向量引擎一跑就报错?DeepSeek API Key、deepseek base_url、Cursor/Dify/Chatbox 接入排错实战
Python 开发者半年踩坑复盘:把链路、知识库和常见 API 报错一次讲透
我做向量引擎、知识库和各种 AI 客户端接入这半年,最深的一条体会其实很简单:真正把项目卡住的,往往不是模型本身,而是链路没配对。
很多人一开始会把问题归结成“模型不稳定”“向量召回不准”“客户端抽风”,但我后来发现,绝大多数报错都能拆成四层:
- 认证层:
DeepSeek API Key对不对。 - 路由层:
deepseek base_url对不对。 - 执行层:模型名、流式参数、超时、代理、客户端协议对不对。
- 检索层:向量引擎的分段、Embedding、索引、召回、重排对不对。
只要把这四层分开看,很多原本像“玄学”的报错都会变得很具体。比如 Cursor 填了 Key 还是报错,Chatbox 一直超时,Dify 知识库明明建好了却搜不出内容,或者向量检索命中了文档,最后回答还是偏题。这些问题经常不是一个点坏了,而是两层甚至三层一起错位。
所以这篇我不想讲空话,也不想讲那种“先注册再开通再配置”的套路。我只讲我自己在 Python 里实际踩过的几个环节:
DeepSeek API Key怎么配才不容易出错。deepseek base_url到底应该怎么理解,官方接口、中转链路、客户端兼容层分别该怎么填。- Cursor、Chatbox、Dify 这三类常见入口怎么一步步接通。
- 向量引擎在 RAG 里最容易掉坑的地方是什么。
- 16 类高频
DeepSeek API报错,我实际是怎么定位和修的。
如果你现在的状态是“Key 也填了,地址也改了,还是不通”,那这篇基本就是按你的场景写的。
我更习惯把它理解成一套调试手记:先把链路跑起来,再谈优化;先把报错分层,再谈体验。
一、先把“向量引擎”和“模型接口”分开看
很多人第一次做向量引擎,容易把所有问题都归到“模型不行”上。其实向量引擎和大模型回答层,本来就是两件事。
我现在做项目时,脑子里一直放着这条链:
用户问题 -> 文本分段 -> 向量化 -> 索引 -> 召回 -> 重排 -> DeepSeek 生成 -> 客户端展示
这里面最容易混淆的,是“检索准确”和“回答漂亮”。
- 检索准确,主要看分段、Embedding、索引结构、召回参数、Top-K、阈值、元数据过滤。
- 回答漂亮,主要看模型、提示词、上下文长度、流式输出、
reasoning、客户端兼容性。
也就是说,向量引擎不是模型本身,但模型接口会直接影响用户体感;反过来,模型接口正常,也不代表向量引擎没问题。
我见过太多这样的场景:
- Cursor 能正常返回文本,但知识库问答一直偏题。
- Chatbox 连通了 DeepSeek,但长上下文一到就截断。
- Dify 模型供应商验证通过了,但知识库检索一跑就报向量层错误。
- Python 里
client.chat.completions.create()一直能通,实际业务却因为base_url、代理、模型名不一致,导致线上全是 400、401 或 422。
所以我自己的排错顺序永远是:
- 先测
API Key能不能完成最小请求。 - 再测
base_url能不能正确路由。 - 再测客户端是否用的是同一种协议。
- 最后才回到向量引擎本身。
这个顺序看着普通,但能节省很多时间。
因为一旦你先去怀疑向量算法,最后经常会发现只是 Key 前后多了一个空格,或者 base URL 少了一个协议头。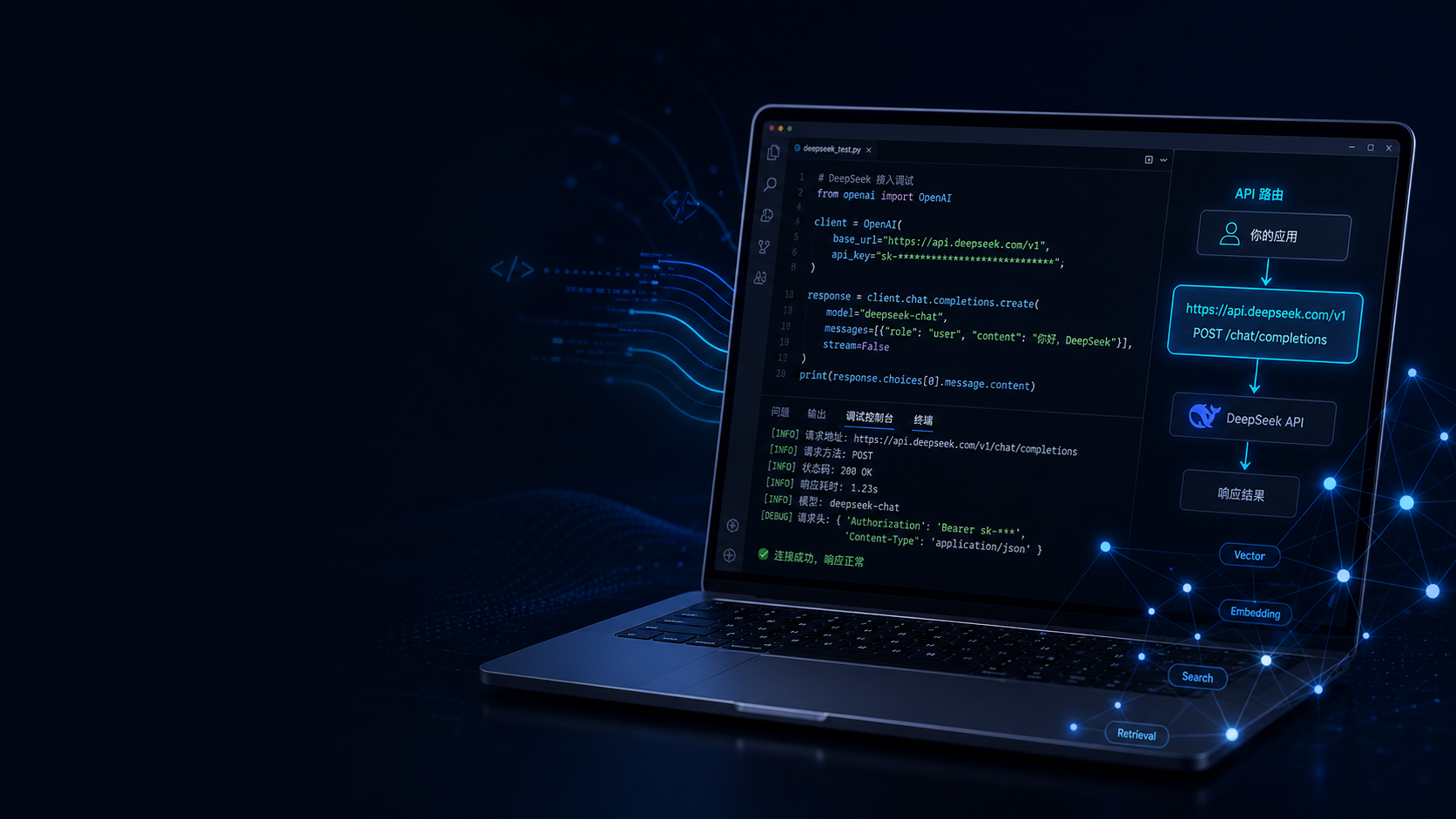
二、DeepSeek API Key:别把它当成普通账号密码
DeepSeek API Key 本质上是 Bearer Token。
它不是登录密码,也不是可随便贴在前端里的公开字符串。
我这半年里见过最常见的三种 Key 问题是:
- 复制时带了空格或换行,肉眼看不出来。
- 把开发环境、测试环境、生产环境共用一把 Key,出问题后根本分不清是哪一层在报错。
- Key 明明没过期,但被客户端缓存、代理配置或错误的环境变量覆盖了。
我现在的习惯是把 Key 分成三套:
- 开发调试 Key
- 联调 Key
- 线上 Key
这样做的好处很直接:
你一眼就能知道报错是“链路问题”还是“环境污染”。
我常用的环境变量写法
DEEPSEEK_API_KEY=sk-xxxxxx
DEEPSEEK_BASE_URL=https://api.deepseek.com
DEEPSEEK_MODEL=deepseek-v4-pro
这里有三个原则:
- 不要把 Key 写死在代码里。
- 不要把
base_url和 Key 混成一个字符串。 - 不要在多个项目之间共享同一份
.env,尤其是你还在同时调 Cursor、Dify、Chatbox 的时候。
我怎么判断是 Key 真的错了
如果是 Key 问题,表现通常很稳定:
- 401 很快就返回。
- 所有请求都失败,而不是偶发失败。
- 换到同一套
base_url后,别的客户端也通不过。
如果是网络或协议问题,表现通常不一样:
- 有时能通,有时超时。
- 直连不行,代理后又能通。
- 同一把 Key,在 Python 里能通,在 Cursor 里却不通。
所以看到 401,我第一反应不是怀疑模型,而是先检查:
- Key 有没有空格。
- 环境变量有没有读错。
- 复制的时候有没有少一位。
- 是否把旧 Key 放进了客户端缓存。
这一步很朴素,但真的是最省时间的。
三、deepseek base_url:这才是很多报错的真正分水岭
如果说 Key 决定“你是谁”,那 deepseek base_url 决定“你走哪条路”。
DeepSeek 官方给出的 OpenAI 兼容接口里,常用的基准地址是:
- OpenAI 格式:
https://api.deepseek.com - Anthropic 格式:
https://api.deepseek.com/anthropic
同时,官方文档里现在推荐的模型名也很明确:
deepseek-v4-flashdeepseek-v4-pro
旧的 deepseek-chat 和 deepseek-reasoner 仍能兼容一段时间,但官方已经给出了明确的停用时间。
我的习惯是:新项目直接用新模型名,别再把旧名字继续写进模板里。否则以后你会在“明明今天还能通、过几周突然失效”的问题上浪费很多时间。
Python 里最小可用的 DeepSeek 调试脚本
我现在会先用一个极简脚本测链路,不上业务逻辑,不接向量引擎,不接知识库,先确认接口层没问题。
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com"),
)
def ping():
resp = client.chat.completions.create(
model=os.getenv("DEEPSEEK_MODEL", "deepseek-v4-pro"),
messages=[
{"role": "system", "content": "你是一个稳定输出的调试助手。"},
{"role": "user", "content": "只回复 pong"},
],
stream=False,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}},
)
return resp.choices[0].message.content
if __name__ == "__main__":
print(ping())
这段代码的意义,不是让你直接拿去做产品,而是先验证三件事:
- Key 是否有效。
base_url是否正确。- 模型名和请求体格式是否匹配。
如果这段都跑不通,那后面的 Cursor、Chatbox、Dify、向量引擎,一律先别碰。
因为你现在不是在调业务,而是在调基础连接。
我最常见的 base_url 坑
1. 多写了 /v1
有些客户端和网关会自己拼路径,你手工再加一层,就会变成重复路径。表现通常是 404、405 或者请求一直发不出去。
我的做法是:先看对方文档要求什么格式,再决定要不要补 /v1。
2. 末尾多了斜杠或者空格https://api.deepseek.com 这种看起来只是多一个空格,实际会让请求全挂。
我遇到过不少次,最后就是重新粘贴一遍,连格子都要手动删干净。
3. 用错模型名
模型名不是“随便填一个差不多的字符串”就行。
如果你填的是旧名字,客户端虽然有时能识别,但后面很容易和新配置冲突。
4. 只改了 Key,没改 base_url
这类错误最迷惑。你以为自己已经切到 DeepSeek 了,实际上客户端还在走原来的地址。
所以我现在每次改配置,都会把 Key、地址、模型名一起核对。
5. 流式和非流式参数混着用
有些客户端对 stream 的支持并不完全一致。
如果你先测连通性,建议先关掉流式;等基础请求稳了,再打开流式看输出体验。
一个判断标准
如果你只想知道“我这条请求到底走没走通”,那就先看 models.list() 或最短的聊天请求。
如果你一上来就接知识库、工具调用、长上下文、流式输出,那你排错时会同时碰到四五层变量,几乎不可能迅速定位。
四、原生接口 VS DeepSeek中转站:我怎么客观看
我一直不喜欢把“原生接口”和“中转链路”写成谁绝对更好。
对我来说,它们的区别不是优劣,而是你当前环境里谁更适合。
这里我把“DeepSeek中转站”统一理解成一类 OpenAI 兼容的接入层:它可能是你自己的网关,也可能是你内部的代理层,或者是某个用于统一管理 base_url 的技术入口。
关键不是名字,而是它是否保持了协议兼容、参数透传和可观测性。
| 维度 | 原生 DeepSeek 接口 | DeepSeek中转站 / 兼容网关 |
|---|---|---|
| 连通成功率 | 直连链路短,配置简单,但更依赖本地网络 | 多一层转发,配置多一点,但常常更容易统一接入 |
| 延时 | 理论上更短 | 会多一跳,实际延时通常略高 |
| 密钥管理 | 只需要管理官方 Key | 可能要同时管理上游 Key 和网关 Key |
| 客户端兼容性 | 标准 OpenAI-compatible 客户端基本都能接 | 如果网关做得好,老客户端更省事 |
| 网络门槛 | 更依赖本地出口和代理设置 | 取决于网关本身可达性 |
| 运维难度 | 低,变量少 | 高一点,需要维护额外一层 |
| 适合人群 | 网络路径稳定、想尽量少依赖中间层的人 | 客户端多、环境杂、调试频繁的人 |
我的实际经验是:
- 如果你是个人开发、网络环境稳定、追求链路最短,原生接口更干净。
- 如果你手里同时跑 Cursor、Chatbox、Dify,还要兼顾 Windows、macOS、桌面端、网页端、测试机,兼容网关往往更省时间。
但是有一个原则不能变:
不管你走哪条路,都不要同时改太多变量。
我排错时只改一项:
- 先确认 Key。
- 再确认
base_url。 - 再确认模型名。
- 再确认代理和超时。
- 最后才碰客户端的高级参数。
这样做虽然慢一点,但能避免把“网络问题”“协议问题”“客户端问题”全搅在一起。
五、Cursor 接入:最容易被忽略的是请求形态
Cursor 接入我踩过很多次坑,最后总结成一句话:
你以为你在调模型,其实你在调客户端请求格式。
我现在的 Cursor 接法
- 打开 Cursor 的设置页,找到模型配置。
- 先填
OpenAI API Key,把DeepSeek API Key贴进去。 - 打开
Override OpenAI Base URL或同类入口。 - 把
base_url写成你实际要用的地址,原生就写https://api.deepseek.com。 - 模型名先用
deepseek-v4-pro或deepseek-v4-flash。 - 先做一个最短消息测试,别一上来就上长上下文或 Agent。
Cursor 里我最常见的三个问题
1. Base URL 写对了,还是报错
这时候我会先看是不是 Agent 模式。
有些版本里,Agent、Ask、Inline Edit 的请求形态并不完全一样。
如果 Ask 能通,Agent 不通,通常不是 Key 问题,而是客户端请求结构和后端支持范围没完全对上。
2. 改了 Base URL 后,别的模型也开始异常
我遇到过这种情况,所以现在的习惯是:
把自定义 endpoint 和内置模型的测试分开做,不要一口气混在一个窗口里看结果。
3. 网络层能通,但 Cursor 里还是提示 provider error
这类问题先不要怀疑 DeepSeek。
先看 Cursor 自己的设置、HTTP 兼容模式、代理、证书、版本差异,再看请求体是否和你当前 endpoint 的支持范围一致。
Cursor 接入的调试顺序
我建议按这个顺序:
- 先用最短的纯文本请求。
- 再测试普通聊天。
- 再开流式。
- 再测试长上下文。
- 最后再开 Agent 或复杂工具链。
这个顺序的核心是:
先把“模型是否可达”确认下来,再去谈“能不能聪明地工作”。
如果第一步都没通,后面的调试只会把时间越拉越长。
六、Chatbox 接入:最适合拿来做链路自检
Chatbox 对我来说最大的价值,不是“好看”,而是它很适合做 endpoint 的第一跳自检。
因为它的配置逻辑比较直观,尤其适合把“API Key、Host、模型名、流式输出”一次性看清楚。
如果你在 Python 里有一点不确定,我通常会先拿 Chatbox 做对照测试,再回头看代码。
Chatbox 的配置思路
- 打开设置页,找到模型供应商或自定义模型入口。
- 选择 OpenAI API compatible 这一类配置。
- 填入 API Key。
- 填入 API Host,也就是你的
base_url。 - 添加一个模型名,建议和官方文档、网关文档保持一致。
- 保存后点
Check或连接测试按钮。 - 连接通过后,再开流式输出测试长文本。
我在 Chatbox 里常看的不是“能不能连上”,而是这三件事
1. 连接测试是否稳定
有些环境能偶尔连上,但一切到流式就中断。
这种情况通常不是模型能力问题,而是网络、代理或者超时设置问题。
2. 模型名是否一致
如果模型名和 endpoint 支持的不一致,Chatbox 有时会给出很笼统的提示。
这时候不要只看“连接失败”四个字,要回头核对模型名。
3. 长对话是否被截断
Chatbox 很适合测试上下文,尤其能看出是不是 max tokens 太小,或者流式输出中断得太早。
我的 Chatbox 排错方法
我会拿同一段 prompt,分别在 Python、Cursor、Chatbox 里测:
- 如果 Python 能通,Chatbox 不通,多半是客户端配置问题。
- 如果 Chatbox 能通,Python 不通,多半是 SDK 参数或代码问题。
- 如果两边都不通,才回到 Key、
base_url、网络和模型名。
这种方法很土,但特别好用。
因为它能把“是不是服务本身坏了”这件事先排掉。
七、Dify 接入:向量引擎真正开始出问题的地方
如果说 Cursor 和 Chatbox 更像是“调用入口”,那 Dify 才是我最常拿来验证向量引擎全链路的地方。
因为 Dify 不只是一个聊天框,它会把:
- 模型供应商
- 知识库
- 分段
- 索引
- 检索
- 工作流
串在一起。
这也是为什么很多人觉得“Dify 一接就复杂”,实际上是因为它把向量引擎那条链全暴露出来了。
Dify 里我通常先做这三步
第一步:配置模型供应商
Dify 的模型供应商是工作区级别的。
如果你要用自定义供应商,就填自己的 API Key;如果工作区里已经有兼容 DeepSeek 的供应商入口,就直接在工作区层配置好。
第二步:创建知识库
我会先上传一小份文档,不要一上来就塞几百页资料。
先做一个最小知识库,确认分段、索引、召回都正常,再扩大数据量。
第三步:把知识库接到应用里
这一步才是向量引擎的核心。
你不是让模型“记住一切”,而是让模型先检索,再生成。
知识库里最容易错的不是模型,而是这四个参数
-
分段太大
长文本切得太大,召回时相关性会被稀释,模型拿到的上下文会很散。 -
分段太小
太小又会把完整语义切碎,最后召回的是零散片段。 -
Embedding 模型和向量维度不一致
这是典型的“表面看是知识库错了,实际上是索引层错了”。 -
检索阈值或 Top-K 不合适
阈值太高,召回不到;Top-K 太大,噪音又会把答案拉偏。
我怎么看 Dify 的向量引擎
我现在不把 Dify 知识库当成“问答功能”,而是当成一个标准的 RAG 管线:
文档 -> 分段 -> Embedding -> 向量索引 -> 检索 -> 上下文增强 -> LLM 生成
这个链路里,DeepSeek 负责的是后半段的生成;
真正决定“答得准不准”的,往往是前半段的向量检索。
所以如果你在 Dify 里看到:
- 模型供应商验证通过了。
- App 也发布了。
- 但回答总是空、偏题、或者只会套话。
那你第一反应不要只看模型参数。
更该去看:
- 知识库有没有真正命中。
- 检索的 chunk 有没有把问题覆盖住。
- 元数据过滤是不是过严。
- Embedding 和向量库是否一致。
我做 Dify 联调时的顺序
- 先让单个模型请求跑通。
- 再让知识库能召回一小段文本。
- 再把召回结果接入工作流。
- 最后再加提示词、重排和更复杂的节点。
如果你倒着来,排错会非常痛苦。
因为你根本分不清到底是模型错了、向量错了,还是工作流节点错了。
八、Python 侧:我现在怎么搭一个最小可调试闭环
如果你问我,做向量引擎和 DeepSeek 接入,Python 里最值得保留的是什么。
我的答案是:一个最小可调试闭环。
这个闭环不是为了“直接上线”,而是为了“能在 10 分钟内判断问题在哪一层”。
1)先做接口层 smoke test
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url=os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com"),
)
try:
models = client.models.list()
print("models:", [m.id for m in models.data[:5]])
except Exception as e:
print(type(e).__name__, e)
这段的作用很简单:
- 能拿到模型列表,说明 Key 和 base URL 大概率没问题。
- 如果这里就报错,说明你连基础请求都没打通。
2)再做最短聊天测试
def chat_once(question: str):
resp = client.chat.completions.create(
model=os.getenv("DEEPSEEK_MODEL", "deepseek-v4-pro"),
messages=[
{"role": "system", "content": "你是一个稳定、简洁、会排错的助手。"},
{"role": "user", "content": question},
],
stream=False,
reasoning_effort="high",
extra_body={"thinking": {"type": "enabled"}},
)
return resp.choices[0].message.content
print(chat_once("只回复一句:链路已通"))
这里我只测一个最短句子。
原因很简单:在排错阶段,长上下文不是优势,反而会掩盖问题。
3)最后才接向量引擎
向量引擎的调试,我现在一般先看逻辑,不先看花哨功能。
import numpy as np
def cosine(a, b):
a = np.asarray(a, dtype=float)
b = np.asarray(b, dtype=float)
denom = np.linalg.norm(a) * np.linalg.norm(b) + 1e-9
return float(np.dot(a, b) / denom)
docs = [
"Cursor 接入时先测 base_url 和 Key。",
"Chatbox 适合做第一跳连接测试。",
"Dify 的知识库核心是检索,不是聊天框。",
]
def embed_texts(texts):
"""
这里换成你自己的 embedding 服务。
可以是本地模型,也可以是你已经接好的向量化接口。
"""
raise NotImplementedError
def search(query, top_k=2):
doc_vecs = embed_texts(docs)
q_vec = embed_texts([query])[0]
scored = [(i, cosine(q_vec, vec)) for i, vec in enumerate(doc_vecs)]
return sorted(scored, key=lambda x: x[1], reverse=True)[:top_k]
这段代码的重点不是“马上跑起来”,而是帮你明确一件事:
向量引擎的调试核心,是确认 Embedding、维度、召回、阈值和上下文拼接都没有错。
如果你的向量引擎现在表现怪异,我建议你先检查这几件事:
- 文本切分是不是过长或过短。
- Embedding 结果的维度是不是统一。
- 索引里存的向量是不是最新版本。
- 查询时是不是把过滤条件设得太死。
- 召回后拼给 DeepSeek 的上下文是不是被截断了。
九、我整理的 16 类高频 DeepSeek API报错
下面这部分是我自己踩得最多的一段。
我不想把错误写成“玄学列表”,所以每一条都尽量写成:现象 -> 原因 -> 修法。
1. 401 Authentication Fails
- 现象:一请求就返回鉴权失败。
- 常见原因:Key 错了、复制多了空格、环境变量没读到、旧 Key 被替换。
- 修法:先用最小脚本测
/models,再重新粘贴 Key,删掉前后空白。
2. 400 Invalid Format
- 现象:请求体格式不对。
- 常见原因:消息结构错了、字段拼错了、客户端发的不是当前 endpoint 支持的格式。
- 修法:先用官方最小示例,对照参数名逐个核对。
3. 402 Insufficient Balance
- 现象:余额不足。
- 常见原因:确实没额度了,或者某个环境用了错误的账号。
- 修法:先确认当前 Key 属于哪个账户,再看余额状态,不要先改代码。
4. 422 Invalid Parameters
- 现象:参数合法性检查失败。
- 常见原因:模型名写错、reasoning 参数冲突、stream 与某些高级参数不兼容。
- 修法:删掉所有非必要参数,先只保留
model和messages。
5. 429 Rate Limit Reached
- 现象:请求太快。
- 常见原因:并发过高、轮询过猛、多个客户端共用一把 Key。
- 修法:降低并发、加退避、分环境用不同 Key。
6. 500 Server Error
- 现象:服务端内部错误。
- 常见原因:偶发服务异常。
- 修法:稍后重试,先别改本地配置;如果持续存在,再收集请求 ID 和报错信息。
7. 503 Server Overloaded
- 现象:服务器繁忙。
- 常见原因:高峰期负载过高。
- 修法:重试、降低请求频率、短时间内别反复打同一条长请求。
8. base_url 域名解析失败
- 现象:DNS 解析不出来,或者请求卡在连接阶段。
- 常见原因:地址写错、网络出口不通、代理配置不对。
- 修法:先用浏览器或
curl测域名能不能连,再回到客户端。
9. HTTPS / 证书错误
- 现象:地址看着对,但 TLS 直接失败。
- 常见原因:代理拦截、证书链异常、系统时间不对。
- 修法:先确认系统时间和证书,再排查代理和公司网络策略。
10. 模型不存在 / model not found
- 现象:模型名不识别。
- 常见原因:用了旧名字、拼写错误、客户端缓存了旧配置。
- 修法:按官方当前模型名重新填一次,不要沿用历史模板。
11. 流式输出中断
- 现象:前面还能出字,后面突然停了。
- 常见原因:超时、网络抖动、客户端流式处理不稳。
- 修法:先关流式测试,再检查 timeout 和代理。
12. Cursor 里提示 provider error
- 现象:Python 能通,Cursor 却报 provider error。
- 常见原因:Cursor 的请求模式和 endpoint 支持范围不一致,或者 Agent / Ask 模式切换后请求结构变化。
- 修法:先用最短消息在 Ask 模式测试,再看 Agent 是否兼容。
13. Cursor 改了 Base URL 后,其他模型也异常
- 现象:自定义 endpoint 一开,其他模型也开始报错。
- 常见原因:Cursor 当前配置页把同一组 Base URL 作用到了多个模型。
- 修法:把测试分开做,别在一个会话里同时切太多模型。
14. Chatbox 点击 Check 失败
- 现象:连不上,或者校验失败。
- 常见原因:API Host 写错、模型名不对、Key 失效、路径被手动改坏。
- 修法:先回到最简单的 OpenAI-compatible 配置,别自己额外拼路径。
15. Dify 模型供应商验证失败
- 现象:工作区层配置过不去。
- 常见原因:Key 或自定义供应商信息错、工作区权限不够、填写了不该填写的路径。
- 修法:管理员账号下重配一次,确认所有必填项都正确。
16. Dify 知识库检索不出内容
- 现象:模型能用,但知识库结果不对。
- 常见原因:分段不合理、Embedding 不一致、索引没更新、召回阈值过严、过滤条件过窄。
- 修法:缩小数据集,先确认单篇文档能不能命中,再逐步扩大。
如果你要我把这 16 条再压缩成一句通用判断,我会这么说:
401 先看 Key,400/422 先看请求体,429 先看频率,500/503 先看服务状态,Cursor/Chatbox/Dify 的报错先看客户端协议和本地配置,知识库问题优先看分段、Embedding 和索引。
十、新手 FAQ:我最常被问到的 5 个问题

Q1:同一个 DeepSeek API Key 可以给多个软件同时用吗?
可以,但我不建议把开发、测试、生产全都混在一把 Key 上。
最好按环境拆分,不然一旦限流、报错或误操作,你很难判断是哪一个客户端触发的。
Q2:改了 deepseek base_url 之后还是不通,先查什么?
先查四项:
- Key 是否读对。
- 模型名是否当前可用。
base_url有没有多余空格、斜杠或错误路径。- 客户端是不是把代理、HTTP 版本或缓存配置带歪了。
如果这四项都对,再看网络出口和客户端请求格式。
Q3:DeepSeek中转站一定要换新 Key 吗?
不一定。
要看你接的是哪一层:有些是单纯的兼容网关,有些是自己管理上游 Key 的代理层。
我建议你先把“谁负责认证,谁负责转发,谁负责记账”这三件事弄清楚,再决定 Key 怎么放。
Q4:Cursor 更新后接口突然失效,怎么排?
我一般按这个顺序:
- 先回退到最简单的纯文本测试。
- 再看
base_url和模型名有没有被重置。 - 再看 Agent / Ask / Inline Edit 的模式差异。
- 再检查 HTTP 兼容性、代理和证书。
Cursor 更新后出现的很多问题,表面像是“模型失效”,本质其实是客户端行为变了。
Q5:Dify 里知识库已经建了,为什么回答还是不准?
因为知识库不是“把文件放进去就自动懂了”。
它本质上是检索系统,效果通常取决于:
- 文本分段是否合理。
- Embedding 是否一致。
- 检索阈值是否合适。
- 是否做了元数据过滤。
- 召回内容有没有被 prompt 进一步约束。
我现在排 Dify 的优先级是:先看检索,再看生成。
这一步顺序反过来,通常会越调越乱。
十一、我现在整理模板时只保留这几项
如果让我把这套流程收缩成一个最小模板,我只会留这些参数:
DeepSeek API Keydeepseek base_urlmodelstreamtimeoutproxy- 知识库的 chunk size
- chunk overlap
- top_k
- Embedding provider
- 索引更新状态
其他参数当然也能调,但它们都属于“在基础链路通了以后再慢慢优化”的东西。
我最怕的就是有人一上来就堆一堆高级参数,最后连最基础的 401 和 400 都分不清。
我会把资料页当成什么
如果你要找一份 base_url 模板、客户端参数、报错清单,我建议你把它当成“查阅入口”,不是“答案本身”。
像这类技术资料页,我通常只拿来做对照,不会直接照抄:
https://178.nz/awa
我的用法很简单:
- 先对照
base_url格式。 - 再对照模型名。
- 再对照超时、流式和兼容参数。
- 最后回到自己的请求日志和报错码。
因为真正决定问题能不能解决的,从来不是页面本身,而是你自己的请求到底发了什么。
结尾
这半年我最大的变化,不是“会接更多模型”了,而是我越来越习惯把问题拆层。
以前我看到报错,第一反应是“模型挂了”。
现在我会先问自己四句话:
- Key 对不对。
base_url对不对。- 客户端协议对不对。
- 向量引擎的分段、Embedding、索引对不对。
这四句话能回答清楚,绝大多数 DeepSeek API 报错、Cursor 接入失败、Chatbox 连接异常、Dify 知识库不召回的问题,都会立刻缩小范围。
如果你正在做向量引擎、RAG、知识库问答,或者只是单纯在调 DeepSeek 接入,我建议你别急着改一堆参数。
先把一条最短链路跑通,再逐步叠加功能。
能跑通基础链路的系统,后面才有资格谈体验、稳定性和优化。
如果你现在用的是 Cursor、Chatbox 还是 Dify,遇到哪一类 DeepSeek API报错,把报错码、base_url、模型名和客户端版本贴出来,我通常先看 Key 和路由,再看请求体和向量层。
很多问题,不是难,而是先后顺序错了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)