语义工程-01.AI时代为什么语义层不可或缺?
引子:
到2026年,几乎所有企业数据平台都声称拥有某种“语义层”。Palantir公司有Foundry,Snowflake有其YAML语义模型,微软有Fabric IQ,Databricks有Unity Catalog,Salesforce有数据模型对象。
那么,什么是语义层?它为什么成为AI时代不可或缺的架构组件?本文将带你了解语义层的来龙去脉,并解释为什么在AI时代它如此重要。
正文:
什么是语义层?
语义层是位于源数据和数据使用者之间的一层业务抽象层。
语义层负责解释数据的含义,它把数据库(表、列、连接)转换为易于理解的业务概念(收入、客户生命周期价值、活跃用户)。
语义层传统上是BI时代的工具层,如今正成为AI架构的关键基础设施。
语义层进化史
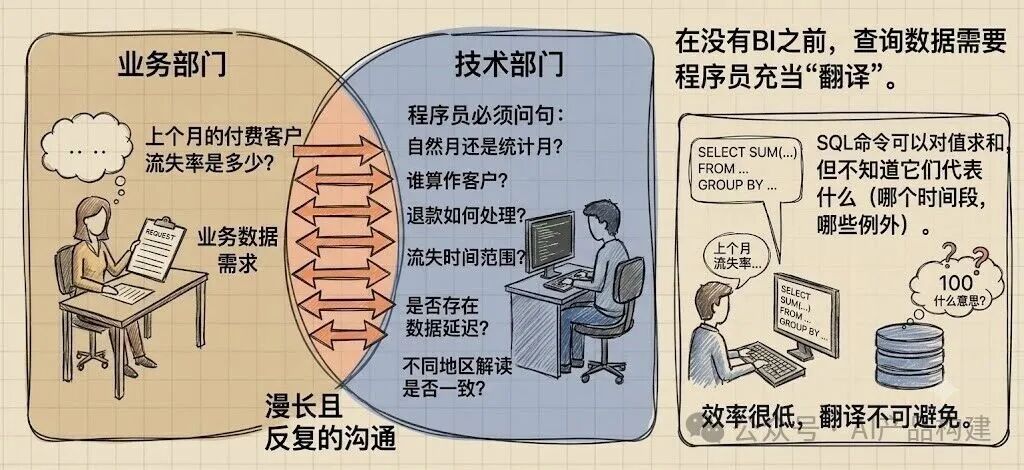
BI之前:手工古法取数
在没有BI之前,查询数据需要程序员协助你完成。
一个典型业务查询需求是:“上个月的付费客户流失率是多少?”。
为此,程序员需要向业务人员反复确认:
-
是自然月还是统计月?
-
谁算作客户?
-
退款如何处理?
-
如何计算客户流失的时间范围?
-
是否存在数据延迟?
-
不同地区对客户流失的解读是否一致?
然后程序员编写SQL完成查询。
这个阶段效率很低,反复的沟通几乎不可避免。
关键在于 SQL 操作的是行和数字。SQL命令可以对值求和,但它并不知道这些值代表什么,它们属于哪个时间段,或者存在哪些例外情况。
这个阶段,程序员充当了“翻译”的角色,把业务查询需求转化为SQL语言。
BI时代:自助查询+语义层
后来有了BI,企业进入了自助查询阶段,或者说可视化查询阶段。
真正的转变在于我们不再是直接对数据库查询,而是通过可视化界面进行操作。
这个阶段,数据分析师充当了“翻译”的角色,他把业务查询需求转化为业务模型所需要的UI操作。
数据分析师根据业务模型选择合适的指标和维度,通过点击界面上的菜单就可以完成查询,因为业务模型和 SQL 查询语言已经通过代码进行了关联。
例如,当你点击BI界面上的“客户流失率和上月”后,代码会自动对数据库的Customer表、Order表进行关联、过滤和聚合并返回结果。
正因如此,数据在管理层层面才变得可复现:无论查询如何,相同的数字都代表相同的含义。
看似可视化的功能,在系统内部实际上是一种使自然语言与SQL查询语言相符的机制,这就是语义模型。
语义模型捕获组织共识(如“每月经常性收入、客户流失率、日活跃用户数、客户获取成本”),并将这些共识建模为业务指标和维度:
1. 指标 — 每个指标都有精确的定义:使用哪个表、哪个聚合、使用哪些筛选条件、使用哪个时间维度。只需定义一次,即可在所有地方一致使用。
2. 维度 — 用于对指标进行切片的轴。例如:区域、产品层级、客户细分、队列月份。
起初,这个语义模型是作为BI工具存在的。
试想一下,一家公司它可能同时运行多个BI工具。财务部门使用 Power BI,因为它与 Excel 紧密集成。市场营销团队偏爱 Tableau,因为它提供了更强大的可视化功能。产品团队使用 Python Notebook 分析用户行为。工程师则构建自己的分析服务,并通过 API 对外开放。
这些工具都从数据仓库获取数据,但各自以不同的方式解读数据。如果数据模型没有集中管理,最终得到的不是统一的结果,而是一系列对同一数据的互不关联的解读。 我们开始认识到:语义模型不应该存在于BI工具内部。
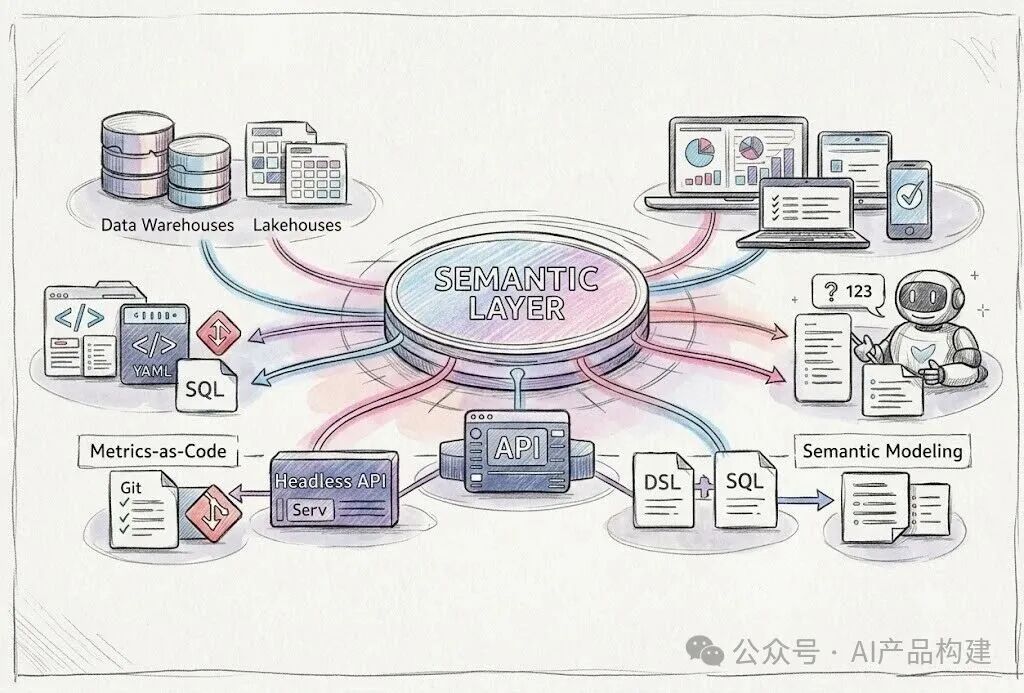
最终,一个独立的语义层诞生了,以下概括了它的主要特点:
-
单一事实来源:负责解释数据的含义,而不是可视化;
-
指标集中管理:允许数据分析师定义指标、维度、筛选器、表之间的关系以及其他业务逻辑元素,用户可以看到一致的定义;
-
统一建模:语义模型捕获企业的业务共识并存储在单独的服务或存储库中,可以同时供多个系统使用;
-
指标即代码:在版本控制系统(例如 Git)中进行变更关联,每一次更改都应该像其他代码修改一样经过审查流程。
AI时代:自动化查询+语义层
在AI时代,Agent成为数据的使用者,而非数据分析师。 转折点在于数据的新“用户”不再是人,而是机器。
我们期待的结果是:用户用自然语言提问,经过训练的Agent编写 SQL 语句,然后返回一个表格。
一切似乎都很完美,我们一度以为语义层已经消失了,仿佛我们很快就可以实现自动化,然而实际结果并非如此。
在BI时代,指标的用户是数据分析师,我们依赖他们来查询数据——他们记住了季节性因素、例外情况和规则变更。 正是这种记忆确保了查询的正确性。 Agent没有这样的记忆:它不知道节假日、人口迁移、价格变动或部门间的协议。
对Agent来说,任何变化都只是统计偏差。
结果,它要么反应过度,要么错过真正重要的事件,因为它无法区分重要信息和噪声。 当同样的查询需求“上个月的付费客户流失率是多少?”被交给Agent时,它只能依赖数据结构和可能的模式。它会找到客户的最后活跃的日期,以“月”为时间间隔,然后统计那些不再活跃的客户数量。
从数据库的角度来看,这是一个完全合理的操作,在数学上也是正确的。但在公司内部,客户流失的定义可能取决于支付状态、用户群组和是否排除退款。
最后的结果大概率是错的:Agent 缺乏对“支付状态”中“0”和“1”具体定义的认知。 这为系统提出了新的要求,我们需要一个中间层——它不仅要描述事实,还要描述读取和使用这些事实的权限、规则和行为。
-
权限:谁可以访问这些数据?如区域经理无权跨区域访问其他区域的数据;
-
规则:数据的含义是什么?如支付状态中的“1”代表已支付,“0”代表未支付。
-
行为:数据可以干什么?如系统不仅要知道有多少客户流失,还要知道何时流失至关重要以及如何应对;
这不再是简单的数据描述,而是业务模型。
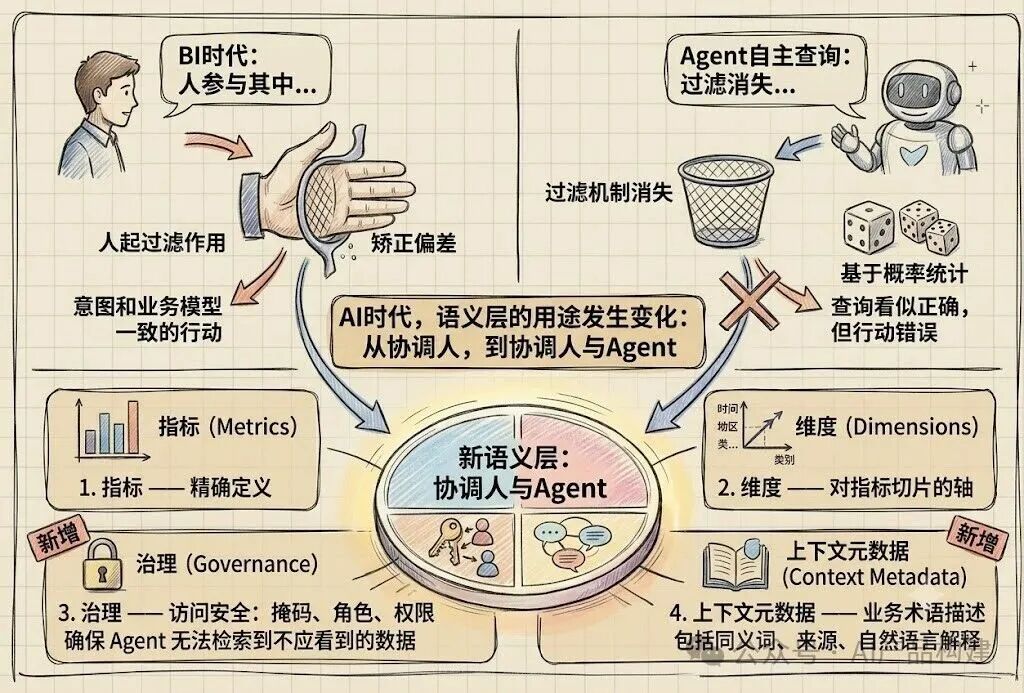
Agent的任务不仅需要理解用户查询意图,还要将查询意图和业务模型进行匹配。 在BI时代,只要有人参与其中,人就能起到过滤作用,纠正意图和业务模型之间的偏差。
当Agent开始自主查询时,这种过滤机制就消失了,系统开始基于概率统计训练的模型采取行动,最终会导致查询过程看似正确,但行动却错误的结果。
AI时代,语义层的用途发生了变化:它过去用于协调人,现在协调人与Agent。 为此我们需要一个新的语义层,它包括:
1. 指标 — 旧的功能。每个指标都有精确的定义。
2. 维度 — 旧的功能。用于对指标进行切片的轴。
3. 治理 ——新增功能。它定义访问安全,包括掩码、角色和权限。无论代理请求什么,它都无法检索到它不应该看到的数据。
4. 上下文元数据 ——新增功能。它为每个指标附加业务术语描述,包括同义词、来源和自然语言解释。
正是这个新的语义层使得Agent能够可靠地将 “我们的经常性收入是多少?” 与 monthly_recurring_revenue 指标匹配起来。
为什么AI时代需要一个语义层
在AI时代,如果没有语义层,Agent对数据查询的返回结果将会是:
- 不一致的
——同一个问题可能会得到不同的结果;
- 不受控制
——Agent可能会显示某些用户不应该看到的数据。
- 不可审计
——你无法追溯某个数字的含义;
- 不够健壮
——数据库模式(Schema)的更改会导致代理程序悄无声息地崩溃。
通过一个统一的语义层,可以解决这些问题:
-
指标的计算采用版本化的、受控的逻辑——每次结果都相同;
-
访问控制是集中管理且强制的,而非简单通过提示层即可执行;
-
每个答案都可以追溯到已定义、已记录的指标定义;
-
为数据库模式变更提供中间层,Agent 保持稳定。
语义层为Agent提供 唯一事实来源——减轻业务指标的错觉,确保治理,并提供从 AI 输出到版本化定义的可审计路径。
这是构建与企业数据交互的生产级Agent产品的基本模式:
用户查询 → Agent 识别意图 → Agent 查询语义层(指标,过滤器) → Agent 返回结构化结果 → Agent 推理 → 辅助决策
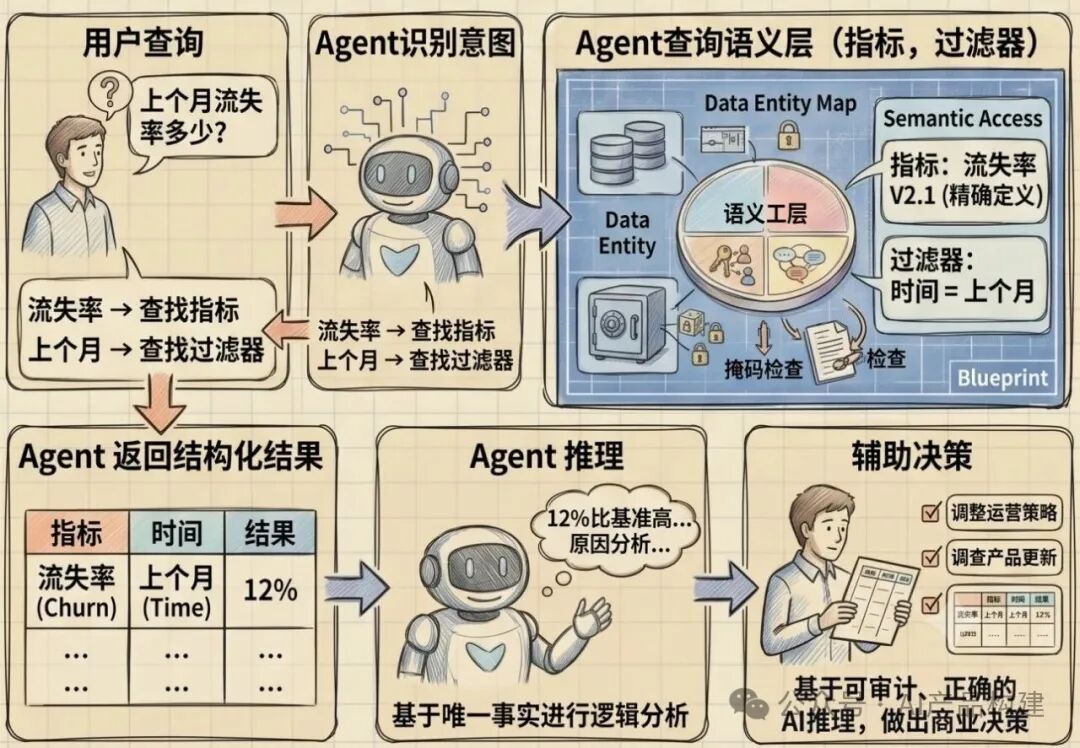
总结
语义层是架在源数据与数据使用者之间的业务抽象层,将数据库字段转化为“收入”“活跃用户”等可理解的概念。
从BI时代的自助查询到AI时代的自动化查询,它的核心始终是把业务共识固化为指标与维度;而在Agent自主查询的今天,语义层更需叠加治理与上下文元数据,成为确保结果一致、可控、可审计的唯一事实来源。
End

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)