更快更准更强!碧桂园服务“一问“智能体用 Agentic RAG 破解知识问答难题
更快更准更强!碧桂园服务"一问"智能体用 Agentic RAG 破解知识问答难题

随着碧桂园服务的数字化建设持续深化,财务、人力、收费、运营等业务已全面实现线上化,形成覆盖38个业务系统的数字化体系。为提高员工获取知识和解决业务问题的效率,碧桂园服务打造了企业内部智能问答助手“一问”,通过统一入口连接各业务系统知识库,实现企业知识的集中查询与服务。 在建设初期,“一问”基于传统RAG(检索增强生成)技术运行,已经能够解决大部分常见咨询问题。但随着知识库规模持续扩大、业务场景不断丰富, 新的挑战也逐渐显现: 机器人能够检索资料,却未必总能准确理解问题所属的业务场景;能够生成答案,却未必总能找到最匹配的知识内容, 问答准确率面临进一步提升的挑战。 为解决这一问题,碧桂园服务 将Agentic RAG(智能体驱动的RAG)引入“一问” ,让系统具备感知、规划、反思和自我修正能力。在2000余条真实问题盲测中, 意图识别准确率提升至94.2%,有效回答覆盖率达到96.8% ,进一步提升了员工获取知识和解决业务问题的效率。 下文我们将为大家拆解这套Agentic RAG解决方案。 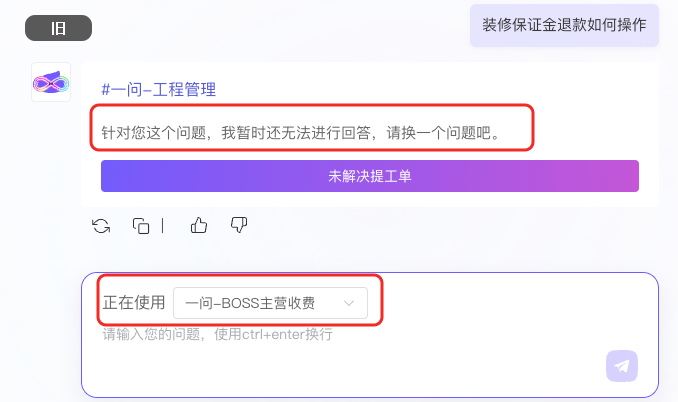 注:旧方案依赖用户手动选择知识库,知识匹配准确性受限
注:旧方案依赖用户手动选择知识库,知识匹配准确性受限 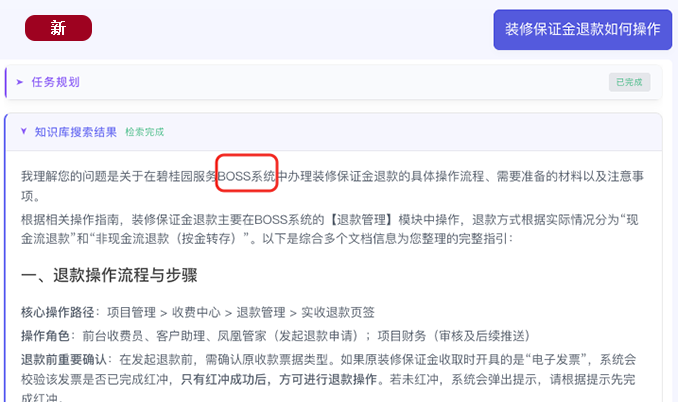 注:新方案自动识别问题所属业务场景,智能匹配对应知识库并生成答案
注:新方案自动识别问题所属业务场景,智能匹配对应知识库并生成答案
- 以下内容来自碧桂园服务数字赋能AI团队
 对于个人用户而言,基于RAG的大模型问答已经十分常见:检索相关资料,再由大模型生成答案即可。 但在企业场景中,知识分散在不同系统、不同知识库之中,问题远比公开互联网问答复杂。传统RAG通常会面临以下三道“墙”:
对于个人用户而言,基于RAG的大模型问答已经十分常见:检索相关资料,再由大模型生成答案即可。 但在企业场景中,知识分散在不同系统、不同知识库之中,问题远比公开互联网问答复杂。传统RAG通常会面临以下三道“墙”: 
第一道墙: 跨知识库的语义干扰 | 问题表现 “审批”、“流程”、“权限”、“付款”、“发票”等关键词几乎存在于多个业务系统中。当员工询问“零灵快报里的报账付款单为什么显示在收款单”时,系统需要先判断问题属于哪个业务领域,再决定去哪个知识库检索答案。 如果仅依赖语义召回,相关度排序靠前的文档可能同时来自NCC财务、明源成本合同、OA等多个系统,真正与问题相关的内容反而被大量无关信息淹没,最终导致回答偏离用户真实需求。 | 需要的能力 这堵墙考验的是系统的“ 感知 ”能力:在检索之前先理解问题所属的业务场景,准确识别业务归属和知识来源,避免检索范围偏离目标知识库。
第二道墙: 业务别名与噪声信息影响理解 | 问题表现 企业内部同一系统往往存在多个名称,例如BOSS、BSS、收费系统指向同一平台;HCM与人力系统、新OA与BIP也经常混用。同时,员工提问中还可能包含工单号、截图说明、礼貌用语、@机器人等无效信息,增加了问题理解难度。 | 需要的能力 这堵墙考验的是系统的“ 规划 ”能力:准确识别用户真实意图,并将问题路由到正确的业务领域和知识库,实现精准检索。
第三道墙: 检索失败后的回答能力不足 | 问题表现 传统RAG通常采用“一次检索、一次回答”的模式。当召回结果质量不足或未能匹配到有效知识时,机器人往往只能基于有限信息作答,甚至直接返回未找到相关内容。 | 需要的能力 这堵墙考验的是系统的“ 反思 + 自我修正 ”能力:能够主动评估检索结果质量,在发现答案支撑不足时重新调整检索策略,通过反思与自我修正提升回答成功率。
 为应对上述挑战,AI团队将Agentic RAG引入“一问”,并围绕 感知、规划、行动、反思、自我修正五个步骤 构建完整能力体系。 通过这五个步骤,系统不仅能够理解问题、检索知识,还能够判断结果质量并进行自我修正,从而提升问答准确率和回答成功率。下面,我们将逐步拆解这套解决方案。
为应对上述挑战,AI团队将Agentic RAG引入“一问”,并围绕 感知、规划、行动、反思、自我修正五个步骤 构建完整能力体系。 通过这五个步骤,系统不仅能够理解问题、检索知识,还能够判断结果质量并进行自我修正,从而提升问答准确率和回答成功率。下面,我们将逐步拆解这套解决方案。
第一步:感知 (Perceive) 让系统先听懂问题 第一步是让系统“听得懂”。AI团队把混沌的业务咨询收敛为 35 个闭集标签 ,每个标签明确三件事——核心业务对象、常见别名、判别边界。例如: 标签 核心对象 易混淆边界 零灵快报 报账应付单、划扣预付单、费用类型、限额 与"明源成本合同"、"NCC"的核心差异 明源成本合同 付款申请、扣款登记、合同中止、变更 强调"成本合同"主体,区别于零灵报销 BOSS 主营收费 物业费/水电费/车位管理费、转名、减免 与"停车平台"区分车场运营 vs 物业收费 配套的 Prompt 显式声明三条优先级原则,把模糊判断变成有章可循的规则:
- 系统名 > 业务语义 > 动作词
- 核心业务对象 > 通用流程词
- 出问题的环节 > 顺带提及的关联系统 基于这套规则体系,AI团队对 Qwen3-8B 做了 SFT-LoRA 微调,让感知能力"内化"为模型本能: 配置项 取值 取舍理由 基础模型 Qwen3-8B 中文业务理解强,推理性价比高 训练方法 LoRA SFT (rank=8, alpha=16) 仅训练增量参数,省资源、易迭代 learning_rate / epochs 3e-4 / 3 轮 平衡过拟合与收敛 数据规模 约 1.5 万条精选样本 覆盖每一类标签的高频边界 训练耗时 4 小时 39 分钟 单次完整训练
第二步:规划 (Plan) 确定该去哪里找答案 完成问题识别后,系统还需要解决知识库选择问题,即确定最适合的检索路径。 AI团队把 38 个业务系统对应的 31 个独立 KB 归并为 9 大业务组 + 1 公文 + 1 兜底 ——财务报销、成本合同、人力、主营收费、物业运营、采购零售、市拓运营、平台工具、默认兜底。每组配置专属 System Prompt,让回答风格契合领域规范(HCM 严守材料提取格式、停车平台落实脱敏、市拓领域屏蔽敏感口径)。 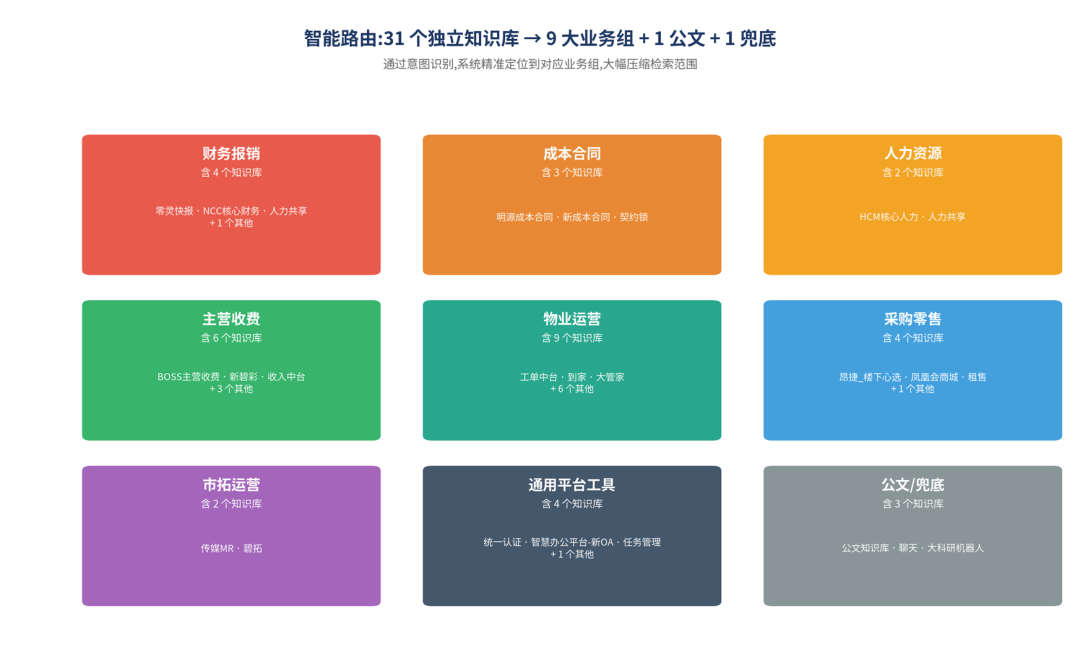
第三步:行动 (Act) 提升知识检索质量 知识库路由完成后,系统还需要进一步提升知识召回的准确性与相关性。AI团队设计了 双策略多因子重排 机制:
- 公文场景(强时效性):以年份新鲜度为主导因子,叠加向量原始分、发文单位匹配等加成项,确保引用的是最新政策。
- 非公文场景(强语义性):以向量原始分为基础,叠加发文单位匹配、内容质量、问答类型等加成项,保证语义和业务上下文的双重匹配。
第四步:反思 (Reflect) 判断答案是否可靠 与传统RAG相比,反思机制是Agentic RAG的重要能力之一。系统在生成答案前会主动评估: 这次召回的文档质量是否足以支撑回答? AI团队设置了召回质量阈值——如果高质量文档不足,系统不会"硬答",而是主动触发下一步。
第五步:自我修正 (Self-Correct) 在失败时主动重试 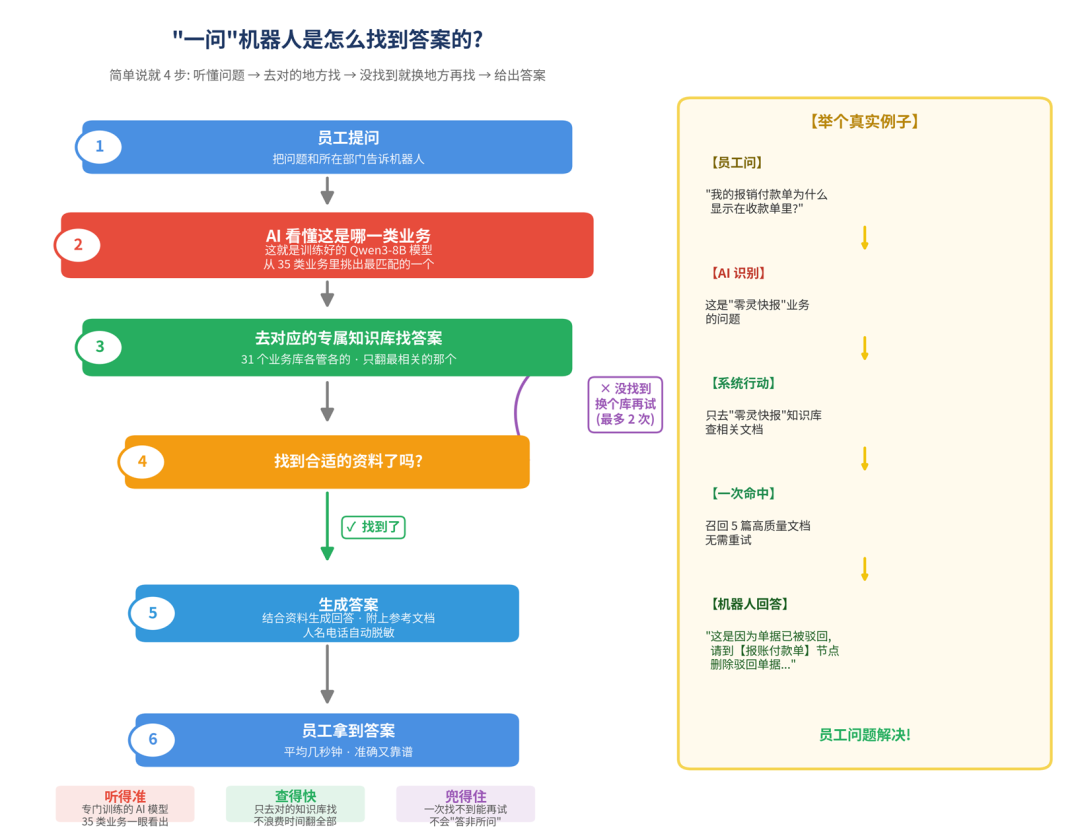 当检索质量未达到预设阈值时,系统将启动重试流程: 由轻量 LLM 改写用户问题(换同义词、补充上下文),并切换到其他可能匹配的知识库分组 ,重新走一遍“感知→规划→行动→反思”的闭环。最多两轮,避免无限循环;如果两轮均未命中,系统进入兜底分支,给出友好的引导式回复。 整套链路由 LangGraph 编排,五个能力节点串联成完整的智能体决策图。这种 “感知→规划→行动→反思→修正” 的闭环设计,是 Agentic RAG 区别于传统 RAG 的本质特征。
当检索质量未达到预设阈值时,系统将启动重试流程: 由轻量 LLM 改写用户问题(换同义词、补充上下文),并切换到其他可能匹配的知识库分组 ,重新走一遍“感知→规划→行动→反思”的闭环。最多两轮,避免无限循环;如果两轮均未命中,系统进入兜底分支,给出友好的引导式回复。 整套链路由 LangGraph 编排,五个能力节点串联成完整的智能体决策图。这种 “感知→规划→行动→反思→修正” 的闭环设计,是 Agentic RAG 区别于传统 RAG 的本质特征。
 项目上线后,AI团队对“一问”机器人进行了系统性的效果评估。 基于 2000+ 条线上真实问题构建的盲测集 ,AI团队对比了新旧方案在算法精度与系统效率两个核心维度上的关键指标: 评估维度 旧方案 (规则匹配 + 通用 LLM) 新方案(Agentic RAG) 变化 【算法精度】 意图识别准确率 (Top-1) 78.4% 94.2% ↑ 15.8 pp 知识库召回精准度 (Top-3 命中) 81.2% 91.5% ↑ 10.3 pp 高质量召回比例 (score > 0.3) 78.6% 87.3% ↑ 9.7 pp 【系统效率】 端到端有效回答覆盖率 76.3% 96.8% ↑ 20.5 pp 平均响应延迟 (P50) 8.2 秒 5.4 秒 ↓ 34.2% 注:评估基于 2000+ 条线上真实问题构建的盲测集,覆盖 35 类业务标签;旧系统为本项目上线前的"规则匹配 + 通用大模型"基线方案。 指标提升的背后,是问答机制的整体升级。系统不再停留于“检索—生成”的单轮流程,而是形成了包含理解、判断和修正的完整闭环。 具体落到员工的使用感受上,这场升级可以拆为四个层次: | 从“被动查询”到“主动思考” Agent 在每一次回答前都会感知问题归属、规划检索路径、反思召回质量。当员工问出一个模糊的问题,机器人不再"硬答",而是像一个有经验的同事,知道该去哪儿找、该怎么找、什么时候该再找一次。 | 从“全库扫描”到“精准定位” 感知前置 + 智能路由把单次召回从“全库扫描”压缩为“目标库精炼”,平均检索范围下降近一个数量级,端到端响应延迟显著优化。 | 从“一次失败 = 失语”到“两次自愈” 反思 + 修正机制让“一次召回失败 ≠ 机器人失语”,整体有效回答覆盖率明显抬升。 | 从“重训模型”到“配置驱动” 标签体系 / Prompt 配置 / 知识库分组三者完全解耦——新增业务系统只需更新配置文件,不需要重训模型,业务团队可自助迭代。
项目上线后,AI团队对“一问”机器人进行了系统性的效果评估。 基于 2000+ 条线上真实问题构建的盲测集 ,AI团队对比了新旧方案在算法精度与系统效率两个核心维度上的关键指标: 评估维度 旧方案 (规则匹配 + 通用 LLM) 新方案(Agentic RAG) 变化 【算法精度】 意图识别准确率 (Top-1) 78.4% 94.2% ↑ 15.8 pp 知识库召回精准度 (Top-3 命中) 81.2% 91.5% ↑ 10.3 pp 高质量召回比例 (score > 0.3) 78.6% 87.3% ↑ 9.7 pp 【系统效率】 端到端有效回答覆盖率 76.3% 96.8% ↑ 20.5 pp 平均响应延迟 (P50) 8.2 秒 5.4 秒 ↓ 34.2% 注:评估基于 2000+ 条线上真实问题构建的盲测集,覆盖 35 类业务标签;旧系统为本项目上线前的"规则匹配 + 通用大模型"基线方案。 指标提升的背后,是问答机制的整体升级。系统不再停留于“检索—生成”的单轮流程,而是形成了包含理解、判断和修正的完整闭环。 具体落到员工的使用感受上,这场升级可以拆为四个层次: | 从“被动查询”到“主动思考” Agent 在每一次回答前都会感知问题归属、规划检索路径、反思召回质量。当员工问出一个模糊的问题,机器人不再"硬答",而是像一个有经验的同事,知道该去哪儿找、该怎么找、什么时候该再找一次。 | 从“全库扫描”到“精准定位” 感知前置 + 智能路由把单次召回从“全库扫描”压缩为“目标库精炼”,平均检索范围下降近一个数量级,端到端响应延迟显著优化。 | 从“一次失败 = 失语”到“两次自愈” 反思 + 修正机制让“一次召回失败 ≠ 机器人失语”,整体有效回答覆盖率明显抬升。 | 从“重训模型”到“配置驱动” 标签体系 / Prompt 配置 / 知识库分组三者完全解耦——新增业务系统只需更新配置文件,不需要重训模型,业务团队可自助迭代。
 项目上线后,最直接的变化体现在“一问”的回答方式上。 过去,机器人更像一个检索工具:找到什么资料,就基于什么资料生成答案;一旦检索结果不准确,回答质量也会受到影响。 引入Agentic RAG后,系统具备了判断和修正能力。在回答问题之前,它会先理解问题属于什么业务场景,再规划检索路径;当发现检索结果质量不足时,还能够主动调整策略重新尝试,而不是直接给出不准确的回答。 这种“感知—规划—行动—反思—自我修正”的能力闭环,正是Agentic RAG区别于传统RAG的核心价值。它使问答机器人具备了持续优化回答过程的能力,从而提升复杂场景下的回答质量。 对于碧桂园服务而言, 这次实践不仅提升了“一问”的问答效果,也验证了Agentic RAG在企业知识服务场景中的应用价值。 未来,AI团队将持续优化问题理解、知识检索和自我修正能力,探索更复杂场景下的多轮推理与自主学习机制,让“一问”能够更准确地理解问题、更高效地提供答案,持续提升企业知识服务体验。
项目上线后,最直接的变化体现在“一问”的回答方式上。 过去,机器人更像一个检索工具:找到什么资料,就基于什么资料生成答案;一旦检索结果不准确,回答质量也会受到影响。 引入Agentic RAG后,系统具备了判断和修正能力。在回答问题之前,它会先理解问题属于什么业务场景,再规划检索路径;当发现检索结果质量不足时,还能够主动调整策略重新尝试,而不是直接给出不准确的回答。 这种“感知—规划—行动—反思—自我修正”的能力闭环,正是Agentic RAG区别于传统RAG的核心价值。它使问答机器人具备了持续优化回答过程的能力,从而提升复杂场景下的回答质量。 对于碧桂园服务而言, 这次实践不仅提升了“一问”的问答效果,也验证了Agentic RAG在企业知识服务场景中的应用价值。 未来,AI团队将持续优化问题理解、知识检索和自我修正能力,探索更复杂场景下的多轮推理与自主学习机制,让“一问”能够更准确地理解问题、更高效地提供答案,持续提升企业知识服务体验。
本文作者 曹玉衡 碧桂园服务算法工程师 指导人 刘刚 碧桂园服务架构专家 揭皓翔 碧桂园服务高级算法专家

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)