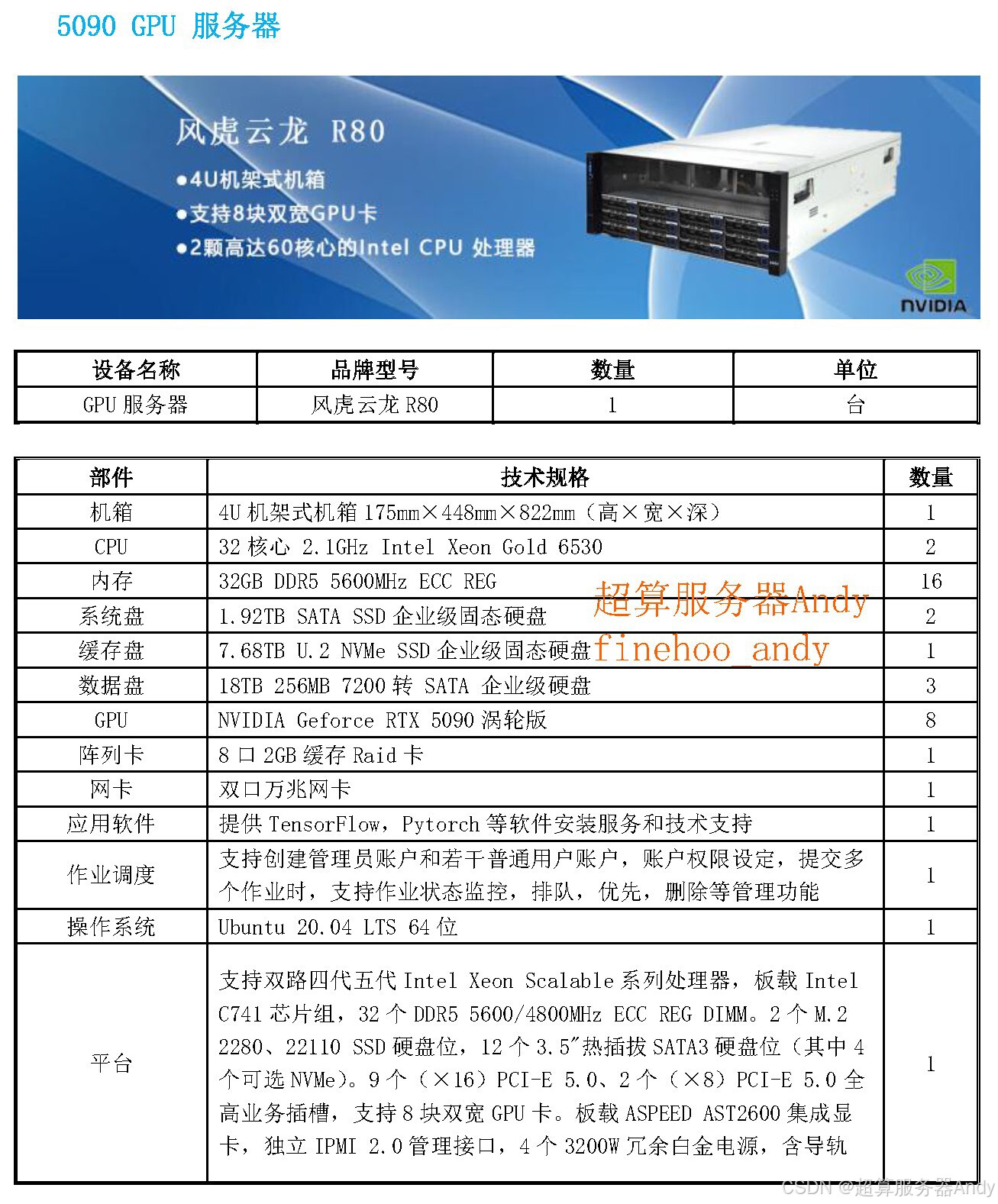
AI算力底层逻辑:CUDA、AI框架与行业硬件选型
硬件服务器是物理载体,CUDA是算力调度的底层基础,AI框架是模型开发与运行的核心工具,而硬件选型则是匹配不同业务场景的关键。三者相辅相成,决定了AI项目的运行效率、稳定性与落地效果。本文将以纯技术科普的角度,系统拆解三者的核心原理、适配规则与行业应用逻辑。
一、CUDA:AI算力运行的底层核心基石
CUDA是英伟达推出的通用并行计算平台与编程模型,是目前全球AI领域的底层算力标准。简单来说,绝大多数AI模型无法直接调用GPU算力,必须依托CUDA生态才能实现显卡的运算调度,这也是英伟达GPU垄断AI算力市场的核心原因。
1. CUDA核心生态组件
-
GPU驱动:实现操作系统与显卡的基础通信,识别硬件设备,保障显卡基础运行;
-
cuDNN:基于CUDA的神经网络专用加速库,针对AI模型的卷积、归一化等核心运算做了深度优化,大幅提升模型训练和推理速度。
CUDA版本具备严格的向下兼容性,高版本可兼容低版本模型与框架,低版本无法适配高版本生态,这是硬件与软件适配的核心原则,不同显卡对应专属适配版本:
-
经典算力卡(A10、T4、V100):稳定适配 CUDA 11.x 版本,兼容各类传统AI项目;
3. 关键特性与使用常识
二、主流AI框架:模型开发与运行的标准化工具
1. PyTorch:当下主流通用AI框架
核心适配场景:大语言模型(LLM)研发与微调、AIGC图文视频生成、前沿算法科研、AI初创项目开发。
2. TensorFlow:企业级稳定型框架
核心适配场景:工业视觉检测、安防图像分析、传统机器学习项目、企业级稳定AI落地场景。
3. PaddlePaddle(百度飞桨):国产自主AI框架
核心适配场景:政务AI项目、高校科研教学、国产化智能改造、医疗影像识别、传统行业智能化升级。
4. 核心辅助工具
-
ONNX:通用模型格式,可实现不同AI框架模型的互相转换,解决模型跨平台、跨框架适配问题,广泛应用于模型部署与推理场景。
AI业务核心分为模型训练与模型推理两大类型,两类业务的算力需求差异极大:训练侧重超大显存、高算力、多卡互联能力;推理侧重高并发、低延迟、稳定性与性价比。结合行业场景,硬件选型有明确的标准化适配逻辑。
核心业务:千亿/百亿参数模型预训练、模型微调、私有化部署、智能问答API服务
硬件适配:大规模模型训练需H800、A800高端算力卡,依托多卡NVLink互联技术实现分布式训练;中小模型微调与轻量化推理可选用L20、A10显卡;线上高并发推理优先低功耗、高性价比的L4显卡。整机需搭配大内存、高速NVMe存储,满足大模型加载与运算需求。
核心业务:文生图、图生视频、AI数字人生成、短视频智能剪辑、批量创意内容生成
硬件适配:该场景高度依赖视频编解码能力与并发算力,主流适配L4、A10显卡,兼顾低功耗与高并发性能;高端批量创作场景可选用L20、RTX专业图形算力卡,满足高精度、高效率的内容生成需求。
核心业务:AI算法研究、数理仿真计算、教学实训、各类科研课题实验
硬件适配:通用科研场景以A10、L20为主,通用性极强,可兼顾算法训练、仿真计算、教学实训等多类任务;高能物理、流体仿真等高精度计算场景,需选用A800显卡,满足高双精度算力需求;基础教学场景可选用入门级算力设备,控制硬件成本。
核心业务:安防视觉分析、医疗影像识别、政务智能风控、工业质检、国产化智能改造
硬件适配:该场景核心需求是7×24小时稳定运行、合规可靠。安防、工业高并发视觉场景适配L4、T4显卡;医疗影像、高精度质检场景选用A10显卡;国产化改造项目优先适配兼容国产生态的通用算力硬件,保障项目合规落地。
核心业务:自动驾驶路测数据训练、虚拟场景仿真、环境感知模型迭代、工业数值模拟
硬件适配:仿真与自动驾驶训练对算力精度、设备稳定性要求极高,长期满负载运行场景优先H800、A800高端算力卡;大规模集群仿真需搭配IB高速网络与液冷散热方案,保障多设备协同运算的效率与稳定性。
CUDA是AI算力的底层运行基础,决定硬件与软件的适配上限;AI框架是业务落地的核心工具,不同框架对应不同的行业场景与算力需求;而硬件选型的核心逻辑,是根据训练/推理业务属性、模型规模、生态版本、行业场景匹配对应的算力硬件,在稳定性、性能与适配性之间实现最优平衡。三者深度绑定,是人工智能项目高效落地、稳定运行的核心底层逻辑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)