RabbitMq快速理解
一文看懂 RabbitMQ:从基础概念、工作原理到实际应用
前言
在后端系统中,消息队列是非常常见的中间件。比如用户下单后,需要扣库存、发优惠券、发送短信、写日志、通知商家。如果这些操作全部放在一个接口里同步执行,接口会变慢,而且某个步骤失败还可能影响主流程。
RabbitMQ 就是用来解决这类问题的消息队列中间件。它可以把一些耗时、不需要立即完成的任务拆出去异步处理,提高系统吞吐量和稳定性。
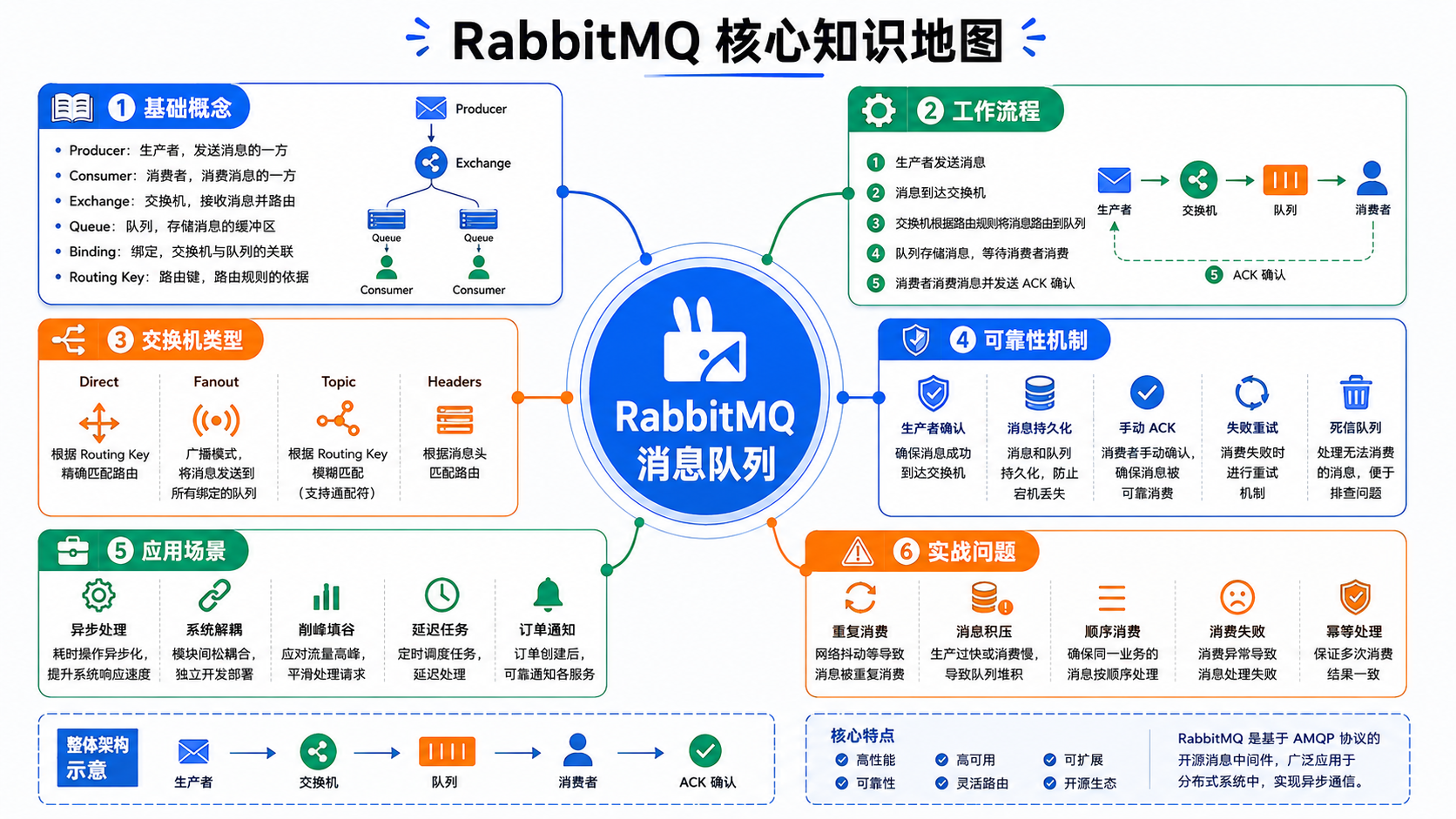
这篇文章主要介绍 RabbitMQ 的核心概念、工作原理、常见模式和实际开发中需要注意的问题。
一、RabbitMQ 是什么?
RabbitMQ 是一个开源消息队列中间件,基于 AMQP 协议实现。
简单理解,RabbitMQ 就像一个“消息中转站”:
- 生产者负责发送消息。
- RabbitMQ 负责存储和转发消息。
- 消费者负责处理消息。
例如用户下单成功后,订单服务可以发送一条消息:
用户 1001 购买商品 2001,下单成功然后库存服务、积分服务、短信服务可以分别消费这条消息,完成各自的业务逻辑。
这样做的好处是:
- 降低系统之间的耦合。
- 提高接口响应速度。
- 削峰填谷,缓解高并发压力。
- 支持失败重试和异步补偿。
二、为什么需要消息队列?
消息队列主要解决三个问题。
1. 异步处理
有些操作不需要立刻完成,可以放到后台慢慢处理。
比如下单接口中:
创建订单 -> 扣库存 -> 发短信 -> 加积分 -> 写日志如果全部同步执行,用户要等所有步骤完成才能拿到响应。
使用 RabbitMQ 后,可以改成:
创建订单成功 -> 发送消息 -> 立即返回后续短信、积分、日志等操作由消费者异步处理。
2. 系统解耦
没有消息队列时,订单服务可能要直接调用库存服务、短信服务、积分服务。
这样会导致订单服务依赖太多系统。如果短信服务临时不可用,可能影响订单主流程。
使用 RabbitMQ 后,订单服务只需要发送消息,不需要关心后面有多少系统消费消息。
3. 削峰填谷
在秒杀、抢购、优惠券发放等场景中,瞬时请求量可能非常大。
如果所有请求直接打到数据库,数据库很容易被压垮。
使用 RabbitMQ 后,可以把请求先放入队列,消费者按照自己的处理能力慢慢消费,从而保护下游系统。
三、RabbitMQ 核心概念
RabbitMQ 中有几个非常重要的概念。
1. Producer:生产者
生产者负责发送消息。
比如订单服务、支付服务、用户服务都可以作为生产者,把业务事件发送到 RabbitMQ。
2. Consumer:消费者
消费者负责接收并处理消息。
比如短信服务消费“订单创建成功”消息后发送短信,积分服务消费后增加积分。
3. Queue:队列
队列用于存放消息。
生产者发送的消息最终会进入队列,消费者从队列中取消息进行处理。
4. Exchange:交换机
交换机负责接收生产者发送的消息,并根据规则把消息路由到不同队列。
生产者一般不是直接把消息发给队列,而是先发给交换机。
5. Binding:绑定关系
Binding 表示交换机和队列之间的绑定规则。
交换机收到消息后,会根据 Binding 和 Routing Key 判断消息应该进入哪个队列。
6. Routing Key:路由键
Routing Key 是消息的路由标识。
例如:
order.created
order.paid
order.cancelled不同的 Routing Key 可以把消息路由到不同队列。
四、RabbitMQ 的工作流程
一个典型流程如下:
生产者 Producer
↓
交换机 Exchange
↓
绑定关系 Binding
↓
队列 Queue
↓
消费者 Consumer例如:
- 订单服务发送一条
order.created消息。 - 消息先进入 Exchange。
- Exchange 根据 Routing Key 找到匹配的 Queue。
- 消息进入队列。
- 消费者从队列中取出消息并处理。
五、Exchange 的四种常见类型
1. Direct Exchange
Direct Exchange 根据 Routing Key 精确匹配。
例如:
Routing Key = order.created只有绑定了 order.created 的队列才能收到消息。
适合场景:
- 订单创建。
- 支付成功。
- 用户注册。
- 单一明确事件通知。
2. Fanout Exchange
Fanout Exchange 不看 Routing Key,会把消息广播给所有绑定的队列。
适合场景:
- 广播通知。
- 配置刷新。
- 多系统同时接收同一事件。
例如订单创建成功后,短信、积分、日志三个队列都需要收到消息。
3. Topic Exchange
Topic Exchange 支持通配符匹配。
常见通配符:
* 匹配一个单词
# 匹配零个或多个单词例如:
order.*可以匹配:
order.created
order.paid而:
order.#可以匹配:
order.created
order.paid.success
order.cancelled.timeout适合场景:
- 多类型业务事件。
- 日志分类。
- 复杂消息路由。
4. Headers Exchange
Headers Exchange 根据消息头匹配,不依赖 Routing Key。
实际业务中使用较少,更多时候 Direct、Fanout、Topic 已经够用。
六、RabbitMQ 如何保证消息可靠?
在实际项目中,最重要的问题不是“能不能发消息”,而是“消息能不能可靠地发到、存住、消费掉”。
主要从三个阶段保证。
1. 生产者确认机制
生产者发送消息后,需要知道消息是否成功到达 RabbitMQ。
RabbitMQ 提供 Confirm 机制,生产者可以收到确认结果。
如果发送失败,可以记录日志、重试,或者落库等待补偿。
2. 消息持久化
为了避免 RabbitMQ 宕机导致消息丢失,需要开启持久化。
一般包括:
- Exchange 持久化。
- Queue 持久化。
- Message 持久化。
只有三者配合,消息可靠性才更完整。
3. 消费者手动确认
消费者处理消息后,需要告诉 RabbitMQ:
这条消息我已经处理成功了如果消费者还没处理完就宕机,RabbitMQ 可以重新投递消息。
所以实际项目中,一般推荐使用手动 ACK,而不是自动 ACK。
七、死信队列
死信队列是 RabbitMQ 中非常重要的机制。
当消息出现以下情况时,可能会变成死信:
- 消息被消费者拒绝。
- 消息超过 TTL 过期时间。
- 队列达到最大长度。
- 消费失败并且不再重新入队。
死信消息会被转发到死信交换机,再进入死信队列。
死信队列常用于:
- 消费失败记录。
- 异常消息排查。
- 延迟任务。
- 失败补偿。
八、延迟队列
RabbitMQ 本身没有直接的普通延迟队列概念,但可以通过 TTL + 死信队列实现。
例如订单超时未支付自动取消:
- 用户创建订单。
- 发送一条消息到延迟队列,TTL 设置为 30 分钟。
- 30 分钟后消息过期。
- 消息进入死信队列。
- 消费者检查订单是否已支付。
- 如果未支付,则取消订单。
这种方式适合:
- 订单超时取消。
- 优惠券到期提醒。
- 定时通知。
- 延迟重试。
九、Spring Boot 集成 RabbitMQ 示例
1. 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>2. 配置连接信息
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
publisher-confirm-type: correlated
publisher-returns: true
listener:
simple:
acknowledge-mode: manual3. 声明交换机、队列和绑定关系
@Configuration
public class RabbitConfig {
public static final String ORDER_EXCHANGE = "order.exchange";
public static final String ORDER_QUEUE = "order.queue";
public static final String ORDER_ROUTING_KEY = "order.created";
@Bean
public DirectExchange orderExchange() {
return new DirectExchange(ORDER_EXCHANGE, true, false);
}
@Bean
public Queue orderQueue() {
return QueueBuilder.durable(ORDER_QUEUE).build();
}
@Bean
public Binding orderBinding() {
return BindingBuilder
.bind(orderQueue())
.to(orderExchange())
.with(ORDER_ROUTING_KEY);
}
}4. 生产者发送消息
@Service
public class OrderProducer {
@Autowired
private RabbitTemplate rabbitTemplate;
public void sendOrderMessage(String orderId) {
rabbitTemplate.convertAndSend(
RabbitConfig.ORDER_EXCHANGE,
RabbitConfig.ORDER_ROUTING_KEY,
orderId
);
}
}5. 消费者监听消息
@Component
public class OrderConsumer {
@RabbitListener(queues = RabbitConfig.ORDER_QUEUE)
public void handleMessage(String orderId, Channel channel, Message message) throws IOException {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
System.out.println("处理订单消息:" + orderId);
// 业务处理成功后手动确认
channel.basicAck(deliveryTag, false);
} catch (Exception e) {
// 处理失败,可以选择重新入队或进入死信队列
channel.basicNack(deliveryTag, false, false);
}
}
}十、实际项目中的注意点
1. 消息重复消费
RabbitMQ 只能尽量保证消息可靠投递,但不能完全避免重复消费。
所以消费者业务逻辑必须保证幂等。
常见做法:
- 使用业务唯一 ID。
- 消费前查询是否已处理。
- 使用 Redis 去重。
- 数据库加唯一索引。
- 记录消息消费日志。
2. 消息积压
如果生产速度远大于消费速度,就会出现消息积压。
解决方式:
- 增加消费者数量。
- 优化消费者处理逻辑。
- 批量消费。
- 拆分队列。
- 对慢 SQL、外部接口进行优化。
3. 消息顺序问题
RabbitMQ 可以在单队列、单消费者情况下保证顺序,但如果多个消费者并发消费,就很难保证全局顺序。
如果业务强依赖顺序,可以考虑:
- 同一业务 ID 路由到同一队列。
- 单队列单消费者处理。
- 在业务层做状态校验。
- 尽量减少对严格顺序的依赖。
4. 消费失败重试
消费失败不能无限重试,否则会阻塞正常消息。
常见做法:
- 设置最大重试次数。
- 超过次数进入死信队列。
- 记录失败原因。
- 后台人工处理或定时补偿。
5. 不要把 RabbitMQ 当数据库用
RabbitMQ 是消息中间件,不适合长期存储大量业务数据。
业务状态应该落在数据库中,消息队列只负责异步传递事件。
十一、RabbitMQ 适合哪些场景?
RabbitMQ 适合:
- 订单异步处理。
- 短信、邮件通知。
- 日志收集。
- 支付结果通知。
- 秒杀削峰。
- 延迟任务。
- 系统解耦。
- 失败重试和补偿。
不太适合:
- 超大规模日志流处理。
- 对吞吐要求极高的大数据场景。
- 长期消息存储。
- 强事务一致性场景。
如果是高吞吐日志、大数据流处理,Kafka 会更常见;如果是业务系统异步解耦,RabbitMQ 使用起来更灵活。
总结
RabbitMQ 的核心价值是异步解耦和削峰填谷。
它通过 Producer、Exchange、Queue、Binding、Consumer 这些组件完成消息投递,通过生产者确认、消息持久化、消费者手动 ACK、死信队列等机制保证消息可靠性。
在真实项目中,使用 RabbitMQ 不能只关注“消息能不能发出去”,更要关注:
- 消息会不会丢?
- 消费失败怎么办?
- 重复消费怎么处理?
- 消息积压怎么排查?
- 业务是否具备幂等性?
真正把这些问题考虑清楚,RabbitMQ 才能在系统中稳定发挥作用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)