AI 语音进化史:这些年,AI是如何学会“说话”的?
语音合成是通过文字人工生成人类声音, 也可以说语音生成是给定一段文字去生成对应的人类读音,也就是 TextToSpeech。 语音合成技术发展现如今,语音模型已经能够做到,只需几秒你的声音样本,它就能完美克隆你,并用任意语言、口音和情绪流畅演说。
回望历史,从2017年谷歌Tacotron的初次亮相、微软FastSpeech的速度飞跃,到 VITS的“老戏骨”模仿、VALLE的“三秒克隆”,每一次技术革新都会推动语音生成更快、更自然、更可控。直至近两年,语音模型更是开始井喷式爆发,每一个语音模型的开源、升级都吸引大量人的关注。
业内每一个模型都有着自己的独家法门,使模型能够做到输出的声音满足,多语言、多音色、多情绪等要求,在真实性、生成速度、声音水印等方面做了大量的研究和迭代,让模型生成的声音在各类应用中能够做到“以假乱真”。
目录
2. Deep Belief Networks(深度信念网络)
一、规则驱动阶段
1. Concatennative TTS(拼接合成)
原理:提前录制大量语音片段(如音素、音节、词),通过数据库检索拼接形成语音。
代表技术:
· 早期通过录制基本语音单元(如英语 44 个音素),根据文本切分后拼接。
· 典型系统:DECtalk(1983 年),通过预录语音片段拼接实现基础语音合成。
特点:
· 音质依赖录制质量,自然度较高,但数据库庞大,难以处理新词或复杂韵律。
· 灵活性差,无法动态调整音色或情感。
2. Formant Synthesis(共振峰合成)
原理:基于语音产生的声学模型,通过数学公式模拟声带振动和声道共振特性。
代表技术:
· 利用滤波器模拟声道形状,调整共振峰频率(F1、F2、F3)生成语音。
· 典型系统:Klattformant synthesizer(1980 年代)。
特点:
模型参数少,存储效率高,但音质生硬,缺乏自然语音的细微变化。
二、统计参数阶段
1. HMMbased TTS(隐马尔可夫模型)
原理:将语音特征(如梅尔频谱、基频)建模为概率分布,通过 HMM 预测声学参数。
代表技术:
· 2001 年,Tokuda 等人提出基于 HMM 的 TTS,首次实现参数化语音合成。
· 输入文本先转换为音素序列,HMM 预测每个音素的声学特征,再通过声码器合成波形。
特点:
模型轻量,可动态调整参数(如语速、音高),但自然度不足,缺乏韵律细节。
2. Deep Belief Networks(深度信念网络)
原理:使用多层神经网络(如 DBN)替代 HMM,提升声学参数预测精度。
代表技术:
2010 年前后,DBN 首次应用于 TTS,通过无监督预训练 + 有监督微调优化模型。
特点:
相比 HMM,能捕捉更复杂的声学特征依赖关系,但仍需分阶段训练(文本分析→参数预测→波形生成)。
三、深度学习端到端阶段
1. Tacotron
由谷歌于 2017 年发布,是第一个端到端、seq2seq 的神经网络系统。其架构彻底改变了传统 TTS 的设计思路,传统的TTS 需分步骤处理文本分析、声学特征生成、波形合成,而 Tacotron 通过 编码器 解码器 注意力机制 的端到端框架,将文本直接映射到声学特征(梅尔频谱),无需人工设计中间模块。
· 输入:文本序列(如单词、字符)→ 编码器转化为隐藏表示;
· 输出:梅尔频谱序列 → 后续通过声码器(如 GriffinLim)生成波形。
过去的方法更像是一种流水线 pipeline 形式,每个模块可能都会产生误差,最终这些误差就会被积累,造成最终生成的音质存在一定的问题。
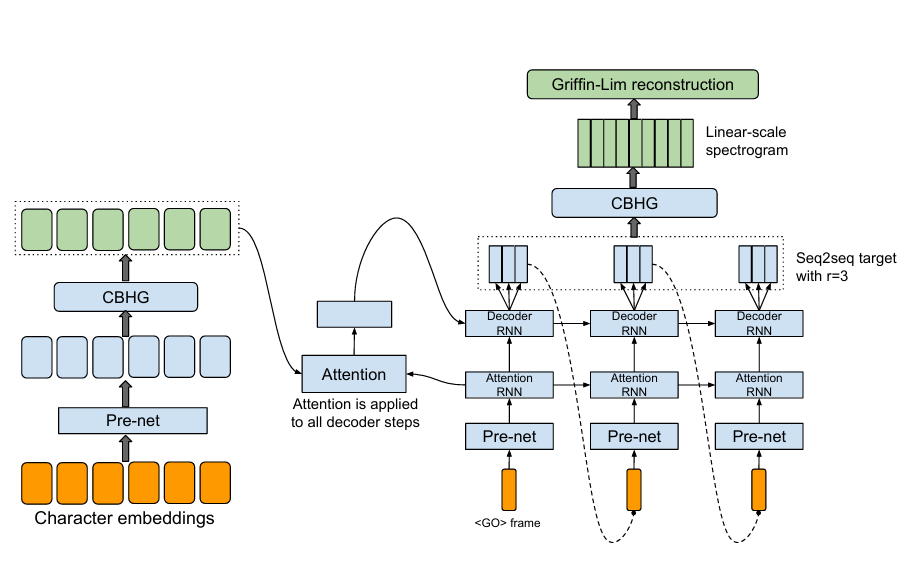
语音波形:

梅尔频谱:
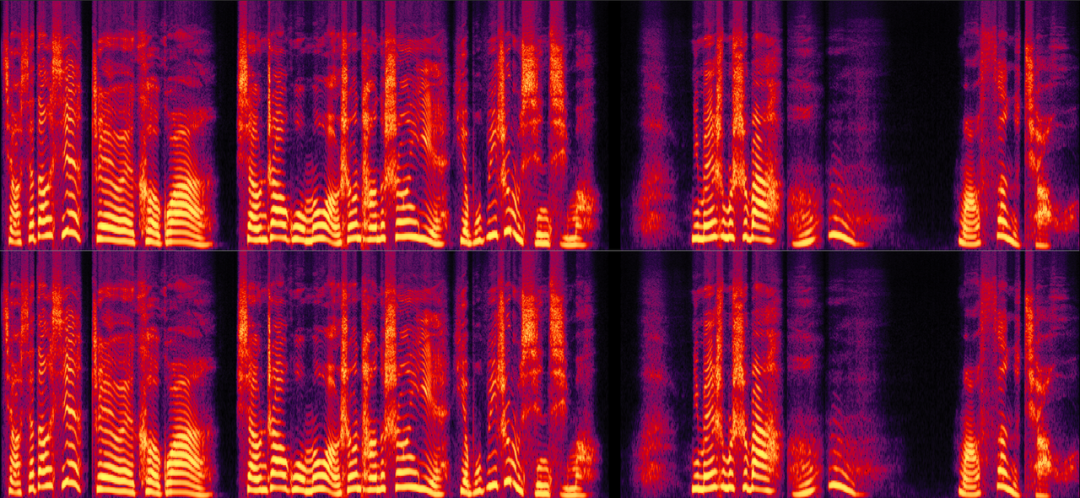
Tacotron 的核心创新在于引入双向注意力机制(Bidirectional Attention),解决文本序列与音频序列的长度不对齐问题。注意力矩阵(Attention Matrix)会呈现文本字符与音频帧的对应关系,相当于提词器,避免传统方法中手动标注音素时长的需求,同时支持变长输入(如不同长度文本),提升模型泛化性。
Tacotron 采用自回归(Autoregressive)生成模式,即每个时间步的输出依赖于前一步的结果,这样做的好处有两个:
· 生成序列具有上下文连贯性,梅尔频谱的时序特征更自然,尤其在处理长句时韵律更流畅;
· 模型通过最大似然估计训练,目标函数与真实数据分布对齐。
这同样也造成了Tacotron的缺陷:
· 生成速度慢:需按时间步逐个生成,无法并行计算,实时性差,这是自回归模型最大的局限性
· 注意力塌陷(Attention Collapse):训练时可能出现注意力集中于固定位置,导致生成重复或模糊频谱
· 误差累积:某一帧的生成错误可能影响后续所有帧(如注意力对齐偏差导致频谱失真)
· 音质依赖声码器:Tacotron 本身仅生成梅尔频谱,波形质量受 GriffinLim 等声码器限制
于是,在2018年推出架构优化版的 Tacotron 2,主要优化注意力机制,引入梅尔频谱预测,以及使用WaveNet 替换之前GriffinLim作为声码器VoCoder,使语音自然度接近人类水平。
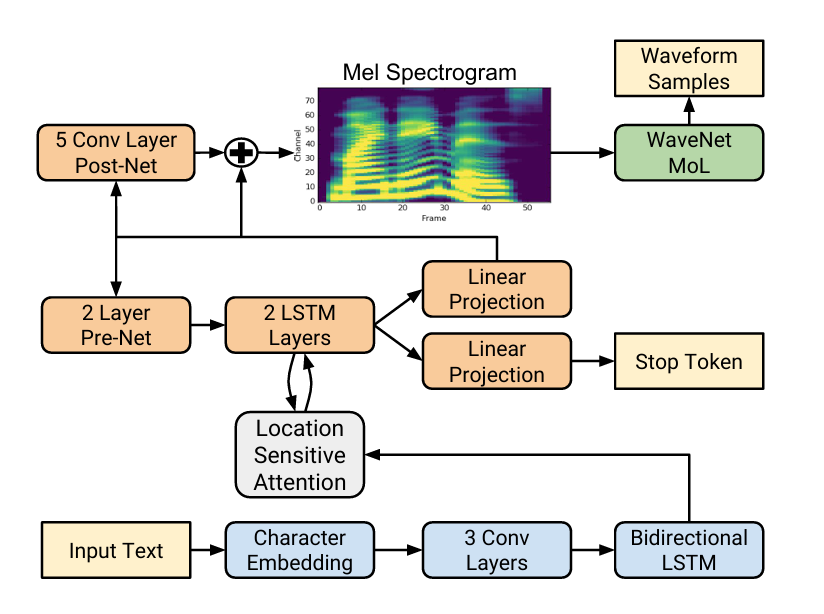
Tacotron 作为一个承前启后,开创一个全新时代的模型,其主要用注意力机制解决文本 音频对齐问题,以端到端自回归模式实现梅尔频谱生成。尽管存在生成速度慢、声码器依赖等局限,但其开创的端到端范式彻底改变了 TTS 研究路径,后续模型(如 FastSpeech、VITS)均在其基础上优化了效率与音质,使其成为现代语音合成技术的重要里程碑。
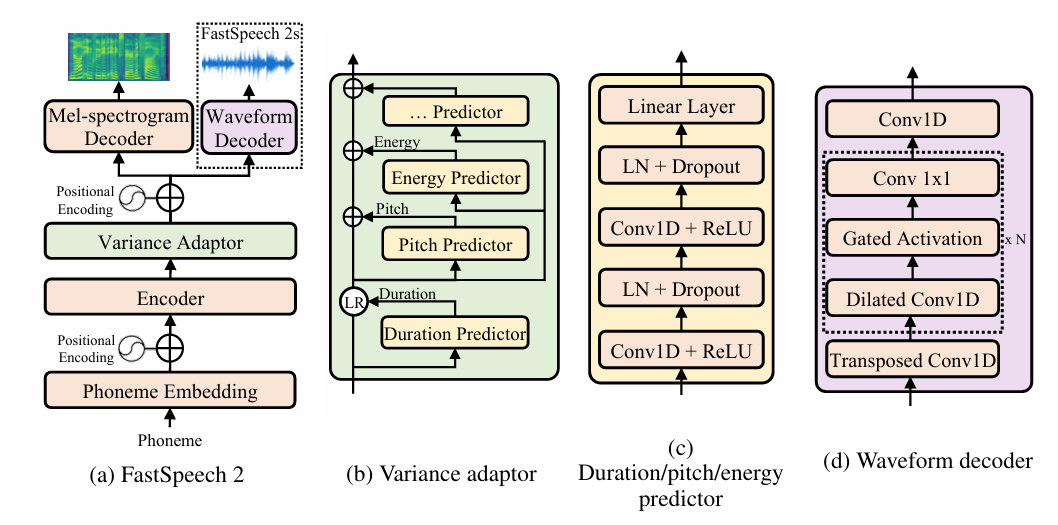
2. FastSpeech
FastSpeech 是 2019 年由微软研究院与浙江大学联合提出的语音合成模型,其核心价值在于通过非自回归(NonAutoregressive)架构彻底解决了 Tacotron 等传统端到端模型生成速度慢的问题,同时保证了音质。如果说Tacotron 是开创端到端 TTS 模型时代的话,那FastSpeech 则是从自回归到非自回归的 TTS 速度革命。
Tacotron 作为首个端到端 TTS 模型,存在自回归生成导致速度极慢、注意力机制不稳定的问题,FastSpeech 的核心目标是:在不牺牲音质的前提下,将 TTS 生成速度提升 10100 倍。
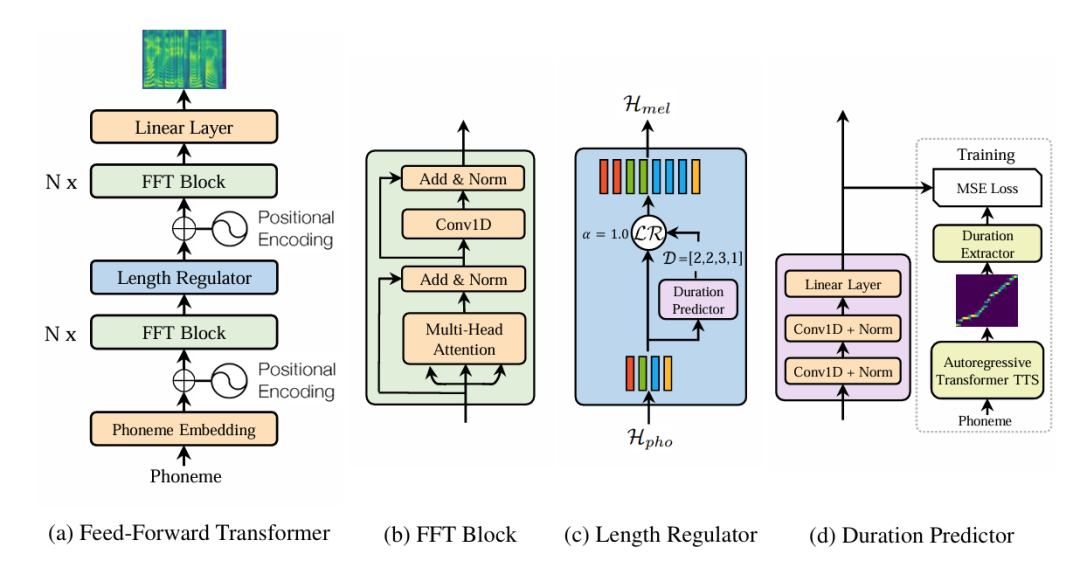
FastSpeech核心技术创新:
1.时长预测器的显式对齐
传统 TTS 通过注意力隐式对齐文本与音频,而 FastSpeech 通过独立网络预测音素时长,使对齐过程可解释、可控制。例如:
· 输入 “今天天空很蓝”,时长预测器可根据语法规则(如 “很” 作为副词可能时长较短)生成对应帧数;
· 支持手动调整时长参数,实现语速控制(如生成快速播报或慢速语音)。
2. 无自回归的并行生成
自回归模型(如 Tacotron)的生成时间与音频长度成正比,而非自回归模型的生成时间仅与文本长度相关。实测显示:
· Tacotron 生成 10 秒语音需约 2 秒(CPU),FastSpeech 仅需 0.02 秒,速度提升 100 倍;
· 支持批量处理多句文本,进一步提升工程部署效率。
3. 对抗训练与数据增强
· 引入对抗训练(Adversarial Training) 优化频谱细节,缓解非自回归模型可能出现的 “频谱模糊” 问题;
· 通过数据增强(如随机插入静音、调整音高)提升模型泛化性,减少过拟合。
2020 年发布的 FastSpeech 2 在初代基础上进一步优化:
1.引入梅尔频谱预测的梅尔损失(Melspectrogram Loss)
增加多尺度频谱损失(MultiScale Spectrogram Loss) 和对抗损失(Adversarial Loss),使生成的梅尔频谱更接近真实语音,音质提升 30% 以上;
2.改进时长预测器
采用更轻量级的神经网络结构(如 CNN 替代全连接层),减少参数数量,同时提升时长预测精度;
3.支持更多语音属性控制
显式建模音高(Pitch)、能量(Energy)等韵律特征,用户可通过调整参数生成不同情感、语气的语音。
FastSpeech技术的推出,带来了极大的影响:
1. 推动 TTS 工业化落地,非自回归架构使 TTS 在手机、智能音箱等实时场景中可用,例如微软 Azure Speech、谷歌 Cloud TTS 等服务均基于 FastSpeech 技术;
2. 启发后续模型设计,后续主流 TTS 模型(如 VITS、Neural Speech)均采用非自回归框架,FastSpeech 被视为 “TTS 从实验室走向产业的转折点”;
3. 多语言与多模态扩展,基于 FastSpeech 的架构可轻松适配多语言(如中文、英文、日文混合语音),并与图像、文本等模态结合,实现跨模态语音生成。
FastSpeech 的核心贡献在于:用显式时长预测替代隐式注意力对齐,以非自回归并行生成突破速度瓶颈。其技术路径表明:TTS 模型无需依赖自回归机制即可实现高质量语音合成,这为后续模型(如 VITS)的发展奠定了基础。如今,FastSpeech 及其衍生架构已成为工业界 TTS 系统的标准配置,支撑着智能客服、有声书生成、虚拟主播等千亿级应用场景。
3. VITS
VITS(Variational Inference with Tacotronbased Speech Synthesis)是 2021 年由韩国科学技术院提出的语音合成模型,它首次将变分自编码器(VAE)、流模型(Normalizing Flow) 与对抗训练结合,实现了 “高音质” 与 “可控性” 的双重突破 。其生成的语音自然度超越人类录音水平,它的推出,完全是一场颠覆 TTS 的端到端神经声码器革命,被称为 “TTS 领域的 GPT3 时刻”。
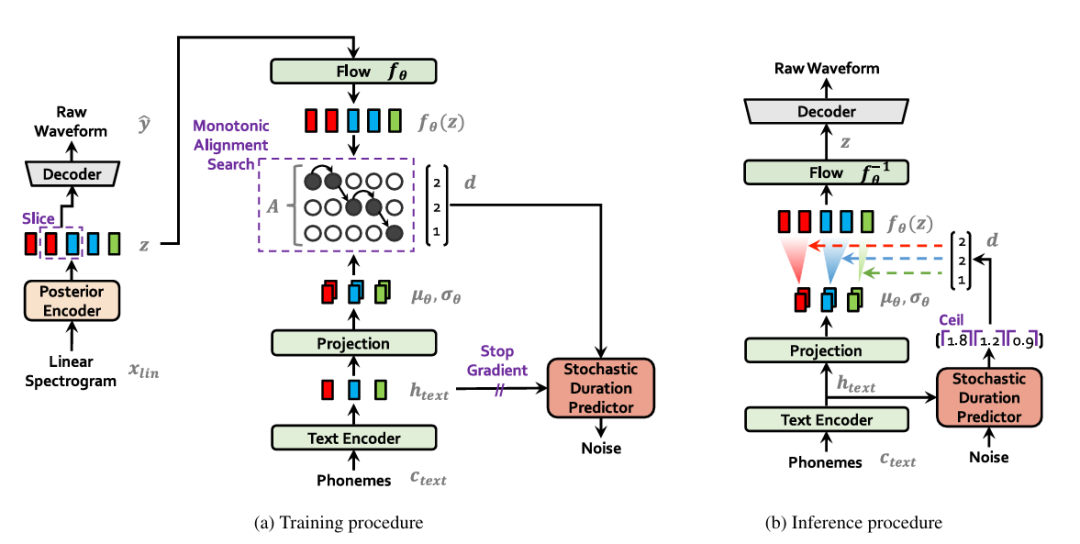
VITS 的核心突破在于:用统一的端到端架构同时解决上述问题,其灵感来源于三大技术路线的融合:
· Tacotron 的文本处理能力:保留 Transformer 编码器处理文本序列;
· VAE 的隐变量建模:通过潜在变量压缩语音特征,实现属性解耦;
· 流模型的可逆变换:将离散语音转换为连续分布,支持高效生成。
VITS 一经推出,就迅速成为业内模型的新标准,目前有很多开源模型都是基于此架构,甚至用在了声音转换的变声器上,网络上爆火的AI 翻唱就是基于此技术的变声系统实现的。VITS 所带来的技术创新与升级时全方位的。
1. 隐变量解耦:让语音属性 “可编辑”
通过 VAE 将语音分解为 “内容” 与 “风格” 隐变量,支持:
· 零样本语音转换:输入文本 + 目标说话人音频(仅需几秒),即可生成该说话人的语音;
· 情感实时调节:通过修改隐变量中的情感参数,同一文本可生成高兴、悲伤等不同情绪语音;
· 跨语言音色迁移:例如将中文语音的音色迁移到英文文本,保持语义不变。
2. 端到端神经声码器:抛弃传统声码器
传统 TTS 需先生成梅尔频谱,再通过 GriffinLim 或 WaveGlow 转换为波形,而 VITS 直接从文本生成波形,省去独立声码器步骤,生成速度提升 30%,且避免声码器引入的失真,同时,支持 24kHz 高保真语音生成,音质超越人类录音(MOS 评分 4.5+,满分 5 分)。
3. 对抗训练与多尺度判别器
引入多尺度判别器(MultiScale Discriminator),使不同尺度的判别器分别关注语音的低频基频(如语调)和高频谐波(如齿音细节),同时,对抗损失迫使生成语音在频谱和波形层面同时接近真实语音,解决非自回归模型的 “频谱模糊” 问题。
4. 无显式对齐的端到端训练
得益于 自动对齐 monotonic alignment search 技术,无需像 FastSpeech 一样依赖时长预测器或外部对齐数据,通过隐变量和流模型自动学习文本与语音的时序对应,成为了一个正在意义上的 GenAI 模型,更具有灵活性。不需要额外标注训练数据,同时避免 Tacotron 等模型的注意力塌陷问题。
VITS 的革命性在于:用隐变量建模打破文本与语音的映射壁垒,使语音合成从 “信号处理” 升级为 “语义 情感的跨模态翻译”。其技术路径表明:未来 TTS 模型不仅要 “像人说话”,更要 “理解说话的意图与情感”。从实验室到产业界,VITS 正在推动语音交互从 “功能型” 向 “情感型” 跨越,而这仅仅是多模态生成式 AI 的冰山一角。VITS的推出,更是让声音克隆技术得到飞跃发展。
开源代表:
GPTSoVITS
· 开发者: 花儿不哭(B站ID)
· Github 仓库地址:RVCBoss/GPTSoVITS: 1 min voice data can also be used to train a good TTS model! (few shot voice cloning)
sovitssvc (AI 孙燕姿之源)
· 目前停止更新
· GIthub 仓库地址:svcdevelopteam/sovitssvc: SoftVC VITS Singing Voice Conversion
RVCwebUI
· 开发者: 花儿不哭等
· Github 仓库地址:RVCProject/RetrievalbasedVoiceConversionWebUI: Easily train a good VC model with voice data <= 10 mins!
OpenAudio(原名 FishSpeech)
· 开发者:fishaudio/冷月大神,B站ID: 冷月2333(南京信息工程大学、华中科技大学)
· 论文地址:Fish-Speech: Leveraging Large Language Models for Advanced Multilingual Text-to-Speech Synthesis
· Github 仓库地址:fishaudio/fish-speech: SOTA Open Source TTS
· 支持多种语言(中文、英语、日语、德语、法语、西班牙语等),并且最近登顶 TTS-Arena2 榜单
四、预训练大模型
1. VALL-E
2023年,微软推出的新的范式,将语音合成问题转变为语音建模问题。
其在论文中提到,由于语音和文本在信息密度和长度上的巨大差异,传统采用端到端方法的语音合成系统,一般流程均为 音速 --> 梅尔频谱图--> 声波,主要使用诸如 mel-spectrogram 这样的连续性声学特征来作为中间表征,语音合成也变为了相对较难的信号回归问题。那么,能否使用离散的声学特征来作为中间表征呢,这样建模成离散信号的分类问题学习的难度或许会更低?所以,在 VALL-E 中,其流程为音素-->离散音频编码-->波形。
这跟 VITS 的思路很像,但是 VITS 的缺陷就在于,需要说话人的训练集,并且这个训练集需要保证语音的质量非常高,所以在使用 VITS 训练之前,需要先爬取对应说话人的数据,并且对这些数据进行处理,提纯、去噪,只保留人声等,只有用处理过的数据,才能针对模型进行下一个训练、微调的步骤,才能让VITS 训练出来的模型能够输出说话人的声音。这也就导致了 VITS 存在泛化能力差的问题。
2022年底,GPT3的火爆,也给语音合成技术带来一种全新的思路,也就是尽可能的使用大规模和多样化的数据进行模型训练。VALL-E 就是首个基于语言模型的语音合成(TTS)框架,它利用了大规模、多样化和多说话人的语音数据。在模型的预训练阶段,VALL-E 使用了一个包含60k小时、超过7000名独特说话人的语料库,LibriLight。
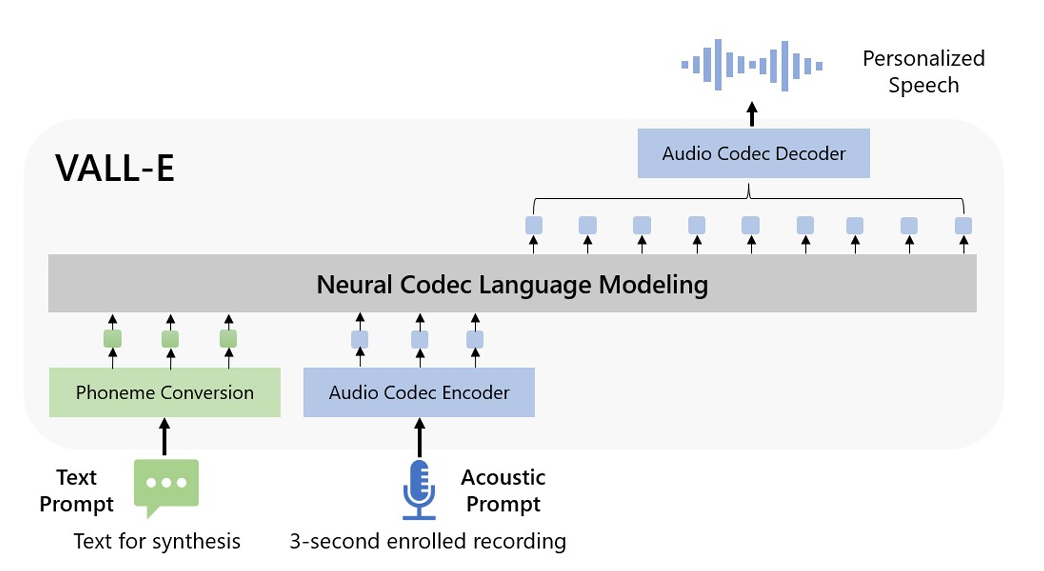
预训练完成之后,生成的东西被称作为音频编解码器语言模型。在此基础上,为了合成个性化语音(例如零样本 TTS),VALL-E 基于 3 秒的注册录音的声学标记和音素提示生成相应的声学标记,分别约束说话人和内容信息。最后,生成的声学标记用于通过相应的神经编码解码器合成最终波形。
从音频编解码器模型中提取的离散声学标记使我们能够将 TTS 视为条件编解码器语言建模,并且可以利用先进的基于提示的大模型技术来处理 TTS 任务。声学标记还允许我们通过在推理过程中使用不同的采样策略来生成多样化的合成结果。
于是,将 TTS 江湖中出现了一个能够一统武林的架构,并且还具有很强的拓展性。所以从2023年开始,就陆陆续续诞生了一大批类似架构的开源语音模型,比如:
2. Index-TTS
开发者:哔哩哔哩
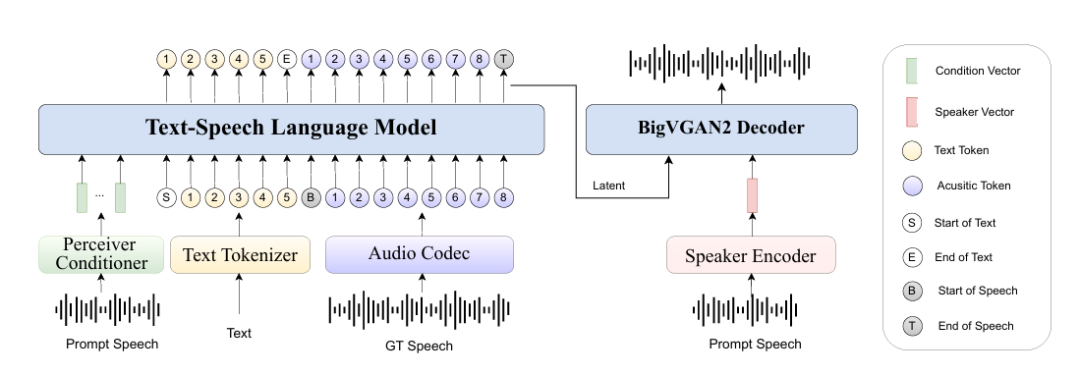
· demo 地址: IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System(https://index-tts.github.io/)
· Github 仓库地址:index-tts/index-tts: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System(https://github.com/index-tts/index-tts)
· 论文地址:[2502.05512] IndexTTS: An Industrial-Level Controllable and Efficient Zero-Shot Text-To-Speech System(https://arxiv.org/abs/2502.05512)
3. CosyVoice2
开发者:阿里巴巴通义实验室
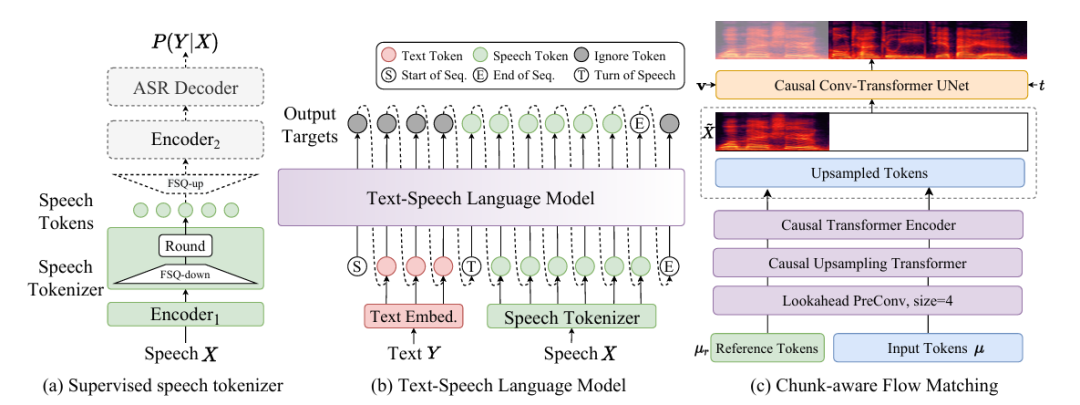
CosyVoice2 效果展示: CosyVoice2.0(https://funaudiollm.github.io/cosyvoice2/)
· Github 仓库地址:FunAudioLLM/CosyVoice: Multi-lingual large voice generation model, providing inference, training and deployment full-stack ability.(https://github.com/FunAudioLLM/CosyVoice)
· 论文地址:[2412.10117] CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models(https://arxiv.org/abs/2412.10117)
4. Mega-TTS
开发者:字节跳动、浙江大学
· Github 仓库地址:bytedance/MegaTTS3(https://github.com/bytedance/MegaTTS3)
· 体验地址:MegaTTS3 Demo - a Hugging Face Space by ByteDance(https://huggingface.co/spaces/ByteDance/MegaTTS3)
六、未来
技术发展:
· 多模态融合,语音、视觉、触觉等,实现数字人在表情、语音、动作方面实现同步;
· 情感加强升级,实现连续、自然的情感,电源《Her》中的场景近在眼前;
· 小语种覆盖;
应用:
· 虚拟主播等产业;
· 工业级实时交互:车载语音、客服等
· 无障碍服务:视障人群,盲文转语音
法律与伦理方面
· 利用合成语音进行诈骗、传播虚假信息等,目前还没有好的办法去准确识别;
· 各个技术厂商在自己生成的声音中加上声纹技术,用于识别是否为AI生成语音;
声音授权技术
声纹鉴定技术

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)