. 日期格式转换:2023年1月2日 → 2023-01-02
String formatDate = formatDate(orderDate);
// 5. 提取月份:2023年1月2日 → 1
String formatMonth = formatMonth(orderDate);
// 将清洗后的字段用逗号拼接成一行
// 输出15个字段(原12个 + profit + profitRate + day + month,去掉order_date)
String output = String.join(",", storeId, city, gender, convertAge,
category,
customersCnt, salesPrice, orderCnt, productCnt, cost, price,
profit,
profitRate, formatDate, formatMonth);
// 写入输出
context.write(NullWritable.get(), new Text(output));
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
/**
* 年龄字段标准化
* 将"<20"转换为"1-20",将">=60"转换为"60及以上"
* 其他年龄段保持不变(如"20-24", "25-29"等)
*/
public static String convertAge(String age) {
String ageValue = age;
if (ageValue.equalsIgnoreCase("<20")) {
ageValue = "1-20";
} else if (ageValue.equalsIgnoreCase(">=60")) {
ageValue = "60及以上";
}
return ageValue;
}
/**
* 计算利润
* 利润 = 销售金额 - 产品数量 × 成本
* @param salesPrice 销售金额
* @param productCnt 产品数量
* @param cost 单件成本
* @return 利润字符串
*/
public static String calculateProfit(String salesPrice, String productCnt, String cost)
{
double salesPriceDouble = Double.parseDouble(salesPrice);
double productCntDouble = Double.parseDouble(productCnt);
double costDouble = Double.parseDouble(cost);
return String.valueOf(salesPriceDouble - (productCntDouble * costDouble));
}
/**
* 计算利润率
* 利润率 = (利润 / 销售金额) × 100,保留两位小数
* 当销售金额为0时,利润率返回0,避免除零错误
* @param salesPrice 销售金额
* @param profit 利润
* @return 利润率字符串
*/
public static String calculateProfitRate(String salesPrice, String profit) {
// 处理销售金额为0的情况,避免除零异常
if (salesPrice.equalsIgnoreCase("0")) {
return "0";
}
try {
double salesPriceDouble = Double.parseDouble(salesPrice);
double profitDouble = Double.parseDouble(profit);
// 保留两位小数
DecimalFormat df = new DecimalFormat("#.##");
return df.format((profitDouble / salesPriceDouble) * 100);
} catch (NumberFormatException e) {
return "0";
}
}
/**
* 日期格式转换
* 将"2023年1月2日"格式转换为"2023-01-02"标准格式
* @param orderDate 原始日期字符串
* @return 格式化后的日期字符串
*/
public static String formatDate(String orderDate) throws ParseException {
SimpleDateFormat oldSdf = new SimpleDateFormat("yyyy年M月d日");
SimpleDateFormat newSdf = new SimpleDateFormat("yyyy-MM-dd");
Date date = oldSdf.parse(orderDate);
return newSdf.format(date);
}
/**
* 从日期中提取月份
* 将"2023年1月2日"转换为"1"
* @param orderDate 原始日期字符串
* @return 月份字符串
*/
public static String formatMonth(String orderDate) throws ParseException {
SimpleDateFormat oldSdf = new SimpleDateFormat("yyyy年M月d日");
SimpleDateFormat newSdf = new SimpleDateFormat("M");
Date date = oldSdf.parse(orderDate);
return newSdf.format(date);
}
/**
* 检查输出目录是否存在,如果存在则删除
* MapReduce要求输出目录不能预先存在,否则会报错
* @param conf Hadoop配置
* @param out 输出路径
*/
public static void checkFileExits(Configuration conf, Path out) throws IOException {
FileSystem fs = FileSystem.get(conf);
if (fs.exists(out)) {
fs.delete(out, true);
}
fs.close();
}
}6.打包并运行MapReduce
cd bigdata
mvn clean package -DskipTests
hadoop jar bigdata-1.0-SNAPSHOT.jar com.bigdata.DataCleanMapReduce
查看文件前 5 行数据
7.创建DWD层Hive表
CREATE DATABASE IF NOT EXISTS dwd;
USE dwd;CREATE EXTERNAL TABLE dwd.dwd_uniqlo_info (
store_id string COMMENT '商店ID',
city string COMMENT '门店所在城市',
gender string COMMENT '性别群体',
age string COMMENT '年龄群体',
category string COMMENT '产品类别',
customers_cnt string COMMENT '客户数量',
sales_price decimal(10,2) COMMENT '销售金额',
order_cnt string COMMENT '订单数量',
product_cnt string COMMENT '购买的产品数量',
cost decimal(10,2) COMMENT '成本',
price decimal(10,2) COMMENT '单价',
profit decimal(10,2) COMMENT '利润',
profit_rate decimal(10,2) COMMENT '利润率',
day string COMMENT '日期(yyyy-MM-dd格式)',
month int COMMENT '月份'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/user/hive/warehouse/dwd.db/dwd_uniqlo_info';验证DWD数据
SELECT COUNT(*) FROM dwd.dwd_uniqlo_info;
-- 应返回清洗后的数据量
SELECT * FROM dwd.dwd_uniqlo_info LIMIT 5;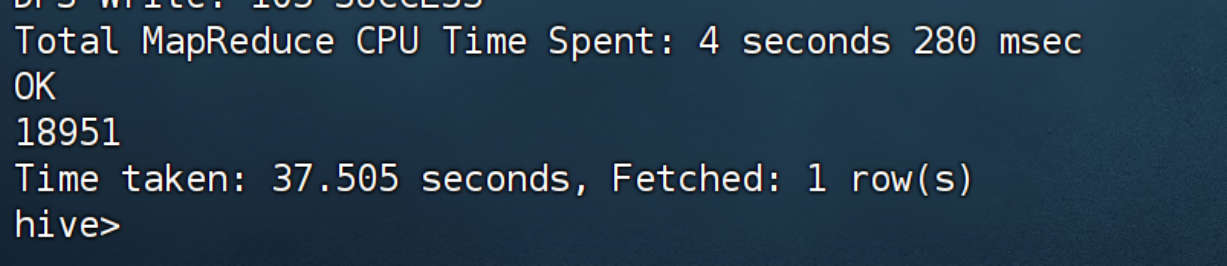
8. ADS层 — Hive SQL聚合分析
ADS层存放的是在HIVE中基于ADS和OWD数据处理后的数据
创建ADS数据库
CREATE DATABASE IF NOT EXISTS ads;
USE ads;创建 8 张分析表
-- ========== 表1:性别消费分析 ==========
-- 按城市和性别聚合,计算各性别的消费总额
CREATE TABLE ads.ads_gender_consumption_analysis(
city string COMMENT '城市',
gender string COMMENT '性别',
price decimal(10,2) COMMENT '消费金额'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
-- 填充数据:按城市和性别分组求和
INSERT OVERWRITE TABLE ads.ads_gender_consumption_analysis
SELECT city, gender, sum(sales_price) as price
FROM dwd.dwd_uniqlo_info
GROUP BY city, gender;
-- ========== 表2:年龄消费分析 ==========
-- 按城市和年龄段聚合,分别计算男女消费金额
CREATE TABLE ads.ads_age_consumption_analysis(
city string COMMENT '城市',
age string COMMENT '年龄',
male_price decimal(10,2) COMMENT '男性消费金额',
female_price decimal(10,2) COMMENT '女性消费金额'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
-- 使用CASE WHEN分别统计男女消费
INSERT OVERWRITE TABLE ads.ads_age_consumption_analysis
SELECT city, age,
sum(case when gender = '男' then sales_price end) as male_price,
sum(case when gender = '女' then sales_price end) as female_price
FROM dwd.dwd_uniqlo_info
GROUP BY city, age;
-- ========== 表3:性别产品消费分析 ==========
-- 按城市和产品类别聚合,分别计算男女消费金额
CREATE TABLE ads.ads_gender_product_consumption(
city string COMMENT '城市',
category string COMMENT '产品类别',
male_price decimal(10,2) COMMENT '男性消费金额',
female_price decimal(10,2) COMMENT '女性消费金额'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
INSERT OVERWRITE TABLE ads.ads_gender_product_consumption
SELECT city, category,
sum(case when gender = '男' then sales_price end) as male_price,
sum(case when gender = '女' then sales_price end) as female_price
FROM dwd.dwd_uniqlo_info
GROUP BY city, category;
-- ========== 表4:产品销售分析 ==========
-- 按城市和产品类别聚合销售金额
CREATE TABLE ads.ads_product_sales_analysis(
city string COMMENT '城市',
category string COMMENT '产品类别',
price decimal(10,2) COMMENT '销售金额'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
INSERT OVERWRITE TABLE ads.ads_product_sales_analysis
SELECT city, category, sum(sales_price) as price
FROM dwd.dwd_uniqlo_info
GROUP BY city, category;
-- ========== 表5:产品销量分析 ==========
-- 按城市和产品类别聚合销售数量
CREATE TABLE ads.ads_product_quantity_analysis(
city string COMMENT '城市',
category string COMMENT '产品类别',
product_cnt int COMMENT '产品数量'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
INSERT OVERWRITE TABLE ads.ads_product_quantity_analysis
SELECT city, category, sum(product_cnt) as product_cnt
FROM dwd.dwd_uniqlo_info
GROUP BY city, category;
-- ========== 表6:产品单价分析 ==========
-- 按城市和产品类别计算平均单价
CREATE TABLE ads.ads_product_price_analysis(
city string COMMENT '城市',
category string COMMENT '产品类别',
price decimal(10,2) COMMENT '平均单价'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
INSERT OVERWRITE TABLE ads.ads_product_price_analysis
SELECT city, category, avg(price) as price
FROM dwd.dwd_uniqlo_info
GROUP BY city, category;
-- ========== 表7:产品利润分析 ==========
-- 按城市和产品类别聚合利润和平均利润率
CREATE TABLE ads.ads_product_profit_analysis(
city string COMMENT '城市',
category string COMMENT '产品类别',
profit decimal(10,2) COMMENT '利润',
profit_rate decimal(10,2) COMMENT '利润率'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
INSERT OVERWRITE TABLE ads.ads_product_profit_analysis
SELECT city, category,
sum(profit) as profit,
avg(profit_rate) as profit_rate
FROM dwd.dwd_uniqlo_info
GROUP BY city, category;
-- ========== 表8:月份利润分析 ==========
-- 按城市和月份聚合利润和平均利润率
CREATE TABLE ads.ads_monthly_profit_analysis(
city string COMMENT '城市',
month string COMMENT '月份',
profit decimal(10,2) COMMENT '利润',
profit_rate decimal(10,2) COMMENT '利润率'
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
INSERT OVERWRITE TABLE ads.ads_monthly_profit_analysis
SELECT city, month,
sum(profit) as profit,
avg(profit_rate) as profit_rate
FROM dwd.dwd_uniqlo_info
GROUP BY city, month;
验证ADS数据
-- 验证每张表都有数据
SELECT COUNT(*) FROM ads.ads_gender_consumption_analysis;
SELECT COUNT(*) FROM ads.ads_age_consumption_analysis;
SELECT COUNT(*) FROM ads.ads_gender_product_consumption;
SELECT COUNT(*) FROM ads.ads_product_sales_analysis;
SELECT COUNT(*) FROM ads.ads_product_quantity_analysis;
SELECT COUNT(*) FROM ads.ads_product_price_analysis;
SELECT COUNT(*) FROM ads.ads_product_profit_analysis;
SELECT COUNT(*) FROM ads.ads_monthly_profit_analysis;
(三)Sqoop导出
1.在MySQL中创建9张业务表
USE op_uniqlo_db;
-- 1. 订单明细表
CREATE TABLE dwd_uniqlo_info (
id int NOT NULL AUTO_INCREMENT COMMENT '主键ID',
store_id varchar(64) COMMENT '商店ID',
city varchar(64) COMMENT '门店所在城市',
gender varchar(64) COMMENT '性别群体',
age varchar(64) COMMENT '年龄群体',
category varchar(64) COMMENT '产品类别',
customers_cnt varchar(64) COMMENT '客户数量',
sales_price decimal(10,2) COMMENT '销售金额',
order_cnt varchar(64) COMMENT '订单数量',
product_cnt varchar(64) COMMENT '购买的产品数量',
cost decimal(10,2) COMMENT '成本',
price decimal(10,2) COMMENT '单价',
profit decimal(10,2) COMMENT '利润',
profit_rate decimal(10,2) COMMENT '利润率',
day varchar(64) COMMENT '日期',
month int COMMENT '月份',
PRIMARY KEY (id),
KEY idx_city (city)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 2. 性别消费分析表
CREATE TABLE ads_gender_consumption_analysis (
city varchar(64) COMMENT '城市',
gender varchar(64) COMMENT '性别',
price decimal(10,2) COMMENT '消费金额',
KEY idx_city (city)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 3. 年龄消费分析表
CREATE TABLE ads_age_consumption_analysis (
city varchar(64) COMMENT '城市',
age varchar(64) COMMENT '年龄段',
male_price decimal(10,2) COMMENT '男性消费金额',
female_price decimal(10,2) COMMENT '女性消费金额'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 4. 性别产品消费表
CREATE TABLE ads_gender_product_consumption (
city varchar(64) COMMENT '城市',
category varchar(64) COMMENT '产品类别',
male_price decimal(10,2) COMMENT '男性消费金额',
female_price decimal(10,2) COMMENT '女性消费金额'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 5. 产品销售分析表
CREATE TABLE ads_product_sales_analysis (
city varchar(64) COMMENT '城市',
category varchar(64) COMMENT '产品类别',
price decimal(10,2) COMMENT '销售金额'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 6. 产品销量分析表
CREATE TABLE ads_product_quantity_analysis (
city varchar(64) COMMENT '城市',
category varchar(64) COMMENT '产品类别',
product_cnt int COMMENT '产品数量'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 7. 产品单价分析表
CREATE TABLE ads_product_price_analysis (
city varchar(64) COMMENT '城市',
category varchar(64) COMMENT '产品类别',
price decimal(10,2) COMMENT '平均单价'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 8. 产品利润分析表
CREATE TABLE ads_product_profit_analysis (
city varchar(64) COMMENT '城市',
category varchar(64) COMMENT '产品类别',
profit decimal(10,2) COMMENT '利润',
profit_rate decimal(10,2) COMMENT '利润率'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 9. 月份利润分析表
CREATE TABLE ads_monthly_profit_analysis (
city varchar(64) COMMENT '城市',
month varchar(64) COMMENT '月份',
profit decimal(10,2) COMMENT '利润',
profit_rate decimal(10,2) COMMENT '利润率'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;2.使用Sqoop导出数据
# 导出订单明细表(注意:MySQL中id是自增的,Hive数据不含id,需指定列名)
sqoop export \
--connect "jdbc:mysql://hadoop01:3306/op_uniqlo_db?useSSL=false&serverTimezone=GMT%2b8" \
--username root \
--password 123456 \
--table dwd_uniqlo_info \
--export-dir /user/hive/warehouse/dwd.db/dwd_uniqlo_info \
--input-fields-terminated-by ',' \
--columns
"store_id,city,gender,age,category,customers_cnt,sales_price,order_cnt,product_cnt,cost,price,profit,profit_rate,day,month"
# 导出性别消费分析表
sqoop export \
--connect "jdbc:mysql://hadoop01:3306/op_uniqlo_db?useSSL=false&serverTimezone=GMT%2b8" \
--username root --password 123456 \
--table ads_gender_consumption_analysis \
--export-dir /user/hive/warehouse/ads.db/ads_gender_consumption_analysis \
--input-fields-terminated-by ','
# 导出年龄消费分析表
sqoop export \
--connect "jdbc:mysql://hadoop01:3306/op_uniqlo_db?useSSL=false&serverTimezone=GMT%2b8" \
--username root --password 123456 \
--table ads_age_consumption_analysis \
--export-dir /user/hive/warehouse/ads.db/ads_age_consumption_analysis \
--input-fields-terminated-by ','
# 导出性别产品消费表
sqoop export \
--connect "jdbc:mysql://hadoop01:3306/op_uniqlo_db?useSSL=false&serverTimezone=GMT%2b8" \
--username root --password 123456 \
--table ads_gender_product_consumption \
--export-dir /user/hive/warehouse/ads.db/ads_gender_product_consumption \
--input-fields-terminated-by ','
# 导出产品销售分析表
sqoop export \
--connect "jdbc:mysql://hadoop01:3306/op_uniqlo_db?useSSL=false&serverTimezone=GMT%2b8" \
--username root --password 123456 \
--table ads_product_sales_analysis \
--export-dir /user/hive/warehouse/ads.db/ads_product_sales_analysis \
--input-fields-terminated-by ','
# 导出产品销量分析表
sqoop export \
--connect "jdbc:mysql://hadoop01:3306/op_uniqlo_db?useSSL=false&serverTimezone=GMT%2b8" \
--username root --password 123456 \
--table ads_product_quantity_analysis \
--export-dir /user/hive/warehouse/ads.db/ads_product_quantity_analysis \
--input-fields-terminated-by ','
# 导出产品单价分析表
sqoop export \
--connect "jdbc:mysql://hadoop02:3306/op_uniqlo_db?useSSL=false&serverTimezone=GMT%2b8" \
--username root --password 123456 \
--table ads_product_price_analysis \
--export-dir /user/hive/warehouse/ads.db/ads_product_price_analysis \
--input-fields-terminated-by ','
# 导出产品利润分析表
sqoop export \
--connect "jdbc:mysql://hadoop01:3306/op_uniqlo_db?useSSL=false&serverTimezone=GMT%2b8" \
--username root --password 123456 \
--table ads_product_profit_analysis \
--export-dir /user/hive/warehouse/ads.db/ads_product_profit_analysis \
--input-fields-terminated-by ','
# 导出月份利润分析表
sqoop export \
--connect "jdbc:mysql://hadoop01:3306/op_uniqlo_db?useSSL=false&serverTimezone=GMT%2b8" \
--username root --password 123456 \
--table ads_monthly_profit_analysis \
--export-dir /user/hive/warehouse/ads.db/ads_monthly_profit_analysis \
--input-fields-terminated-by ','sqoop export \ --connect "jdbc:mysql://hadoop:3306/op_uniqlo_db?useSSL=false&serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=utf-8" \
到处时需要注意hadoop01:3306,我执行到处命令的是hadoop01,友友们要根据自己集群的映射来写,还有&serverTimezone=GMT%2b8,HIVE中的时间使用的GMT%2b8,但是MYSQL不一定支持,我=Asia/Shanghai,要根据自己配置情况灵活修改。
验证MYSQL数据
-- 检查每张表的数据量
SELECT 'dwd_uniqlo_info' AS tbl, COUNT(*) AS cnt FROM dwd_uniqlo_info
UNION ALL
SELECT 'ads_gender', COUNT(*) FROM ads_gender_consumption_analysis
UNION ALL
SELECT 'ads_age', COUNT(*) FROM ads_age_consumption_analysis
UNION ALL
SELECT 'ads_gender_product', COUNT(*) FROM ads_gender_product_consumption
UNION ALL
SELECT 'ads_product_sales', COUNT(*) FROM ads_product_sales_analysis
UNION ALL
SELECT 'ads_product_quantity', COUNT(*) FROM ads_product_quantity_analysis
UNION ALL
SELECT 'ads_product_price', COUNT(*) FROM ads_product_price_analysis
UNION ALL
SELECT 'ads_product_profit', COUNT(*) FROM ads_product_profit_analysis
UNION ALL
SELECT 'ads_monthly_profit', COUNT(*) FROM ads_monthly_profit_analysis;四、后端开发
(一)新建项目
1. IDEA创建项目
2. 编辑 pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 继承Spring Boot父项目,统一管理依赖版本 -->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.1</version>
<relativePath/>
</parent>
<groupId>org.example</groupId>
<artifactId>backend</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>backend</name>
<properties>
<java.version>17</java.version>
</properties>
<dependencies>
<!-- Spring Boot JDBC Starter,提供数据库访问基础支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<!-- Spring Security,提供安全认证框架 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>
<!-- Lombok,自动生成getter/setter/构造方法等 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- MyBatis-Plus核心库,简化数据库操作 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus</artifactId>
<version>3.5.7</version>
</dependency>
<!-- Spring Boot Web Starter,提供REST API支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- MyBatis-Plus与Spring Boot 3整合启动器 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.7</version>
</dependency>
<!-- Hutool工具库,提供各种便捷工具方法 -->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.25</version>
</dependency>
<!-- JWT库,用于生成和验证Token -->
<dependency>
<groupId>com.auth0</groupId>
<artifactId>java-jwt</artifactId>
<version>4.4.0</version>
</dependency>
<!-- Jakarta Servlet API,Web开发需要 -->
<dependency>
<groupId>jakarta.servlet</groupId>
<artifactId>jakarta.servlet-api</artifactId>
<version>6.0.0</version>
<scope>provided</scope>
</dependency>
<!-- Jakarta Persistence API -->
<dependency>
<groupId>jakarta.persistence</groupId>
<artifactId>jakarta.persistence-api</artifactId>
<version>3.2.0</version>
</dependency>
<!-- Spring Boot邮件发送支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
<version>3.3.0</version>
</dependency>
<!-- Knife4j API文档,基于OpenAPI 3 -->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>4.3.0</version>
</dependency>
<!-- Spring Boot测试 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<!-- 使用阿里云Maven镜像,加速依赖下载 -->
<repositories>
<repository>
<id>aliyunmaven</id>
<name>aliyun</name>
<url>https://maven.aliyun.com/repository/public</url>
</repository>
</repositories>
<build>
<plugins>
<!-- Spring Boot Maven打包插件 -->
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
3. 创建项目包结构

4. 配置 application.properties
# ========== 项目基础配置 ==========
# 应用名称
spring.application.name=springboot
# 上下文路径
server.servlet.context-path=/
# 静态资源路径
spring.mvc.static-path-pattern=/**
# 服务器端口号
server.port=1234
# 静态资源位置
spring.web.resources.static-locations=classpath:/static/
# MyBatis XML映射文件位置
mybatis-plus.mapper-locations=classpath:/mapper/*.xml
# JSON序列化时忽略空值
spring.jackson.default-property-inclusion=non_empty
# ========== 文件上传配置 ==========
# 启用文件上传
spring.servlet.multipart.enabled=true
# 单个文件最大10MB
spring.servlet.multipart.max-file-size=10MB
# 请求最大10MB
spring.servlet.multipart.max-request-size=10MB
# ========== 数据库配置 ==========
# MySQL驱动类
spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver
# 数据库连接地址(hadoop是虚拟机主机名,映射到虚拟机IP)
spring.datasource.url=jdbc:mysql://hadoop:3306/op_uniqlo_db?useUnicode=true&characterEncoding=utf8&allowMultiQueries=true&useSSL=false&serverTimezone=GMT%2b8&allowPublicKeyRetrieval=true
#
数据库用户名
spring.datasource.username=root
# 数据库密码
spring.datasource.password=123456
# 开启驼峰命名映射(如user_name → userName)
mybatis.configuration.map-underscore-to-camel-case=true
mybatis.configuration.use-built-in-alias-types=true
# ========== API文档配置(Knife4j) ==========
knife4j.enable=true
knife4j.setting.language=zh_cn
knife4j.basic.enable=true
knife4j.basic.username=admin
knife4j.basic.password=admin
# ========== 用户默认密码 ==========
user.defaultPassword=123456(二)创建MySQL系统管理表
USE op_uniqlo_db;
-- 用户表
CREATE TABLE `user` (
id bigint NOT NULL AUTO_INCREMENT COMMENT '用户ID',
username varchar(64) COMMENT '用户名',
password varchar(255) COMMENT '密码(BCrypt加密)',
name varchar(64) COMMENT '真实姓名',
role varchar(64) DEFAULT 'USER' COMMENT '角色:ADMIN/USER',
email varchar(64) COMMENT '邮箱',
status int DEFAULT 1 COMMENT '状态:1启用,0禁用',
created_at timestamp DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updated_at timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更
新时间',
PRIMARY KEY (id),
UNIQUE KEY uk_username (username),
UNIQUE KEY uk_email (email)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 插入默认管理员(密码123456的BCrypt加密值)
INSERT INTO `user` (username, password, name, role, email, status)
VALUES ('admin', '$2a$10$N.zmdr9k7uOCQb376NoUnuTJ8iAt6Z5EHsM8lE9lBOsl7iKTVKIUi', '管理员',
'ADMIN', 'admin@qq.com', 1);
-- 菜单表
CREATE TABLE `menu` (
id int NOT NULL AUTO_INCREMENT COMMENT '菜单ID',
name varchar(64) COMMENT '菜单名称',
path varchar(64) COMMENT '菜单路径',
icon varchar(64) COMMENT '菜单图标',
description varchar(255) COMMENT '菜单描述',
pid int DEFAULT NULL COMMENT '父级菜单ID',
page_path varchar(64) COMMENT '页面路径',
sort_num int DEFAULT 0 COMMENT '排序号',
chart_type varchar(64) COMMENT '图表类型',
chart_color varchar(64) COMMENT '图表颜色',
table_column_name varchar(255) COMMENT '表格列名称',
table_column_value_one varchar(64) COMMENT '表格列数值1',
table_column_value_two varchar(64) COMMENT '表格列数值2',
role varchar(64) DEFAULT 'USER' COMMENT '菜单角色',
is_visible int DEFAULT 1 COMMENT '是否显示:1显示,0隐藏',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- 分类表
CREATE TABLE `category` (
id bigint NOT NULL AUTO_INCREMENT COMMENT '分类ID',
name varchar(64) COMMENT '分类名称',
icon varchar(64) COMMENT '分类图标',
description varchar(255) COMMENT '分类描述',
created_at timestamp DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
updated_at timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更
新时间',
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
(三)开发应用层
链接: https://pan.baidu.com/s/1_APpCKO2MczsxkDJCT_GJw 提取码: hm9p
(四)开发Service层
package org.example.bancked.service;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.StringUtils;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import jakarta.annotation.Resource;
import org.example.springboot.common.Result;
import org.example.springboot.entity.*;
import org.example.springboot.common.AccountStatus;
import org.example.springboot.mapper.*;
import org.example.springboot.util.JwtTokenUtils;
import org.example.springboot.util.MenusUtils;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.security.crypto.password.PasswordEncoder;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Resource
private UserMapper userMapper;
@Resource
private MenuMapper menuMapper;
// 从配置文件读取默认密码
@Value("${user.defaultPassword}")
private String DEFAULT_PWD;
// BCrypt密码加密器
@Resource
private PasswordEncoder bCryptPasswordEncoder;
/**
* 根据邮箱查询用户
*/
public User getByEmail(String email) {
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>
().eq(User::getEmail, email);
return userMapper.selectOne(wrapper);
}
/**
* 用户登录
* 1. 根据用户名查询用户
* 2. 校验账号是否禁用
* 3. BCrypt比对密码
* 4. 查询菜单并按角色分配
* 5. 生成JWT Token
*/
public Result<?> login(User user) {
// 根据用户名查询用户
User compare = getByUsername(user.getUsername());
if (compare == null) return Result.error("-1", "用户不存在");
// 检查账号是否被禁用
if (compare.getStatus().equals(AccountStatus.DISABLED.getValue()))
return Result.error("-1", "账号被禁用");
// 使用BCrypt验证密码
if (bCryptPasswordEncoder.matches(user.getPassword(), compare.getPassword())) {
// 查询所有菜单
List<Menu> roleMenuList = menuMapper.selectList(null);
// 根据用户角色分配可见菜单
compare.setMenuList(MenusUtils.allocMenus(roleMenuList, compare.getRole()));
// 生成JWT Token
String token = JwtTokenUtils.genToken(String.valueOf(compare.getId()),
compare.getPassword());
compare.setToken(token);
return Result.success(compare);
}
return Result.error("-1", "用户名或密码错误", null);
}
/** 根据角色查询用户列表 */
public List<User> getUserByRole(String role) {
LambdaQueryWrapper<User> queryWrapper = Wrappers.lambdaQuery();
queryWrapper.eq(User::getRole, role);
return userMapper.selectList(queryWrapper);
}
/**
* 创建新用户
* 返回值:>0成功,-1用户名已存在,-2邮箱已存在
*/
public int createUser(User user) {
// 校验用户名唯一性
if (userMapper.selectOne(new QueryWrapper<User>().eq("username",
user.getUsername())) != null) {
return -1;
}
// 校验邮箱唯一性
if (userMapper.selectOne(new LambdaQueryWrapper<User>().eq(User::getEmail,
user.getEmail())) != null) {
return -2;
}
// 密码为空则使用默认密码
user.setPassword(StringUtils.isNotBlank(user.getPassword()) ? user.getPassword() :
DEFAULT_PWD);
// BCrypt加密密码
user.setPassword(bCryptPasswordEncoder.encode(user.getPassword()));
// 设置默认角色和状态
user.setRole(StringUtils.isNotBlank(user.getRole()) ? user.getRole() : "USER");
user.setStatus(AccountStatus.ENABLED.getValue());
return userMapper.insert(user);
}
/** 根据ID删除用户 */
public boolean deleteUserById(Long id) {
return userMapper.deleteById(id) > 0;
}
/** 更新用户信息 */
public boolean updateUser(Long id, User user) {
user.setId(id);
return userMapper.updateById(user) > 0;
}
/** 根据用户名查询用户 */
public User getByUsername(String username) {
return userMapper.selectOne(new LambdaQueryWrapper<User>().eq(User::getUsername,
username));
}
/** 忘记密码:通过邮箱重置 */
public boolean forgetPassword(String email, String newPassword) {
User oldUser = userMapper.selectOne(new QueryWrapper<User>().eq("email", email));
if (oldUser != null) {
oldUser.setPassword(bCryptPasswordEncoder.encode(newPassword));
return userMapper.updateById(oldUser) > 0;
}
return false;
}
/** 修改密码:需验证旧密码 */
public boolean updatePassword(Long id, UserPasswordUpdate userPasswordUpdate) {
User oldUser = userMapper.selectById(id);
if (oldUser != null &&
bCryptPasswordEncoder.matches(userPasswordUpdate.getOldPassword(), oldUser.getPassword()))
{
oldUser.setPassword(bCryptPasswordEncoder.encode(userPasswordUpdate.getNewPassword()));
return userMapper.updateById(oldUser) > 0;
}
return false;
}
/** 批量删除用户 */
public boolean deleteBatch(List<Long> ids) {
return userMapper.deleteBatchIds(ids) > 0;
}
/** 查询所有用户 */
public List<User> getAllUsers() {
return userMapper.selectList(new QueryWrapper<>());
}
/** 根据ID查询用户(仅返回启用状态) */
public User getUserById(Long id) {
User user = userMapper.selectById(id);
if (user != null && user.getStatus().equals(AccountStatus.ENABLED.getValue())) {
return user;
}
return null;
/** 更新用户信息 */
public boolean updateUser(Long id, User user) {
user.setId(id);
return userMapper.updateById(user) > 0;
}
/** 根据用户名查询用户 */
public User getByUsername(String username) {
return userMapper.selectOne(new LambdaQueryWrapper<User>().eq(User::getUsername,
username));
}
/** 忘记密码:通过邮箱重置 */
public boolean forgetPassword(String email, String newPassword) {
User oldUser = userMapper.selectOne(new QueryWrapper<User>().eq("email", email));
if (oldUser != null) {
oldUser.setPassword(bCryptPasswordEncoder.encode(newPassword));
return userMapper.updateById(oldUser) > 0;
}
return false;
}
/** 修改密码:需验证旧密码 */
public boolean updatePassword(Long id, UserPasswordUpdate userPasswordUpdate) {
User oldUser = userMapper.selectById(id);
if (oldUser != null &&
bCryptPasswordEncoder.matches(userPasswordUpdate.getOldPassword(), oldUser.getPassword()))
{
oldUser.setPassword(bCryptPasswordEncoder.encode(userPasswordUpdate.getNewPassword()));
return userMapper.updateById(oldUser) > 0;
}
return false;
}
/** 批量删除用户 */
public boolean deleteBatch(List<Long> ids) {
return userMapper.deleteBatchIds(ids) > 0;
}
/** 查询所有用户 */
public List<User> getAllUsers() {
return userMapper.selectList(new QueryWrapper<>());
}
/** 根据ID查询用户(仅返回启用状态) */
public User getUserById(Long id) {
User user = userMapper.selectById(id);
if (user != null && user.getStatus().equals(AccountStatus.ENABLED.getValue())) {
return user;
}
return null;
package org.example.bancked.service;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.StringUtils;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import jakarta.annotation.Resource;
import org.example.springboot.common.Result;
import org.example.springboot.entity.Order;
import org.example.springboot.mapper.OrderMapper;
import org.springframework.stereotype.Service;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
public class OrderService {
@Resource
private OrderMapper orderMapper;
/** 创建订单数据 */
public Result<?> createOrder(Order order) {
int result = orderMapper.insert(order);
return result > 0 ? Result.success(order) : Result.error("-1", "创建失败");
}
/** 更新订单数据 */
public Result<?> updateOrder(Integer id, Order order) {
order.setId(id);
int result = orderMapper.updateById(order);
return result > 0 ? Result.success(order) : Result.error("-1", "更新失败");
}
/** 删除订单数据 */
public Result<?> deleteOrder(Integer id) {
return orderMapper.deleteById(id) > 0 ? Result.success() : Result.error("-1", "删除
失败");
}
/** 根据ID获取订单详情 */
public Result<?> getOrderById(Integer id) {
Order order = orderMapper.selectById(id);
return order != null ? Result.success(order) : Result.error("-1", "未找到订单");
}
/**
* 分页查询订单数据,支持多条件筛选
* storeId和city使用LIKE模糊查询,gender和age使用精确匹配
*/
public Page<Order> getOrdersByPage(String storeId, String city, String gender, String
age, Integer currentPage, Integer size) {
LambdaQueryWrapper<Order> queryWrapper = Wrappers.lambdaQuery();
if (StringUtils.isNotBlank(storeId)) {
queryWrapper.like(Order::getStoreId, storeId); // 模糊查询
}
if (StringUtils.isNotBlank(city)) {
queryWrapper.like(Order::getCity, city); // 模糊查询
}
if (StringUtils.isNotBlank(gender)) {
queryWrapper.eq(Order::getGender, gender); // 精确匹配
}
if (StringUtils.isNotBlank(age)) {
queryWrapper.eq(Order::getAge, age); // 精确匹配
}
queryWrapper.orderByDesc(Order::getId); // 按ID倒序
Page<Order> page = new Page<>(currentPage, size);
return orderMapper.selectPage(page, queryWrapper);
}
/** 批量删除订单 */
public Result<?> deleteBatch(List<Integer> ids) {
return orderMapper.deleteBatchIds(ids) > 0 ? Result.success() : Result.error("-1",
"删除失败");
}
/** 获取全部订单数据 */
public List<Order> getAllOrders() {
return orderMapper.selectList(null);
}
/** 查询前8条订单数据 */
public Result<?> getTop10Orders() {
LambdaQueryWrapper<Order> wrapper = Wrappers.lambdaQuery();
wrapper.orderByDesc(Order::getId).last("limit 8");
return Result.success(orderMapper.selectList(wrapper));
}
/** 获取订单统计数据(总量、门店数、销售额、利润、城市数) */
public Map<String, Object> getOrderStatistics() {
Map<String, Object> stats = new HashMap<>();
stats.put("totalCount", orderMapper.selectCount(null));
// 其他统计通过自定义SQL查询
return stats;
}
}
package org.example.bancked.service;
import jakarta.annotation.Resource;
import org.example.springboot.mapper.StatisticsMapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
/**
* 统计分析服务类
* 每个方法处理城市参数:将逗号分隔的城市字符串拆分为List
* 传递给StatisticsMapper进行带城市筛选的SQL查询
*/
@Service
public class StatisticsService {
private static final Logger LOGGER = LoggerFactory.getLogger(StatisticsService.class);
@Resource
private StatisticsMapper statisticsMapper;
/** 性别消费分析 */
public List<Map<String, Object>> getGenderPriceAnalysis(String city) {
try {
// 将逗号分隔的城市字符串拆分为List,如"杭州,上海" → ["杭州","上海"]
List<String> cityList = null;
if (city != null && !city.trim().isEmpty()) {
cityList = Arrays.asList(city.split(","));
}
List<Map<String, Object>> result =
statisticsMapper.getGenderPriceAnalysis(city, cityList);
LOGGER.info("获取性别消费分析成功,共{}条记录", result.size());
return result;
} catch (Exception e) {
LOGGER.error("获取性别消费分析失败: {}", e.getMessage());
return List.of();
}
}
/** 年龄消费分析 */
public List<Map<String, Object>> getAgePriceAnalysis(String city) {
try {
List<String> cityList = null;
if (city != null && !city.trim().isEmpty()) {
cityList = Arrays.asList(city.split(","));
}
return statisticsMapper.getAgePriceAnalysis(city, cityList);
} catch (Exception e) {
LOGGER.error("获取年龄消费分析失败: {}", e.getMessage());
return List.of();
}
}
/** 性别产品消费分析 */
public List<Map<String, Object>> getGenderProductPriceAnalysis(String city) {
try {
List<String> cityList = null;
if (city != null && !city.trim().isEmpty()) {
cityList = Arrays.asList(city.split(","));
}
return statisticsMapper.getGenderProductPriceAnalysis(city, cityList);
} catch (Exception e) {
LOGGER.error("获取性别产品消费分析失败: {}", e.getMessage());
return List.of();
}
}
/** 产品销售分析 */
public List<Map<String, Object>> getProductSalesAnalysis(String city) {
try {
List<String> cityList = null;
if (city != null && !city.trim().isEmpty()) {
cityList = Arrays.asList(city.split(","));
}
return statisticsMapper.getProductSalesAnalysis(city, cityList);
} catch (Exception e) {
LOGGER.error("获取产品销售分析失败: {}", e.getMessage());
return List.of();
}
}
/** 产品销量分析 */
public List<Map<String, Object>> getProductCountAnalysis(String city) {
try {
List<String> cityList = null;
if (city != null && !city.trim().isEmpty()) {
cityList = Arrays.asList(city.split(","));
}
return statisticsMapper.getProductCountAnalysis(city, cityList);
} catch (Exception e) {
LOGGER.error("获取产品销量分析失败: {}", e.getMessage());
return List.of();
}
}
/** 产品单价分析 */
public List<Map<String, Object>> getProductUnitPriceAnalysis(String city) {
try {
List<String> cityList = null;
if (city != null && !city.trim().isEmpty()) {
cityList = Arrays.asList(city.split(","));
}
return statisticsMapper.getProductUnitPriceAnalysis(city, cityList);
} catch (Exception e) {
LOGGER.error("获取产品单价分析失败: {}", e.getMessage());
return List.of();
}
}
/** 产品利润分析 */
public List<Map<String, Object>> getProductProfitAnalysis(String city) {
try {
List<String> cityList = null;
if (city != null && !city.trim().isEmpty()) {
cityList = Arrays.asList(city.split(","));
}
return statisticsMapper.getProductProfitAnalysis(city, cityList);
} catch (Exception e) {
LOGGER.error("获取产品利润分析失败: {}", e.getMessage());
return List.of();
}
}
/** 月份利润分析 */
public List<Map<String, Object>> getMonthlyProfitAnalysis(String city) {
try {
List<String> cityList = null;
if (city != null && !city.trim().isEmpty()) {
cityList = Arrays.asList(city.split(","));
}
return statisticsMapper.getMonthlyProfitAnalysis(city, cityList);
} catch (Exception e) {
LOGGER.error("获取月份利润分析失败: {}", e.getMessage());
return List.of();
}
}
}
package org.example.springboot.service;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import org.example.springboot.entity.User;
import org.example.springboot.mapper.UserMapper;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.core.userdetails.UserDetailsService;
import org.springframework.security.core.userdetails.UsernameNotFoundException;
import org.springframework.stereotype.Service;
import jakarta.annotation.Resource;
/**
* Spring Security用户详情服务实现
* 用于Security框架加载用户信息进行认证
*/
@Service
public class UserDetailServiceImpl implements UserDetailsService {
@Resource
private UserMapper userMapper;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException
{
User user = userMapper.selectOne(new LambdaQueryWrapper<User>
().eq(User::getUsername, username));
if (user == null) {
throw new UsernameNotFoundException("用户不存在");
}
// 返回Spring Security的User对象
return org.springframework.security.core.userdetails.User
.withUsername(user.getUsername())
.password(user.getPassword())
.roles(user.getRole())
.build();
}
}
(五)启动类添加MapperScan
package org.example.springboot;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
@MapperScan("org.example.springboot.mapper") // 扫描Mapper接口
public class SpringbootApplication {
public static void main(String[] args) {
SpringApplication.run(SpringbootApplication.class, args);
}
}
(六)启动后端测试
链接: https://pan.baidu.com/s/1MPjlSKk4B0LJZoJWqCsxUw 提取码: y7my
五、搭建Vue前端项目
(一)搭建环境
cd d:\uniqlo-system
# 使用Vue CLI创建Vue 2项目
vue create frontend
# 选择手动配置:
# ? Please pick a preset: Manually select features
# ? Check the features needed: Babel, Router, Vuex
# ? Choose a version: Vue 2
# ? Use history mode: Yes
# ? Pick a linter: ESLint
# ? Config: In dedicated config files 链接: https://pan.baidu.com/s/1lkstj4LVF0qZz9S-IdW4ww 提取码: pxxp

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)