医患沟通评价系统(6)——降低唇形同步延迟及性能需求
上期博客已经实现了流式输出,纯语音对话的延迟已经达到了实时对话的标准,主要影响体验的还是唇形同步,当前项目使用Audio2Face插件,但插件使用深度学习算法计算口型,需要用上GPU跑模型,就导致对电脑性能要求极高(天选4笔记本带不动)本博客将记录我对基于Oculus Lipsync插件的音频驱动唇形方案,实现纯CPU和低性能需求的唇形同步
1. 方案背景与技术可行性分析
1.1 为什么重新启用 Oculus Lipsync?
虽然 Meta 官方已停止对 Oculus Lipsync 插件的维护,且原版插件不原生支持 UE5.6 以及实时唇形同步(原设计主要用于离线动画烘焙),但该插件的核心算法依然具有极高的应用价值。
其底层逻辑为:实时分析音频的波形,计算出“音素(Visemes)”的权重,进而驱动面部表情。
随着团队对 UE C++ 底层 API 掌握的深入,我们决定对该插件进行二次开发。只要能实时提取出插件计算的音素权重,并将其直接映射到面部骨骼或表情曲线上,即可实现低延迟的实时唇形同步。
1.2 插件的集成与编译
由于官方版本不兼容新版引擎,我们采用了 GitHub 社区维护的 UE5 增强版开源分支。
-
将目标项目转换为 C++ 项目。
-
将增强版插件引入项目并重新编译。
-
成功在 UE5 开发环境中恢复了插件的正常加载与运行。
2. 技术实现:音频数据向音素权重的转化
音频向音素的转换主要通过调用插件的 FeedAudio() 函数来实现。由于底层的 ProcessFrameAsync() 是逐帧异步调用的,而输入的音频通常是连续的数据流,因此需要设计一个音频切片辅助函数,将连续音频剪裁为适应渲染帧率的数据块。
数据量计算示例如下:
-
运行帧率:30 fps(单帧时长约为 1/30 秒)
-
音频参数:采样率 24000 Hz,单声道,16-bit(2 字节)
-
单帧所需数据量:
单帧字节数=24000 Hz×2 Bytes30 fps=1600 Bytes单帧字节数=30 fps24000 Hz×2 Bytes=1600 Bytes
通过该辅助函数,我们能够以每帧 1600 字节的速率向插件输送音频切片,从而确保音素权重的计算与画面渲染保持同步。
3. 技术实现:音素权重驱动面部表情
在最新的 UE 版本中,MetaHuman 的面部蓝图(如早期的 Face_BP)结构发生了较大调整。为了在当前版本中准确驱动 MetaHuman 的面部,我们探索并对比了以下两种技术方案:
方案一:通过 Control Rig 驱动
-
对应资源:Metahumans/Common/Face/CR_MetaHuman_HeadMovement_IK_Proc
-
实现逻辑:导入 MetaHuman 预览网格体后,通过面部绑定控制器的 UI 手动或代码调整面部表情。
-
评估:该方案的缺点在于代码调用复杂度极高。MetaHuman 面部拥有 51 个控制点,每个控制点均对应一条曲线。通过单一的音素权重去联动多个 Control Rig 控制点较为繁琐,且缺乏直观的映射关系,不利于美术设计师进行后期微调。
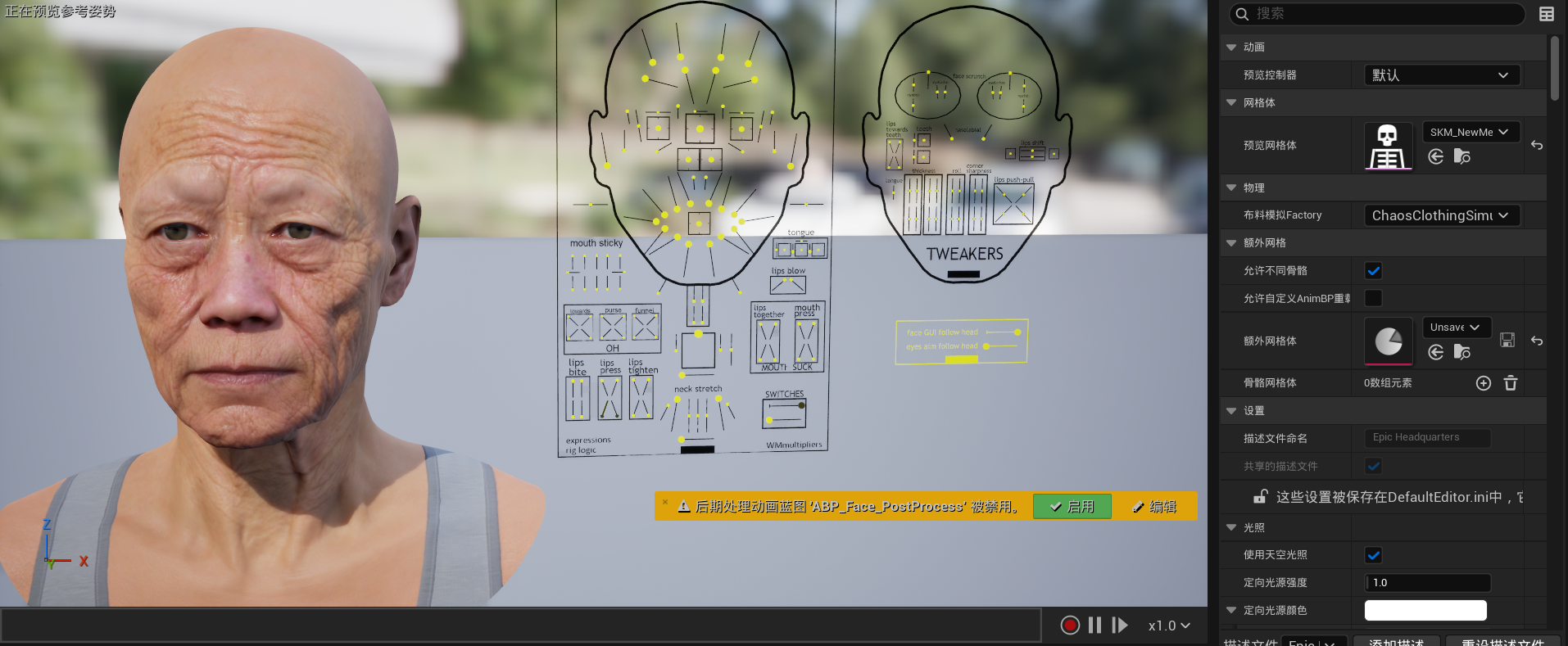
这样做有个致命缺陷:代码调用难度极高。Metahuman面部有51个控制点,每个点代表着一条曲线,虽说动画蓝图可以通过ControlRig接口驱动控制点变化,但是只通过一个音素去驱动多个Control Rig太过于复杂,且没有直接操作、所见即所得,不利于美术调试。
方案二:通过姿势资产(Pose Asset)驱动(最终采用)
-
对应资源:Metahumans/Common/Face/ARKit/PA_MetaHuman_ARKit_Mapping
-
实现逻辑:利用该资产中烘焙好的 ARKit 标准姿势,通过动态调整姿势权重来组合出各种面部表情。
-
评估:该方案交互直观。由于其支持姿势混合(Pose Blending)生成新姿势,我们能够非常方便地将计算出的 16 种标准音素(Visemes)与对应的唇形进行一一映射。在动画蓝图中,通过 Modify Curve 接口即可直接完成对这些曲线权重的实时调用。
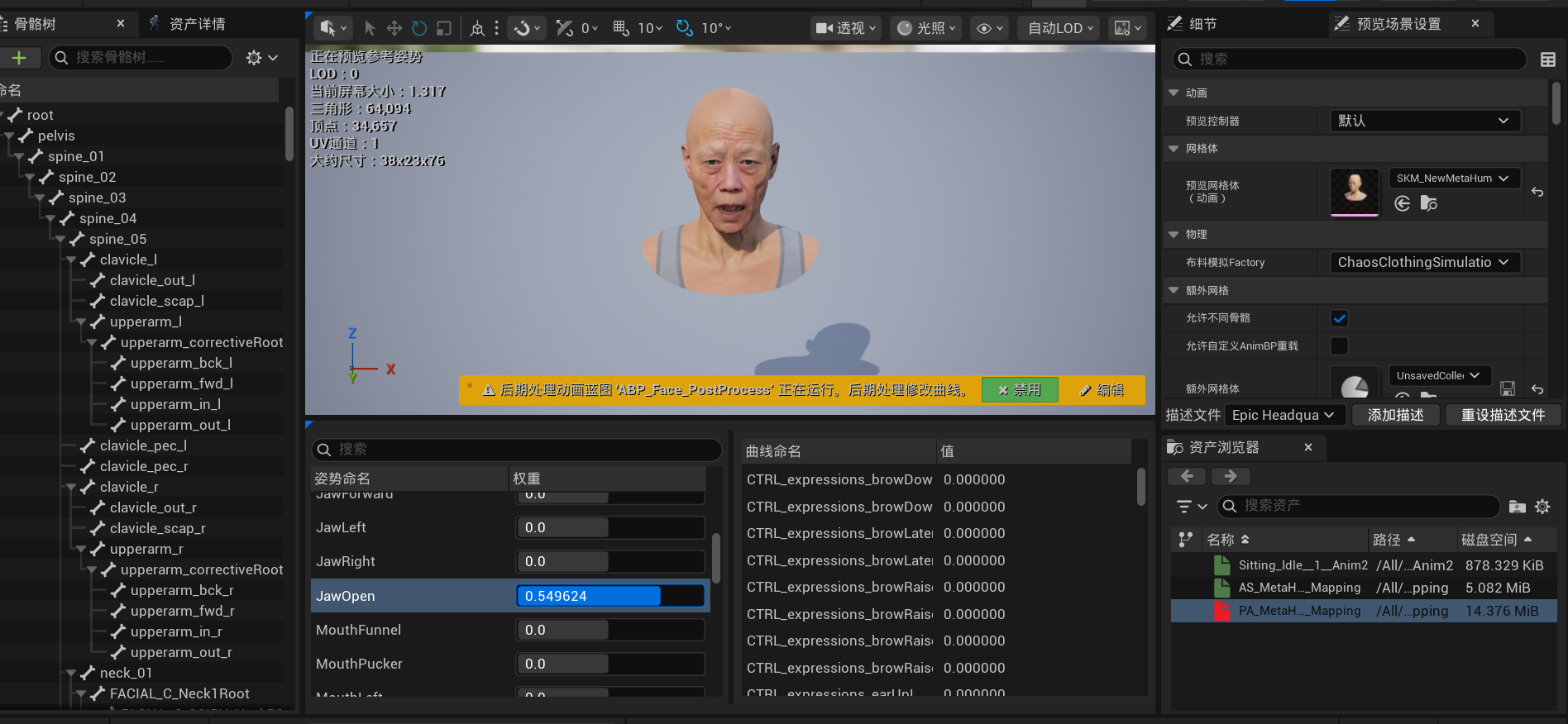 这个方案较Control Rig最好的点就是交互直观且易懂,最重要的一点,它支持姿势混合后生成新姿势,这意味着我们可以为16种音素设立一一对应的唇形。
这个方案较Control Rig最好的点就是交互直观且易懂,最重要的一点,它支持姿势混合后生成新姿势,这意味着我们可以为16种音素设立一一对应的唇形。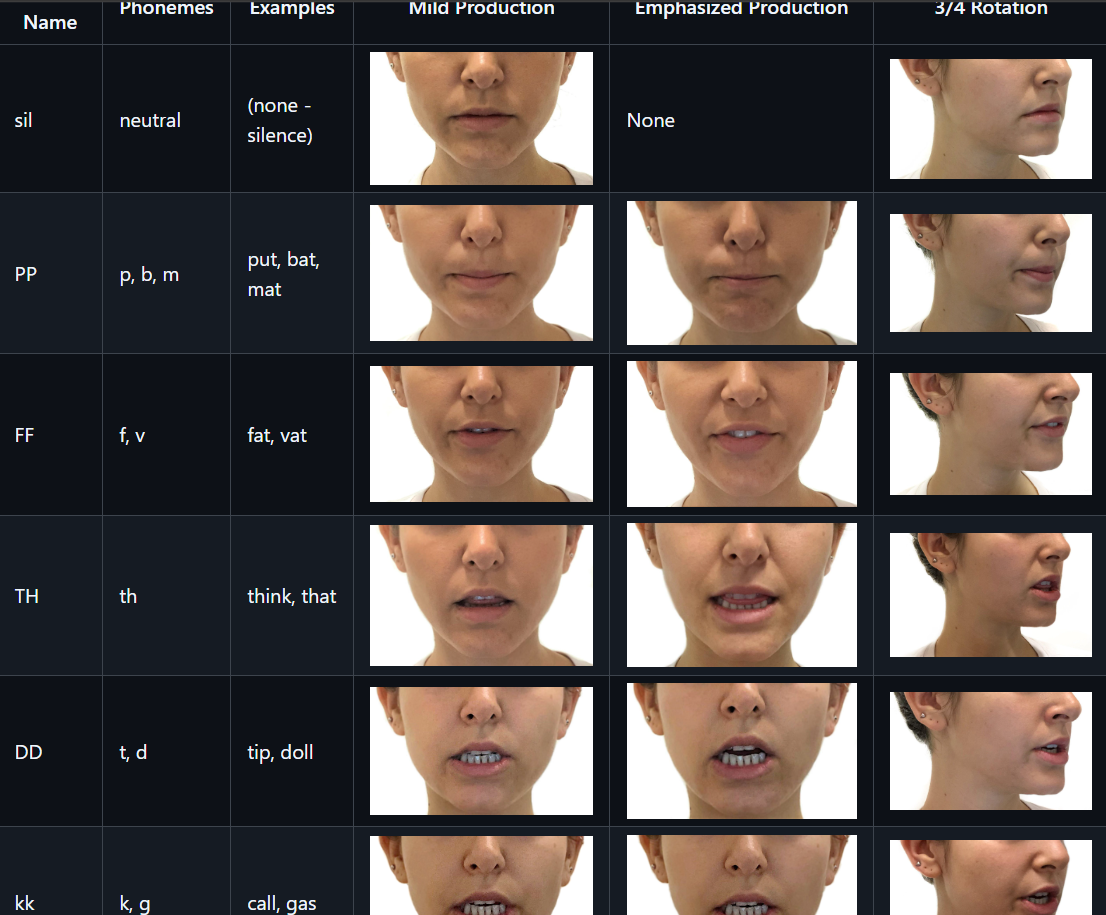
通过Modify Curve接口即可实现动画的调用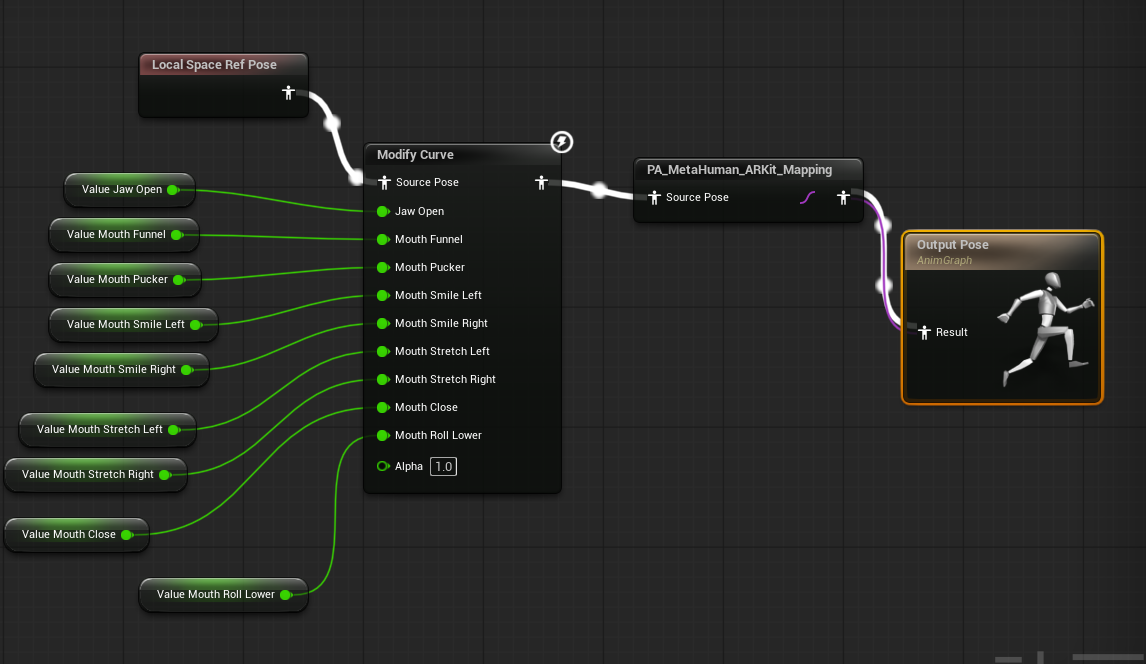
4. 当前进展与后续计划
-
当前进展:
目前,基于 Pose Asset 驱动的实时唇形同步原型已在本地测试环境中实现了较为流畅的运行,技术可行性得到了初步验证。 -
下一步计划:
本周我们将协同美术团队,针对 16 种标准音素逐一精细化设计对应的面部与唇部姿势,以优化口型过渡的自然度,进一步提升唇形同步的整体视觉效果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)