10分钟读懂ICML 2026最新成果:AI Agent如何精准预测药物结合靶点
开篇总结
在AI制药(AIDD)领域,多数团队常把精力放在“什么样的分子能结合”上,却忽略了更前置的瓶颈——究竟应该在蛋白质的哪个位置(靶点部位)进行干预 。
来自加州大学伯克利分校和密歇根大学的研究团队在ICML 2026 GenBio研讨会上发表了最新成果:Site4Drug 。这是一个极具创新性的AI智能体(AI Agent),它打破了传统对蛋白质三维结构的绝对依赖,仅凭一维氨基酸序列,就能通过多智能体协同推理,输出带有风险标记、可追溯决策日志的靶点预测报告,并自适应推荐最佳药物类型(小分子或抗体/多肽) 。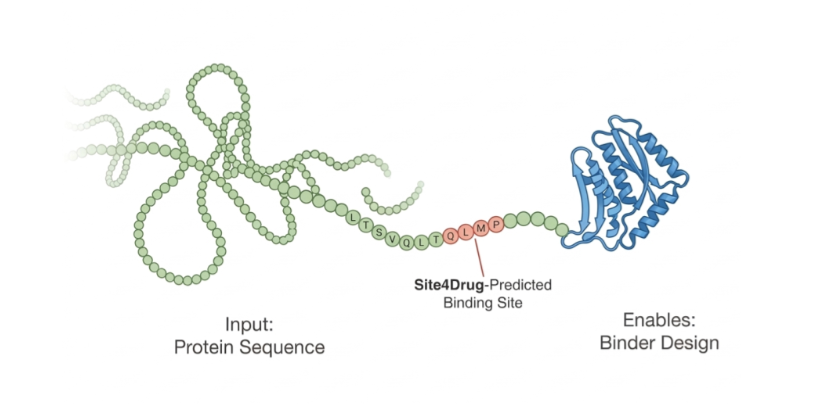
值不值得读
推荐指数: ⭐️⭐️⭐️⭐️ (4/5颗星,应用创新性极高)
适合:
AIDD/生物信息学研究者:寻找突破“结构缺失”限制的靶点发现新思路。
大分子/小分子新药研发人员:期望在分子对接或抗体设计前,快速评估高风险蛋白(如膜蛋白)的可成药位点及潜在风险 。
大模型/AI Agent应用探索者:学习如何利用多Agent专家系统(Bio/Chem/Risk Agent)解决复杂的严谨科学问题 。
预计阅读时间:
- 原论文:约 45 分钟(含附录技术细节)
- 导读版:约 8 分钟
这篇论文的价值
解决的痛点是什么?
传统的AI药物研发流程通常默认“结合位点是已知的”,然后直接跳到分子对接或虚拟筛选 。然而在实际研发中,团队往往卡在更早的一步:面对一个全新的致病蛋白,到底该针对哪个区域下手?是用小分子去掏“口袋”,还是用抗体去贴“表位” ?
特别是对于高难度的膜蛋白,由于其空间拓扑复杂、经常被翻译后修饰(如糖基化)遮蔽,很多在化学上看起来完美的“口袋”,在生物学上其实是完全被堵死、不可触及的 。一旦后续筛选失败,实验人员根本分不清是“AI分子模型算得不准”,还是“一开始就把靶点选错了” 。
为什么作者要研究这个问题?
现有的位点预测工具(如 fpocket)高度依赖高质量的蛋白质复合物晶体结构 。但对于突变频繁的病毒抗原、肿瘤新抗原或缺乏同源结构的罕见靶点,根本没有现成的三维结构可用 。作者希望创造一个“约束优先”的AI系统,像人类专家一样,先综合分析序列、拓扑和修饰等限制条件,把不靠谱的位点提前排除,并给出透明的推理过程 。
EasyReader AI论文导读示例
研究目的
开发一个名为 Site4Drug 的多智能体系统,仅基于蛋白质的氨基酸序列,实现跨药物模态(抗体、多肽、小分子)的靶点位点发现、自动模态推荐以及可审计的决策推理 。
研究方法
Site4Drug 的核心工作流分为两个模块:
- Module 1(核心发现引擎):
特征提取:利用 Kyte-Doolittle 水性图预测粗略的跨膜拓扑结构(区分暴露区与隐藏区) ;通过 MusiteDeep 预测翻译后修饰(PTM)并生成局部掩码 ;查询 ScanProsite 锁定保守基序 ,并统计半胱氨酸数量作为二硫键约束代理 。
多智能体二次评议(Reranking):基础LLM生成候选JSON列表后,由 BioAgent(生物专家)、ChemAgent(化学专家) 和 RiskAgent(风险专家) 组成专家面板,从各自专业角度对候选位点提出质询与修正,最后由 DecisionAgent(决策专家) 汇总并调整最终排名 。
Module 2(设计下游对接):将顶尖候选位点根据模态推荐自动分流。表位模式(Epitope)无缝衔接 BoltzGen 等大分子生成工具 ;口袋模式(Pocket)则手递手交棒给 DrugCLIP 等小分子评分系统 。
[蛋白质序列输入] ──> [特征提取(拓扑/PTM/基序)] ──> [LLM生成候选]
│
▼
[最终报告与模态推荐] <── [DecisionAgent汇总] <── [专家面板二次评议]
创新点
模态自适应推荐:不需要用户预先指定是做小分子还是做抗体,AI 会根据位点物理化学特性的证据,自动给出最优的药物类型建议 。
零结构依赖下的高精度:在针对 63 种小分子靶点的测试中,Site4Drug 在仅输入一维序列的情况下,预测准确率与直接使用 AlphaFold3 预测出的三维结构再运行传统 fpocket 工具的效果相当 。
可审计的“白盒”推理:输出的不只是一个简单的残基残数列表,而是一份包含“糖基化遮蔽风险”、“跨膜区重叠”等结构化风险标签(Risk Flags)和决策日志的完整审计报告 。
以上内容为 EasyReader自动生成导读的部分节选。
用EasyReader高效阅读论文,下载体验:
https://www.easyreader.com.cn/
✓ 核心创新点拆解
✓ 关键实验结果总结
✓ AI论文问答
✓ 思维导图
✓ 还原排版 中英对照翻译阅读
如果你只看10分钟
如果你时间紧迫,建议按照以下顺序快速过完这篇论文的核心精华:
-
第 1-2 页 (Section 1 & 2):必看。这里清晰勾勒了药物研发上游“找靶点位置”的行业残酷现状,以及将该问题 reframes(重构)为“约束优先”决策问题的精妙逻辑 。
-
第 3 页 (Section 3.1 & 3.3):重点看 Section 3.3 (Reranking with Specialist) 。这里展示了 BioAgent、ChemAgent、RiskAgent 是如何吵架并达成共识的,是理解大模型在生物学垂直领域落地(Agentic AI)的绝佳参考 。
-
第 5-6 页 (Section 4.1 & 4.2):看图表。直接看 Fig. 3 的实验对比 。重点关注第 4.2 节的消融实验(Ablation study) ,它证明了加入生物学约束特征后,模型性能相比普通纯序列 Prompt 提升了数倍,打消了对“大模型只是在背序列”的质疑 。
可以跳过的部分:
Section 5 (Module 2 案例应用) :这部分主要是在 EGFR 这一单个经典靶点上做的概念验证(Proof-of-concept),数据量较小 ,如果不是做 EGFR 相关研究的,可以直接跳过,不影响对系统核心能力的把握。
总结
这篇论文非常值得关注,因为它切中了 AI 制药从“精细筛选”走向“前端决策”的关键一步 。在结构生物学数据依然昂贵且充满不确定性的今天,用生物学先验约束去对齐大模型的软性推理,是一条非常务实的技术路线 。
谁应该继续阅读原论文:正在开发大模型生物智能体、或者正在攻坚无结构/难成药靶点(突变体、膜蛋白)的计算生物学专家,论文附录中的 Prompt 设计和训练细节(Appendix B/C/D)极具实操价值 。
谁只看导读即可:普通的湿实验背景制药工程师,或者仅需了解 AIDD 行业最新技术风向的技术投资人,掌握其“序列输入、多Agent评议、白盒输出”的逻辑即可 。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)