山东大学项目实训个人纪实(2)——初步集成
这次项目的推进来到了关键的“初步集成”阶段。
首先是对后端的代码进行集成。随着后端组员完成了Prompt的调试与数据库的编写,我们开始使用Git合并代码。在集成的过程中,我们也总结出了两个至关重要的注意点,这算是团队协作中很宝贵的实践经验:
一是必须在 .gitignore 中把前端的UE项目排除掉,否则合并时极易发生项目覆盖的意外;
二是千万不能把大模型的 API-Key 直接上传到代码仓库中,密钥安全必须时刻警惕。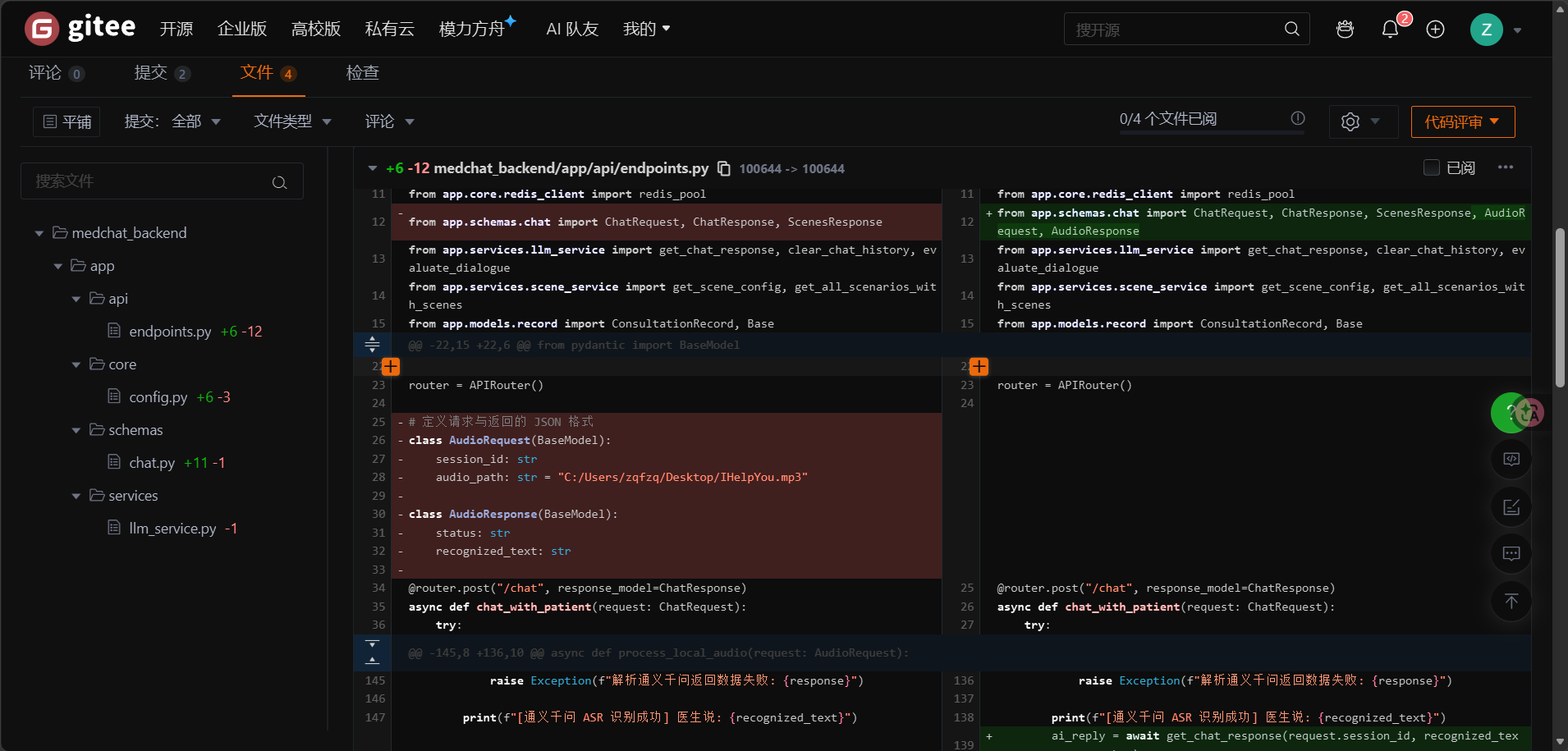
搞定后端集成后,我把精力主要投向了前端语音输入功能的编写。
我们尝试接入了阿里云百炼大模型API来进行音频的读取与处理。目前的整体数据流设计是这样的:前端通过UE的 AudioCapture 插件将用户的语音录制并保存到本地,后端读取该本地文件并调用大模型进行处理,最后通过FastAPI将AI生成的回复结果回传并输出到UE前端展示。
为了确保系统后续的性能表现,另一位前端同学此时正在尝试使用离线大模型来进行音频读取。后续我们计划对这两种方案进行性能测试,综合对比两者的响应速度与准确率,从而决定最终采用哪套技术路线。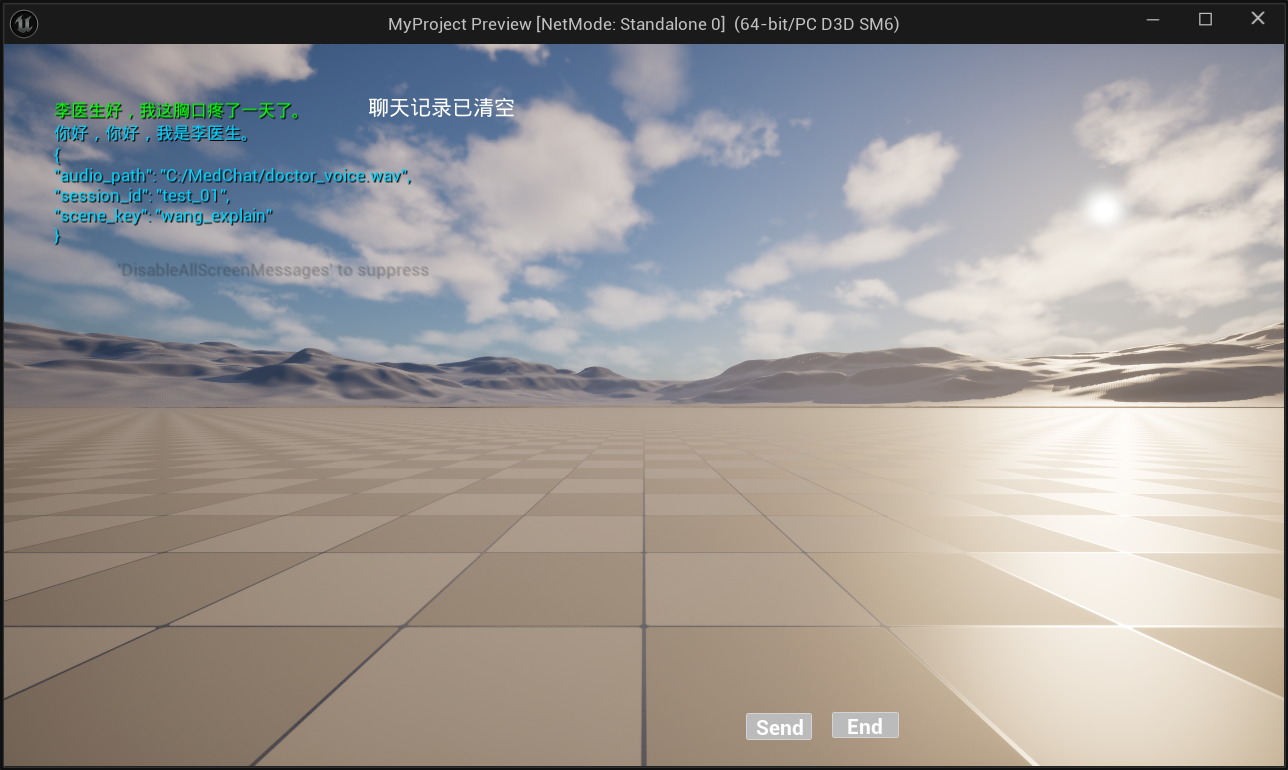
虽然初步集成的架子已经搭起来了,但看着接下来的工作清单,依然觉得挑战不小:
-
UI设计:需要尽快为聊天窗口和SEGUE评分量表制作出正式的UI页面。
-
场景与数字人:第一位数字人模型的调试以及诊室场景的搭建需要尽快收尾。
-
文字转语音(TTS):目前系统还只能“看”到AI的文字回复,后续还要实现语音输出,让整个医患对话的交互更加自然、真实。
-
降低延迟:目前整个语音输入、模型调用到结果回传的链路还存在延迟,如何进一步压缩响应时间、提升流畅度,是后续需要重点攻克的难题。
系统集成工作虽然琐碎,但看着各模块开始串联运行,还是让人觉得每一步的尝试都是值得的。继续推进,踏实做好下一步的优化。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)