python3免费教程
引言
本文主要是针对python3核心语法体系一个完整介绍,相当于一本完整免费电子书了,python是一门充满陷阱的语言,这些陷阱被美化成了灵活性。在语言面向对象改进过程中,不断打补丁,语法变得稀奇古怪,很多特性依赖于双下划线方法或者属性(比如__init__等一大堆),美其名为魔法。
python在数据分析、人工智能领域使用得非常多、处于领先地位。脚本语言特性和性能问题日益凸显,语言本身不断在优化。但是因为不是天生强类型、面向对象语言,很多特性使用起了会很别扭。这里列出来一些主要的变化(细节变化很多,最明显的就是print函数):
1 解释器优化:3.11 引入了新的评估循环(Evaluation Frame),速度提升 10-60%。
2 JIT 编译实验:3.13/3.14 持续探索即时编译(JIT)技术,进一步提升运行时性能。
3 自由线程模式 (No-GIL):Python 3.13/3.14 的重大突破。引入了可选的“自由线程”构建版本,移除了全局解释器锁 (GIL),允许真正的多线程并行计算(此前受 GIL 限制,多线程无法利用多核 CPU 进行计算密集型任务
4 类型提示
python是靠缩进来组织代码块的,这点要注意,容易出问题(这里思考一个问题,格式化插件格式化代码的标准是什么,会不会把你代码逻辑搞变了😏)。pyhon兼容性相对于像java这类语言差很多,如果对python2或者以前历史版本比较清楚的人,应该能感受到pyhon3和以前版本差异很大。这也是对长期稳定运行大型程序一大挑战,容易给别人埋坑。这玩意早期都是很混乱的,面向对象权限限制更多的是约定,所以有很多东控制不好,没有人管控,出现了很多要求把python改成java实现的,代价可不小.很多公司都是搞烂了才找架构师(或者就是不管),这种到后期都不好搞,代价很大,做过很多系统,从菜鸟开始就是独立设计和开发,前后端都做过,都不知道架构师长啥样。现在要稍微好一些(主要是有环境隔离和依赖管理,但工程规范较差),可以参看我另外一篇博客。
学一门语言,一般都不是一两天就搞得定的,可能都要一周以上(这里不说生态和框架哈,要学这些就扯远了,长的可能一年半载都学不完),所以要淡定。python看起来简单,实际上很复杂,有点像汉语和英语区别,汉语一小本字典你都不用记完,你基本没有不认识的。但是英语你把那个大部头牛津词典记完,你还是经常遇到一些你不熟悉的用法。Python为了爽,想加啥就加啥,代价就是有点烧脑壳。
备注:实践pyhon版本:3.13.5
1 基本数据类型
Python 的基本数据类型是解释器内置的,无需导入任何模块即可直接使用。主要包括:
数值型:int (整数), float (浮点数), complex (复数), bool (布尔值)。
序列型:str (字符串), list (列表), tuple (元组), range (范围)。
映射型:dict (字典)。
集合型:set (集合), frozenset (冻结集合)。
其他:bytes, bytearray, NoneType (None)。
1.1 数字
数字和字符串都是属于不可变类型,不过确定的话,可以用id()函数确定其身份。早期python版本可能会缓存一些小整数,导致认为整数是可变类型的的错觉,java也有类似机制
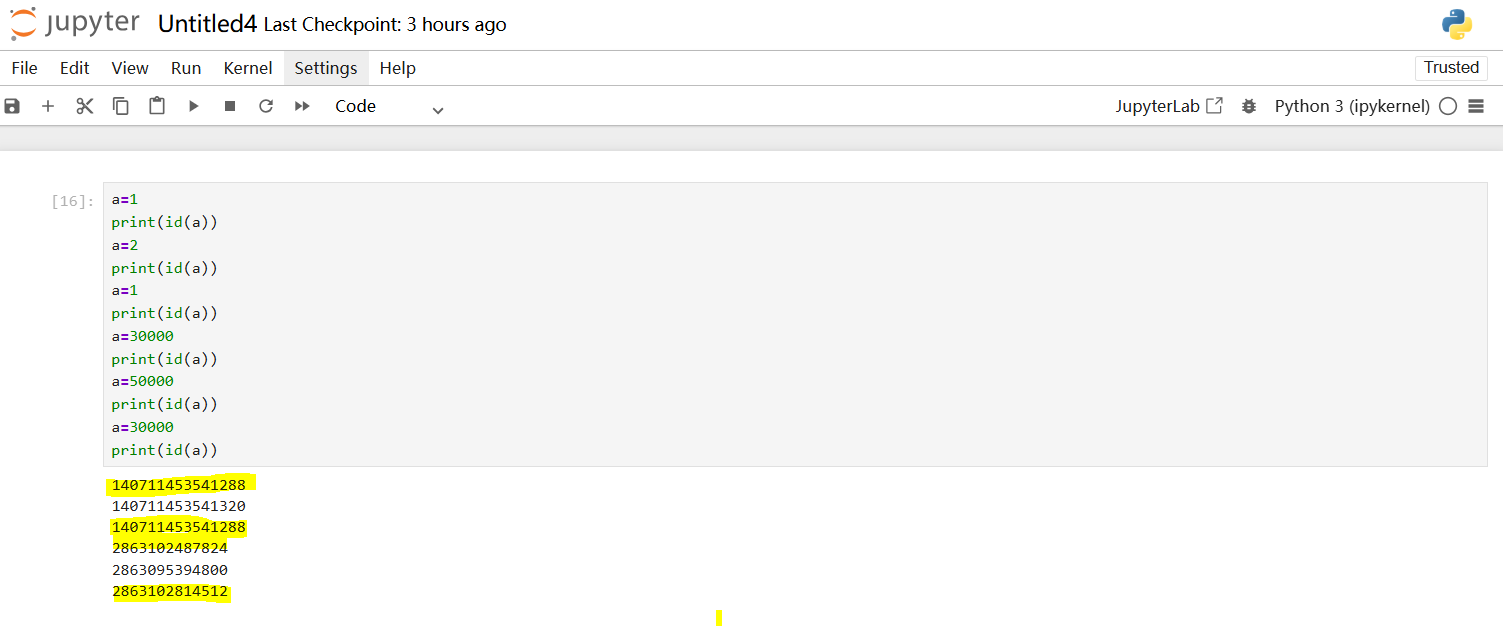
1.1.1 整数
在 Python 2 中:
int:表示固定精度的整数(通常是 32 位或 64 位,取决于平台)。
long:表示任意精度的整数,用于处理超出 int 范围的大数。
两者是不同类型,需要显式转换(如 long(x))。
在 Python 3 中:
移除了 long 类型。int 类型现在直接支持任意精度,自动处理大整数,行为等同于 Python 2 中的 long。不再有 int 和 long 的区别,所有整数都是 int 类型。你不需要担心整数溢出问题(只要内存允许),也不需要区分 int 和 long
1.1.2 浮点数
浮点数在类型系统上也经历了简化
Python 2:
存在 float 类型。没有专门的“长浮点数”类型,但底层 C 实现依赖平台。主要问题在于 int 和 long 的分裂导致涉及大整数转换浮点数时行为复杂。
Python 3:
只有 float 类型。由于 int 已经统一为任意精度,float 与 int 之间的转换逻辑更加清晰:将巨大的 int 转换为 float 可能会损失精度(因为 float 只有 64 位),但这在两个版本中都会发生,只是 Python 3 的类型提示更明确
| 特性 | Python 2 | Python 3 |
|---|---|---|
| 整数除法行为 | 地板除 (Floor Division) 如果两个操作数都是整数, / 会截断小数部分,返回整数。5 / 2 → 2 |
真除法 (True Division) 无论操作数类型, / 总是返回浮点数。5 / 2 → 2.5 |
| 如何获取地板除 | 使用 / (当操作数为整数时) 或 // (需 from __future__ import division) |
必须使用 // 运算符5 // 2 → 2 |
| 如何获取真除法 | 需导入未来特性:from __future__ import division之后 / 行为同 Python 3 |
默认行为,无需导入 |
| 混合运算 | 只要有一个是浮点数,结果就是浮点数。5.0 / 2 → 2.5 |
同左,行为一致。 |
# Python 2
print 5 / 2 # 输出: 2 (整数)
print 5.0 / 2 # 输出: 2.5 (浮点数)
# Python 3
print(5 / 2) # 输出: 2.5 (浮点数)
print(5 // 2) # 输出: 2 (整数,地板除)1.1.3 decimal
需要导入,所以不是基本数据类型,遇到需要考虑到精度的计算场景,比如金融,就可能要使用到decimal,初始化的时候一定要带引号
from decimal import Decimal, ROUND_HALF_UP
# 错误示范 (float)
print(0.1 + 0.2) # 0.30000000000000004
# 正确示范 (Decimal) - 必须用字符串初始化以保证精度
a = Decimal('0.1')
b = Decimal('0.2')
total = a + b
print(total) # 0.3
# 设置舍入模式 (例如保留2位小数,四舍五入)
price = Decimal('19.995')
final_price = price.quantize(Decimal('0.01'), rounding=ROUND_HALF_UP)
print(final_price) # 20.001.1.4 复数
复数一般可能用的少,就是书上说的复数,是一种内置的核心数据类型,无需导入任何模块即可直接使用,它完全遵循数学中的复数定义 a+bi 。复数运算和书本上一样
z1 = 3 + 4j # 实部 3, 虚部 4
z2 = 5j # 实部 0, 虚部 5 (纯虚数)
z3 = 10 # 实部 10, 虚部 0 (自动视为复数 10+0j)
z4 = complex(2, -3) # 使用构造函数:实部 2, 虚部 -3a = 2 + 3j
b = 1 - 2j
print(a + b) # (3+1j)
print(a - b) # (1+5j)
print(a * b) # (8-1j) -> (2*1 - 3*(-2)) + (2*(-2) + 3*1)j = 8 - 1j
print(a / b) # (-0.8+1.4j)1.2 字符串
python 字符串是不可变类型。
1.2.1 字符串定义
字符串能使用单引号、双引号、三引号。如果字符串内容有双引号,外层就可以使用单引号,减少转义。三引号可以写行数据
# ✅ 推荐:清晰易读
s1 = 'He said, "Hello World!"'
# ❌ 不推荐:需要转义
s2 = "He said, \"Hello World!\""
# 使用三引号定义多行文本
poem = """床前明月光,
疑是地上霜。
举头望明月,
低头思故乡。"""
print(poem)
# 输出会严格保持换行格式:
# 床前明月光,
# 疑是地上霜。
# ...
# 对比:如果用普通引号,必须手动加 \n
poem_bad = "床前明月光,\n疑是地上霜。\n..." 1.2.2 大小写转换
| 方法 | 说明 | 示例 |
|---|---|---|
capitalize() |
首字母大写,其余小写 | 'hello'.capitalize() → 'Hello' |
casefold() |
强力转为小写(用于不区分大小写的比较,比 lower() 更彻底) |
'Straße'.casefold() → 'strasse' |
lower() |
转为小写 | 'HELLO'.lower() → 'hello' |
upper() |
转为大写 | 'hello'.upper() → 'HELLO' |
swapcase() |
大小写互换 | 'Hello'.swapcase() → 'hELLO' |
title() |
每个单词首字母大写 | 'hello world'.title() → 'Hello World' |
1.2.3 查找与统计
这里要注意的是index方法查找不到会抛出异常
| 方法 | 说明 | 返回值 |
|---|---|---|
count(sub[, start, end]) |
统计子串出现次数 | int |
find(sub[, start, end]) |
查找子串首次位置,找不到返回 -1 | int |
index(sub[, start, end]) |
查找子串首次位置,找不到抛 ValueError | int |
rfind(sub[, start, end]) |
反向查找(从右向左),找不到返回 -1 | int |
rindex(sub[, start, end]) |
反向查找,找不到抛 ValueError | int |
startswith(prefix[, start, end]) |
检查是否以指定前缀开头 | bool |
endswith(suffix[, start, end]) |
检查是否以指定后缀结尾 | bool |
1.2.4 清理与填充
| 方法 | 说明 | 示例 |
|---|---|---|
strip([chars]) |
去除两端空白符(或指定字符) | ' hi '.strip() → 'hi' |
lstrip([chars]) |
去除左侧空白符 | ' hi'.lstrip() → 'hi ' |
rstrip([chars]) |
去除右侧空白符 | 'hi '.rstrip() → ' hi' |
center(width[, fillchar]) |
居中对齐,用指定字符填充 | 'hi'.center(5, '*') → '*hi*' |
ljust(width[, fillchar]) |
左对齐,右侧填充 | 'hi'.ljust(5, '*') → 'hi***' |
rjust(width[, fillchar]) |
右对齐,左侧填充 | 'hi'.rjust(5, '*') → '***hi' |
expandtabs(tabsize) |
将制表符 \t 替换为空格 |
'a\tb'.expandtabs(4) |
zfill(width) |
左侧用 0 填充到指定宽度(常用于数字) |
'42'.zfill(5) → '00042' |
1.2.3 判断类型
| 方法 | 说明 |
|---|---|
isalnum() |
是否只包含字母和数字 |
isalpha() |
是否只包含字母 |
isdigit() |
是否只包含数字(包括上标数字如 ²) |
isdecimal() |
是否只包含十进制数字(最严格,不包括 ²) |
isnumeric() |
是否只包含数字字符(包括中文数字如 "四") |
isspace() |
是否只包含空白字符(空格、\n, \t 等) |
islower() |
是否所有有大小写的字符都是小写 |
isupper() |
是否所有有大小写的字符都是大写 |
istitle() |
是否符合标题格式(每个单词首字母大写) |
isprintable() |
是否所有字符都可打印(不含 \n, \t 等控制符) |
isidentifier() |
是否是合法的 Python 标识符(变量名) |
1.2.4 替换与分割
| 方法 | 说明 | 示例 |
|---|---|---|
replace(old, new[, count]) |
替换子串(可选替换次数) | 'aaa'.replace('a', 'b', 1) → 'baa' |
split([sep[, maxsplit]]) |
分割字符串为列表(默认按空白符) | 'a b c'.split() → ['a','b','c'] |
rsplit([sep[, maxsplit]]) |
从右向左分割 | 'a b c'.rsplit(' ', 1) → ['a b', 'c'] |
splitlines([keepends]) |
按行分割(保留或不保留换行符) | 'a\nb'.splitlines() → ['a', 'b'] |
partition(sep) |
分成三部分:(头, 分隔符, 尾) | 'a:b:c'.partition(':') → ('a', ':', 'b:c') |
rpartition(sep) |
从右向左分成三部分 | 'a:b:c'.rpartition(':') → ('a:b', ':', 'c') |
join(iterable) |
重要:用该字符串连接列表中的元素 | '-'.join(['a','b']) → 'a-b' |
1.2.5 编码与格式化
| 方法 | 说明 |
|---|---|
encode(encoding='utf-8', errors='strict') |
将字符串编码为 bytes 对象 |
format(*args, kwargs) |
格式化字符串(配合 {} 使用) |
format_map(mapping) |
类似 format,但使用字典映射 |
maketrans(x[, y[, z]]) |
创建转换表(配合 translate 使用) |
translate(table) |
根据转换表替换/删除字符 |
| 特性 | Python 2 | Python 3 |
|---|---|---|
'hello' |
类型是 str (本质是 bytes/字节串) |
类型是 str (本质是 Unicode/字符串) |
u'hello' |
类型是 unicode (真正的 Unicode/字符串) |
类型是 str (本质是 Unicode/字符串) |
| 区别 | 完全不同。一个是字节,一个是字符。混合使用容易报错。 | 完全相同。u 前缀被忽略。 |
python不在需要u开头了

1.2.6 转义字符串
| 转义字符 | 描述 (Description) | 示例代码 | 输出效果 (Visual) |
|---|---|---|---|
\\ |
反斜杠 (Backslash) | print("C:\\Users\\Name") |
C:\Users\Name |
\' |
单引号 (Single Quote) | print('It\'s me') |
It's me |
\" |
双引号 (Double Quote) | print("He said \"Hi\"") |
He said "Hi" |
\n |
换行 (Newline) | print("Line1\nLine2") |
Line1 Line2 |
\r |
回车 (Carriage Return) | print("Hi\rBye") |
Bye (覆盖前面的 Hi) |
\t |
水平制表符 (Tab) | print("A\tB") |
A B |
\b |
退格 (Backspace) | print("ABC\bD") |
ABD (C 被删除) |
\f |
换页 (Formfeed) | print("Page1\fPage2") |
(打印机换页,终端通常显示为空格或换行) |
\v |
垂直制表符 (Vertical Tab) | print("A\vB") |
(终端通常显示为带间距的换行) |
\a |
响铃 (Bell/Alert) | print("\a") |
(播放系统提示音/哔声) |
\ooo |
八进制 ASCII (Octal) | print("\101") |
A (101 是 A 的八进制) |
\xhh |
十六进制 ASCII (Hex) | print("\x41") |
A (41 是 A 的十六进制) |
\N{name} |
Unicode 字符名 | print("\N{SNOWMAN}") |
☃ |
\uhhhh |
16位 Unicode | print("\u4e2d") |
中 |
\Uhhhhhhhh |
32位 Unicode | print("\U0001F600") |
😀 |
1.2.7 原始字符串
在字符串引号前加上字母 r 或 R(大小写均可,推荐小写 r),这是原始字符串最重要的作用。在普通字符串中,\ 是转义符;在原始字符串中,\ 只是一个普通的反斜杠字符。
# ❌ 错误示范:普通字符串中的 \n 和 \t 被转义了
path_wrong = "C:\new_folder\test.txt"
print("普通字符串:", path_wrong)
# 输出可能类似: C:
# ew_folder est.txt (因为 \n 变换行,\t 变制表符)
# ✅ 正确示范:原始字符串保留了所有反斜杠
path_right = r"C:\new_folder\test.txt"
print("原始字符串:", path_right)
# 输出: C:\new_folder\test.txt1.3 元组
使用()包起来或者逗号给开的数据定义是元组
1.3.1 元组定义
1 使用小括号将元素包裹起来,元素之间用逗号 , 分隔。
特点: 语法清晰,可读性最强。
注意: 括号其实是可选的(见方式 2),但为了代码清晰,强烈建议始终加上
# 空元组
empty = ()
# 普通元组
colors = ("red", "green", "blue")
numbers = (1, 2, 3, 4, 5)
# 混合类型
mixed = (1, "hello", 3.14, True)
print(type(colors)) # <class 'tuple'>2. 省略括号法 (隐式元组)
在 Python 中,真正定义元组的是逗号 ,,而不是括号 ()。
如果你写出一串用逗号分隔的值,Python 会自动将其识别为元组。
用途: 常用于函数返回多个值、多重赋值。
# 没有括号,依然是元组!
point = 10, 20
print(point) # (10, 20)
print(type(point))# <class 'tuple'>
# 函数返回多个值时,本质是返回了一个元组
def get_coords():
return 100, 200 # 等同于 return (100, 200)
x, y = get_coords() # 解包3. 单元素元组 (⚠️ 易错点)
如果要定义只有一个元素的元组,必须在元素后面加一个逗号 ,。
错误写法: t = (1) -> 这只是一个整数 int,括号被当作数学运算优先级处理了。
正确写法: t = (1,) -> 逗号告诉 Python 这是一个元组。
# ❌ 错误:这只是个整数
wrong = (1)
print(type(wrong)) # <class 'int'>
# ✅ 正确:加上逗号
correct = (1,)
print(type(correct)) # <class 'tuple'>
print(correct) # (1,)
# 即使不加括号,单元素也必须有逗号
also_correct = 1,
print(type(also_correct)) # <class 'tuple'>
def get_coordsa():
return (100) # 等同于 return (100, 200)
def get_coordsb():
return (200,) # 等同于 return (100, 200)
def get_coordsc():
return 200, # 等同于 return (100, 200)
a=get_coordsa()
b=get_coordsb()
c=get_coordsc()
print(f'aType={type(a)},bType={type(b)},cType={type(c)}') #aType=<class 'int'>,bType=<class 'tuple'>,cType=<class 'tuple'>4.tuple() 构造函数 (类型转换)
将其他可迭代对象(如列表、字符串、范围)转换为元组
# 从列表转换
lst = [1, 2, 3]
t_from_list = tuple(lst)
print(t_from_list) # (1, 2, 3)
# 从字符串转换 (每个字符变成元组的一个元素)
s = "abc"
t_from_str = tuple(s)
print(t_from_str) # ('a', 'b', 'c')
# 从 range 转换
t_from_range = tuple(range(3))
print(t_from_range) # (0, 1, 2)
# 空元组
empty = tuple()
print(empty) # ()1.3.1 访问方式
主要通过索引位置和切片访问
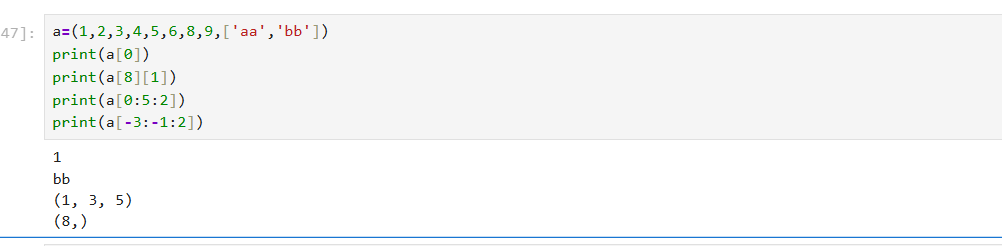
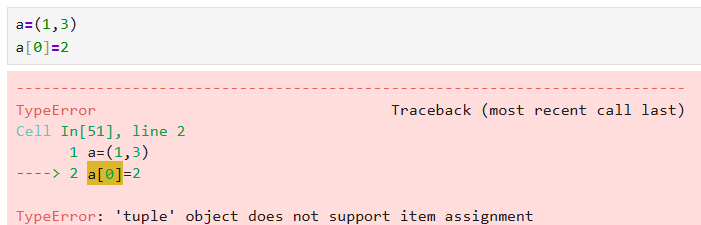
1.3.2 不可变性
元组表面上是不可变类型,实际上是有可能改变的。
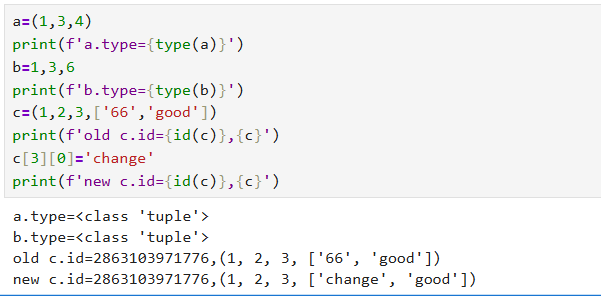
元组可以多层嵌套,还可以类型不同。
1.3.3 深拷贝与浅拷贝
| 操作方式 | 代码示例 | 内存关系 | 修改子对象的影响 | 适用场景 |
|---|---|---|---|---|
| 直接赋值 | b = a |
完全同一个对象 | 影响 (因为是同一个) | 不需要副本,只是起别名 |
| 浅拷贝 | b = a.copy()b = copy.copy(a) |
外层新,内层共享 | 影响 (内层引用相同) | 对象只有一层,或确定内层不会被修改 |
| 深拷贝 | b = copy.deepcopy(a) |
完全独立,递归复制 | 不影响 (彻底隔离) | 嵌套可变对象,需要完全独立的副本 |
1.3.4 元组方法
因为元组是不可变对象,所以很多修改自身的方法不存在
| 方法名 | 语法 | 功能描述 | 返回值类型 | 是否修改原元组 |
|---|---|---|---|---|
count() |
t.count(value) |
统计指定元素在元组中出现的次数 | int (整数) |
❌ 否 |
index() |
t.index(value[, start[, end]]) |
查找指定元素第一次出现的索引位置 | int (整数) |
❌ 否 |
1.4 列表
列表是使用[]来定义和初始化的。
1.4.1 列表定义
| 定义方式 | 语法示例 | 核心用途 | 注意事项 |
|---|---|---|---|
| 方括号 | [1, 2, 3] |
通用定义 | 最直观,支持任意类型 |
| 构造函数 | list("abc") |
类型转换 | 参数必须是可迭代对象 |
| 推导式 | [x*2 for x in data] |
高效生成/过滤 | 代码简洁,性能优于循环 |
| 乘法 | [0] * 10 |
快速初始化 | 慎用于可变对象(引用陷阱) |
| 解包 | [*list1, *list2] |
灵活合并 | Python 3.5+ 特性 |
💡 最佳实践建议
1 手动写数据: 用方括号 [...]。
2 由旧数据生成新数据: 优先用列表推导式(既快又优雅)。
3 初始化固定长度:
6 存数字/字符串等不可变值:用 [0] * n。
7 存列表/字典等可变值:必须用 [..., ...] 推导式,避免引用坑。
8 合并列表: 小列表用 + 或 [*a, *b],大列表频繁合并建议用 extend() 方法(原地修改,省内存)。
1. 方括号法 [ ] (最常用)
使用方括号将元素包裹起来,元素之间用逗号 , 分隔。
特点: 直观、简洁,支持混合数据类型。
适用: 绝大多数场景。
# 空列表
empty_list = []
# 整数列表
numbers = [1, 2, 3, 4, 5]
# 混合类型列表 (Python 特色)
mixed = [1, "hello", 3.14, True, None]
# 嵌套列表 (二维数组/矩阵)
matrix = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
print(type(numbers)) # <class 'list'>2. list() 构造函数 (类型转换)
将其他可迭代对象(如字符串、元组、集合、range)转换为列表。
特点: 用于数据清洗或类型转换
# 从字符串转换 (每个字符成为一个元素)
s = "python"
lst_from_str = list(s)
print(lst_from_str) # ['p', 'y', 't', 'h', 'o', 'n']
# 从元组转换
t = (10, 20, 30)
lst_from_tuple = list(t)
print(lst_from_tuple) # [10, 20, 30]
# 从 range 转换 (生成数字序列)
lst_from_range = list(range(5))
print(lst_from_range) # [0, 1, 2, 3, 4]
# 从集合转换 (注意:集合无序,结果顺序可能不固定)
st = {1, 2, 3}
lst_from_set = list(st) 3. 列表推导式 (List Comprehension)
Python 最强大的特性之一。用于基于现有序列生成新列表,语法紧凑且执行效率高。
语法: [表达式 for 变量 in 可迭代对象 if 条
# 场景 A: 简单生成 (0-9 的平方)
squares = [x**2 for x in range(10)]
print(squares) # [0, 1, 4, 9, ..., 81]
# 场景 B: 带条件过滤 (只保留偶数的平方)
even_squares = [x**2 for x in range(10) if x % 2 == 0]
print(even_squares) # [0, 4, 16, 36, 64]
# 场景 C: 嵌套循环 (展平二维列表)
matrix = [[1, 2], [3, 4], [5, 6]]
flat = [num for row in matrix for num in row]
print(flat) # [1, 2, 3, 4, 5, 6]
# 场景 D: 类型转换 + 处理
str_nums = ["1", "2", "3"]
int_nums = [int(x) * 10 for x in str_nums]
print(int_nums) # [10, 20, 30]4. 乘法操作符 * (快速初始化)
用于快速创建一个包含重复元素的列表。
适用: 初始化固定大小的占位列表。
⚠️ 高危陷阱: 如果元素是可变对象(如列表),所有位置会指向同一个对象(引用共享)
# 场景 A: 不可变对象 (安全)
zeros = [0] * 5
print(zeros) # [0, 0, 0, 0, 0]
names = ["None"] * 3
print(names) # ['None', 'None', 'None']
# 场景 B: ⚠️ 可变对象 (危险!)
# 错误写法:创建 3 个指向同一个列表的引用
bad_matrix = [[]] * 3
bad_matrix[0].append(1)
print(bad_matrix)
# ❌ 输出: [[1], [1], [1]] (所有子列表都变了!)
# ✅ 正确写法:使用列表推导式创建独立对象
good_matrix = [[] for _ in range(3)]
good_matrix[0].append(1)
print(good_matrix)
# ✅ 输出: [[1], [], []] (只有第一个变了)5. * 解包操作符 (Python 3.5+)
在列表字面量中使用 * 将另一个可迭代对象“展开”并入当前列表。
适用: 合并多个列表、在列表中间插入元素。
list1 = [1, 2]
list2 = [3, 4]
# 合并列表 (比 list1 + list2 更灵活,可插入中间)
combined = [0, *list1, 99, *list2, 100]
print(combined)
# [0, 1, 2, 99, 3, 4, 100]
# 将 range 展开
nums = [*range(3), 100, *range(3, 5)]
print(nums) # [0, 1, 2, 100, 3, 4]1.4.2 可变性
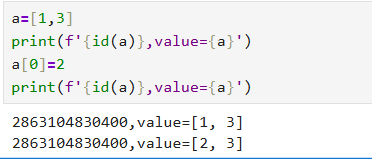
1.4.3 列表与元组转换
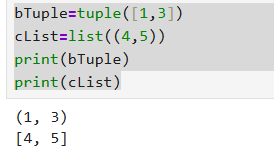
这里要注意深拷贝问题
1.4.4 列表方法
| 类别 | 方法名 | 语法示例 | 功能描述 | 返回值 | 是否修改原列表 |
|---|---|---|---|---|---|
| 增 | append() |
lst.append(x) |
在末尾添加一个元素 | None |
✅ 是 |
extend() |
lst.extend(iterable) |
在末尾追加另一个可迭代对象的所有元素 | None |
✅ 是 | |
insert() |
lst.insert(i, x) |
在指定索引 i 处插入元素 |
None |
✅ 是 | |
| 删 | remove() |
lst.remove(x) |
删除第一个匹配的值 x |
None |
✅ 是 |
pop() |
lst.pop([i]) |
删除并返回指定索引的元素(默认最后一个) | 元素值 | ✅ 是 | |
clear() |
lst.clear() |
清空列表所有元素 | None |
✅ 是 | |
| 查 | index() |
lst.index(x) |
返回第一个匹配值 x 的索引 |
int |
❌ 否 |
count() |
lst.count(x) |
统计值 x 出现的次数 |
int |
❌ 否 | |
| 改/序 | sort() |
lst.sort() |
原地排序(升序) | None |
✅ 是 |
reverse() |
lst.reverse() |
原地反转列表 | None |
✅ 是 | |
| 复制 | copy() |
lst.copy() |
返回列表的浅拷贝 | 新列表 |
❌ 否 |
重要提示:除了 copy(), index(), count(), pop() (返回值) 外,绝大多数列表方法(如 append, sort, remove)都返回 None。千万不要写成 new_lst = lst.sort(),这会导致 new_lst 变为 None
可以用列表本身的方法实现队列功能
1.4.5 itertools 模块
除了range,这里给出一个更强大的模块工具
| 函数 | 描述 | 对应 range 的场景 |
示例代码 |
|---|---|---|---|
count(start, step) |
无限计数器 | 无限版 range (range 必须有终点) | list(itertools.islice(itertools.count(0, 0.5), 5)) → [0, 0.5, 1.0, 1.5, 2.0] (支持浮点步长) |
repeat(obj, times) |
重复某个值 | 生成常数列表 | list(itertools.repeat('A', 3)) → ['A', 'A', 'A'] |
cycle(iterable) |
无限循环遍历 | 循环序列 | list(itertools.islice(itertools.cycle([1, 2]), 5)) → [1, 2, 1, 2, 1] |
chain(*iterables) |
连接多个序列 | 拼接多个 range | list(itertools.chain(range(2), range(5, 7))) → [0, 1, 5, 6] |
islice(iterable, stop) |
切片迭代器 | 截取无限序列 (配合 count 使用) | 见 count 示例 |
product() |
笛卡尔积 | 多重嵌套 range | list(itertools.product(range(2), range(2))) → [(0,0), (0,1), (1,0), (1,1)] |
permutations() |
排列 | 生成所有排列顺序 | list(itertools.permutations([1, 2, 3], 2)) |
combinations() |
组合 | 生成所有不重复组合 | list(itertools.combinations([1, 2, 3], 2)) |
1.4.6 array
非内置,array可以支持同类型限制,因为相关方法较少,可能不太好用,可以使用numpy包的数组,更强大
import array
# 创建一个只存整数的数组 ('i' 表示 signed int)
arr = array.array('i', [1, 2, 3, 4])
# arr * 2 会报错,不支持向量化乘法
# arr + arr 可以拼接,但不能数学运算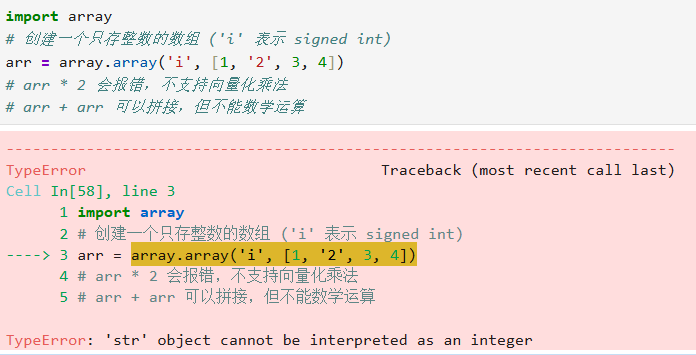
1.4.7 numpy
numpy主要用于数据分析,支持多维数组和更强大的功能,也更复杂。感兴趣的可以自行学习实践。不适合做基础学习
1.5 序列
字符串、元组、列表都可以归为序列一类,所以有一些共有的方法
1.5.1 内置函数
这些函数接受一个序列作为参数,返回计算结果或新对象。它们不会修改原序列(因为字符串和元组本身不可变,列表虽可变但这些函数设计为非原地操作,如果不确定,可以验证一下)
| 函数名 | 语法 | 功能描述 | 返回值类型 | 适用示例 |
|---|---|---|---|---|
len() |
len(s) |
返回序列的长度(元素个数) | int |
len([1,2]) → 2 |
max() |
max(s) |
返回序列中的最大元素 | 元素类型 | max("abc") → 'c' |
min() |
min(s) |
返回序列中的最小元素 | 元素类型 | min((3,1,2)) → 1 |
sum() |
sum(s) |
返回序列中所有元素的和 | 数字类型 | sum([1,2,3]) → 6 |
sorted() |
sorted(s) |
返回排序后的新列表 | list |
sorted("cba") → ['a','b','c'] |
reversed() |
reversed(s) |
返回反转后的迭代器 | iterator |
list(reversed([1,2])) → [2,1] |
enumerate() |
enumerate(s) |
返回带索引的迭代器 (index, value) |
iterator |
list(enumerate("ab")) → [(0,'a'), (1,'b')] |
zip() |
zip(s1, s2) |
将多个序列打包成元组序列 | iterator |
list(zip([1,2], ['a','b'])) → [(1,'a'), (2,'b')] |
list() |
list(s) |
将任意序列转换为列表 | list |
list("abc") → ['a','b','c'] |
tuple() |
tuple(s) |
将任意序列转换为元组 | tuple |
tuple([1,2]) → (1,2) |
str() |
str(s) |
将序列转换为字符串表示 | str |
str([1,2]) → "[1, 2]" |
all() |
all(s) |
所有元素为真则返回 True |
bool |
all([1, True]) → True |
any() |
any(s) |
只要有一个元素为真则返回 True |
bool |
any([0, False, 1]) → True |
count()* |
s.count(x) |
注意:这是方法不是函数,但所有序列都有 | int |
"aba".count('a') → 2 |
index()* |
s.index(x) |
注意:这是方法不是函数,但所有序列都有 | int |
(1,2).index(2) → 1 |
这里比较有意思的是zip函数
1.5.2 通用操作
| 操作符 | 语法 | 功能描述 | 示例 |
|---|---|---|---|
| 索引 | s[i] |
获取第 i 个元素(从 0 开始) |
[10, 20][0] → 10 |
| 负索引 | s[-i] |
获取倒数第 i 个元素 |
"abc"[-1] → 'c' |
| 切片 | s[start:end:step] |
截取子序列 | [1,2,3,4][1:3] → [2, 3] |
| 拼接 | s1 + s2 |
连接两个同类型序列 | [1] + [2] → [1, 2] |
| 重复 | s * n |
将序列重复 n 次 |
"A" * 3 → 'AAA' |
| 成员检查 | x in s |
判断 x 是否在序列中 |
3 in [1, 2, 3] → True |
| 成员检查 | x not in s |
判断 x 是否不在序列中 |
5 not in (1, 2) → True |
| 比较 | s1 == s2 |
判断两个序列内容是否相等 | [1, 2] == (1, 2) → False (类型不同) |
| 比较 | s1 < s2 |
字典序比较(逐个元素比较) | "ab" < "ac" → True |
注意s1 == s2比较的是内容,不是引用
1.5.3 collections
这个包可以参考一下,简单来说:当内置的 list, dict, set, tuple 无法满足特定需求(如:需要有序字典、需要计数、需要双端队列)时,collections 就是你的最佳选择。
| 需求 | 推荐工具 | 核心优势 |
|---|---|---|
| 统计频率 | Counter |
语法简洁,支持数学运算 |
| 避免 KeyErrors / 分组 | defaultdict |
自动初始化默认值,代码更干净 |
| 队列 / 栈 / 滑动窗口 | deque |
两端操作 O(1) 极速,支持 maxlen |
| 轻量级数据结构 / 记录 | namedtuple |
像对象一样访问,内存占用极低,不可变 |
| 严格顺序控制 / LRU | OrderedDict |
显式的顺序控制方法 (move_to_end) |
| 多层级配置合并 | ChainMap |
逻辑合并多个字典,无需复制数据 |
| 普通键值对 | dict |
通用,Python 3.7+ 已保序 |
| 普通列表 | list |
通用 |
这里举一些例子:
1.5.3.1 Counter (计数器)
用途:快速统计可哈希对象出现的次数。它是 dict 的子类。
场景:词频统计、找出出现最多的元素、数据分布分析。
from collections import Counter
data = ['apple', 'banana', 'apple', 'orange', 'banana', 'apple']
# ✅ 初始化并统计
c = Counter(data)
print(c)
# 输出: Counter({'apple': 3, 'banana': 2, 'orange': 1})
# ✅ 获取最常见的 N 个元素
print(c.most_common(2))
# 输出: [('apple', 3), ('banana', 2)]
# ✅ 数学运算 (支持加减并集交集)
c2 = Counter(['apple', 'kiwi'])
print(c + c2)
# 输出: Counter({'apple': 4, 'banana': 2, 'orange': 1, 'kiwi': 1})
# ✅ 访问不存在的键不会报错,返回 0
print(c['grape']) # 输出: 01.5.3.2 defaultdict (默认字典)
用途:为字典的键提供默认值。当访问不存在的键时,自动创建默认值,而不是抛出 KeyError。
场景:分组数据、构建邻接表、避免大量的 if-else 检查
from collections import defaultdict
# ❌ 原生 dict 做法
d = {}
# d['a'].append(1) # 报错 KeyError
# ✅ defaultdict 做法
# 参数是一个工厂函数:int(), list(), set(), lambda: "default"
dd_list = defaultdict(list)
dd_list['fruits'].append('apple')
dd_list['fruits'].append('banana')
dd_list['nums'].append(1) # 自动初始化为空列表 []
print(dd_list)
# 输出: defaultdict(<class 'list'>, {'fruits': ['apple', 'banana'], 'nums': [1]})
# ✅ 统计计数 (默认值为 int,即 0)
dd_count = defaultdict(int)
for char in "hello":
dd_count[char] += 1 # 不需要判断 key 是否存在
print(dd_count)
# 输出: defaultdict(<class 'int'>, {'h': 1, 'e': 1, 'l': 2, 'o': 1})1.5.3.3 deque (双端队列)
用途:线程安全的、支持两端高效添加/删除元素的队列。
场景:实现队列 (FIFO)、栈 (LIFO)、滑动窗口、最近浏览记录。
优势:在列表头部插入/删除 (pop(0), insert(0)) 是 O(n) 复杂度,而 deque 是 O(1)。
from collections import deque
q = deque(['a', 'b', 'c'])
# ✅ 右侧操作 (类似 list)
q.append('d') # 右边加
q.pop() # 右边删
# ✅ 左侧操作 (list 做这个很慢!)
q.appendleft('z') # 左边加
q.popleft() # 左边删
print(q) # deque(['b', 'c', 'd'])
# ✅ 限制最大长度 (自动丢弃旧元素)
# 适合做“最近 N 条记录”
history = deque(maxlen=3)
for i in range(5):
history.append(i)
print(history)
# 输出: deque([2, 3, 4], maxlen=3) (0和1被自动丢弃)1.5.3.4 namedtuple (命名元组)
from collections import namedtuple
# ✅ 定义一个名为 Point 的类,有 x 和 y 两个字段
Point = namedtuple('Point', ['x', 'y'])
p = Point(10, 20)
# ✅ 通过属性访问 (比元组索引 p[0] 可读性强太多)
print(p.x, p.y) # 输出: 10 20
# ✅ 依然拥有元组的特性
print(len(p)) # 输出: 2
# p.x = 5 # 报错:AttributeError (不可变)
# ✅ 转换为字典
print(p._asdict()) # 输出: OrderedDict([('x', 10), ('y', 20)])
# ✅ 解包
x, y = pPython 3.7+ 替代方案:对于可变对象,现在更推荐使用 dataclasses 模块 (@dataclass),但 namedtuple 在需要不可变且轻量的场景下依然无敌
1.5.3.5 OrderedDict (有序字典)
用途:记住键值对插入顺序的字典。
现状:⚠️ 注意,从 Python 3.7 开始,标准的 dict 已经默认保持插入顺序。
场景:
- 需要兼容 Python 3.6 及以下版本。
- 需要使用
move_to_end()方法(例如实现 LRU 缓存逻辑)。 - 需要比较两个字典是否完全相等(包括顺序),标准 dict 比较只看内容,
OrderedDict比较看顺序。
from collections import OrderedDict
od = OrderedDict()
od['first'] = 1
od['second'] = 2
od['third'] = 3
# ✅ 移动某个键到末尾 (常用于实现 LRU 缓存)
od.move_to_end('first')
print(list(od.keys()))
# 输出: ['second', 'third', 'first']
# ✅ 弹出第一个元素 (标准 dict 在 3.7+ 也可以 popitem(last=False),但 OrderedDict 语义更明确)
od.popitem(last=False)
print(list(od.keys()))
# 输出: ['third', 'first']1.5.3.6 ChainMap (映射链)
用途:将多个字典/映射组合成一个逻辑单元。查找时会按顺序在各个字典中搜索。
场景:管理多层级配置(命令行参数 > 环境变量 > 默认配置)、合并命名空间。
from collections import ChainMap
defaults = {'color': 'red', 'user': 'guest'}
env_vars = {'user': 'admin'}
cmd_args = {'color': 'blue'}
# ✅ 优先级:cmd_args > env_vars > defaults
config = ChainMap(cmd_args, env_vars, defaults)
print(config['color']) # 输出: 'blue' (来自 cmd_args)
print(config['user']) # 输出: 'admin' (来自 env_vars)
print(config['port']) # 如果都没有,报 KeyError
# ✅ 动态更新
# 修改 ChainMap 会直接修改底层的第一个字典
config['color'] = 'green'
print(cmd_args) # 输出: {'color': 'green'} (原字典被改了!)1.6 字典
字典主要是用{}定义的键值对数据结构。访问主要通过key
| 方式 | 语法示例 | 最佳适用场景 |
|---|---|---|
| 字面量 | {"a": 1} |
静态数据,键值明确 |
| 关键字参数 | dict(a=1) |
键是合法变量名,追求简洁 |
| Zip/列表 | dict(zip(k, v)) |
两个列表配对,或从元组列表构建 |
| 推导式 | {k:v for ...} |
数据转换、过滤、动态生成 |
| Fromkeys | dict.fromkeys(k, val) |
批量初始化相同默认值 (注意可变对象陷阱) |
| 合并 (` | `) | d1 | d2 |
1.6.1 定义方法
1. 字面量直接定义 (Literal Syntax)
最常用、最直观的方式。适用于键值对已知且固定的场景
# 基本用法
user = {
"name": "Alice",
"age": 25,
"is_active": True
}
# 键可以是任何不可变类型 (字符串、数字、元组)
data = {
"id": 101,
3.14: "Pi Value",
("x", "y"): "Coordinate Key"
}
print(user["name"]) # 输出: Alice
print(data) # 输出: {'id': 101, 3.14: 'Pi Value', ('x', 'y'): 'Coordinate Key'}2. dict() 构造函数 + 关键字参数
适用于键是合法变量名(字符串且无空格、特殊字符)的场景。代码非常简洁。
# 键自动转为字符串
config = dict(host="localhost", port=8080, debug=True)
print(config)
# 输出: {'host': 'localhost', 'port': 8080, 'debug': True}
# 注意:键必须是合法的标识符,不能是 "my-port" 或 "1st"3. dict() + 可迭代对象 (列表/元组)
适用于从外部数据(如数据库查询结果、CSV 行)批量构建字典。数据源通常是包含 (key, value) 元组的列表。
# 来源:列表中包含元组
items = [("apple", 1.5), ("banana", 0.8), ("orange", 2.0)]
prices = dict(items)
print(prices)
# 输出: {'apple': 1.5, 'banana': 0.8, 'orange': 2.0}
# 来源:zip() 函数动态生成 (非常常用!)
keys = ["name", "role", "level"]
values = ["Bob", "Admin", 5]
user_info = dict(zip(keys, values))
print(user_info)
# 输出: {'name': 'Bob', 'role': 'Admin', 'level': 5}4. 字典推导式 (Dictionary Comprehension)
类似于列表解析,用于根据现有数据动态生成或转换字典。功能最强大
# 场景 A: 生成平方数字典 {1:1, 2:4, ...}
squares = {x: x**2 for x in range(1, 6)}
print(squares)
# 输出: {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}
# 场景 B: 过滤数据 (只保留值大于 2 的项)
filtered = {k: v for k, v in squares.items() if v > 10}
print(filtered)
# 输出: {4: 16, 5: 25}
# 场景 C: 交换键和值
original = {"a": 1, "b": 2}
swapped = {v: k for k, v in original.items()}
print(swapped)
# 输出: {1: 'a', 2: 'b'}5. dict.fromkeys() (初始化默认值)
当你需要创建一个新字典,所有键都有相同的初始值(常用于计数器初始化或占位符)时使用。
keys = ["red", "green", "blue"]
# 所有键的默认值为 0
color_counts = dict.fromkeys(keys, 0)
print(color_counts)
# 输出: {'red': 0, 'green': 0, 'blue': 0}
# 所有键的默认值为空列表 (⚠️ 陷阱警告:见下方注意事项)
# 如果默认值是可变对象,所有键会共享同一个对象引用!
shared_list = dict.fromkeys(keys, [])
shared_list["red"].append(1)
print(shared_list)
# 输出: {'red': [1], 'green': [1], 'blue': [1]} (通常这不是你想要的!)6. 合并操作符 | (Python 3.9+ 新特性)
如果你使用的是 Python 3.9 或更高版本,可以使用 | 运算符轻松合并字典。旧版本需使用 {**d1, **d2} 或 update()
# 假设运行环境 >= Python 3.9
defaults = {"theme": "dark", "lang": "en"}
user_prefs = {"lang": "zh", "font_size": 14}
# 合并:后者覆盖前者
config = defaults | user_prefs
print(config)
# 输出: {'theme': 'dark', 'lang': 'zh', 'font_size': 14}
# 原地更新
defaults |= user_prefs 1.6.2 访问方法
1 字典访问主要通过key
# 键自动转为字符串
config = dict(host="localhost", port=8080, debug=True)
print(config['host']) #输出localhost
#print(config[host]) 不加引号要报错
#print(config.host) 也不能这样用2 遍历keys
# 方式 A: 省略 .keys() (最常用,Pythonic)
print("学生名单:")
for name in user_scores:
print(f"- {name}")
# 方式 B: 显式调用 .keys() (代码可读性稍好,但功能相同)
for name in user_scores.keys():
pass 3 编列values
user_scores = {
"Alice": 95,
"Bob": 82,
"Charlie": 88,
"David": 95
}
print("所有分数:")
total = 0
count = 0
for score in user_scores.values():
print(f"分数: {score}")
total += score
count += 1
print(f"平均分: {total / count:.2f}")
#输出
tip = """
所有分数:
分数: 95
分数: 82
分数: 88
分数: 95
平均分: 90.00
"""4 遍历key,value
user_scores = {
"Alice": 95,
"Bob": 82,
"Charlie": 88,
"David": 95
}
print("成绩单:")
for name, score in user_scores.items():
print(f"{name}: {score}分")
#输出
tip = """
成绩单:
Alice: 95分
Bob: 82分
Charlie: 88分
David: 95分
"""5 使用get访问
user = {"name": "Alice", "age": 25}
# 场景 A: 键存在 -> 返回值
name = user.get("name")
print(name) # 输出: Alice
# 场景 B: 键不存在 -> 返回 None (默认)
email = user.get("email")
print(email) # 输出: None (程序继续运行,不报错)
# 场景 C: 键不存在 -> 返回自定义默认值 (常用!)
role = user.get("role", "guest")
print(role) # 输出: guest1.6.3 无key异常
字典在无key时访问会抛出异常,这点需要特别注意
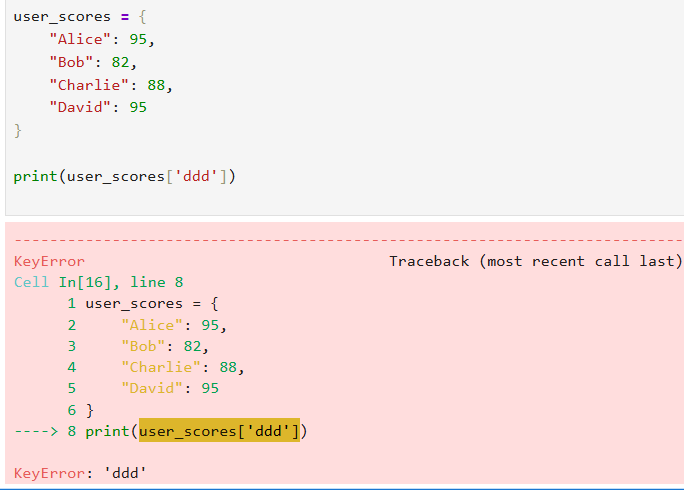
有以下几个处理办法:
使用get访问(上面已经介绍过)
使用in or not in提前判断
user = {"name": "Alice"}
if "email" in user:
print(f"邮箱是: {user['email']}")
else:
print("邮箱未设置,使用默认值")
# 在这里可以执行备用逻辑
if "email" not in user:
user["email"] = "default@example.com"使用try...except异常捕获
user = {"name": "Alice"}
try:
email = user["email"]
print(f"邮箱: {email}")
except KeyError:
print("键 'email' 不存在,使用默认逻辑")
email = "no-reply@example.com"1.6.4 字典修改
“修改字段”通常指三种操作:更新已有值、添加新键值对、批量合并/更新。由于字典是可变对象,这些操作都会直接改变原字典。
| 方法 | 代码示例 | 是否修改原字典 | 适用场景 |
|---|---|---|---|
.get() |
d.get("k", default) |
❌ 否 | 通用首选,获取值并提供默认值 |
in 检查 |
if "k" in d: |
❌ 否 | 需要根据键是否存在执行不同逻辑块 |
try-except |
try: d["k"] ... |
❌ 否 | 键大概率存在,或逻辑复杂时 |
defaultdict |
dd = defaultdict(type) |
✅ 是 (自动) | 计数器、分组聚合,需频繁处理缺失键 |
setdefault() |
d.setdefault("k", v) |
✅ 是 | 需要确保键存在并初始化(如嵌套列表) |
1. 直接赋值法 (Direct Assignment) - 最基础
user = {"name": "Alice", "age": 25}
# 场景 A: 修改已存在的值
user["age"] = 26
print(user) # {'name': 'Alice', 'age': 26}
# 场景 B: 添加新字段
user["city"] = "Beijing"
print(user) # {'name': 'Alice', 'age': 26, 'city': 'Beijing'}
# 场景 C: 值是可变对象时的“深层”修改
user["skills"] = ["Python"]
print(user)
user["skills"].append("Java") # 修改列表内容,字典本身结构未变,但数据变了
print(user["skills"]) # ['Python', 'Java']
#输出
tip='''
{'name': 'Alice', 'age': 26}
{'name': 'Alice', 'age': 26, 'city': 'Beijing'}
{'name': 'Alice', 'age': 26, 'city': 'Beijing', 'skills': ['Python']}
['Python', 'Java']
'''2. .update() 方法 - 批量修改/合并
user = {"name": "Alice", "age": 25, "role": "user"}
# 方式 A: 传入另一个字典 (常用)
updates = {"age": 26, "city": "Shanghai"}
user.update(updates)
print(user)
# {'name': 'Alice', 'age': 26, 'role': 'user', 'city': 'Shanghai'}
# 方式 B: 传入关键字参数 (适合键名合法时)
user.update(role="admin", status="active")
print(user)
# {..., 'role': 'admin', 'status': 'active'}
# 方式 C: 传入元组列表
user.update([("level", 5), ("score", 90)])
print(user)3 .setdefault() 方法 - “仅当不存在时”修改
如果键不存在,则设置默认值并返回;如果键已存在,则什么都不做,直接返回原值。
用途: 防止覆盖已有数据,常用于初始化嵌套结构。
user = {"name": "Alice"}
# 如果 "email" 不存在,则设置为 "unknown" 并返回 "unknown"
# 如果 "email" 已存在,则返回原值,不做修改
email = user.setdefault("email", "unknown")
print(email) # 输出: unknown
print(user) # 输出: {'name': 'Alice', 'email': 'unknown'} (字典被修改了!)1.6.5 字典key删除
删除字典(Dictionary)中的键(Key)主要有 4 种常用方法,以及一种批量删除的技巧。选择哪种方法取决于你是否需要获取被删除的值,以及键是否存在
1. pop(key[, default]) - 最推荐 (安全且返回值)
这是最灵活的方法。它会删除指定的键,并返回该键对应的值。
特点: 可以指定默认值,防止键不存在时报错。
适用: 需要拿到被删除的值,或者希望代码健壮(不报错)。
data = {"a": 1, "b": 2, "c": 3}
# 场景 A: 键存在 -> 删除并返回值
val = data.pop("b")
print(val) # 输出: 2
print(data) # 输出: {'a': 1, 'c': 3}
# 场景 B: 键不存在 + 提供默认值 -> 不报错,返回默认值
val = data.pop("z", "Not Found")
print(val) # 输出: Not Found
print(data) # 输出: {'a': 1, 'c': 3} (字典未变)
# 场景 C: 键不存在 + 无默认值 -> 抛出 KeyError (慎用)
# data.pop("z") 2. del 语句 - 最快但危险
使用 Python 的 del 关键字直接删除。
特点: 语法简洁,执行速度快,不返回被删除的值。
风险: 如果键不存在,必定抛出 KeyError 导致程序崩溃。
适用: 你100% 确定键存在,且不需要返回值。
data = {"a": 1, "b": 2}
# 场景 A: 键存在 -> 成功删除
del data["a"]
print(data) # {'b': 2}
# 场景 B: 键不存在 -> 报错! (Runtime Error)
# del data["z"] # KeyError: 'z'
# ✅ 安全用法:配合 in 检查
if "z" in data:
del data["z"]3. popitem() - 删除最后一项 (LIFO)
删除并返回字典中的最后一个键值对(元组形式)。
特点: Python 3.7+ 保证按插入顺序删除最后加入的一项(栈行为)。
风险: 如果字典为空,抛出 KeyError。
适用: 需要逐个处理并移除元素,或实现栈结构。
data = {"first": 1, "last": 2}
# 删除最后一项 ("last": 2)
key, value = data.popitem()
print(f"Deleted: {key} = {value}") # Deleted: last = 2
print(data) # {'first': 1}
# 空字典调用会报错
# {}.popitem() # KeyError4. clear() - 清空所有
一次性删除字典中的所有键值对。
特点: 字典变为空 {},原地修改,不返回内容。
适用: 重置配置、清理缓存
data = {"a": 1, "b": 2}
data.clear()
print(data) # {}5. 高级技巧:批量删除 (过滤)
Python 没有内置的“批量删除指定键”的方法,通常使用字典推导式创建一个新字典(排除掉不想要的键)。
data = {"a": 1, "b": 2, "c": 3, "d": 4}
keys_to_remove = {"b", "d"}
# 方法:保留那些 不在 删除列表中的键
new_data = {k: v for k, v in data.items() if k not in keys_to_remove}
print(new_data) # {'a': 1, 'c': 3}
# 注意:原字典 data 未变,如果需要替换,执行 data = new_data⚠️ 重要警告:遍历中删除
永远不要在直接遍历字典(for k in d:)的同时使用 del 或 pop 删除当前遍历的键,这会引发 RuntimeError。
❌ 错误写法
for key in data:
if data[key] < 0:
del data[key] # 报错:RuntimeError: dictionary changed size during iteration1.7 集合(set)
集合(Set) 是一个无序、不重复的元素序列。它基于数学中的集合论,主要用于去重和关系运算(交集、并集等)。定义集合主要有 3 种方式,其中空集合的定义是新手最容易犯错的地方.
1.7.1 集合定义
| 定义方式 | 语法示例 | 适用场景 | 关键点 |
|---|---|---|---|
| 花括号 | {1, 2, 3} |
定义非空集合 | 自动去重,元素必须不可变 |
| 构造函数 | set() |
定义空集合 / 去重转换 | 唯一定义空集的方法 |
| 推导式 | {x for x in data} |
生成规律性集合 | 类似列表推导式,用 {} |
| 冻结集合 | frozenset(...) |
需要不可变集合时 | 可作为字典的 Key |
⚠️ 新手避坑指南
1 永远不要写 {} 来创建空集合,请始终使用 set()。
2 不要尝试对集合进行索引操作(s[0]),如果需要索引,请先转为列表 list(s)。
3 如果需要存储“列表”在集合中,请先将其转换为“元组”
1. 花括号法 { } (最常用)
使用花括号将元素包裹起来,元素之间用逗号 , 分隔。
特点: 自动去重,无序。
⚠️ 重要陷阱: 不能用 {} 定义空集合,因为 {} 默认是空字典。
# ✅ 普通集合 (自动去重)
numbers = {1, 2, 3, 2, 1}
print((numbers)) # 输出顺序可能不同,且重复项消失: {1, 2, 3}
print(type(numbers)) #<class 'set'>
# ✅ 混合类型 (必须是可哈希的/不可变的)
mixed = {1, "hello", 3.14, (1, 2)}
# 注意:列表 [1,2] 或字典 {} 不能作为集合元素,会报错 TypeError
# ❌ 错误:这不是空集合,这是空字典!
empty_wrong = {}
print(type(empty_wrong)) # <class 'dict'>2. 可变 vs 不可变集合
set: 可变集合。可以添加 (add) 或删除 (remove) 元素。不能作为字典的键或另一个集合的元素。
frozenset: 不可变集合。创建后不能修改。可以作为字典的键或集合的元素
# 定义冻结集合
f_set = frozenset([1, 2, 3])
# f_set.add(4) # ❌ 报错:AttributeError
# 用途:作为字典的键
d = {frozenset([1, 2]): "value"} 1.7.2 集合访问
| 目的 | 推荐方法/操作符 | 关键点 |
|---|---|---|
| 判断存在 | x in s |
速度最快 (O(1)) |
| 遍历所有 | for x in s: |
无序,不可控顺序 |
| 取出一个 | s.pop() |
随机取出并删除 |
| 安全删除 | s.discard(x) |
不存在也不报错 |
| 危险删除 | s.remove(x) |
不存在会报错 |
| 找共同点 | s1 & s2 或 intersection() |
交集 |
| 找不同点 | s1 - s2 或 difference() |
差集 |
| 合并去重 | s1 | s2 或 union() |
并集 |
| 转列表索引 | list(s)[index] |
不推荐,除非万不得已 |
1 成员检测 (in / not in)
这是访问集合最高效的方式(时间复杂度 O(1)),用于判断元素是否存在。
s = {"apple", "banana", "cherry"}
if "apple" in s:
print("Found it!") # ✅ 快速判断
if "grape" not in s:
print("Not found")2 遍历 (for 循环)
由于无序,只能按顺序(逻辑顺序,非插入顺序)逐个访问
s = {1, 2, 3}
for item in s:
print(item)
# 输出顺序不确定,例如可能是 2, 1, 33 获取/提取元素 (Extracting)
| 方法 | 语法 | 功能描述 | 返回值 | 备注 |
|---|---|---|---|---|
pop() |
s.pop() |
随机移除并返回一个元素 | 被移除的元素 | 唯一能直接“拿出”元素的方法;若集合为空抛 KeyError |
copy() |
s.copy() |
浅拷贝集合 | 新集合 | 用于在不修改原集合的情况下操作 |
1.7.3 集合元素添加
| 方法 | 语法 | 功能描述 | 返回值 | 备注 |
|---|---|---|---|---|
add() |
s.add(elem) |
添加单个元素 | None |
若元素已存在,不执行任何操作(不报错) |
update() |
s.update(iterable) |
批量添加多个元素 | None |
参数可以是列表、元组、字符串或其他集合 |
1.7.4 集合元素删除
| 方法 | 语法 | 功能描述 | 返回值 | 备注 |
|---|---|---|---|---|
remove() |
s.remove(elem) |
删除指定元素 | None |
若元素不存在,抛 KeyError ⚠️ |
discard() |
s.discard(elem) |
删除指定元素 | None |
若元素不存在,不报错 (✅ 推荐用于安全删除) |
clear() |
s.clear() |
清空所有元素 | None |
集合变为空集 set() |
1.7.4 集合运算
数学中的交、并、差、子集等判断
| 方法 | 对应运算符 | 功能描述 | 示例 |
|---|---|---|---|
intersection() |
& |
交集:返回两个集合共有的元素 | s1.intersection(s2) |
union() |
| |
并集:返回两个集合所有不重复元素 | s1.union(s2) |
difference() |
- |
差集:返回在 s1 但不在 s2 的元素 | s1.difference(s2) |
symmetric_difference() |
^ |
对称差集:只在其中一个集合出现的元素 | s1.symmetric_difference(s2) |
issubset() |
<= |
子集判断:s1 是否包含于 s2 | s1.issubset(s2) (返回 bool) |
issuperset() |
>= |
父集判断:s1 是否包含 s2 | s1.issuperset(s2) (返回 bool) |
isdisjoint() |
- | 无交集判断:两个集合是否完全没有共同元素 | s1.isdisjoint(s2) (返回 bool) |
有一点要注意,同类行|,操作结果类型不变,一个set和一个frozenset要变,看以下代码
s = {1, 2, 3} # set (可变)
fs = frozenset([3, 4, 5]) # frozenset (不可变)
result1 = fs|s
print(f"结果: {result1}")
print(f"结果类型: {type(result1)}")
result2 = s|fs
print(f"结果: {result2}")
print(f"结果类型: {type(result2)}")
tip='''
结果: frozenset({1, 2, 3, 4, 5})
结果类型: <class 'frozenset'>
结果: {1, 2, 3, 4, 5}
结果类型: <class 'set'>
'''1.7.5 速查表
| 目的 | 推荐方法/操作符 | 关键点 |
|---|---|---|
| 判断存在 | x in s |
速度最快 (O(1)) |
| 遍历所有 | for x in s: |
无序,不可控顺序 |
| 取出一个 | s.pop() |
随机取出并删除 |
| 安全删除 | s.discard(x) |
不存在也不报错 |
| 危险删除 | s.remove(x) |
不存在会报错 |
| 找共同点 | s1 & s2 或 intersection() |
交集 |
| 找不同点 | s1 - s2 或 difference() |
差集 |
| 合并去重 | s1 | s2 或 union() |
并集 |
| 转列表索引 | list(s)[index] |
不推荐,除非万不得已 |
2 语句
2.1 if
1 缩进 (Indentation):Python 使用缩进来定义代码块,而不是大括号 {}。if、elif 和 else 后面的代码必须缩进(通常使用 4 个空格)。
2 冒号 (:):if、elif 和 else 语句末尾必须有冒号。
3 布尔值:条件表达式的结果必须是布尔值 (True 或 False)。在 Python 中,以下值被视为 False:
False
None
零值:0, 0.0, 0j
空序列/集合:'' (空字符串), [] (空列表), () (空元组), {} (空字典)
其他所有值都视为 True
2.1.1 if
age = 20
if age >= 18:
print("你已成年。")
# 输出:你已成年。2.1.3 if else
score = 45
if score >= 60:
print("及格")
else:
print("不及格")
# 输出:不及格2.1.4 if-elif-else
temperature = 25
if temperature > 30:
print("天气很热")
elif temperature > 20:
print("天气舒适")
elif temperature > 10:
print("天气有点凉")
else:
print("天气很冷")
# 输出:天气舒适2.1.5 if嵌套
user_logged_in = True
user_is_admin = False
if user_logged_in:
print("用户已登录")
if user_is_admin:
print("欢迎管理员!")
else:
print("欢迎普通用户。")
else:
print("请先登录。")2.1.6 if三元运算
score=70
# 语法: 值1 if 条件 else 值2
status = "通过" if score >= 60 else "失败"
print(status)2.1.7 常见运算符搭配
在 if 条件中,常配合以下逻辑运算符使用:
and: 与 (两边都为 True 才为 True)
or: 或 (只要有一边为 True 即为 True)
not: 非 (取反)
x = 5
y = 10
if x > 0 and y > 0:
print("x 和 y 都是正数")
if not (x > 10):
print("x 不大于 10")2.1.8 赋值与判断
# 1. 先赋值
def getValue():
return True
b = getValue()
# 2. 再判断
if b:
# 执行逻辑
print('hhhh')
#上面的写法等价于
if b:= getValue():
print('hhhh')python看起来简单,实际上很复杂,想加啥就加啥,有点像英语
2.2 while
语句用于在条件为真(True)时重复执行代码块。只要条件保持为 True,循环就会一直继续;一旦条件变为 False,循环终止
2.2.1 基本使用
count = 0
while count < 5:
print(f"当前计数: {count}")
count += 1 # 重要:更新计数器,否则死循环
# 输出: 0, 1, 2, 3, 42.2.2 配合else
while正常结束、才会执行else。这个玩意慎用。虽然能满足一些特殊需求,用起来总感觉怪怪的。就像最初人只有男人和女人、后面多了个人妖一样。
print("--- 场景 A: 循环正常结束 ---")
count = 0
while count < 3:
print(f"计数: {count}")
count += 1
else:
# 因为 count 变成 3,条件 count < 3 变为 False,循环自然结束
print(f"循环自然结束,执行 else 块。count={count}")
print("\n--- 场景 B: 循环被 break 中断 ---")
count = 0
while count < 3:
print(f"计数: {count}")
if count == 1:
print("检测到特定条件,触发 break!")
break # 强制退出
count += 1
else:
# 因为遇到了 break,这里会被跳过
print("这行永远不会打印。")
print("程序继续运行...")
tip=='''
--- 场景 A: 循环正常结束 ---
计数: 0
计数: 1
计数: 2
循环自然结束,执行 else 块。count=3
--- 场景 B: 循环被 break 中断 ---
计数: 0
计数: 1
检测到特定条件,触发 break!
程序继续运行...
'''2.3 for
基本用发是用于遍历可迭代对象、如元组、列表、等
for 变量 in 可迭代对象:
# 对每个元素执行这里的代码
语句块2.3.1 遍历列表、元组和字符串
# 遍历列表
fruits = ["apple", "banana", "cherry"]
for fruit in fruits:
print(fruit)
# 遍历字符串
for char in "Python":
print(char, end="-")
# 输出: P-y-t-h-o-n-2.3.2 配合 range() 进行数字循环
# range(停止值): 0 到 4
for i in range(5):
print(i, end=" ")
# 输出: 0 1 2 3 4
# range(开始, 停止): 2 到 4
for i in range(2, 5):
print(i, end=" ")
# 输出: 2 3 4
# range(开始, 停止, 步长): 0, 2, 4, 6, 8
for i in range(0, 10, 2):
print(i, end=" ") 2.3.3 配合enumerate使用
colors = ["red", "green", "blue"]
# 错误做法: 手动维护 index
# index = 0
# for color in colors: ... index += 1
# 正确做法:
for index, color in enumerate(colors):
print(f"索引 {index}: 颜色 {color}")
# 输出:
# 索引 0: 颜色 red
# 索引 1: 颜色 green
# 索引 2: 颜色 blue2.3.4 遍历字典
user = {"name": "Alice", "age": 25, "city": "Beijing"}
# 只遍历键
for key in user:
print(key)
# 遍历键和值 (推荐)
for key, value in user.items():
print(f"{key}: {value}")
# 只遍历值
for value in user.values():
print(value)2.3.5 配合else使用
与 while...else 类似。如果循环正常结束(即遍历完所有元素,没有遇到 break),则执行 else 块
numbers = [1, 3, 6, 7]
for n in numbers:
if n % 2 == 0:
print(f"找到偶数: {n}")
break
else:
# 只有当循环没有被 break 打断时才执行
print("列表中没有偶数")
# 输出: 列表中没有偶数2.4 continue
它的作用是立即结束当前这一轮循环,跳过循环体中剩余的代码,直接进入下一次循环的判断和执行。
位置:只能用在 for 或 while 循环内部。
行为:
遇到 continue 时,不再执行该行之后、当前缩进块内的任何代码。
直接跳回到循环的开始处。
如果是 for 循环:获取序列中的下一个元素。
如果是 while 循环:重新判断条件表达式。
对比 break:
break:彻底终止整个循环(不再进行任何迭代)。
continue:仅跳过本次迭代(循环还会继续处理剩下的元素)
不支持带标签,也就是只能继续当前层循环。
2.4.1 基本示例
for i in range(10):
if i == 5:
print("跳过 5")
continue # 遇到 5,跳过下面的 print(i),直接进入下一轮 i=6
print(f"当前数字: {i}")
print("循环结束")2.5 break
它的作用是立即彻底终止当前所在的整个循环,不支持跳出多层循环
一旦执行到 break:
1 循环立即结束,不再进行任何后续的迭代。
2 程序流程跳转到循环体之后的第一行代码继续执行。
3 如果是嵌套循环,它只跳出最内层的那一层循环,外层循环不受影响(除非配合其他逻辑)
2.5.1 基本示例
numbers = [1, 5, 8, 12, 3, 9]
target = 8
found_index = -1
for i, num in enumerate(numbers):
if num == target:
found_index = i
print(f"找到了!{target} 在索引 {i} 处")
break # 找到后立刻停止循环,后面的 12, 3, 9 不再检查
print(f"正在检查: {num}")
print(f"循环结束,最终索引: {found_index}")2.6 with
with 语句用于简化资源管理(如文件操作、网络连接、数据库连接、锁等)。它确保资源在使用完毕后会被自动、正确地释放,即使在使用过程中发生了异常(错误)
它的核心机制是上下文管理器(Context Manager),基于两个魔法方法:__enter__ 和 __exit__。
2.6.1 传统写法
如果不使用 with,你需要手动打开和关闭文件。如果在读写过程中发生异常,close() 可能永远不会被执行,导致资源泄露。
f = open('data.txt', 'r')
try:
content = f.read()
# 假设这里发生了错误...
# 1/0 <-- 如果这里报错,下面的 close() 就不会执行!
except Exception as e:
print(f"出错了: {e}")
finally:
f.close() # 必须写在 finally 中确保执行,代码繁琐2.6.2 with写法
with 语句会自动处理 try...finally 逻辑。无论代码是否报错,离开 with 代码块时,文件都会自动关闭
# 语法:with 表达式 as 变量:
with open('data.txt', 'r') as f:
content = f.read()
# 即使这里发生错误 (如 1/0)
# Python 也会自动调用 f.close()
print("文件已自动关闭,程序继续运行")2.6.3 lock中的应用
import threading
lock = threading.Lock()
# 传统写法需要 lock.acquire() 和 lock.release()
with lock:
# 临界区代码
print("正在访问共享资源...")
# 离开缩进块后,锁自动释放2.6.4 数据库连接
确保数据库连接或事务在结束后正确关闭或回滚
import sqlite3
# 假设 conn 是一个数据库连接对象
with sqlite3.connect('example.db') as conn:
cursor = conn.cursor()
cursor.execute("SELECT * FROM users")
# 离开块后,连接自动提交事务并关闭(具体行为取决于库的实现)2.6.5 临时改变环境设置
import os
from contextlib import chdir
# 临时进入 /tmp 目录
with chdir('/tmp'):
print(os.getcwd()) # 输出: /tmp
# 在这里创建文件...
# 离开块后,自动回到原来的目录
print(os.getcwd()) 2.6.6 同时管理多个资源
可以在一行 with 中管理多个资源(Python 2.7+ / 3.1+ 支持)
# 同时打开两个文件
with open('input.txt', 'r') as f_in, open('output.txt', 'w') as f_out:
content = f_in.read()
f_out.write(content.upper())
# 两个文件都会自动关闭2.6.7 原理
with 语句背后的逻辑等价于以下代码结构:
manager = EXPR # with 后面的表达式
value = manager.__enter__() # 进入上下文,返回值赋给 as 后的变量
try:
BLOCK # 执行 with 块内的代码
except:
# 如果发生异常
manager.__exit__(type, value, traceback) # 处理异常
else:
# 如果没有异常
manager.__exit__(None, None, None)__enter__: 在进入 with 块时执行。通常用于初始化资源(如打开文件),并返回资源对象。
__exit__: 在离开 with 块时执行(无论是否发生异常)。通常用于清理资源(如关闭文件)。如果发生异常,它会接收异常类型、值和追踪信息;如果它返回 True,异常会被抑制(不抛出
2.6.8 自定义with
class MyResource:
def __enter__(self):
print("资源已获取 (Enter)")
return self # 返回给 as 后面的变量
def __exit__(self, exc_type, exc_val, exc_tb):
print("资源已释放 (Exit)")
if exc_type:
print(f"检测到异常: {exc_val}")
# 返回 True 可以吞掉异常,返回 False 或 None 则让异常继续抛出
return False
# 使用自定义的上下文管理器
with MyResource() as res:
print("正在使用资源...")
# raise ValueError("模拟错误")
print("程序结束")2.7 pass
pass 是一个空操作语句(null operation)。当它被执行时,什么也不会发生
2.7.1 定义空函数或类(作为开发草稿)
当你设计好程序架构,定义了函数名或类名,但还没想好具体实现逻辑时,可以用 pass 避免报错,很多脚本语言都具有类似的一些奇葩特性,简直无法理解。有人说天才都有些不正常的地方。
def future_feature():
# TODO: 以后在这里实现具体功能
pass
class MyNewClass:
# 暂时还没有属性和方法
pass
# 调用它们不会报错,虽然也没什么实际效果
future_feature()
obj = MyNewClass()2.7.2 在条件判断中忽略特定情况
当你希望某些条件满足时什么都不做,直接跳过,可以使用 pass。这比写注释更明确地表示“这里是故意留空的”
value = 10
if value < 5:
print("值很小")
elif value == 10:
# 暂时不需要处理等于 10 的情况,但不想删除这个分支
pass
else:
print("值很大")2.7.3 在循环中跳过特定逻辑
for i in range(5):
if i == 2:
# 遇到 2 时暂时不做任何处理,继续下一次循环
pass
else:
print(i)
# 输出: 0, 1, 3, 4
# 注意:这里其实直接用 continue 效果更好,pass 常用于逻辑尚未确定的占位。当然上面代码换成下面方式会更简洁
for i in range(5):
if i != 2:
print(i)2.7.4 捕获异常但不处理
try:
result = 10 / 0
except ZeroDivisionError:
# 捕获了除零错误,但决定忽略它,程序继续运行
pass
print("程序继续运行...")2.8 迭代器
python中的迭代会抛出StopIteration,这是个陷阱,要注意。很多脚本语言都容易整些语法陷阱,让你防不胜防,这就是我吐槽这类语言的原因。如果是大型长期稳定运行的程序,不是有特殊需求,使用这类语言存粹就是有点智障。
2.8.1 基本用法
python2中的和python用法不一样
#python 2中写法不能用于python3
testTuple=(123,'hello',45.67)
ittest=iter(testTuple)
ittest.next()
ittest.next()
ittest.next()
#python3写法
testTuple=(123,'hello',45.67)
ittest=iter(testTuple)
next(ittest)
next(ittest)
next(ittest)
next(ittest)# 这句会抛出StopIteration2.8.2 文件迭代
手动控制,代码看起来有点恶心
filename = 'data.csv'
with open(filename, 'r', encoding='utf-8') as f:
# 1. 读取第一行 (通常是标题)
header = next(f)
print(f"标题: {header.strip()}")
# 2. 读取第二行
first_row = next(f)
print(f"第一行数据: {first_row.strip()}")
# 3. 继续用循环读取剩余部分
# 注意:文件指针已经移动到了第三行,循环会从那里开始
for line in f:
print(f"剩余数据: {line.strip()}")
# 4. 如果文件读完再调用 next(),会抛出 StopIteration
try:
next(f)
except StopIteration:
print("文件已读取完毕!")实在是受不了,所以搞出个with来
优点:
内存高效:即使文件有 10GB,内存占用也极小。
代码简洁:不需要手动管理索引或读取状态。
# 假设有一个文件 'example.txt'
# 内容:
# Line 1
# Line 2
# Line 3
filename = 'example.txt'
# ✅ 最佳实践:直接在 for 循环中使用文件对象
with open(filename, 'r', encoding='utf-8') as f:
# f 本身就是一个迭代器
for line in f:
# line 包含换行符 '\n',通常需要用 .strip() 去除
print(f"当前行: {line.strip()}")手动控制
2.9 生成器
生成器 (Generator) 是一种特殊的迭代器,它允许你按需生成值,而不是一次性将所有值加载到内存中。它是处理大数据流、无限序列或节省内存的神器
| 特性 | 列表 (List) | 生成器 (Generator) |
|---|---|---|
| 定义符号 | 方括号 [] 或 list() |
圆括号 () 或含 yield 的函数 |
| 内存占用 | 高 一次性将所有数据加载到内存中。数据量过大易导致 OOM (内存溢出)。 |
极低 惰性求值,每次只生成一个值,内存占用恒定(仅保存当前状态)。 |
| 计算时机 | 立即执行 (Eager) 创建时立刻计算所有元素。 |
延迟执行 (Lazy) 只有在迭代请求 ( next) 时才计算当前值。 |
| 遍历次数 | 可重复遍历 可以多次 for 循环或通过索引访问。 |
仅限一次 遍历完成后即耗尽 (Exhausted),无法再次使用,需重新创建。 |
| 索引/切片 | 支持 支持 lst[0], lst[-1], lst[1:5] 等随机访问。 |
不支持 无法通过索引访问,只能按顺序逐个获取。 |
| 长度查询 | 支持len(lst) 可立即返回长度。 |
不支持 无法直接获取 len() (除非遍历完计数,但这会耗尽它)。 |
| 数据规模 | 适合小规模数据集。 | 适合大规模数据集、无限序列或流式数据。 |
| 性能特点 | 首次创建慢 (需计算全部),但后续随机访问极快。 | 创建极快,但逐个访问有微小的函数调用开销。 |
| 典型应用 | 需要多次随机访问、修改、排序或切片的数据。 | 读取大文件、数据库分页、实时数据流、管道处理。 |
| 代码示例 | data = [x*2 for x in range(100)] |
data = (x*2 for x in range(100))或 def gen(): yield ... |
2.9.1 生成器定义
表达式
# 列表推导式 (立即执行,占内存)
squares_list = [x**2 for x in range(5)]
# 结果: [0, 1, 4, 9, 16] (列表对象)
# 生成器表达式 (延迟执行,省内存)
squares_gen = (x**2 for x in range(5))
# 结果: <generator object <genexpr> at 0x...> (生成器对象)
# 使用时逐个获取
print(next(squares_gen)) # 0
print(next(squares_gen)) # 1
# 或者遍历
for num in squares_gen:
print(num) # 依次输出 4, 9, 16函数
在函数中使用 yield 关键字代替 return。
return:返回值并终止函数。
yield:返回值并暂停函数,保留当前局部变量的状态,下次调用从暂停处继续执行
def fibonacci_generator(n):
"""生成前 n 个斐波那契数"""
a, b = 0, 1
count = 0
while count < n:
yield a # 暂停在这里,返回 a
a, b = b, a + b
count += 1
# 调用函数不会立即执行代码,而是返回一个生成器对象
fib = fibonacci_generator(5)
print(type(fib)) # <class 'generator'>
# 遍历生成器
for num in fib:
print(num)
# 输出: 0, 1, 1, 2, 3生成器每次创建都是一个独立的,调用close之后就,再次调用就会抛出异常
| 方法 | 功能描述 | 典型用途 |
|---|---|---|
.send(value) |
向生成器内部发送值,并恢复执行。 | 协程、双向数据流、动态调整参数。 |
.throw(type, value, traceback) |
在生成器暂停处抛出异常。 | 错误注入、强制中断逻辑、资源清理。 |
.close() |
关闭生成器,抛出 GeneratorExit 异常。 |
释放外部资源(如文件、网络连接)。 |
2.9.2 高级用法
1 处理无限序列
由于生成器不存储所有值,它可以表示无限长的序列。
def infinite_counter():
i = 0
while True:
yield i
i += 1
counter = infinite_counter()
print(next(counter)) # 0
print(next(counter)) # 1
print(next(counter)) # 2
# 可以一直 next 下去,不会爆内存2 管道式数据处理 (Data Pipeline)
生成器可以串联起来,形成高效的数据处理流,中间不产生临时大列表。
# 1. 读取行 (模拟)
def read_lines(filename):
for i in range(1000000): # 假设文件有 100 万行
yield f"Line {i}: data"
# 2. 过滤
def filter_lines(lines):
for line in lines:
if "Line 5" in line: # 只保留包含 "Line 5" 的行
yield line
# 3. 转换
def parse_lines(lines):
for line in lines:
yield line.upper()
# 串联管道
data_stream = read_lines("dummy.txt")
filtered_stream = filter_lines(data_stream)
final_stream = parse_lines(filtered_stream)
# 只有在这里遍历时,整个链条才会开始流动
for item in final_stream:
print(item)
# 处理完一个就丢弃一个,内存占用极低3 send() 和 throw() (双向通信)
生成器不仅可以产出值,还可以接收外部传入的值(协程的基础)。这个 value = yield total稍微有点难理解
def accumulator():
total = 2
while True:
# yield 左边可以接收 send 传来的值
value = yield total
if value is None:
print('None')
break
total += value
acc = accumulator()
print(next(acc)) # 启动生成器,运行到 yield,返回 2
#print(next(acc))
print(acc.send(10)) # 发送 10 给 value,total 变为 10,返回 10
print(acc.send(20)) # 发送 20 给 value,total 变为 30,返回 30
print(acc.send(20)) # 发送 20 给 value,total 变为 30,返回 30| 步骤 | 代码执行 | 动作详解 | 内部变量变化 | 外部输出 (Print) | 生成器状态 |
|---|---|---|---|---|---|
| 1 | next(acc) |
启动生成器。 执行到 yield total。返回当前的 total 值。 |
total = 2value = (未定义) |
2 | 暂停 (停在 value = yield ... 处,等待接收值) |
| 2 | acc.send(10) |
发送 10。 1. yield 表达式接收到 10。2. 赋值: value = 10。3. 判断 if value is None (False)。4. 累加: total += 10 (2 + 10)。5. 循环回到开头。 6. 再次遇到 yield total,返回新 total。 |
value = 10total = 12 |
12 | 暂停 (停在下一轮循环的 yield 处) |
| 3 | acc.send(20) |
发送 20。 1. yield 表达式接收到 20。2. 赋值: value = 20。3. 判断 if (False)。4. 累加: total += 20 (12 + 20)。5. 循环,遇到 yield,返回新 total。 |
value = 20total = 32 |
32 | 暂停 |
| 4 | acc.send(20) |
发送 20。 1. yield 表达式接收到 20。2. 赋值: value = 20。3. 判断 if (False)。4. 累加: total += 20 (32 + 20)。5. 循环,遇到 yield,返回新 total。 |
value = 20total = 52 |
52 | 暂停 |
def safe_processor():
try:
while True:
x = yield "Waiting..."
print(f"处理数据: {x}")
except ValueError as e:
print(f"捕获到注入的错误: {e}")
return "已安全退出"
except GeneratorExit:
print("生成器被强制关闭")
raise
gen = safe_processor()
next(gen) # 启动
try:
# 在 yield 处抛出一个 ValueError
gen.throw(ValueError("数据格式错误!"))
except StopIteration as e:
# 如果生成器内部 return 了,会触发 StopIteration
print(f"生成器返回: {e.value}")
# 输出:
# Waiting... (来自 next)
# 捕获到注入的错误: 数据格式错误!
# 生成器返回: 已安全退出2.10 三个点用法
... 被称为 Ellipsis(省略号)。它不仅仅是一个符号,而是 Python 的一个内置常量对象(单例对象),其类型是 types.EllipsisType
- 它是一个对象:你可以直接打印它,也可以把它赋值给变量。
- 它不是 pass:pass 是一个空语句,什么都不做;而 ... 是一个表达式,它会被求值为 Ellipsis 对象。
print(...) # 输出: Ellipsis
print(type(...)) # 输出: <class 'ellipsis'>
print(... is Ellipsis) # 输出: True| 场景 | 含义 | 示例 |
|---|---|---|
| 代码占位 | 待实现/省略逻辑 | def foo(): ... |
| NumPy 切片 | 补全所有剩余维度 | arr[0, ..., -1] |
| 类型提示 | 任意参数列表 | Callable[..., int] |
| 终端交互 | 等待继续输入 | >>> if True: ... |
python这玩意要多爽就有多爽,反过来要多恶心就有多,你以为你精通python了,冷不丁的冒出一个你不认识的东西。看看你下面代码,你是不不是看不懂!
from pydantic import BaseModel, Field
from langchain.chat_models import init_chat_model
class Movie(BaseModel):
"""A movie with details."""
title: str = Field(description="The title of the movie")
year: int = Field(description="The year the movie was released")3 文件操作
3.1 open
Python3 的文件操作非常直观且功能强大,主要内置在 open() 函数中。现代 Python 开发强烈推荐使用 with 语句(上下文管理器),因为它能自动处理文件关闭,即使发生错误也能确保资源被释放
3.1.1 基础用法:使用 with 语句(推荐)
# 读取文件 三个参数:文件路径,操作模式,编码
#在 Python 3 中处理文本文件时,强烈建议始终指定 encoding='utf-8'
with open('example.txt', 'r', encoding='utf-8') as f:
content = f.read()
print(content)
# 离开 with 块后,文件会自动关闭,无需 f.close()3.1.2 模式
open() 函数的第二个参数决定了对文件的操作方式
| 模式 | 描述 | 文件不存在时 | 文件存在时 |
|---|---|---|---|
'r' |
只读 (默认) | 报错 (FileNotFoundError) |
保留原内容,指针在开头 |
'w' |
只写 | 创建新文件 | 清空原内容,重新写入 |
'a' |
追加 | 创建新文件 | 保留原内容,指针在末尾 |
'x' |
独占创建 | 创建新文件 | 报错 (FileExistsError) |
'b' |
二进制 (配合使用,如 'rb', 'wb') |
- | 用于图片、音频等非文本文件 |
'+' |
更新 (读写同时,如 'r+', 'w+') |
取决于主模式 | - |
3.1.3 文件句柄方法汇总
1 读取方法
| 方法名 | 描述 | 返回值 |
|---|---|---|
read([size]) |
读取指定字节数(二进制)或字符数(文本)。若省略 size,则读取直到文件末尾。 |
str (文本) 或 bytes (二进制) |
readline([size]) |
读取一行(包括换行符 \n)。若指定 size,则最多读取该长度的字符。 |
str 或 bytes |
readlines([hint]) |
读取所有行并返回一个列表。hint 用于限制读取的总字节/字符数(近似值)。 |
list[str] 或 list[bytes] |
readable() |
检查文件是否支持读取操作。 | bool |
2 写入方法
| 方法名 | 描述 | 返回值 |
|---|---|---|
write(s) |
将字符串 s (文本) 或字节串 s (二进制) 写入文件。 |
写入的字符数或字节数 (int) |
writelines(lines) |
将一个字符串列表写入文件。注意:它不会自动添加换行符,列表中每个元素需自带 \n。 |
None |
writable() |
检查文件是否支持写入操作。 | bool |
flush() |
强制刷新缓冲区,将数据立即写入磁盘。常用于日志记录或长运行程序。 | None |
3 定位
| 方法名 | 描述 | 返回值 |
|---|---|---|
seek(offset, whence=0) |
移动文件指针到新位置。 - offset: 偏移量- whence: 参考点 (0: 开头, 1: 当前位置, 2: 文件末尾) |
新的绝对位置 (int) |
tell() |
返回当前文件指针的位置。 | int |
truncate([size]) |
截断文件。若指定 size,则保留前 size 字节/字符;若省略,则在当前指针处截断。 |
文件大小 (int) |
seekable() |
检查文件是否支持随机访问(即是否支持 seek 和 tell)。 |
bool |
4 属性状态
| 方法名 | 描述 | 返回值 |
|---|---|---|
close() |
关闭文件。使用后无法再进行读写操作。(使用 with 语句时会自动调用) |
None |
closed |
(属性) 检查文件是否已关闭。 | bool |
fileno() |
返回底层的文件描述符整数(File Descriptor),用于底层系统调用。 | int |
isatty() |
检查文件是否连接到终端(TTY)设备。 | bool |
name |
(属性) 返回文件名。 | str |
mode |
(属性) 返回打开文件的模式(如 'r', 'wb')。 |
str |
encoding |
(属性) 返回文本文件的编码格式(如 'utf-8')。二进制文件无此属性。 |
str |
3.2 os模块
os 模块是 Python 标准库中用于与操作系统交互的核心模块。它提供了大量方法来处理文件、目录、环境变量、进程等。虽然现代 Python 开发中推荐使用 pathlib 模块来处理路径(因为它更面向对象且跨平台兼容性更好),但 os 模块在许多底层操作、环境变量管理和遗留代码中仍然不可或缺
3.2.1 路径操作
| 方法 | 描述 | 示例 |
|---|---|---|
os.path.join(path, *paths) |
智能拼接路径。自动处理不同操作系统的路径分隔符(Windows 用 \,Linux/Mac 用 /)。 |
'home\\user\\file.txt' |
os.path.exists(path) |
判断路径(文件或目录)是否存在。 | os.path.exists('data.txt') |
os.path.isfile(path) |
判断是否为文件。 | os.path.isfile('script.py') |
os.path.isdir(path) |
判断是否为目录。 | os.path.isdir('images') |
os.path.abspath(path) |
返回绝对路径。 | os.path.abspath('..') |
os.path.basename(path) |
返回路径中的文件名部分。 | os.path.basename('/a/b/c.txt') → 'c.txt' |
os.path.dirname(path) |
返回路径中的目录部分。 | os.path.dirname('/a/b/c.txt') → '/a/b' |
os.path.split(path) |
将路径分割为 (目录名, 文件名) 元组。 |
os.path.split('/a/b.txt') → ('/a', 'b.txt') |
os.path.splitext(path) |
分离文件名和扩展名,返回 (文件名, 扩展名)。 |
os.path.splitext('img.png') → ('img', '.png') |
os.path.getsize(path) |
返回文件大小(字节)。 | os.path.getsize('log.txt') |
os.path.getmtime(path) |
返回最后修改时间(时间戳)。 | os.path.getmtime('data.csv') |
3.2.2 目录操作
| 方法 | 描述 | 示例 |
|---|---|---|
os.getcwd() |
获取当前工作目录 (Get Current Working Directory)。 | os.getcwd() |
os.chdir(path) |
切换当前工作目录 (Change Directory)。 | os.chdir('/tmp') |
os.mkdir(path) |
创建单个目录。如果父目录不存在会报错。 | os.mkdir('new_folder') |
os.makedirs(path) |
递归创建多级目录。如果中间目录不存在会自动创建(推荐)。 | os.makedirs('a/b/c') |
os.rmdir(path) |
删除空目录。如果目录非空会报错。 | os.rmdir('empty_folder') |
os.removedirs(path) |
递归删除空目录(从叶子节点向上删,直到遇到非空目录)。 | os.removedirs('a/b/c') |
os.listdir(path='.') |
列出指定目录下的所有文件和子目录名称(不包含 . 和 ..)。 |
os.listdir('.') |
os.scandir(path='.') |
高效迭代目录条目(返回 DirEntry 对象,可快速判断是文件还是目录,比 listdir 性能更好)。 |
for entry in os.scandir(): ... |
os.walk(top) |
递归遍历目录树。生成一个三元组 (dirpath, dirnames, filenames)。 |
for root, dirs, files in os.walk('.'): ... |
3.2.3 文件操作
| 方法 | 描述 | 示例 |
|---|---|---|
os.remove(path) |
删除文件。不能删除目录。 | os.remove('old.txt') |
os.unlink(path) |
os.remove 的别名,功能完全相同。 |
os.unlink('temp.log') |
os.rename(src, dst) |
重命名文件或移动文件(如果 dst 包含新路径)。 |
os.rename('old.txt', 'new.txt') |
os.replace(src, dst) |
重命名或移动,如果目标存在则强制覆盖(原子操作,更安全)。 | os.replace('tmp.txt', 'final.txt') |
os.stat(path) |
获取文件状态信息(大小、权限、时间等),返回 stat_result 对象。 |
os.stat('file.txt').st_size |
os.access(path, mode) |
检查当前用户是否有权限访问文件(读/写/执行)。 | os.access('script.sh', os.X_OK) |
3.2.4 环境与系统信息
| 方法 | 描述 | 示例 |
|---|---|---|
os.getenv(key, default=None) |
获取环境变量。如果不存在返回 default。 |
os.getenv('HOME', '/root') |
os.environ |
包含所有环境变量的字典对象,可读写。 | os.environ['PATH'] |
os.putenv(key, value) |
设置环境变量(通常直接修改 os.environ 即可)。 |
os.environ['MY_VAR'] = '123' |
os.system(command) |
执行 Shell 命令字符串。不推荐用于获取输出,仅用于执行。 | os.system('ls -l') |
os.popen(command) |
执行 Shell 命令并返回文件对象以读取输出(较老,推荐用 subprocess)。 |
os.popen('date').read() |
os.name |
返回操作系统名称 ('nt' for Windows, 'posix' for Linux/Mac)。 |
print(os.name) |
os.sep |
当前系统的路径分隔符 ('\\' 或 '/')。 |
path = 'a' + os.sep + 'b' |
os.linesep |
当前系统的行结束符 ('\r\n' 或 '\n')。 |
- |
3.3 pathlib
pathlib 是 Python 3.4+ 引入的标准库模块,它提供了面向对象的路径操作方式。相比 os.path 的字符串操作,pathlib 更加直观、易读,且自动处理不同操作系统的路径分隔符问题。
3.3.1 基础创建与表示
| 方法/属性 | 描述 | 示例 |
|---|---|---|
Path(...) |
创建路径对象。可以传入多个部分自动拼接。 | p = Path('home', 'user', 'docs') |
Path.cwd() |
获取当前工作目录的绝对路径对象。 | p = Path.cwd() |
Path.home() |
获取当前用户的主目录路径对象。 | p = Path.home() |
p.as_posix() |
将路径转换为 POSIX 风格(使用 / 分隔符),常用于生成 URL 或跨平台配置。 |
p.as_posix() → 'C:/Users/...' (即使在 Windows) |
str(p) |
将路径对象转换为普通字符串(用于传给不支持 Path 的旧函数)。 | file_path = str(p) |
3.3.2 路径拼接与分解
| 操作 | 描述 | 示例 |
|---|---|---|
p / 'subdir' |
拼接路径 (重载了 / 运算符)。自动处理分隔符。 |
Path('data') / 'logs' / 'app.txt' |
p.name |
获取路径最后的文件名(含扩展名)。 | Path('/a/b.py').name → 'b.py' |
p.stem |
获取文件名不含扩展名的部分。 | Path('/a/b.py').stem → 'b' |
p.suffix |
获取文件扩展名(含点)。 | Path('/a/b.py').suffix → '.py' |
p.suffixes |
获取所有扩展名列表(针对 .tar.gz 等多重后缀)。 |
Path('archive.tar.gz').suffixes → ['.tar', '.gz'] |
p.parent |
获取父目录路径对象。 | Path('/a/b/c').parent → PosixPath('/a/b') |
p.parents |
获取所有祖先目录的序列(可索引)。 | p.parents[0] (父), p.parents[1] (祖父) |
p.parts |
将路径拆分为元组。 | Path('/a/b').parts → ('/', 'a', 'b') |
3.3.3 检查与状态
| 方法/属性 | 描述 | 示例 |
|---|---|---|
p.exists() |
判断路径是否存在(文件或目录)。 | if p.exists(): ... |
p.is_file() |
判断是否为文件。 | p.is_file() |
p.is_dir() |
判断是否为目录。 | p.is_dir() |
p.is_symlink() |
判断是否为符号链接。 | p.is_symlink() |
p.is_absolute() |
判断是否为绝对路径。 | p.is_absolute() |
p.stat() |
获取文件状态信息(类似 os.stat),返回 stat_result 对象。 |
p.stat().st_size (大小), p.stat().st_mtime (修改时间) |
p.samefile(other) |
判断是否与另一个路径指向同一个文件。 | p.samefile(q) |
3.3.4 目录操作
| 方法 | 描述 | 示例 |
|---|---|---|
p.mkdir(mode=0o777, parents=False, exist_ok=False) |
创建目录。 - parents=True: 递归创建缺失的父目录。- exist_ok=True: 如果目录已存在不报错。 |
p.mkdir(parents=True, exist_ok=True) |
p.iterdir() |
迭代当前目录下的所有条目(返回 Path 对象生成器)。比 os.listdir 更高效且直接返回对象。 |
for child in p.iterdir(): print(child) |
p.glob(pattern) |
根据通配符模式查找文件(非递归)。返回生成器。 支持 *, ?, [...]。 |
list(p.glob('*.txt')) |
p.rglob(pattern) |
递归查找文件(相当于 `` 前缀)。 | list(p.rglob('*.log')) |
p.rename(target) |
重命名或移动此路径到 target。 |
p.rename(new_name) |
p.replace(target) |
强制重命名或移动(如果目标存在则覆盖)。 | p.replace(backup_path) |
p.unlink() |
删除文件。不能删除目录。 | p.unlink() |
p.rmdir() |
删除空目录。如果目录非空会报错。 | p.rmdir() |
3.3.5 文件读写
| 方法 | 描述 | 示例 |
|---|---|---|
p.read_text(encoding='utf-8') |
读取文件全部内容为字符串。 | content = p.read_text() |
p.read_bytes() |
读取文件全部内容为字节串。 | data = p.read_bytes() |
p.write_text(data, encoding='utf-8') |
写入字符串到文件(覆盖模式)。自动创建文件。 | p.write_text('Hello') |
p.write_bytes(data) |
写入字节串到文件。 | p.write_bytes(b'\x00\x01') |
with p.open(...) |
以传统方式打开文件句柄(支持 mode, buffering 等参数)。 | with p.open('r') as f: ... |
3.4 sys
3.4.1 命令行参数与程序控制
| 属性/方法 | 描述 | 示例/用法 |
|---|---|---|
sys.argv |
命令行参数列表。argv[0] 是脚本文件名,后续元素是传入的参数。 |
python script.py arg1 arg2sys.argv → ['script.py', 'arg1', 'arg2'] |
sys.exit([arg]) |
退出程序。抛出 SystemExit 异常。- 0 或省略:正常退出- 非零整数:异常退出(错误码) |
sys.exit(1) # 报错退出 |
sys.stdin |
标准输入流(文件对象)。通常对应键盘输入,可被重定向。 | for line in sys.stdin: ... |
sys.stdout |
标准输出流(文件对象)。通常对应屏幕打印,可被重定向。 | sys.stdout.write("Hello\n") |
sys.stderr |
标准错误流(文件对象)。通常对应屏幕错误信息,默认不缓冲。 | sys.stderr.write("Error!\n") |
3.4.2 模块搜索路径与环境
| 属性/方法 | 描述 | 示例/用法 |
|---|---|---|
sys.path |
模块搜索路径列表。Python 导入模块时会按顺序查找这些目录。包含当前目录、标准库路径等。 | sys.path.insert(0, '/my/libs')(优先从自定义路径导入) |
sys.modules |
字典,记录已加载的模块。键是模块名,值是模块对象。用于高级元编程或检查模块是否已加载。 | if 'numpy' in sys.modules: ... |
sys.prefix |
站点级目录前缀(通常是虚拟环境或 Python 安装根目录)。 | 用于构建特定于安装的路径。 |
sys.executable |
当前运行 Python 解释器的绝对路径。 | 用于在脚本中调用自身或其他脚本:subprocess.run([sys.executable, 'other.py']) |
3.4.3 版本与平台信息
| 属性/方法 | 描述 | 示例返回值 |
|---|---|---|
sys.version |
Python 版本字符串(包含编译信息)。 | '3.9.7 (default, Sep 16 2021)...' |
sys.version_info |
Python 版本元组 (major, minor, micro, releaselevel, serial)。推荐用于版本判断。 |
sys.version_info >= (3, 8) |
sys.platform |
平台标识符。用于判断操作系统类型。 | 'win32', 'linux', 'darwin' (MacOS) |
sys.byteorder |
系统字节序。 | 'little' 或 'big' |
3.4.4 递归限制与内存管理
| 属性/方法 | 描述 | 示例/用法 |
|---|---|---|
sys.getrecursionlimit() |
获取当前最大递归深度限制(默认通常为 1000)。 | 防止无限递归导致栈溢出。 |
sys.setrecursionlimit(limit) |
设置最大递归深度。慎用,设得太高可能导致 C 栈溢出崩溃。 | sys.setrecursionlimit(2000) |
sys.getsizeof(obj) |
返回对象在内存中占用的字节数(仅计算对象本身,不包含引用对象的大小)。 | sys.getsizeof([1, 2, 3]) |
sys.getrefcount(obj) |
返回对象的引用计数(注意:调用此函数本身会临时增加一次引用)。 | 用于调试内存泄漏。 |
sys.gc() |
强制触发垃圾回收(通常不需要手动调用,Python 会自动处理)。 | sys.gc() |
3.4.5 钩子与异常处理 (高级)
| 属性/方法 | 描述 | 示例/用法 |
|---|---|---|
sys.exc_info() |
返回当前正在处理的异常信息元组 (type, value, traceback)。仅在 except 块中有效。 |
用于自定义日志记录。 |
sys.tracebacklimit |
设置打印 traceback 时的最大层数。设为 0 可隐藏 traceback。 | sys.tracebacklimit = 0 |
sys.displayhook |
交互式解释器中用于显示表达式结果的函数。可被重写以改变 REPL 行为。 | - |
sys.stdin.encoding |
获取标准输入的编码格式(如 'utf-8', 'cp936')。 | 用于处理编码兼容性问题。 |
3.5 对象序列化
pickle 和 marshal 都是 Python 标准库中用于序列化(将 Python 对象转换为字节流)和反序列化(将字节流恢复为 Python 对象)的模块
| 特性 | pickle |
marshal |
|---|---|---|
| 主要用途 | 通用对象序列化(保存/加载复杂对象) | Python 内部编译字节码 (.pyc) |
| 支持的数据类型 | 极广:基本类型、列表、字典、自定义类/实例、函数、递归结构等 | 有限:基本类型、列表、元组、字典、代码对象 (code object)。不支持自定义类实例。 |
| 版本兼容性 | 较好:高版本 Python 通常能读取低版本生成的 pickle(需指定 protocol),但低版本无法读取高版本的新特性。 | 极差:格式随 Python 小版本(如 3.8 vs 3.9)变化。严禁在不同 Python 版本间交换 marshal 数据。 |
| 安全性 | ❌ 不安全:加载恶意 pickle 数据可执行任意代码(RCE)。 | ❌ 不安全:同样可执行任意代码(通过构造特殊的 code object)。 |
| 性能 | 中等(取决于 protocol 版本,protocol 5 较快) | 极快(因为结构简单,专为内部优化) |
| 人类可读性 | 二进制(不可读),但有文本协议(protocol 0,已过时且不推荐) | 纯二进制(完全不可读) |
| 跨语言支持 | 无(仅限 Python,虽有第三方库但非标准) | 无(仅限 Python 内部) |
| 处理循环引用 | 支持 | 支持 |
3.5.1 pickle基本用法
import pickle
data = {
'name': 'Alice',
'scores': [90, 85, 88],
'active': True
}
# 序列化 (Dump) - 写入文件
# protocol=pickle.HIGHEST_PROTOCOL 推荐使用最新协议以获得最佳性能和功能
with open('data.pkl', 'wb') as f:
pickle.dump(data, f, protocol=pickle.HIGHEST_PROTOCOL)
# 反序列化 (Load) - 读取文件
with open('data.pkl', 'rb') as f:
loaded_data = pickle.load(f)
print(loaded_data)
# 输出: {'name': 'Alice', 'scores': [90, 85, 88], 'active': True}支持自定义对象,这是 pickle 最大的优势
class User:
def __init__(self, name):
self.name = name
user = User("Bob")
# 保存对象
with open('user.pkl', 'wb') as f:
pickle.dump(user, f)
# 恢复对象 (注意:运行时必须定义相同的 User 类)
with open('user.pkl', 'rb') as f:
restored_user = pickle.load(f)
print(restored_user.name) # 输出: Bob3.5.2 marshal 基本用法
marshal 主要用于 Python 解释器内部,将编译后的代码对象写入 .pyc 文件,不支持自定义类
import marshal
data = {'a': 1, 'b': [1, 2, 3]} # 只能是基本类型
# 序列化
with open('data.marshal', 'wb') as f:
marshal.dump(data, f)
# 反序列化
with open('data.marshal', 'rb') as f:
loaded_data = marshal.load(f)
print(loaded_data)3.5.3 shelve
shelve 是 Python 标准库中的一个模块,它提供了一个简单的持久化字典(persistent dictionary)功能。简单来说,它允许你像操作普通 Python 字典一样操作一个文件,但数据会被自动保存到磁盘上。当你关闭程序再重新打开时,数据依然存在。它是 pickle 模块的封装,支持存储几乎所有 Python 对象(列表、字典、类实例等),而不仅仅是字符串。
import shelve
# 'mydata.db' 是文件名前缀 (实际可能生成 .db, .dir, .bak 等多个文件)
# writeback=True 是一个重要参数,稍后解释
with shelve.open('mydata', writeback=True) as db:
# 像字典一样赋值
db['user_settings'] = {'theme': 'dark', 'font_size': 14}
db['user_list'] = ['Alice', 'Bob', 'Charlie']
db['count'] = 100
print("数据已保存。")
with shelve.open('mydata') as db:
# 检查键是否存在
if 'user_settings' in db:
settings = db['user_settings']
print(f"读取到的设置: {settings}")
# 遍历所有键
print("\n所有键:")
for key in db:
print(f"{key}: {db[key]}")4 异常和错误处理
Python 的异常体系是面向对象的,所有异常都继承自基类 BaseException。在实际开发中,我们通常捕获继承自 Exception 的子类
4.1 异常等级
和早期版本有些差异,StandardError 已经不存在了
BaseException
+-- SystemExit (sys.exit() 抛出)
+-- KeyboardInterrupt (Ctrl+C 抛出)
+-- GeneratorExit (生成器关闭)
+-- Exception (⚠️ 绝大多数普通异常都继承自这里)
+-- StopIteration
+-- ArithmeticError
| +-- ZeroDivisionError
| +-- OverflowError
+-- AssertionError
+-- AttributeError
+-- EOFError
+-- ImportError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- NameError
+-- OSError ( IOError, EnvironmentError )
| +-- FileNotFoundError
| +-- PermissionError
+-- RuntimeError
+-- SyntaxError
+-- TypeError
+-- ValueError
...4.2 常用内置异常详解
4.2.1 逻辑与类型错误 (最常见)
| 异常类型 | 描述 | 触发示例 |
|---|---|---|
TypeError |
操作或函数应用于不适当类型的对象。 | len(10)"hello" + 5func(arg=None) (当 arg 不能为 None) |
ValueError |
类型正确,但值不合适。 | int("abc")math.sqrt(-1)list.remove(x) (x 不在列表中) |
AttributeError |
引用或赋值属性失败(对象没有该属性)。 | None.length[1,2].foo() |
NameError |
尝试访问未定义的变量。 | print(undefined_var) |
IndexError |
序列下标超出范围。 | lst = [1,2]; lst[5] |
KeyError |
字典中键不存在。 | d = {'a': 1}; d['b'] |
4.2.2 算术与计算错误
| 异常类型 | 描述 | 触发示例 |
|---|---|---|
ZeroDivisionError |
除法或取模运算的除数为零。 | 10 / 010 % 0 |
OverflowError |
算术运算结果太大,无法表示。 | math.exp(1000) (在某些系统上) |
FloatingPointError |
浮点运算出错(通常需开启 float_exception 才会触发,默认忽略)。 |
- |
4.2.3 文件与操作系统错误 (OSError 子类)
| 异常类型 | 描述 | 触发示例 |
|---|---|---|
FileNotFoundError |
文件或目录不存在。 | open('missing.txt') |
PermissionError |
没有权限执行操作。 | 打开一个只读文件进行写入 |
IsADirectoryError |
期望是文件,但实际是目录。 | open('/home/user/') (作为文件打开) |
NotADirectoryError |
期望是目录,但实际是文件。 | os.listdir('file.txt') |
InterruptedError |
系统调用被信号中断。 | - |
4.2.4 导入与模块错误
| 异常类型 | 描述 | 触发示例 |
|---|---|---|
ImportError |
导入模块失败。 | import non_existent_module |
ModuleNotFoundError |
ImportError 的子类,特指找不到模块 (Python 3.6+)。 |
同上 |
4.2.5 其他常见异常
| 异常类型 | 描述 | 触发示例 |
|---|---|---|
AssertionError |
assert 语句失败。 |
assert 1 == 2 |
StopIteration |
迭代器没有更多元素(for 循环自动处理,手动 next() 时需注意)。 |
next(iter([])) |
RuntimeError |
检测到不属于任何特定类别的错误。 | 递归过深(有时)、自定义通用错误 |
NotImplementedError |
抽象方法未实现(常用于基类)。 | 在基类中定义但未重写的方法 |
SyntaxError |
语法错误(解析器抛出,无法在运行时 try...except 捕获,必须在编码阶段修复)。 |
if True print("hi") (缺冒号) |
IndentationError |
缩进错误 (SyntaxError 的子类)。 |
混合使用 Tab 和空格导致对齐错误 |
4.3 异常处理
4.3.1 基础格式
try:
# 可能出错的代码
result = 10 / 0
except ZeroDivisionError as e:
# 仅当发生 ZeroDivisionError 时执行
print("不能除以零!",e)
#早期版本是这样写的
try:
# 可能出错的代码
result = 10 / 0
except ZeroDivisionError,e:
# 仅当发生 ZeroDivisionError 时执行
print("不能除以零!",e)4.3.2 try finally
try:
# 可能出错的代码
result = 10 / 0
finally:
# 仅当发生 ZeroDivisionError 时执行
print("不能除以零!")4.3.3 捕获多异常(元组形式)
try:
# 可能出错的代码
value = int("abc") # 可能触发 ValueError
result = 10 / 0 # 可能触发 ZeroDivisionError
except (ValueError, ZeroDivisionError) as e:
# 任意一个异常发生时都会进入这里
print(f"发生错误: {type(e).__name__} - {e}")4.3.2 捕获多个异常(多个 except 块)
try:
# ...
pass
except FileNotFoundError:
print("文件没找到,请检查路径。")
except PermissionError:
print("权限不足,无法操作文件。")
except Exception as e:
# 捕获其他所有未被上面处理的异常 (兜底)
print(f"发生了未知错误: {e}")4.3.3 获取异常信息 (as 子句)
try:
open('missing.txt')
except IOError as e:
print(f"错误类型: {type(e)}")
print(f"错误信息: {e}")
print(f"错误参数: {e.args}")
# 在 Python 3 中,通常直接打印 e 即可看到详细信息4.3.4 完整结构:try - except - else - finally
这是最完整的语法结构,包含所有可选部分。
这是最完整的语法结构,包含所有可选部分。
try: 放置可能出错的代码。
except: 处理发生的异常。
else: 仅当 try 块没有发生任何异常时执行。通常用于放置那些依赖于 try 成功但不应该被 try 包裹的代码(避免捕获不该捕获的错误)。
finally: 无论是否发生异常,最后都会执行。通常用于资源清理(关闭文件、断开数据库连接等)
def divide_and_write(a, b, filename):
try:
result = a / b # 风险代码 1
except ZeroDivisionError:
print("除数不能为 0")
return
else:
# 只有除法成功才执行这里
print(f"计算结果: {result}")
try:
with open(filename, 'w') as f:
f.write(str(result)) # 风险代码 2 (如果在 try 里,会被上面的 except 捕获,这通常不是我们想要的)
except IOError:
print("写入文件失败")
finally:
# 无论成功、除法错误还是写入错误,都会执行
print("操作结束,进行清理工作。")
# 调用示例
divide_and_write(10, 2, 'output.txt')4.4 异常堆栈
需要用到traceback,看起来有点怪
4.4.1 简单打印
import traceback
try:
1 / 0
except Exception:
# 自动打印当前异常的完整堆栈到 stderr
traceback.print_exc()4.4.2 获取堆栈为字符串
如果你不想直接打印到屏幕,而是想记录到日志文件、发送到网络或存入数据库,使用此方法。它返回包含堆栈信息的字符串
import traceback
import logging
logging.basicConfig(level=logging.ERROR)
try:
raise ValueError("某个数据错误")
except Exception:
# 获取堆栈字符串
error_msg = traceback.format_exc()
# 写入日志
logging.error(f"发生异常:\n{error_msg}")
# 或者存入变量用于后续处理
print(f"捕获到的堆栈信息:\n{error_msg}")4.4.3 打印特定异常对象
import traceback
import sys
try:
int("abc")
except Exception as e:
exc_type, exc_value, exc_tb = sys.exc_info()
# 手动传入异常信息进行打印
traceback.print_exception(exc_type, exc_value, exc_tb)
# 或者在 Python 3.10+ 可以直接传 exception 对象 (部分版本支持)
# traceback.print_exception(e) 4.4.4 在程序崩溃时打印
import traceback
# 模拟一个未捕获的异常流程(通常在 IDE 或交互模式下有用)
# 注意:如果在 try-except 外部运行此代码,程序会先崩溃,这行可能执行不到
# 此函数主要用于调试已发生的未处理异常
try:
raise RuntimeError("测试错误")
except:
pass # 吞掉异常,但保留现场
# 打印刚才发生的最后一个异常
traceback.print_last()4.4.5 限制栈深度
import traceback
try:
def a(): b()
def b(): c()
def c(): 1/0
a()
except:
# 只打印最后 2 层堆栈
traceback.print_exc(limit=2)4.4.6 提取栈摘要
import traceback
import sys
try:
1 / 0
except:
tb_list = traceback.extract_tb(sys.exc_info()[2])
print("自定义格式的堆栈摘要:")
for frame in tb_list:
print(f"文件: {frame.filename}, 行号: {frame.lineno}, 函数: {frame.name}, 代码: {frame.line}")4.5 异常触发
raise 是 Python 中用于主动触发异常的关键字。它允许你在检测到错误条件、无效输入或特定业务逻辑失败时,中断当前程序流程并抛出异常
4.5.1 基础用法
抛出一个新的异常实例
# 语法:raise ExceptionType("错误消息")
def set_age(age):
if age < 0:
# 抛出一个 ValueError,提示年龄不能为负
raise ValueError("年龄不能是负数!")
if age > 150:
# 抛出一个自定义消息的 ValueError
raise ValueError(f"年龄 {age} 超出了合理范围 (0-150)。")
print(f"年龄设置成功: {age}")
# 调用
try:
set_age(-5)
except ValueError as e:
print(f"捕获到错误: {e}")4.5.2 重新抛出当前异常
raise 不带参数
def process_data(data):
try:
result = 10 / data
return result
except ZeroDivisionError:
print("日志:检测到除以零错误,正在记录...")
# 记录完日志后,将异常再次抛给上层调用者
raise # 等价于 raise ZeroDivisionError(...) (保留原始堆栈)
try:
process_data(0)
except ZeroDivisionError:
print("主程序:接收到下层传来的除零错误,程序终止或降级处理。")4.5.3 异常链
raise ... from ... (Python 3+)
class DatabaseConnectionError(Exception):
pass
class ServiceUnavailableError(Exception):
pass
def connect_to_db():
try:
# 模拟底层错误
raise FileNotFoundError("配置文件丢失")
except FileNotFoundError as e:
# 抛出一个新的业务异常,但指明是由 e 引起的
raise ServiceUnavailableError("数据库服务启动失败") from e
try:
connect_to_db()
except ServiceUnavailableError as e:
print(f"业务错误: {e}")
# 访问原始异常
print(f"根本原因: {e.__cause__}")
tip='''
业务错误: 数据库服务启动失败
根本原因: 配置文件丢失
'''4.5.4 错误用法
| 写法 | 行为 | 堆栈跟踪 (Traceback) | 推荐场景 |
|---|---|---|---|
raise |
重新抛出当前异常 | 保留原始位置 (指向最初出错的那一行) | ✅ 推荐。用于透传异常。 |
raise e |
抛出变量 e 代表的异常 |
重置位置 (指向 raise e 这一行,丢失原始出错行号) |
❌ 不推荐。除非你故意想隐藏原始出错位置(极少见)。 |
4.5.5 自定义异常
# 定义自定义异常
class InsufficientFundsError(Exception):
"""余额不足异常"""
def __init__(self, balance, amount):
super().__init__(f"余额不足: 当前余额 {balance}, 需要 {amount}")
self.balance = balance
self.amount = amount
def withdraw(balance, amount):
if amount > balance:
# 抛出自定义异常,携带更多上下文信息
raise InsufficientFundsError(balance, amount)
return balance - amount
try:
withdraw(100, 200)
except InsufficientFundsError as e:
print(e) # 输出: 余额不足: 当前余额 100, 需要 200
print(f"差额: {e.amount - e.balance}")
tip='''
余额不足: 当前余额 100, 需要 200
差额: 100
'''4.5.6 常见应用场景总结
1 参数验证:函数入口处检查参数类型、范围、格式,不合法则 raise ValueError 或 TypeError。
2 状态检查:对象处于无效状态时(如文件未打开却尝试读取),raise RuntimeError。
3 抽象方法实现:在基类中定义方法,强制子类重写,否则 raise NotImplementedError
class Animal:
def speak(self):
raise NotImplementedError("子类必须实现 speak 方法")4.6 断言
assert(断言)是 Python 中用于调试和内部逻辑检查的关键字。它的核心作用是:“如果这个条件为假(False),程序就立刻崩溃并报错”,一般是调试时使用,或者单元测试中。Python 解释器有一个优化模式(Optimized Mode)。当你使用 -O (大写 O) 或 -OO 标志运行脚本时,所有的 assert 语句都会被忽略(相当于被删除了)。
4.6.1 assert vs except
| 特性 | assert (断言) |
raise / try...except (异常处理) |
|---|---|---|
| 目的 | 调试、检查代码逻辑假设 (Sanity Check)。 | 错误处理、应对用户输入、网络故障、文件缺失等。 |
| 生产环境 | 可以被禁用 (使用 -O 优化标志运行 Python 时,所有 assert 会被移除)。 |
永远生效,无论是否优化。 |
| 副作用 | 断言表达式中不能包含必要的业务逻辑副作用。 | 可以包含任何逻辑。 |
| 适用场景 | “这种情况理论上绝不应该发生,如果发生了说明代码有 Bug”。 | “这种情况可能会发生(如用户输错密码),我们需要优雅地处理”。 |
4.6.2 基本语法
assert condition, "错误消息"condition: 一个表达式,结果应为 True。"错误消息" (可选): 当 cond
ition 为 False 时,显示给用户的提示信息。
执行逻辑:
1 如果 condition 为 True:程序继续正常运行,无任何输出。
2 如果 condition 为 False:程序立即中断,抛出 AssertionError,并显示可选的错误消息
age = -5
# 如果 age < 0 为 False (即 age >= 0),则通过
# 如果 age < 0 为 True (即 age 是负数),则断言失败 -> 实际上我们要检查的是 age >= 0
assert age >= 0, "年龄不能是负数!"
print("年龄检查通过")
# 如果 age = -5,上面这行不会执行,直接报错:
# AssertionError: 年龄不能是负数!5 函数
定义函数的方式非常灵活,从最基础的 def 到高级的匿名函数、装饰器甚至类型提示,共有多种形态。大型正规程序最好都使用面向对象方法,不要使用函数。
5.1 函数定义
5.1.1 基本定义方式
def function_name(arg1, arg2):
"""文档字符串 (Docstring)"""
return arg1 + arg25.1.2 嵌套定义
def funA(arg1, arg2):
"""文档字符串 (Docstring)"""
def funB():
print("call B")
funB()
print("call A")
return arg1 + arg2
sum = funA(1,2)
#funB() 不可直接调用
print(sum)5.1.3 lambda定义
# 语法: lambda 参数: 表达式
add = lambda x, y: x + y
print(add(1,2))
# 常用场景:排序
data = [(1, 'b'), (3, 'a'), (2, 'c')]
data.sort(key=lambda x: x[1]) # 按元组第二个元素排序5.2 函数属性
| 属性名 | 类型 | 描述 | 是否可写 |
|---|---|---|---|
__name__ |
str |
函数的名称。 | ✅ 可写 |
__doc__ |
str |
函数的文档字符串(Docstring)。如果没有文档,则为 None。 |
✅ 可写 |
__module__ |
str |
函数定义的模块名称(例如 '__main__' 或 'my_module')。 |
✅ 可写 |
__qualname__ |
str |
函数的限定名称(Qualified Name)。对于嵌套函数或类方法,它包含路径(如 OuterClass.method 或 outer.<locals>.inner)。Python 3.3+ 引入。 |
✅ 可写 |
__defaults__ |
tuple |
包含函数位置参数的默认值元组。如果没有默认值,则为 None。 |
✅ 可写 |
__kwdefaults__ |
dict |
包含函数关键字_only 参数的默认值字典。如果没有,则为 None。Python 3+。 |
✅ 可写 |
__code__ |
code object |
函数的代码对象,包含编译后的字节码、变量名、常量等底层信息。 | ❌ 只读 (但可替换) |
__globals__ |
dict |
函数定义时所在的全局命名空间字典的引用。 | ❌ 只读 (引用不可变,内容可变) |
__closure__ |
tuple |
包含闭包单元(cell objects)的元组,用于访问自由变量。如果函数不是闭包,则为 None。 |
❌ 只读 |
__annotations__ |
dict |
函数的参数和返回值类型注解字典。Python 3+。 | ✅ 可写 |
__dict__ |
dict |
用于存储自定义属性的命名空间字典。 | ✅ 可写 |
__wrapped__ |
function |
如果被 @wraps 装饰器包装过,该属性指向被包装的原始函数。Python 3.2+ (functools)。 |
✅ 可写 |
5.2.1 属性查看
def test(): pass
#添加属性,这个很容易乱搞,如果是对象的话更糟糕,每次脚本语言都喜欢用灵活来开拓
#实际上语言的核心就是短、频繁、快,维护性不是脚本语言最关心的问题,只是后面
#用得多了,发现不好维护,就各种查缺补漏,搞得不论不类的
test.xx = 'fff'
print(f'text.xx={test.xx}')
print(dir(test))
# 输出包含: ['__annotations__', '__call__', '__code__',5.2.2 基本信息
def my_func():
"""这是一个测试函数"""
pass
print(my_func.__name__) # 'my_func'
print(my_func.__doc__) # '这是一个测试函数'
print(my_func.__module__) # '__main__' (如果在脚本直接运行)
# 嵌套函数示例
def outer():
def inner():
pass
return inner
f = outer()
print(f.__name__) # 'inner'
print(f.__qualname__) # 'outer.<locals>.inner' (显示了层级关系)5.2.3 默认参数
#* 是个分割符号,强制后面的是关键字参数,又出了个奇葩
def demo(a, b=10, *, c=20):
pass
print(demo.__defaults__) # (10,) -> 对应 b
print(demo.__kwdefaults__) # {'c': 20} -> 对应 c
#demo() 要报错
demo(1)
demo(1,5)
#demo(1,5,9) 要报错
demo(1,5,c=9)5.2.4 代码对象
def demo(a, b=10,c=20):
pass
code_obj = demo.__code__
print(code_obj.co_argcount) # 参数个数 (不含 *args, **kwargs)
print(code_obj.co_varnames) # 局部变量名元组 ('a', 'b', 'c')
print(code_obj.co_filename) # 文件路径
print(code_obj.co_firstlineno) # 函数定义的行号
print(code_obj.co_name) # 函数名 (同 __name__)
tip='''
3
('a', 'b', 'c')
F:\Users\admin2\AppData\Local\Temp\ipykernel_14176\3873755586.py
1
demo
'''5.2.5 闭包
def make_adder(n):
def adder(x):
return x + n # 引用了外部变量 n
return adder
func = make_adder(5)
print(func.__closure__)
# (<cell at 0x...: int object at 0x...>,)
print(func.__closure__[0].cell_contents) # 5 (获取闭包变量的值)5.2.6 全局空间
global_var = 100
def check_global():
return global_var
print(check_global.__globals__['global_var']) # 100
# 甚至可以动态修改:
check_global.__globals__['global_var'] = 200
print(check_global()) # 200
print(global_var) # 2005.2.7 自定义属性
def counter():
count = 0
def inner():
nonlocal count
count += 1
return count
return inner
fn = counter()
# 给函数动态添加属性
fn.description = "这是一个计数器函数"
fn.version = "1.0.0"
fn.call_count = 0
print(fn.description) # "这是一个计数器函数"
print(fn.__dict__) # {'description': '...', 'version': '...', 'call_count': 0}5.2.8 特殊属性:__wrapped__
from functools import wraps
def my_decorator(f):
@wraps(f) # 自动设置 f.__wrapped__ = original_f
def wrapper(*args, **kwargs):
return f(*args, **kwargs)
return wrapper
# @my_decorator
def original_func():
"""Original Doc"""
pass
print(original_func.__name__) # 'original_func' (被 wraps 修复了)
print(original_func.__wrapped__) # <function original_func at ...> (原始函数)5.3 函数传参规则
5.3.1 位置传参
def greet(name, age):
print(f"{name} is {age}")
greet("Alice", 25) # name="Alice", age=255.3.2 关键字传参
通过 参数名=值 的形式传递,顺序可以打乱。
greet(age=25, name="Alice") # 效果同上5.3.3 序列解包传参
def greet(name, age):
print(f"{name} is {age}")
params = ["Bob", 30]
greet(*params) # 等价于 greet("Bob", 30)
paramsb = ("Bob", 30)
greet(*paramsb) # 等价于 greet("Bob", 30)5.3.4 字典传参
params_dict = {"name": "Charlie", "age": 35}
greet(**params_dict) # 等价于 greet(name="Charlie", age=35)5.3.5 参数匹配优先级
这点容易出问题
当多种传参方式混合使用时,Python 解释器按以下顺序进行匹配:
1 位置参数 优先匹配 位置形参。
2 关键字参数 精确匹配对应的形参名。
3 *args 收集剩余未匹配的 位置参数 (打包成元组)。
4 **kwargs 收集剩余未匹配的 关键字参数 (打包成字典)。
冲突检测:
1 如果同一个参数既通过位置传递,又通过关键字传递,会报错 TypeError: got multiple values for argument 'x'。
2如果缺少必填的位置参数或命名关键字参数,会报错 TypeError: missing required argument。
5.3.6 默认参数陷阱
❌ 错误写法:
def add_item(item, box=[]): # box 只在定义时创建一次
box.append(item)
return box
print(add_item(1)) # [1]
print(add_item(2)) # [1, 2] <-- 意外!累积了上一次的值✅ 正确写法
def add_item(item, box=None):
if box is None:
box = [] # 每次调用都创建新列表
box.append(item)
return box5.3.7 强制关键字参数
如果你希望某些参数必须使用关键字传参(防止位置传参导致的歧义),可以将它们放在 *args 之后,或者单独放一个 *。
# 场景:create_user 函数,role 必须明确指定
def create_user(name, *, role, active=True):
pass
# create_user("Alice", "admin") ❌ 报错:role 必须用关键字
create_user("Alice", role="admin") # ✅ 正确
create_user("Alice", role="admin", active=False) # ✅ 正确5.4 函数式编程
函数式编程中主要是使用lambda表达式,函数式编程(Functional Programming)主要依赖一些内置的高阶函数以及 functools 和 operator 标准库模块。虽然 Python 是多范式语言,但这些工具能帮助你写出更简洁、声明式的代码
5.4.1 核心内置高阶函数
这些函数直接内置在 Python 解释器中,无需导入即可使用(reduce 除外,和老版本有些区别)。
| 函数名 | 说明 | 返回值类型 (Python 3) | 示例用途 |
|---|---|---|---|
map(function, iterable, ...) |
将指定函数应用于可迭代对象的每个元素,返回结果。 | map 对象 (迭代器) |
批量转换数据(如将所有数字平方)。 |
filter(function, iterable) |
使用函数过滤序列,仅保留使函数返回 True 的元素。 |
filter 对象 (迭代器) |
筛选偶数、非空字符串等。 |
zip(*iterables) |
将多个可迭代对象打包成元组迭代器。常用于并行遍历。 | zip 对象 (迭代器) |
同时遍历两个列表。 |
enumerate(iterable, start=0) |
将一个可遍历的数据对象组合为一个索引序列,同时列出数据和下标。 | enumerate 对象 |
需要在循环中获取索引时。 |
sorted(iterable, *, key=None, reverse=False) |
对所有可迭代对象进行排序并返回新列表(不修改原对象)。 | list |
函数式风格的排序操作。 |
reversed(seq) |
返回一个反向迭代器。 | reversed 对象 |
反向遍历序列。 |
5.4.2 functools 模块中的关键函数
| 函数名 | 说明 | 示例用途 |
|---|---|---|
functools.reduce(function, iterable[, initializer]) |
对一个序列进行累积操作(如求和、求积)。它将函数作用于前两个元素,然后将结果与下一个元素继续运算,直到序列结束。Python 3 已将其从内置移除,移至此模块。 | 计算列表所有元素的乘积、扁平化嵌套列表。 |
functools.partial(func, *args, kwargs) |
偏函数应用。固定函数的某些参数,生成一个新的函数。 | 创建一个专门用于转换二进制到整数的函数 int2 = partial(int, base=2)。 |
functools.lru_cache(maxsize=128, typed=False) |
最近最少使用缓存装饰器。用于优化递归或重复计算的函数。 | 优化斐波那契数列递归计算。 |
functools.total_ordering |
类装饰器。只要定义了 __eq__ 和另一个比较方法(如 __lt__),它会自动生成其余的比较方法。 |
简化自定义类的比较逻辑。 |
5.4.3 operator 模块中的常用函数
| 函数名 | 对应操作 | 示例 |
|---|---|---|
operator.add(a, b) |
a + b |
reduce(operator.add, list) (求和) |
operator.mul(a, b) |
a * b |
reduce(operator.mul, list) (求积) |
operator.itemgetter(n) |
获取对象的第 n 个元素 | sorted(list_of_tuples, key=itemgetter(1)) |
operator.attrgetter('name') |
获取对象的属性 | 按对象属性排序 |
operator.not_, operator.and_, operator.or_ |
逻辑非、与、或 | 在 filter 中进行复杂逻辑判断 |
5.4.4 简单示例与选择
from functools import reduce
import operator
numbers = [1, 2, 3, 4, 5]
# 1. map: 将所有数字平方
squared = list(map(lambda x: x**2, numbers))
# 或者使用 operator (如果操作符支持),但平方通常用 lambda 或自定义函数
# squared = list(map(lambda x: operator.pow(x, 2), numbers))
# 2. filter: 筛选出偶数
evens = list(filter(lambda x: x % 2 == 0, numbers))
# 3. reduce: 计算所有数字的乘积 (需导入 functools)
# Python 3 中必须从 functools 导入
product = reduce(operator.mul, numbers, 1)
# 4. 组合使用: 先筛选偶数,再平方,最后求和
result = reduce(operator.add, map(lambda x: x**2, filter(lambda x: x % 2 == 0, numbers)), 0)
print(f"原列表: {numbers}")
print(f"平方后: {squared}")
print(f"偶数: {evens}")
print(f"乘积: {product}")
print(f"偶数平方和: {result}")首选列表推导式:在现代 Python 开发中,对于简单的映射和过滤,列表推导式(List Comprehensions)通常比 map 和 filter 更具可读性。
1 map 替代: [x**2 for x in numbers]
2 filter 替代: [x for x in numbers if x % 2 == 0]
何时使用函数式工具:
1 当需要链式调用多个操作时(如 map -> filter -> reduce)。
2 当处理大型数据流且希望利用迭代器的惰性求值特性(节省内存)时。
3 当使用 partial 进行参数固化或 lru_cache 进行性能优化时。
4 当配合 operator 模块使代码更简洁时(如 key=operator.itemgetter(1))。
5.5 偏函数
偏函数(Partial Function) 是指通过固定原函数的某些参数,从而生成一个新的、参数更少的函数的技术。Python 实现这一功能的核心工具是标准库 functools 中的 partial 函数。
5.5.1 基本用法
from functools import partial
# 定义一个普通函数
def multiply(x, y, z):
return x * y * z
# 创建一个偏函数:固定 x=2, y=3
# 新函数 double_triple 只需要接收 z
double_triple = partial(multiply, 2, 3)
#其实类似下面写法
def double_triple2(z):
return multiply(2,3,z)
# 调用偏函数
result = double_triple(4)
result2 = double_triple2(4)
# 等价于 multiply(2, 3, 4)
# 计算过程: 2 * 3 * 4 = 24
print(result) # 输出: 24
print(result2) # 输出: 245.5.2 参数匹配规则
当你调用 partial(func, *args, **kwargs) 时:
1 *args (位置参数):会依次填充原函数最左边的参数。你不能跳过前面的参数直接用位置参数去绑定后面的参数。
2 **kwargs (关键字参数):可以通过参数名直接绑定原函数中的任何参数,无论它在前还是在后
def demo_func(a, b, c, d):
return f"a={a}, b={b}, c={c}, d={d}"
# 这样写会把 10 赋值给 a,而不是 d!
# p = partial(demo_func, 10)
# 调用 p(1, 2, 3) -> a=10, b=1, c=2, d=3 (完全错了)
from functools import partial
# 使用关键字参数固定 d=100
p = partial(demo_func, d=100)
# 调用时只需提供 a, b, c
result = p(1, 2, 3)
print(result)
# 输出: a=1, b=2, c=3, d=100| 绑定方式 | 能否绑定后面的参数? | 说明 |
|---|---|---|
位置参数 (partial(f, val)) |
不能 | 必须从左到右依次填充,无法跳过。 |
关键字参数 (partial(f, param=val)) |
能 | 可以指定任意参数名进行绑定,无论位置前后。 |
5.6 高阶函数
高阶函数(Higher-Order Function) 是指满足以下任一条件的函数:
1 接收一个或多个函数作为参数。
2 返回一个函数作为结果
5.6.1 基本示例
def process_data(data_list, operation_func):
"""
高阶函数:接收一个列表和一个操作函数
"""
result = []
for item in data_list:
# 调用传入的函数
transformed = operation_func(item)
result.append(transformed)
return result
# 定义具体的操作函数
def add_10(x):
return x + 10
def square(x):
return x * x
numbers = [1, 2, 3]
# 传入不同的函数,实现不同的行为
print(process_data(numbers, add_10)) # 输出: [11, 12, 13]
print(process_data(numbers, square)) # 输出: [1, 4, 9]
# 甚至可以直接传 lambda
print(process_data(numbers, lambda x: x * 3)) # 输出: [3, 6, 9]5.6.2 装饰器
装饰器(Decorator) 是 Python 中的一种高阶函数。
输入:它接收一个函数(或类)作为参数。
输出:它返回一个新的函数(通常是对原函数的增强或包装)。
目的:在不修改原函数源代码、不改变原函数调用方式的前提下,为函数动态地添加额外功能(如日志记录、性能测试、事务处理、权限校验等)
这应该就是代理模式
@my_decorator
def my_func():
pass
#等价于
def my_func():
pass
my_func = my_decorator(my_func)5.6.2.1 无参装饰器
# 1. 定义装饰器
def add_greeting(func):
"""
这是一个简单的装饰器:
在调用原函数前,先打印一句问候语。
"""
# 内部函数(闭包),用于包裹原函数
def wrapper():
print("👋 你好!我是装饰器添加的问候:")
# 执行原函数
func()
print("👋 再见!")
# 返回包装后的新函数
return wrapper
# 2. 使用装饰器 (语法糖写法)
@add_greeting
def say_hello():
print(" >>> 这是原函数在说:Hello World! <<<")
# 3. 调用函数
say_hello()5.6.2.2 带参数函数装饰器
import functools
def logger(func):
@functools.wraps(func) # 保留原函数名,不然就会被wrapper替换
def wrapper(*args, **kwargs): # 接收任意参数
print(f"[日志] 正在调用函数: {func.__name__}")
result = func(*args, **kwargs) # 将参数透传给原函数
print(f"[日志] 函数执行完毕,返回值: {result}")
return result # 返回原函数的结果
return wrapper
@logger
def add(a, b):
return a + b
add(3, 5)
#加了这个 @functools.wraps(func) 输出是add,不加就是wrapper
print(f"函数名: {add.__name__}")
output='''
[日志] 正在调用函数: add
[日志] 函数执行完毕,返回值: 8
函数名: add
'''实际场景中的灾难
场景 A:日志系统 (Logging)
很多日志库会自动记录 func.__name__。如果不加 wraps,所有被装饰的函数在日志里都会显示为 wrapper,你根本不知道是哪个业务函数出错了。
import logging
logging.warning(f"{bad_login.__name__} 执行失败")
# 日志输出: [WARNING] wrapper 执行失败 <-- 运维人员一脸懵逼:哪个 wrapper?场景 B:Web 框架路由 (如 Flask)
在 Flask 中,路由通常基于函数名生成端点名称。如果名字都变成了 wrapper,可能会导致路由冲突或调试困难。
# 伪代码示例
# @app.route('/login')
# def login(): ...
# 如果装饰器没加 wraps,Flask 内部注册的名字可能是 'wrapper',
# 导致 url_for('login') 找不到对应的端点,或者多个路由都叫 'wrapper' 引发冲突。场景 C:序列化 (Pickle)
如果你尝试保存(pickle)这个函数,可能会失败,因为 pickle 默认通过 模块名.函数名 来查找函数。如果名字变成了 wrapper,而模块里没有叫 wrapper 的全局函数(因为它只是局部变量),反序列化时会报错。
import pickle
try:
data = pickle.dumps(bad_login)
# 尝试加载时可能报错:
# pickle.UnpicklingError: Can't get attribute 'wrapper' on <module '__main__' ...>
except Exception as e:
print(f"序列化失败: {e}")| 特性 | 不加 @functools.wraps |
加上 @functools.wraps |
|---|---|---|
__name__ |
'wrapper' (装饰器内部函数名) |
'original_func' (原函数名) |
__doc__ |
wrapper 的文档 (或 None) |
原函数的文档字符串 |
__module__ |
当前模块 (通常没问题) | 原函数定义的模块 |
help() 显示 |
显示包装器信息,误导用户 | 显示原函数信息,清晰准确 |
| 日志/监控 | 所有函数名混淆为 wrapper |
保留真实业务函数名 |
| 调试体验 | 堆栈跟踪难以阅读 | 堆栈跟踪清晰 |
| 兼容性 | 可能导致序列化或框架集成失败 |
兼容性好,符合 Python 规范 |
5.6.2.3 带参装饰器
要实现带参数的装饰器,你需要三层函数嵌套:
1 最外层:接收装饰器的参数(如 repeat_times=3)。
2 中间层:接收被装饰的函数对象(func)。
3 最内层 (wrapper):接收被装饰函数的调用参数(*args, **kwargs),执行逻辑并返回结果。
这玩意嵌套有点深少用,嵌套深的代码都有点坏的味道,模板如下
要实现带参数的装饰器,你需要三层函数嵌套:
最外层:接收装饰器的参数(如 repeat_times=3)。
中间层:接收被装饰的函数对象(func)。
最内层 (wrapper):接收被装饰函数的调用参数(*args, **kwargs),执行逻辑并返回结果。实例
import functools
# 1. 定义带参数的装饰器
def add_title(title_text):
"""
title_text: 你想要添加的标题字符串
"""
# 第一层:接收装饰器的参数 (title_text)
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 2. 执行额外逻辑:先打印标题
print(f"=== {title_text} ===")
# 3. 执行原函数
return func(*args, **kwargs)
return wrapper
return decorator
# --- 使用示例 ---
# 使用装饰器,传入参数 "用户登录"
@add_title("用户登录")
def login():
print("正在验证用户名和密码...")
# 使用装饰器,传入参数 "系统设置"
@add_title("系统设置")
def settings():
print("正在加载配置项...")
# --- 调用 ---
login()
print("-" * 20)
settings()5.6.2.4 装饰器堆叠
当你在一个函数上应用多个装饰器时:
加载顺序(从上到下):Python 解释器会从下往上依次应用装饰器。
即:@decorator_A 在最上面,@decorator_B 在下面。
实际执行逻辑是:func = decorator_A(decorator_B(func))。
离函数最近的那个装饰器先被应用。
调用顺序(从外到内):当你调用函数时,执行流程像剥洋葱一样,从最外层(最上面的装饰器)开始,一层层向内,直到执行原函数,然后再一层层返回。
这玩意有先后顺序,不能随意调换,非常危险,要注意,谨慎使用,执行过程有点拦截器链
import time
import functools
# --- 装饰器 1: 性能计时 (最内层) ---
def timing(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
start = time.time()
print(f"timing start [计时] {func.__name__}")
result = func(*args, **kwargs) # 执行下一层
end = time.time()
print(f"timing end [计时] {func.__name__} 耗时: {end - start:.4f} 秒")
return result
return wrapper
# --- 装饰器 2: 日志记录 (中间层) ---
def log_execution(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
print(f"log_execution start [日志] >>> 开始执行: {func.__name__}")
result = func(*args, **kwargs) # 执行下一层
print(f"log_execution end [日志] <<< 结束执行: {func.__name__}")
return result
return wrapper
# --- 装饰器 3: 权限验证 (最外层) ---
def login_required(func):
@functools.wraps(func)
def wrapper(*args, **kwargs):
# 模拟全局登录状态
is_logged_in = True
if not is_logged_in:
return "login_required [错误] 请先登录!"
print("login_required start [权限] 用户已验证通过。")
result = func(*args, **kwargs) # 执行下一层
print("login_required end [权限] 用户已验证通过。")
return result
return wrapper
# --- 应用多个装饰器 ---
# 等价于: process_order = login_required(log_execution(timing(process_order)))
@login_required
@log_execution
@timing
def process_order(order_id):
print(f"process_order [业务] 正在处理订单 {order_id}...")
time.sleep(0.5) # 模拟耗时操作
return "订单处理成功"
# --- 调用 ---
print("=== 开始调用 ===")
result = process_order("ORD-2026-001")
print(f"最终结果: {result}")
output='''
=== 开始调用 ===
login_required start [权限] 用户已验证通过。
log_execution start [日志] >>> 开始执行: process_order
timing start [计时] process_order
process_order [业务] 正在处理订单 ORD-2026-001...
timing end [计时] process_order 耗时: 0.5001 秒
log_execution end [日志] <<< 结束执行: process_order
login_required end [权限] 用户已验证通过。
最终结果: 订单处理成功
'''5.7 变量作用域
名称空间 (Namespace) 本质上是一个从名称到对象的映射字典。简单来说,它决定了你在代码的某个特定位置看到的变量名 x 到底指向内存中的哪个对象。名称空间有全局,内建和局部名称空间。名称空间就是为了找到对对应对象,和作用域有很大关系。函数,模块,对象等都可以作为名称空间隔离变量。
在 Python 中,变量的作用域(Scope)决定了变量在代码中的哪些部分是可见和可访问的。
当你在代码中使用一个变量名时,Python 遵循 LEGB 规则 来查找变量:
L (Local):局部作用域。当前函数内部定义的变量。
E (Enclosing):嵌套作用域。外层函数的局部作用域(即闭包环境)。
G (Global):全局作用域。当前模块(文件)顶层定义的变量。
B (Built-in):内置作用域。Python 内置模块(如 len, print, Exception)中的名称。
查找原则:一旦在某一层找到变量,查找立即停止。如果在所有层都找不到,则抛出 NameError。
作用域的效果不同版本可能在一些场景不太一样,不确定的化需要自己测试一下
5.7.1 局部变量
def my_func():
x = 10 # Local 变量
print(x)
my_func() # 输出: 10
# print(x) # 报错: NameError: name 'x' is not defined5.7.2 全局变量
在文件顶层定义的变量,或者在函数内使用 global 关键字声明的变量
y = "yGlobal" # Global 变量
x = "xGlobal"
def test_global():
#这里覆盖了全局变量作用域,x式函数内部新的独立变量
x="xLocal"
# 这里读取的是 Global 变量 y 要是使用语句提前声明,看起来有点怪怪的
#还不能写成一行。比如global y = 'yyyGlobal'
global y
y='yyyGlobal'
print(f"test_global:x={x},y={y}")
print(f"bufore call out:x={x},y={y}")
test_global()
print(f"after call out:x={x},y={y}")
tip='''
bufore call out:x=xGlobal,y=yGlobal
test_global:x=xLocal,y=yyyGlobal
after call out:x=xGlobal,y=yyyGlobal
'''5.7.3 闭包作用域
闭包作用域有点不同于全局和局部,所以需要单独对待
x='globalX'
def outer():
num = 10 # Enclosing
def inner():
nonlocal num # 声明我们要修改的是外层的 num
num += 5
global x
x='innerGlobal'
print(f"Inner: num={num},x={x}")
inner()
print(f"Outer: {num},x={x}") # 这里的 num 也被修改了
print(f"before: x={x}")
outer()
print(f"after: x={x}")
output='''
before: x=globalX
Inner: num=15,x=innerGlobal
Outer: 15,x=innerGlobal
after: x=innerGlobal
'''5.7.4 常见陷阱
陷阱1:延迟绑定与循环中的闭包
x=5
def test():
y=10
bar=lambda : x+y
print(bar())
y=11
print(bar())
test() # 输出 15 16 符合预期,早期版本y重新赋值后不一定生效,奇葩问题很多
funcs = []
for i in range(3):
# 这里的 i 是自由变量,引用的是全局/外层作用域的 i
funcs.append(lambda: i)
# 调用时,i 已经是 2 了
print([f() for f in funcs])
# 输出: [2, 2, 2] (期望可能是 [0, 1, 2])
# ✅ 修正方法:利用默认参数捕获当前值
funcs_fixed = []
for i in range(3):
#这问题有点像早期版本的问题,看来式没有处理彻底,js也有类似问题,喜欢拿来考人,防不胜防
funcs_fixed.append(lambda x=i: x)
print([f() for f in funcs_fixed])
# 输出: [0, 1, 2]陷阱2:可变对象 vs 不可变对象
不可变对象(整数、字符串、元组):在函数内修改(如 x += 1)通常需要 global 或 nonlocal,因为这实际上是重新赋值。
可变对象(列表、字典):可以在不声明 global 的情况下修改其内容,因为变量名本身没有变,只是对象内部状态变了。
my_list = [1, 2]
def modify_list():
# 不需要 global,因为没有重新绑定 my_list 这个名字
my_list.append(3)
# my_list = [4] <-- 这行需要 global,因为是重新赋值
modify_list()
print(my_list) # 输出: [1, 2, 3]6 模块
python模块是一个深坑,如果不是研究学习、需要做好工程化处理。
6.1 定义
模块(Module) 是一个包含 Python 定义和语句的文件。文件的名称就是模块名加上 .py 后缀。模块允许你将代码逻辑组织成独立的文件,以便在其他程序中复用、维护和管理。模块这里就和python文件对应。
6.2 模块命名规范
模块命名规范是python一个比较坑的地方,这个玩意到处都是坑,有点混账。
| 类别 | ✅ 推荐 (Good) | ❌ 避免/错误 (Bad) | 原因 |
|---|---|---|---|
| 大小写 | config.py |
Config.py, CONFIG.py |
PEP 8 规定模块名全小写 |
| 分隔符 | user_auth.py |
userauth.py, user-auth.py |
下划线提高可读性;连字符非法 |
| 标准库冲突 | my_math.py |
math.py, random.py |
会覆盖标准库,导致导入错误 |
| 数字开头 | module_v2.py |
2nd_module.py |
语法错误,无法导入 |
| 包初始化 | __init__.py |
init.py |
只有双下划线版本会被识别为包入口 |
6.2.1 核心命名规则 (PEP 8)
全小写字母:模块名应全部使用小写字母。
✅ mymodule.py, utils.py, data_processor.py
❌ MyModule.py, Utils.py
下划线分隔:如果名字由多个单词组成,使用下划线 _ 分隔,以提高可读性。
✅ file_utils.py, http_client.py
❌ fileutils.py (难读), file-utils.py (非法字符), fileUtils.py (驼峰式,通常用于类名)简短且具有描述性:名字应能清晰反映模块的功能,但不要过长。
6.2.2 严格禁止的命名 (避免冲突)
这是新手最容易犯的错误。绝对不要使用 Python 标准库模块或内置函数的名字作为你的模块名,否则会导致“阴影遮蔽”(Shadowing),使标准库无法导入。
❌ 严禁使用的名字示例:
math.py (覆盖标准库 math 模块)
random.py (覆盖标准库 random 模块)
string.py (覆盖标准库 string 模块)
os.py, sys.py, json.py, datetime.py
list.py, dict.py, str.py (虽然这些不是模块文件,但也不要这样命名,容易混淆)
test.py (如果你运行 python test.py,有时会与 unittest 的测试发现机制冲突,建议命名为 test_myfeature.py)
后果示例:
如果你创建了一个名为 math.py 的文件,并在其中写 import math,Python 会导入你自己的文件而不是标准库,导致 math.sqrt() 等函数不可用,甚至引发无限递归导入错误。
6.2.3 字符限制
只能包含:小写字母 (a-z)、数字 (0-9) 和下划线 (_)。
必须以字母或下划线开头:不能以数字开头。
✅ module1.py, _private.py
❌ 1module.py
不能有特殊字符:如 - (连字符), @, $, 空格 等。
❌ my-module.py (这在导入时会报错,因为 - 会被解析为减号)
❌ my module.py
6.2.4 特殊模块名约定
__init__.py:
这是包(Package)的标识文件。如果一个目录中包含 __init__.py,Python 就会将该目录视为一个包。该文件可以为空,也可以包含包的初始化代码。
__main__.py:
允许将一个目录或 zip 文件当作脚本直接运行(例如:python my_package)。
以下划线开头 (如 _helper.py):
这是一种约定,表示该模块是“内部使用”的,不建议被外部直接导入(尽管 Python 并不强制阻止导入)。通常配合 from package import * 使用时,以下划线开头的名字不会被导出。实际上也可以通过其他方式使用,权限控制不硬核
6.2.5 操作系统兼容性考虑
大小写敏感性:
Linux/macOS 文件系统通常是大小写敏感的 (Module.py 和 module.py 是两个不同的文件)。
Windows 文件系统通常是大小写不敏感的。
最佳实践:始终使用全小写,可以避免在不同操作系统间迁移代码时出现 ImportError 或奇怪的缓存问题。
6.3 包
包(Package) 是一种组织模块(.py 文件)的方式,它允许你使用“点式命名法”(如 package.module)来构建分层级的命名空间。
6.3.1 目录结构
物理结构:包是一个目录。
- 关键标识:该目录下必须包含一个名为 __init__.py 的文件(在 Python 3.3+ 中,为了支持“命名空间包”,这个文件不再是绝对强制的,但在常规开发中,强烈建议保留它以明确这是一个普通包)。
- 作用:避免不同模块之间的命名冲突(例如 sound.effects.echo 和 image.effects.echo 可以共存)。
sound/ <-- 顶层包
__init__.py <-- 初始化文件,标志这是包
formats/ <-- 子包
__init__.py
wavread.py <-- 模块
wavwrite.py <-- 模块
aiffread.py
aiffwrite.py
effects/ <-- 子包
__init__.py
echo.py <-- 模块
surround.py
reverse.py
filters/ <-- 子包
__init__.py
equalizer.py
vocoder.py在这个结构中:
sound是主包。sound.formats和sound.effects是子包。sound.effects.echo是一个具体的模块
6.3.2 __init__.py作用
这个文件非常重要,它有两个主要功能:
1 标识作用:告诉 Python 解释器“把这个目录当作一个包来处理”,而不是普通的文件夹。
2 初始化代码:当包被导入时,这个文件中的代码会被执行。通常用于:
1 定义 __all__ 变量(控制 from package import * 时导出哪些内容)。
2 初始化包级别的全局变量。
3 简化导入(例如在 __init__.py 中导入子模块,让用户可以直接 import sound 而无需深入层级)
建议是每个包都加__init__.py,但是在高版本加了一个隐式包。可以在最顶层加一个就行了。
6.3.3 __all__
__all__ 是 Python 模块(包括 __init__.py)中的一个特殊变量(也可以在模块文件中),它是一个字符串列表。它的核心作用只有一个:控制 from module import * 的行为。
当你执行 from module import * 时:
1 如果定义了 __all__:Python 只导入 __all__ 列表中列出的名字。
2 如果没有定义 __all__:Python 会导入模块中所有不以下划线 _ 开头的名字。
# utils.py
# 1. 公开函数:用户可以直接使用
def add(a, b):
return a + b
def subtract(a, b):
return a - b
# 2. 内部辅助函数:通常以下划线开头,默认不会被 * 导入
def _internal_log(msg):
print(f"[LOG]: {msg}")
# 3. 敏感/私有功能:虽然没以下划线,但我不想让用户通过 * 导入
def delete_database():
print("⚠️ 危险操作:删除数据库!")
# ✅ 关键步骤:定义 __all__
# 只有这里列出的名字,才能被 "from utils import *" 导入
__all__ = ['add', 'subtract'] 当你执行 import * 时,有两种场景
场景 A:from my_package.utils import *
Python 读取 my_package/utils.py。
检查 utils.py 里有没有 __all__。
my_package/__init__.py 里的 __all__ 完全被无视。
场景 B:from my_package import *
Python 读取 my_package/__init__.py。
检查 __init__.py 里有没有 __all__。
子模块(如 utils.py)里的 __all__ 完全被无视(除非 __init__.py 显式地根据子模块的 __all__ 做了特殊处理,但这需要写代码,不是自动的)。
6.3.4 __main__.py
sound/
├── __init__.py # 负责包的初始化和简化导入
├── __main__.py # 👉 程序的入口点 (Entry Point)
├── player.py # 播放逻辑
└── recorder.py # 录音逻辑python -m sound
6.4 模块导入
模块导入主要有相对导入和绝对导入,相对导入需要注意验证一下是否受到执行路径影响。
绝对导入就是从最顶层包开始导入。导入时尽量避免使用*号
6.4.1 基本导入格式
| 格式 | 示例 | 说明 | 使用方式 |
|---|---|---|---|
import 模块 |
import os |
导入整个模块 | os.path.join() |
import 模块 as 别名 |
import numpy as np |
导入模块并起别名 | np.array() |
from 模块 import 成员 |
from os import path |
导入模块中的特定成员 | path.join() |
from 模块 import 成员 as 别名 |
from os import path as p |
导入成员并起别名 | p.join() |
from 模块 import * |
from os import * |
导入模块所有公共成员 | path.join() ⚠️ |
6.4.2 导入包
| 格式 | 示例 | 说明 | 使用方式 |
|---|---|---|---|
import 包 |
import my_package |
只执行 __init__.py |
my_package.xxx |
import 包.子模块 |
import my_package.utils |
导入包下的子模块 | my_package.utils.func() |
from 包 import 子模块 |
from my_package import utils |
从包导入子模块 | utils.func() |
from 包.子模块 import 成员 |
from my_package.utils import add |
从子模块导入成员 | add() |
from 包.子包 import 模块 |
from my_package.subpkg import module |
跨包子包导入 | module.func() |
默认情况下不会导入包下的模块,只会执行__init__.py
# my_package/__init__.py
print("📦 __init__.py 被执行了!")
# my_package/module_a.py
print("📄 module_a.py 被加载了!")
def func_a(): pass
# my_package/module_b.py
print("📄 module_b.py 被加载了!")
def func_b(): pass# 测试导入主程序
import my_package
# 输出:
# 📦 __init__.py 被执行了!
# (只有这一行!)
、
# 查看包的内容
print(dir(my_package))
# 输出:['__all__', '__builtins__', '__cached__', '__doc__', '__file__', ...]
# 只有 __init__.py 中定义的内容,没有 module_a, module_b
# 尝试访问子模块
my_package.module_a # ❌ AttributeError!在__init__py中加导出语句
这是个绕圈圈,很多时候应该没有必要这样搞
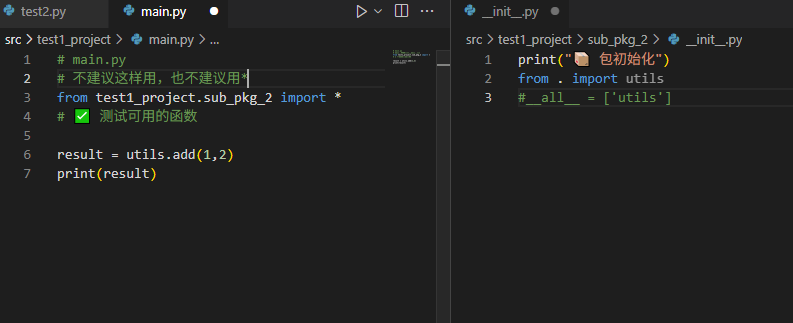
6.4.3 相对导入
相对导入都是from开头,使用相对路径
| 格式 | 示例 | 说明 | 使用场景 |
|---|---|---|---|
from . import 模块 |
from . import utils |
导入同包下的模块 | 包内部 |
from .模块 import 成员 |
from .utils import add |
导入同包模块的成员 | 包内部 |
from .. import 模块 |
from .. import config |
导入父包的模块 | 子包内部 |
from ..父包 import 模块 |
from ..parent import module |
导入指定父包的模块 | 子包内部 |
from ... 导入 |
from ...config import CFG |
导入祖父包的成员 | 深层子包 |
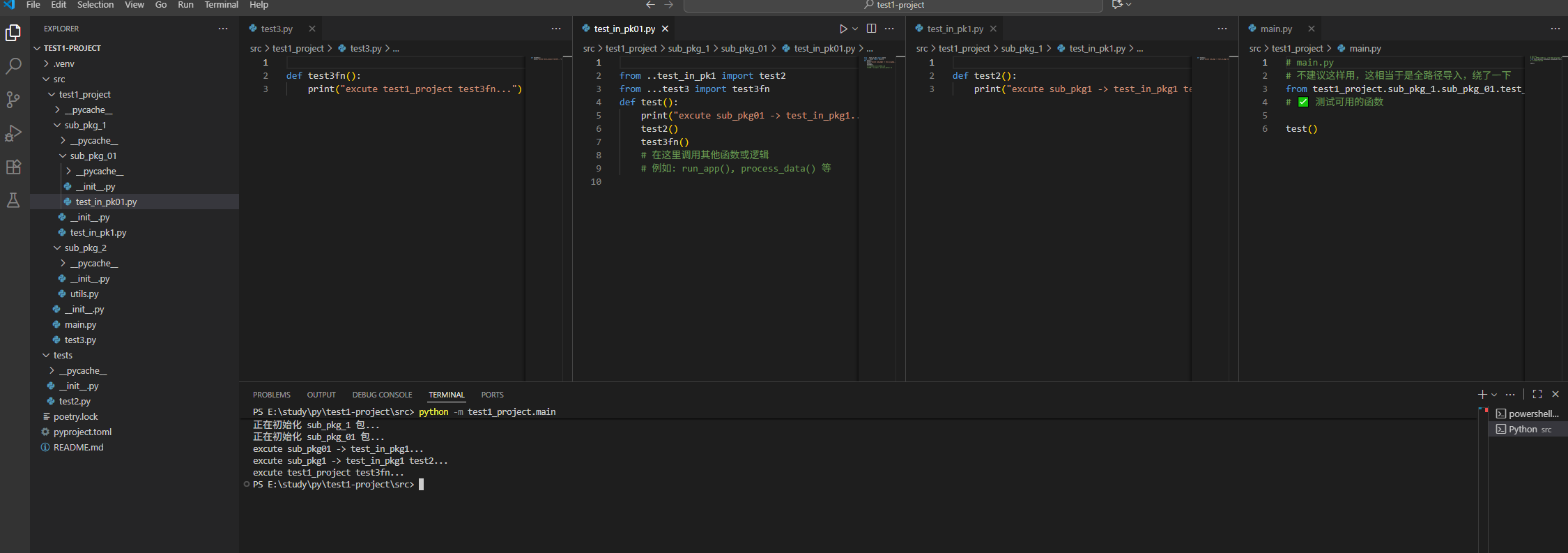
6.4.4 其他导入场景
条件导入格式
| 格式 | 示例 | 说明 |
|---|---|---|
| 尝试导入 | try: import xxx except ImportError: ... |
可选依赖 |
| 版本判断导入 | if sys.version_info >= (3, 8): import xxx |
版本兼容 |
| 平台判断导入 | if platform.system() == 'Windows': import xxx |
跨平台 |
延迟导入
| 格式 | 示例 | 说明 |
|---|---|---|
| 函数内导入 | def func(): import xxx |
按需加载 |
| 条件分支导入 | if condition: import xxx |
减少启动时间 |
importlib 动态导入 |
importlib.import_module('xxx') |
运行时导入 |
6.4.5 名称隔离
# # main.py
# # 不建议这样用,这相当于是全路径导入,绕了一下
# from test1_project.sub_pkg_1.sub_pkg_01.test_in_pk01 import show,f
# # ✅ 测试可用的函数
# show()
# f='kkkk' # 并没有修改到test_in_pk01 f值
# show()
#上面问题的解决办法
from test1_project.sub_pkg_1.sub_pkg_01 import test_in_pk01
import test1_project.sub_pkg_1.sub_pkg_01.test_in_pk01 as test_in_pk01
#import test1_project.sub_pkg_1.sub_pkg_01.test_in_pk01 这句不行
# ✅ 测试可用的函数
test_in_pk01.show() # 输出f=fffff
f='kkkk'
test_in_pk01.show() # 输出f=fffff
test_in_pk01.f='kkkk'
test_in_pk01.show() # 输出f=kkkk
#test_in_pk01.py内容
f='fffff'
def show():
print(f'f={f}')6.4.5 防止导入
属性是_开头可以防止import * 导入,这意义不大,python的权限控制很不到位,不要太依赖
6.4.6 大小写
PYTHONCASEOK 是控制大小写的环境变量,命名不最好不要依赖大小写。PYTHONCASEOK=1有值就会忽略大小写。
6.4.7 导入循环
循环导入(Circular Import)是 Python 开发中常见的问题,通常表现为 ImportError: cannot import name 'X' from 'Y' 或者程序行为异常(如属性为 None 或函数未定义)。
这通常发生在两个模块互相依赖时:
module_a.py 需要 module_b 的内容。
module_b.py 也需要 module_a 的内容。
以下是解决循环导入的 5 种主要方法,按推荐程度排序
1. 重构代码
这是最根本的解决方法。循环导入通常意味着代码结构不合理,存在过高的耦合度
2. 延迟导入
如果无法重构代码(例如逻辑确实紧密耦合),可以将 import 语句从文件顶部移动到函数内部。
原理:Python 只有在执行到该函数时才会执行导入语句。此时,另一个模块可能已经完成了初始化,从而打破循环。
缺点:导入语句分散在代码中,稍微影响可读性;每次调用函数都会检查导入(虽然有缓存,性能影响极小)。
# module_a.py
def func_a():
# 延迟导入:只有调用 func_a 时才导入 module_b
from module_b import func_b
return func_b()
# module_b.py
def func_b():
from module_a import func_a # 同样延迟
return "Done"
#注意:这种写法在解决“运行时”循环依赖非常有效,但在模块顶层变量互相引用时依然要小心。3 使用 TYPE_CHECKING 处理类型注解(⭐ 类型提示专用)
如果你是因为类型提示(Type Hinting)导致的循环导入(例如 A 需要 B 的类型,B 需要 A 的类型),这是标准解法。
做法:利用 typing.TYPE_CHECKING 常量。它只在静态类型检查工具(如 mypy, Pyright)运行时为 True,在运行时为 False。
6.5 模块执行
模块执行时需要得到顶层包目录执行,需要加-m参数

6.6 模块内建函数
6.6.1 __import__
主要是用来做自定义导入,一般用不上
| 参数 | 类型 | 必填 | 说明 |
|---|---|---|---|
name |
str |
✅ | 要导入的模块名称(字符串) |
globals |
dict |
❌ | 当前全局命名空间,默认 globals() |
locals |
dict |
❌ | 当前局部命名空间,默认 locals() |
fromlist |
list |
❌ | 类似 from ... import 中的导入列表 |
level |
int |
❌ | 相对导入级别,0=绝对导入,>0=相对导入 |
# 简单示例,等价于:import math
math_module = __import__('math')
print(math_module.sqrt(16)) # 4.06.6.2 globals和locals
globals() 和 locals() 是 Python 中两个非常重要的内置函数,它们用于访问当前作用域的名称空间字典。理解它们的用法对于调试、动态编程以及深入理解 Python 的作用域机制至关重要
| 特性 | globals() |
locals() |
|---|---|---|
| 返回内容 | 全局名称空间的字典 | 局部名称空间的字典 |
| 范围 | 模块级别(整个 .py 文件) |
函数内部、类定义内部或当前执行帧 |
| 可修改性 | 可修改。修改字典会直接改变全局变量。 | 不可靠/只读。在函数内修改字典通常不会改变局部变量。 |
| 生命周期 | 随模块加载而存在,程序结束销毁。 | 随函数调用创建,函数返回销毁。 |
| 典型用途 | 动态访问全局配置、检查已导入模块、调试。 | 调试函数内部状态、动态获取参数值。 |
globals() 返回一个字典,表示当前的全局符号表。
在模块顶层,它包含该模块定义的所有变量、函数、类和导入的模块。
在函数内部调用 globals(),返回的仍然是定义该函数的模块的全局字典,而不是函数内部的局部变量。
x = 10
name = "Alice"
def my_func():
y = 20
# 在函数内部调用 globals(),看到的依然是模块级的变量
print(globals()['x']) # 输出: 10
print(globals()['name']) # 输出: Alice
# print(globals()['y']) # 报错: KeyError,因为 y 是局部变量,不在全局字典中
# 【重要】修改 globals() 字典会直接改变全局变量
globals()['x'] = 999
globals()['new_var'] = "I am global now"
my_func()
print(x) # 输出: 999 (被函数修改了)
print(new_var) # 输出: "I am global now" (动态添加了新全局变量)⚠️ 警告:虽然可以通过 globals() 动态修改变量,但这通常被视为坏实践(Bad Practice),因为它会让代码流程难以追踪,破坏代码的可读性和安全性
locals() 返回一个字典,表示当前的局部符号表。
在函数内部:包含函数的参数和局部定义的变量。
在模块顶层:行为与 globals() 相同(因为模块顶层既是全局也是局部)。
在类定义体内:包含类属性。
def calculate(a, b):
c = a + b
d = a * b
# 获取当前局部变量的字典
local_vars = locals()
print(local_vars['a']) # 输出: 传入的 a 值
print(local_vars['c']) # 输出: 计算结果
print(local_vars.keys()) # 输出: dict_keys(['a', 'b', 'c', 'd', ...])
return c
calculate(3, 4)⚠️ 关键陷阱:修改 locals() 的行为,这是面试和实际开发中最容易踩的坑:
在函数内部:修改 locals() 返回的字典,通常不会影响实际的局部变量值。
原因:Python 为了优化速度,局部变量存储在栈帧的特定槽位(slots)中,而不是完全依赖字典。locals() 在函数内只是生成一个快照(副本)。
def test_modify():
x = 10
print(f"初始 x: {x}")
# 尝试修改 locals 字典
locals()['x'] = 999
# 再次打印 x
print(f"修改后 x: {x}")
# 输出仍然是 10!修改字典并没有改变真正的变量 x
# 但是,如果是动态生成的变量名,有时会有不同表现,但强烈不建议依赖此行为。
test_modify()6.6.3 reload
重新导入模块
import importlib
import my_module # 假设这是你已经导入的模块
# ... 修改了 my_module.py 的代码 ...
# 重新加载模块
importlib.reload(my_module)
# 现在可以使用更新后的代码
my_module.some_function()6.5 路径搜索
6.5.1 基本搜索流程
1 检查缓存 (sys.modules):首先检查该模块是否已经被导入并缓存在 sys.modules 字典中。如果是,直接使用缓存对象,不再进行后续搜索。
2 检查内置模块:如果不在缓存中,检查它是否是 Python 的内置模块(如 sys, math, time 等)。
3 搜索 sys.path:如果前两步都没找到,解释器会遍历 sys.path 列表中的每一个目录路径,寻找名为 my_module.py 的文件或名为 my_module 的包(文件夹)。
一旦找到,搜索立即停止。这意味着 sys.path 中靠前的路径具有更高的优先级。如果两个路径下都有同名模块,排在前面的那个会被导入(这被称为“路径遮蔽”)。
4 抛出异常:如果遍历完所有路径仍未找到,抛出 ModuleNotFoundError。
6.5.2 sys.path
sys.path 是一个字符串列表,其内容在 Python 启动时动态生成。它的默认组成通常包括以下几个部分(按优先级从高到低):
(1) 脚本所在目录 (或当前工作目录)
直接运行脚本时 (python script.py):
脚本文件所在的绝对路径会被添加到 sys.path 的最前端(索引 0)。
注意:这不是“当前工作目录”,而是脚本文件本身的目录。
交互式命令行 (python 回车) 或 使用 -c 参数时:
当前工作目录 (Current Working Directory, CWD) 会被添加到最前端。
使用 -m 参数运行时 (python -m package.module):
当前工作目录 会被添加到最前端,而不是脚本所在的子目录。这是运行包内模块时的常见陷阱。
(2) PYTHONPATH 环境变量
如果在操作系统中设置了 PYTHONPATH 环境变量,其中包含的所有目录路径会被插入到 sys.path 中(通常在脚本目录之后,标准库之前)。
这是一个全局配置,允许用户在不修改代码的情况下扩展模块搜索范围。
格式:在 Windows 上用分号 ; 分隔,在 macOS/Linux 上用冒号 : 分隔。
(3) 标准库路径
Python 安装目录下的标准库路径(例如 .../lib/python3.x 和 .../lib/python3.x/lib-dynload)。
(4) 第三方包路径 (site-packages)
通过 pip 安装的第三方包默认存放的位置(例如 .../lib/python3.x/site-packages)。
这也是虚拟环境(venv/conda)隔离依赖的关键目录,每个虚拟环境有自己独立的 site-packages
运行时可以动态修改
import sys
import os
# 将特定目录添加到搜索路径的最前端 (最高优先级)
sys.path.insert(0, '/path/to/my/custom/module')
# 或者添加到末尾
sys.path.append('/another/path')
# 现在可以导入该路径下的模块了
# import my_custom_module7 面向对象
7.1 类与实例
类定义关键字是class,类名是首字母大写,以便在使用时区别于函数调用。类实例化不需要使用new
class ClassName(ParentClass1, ParentClass2, ...):
"""类的文档字符串 (Docstring),用于说明类的用途"""
# 类属性 (Class Attributes) - 所有实例共享
class_variable = "默认值"
def __init__(self, param1, param2, ...):
"""构造方法 (Constructor)
在创建对象时自动调用,用于初始化实例属性
"""
# 实例属性 (Instance Attributes) - 每个实例独有
self.instance_param1 = param1
self.instance_param2 = param2
def instance_method(self, arg1):
"""实例方法
第一个参数必须是 self,代表实例本身
"""
# 方法逻辑
return f"{self.instance_param1} 处理 {arg1}"
@classmethod
def class_method(cls, arg1):
"""类方法
第一个参数必须是 cls,代表类本身
使用 @classmethod 装饰器
"""
return f"类方法被调用: {cls.class_variable}"
@staticmethod
def static_method(arg1):
"""静态方法
不需要 self 或 cls 参数
使用 @staticmethod 装饰器
"""
return f"静态方法计算: {arg1 * 2}"
#实例化,参数会传入__init__
obj = ClassName(param1, param2, ...)7.1.1 基础类与新式类
python3 中的类默认都继承至object,属于新式类
经典类:实例的 type 是 <type 'instance'>,类本身的类型是 <type 'class'>。类和类型是分开的概念。
新式类:实例的 type 就是它的类。type(obj) 返回 obj.__class__。实现了“类也是对象”的概念,使得元类(Metaclass)编程更加一致和强大
class MyClass:
pass
class MyExplicitObjectClass(object):
pass
# 检查基类
print(MyClass.__bases__) # 输出: (<class 'object'>,)
print(MyExplicitObjectClass.__bases__) # 输出: (<class 'object'>,)
# 检查 MRO
print(MyClass.__mro__)
# 输出: (<class '__main__.MyClass'>, <class 'object'>)
# 检查类型
obj = MyClass()
print(type(obj)) # 输出: <class '__main__.MyClass'>
print(type(obj) is obj.__class__) # 输出: True7.1.2 __init__
比较严格的说法是初始化方法,还有一个__new__方法,该方法更像构造器,但是一般都不用。
__init__没有返回值。该方法中定义的self开头的是实例变量
7.1.3 变量访问权限
python中是没有权限修饰的,是通过一些约定或者是转弯磨角方法实现。
1. 单下划线开头 (_var)
含义:内部使用约定 (Internal Use Convention)
语义:告诉程序员和其他开发者,“这个变量或方法是供类内部使用的,请不要在类外部直接访问它”。
实际效果:Python 解释器完全忽略这个前缀。你仍然可以在类外部自由访问和修改它。它不会触发任何特殊的名称转换。
主要用途:
作为代码文档的一部分,提示该成员是“受保护的”(Protected,类似 Java/C++ 的概念,但 Python 没有强制的访问控制)。
在使用 from module import * 时,以单下划线开头的名字不会被导入到当前命名空间。
class MyClass:
def __init__(self):
self._internal_var = "我是内部变量"
obj = MyClass()
print(obj._internal_var) # ✅ 可以正常访问,不会报错
# 输出: 我是内部变量2 双下划线开头 (__var)
含义:名称修饰 (Name Mangling)
语义:旨在避免子类意外覆盖父类的属性或方法。它通常用于表示“私有”(Private)成员。
实际效果:Python 解释器会主动干预。它会将变量名重写(修饰)为 _ClassName__var 的形式。这使得在类外部直接通过原名访问变得困难(虽然不是不可能)。
主要用途:
防止命名冲突:当你在一个复杂的继承体系中,确保子类的 __var 不会意外覆盖父类的 __var。
模拟私有属性:虽然 Python 没有真正的私有属性,但这是一种强烈的信号,表明“除非万不得已,否则不要在外部访问”。
class MyClass:
def __init__(self):
self.__private_var = "我是私有变量"
obj = MyClass()
# print(obj.__private_var)
# ❌ 报错: AttributeError: 'MyClass' object has no attribute '__private_var'
# 但是,可以通过修饰后的名字访问(不推荐这样做):
print(obj._MyClass__private_var)
# ✅ 可以访问,输出: 我是私有变量7.1.4 类变量与实例变量
这里有个特别需要注意的是最好不要通过实例访问类变量,通过实例给类变量赋值存在语言陷阱,参看下面实例
| 特性 | 类变量 (Class Variable) | 实例变量 (Instance Variable) |
|---|---|---|
| 定义位置 | 在类的方法外部,直接定义在类体中。 | 在方法内部(通常是 __init__),通过 self 定义。 |
| 访问方式 | 类名.变量名 或 实例名.变量名 |
只能通过 实例名.变量名 (即 self.变量名) |
| 代码示例 | class A: count = 0 |
def __init__(self): self.name = "..." |
class Dog:
# 【类变量】所有狗共享的物种名称
species = "Canine"
__varA = 'test'
def __init__(self, name):
# 【实例变量】每只狗独有的名字
self.name = name
# 创建两个实例
dog1 = Dog("Buddy")
dog2 = Dog("Max")
# 1. 读取:初始状态
print(f"1. {dog1.name} is a {dog1.species}") # Buddy is a Canine
print(f" {dog2.name} is a {dog2.species}") # Max is a Canine
# 2. 修改【类变量】(正确方式:通过类名)
Dog.species = "Feline"
print("\n2. 修改类变量后 (Dog.species = 'Feline'):")
print(f" {dog1.name} is a {dog1.species}") # Buddy is a Feline (变了!)
print(f" {dog2.name} is a {dog2.species}") # Max is a Feline (变了!)
# 3. 修改【实例变量】
dog1.name = "Old Buddy"
print("\n3. 修改实例变量后 (dog1.name = 'Old Buddy'):")
print(f" {dog1.name} is a {dog1.species}") # Old Buddy is a Feline
print(f" {dog2.name} is a {dog2.species}") # Max is a Feline (没变)
# 4. 【陷阱】通过实例修改类变量名
# 这不会改变类变量,而是给 dog1 创建了一个新的实例变量叫 'species'
dog1.species = "Reptile"
print("\n4. 陷阱操作后 (dog1.species = 'Reptile'):")
print(f" {dog1.name} is a {dog1.species}") # Old Buddy is a Reptile (dog1 独有)
print(f" {dog2.name} is a {dog2.species}") # Max is a Feline (dog2 依然共享类的值)
print(f" 类本身的值: {Dog.species}") # Feline (类变量本身没变)
print("\n4.:")
#print(Dog.__varA 报错
print(Dog._Dog__varA) # test
print(dog1._Dog__varA)# test
Dog._Dog__varA = 'mmm'
print(Dog._Dog__varA) #mmm
print(dog1._Dog__varA) #mmm7.1.5 糟糕的实例外挂
除了,类属性和实例属性,还有一种实例外挂属性,这个特性相当糟糕。对代码可维护性会造成很大破坏。
class Dog:
# 【类变量】所有狗共享的物种名称
species = "Canine"
__varA = 'test'
def __init__(self, name):
# 【实例变量】每只狗独有的名字
self.name = name
# 创建两个实例
dog1 = Dog("Buddy")
dog2 = Dog("Max")
# 如果你不看类定义,你并不知道ff是类中定义的还是,添加的,相当恶心,代码很难维护
#每次遇到恶心的规则,就会用灵活性来恶心人。这种在实例上附加属性的做法完全可以禁止
#作为一个靠谱的程序员,程序的可维护性,是前期就必须要考虑的问题
dog2.ff='kkk'
print(dog2.ff)
#print(dog1.ff) 要报错 实例属性不存在- 可读性灾难:看到
dog2.ff,如果不翻遍整个文件甚至整个项目,根本不知道ff是哪里来的。是类里定义的?是父类继承的?还是某行代码临时挂上去的? - 隐蔽的 Bug:最常见的情况是拼写错误。你想写
self.age,结果手滑写成self.aeg。在 Java 里编译器直接报错,程序跑不起来;在 Python 默认模式下,它只是默默创建了一个新属性aeg,程序正常运行,但逻辑全错,这种 Bug 最难排查。 - 架构腐蚀:如果团队里有人习惯随手给对象“打补丁”(动态加属性),久而久之,类的结构就会变得支离破碎,任何人都无法确信一个对象到底包含什么数据
- 结构腐蚀:也容易造成类似上文中的属性覆盖
另一种是可变对象
class Dog:
# 【类变量】所有狗共享的物种名称
species = "Canine"
listVar = [1,2,3]
def __init__(self, name):
# 【实例变量】每只狗独有的名字
self.name = name
# 创建两个实例
dog1 = Dog("Buddy")
dog2 = Dog("Max")
# 1. 读取:初始状态
print(f'dog1.listVar={dog1.listVar} of {id(dog1.listVar)},Dog.listVar={Dog.listVar} of {id(Dog.listVar)}')
dog1.listVar[0]=4
print(f'dog1.listVar={dog1.listVar} of {id(dog1.listVar)},Dog.listVar={Dog.listVar} of {id(Dog.listVar)}')
dog1.listVar=[7,8,9] #整个赋值就会遮蔽
print(f'dog1.listVar={dog1.listVar} of {id(dog1.listVar)},Dog.listVar={Dog.listVar} of {id(Dog.listVar)}')
output='''
dog1.listVar=[1, 2, 3] of 2540229032960,Dog.listVar=[1, 2, 3] of 2540229032960
dog1.listVar=[4, 2, 3] of 2540229032960,Dog.listVar=[4, 2, 3] of 2540229032960
dog1.listVar=[7, 8, 9] of 2540229101632,Dog.listVar=[4, 2, 3] of 2540229032960
'''7.1.6 实例方法
实例方法都要传一个self,这个也有点恶心。号称简洁的语言,有时候就喜欢来些乌七八糟的,自相矛盾。实例方法只能在实例上调用。
7.1.7 类方法与静态方法
实例和类都可以调用,是通过装饰器实现,原生语法并不支持
class Demo:
data = "我是类变量" # 大家共享的
def __init__(self,name):
self.name=name
# 1. 实例方法 (默认,不用写装饰器)
# 第一个参数是 self (代表具体的对象)
# 用途:操作具体对象的数据
def instance_method(self):
return f"实例方法:我能访问self.data={self.data},Demo.data={Demo.data}"
# 2. 类方法 (加 @classmethod)
# 第一个参数是 cls (代表类本身)
# 用途:操作共享数据,或者用来创建新对象
@classmethod
def class_method(cls):
return f"实例方法:我能访问cls.data={cls.data},Demo.data={Demo.data}"
# 3. 静态方法 (加 @staticmethod)
# 不需要 self 或 cls
# 用途:纯工具函数,跟类或对象都没关系,只是借个名字放这里
@staticmethod
def static_method():
return f"实例方法:我能访问Demo.data={Demo.data}"
# --- 怎么调用 ---
obj = Demo('11')
print(obj.instance_method()) # ✅ 必须用对象调用 (通常)
print(Demo.class_method()) # ✅ 推荐用类调用 (也能用对象)
print(Demo.static_method()) # ✅ 推荐用类调用 (也能用对象)
output='''
实例方法:我能访问self.data=我是类变量,Demo.data=我是类变量
实例方法:我能访问cls.data=我是类变量,Demo.data=我是类变量
实例方法:我能访问Demo.data=我是类变量
'''7.1.8 如何实现抽象方法
python没有语法上支持,可以在要实现的方法上抛出异常来逼迫子类实现,但是语法不会报错,只有运行时才会报错。
7.1.9 __slots__ 属性
可以使用slot冻结属性,但是又会引发一些新问题,如果没有别要就不要用。
| 场景 | 建议 |
|---|---|
| 创建数百万个小对象 (如坐标点、粒子、数据库行映射) | ✅ 强烈推荐。显著节省内存,提升性能。 |
| 作为数据结构或 DTO (Data Transfer Object) | ✅ 推荐。固定字段,防止拼写错误,代码更健壮。 |
| 需要严格限制属性,防止动态修改 | ✅ 推荐。作为一种防御性编程手段。 |
| 普通的业务逻辑类,数量不多 | ⚠️ 可选。收益不明显,但能增加代码约束性。 |
| 需要频繁动态添加属性的类 | ❌ 不要用。会给自己找麻烦。 |
| 需要多重继承且结构复杂 | ⚠️ 谨慎。需仔细处理 __slots__ 的继承关系。 |
class StrictDog:
# 只允许这两个属性,这里是个坑,忘记添加怎么办,又不会报错
__slots__ = ['name', 'age']
def __init__(self, name, age):
self.name = name
self.age = age
dog = StrictDog("Buddy", 3)
# 1. 访问已声明的属性:正常
print(dog.name) # Buddy
# 2. 尝试动态添加新属性:❌ 报错!
try:
dog.color = "Brown"
except AttributeError as e:
print(f"错误: {e}")
# 输出: 错误: 'StrictDog' object has no attribute 'color'
# 3. 尝试拼写错误赋值:❌ 报错!
try:
dog.nmae = "Max"
except AttributeError as e:
print(f"错误: {e}")
# 输出: 错误: 'StrictDog' object has no attribute 'nmae'
# 4. 检查 __dict__:❌ 不存在!
try:
print(dog.__dict__)
except AttributeError as e:
print(f"错误: {e}")
# 输出: 错误: 'StrictDog' object has no attribute '__dict__'继承中的 __slots__
如果父类定义了 __slots__,子类必须也定义 __slots__ 才能添加新的属性。如果子类不定义,它将无法添加任何新属性(只能使用父类声明的)。
class Animal:
__slots__ = ['name']
class Dog(Animal):
# 如果想让 Dog 有 'breed' 属性,必须在这里声明
__slots__ = ['breed']
def __init__(self, name, breed):
self.name = name # 来自父类 slots
self.breed = breed # 来自子类 slots
d = Dog("Buddy", "Golden")
# d.age = 3 # ❌ 依然报错,因为既不在 Animal 也不在 Dog 的 slots 中注意:如果子类想允许动态添加属性(打破限制),可以在子类的 __slots__ 中加入 '__dict__'
class FlexibleDog(Animal):
__slots__ = ['breed', '__dict__'] # 允许 breed + 其他动态属性
def __init__(self, name, breed):
self.name = name
self.breed = breed
fd = FlexibleDog("Max", "Pug")
fd.trick = "roll over" # ✅ 现在允许了,因为有了 __dict___slots__ 可以减少内存,当需要创建大量轻量级对象(如数据点、节点、游戏实体)时,效果惊人。
import sys
class NoSlots:
def __init__(self, x, y):
self.x = x
self.y = y
class WithSlots:
__slots__ = ['x', 'y']
def __init__(self, x, y):
self.x = x
self.y = y
# 创建 100 万个实例
list_no_slots = [NoSlots(i, i) for i in range(1000000)]
list_with_slots = [WithSlots(i, i) for i in range(1000000)]
# 估算内存 (简单计算单个对象大小 * 数量)
# 注意:sys.getsizeof 只计算对象本身,不包含引用的对象,但在本例中足以展示差异
size_no = sys.getsizeof(NoSlots(1, 1))
size_yes = sys.getsizeof(WithSlots(1, 1))
print(f"无 slots 实例大小: ~{size_no} bytes")
print(f"有 slots 实例大小: ~{size_yes} bytes")
print(f"节省比例: {(1 - size_yes/size_no) * 100:.2f}%")
# 典型输出 (具体数值因系统而异):
# 无 slots: ~56-64 bytes (包含字典指针)
# 有 slots: ~32-48 bytes (紧凑存储)
# 节省比例通常在 30% - 50% 甚至更多常见陷阱
类变量依然可以动态添加:
__slots__ 限制的是实例属性。你依然可以随时给类本身添加属性(这会影响所有实例)。
class S:
__slots__ = ['x']
s1 = S()
# s1.y = 1 # ❌ 实例不行
S.z = 100 # ✅ 类可以
print(S.z) # 100多重继承冲突:
如果多个父类都有非空的 __slots__,且内容不兼容,可能会导致问题。通常建议在多重继承中,只有一个基类定义 __slots__,或者所有子类都妥善处理。
无法使用 __dict__ 和 __weakref__:
默认情况下,定义了 __slots__ 的类不支持弱引用(weakref)。如果需要支持弱引用,必须显式在 __slots__ 中加入 '__weakref__'
7.1.10 property()
原始写法
class Person:
def __init__(self, name):
self._name = name
def get_name(self):
return self._name
def set_name(self, value):
if not value: raise ValueError("不能为空")
self._name = value
# 手动将方法绑定到属性
name = property(get_name, set_name)
p = Person('ZhangShan')
print(p.name)
print(p.get_name())
p.name='Lisi'
print(p.name)
print(p.get_name())
output='''
ZhangShan
ZhangShan
Lisi
Lisi
'''新式装饰器写法
class Person:
def __init__(self, name):
# 注意:这里用 _name 存储真实数据,避免和属性名冲突
self._name = name
# 1. Getter (获取值)
# 当用户执行 p.name 时,自动调用这个方法
@property
def name(self):
print("👀 正在读取名字...")
return self._name.upper() # 可以动态处理数据
# 2. Setter (设置值)
# 当用户执行 p.name = "Tom" 时,自动调用这个方法
@name.setter
def name(self, value):
print("✍️ 正在设置名字...")
if not value:
raise ValueError("名字不能为空!")
self._name = value
# 3. Deleter (删除值) - 可选
# 当用户执行 del p.name 时,自动调用
@name.deleter
def name(self):
print("🗑️ 正在删除名字...")
del self._name
# --- 使用演示 ---
p = Person("alice")
# ✅ 像访问变量一样读取(实际触发了 @property 方法)
print(p.name)
# 输出:
# 👀 正在读取名字...
# ALICE
# ✅ 像修改变量一样赋值(实际触发了 @name.setter 方法)
p.name = "bob"
# 输出: ✍️ 正在设置名字...
# (此时 p._name 变成了 "bob")
# ❌ 如果赋空值,会触发验证逻辑报错
# p.name = "" -> 抛出 ValueError
# ✅ 删除
del p.name7.1.11 is与isinstance
is 和 isinstance() 是 Python 中两个非常容易混淆但用途完全不同的操作符/函数。
简单总结:
is:判断身份(是不是同一个对象?内存地址一样吗?)。
isinstance():判断类型(是不是某一种类或其子类的实例?)
7.2 类的继承
支持单继承、多继承以及复杂的方法解析顺序(MRO)
7.2.1 基本用法
class A:pass
class B:pass
class C(A,B):pass #多重继承
class Parent:
def __init__(self, val):
self.val = val
def show(self):
print(f"Parent: {self.val}")
class Child(Parent):
def __init__(self, val, extra):
super().__init__(val) # 继承初始化
self.extra = extra # 新增属性
def show(self): # 重写方法
super().show() # 调用父类逻辑
print(f"Child Extra: {self.extra}")
# 使用
obj = Child(100, "ABC")
obj.show()7.2.2 菱形依赖
核心冲突:
如果类 A 有一个方法 do_something(),而 B 和 C 都重写了这个方法。当我们在 D 的实例上调用 do_something() 时:
D 应该调用 B 的版本还是 C 的版本?
如果 B 和 C 都通过 super() 调用了 A 的方法,A 的方法会被执行一次还是两次?
执行两次:通常是错误的(例如:初始化代码跑了两次,资源被重复分配)。
执行一次:通常是正确的期望。
A
/ \
B C
\ /
DPython 的解决方案:C3 线性化算法 (MRO)
在 旧式类(Python 2.2 之前,不继承 object)中,Python 使用深度优先搜索(DFS),这会导致 A 的方法被调用两次,引发严重 Bug。
在 新式类(Python 3 中所有类默认都是新式类,显式或隐式继承 object)中,Python 采用了 C3 线性化算法 来计算 方法解析顺序 (MRO, Method Resolution Order)。
C3 算法的核心保证:
1 单调性:子类永远在父类之前被检查。
2 局部优先次序:如果在定义类时写了 class D(B, C),那么 B 永远在 C 之前被检查。
3 唯一性:每个类在 MRO 列表中只出现一次。这意味着父类的方法只会被调用一次。
代码演示:验证“只调用一次”
class A:
def do(self):
print("A: do called")
# 注意:这里通常不需要 super(),因为 A 是顶层基类,但为了演示链式调用,我们加上
# 如果 A 继承自 object,super().do() 会最终调用 object 的方法(通常什么都不做)
# 为了清晰,这里我们假设 A 是终点,或者我们观察调用顺序
class B(A):
def do(self):
print("B: do called")
super().do() # 调用下一个 MRO 中的类
class C(A):
def do(self):
print("C: do called")
super().do() # 调用下一个 MRO 中的类
# 关键点:定义顺序是 (B, C)
class D(B, C):
def do(self):
print("D: do called")
super().do() # 触发 MRO 链
# 查看 MRO 顺序
print("MRO 顺序:", [cls.__name__ for cls in D.__mro__])
# 输出: ['D', 'B', 'C', 'A', 'object']
# 注意:A 只出现了一次!
print("\n开始调用 d.do():")
d = D()
d.do()
output='''
MRO 顺序: ['D', 'B', 'C', 'A', 'object']
开始调用 d.do():
D: do called
B: do called
C: do called
A: do called
'''7.3 内建函数
7.3.1 检查与判断
这些函数用于在运行时确认对象的类型和结构
| 函数 | 语法 | 作用 | 典型场景 |
|---|---|---|---|
isinstance() |
isinstance(obj, cls) |
判断 obj 是否是 cls 类或其子类的实例。 |
类型检查,多态处理。isinstance(dog, Animal) → True |
issubclass() |
issubclass(cls_a, cls_b) |
判断 cls_a 是否是 cls_b 的子类。 |
验证继承关系。issubclass(Dog, Animal) → True |
hasattr() |
hasattr(obj, 'name') |
判断对象 obj 是否拥有名为 'name' 的属性。 |
安全检查,避免报错。if hasattr(user, 'vip'): ... |
callable() |
callable(obj) |
判断对象 obj 是否可被调用(即是否有 __call__ 方法)。 |
区分方法和普通属性,或检查类本身是否可实例化。 |
class Animal: pass
class Dog(Animal): pass
dog = Dog()
print(isinstance(dog, Dog)) # True
print(isinstance(dog, Animal)) # True (支持继承链检查)
print(issubclass(Dog, Animal)) # True
print(hasattr(dog, 'name')) # False (除非定义了 name)
print(callable(Dog)) # True (类是可以被调用来创建实例的)
print(callable(dog)) # False (除非定义了 __call__)7.3.2 获取与动态操作
这些函数允许你通过字符串名称来动态地访问或修改属性,是反射(Reflection)机制的基础
| 函数 | 语法 | 作用 | 典型场景 |
|---|---|---|---|
getattr() |
getattr(obj, 'name', default) |
获取属性值。如果不存在,返回 default(若不填则报错)。 |
动态配置读取,处理可选属性。val = getattr(config, 'timeout', 30) |
setattr() |
setattr(obj, 'name', value) |
设置属性值。相当于 obj.name = value。 |
动态添加属性,批量初始化。setattr(user, 'role', 'admin') |
delattr() |
delattr(obj, 'name') |
删除属性。相当于 del obj.name。 |
清理敏感数据,重置状态。 |
dir() |
dir(obj) |
列出对象的所有属性和方法(包括继承的)。 | 调试,查看对象能力,自动补全提示。 |
vars() |
vars(obj) |
返回对象的 __dict__ 字典(仅实例变量)。 |
查看对象内部状态,序列化。 |
type() |
type(obj) |
返回对象的确切类型(类)。 | 精确类型判断(不考虑继承)。 |
class Dog:
def __init__(self, name):
self.name = name
dog = Dog("Buddy")
# 1. 动态获取 (安全模式)
print(getattr(dog, 'breed', 'Unknown')) # Unknown (因为没定义)
# 2. 动态设置 (你之前提到的“恶心”操作通常由它完成)
setattr(dog, 'ff', 'kkk')
print(dog.ff) # kkk 整个和外挂属性一样,只对当前实例生效
# 3. 动态删除
delattr(dog, 'ff')
# print(dog.ff) # 这里会报错
# 4. 查看所有内容
print(dir(dog))
# ['__class__', ..., 'name'] (包含所有内置和自定义属性)
# 5. 查看实例字典 (只包含动态绑定的实例变量)
print(vars(dog))
# {'name': 'Buddy'} (注意:ff 已经被删除了)
# 6. type vs isinstance
print(type(dog) == Dog) # True
print(type(dog) == Animal) # False (即使 Dog 继承 Animal,type 也只认直接类)7.3.3 元编程与高级控制
这些函数用于在运行时创建类或控制属性查找逻辑
| 函数 | 语法 | 作用 | 典型场景 |
|---|---|---|---|
super() |
super() 或 super(cls, obj) |
返回一个代理对象,用于调用父类的方法。 | 多重继承中调用父类逻辑,避免硬编码父类名。 |
property() |
property(fget, fset, fdel, doc) |
将方法转换为属性访问(装饰器 @property 的底层实现)。 |
封装 getter/setter,实现计算属性。 |
classmethod() |
classmethod(func) |
将方法转换为类方法(第一个参数是 cls)。 |
工厂模式,替代构造函数。 |
staticmethod() |
staticmethod(func) |
将方法转换为静态方法(无 self 或 cls)。 |
工具函数,逻辑上属于类但不依赖实例。 |
globals() / locals() |
globals(), locals() |
返回当前全局或局部符号表的字典。 | 极其动态的场景,如从字符串动态查找类并实例化。 |
exec() / eval() |
exec(code), eval(expr) |
执行动态生成的 Python 代码。 | 慎用!常用于框架加载插件或配置文件。 |
特别提及:type() 作为类构造器
type 不仅是查询类型的函数,它还是所有类的元类。你可以用它动态创建一个全新的类:
# 动态创建一个类:type(类名, 基类元组, 参数字典)
MyDynamicClass = type('MyDynamicClass', (object,), {'x': 1, 'say_hi': lambda self: "Hi"})
obj = MyDynamicClass()
print(obj.x) # 1
print(obj.say_hi()) # Hi7.4 类的特殊方法
python所谓的魔法,很多是通过这种方式实现,非常多的方法,这里只是列举一些,没法记忆,太多了
7.4.1 构造与初始化
| 方法 | 触发时机 | 作用 |
|---|---|---|
__new__(cls, ...) |
实例化之前 | 真正创建对象的地方。通常用于单例模式或继承不可变类型(如 str, tuple)时使用。一般不需要重写。 |
__init__(self, ...) |
实例化之后 | 初始化对象。new 创建好对象后,自动调用它来赋值属性。最常用。 |
__del__(self) |
对象被销毁时 | 析构函数。当垃圾回收机制回收对象前调用(如关闭文件、断开连接)。注意: 由于垃圾回收时间不确定,重要资源建议用 with 上下文管理。 |
class Demo:
def __new__(cls, *args, **kwargs):
print("1. __new__: 正在创建实例...")
return super().__new__(cls)
def __init__(self, name):
print("2. __init__: 正在初始化...")
self.name = name
def __del__(self):
print(f"3. __del__: {self.name} 被销毁了")
d = Demo("测试") # 输出 1 -> 2
# 脚本结束或 del d 时输出 37.4.2 字符串表示
| 方法 | 触发时机 | 作用 | 推荐写法 |
|---|---|---|---|
__str__(self) |
print(obj) 或 str(obj) |
给用户看的友好字符串。 | 返回易读的中文或简略信息。 |
__repr__(self) |
直接输入 obj 或 repr(obj) |
给开发者看的调试字符串。 | 返回能还原对象的代码格式(如 <Person name='Tom'>)。 |
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return f"用户:{self.name}" # print(p) 显示这个
def __repr__(self):
return f"Person('{self.name}', {self.age})" # 直接敲 p 显示这个
p = Person("张三", 18)
print(p) # 输出:用户:张三
print(repr(p)) # 输出:Person('张三', 18)7.4.3 运算符重载
| 运算符 | 对应方法 | 示例 |
|---|---|---|
+ |
__add__(self, other) |
a + b |
- |
__sub__(self, other) |
a - b |
* |
__mul__(self, other) |
a * b |
== |
__eq__(self, other) |
a == b (判断相等) |
< |
__lt__(self, other) |
a < b (排序时用) |
!= |
__ne__(self, other) |
a != b |
class Vector:
def __init__(self, x, y):
self.x = x
self.y = y
def __add__(self, other):
# 定义向量相加:(1,2) + (3,4) = (4,6)
return Vector(self.x + other.x, self.y + other.y)
def __eq__(self, other):
# 定义相等判断
#print('call eq')
return self.x == other.x and self.y == other.y
def __repr__(self):
return f"Vector({self.x}, {self.y})"
v1 = Vector(1, 2)
v2 = Vector(3, 4)
print(v1 + v2) # 输出:Vector(4, 6) 调用__add__
print(v1 == v2) # 输出:False 调用 __eq__7.4.4 容器行为
让你的对象支持 len(), [], in, for 循环
| 功能 | 对应方法 | 示例 |
|---|---|---|
| 长度 | __len__(self) |
len(obj) |
| 读取 | __getitem__(self, key) |
obj[key] |
| 写入 | __setitem__(self, key, value) |
obj[key] = val |
| 删除 | __delitem__(self, key) |
del obj[key] |
| 成员检查 | __contains__(self, item) |
item in obj |
| 迭代器 | __iter__(self) |
for x in obj: |
class MyList:
def __init__(self):
self._data = [10, 20, 30]
def __len__(self):
return len(self._data)
def __getitem__(self, index):
return self._data[index]
def __contains__(self, item):
return item in self._data
ml = MyList()
print(len(ml)) # 2. 输出:3
print(ml[1]) # 2. 输出:20
print(20 in ml) # 3. 输出:True
for x in ml: # 4. 如果没写 __iter__ 但写了 __getitem__,也能遍历
print(x)7.4.5 上下文管理
class FileManager:
def __enter__(self):
print("🔓 打开文件")
self.file = open("data.txt", "w")
return self.file
def __exit__(self, exc_type, exc_val, exc_tb):
print("🔒 关闭文件")
self.file.close()
# 如果返回 True,可以吞掉异常;返回 False (或 None) 则让异常抛出
return False
# 使用
with FileManager() as f:
f.write("Hello")
# 即使里面报错,__exit__ 也会执行,确保文件关闭7.4.6 可调用对象
这玩意有点搞扯
| 方法 | 触发时机 | 示例 |
|---|---|---|
__call__(self, ...) |
obj(...) |
my_obj() |
class Adder:
def __init__(self, base):
self.base = base
def __call__(self, x):
return self.base + x
add_5 = Adder(5)
print(add_5(10)) # 输出:15 (像调用函数一样)7.4.7 比较运算
| 运算符 | 特殊方法 | 说明 |
|---|---|---|
== |
__eq__(self, other) |
等于 (最常用,用于判断相等) |
!= |
__ne__(self, other) |
不等于 (通常不需要写,Python 会自动对 __eq__ 取反) |
< |
__lt__(self, other) |
小于 (排序 sort() 的核心) |
> |
__gt__(self, other) |
大于 |
<= |
__le__(self, other) |
小于等于 |
>= |
__ge__(self, other) |
大于等于 |
7.4.8 序列相关
| 方法 | 对应操作 | 作用 |
|---|---|---|
__len__(self) |
len(obj) |
返回序列长度(整数)。如果返回 0,对象在布尔判断中为 False。 |
__getitem__(self, key) |
obj[key] |
读取元素。支持整数索引(obj[0])和 切片(obj[1:5])。 |
__setitem__(self, key, value) |
obj[key] = val |
修改/添加元素。如果不实现,序列就是只读的。 |
__delitem__(self, key) |
del obj[key] |
删除元素。 |
class MyRange:
def __init__(self, start, end):
self._data = list(range(start, end))
def __len__(self):
return len(self._data)
def __getitem__(self, key):
print(f"🔍 获取数据,key 类型: {type(key)}")
# 情况 A: 如果是切片对象 (例如 [1:3])
if isinstance(key, slice):
print(" -> 检测到切片操作")
# 直接利用内部列表的切片功能返回新列表,或者返回一个新的 MyRange 对象
return self._data[key]
# 情况 B: 如果是整数索引 (例如 [0])
elif isinstance(key, int):
print(" -> 检测到索引操作")
if key < 0:
key += len(self) # 支持负数索引
if 0 <= key < len(self):
return self._data[key]
raise IndexError("索引超出范围")
else:
raise TypeError("无效的索引类型")
def __setitem__(self, key, value):
self._data[key] = value
def __delitem__(self, key):
del self._data[key]
def __repr__(self):
return f"MyRange({self._data})"
# --- 测试 ---
mr = MyRange(10, 20) # [10, 11, ..., 19]
print(len(mr)) # 10
print(mr[0]) # 10 (触发 __getitem__, key=0)
print(mr[-1]) # 19 (触发 __getitem__, key=-1)
print(mr[1:4]) # [11, 12, 13] (触发 __getitem__, key=slice(1,4,None))
mr[0] = 99 # 修改第一个值
print(mr[0]) # 99
del mr[1] # 删除第二个值
print(len(mr)) # 97.4.9 属性相关
这四个方法是属性拦截的基石
| 方法 | 触发时机 | 作用 | 典型场景 |
|---|---|---|---|
__getattr__(self, name) |
访问不存在的属性时 | 当正常查找(包括 __dict__ 和类属性)都失败后,最后调用此方法。 |
实现动态属性、默认值、API 代理。 |
__getattribute__(self, name) |
访问任何属性时 | 无条件拦截所有属性访问。优先级最高。 | 强制日志记录、权限控制、调试。慎用,易导致死循环。 |
__setattr__(self, name, value) |
赋值任何属性时 | 拦截所有 obj.name = value 操作。 |
数据验证、类型检查、只读属性模拟。 |
__delattr__(self, name) |
删除任何属性时 | 拦截 del obj.name 操作。 |
防止删除关键属性、清理关联资源。 |
class Config:
def __init__(self):
self._data = {"timeout": 30, "retries": 3}
def __getattr__(self, name):
# 只有当 _data 里没有这个 key,且实例字典里也没有时才会触发
print(f"⚠️ 属性 '{name}' 不存在,尝试动态获取...")
# 模拟从环境变量或远程配置获取
if name.startswith("env_"):
return f"DynamicValue_{name}"
# 如果真的找不到,抛出标准异常
raise AttributeError(f"配置项 '{name}' 未找到")
cfg = Config()
#print(cfg.timeout) # 30 (正常查找,不触发 __getattr__)
print(cfg.env_api) # 触发 __getattr__ -> 输出: DynamicValue_env_api
# print(cfg.unknown) # 触发 __getattr__ -> 抛出 AttributeError警告:由于它拦截所有访问(包括 self.__dict__),使用时必须非常小心,通常直接调用 super() 来避免破坏内部机制
class LoggedObject:
def __getattribute__(self, name):
# 避免拦截内部特殊方法导致死循环 (如 __class__, __dict__)
if name.startswith('_'):
return super().__getattribute__(name)
print(f"📝 [LOG] 用户访问了属性: {name}")
return super().__getattribute__(name)
obj = LoggedObject()
obj.x = 10
print(obj.x)
# 输出: 📝 [LOG] 用户访问了属性: x
# 输出: 10| 方法 | 所在类 | 触发时机 |
|---|---|---|
__get__(self, instance, owner) |
描述符类 | 当通过实例或类访问该属性时 |
__set__(self, instance, value) |
描述符类 | 当通过实例赋值该属性时 |
__delete__(self, instance) |
描述符类 | 当删除该属性时 |
class TypedProperty:
def __init__(self, name, expected_type):
self.name = name
self.expected_type = expected_type
def __get__(self, instance, owner):
if instance is None:
return self
return instance.__dict__.get(self.name)
def __set__(self, instance, value):
if not isinstance(value, self.expected_type):
raise TypeError(f"{self.name} 必须是 {self.expected_type.__name__}")
instance.__dict__[self.name] = value
class Product:
# 复用 TypedProperty,无需在 Product 中写 __setattr__
name = TypedProperty("name", str)
price = TypedProperty("price", float)
count = TypedProperty("count", int)
p = Product()
p.name = "Apple" # ✅
p.price = 1.5 # ✅
p.price = "expensive" # ❌ TypeError
# p.count = 1.5 # ❌ TypeError7.4.10 迭代器
| 概念 | 英文 | 必须实现的方法 | 作用 | 例子 |
|---|---|---|---|---|
| 可迭代对象 | Iterable | __iter__(self) |
返回一个迭代器对象。可以被 for 循环遍历。 |
list, str, dict, 自定义容器 |
| 迭代器 | Iterator | __iter__(self)__next__(self) |
记录当前状态,每次调用 __next__ 返回下一个值。当没有值时抛出 StopIteration。 |
list_iterator, file object, 生成器 |
class Fibonacci:
def __init__(self, max_count):
self.max_count = max_count
self.count = 0
self.a, self.b = 0, 1
# 1. 实现 __iter__ (让它成为 Iterable)
# 对于迭代器来说,__iter__ 通常直接返回 self
def __iter__(self):
return self
# 2. 实现 __next__ (让它成为 Iterator)
def __next__(self):
if self.count >= self.max_count:
# 🛑 关键:没有更多数据时,必须抛出 StopIteration
raise StopIteration
# 计算当前值
result = self.a
# 更新状态 (准备下一次调用)
self.a, self.b = self.b, self.a + self.b
self.count += 1
return result
# --- 测试 ---
fib = Fibonacci(5)
# 方式 A: 使用 for 循环 (自动调用 __iter__ 和 __next__)
print("For 循环:")
for num in fib:
print(num, end=" ")
# 输出: 0 1 1 2 3
# 方式 B: 手动模拟 for 循环 (深入理解原理)
print("\n\n手动模拟:")
fib2 = Fibonacci(3)
it = iter(fib2) # 调用 __iter__()
try:
while True:
val = next(it) # 调用 __next__()
print(val, end=" ")
except StopIteration:
print("\n-> 遍历结束")7.4.11 数值转换相关
class Money:
def __init__(self, amount, currency="USD"):
self.amount = amount
self.currency = currency
def __int__(self):
# 强制转为整数:向下取整,丢弃小数部分
return int(self.amount)
def __float__(self):
# 强制转为浮点:保留精度
return float(self.amount)
def __complex__(self):
# 转为复数:实部为金额,虚部为0 (或者你可以定义其他逻辑)
return complex(self.amount, 0)
def __repr__(self):
return f"{self.amount} {self.currency}"
m = Money(19.95)
print(int(m)) # 19 (触发 __int__)
print(float(m)) # 19.95 (触发 __float__)
print(complex(m)) # (19.95+0j) (触发 __complex__)
# ✅ 实际用途:作为列表索引
items = ["apple", "banana", "cherry", "date"]
# 假设我们要买第 19.95 个物品?通常取整
index = int(m) % len(items)
print(f"购买物品: {items[index]}") 7.5 元类
元类(Metaclass) 是“创建类的类”。如果说类是对象的模板,那么元类就是类的模板。
默认情况下,Python 中所有的类都是由内置的 type 元类创建的。元类允许你在类被创建时(而不是实例化时)拦截并修改类的定义行为,例如自动注册子类、强制命名规范、自动添加方法或属性等在 Python 中,一切皆对象,类本身也是对象。
普通对象:由类创建(实例化)。
类:由元类创建。
默认元类:type
class MyClass:pass
#上面的定义相当于下面的定义,第一个参数类名,第二个参数父类元组,第三个参数父类字典
MyClass = type('MyClass', (), {})总结
定义:元类是创建类的类,默认是 type。
入口:通过 class MyClass(metaclass=MyMeta): 指定。
核心方法:__new__ (修改类结构), __init__ (初始化类), __call__ (控制实例化)。
用途:框架开发、ORM 映射、API 自动注册、强制编码规范、单例模式等高级架构场景。
建议:除非你在编写框架或库,且类装饰器无法满足需求,否则尽量避免使用元类,以保持代码的可读性。
7.5.1 自定义元类
要创建自定义元类,通常需要继承 type 类,并重写其 __new__ 或 __init__ 方法。
__new__:在类创建之前调用,用于修改类的结构(如添加/删除属性)。它必须返回一个新的类对象。
__init__:在类创建之后调用,用于初始化类对象
class MyMeta(type):
def __new__(mcs, name, bases, attrs):
# mcs: 元类本身 (MyMeta)
# name: 正在创建的类名 (字符串)
# bases: 父类元组
# attrs: 类属性字典
print(f"正在创建类: {name}")
# 示例:强制所有方法名必须是小写,否则报错
for key, value in list(attrs.items()):
if callable(value) and not key.startswith('__') and key != key.lower():
raise TypeError(f"方法名 {key} 必须全小写")
# 示例:自动添加一个属性
attrs['created_by'] = 'MyMeta'
return super().__new__(mcs, name, bases, attrs)
# 使用元类 (通过 metaclass 参数指定)
class MyClass(metaclass=MyMeta):
def Hello(self): # 这会触发错误,因为方法名不是全小写
pass7.5.2 元类实现单例
class SingletonMeta(type):
_instances = {}
def __call__(cls, *args, **kwargs):
print(cls.__name__)# 输出Database
if cls not in cls._instances:
cls._instances[cls] = super().__call__(*args, **kwargs)
return cls._instances[cls]
class Database(metaclass=SingletonMeta):
def __init__(self):
self.connection = "Connected"
db1 = Database()
db2 = Database()
print(db1 is db2) # 输出: True7.5 3 自动注册插件
registry = {}
class PluginMeta(type):
def __new__(mcs, name, bases, attrs):
cls = super().__new__(mcs, name, bases, attrs)
if name != 'BasePlugin': # 不注册基类
registry[name] = cls
return cls
class BasePlugin(metaclass=PluginMeta):
pass
class EmailPlugin(BasePlugin):
pass
class SmsPlugin(BasePlugin):
pass
print(registry)
# 输出: {'EmailPlugin': <class '__main__.EmailPlugin'>, 'SmsPlugin': <class '__main__.SmsPlugin'>}7.5.4 接口检查
class RequiredMethodsMeta(type):
required_methods = ['process', 'save']
def __init__(cls, name, bases, attrs):
super().__init__(name, bases, attrs)
# 跳过基类检查
if any(base.__name__ == 'BaseHandler' for base in bases):
return
for method in cls.required_methods:
if not hasattr(cls, method) or not callable(getattr(cls, method)):
raise TypeError(f"类 {name} 必须实现方法: {method}")
class BaseHandler(metaclass=RequiredMethodsMeta):
pass
# 正确
class GoodHandler(BaseHandler):
def process(self): pass
def save(self): pass
# 错误:定义时直接报错
# class BadHandler(BaseHandler):
# def process(self): pass
# # 缺少 save 方法7.6 类型提示
弱类型语言灵活(AI会说python是动态类型语言,不是弱类型,相对的是静态类型语言),代价是维护性不好。主要体现在可读,类型检查、代码提示等方面。所以python也想有强类型的优势,但是本身不是强类型,所以搞了个类型提示,用起来自然不太好使。
7.6.1 类型提示发展史
-
Python 3.5 (2015年)
- 类型提示诞生:通过 PEP 484 正式引入了类型提示语法,允许开发者为函数参数和返回值添加类型注解。
typing模块出现:与类型提示一同引入的,还有typing模块。这个模块不仅提供了List,Dict,Optional等基础类型,也首次引入了泛型的核心概念,比如TypeVar和Generic。
-
Python 3.9 (2020年)
- 内置的容器类型(如
list,dict)可以直接作为泛型使用,例如list[str],无需再从typing模块导入List,Dict。
- 内置的容器类型(如
-
Python 3.10 (2021年)
- 引入了
|操作符来表示联合类型(如int | str),使类型提示的语法更加简洁。
- 引入了
-
Python 3.12 (2023年)
- 通过 PEP 695 引入了全新的、更简洁的泛型语法,允许使用
class Box[T]:这样的方式定义泛型类。
- 通过 PEP 695 引入了全新的、更简洁的泛型语法,允许使用
7.6.2 无类型缺点
class TestOne:
def test(self):
return 1
#这个函数可能是在某ff.py文件
#单看这个方法 声明 test5(obj) ,你不知道有没有返回值,如果有返回值是什么
#这个参数是什么。大体只知道是一个对象,不看代码体,你是不知道要传的对象需要具有什么限制
#即使看了代码体,你也只知道对象参数只需要有test方法就行。但是这个方法想要传参是TestOne,还是TestTwo的对象?限制不了
#很多方法的做作用,一般是看入参和返回值,很多时候不需要文档说明,静态类型的语言带有自己解释性,还能做强限制
def test5(testOneObj):
testOneObj.test()
oneObj = TestOne()
test5(oneObj)7.6.3 类型提示
就是做提示的作用,运行前不会检查,鸭式辨型
from typing import Protocol
class TestOne:
def test(self) -> int: # 提示 test 方法返回整数
return 1
class TestTwo:
def test(self) -> int: # 提示 test 方法返回整数
return 2
class TestThree:
def testff(self) -> int: return # 没有test方法,没有返回也不报错(None)
# 定义一个协议(接口),表示任何有 test 方法的对象都符合这个协议,更像个接口
class HasTestMethod(Protocol):
def test(self) -> int: ...
def test5(testOneObj: TestOne) -> int: # 提示参数必须是 TestOne 类型,返回值int
return testOneObj.test()
# 使用协议作为类型提示,增加了代码的灵活性
def test6(testOneObj: HasTestMethod) -> None:
testOneObj.test()
obj = TestOne()
print(test5(obj))
obj = TestTwo()
#test5 编写者是想传TestOne实例的,结果TestTwo的也行,当然test5在代码里面自己写代码校验类型,这是另外一回事了
print(test5(obj))
#
print(test6(obj))
obj = TestThree()
#这个也是不会检查错误,在运行时才会报错,不知道IDE,有没有相关设置,不要太依赖这个特性,毕竟用这个做开发的
#都是喜欢短、频繁、块,维护代价这玩意不重要。写多了的时候才觉得有必要,已经晚了,还不如摆烂好。
# 所以控制好规模和规范就好了,维护好说明文档,也能一定程度上解决
print(test6(obj))7.7 泛型
Python 的泛型语法经历了一次重大的演进,以 Python 3.12 为分界线,分为现代语法(推荐)和传统语法(兼容旧版本)。简单来说,泛型允许你编写“可复用”的代码,让函数或类能够处理多种数据类型,同时保留类型检查的严谨性(比如让 IDE 知道输入是 int,输出也一定是 int)
7.7.1 Python 3.12+ 现代语法 (推荐)
PEP 695 引入了全新的语法糖,让 Python 的泛型写法终于像 Java、C++ 或 TypeScript 那样简洁自然。无需导入 TypeVar 或 Generic。直接在类或函数名后使用 [T] 定义类型参数。
泛型函数
# 直接在函数名后定义 [T]
def echo[T](x: T) -> T:
return x
# 使用
val = echo(10) # T 被推断为 int泛型类
# 直接在类名后定义 [T]
class Box[T]:
def __init__(self, value: T):
self.value = value
def get(self) -> T:
return self.value
# 使用
box = Box[int](42)7.7.2 Python 3.5 - 3.11 传统语法
泛型函数
from typing import TypeVar
# 1. 定义类型变量 T
T = TypeVar('T')
# 2. 在函数签名中使用
def echo(x: T) -> T:
return x泛型类
from typing import Generic, TypeVar
T = TypeVar('T')
# 1. 继承 Generic[T]
class Box(Generic[T]):
def __init__(self, value: T):
self.value = value
def get(self) -> T:
return self.value
# 使用
box = Box[int](42)8 执行环境
8.1 可调用对象
“可调用对象”指的是任何可以像函数一样被“调用”(即使用 () 操作符执行)的对象。
常见的可调用对象包括
1 内置函数:如 len(), print(), max()。
2 用户定义函数:使用 def 或 lambda 定义的函数。
3 类:类本身是可调用的,调用时会触发 __new__ 和 __init__ 来创建实例。
4 类的实例:如果类定义了 __call__ 方法,其实例也可以像函数一样被调用。
5 方法:绑定到实例或类的方法。
6 其他实现了 __call__ 的对象
8.1.1 实例
# 1. 普通函数
def my_func(x):
return x * 2
# 2. Lambda 表达式
my_lambda = lambda x: x * 2
# 3. 类 (调用类会创建实例)
class MyClass:
def __init__(self, value):
self.value = value
# 4. 实现了 __call__ 的实例 (函数式对象)
class Multiplier:
def __init__(self, factor):
self.factor = factor
def __call__(self, x):
return x * self.factor
def test():pass
double = Multiplier(2)
# 测试调用
print(my_func(5)) # 输出: 10
print(my_lambda(5)) # 输出: 10
obj = MyClass(10) # 调用类
print(double(5)) # 输出: 10 (实例像函数一样被调用)
# 检查是否可调用
print(callable(my_func)) # True
print(callable(double)) # True
print(callable(obj)) # False (除非 MyClass 定义了 __call__)
print(type(my_func)) # <class 'function'>
print(type(my_lambda)) #<class 'function'> 早期版本可能是 <type 'function'>
print(type(dict())) # <class 'dict'>
print(type([].append)) #<class 'builtin_function_or_method'>
print(type(Multiplier.test)) #<class 'function'>8.2 代码对象
在 Python 中,“代码对象”(Code Object)是一个底层且核心的概念。是 types.CodeType 的实例。它包含了函数执行所需的所有静态信息,但不包含运行时的状态(如局部变量的值。
它是 编译后的字节码(Bytecode)的容器,是 Python 函数、类、模块甚至 lambda 表达式在内存中的真实表现形式。
当你编写 Python 代码时,解释器会经历以下步骤:
源码 (Source Code) .py 文件。
编译 (Compile) -> 生成 代码对象 (Code Object)。
执行 (Execute) -> Python 虚拟机 (PVM) 读取代码对象中的字节码并运行
8.2.1 代码对象包含信息
co_code: 实际的字节码指令序列(二进制数据)。co_consts: 代码中使用的常量池(如数字、字符串、None)。co_names: 代码中引用的全局变量名或属性名。co_varnames: 局部变量名(包括参数)。co_filename: 源代码文件名。co_name: 代码块的名字(通常是函数名)。co_firstlineno: 函数定义所在的起始行号。co_argcount: 位置参数的数量
def my_func(x, y):
z = x + y
return z * 2
# 获取代码对象
code_obj = my_func.__code__
print(type(code_obj)) # 输出: <class 'code'>
# 查看关键属性
print(f"函数名: {code_obj.co_name}")
print(f"文件名: {code_obj.co_filename}")
print(f"局部变量: {code_obj.co_varnames}")
print(f"常量池: {code_obj.co_consts}") # None 是隐式的,2 是代码中的常数
print(f"字节码长度: {len(code_obj.co_code)} bytes")
output='''
<class 'code'>
函数名: my_func
文件名: F:\Users\admin2\AppData\Local\Temp\ipykernel_9620\990376298.py
局部变量: ('x', 'y', 'z')
常量池: (None, 2)
字节码长度: 20 bytes
'''8.2.2 代码对象与函数对象区别
函数对象 (function): 是高级抽象。它包裹了代码对象,并添加了运行时上下文,如全局命名空间 (__globals__)、默认参数值、闭包变量 (__closure__)、注解等。
代码对象 (code): 是低级抽象。它只包含“怎么做”(指令),不包含“在哪里做”(环境)或“初始数据是什么”(默认值
函数对象 (func)
├── __code__ ---> [ 代码对象 (Code Object) ] (包含字节码 co_code)
├── __globals__ ---> { 'x': 1, ... } (全局作用域)
├── __defaults__ ---> (10, 20) (默认参数)
└── __closure__ ---> (...) (闭包变量)你可以用同一个代码对象创建多个不同的函数对象(虽然通常不这么做)
import types
def original(a):
return a + 1
# 提取代码对象
code = original.__code__
# 用同一个代码对象创建一个新函数,但指定不同的全局环境
new_globals = {'__builtins__': __builtins__}
new_func = types.FunctionType(code, new_globals, "new_func_name")
print(new_func(5)) # 输出: 6
print(new_func.__name__) # 输出: new_func_name8.2.2 反编译代码对象
import dis
def add_and_mul(x, y):
return (x + y) * 2
# 直接反汇编函数(实际上是反汇编它的 __code__)
dis.dis(add_and_mul)
output='''
3 RESUME 0 #用于标记生成器、协程或普通函数的入口点,主要用于调试和异常处理追踪,替代了旧版本中的 GEN_START 或隐式逻辑
4 LOAD_FAST_LOAD_FAST 1 (x, y) #加载两个局部变量
BINARY_OP 0 (+) #执行加法操作。0 代表 + 运算符
LOAD_CONST 1 (2) #将常量 2 压入栈中
BINARY_OP 5 (*) #执行乘法
RETURN_VALUE #返回结果
'''8.2.3 代码对象不可变
代码对象一旦创建,就是不可变的。你不能直接修改某个函数的字节码。如果你想“修改”代码逻辑,必须创建一个新的代码对象(通常通过重新编译源码或使用 replace 方法生成新对象),然后替换函数的 __code__ 属性。
# 修改代码对象的一个属性(例如改变文件名记录,虽然很少见)
# 注意:不能直接修改 co_code,因为它是不可变的,但可以用 replace 创建副本
new_code = my_func.__code__.replace(co_name="modified_name")
# 将新代码对象赋回给函数
my_func.__code__ = new_code
print(my_func.__code__.co_name) # 输出: modified_name8.3 compile函数
compile() 是 Python 的内置函数,用于将源代码字符串动态编译成代码对象(Code Object)
它是连接“源码文本”和“可执行代码”的桥梁。通常我们运行 .py 文件时,Python 解释器会在后台自动调用类似 compile 的过程;而当你需要在运行时动态生成并执行代码(例如实现脚本引擎、评估用户输入、元编程)时,就需要手动使用它。
8.3.1 方法签名
compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1)
核心参数详解:
1 source (str | bytes | AST):
要编译的源代码字符串。
也可以是 ast.AST 对象(如果你先解析成了抽象语法树)。
2 filename (str):
代码来源的文件名。
作用:主要用于报错信息(Traceback)。如果代码出错,错误信息会显示这个文件名。
如果不是从文件读取,通常传 '<string>' 或 '<stdin>'。
3 mode (str) [最重要]:
指定代码的类型,必须是以下三者之一:
'exec': 用于编译一系列语句(如完整的脚本、函数定义、类定义)。返回值是一个可以执行的代码对象。
'eval': 用于编译单个表达式(如 1 + 2, x * y)。返回值是一个表达式对象,执行后返回计算结果。
'single': 用于编译单个交互式语句(类似 Python REPL 的行为)。如果结果是表达式且不为 None,会自动打印结果。
4 flags, dont_inherit, optimize:
高级选项,用于控制编译器行为(如开启优化、未来特性 from __future__ import ... 等),通常保持默认即可。
场景 A:编译并执行一段脚本 (mode='exec')
source_code = """
def greet(name):
return f"Hello, {name}!"
result = greet("World")
print(result)
"""
# 1. 编译
code_obj = compile(source_code, filename='<dynamic_script>', mode='exec')
# 检查类型
print(type(code_obj)) # <class 'code'>
# 2. 执行 (需要提供一个命名空间字典)
global_ns = {}
exec(code_obj, global_ns)
# 现在 global_ns 中有了 greet 函数和 result 变量
print(global_ns['greet']("Python")) # 输出: Hello, Python!场景 B:计算表达式的值 (mode='eval')
当你只需要计算一个数学公式或逻辑表达式,而不需要定义函数或变量时使用
expr = "2 * (3 + 5) ** 2"
# 1. 编译为表达式
code_obj = compile(expr, filename='<expression>', mode='eval')
# 2. 求值 (使用 eval() 函数,而不是 exec())
result = eval(code_obj)
print(result) # 输出: 128
# 也可以传入变量上下文
x = 10
expr_with_var = "x ** 2 + 5"
code_obj2 = compile(expr_with_var, '<var_expr>', 'eval')
print(eval(code_obj2, {"x": x})) # 输出: 105场景 C:模拟交互式命令行 (mode='single')
这种模式常用于实现自定义的 REPL(读取-求值-输出循环)。
# 在交互模式下,输入表达式会自动打印结果,输入赋值则不打印
code1 = compile("10 + 20", '<input>', 'single')
exec(code1)
# 输出: 30 (自动打印了表达式的结果)
code2 = compile("a = 100", '<input>', 'single')
exec(code2)
# 无输出 (赋值语句不打印)8.3.2 核心价值
1 性能优化:
如果你需要重复执行同一段动态生成的代码字符串,先 compile 再 exec/eval 比直接 exec/eval 字符串要快。因为编译过程(词法分析、语法分析、生成字节码)只做了一次,后续执行直接运行字节码。
2 安全性控制(部分):
虽然 eval/exec 本身有风险,但配合 compile 可以做些预处理。例如,你可以先解析成 AST,检查是否有危险操作(如 __import__, open),确认安全后再 compile 执行。
(注意:仅仅使用 compile 并不能阻止恶意代码执行,必须配合沙箱或白名单机制)
3 动态代码生成:
许多框架(如 Django ORM, SQLAlchemy, 模板引擎)会在运行时根据配置动态构建代码字符串,然后编译成代码对象以提高运行效率。
8.4 eval
是 Python 的内置函数,用于动态执行一个字符串形式的 Python 表达式,并返回表达式的计算结果。它的核心特点是:只接受单个表达式(不能包含语句,如 if, for, def 等),且执行结果有返回值
基本语法
eval(source, globals=None, locals=None)
source(必填): 一个字符串,或者编译后的代码对象(必须是表达式)。globals(可选): 一个字典,指定全局命名空间。如果提供,必须是字典类型。locals(可选): 一个映射对象(通常是字典),指定局部命名空间
8.4.1 用法举例
result = eval("1 + 2 * 3")
print(result) # 输出: 7
x = 10
y = 5
# eval 可以访问当前作用域中的变量
result = eval("x + y * 2")
print(result) # 输出: 20
def add(a, b):
return a + b
# 可以在字符串中调用已定义的函数
result = eval("add(3, 4)")
print(result) # 输出: 7
s = "[1, 2, 3]"
lst = eval(s)
print(lst) # 输出: [1, 2, 3]
print(type(lst)) # 输出: <class 'list'>
# 只允许访问 x 和 y,不允许访问 z 或内置函数
allowed_globals = {"x": x, "y": y}
try:
# 这里会报错,因为 z 不在 allowed_globals 中
res = eval("x + y + z", allowed_globals)
except NameError as e:
print(f"错误: {e}")
# 正常执行
res = eval("x + y", allowed_globals)
print(res) # 输出: 3008.4.2 安全问题
永远不要对不可信的用户输入直接使用 eval()!
如果用户输入的字符串包含恶意代码,eval() 会原样执行,可能导致:
- 删除文件 (
eval("os.system('rm -rf /')")) - 窃取敏感数据
- 执行任意系统命令
- 无限循环导致拒绝服务
1 ast.literal_eval(): 如果你只需要解析字符串形式的 Python 字面量(如数字、字符串、列表、字典、元组、布尔值、None),务必使用这个。它比 eval 安全得多,因为它只解析字面量,不执行代码。
2 专门的数学解析库: 如果需要复杂的数学计算,使用 sympy, numexpr 或自己写一个简单的解析器,而不是直接用 eval。
3 严格的沙箱: 如果必须用 eval 处理动态逻辑,必须配合极其严格的 globals/locals 限制(如上文的 {"__builtins__": {}}),但即便如此,仍有绕过风险。
完全沙箱化 eval 非常困难且容易出错。外部不可性输入风险极高。
8.5 exec
exec() 是 Python 的内置函数,用于动态执行存储在字符串或代码对象中的 Python 代码
基本语法
exec(object[, globals[, locals]])
object: 要执行的代码。可以是字符串,也可以是代码对象(由compile()生成)。globals(可选): 一个字典,作为代码执行时的全局命名空间。locals(可选): 一个映射对象(通常是字典),作为代码执行时的局部命名空间
8.5.1 基本用法
用法 A:执行字符串代码(最简单)
code = """
x = 10
y = 20
print(f"Sum: {x + y}")
def greet(name):
return f"Hello, {name}"
message = greet("World")
"""
# 执行代码
exec(code)
# 输出: Sum: 30
# 注意:exec 返回 None
result = exec(code)
print(result) # 输出: None
# 定义的变量和函数会进入当前的局部作用域
print(message) # 输出: Hello, World
print(greet("Python")) # 输出: Hello, Python用法 B:控制命名空间(推荐做法)
code = """
a = 100
b = 200
result = a + b
"""
# 创建一个空字典作为全局命名空间
my_globals = {}
# 在 my_globals 中执行代码
exec(code, my_globals)
# 当前作用域没有 a, b, result
# print(a) # 报错: NameError
# 但它们存在于 my_globals 字典中
print(my_globals['result']) # 输出: 300
print(my_globals['a']) # 输出: 300
print(my_globals.keys()) # 输出: dict_keys(['__builtins__', 'a', 'b', 'result'])用法 C:配合 compile() 使用(高性能)
如果你需要重复执行同一段代码,先编译再 exec 效率更高
source = "for i in range(3): print(i)"
# 1. 编译成代码对象
code_obj = compile(source, '<string>', 'exec')
# 2. 多次执行代码对象
exec(code_obj)
# 输出: 0, 1, 2
exec(code_obj)
# 输出: 0, 1, 2用法 D:动态定义函数或类
这是 exec 最强大的地方,可以在运行时根据字符串生成新的类或函数。
class_code = """
class DynamicClass:
def __init__(self, value):
self.value = value
def show(self):
return f"Value is {self.value}"
"""
namespace = {}
exec(class_code, namespace)
# 从命名空间中获取生成的类
DynamicClass = namespace['DynamicClass']
obj = DynamicClass(42)
print(obj.show()) # 输出: Value is 428.5.2 globals 和 locals 的陷阱
在函数内部执行时,如果 locals 是一个普通的字典,代码中定义的局部变量可能不会更新到这个字典中(取决于 Python 版本和优化级别)。
最佳实践:如果你需要读取执行后的变量,通常只传一个字典给 globals 参数,并让 locals 默认为与 globals 相同,或者干脆不传 locals
# 安全且通用的写法
namespace = {}
exec("y = 20", namespace)
print(namespace['y']) # 可靠地输出 208.5.3 文件参数
# script.py
x = 100
y = 200
result = x + y
print(f"计算结果: {result}")
def say_hello():
return "Hello from file!"
# main.py
# 1. 打开文件对象 (使用 'r' 模式读取)
with open('script.py', 'r') as f:
# 2. 直接将文件对象传给 exec
exec(f)
# 3. 执行后,script.py 中的变量和函数现在存在于当前作用域中
print(result) # 输出: 300
print(say_hello()) # 输出: Hello from file!可以使用f.seek,f.tell等文件方法
8.5.4 安全问题
有类似eval安全问题
8.5.5 与eval对比
| 特性 | exec() |
eval() |
|---|---|---|
| 输入类型 | 语句块 (Statements) | 表达式 (Expression) |
| 示例内容 | if..., def..., x=1, import os |
1+1, "hi", func(x) |
| 返回值 | 总是 None |
表达式的计算结果 |
| 主要用途 | 动态生成类/函数、运行脚本片段 | 动态计算数值、解析配置公式 |
| 安全性 | 极高危 (可执行任意操作) | 高危 (但仍受限于表达式) |
8.6 input
由于 input() 总是返回字符串,如果你需要数字进行计算,必须手动转换类型,否则会报错或得到奇怪的结果(例如字符串拼接)
相当于raw_input和eval
# ❌ 错误示范:直接相加会变成字符串拼接
age_str = input("请输入年龄: ") # 用户输入 18
#next_year = age_str + 1 # 报错: TypeError (不能把 str 和 int 相加)
# 或者如果是两个输入: "1" + "1" = "11" 而不是 2
# ✅ 正确示范:强制类型转换
age = int(input("请输入年龄: ")) # 转换为整数
height = float(input("请输入身高: ")) # 转换为浮点数
next_year_age = age + 1
print(f"明年你将是 {next_year_age} 岁")8.7 os.system(不推荐)
用于在当前进程中启动一个子进程来执行系统命令(shell 命令)
import os
# Linux/Mac: 列出当前目录文件
# Windows: 可以使用 "dir"
ret = os.system("ls -l")
if ret == 0:
print("命令执行成功")
else:
print(f"命令执行失败,退出码: {ret}")8.8 os.fork(不推荐)
现代 Python 应用开发中,绝大多数情况下都不推荐直接使用它。
1 “一次调用,两次返回”:代码执行流突然分叉,需要写 if pid == 0: ... else: ...,逻辑容易混乱。
2 内存共享的陷阱:子进程复制了父进程的所有变量,修改数据时容易让人困惑(是改了自己的副本还是共同的?)。
3 资源泄露风险:忘记 wait() 会产生僵尸进程;文件描述符继承可能导致锁死或数据错乱。
4 多线程灾难:在多线程程序中 fork 极易导致死锁(只复制了当前线程,其他线程持有的锁在子进程中永远无法释放)。
5 跨平台不可用:Windows 直接报错,代码无法移植。
8.9 subprocess
官方唯一标准:它是 Python 标准库的一部分,无需安装,跨所有平台(Windows, Linux, macOS)。
安全性最高:支持以列表形式传递参数(['ls', '-l']),彻底杜绝 Shell 注入攻击(这是 os.system 的最大痛点)。
功能最全:
2 同时捕获 stdout 和 stderr。
2 设置超时时间 (timeout),防止命令卡死。
3 处理输入输出流 (stdin, stdout, PIPE)。
4 获取精确的退出码 (returncode)。
5 灵活性强:既可以用简单的 run() 一键执行,也可以用 Popen() 进行复杂的流式控制
8.9.1 基本执行
import subprocess
try:
# check=True: 如果命令返回非零退出码,自动抛出 CalledProcessError
# capture_output=True: 捕获 stdout 和 stderr
# text=True: 返回字符串而不是字节 (bytes)
result = subprocess.run(
["git", "status"],
check=True,
capture_output=True,
text=True
)
print("输出:\n", result.stdout)
except subprocess.CalledProcessError as e:
print(f"命令执行失败: {e}")
print("错误信息:", e.stderr)8.9.2 超时设置
import subprocess
try:
# timeout=5: 5秒没跑完就杀掉进程并抛出 TimeoutExpired
result = subprocess.run(
["ping", "-c", "10", "google.com"],
timeout=5,
capture_output=True,
text=True
)
except subprocess.TimeoutExpired:
print("命令执行超时!")8.9.3 实时查看输出
import subprocess
# 逐行读取输出
proc = subprocess.Popen(
["ping", "-c", "5", "8.8.8.8"],
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
text=True,
bufsize=1 # 行缓冲
)
for line in proc.stdout:
print(f"实时日志: {line}", end='')
proc.wait()8.9.4 安全问题
# 错误写法
# 如果 user_input 是 "; rm -rf /",整个系统可能被清空!
cmd = f"ls -l {user_input}"
subprocess.run(cmd, shell=True) # 极度危险!
# 正确写法
# 参数作为列表传递,shell 不会解析特殊字符
subprocess.run(["ls", "-l", user_input]) 8.10 结束执行
8.10.1 sys.exit
这是官方推荐的用于“主动终止程序”的方法。
- 机制:抛出
SystemExit异常。如果这个异常没有被捕获,解释器就会退出。 - 参数:
0或None:表示成功退出。- 非零整数:表示出错退出(Shell 中可以通过
$?获取该状态码)。 - 字符串/对象:会将内容打印到 stderr 并作为错误退出。
- 优点:
- 允许清理:因为它本质是异常,所以会被
try...finally捕获,确保资源被清理。 - 可被拦截:在测试或特殊框架中,可以捕获
SystemExit来阻止程序真的退出。
- 允许清理:因为它本质是异常,所以会被
import sys
error_condition=1
try:
if error_condition:
print("发生错误,准备退出")
sys.exit(1) # 抛出异常
finally:
print("这里一定会执行,进行清理工作")8.10.2 os.exit(n)
这是底层级的“核按钮”,通常只在子进程中使用。
- 机制:直接调用操作系统的
_exit系统调用。不抛异常,不执行任何清理。 - 特点:
- ❌ 不执行
finally块。 - ❌ 不执行
atexit钩子。 - ❌ 不刷新 缓冲区(可能导致
print的内容丢失)。 - ❌ 不关闭 打开的文件。
- ❌ 不执行
- 适用场景:
- 多进程 (
os.fork) 的子进程中:防止子进程的清理逻辑干扰父进程(例如刷新父进程的文件缓冲区导致数据重复写入)。 - 程序已经严重损坏(如死锁、内存破坏),无法执行正常的清理逻辑时
- 多进程 (
import os
pid = os.fork()
if pid == 0:
# 子进程
do_work()
os._exit(0) # 必须用这个,不能用 sys.exit
else:
# 父进程
os.wait()注意os.fork不推荐使用
8.10.3 操作系统信号 (外部终止)
由外部发送信号给进程。
- 方式:
Ctrl + C:发送SIGINT信号(默认行为是退出)。kill <pid>:发送SIGTERM(默认) 或SIGKILL(-9)。
- Python 中的处理:
- 可以使用
signal模块捕获这些信号进行优雅退出
- 可以使用
import signal
import sys
def handler(sig, frame):
print("\n收到中断信号,正在保存数据...")
save_data()
sys.exit(0)
signal.signal(signal.SIGINT, handler)
while True:
pass8.10.3 抛出未捕获异常
让程序因为错误而崩溃。
- 机制:抛出异常且未被
try...except捕获,解释器打印堆栈跟踪 (Traceback) 后退出。 - 特点:
- 退出码通常为 1。
- 会打印详细的错误信息。
finally块依然会执行。
- 评价:这是错误处理的结果,而不是控制流程的手段。不要故意写
raise Exception("Exit")来退出程序,这会让日志充满噪音。
8.11 python命令参数
基本格式:
python [解释器选项] 脚本文件.py [脚本参数]
8.11.1 基本格式(相当重要)
| 参数 | 全称 | 作用 | 典型场景 |
|---|---|---|---|
| -m | --module |
以模块方式运行。告诉 Python 去 sys.path 里找模块名而不是文件。 |
python -m pip install ...python -m http.serverpython -m unittest test.py |
| -u | --unbuffered |
强制标准输出/错误不缓冲。确保 print 的内容立即显示,不存缓冲区。 |
Docker 日志、CI/CD 流水线中防止日志丢失或延迟。 |
| -O | --optimize |
优化模式。移除 assert 断言,移除 __debug__ 为真的代码块。生成 .pyo (旧版) 或不生成 .pyc。 |
生产环境部署,稍微提升启动速度,减小体积。 |
| -OO | (双重优化) | 深度优化。除了 -O 的功能外,还会丢弃 __doc__ 文档字符串。 |
极度精简的生产环境。 |
| -B | --dont-write-bytecode |
不生成 .pyc 文件。阻止 Python 在 __pycache__ 目录下创建编译后的字节码文件。 |
只读文件系统、Docker 构建层优化、不想产生垃圾文件时。 |
| -i | --interactive |
交互模式。脚本执行完毕后,不退出,直接进入 Python 交互式命令行 (REPL)。 | 调试脚本:运行完脚本后,检查变量状态 (python -i script.py)。 |
| -c | --command |
执行字符串命令。直接运行引号内的 Python 代码,不需要文件。 | python -c "print('Hello')"python -c "import sys; print(sys.version)" |
| -V / -version | --version |
打印版本号。显示 Python 版本并退出。 | 检查环境:python -V |
| -h / -help | --help |
显示帮助。列出所有可用的解释器选项。 | 忘记参数时查询:python -h |
注意:大型的python项目都是以模块形式组织,所以执行时要加m,不加参数是以脚本方式执行,模块查找要出问题
8.11.2 进阶选项
| 参数 | 作用 | 典型场景 |
|---|---|---|
| -X | 设置特定的实现选项。 | python -X faulthandler (崩溃时打印堆栈)python -X dev (开启开发模式,检查资源泄漏) |
| -W | 控制警告行为 (Warning control)。 | python -W error (将警告视为错误)python -W ignore::DeprecationWarning (忽略特定警告) |
| -s | 不添加用户站点包目录 (site-packages)。 |
隔离环境,确保不使用用户全局安装的包。 |
| -E | 忽略所有环境变量 (如 PYTHONPATH, PYTHONHOME)。 |
确保脚本在纯净环境下运行,不受用户配置干扰。 |
| -S | 不自动导入 site 模块。 |
极特殊的启动定制,普通用户很少用。 |
| -b | 对 bytes 和 str 混合操作发出警告 (-b) 或报错 (-bb)。 |
迁移 Python 2 到 3 的代码,检查类型混合问题。 |
8.12 multiprocessing
8.12.1 Process
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
group |
None |
None |
保留参数。必须为 None,用于兼容 threading 模块,无实际作用。 |
target |
callable |
None |
目标函数。这是子进程启动后要执行的可调用对象(函数)。 ⚠️ 如果为 None,则必须重写 Process 类的 run() 方法。 |
name |
str |
None |
进程名称。用于标识进程(显示在日志或调试工具中)。 默认为 Process-N(N 是递增整数)。 |
args |
tuple |
() |
位置参数元组。传递给 target 函数的位置参数。即使只有一个参数,也必须加逗号,例如 args=(1,)。 |
kwargs |
dict |
{} |
关键字参数字典。传递给 target 函数的关键字参数。例如 kwargs={'x': 10, 'y': 20}。 |
daemon |
bool |
None |
守护进程标志。 - True: 主进程退出时,子进程会被强制终止。- False: 主进程会等待子进程结束。- None (默认): 继承父进程的 daemon 状态(通常主进程为 False)。 |
相关属性
import multiprocessing
import time
import os
def worker():
print(f"[子进程] 开始运行。PID: {os.getpid()}, 名称: {multiprocessing.current_process().name}")
time.sleep(2)
print(f"[子进程] 准备退出。")
# 可以通过 sys.exit(5) 设置特定的退出码
if __name__ == '__main__':
# 1. 创建进程
p = multiprocessing.Process(target=worker, name="MyWorker-01")
# 2. 查看启动前的属性
print(f"启动前 -> Name: {p.name}, PID: {p.pid}, Exitcode: {p.exitcode}, Daemon: {p.daemon}")
# 3. 设置守护进程 (必须在 start 之前)
p.daemon = True # 如果设为 True,主程序结束它会立刻被杀
# 4. 启动进程
p.start()
# 5. 查看启动后的属性
print(f"启动后 -> Name: {p.name}, PID: {p.pid}, Exitcode: {p.exitcode}")
# 6. 等待进程结束 (如果设置了 daemon=True,注释掉这行,主程序会直接结束并杀掉子进程)
p.join()
# 7. 查看结束后的属性
print(f"结束后 -> Name: {p.name}, PID: {p.pid}, Exitcode: {p.exitcode}")
print("主程序结束。")from multiprocessing import Process
import os
def worker(name, value):
print(f"进程 {name} (PID: {os.getpid()}) 开始工作,接收值: {value}")
# 模拟耗时任务
import time
time.sleep(1)
print(f"进程 {name} 完成")
if __name__ == '__main__':
# Windows/macOS 必须加这个保护,否则会导致无限递归创建进程
processes = []
for i in range(3):
# target: 目标函数, args: 参数元组
p = Process(target=worker, args=(f"Worker-{i}", i * 10))
p.start()
processes.append(p)
# 等待所有进程结束
for p in processes:
p.join()
print("✅ 所有子进程结束")if __name__ == '__main__'::在 Windows 和 macOS (spawn 模式) 上必须加这个判断。因为子进程会重新导入主模块,如果没有这个保护,子进程会再次执行创建进程的代码,导致无限循环爆炸。- 参数传递:通过
args或kwargs传递数据。数据会被序列化 (pickle) 后复制给子进程(内存隔离)。
继承 Process 类
如果你的任务逻辑很复杂,需要维护内部状态,或者需要重写 run、terminate 等行为,可以继承 Process 类。
适用场景:
- 任务逻辑封装在类中。
- 需要访问类的属性或方法。
- 类似
threading.Thread的子类用法。
from multiprocessing import Process
import time
class MyWorker(Process):
def __init__(self, task_id):
super().__init__()
self.task_id = task_id
def run(self):
# 这里是子进程执行的入口
print(f"任务 {self.task_id} 在进程 {self.pid} 中运行")
time.sleep(1)
print(f"任务 {self.task_id} 完成")
if __name__ == '__main__':
workers = []
for i in range(3):
p = MyWorker(i)
p.start()
workers.append(p)
for p in workers:
p.join()8.12.2 Pool
如果你有一堆相似的任务(例如处理 1000 张图片、计算 10000 个数据),手动创建 1000 个进程会耗尽系统资源。Pool 可以限制最大并发进程数,并自动分配任务。
适用场景:
- Map-Reduce 风格:对列表中的每个元素执行相同函数。
- 需要控制最大并发数(如限制为 CPU 核心数)。
- 希望自动管理进程的生命周期
multiprocessing.Pool(
processes=None,
initializer=None,
initargs=(),
maxtasksperchild=None,
context=None
)构造器参数说明
| 参数名 | 类型 | 默认值 | 详细说明 |
|---|---|---|---|
processes |
int |
None |
进程池中的工作进程数量。 - 如果为 None (默认),则使用 os.cpu_count() 返回的 CPU 核心数。- 建议:通常设置为 CPU 核心数。如果是 I/O 密集型任务,可以适当调大;如果是纯 CPU 密集型,不要超过核心数太多,否则上下文切换会降低性能。 |
initializer |
callable |
None |
初始化函数。每个工作进程启动时都会执行一次此函数。 常用于: 1. 初始化全局变量(因为子进程是复制内存,无法共享父进程的全局变量)。 2. 建立数据库连接或打开文件句柄(避免在父进程打开后直接传给子进程导致锁问题)。 |
initargs |
tuple |
() |
传递给 initializer 函数的参数元组。 |
maxtasksperchild |
int |
None |
每个工作进程执行的任务上限。 - None (默认):进程会一直存活,直到池关闭。- 设置为整数 N:当某个进程执行完 N 个任务后,它会被终止并替换为一个新进程。用途:防止内存泄漏。如果任务函数中有轻微的内存泄漏,定期重启进程可以释放内存。 |
context |
context |
None |
指定用于创建池的上下文(如 'fork', 'spawn', 'forkserver')。通常保持默认即可,除非你有特定的跨平台兼容性需求。 |
pool方法
| 方法 | 阻塞/非阻塞 | 返回值 | 说明 |
|---|---|---|---|
map(func, iterable) |
阻塞 | list |
将 iterable 中的数据分块发送给进程,按输入顺序返回结果列表。如果其中一个任务报错,整个调用会抛出异常。 |
imap(func, iterable) |
非阻塞 (迭代器) | iterator |
返回一个迭代器。结果按完成顺序(或接近顺序)产生,无需等待所有任务完成即可开始处理结果。节省内存。 |
imap_unordered(func, iterable) |
非阻塞 (迭代器) | iterator |
类似 imap,但结果完全无序,哪个先做完哪个先返回。性能通常略高于 imap。 |
apply_async(func, args) |
非阻塞 | AsyncResult |
提交单个任务。立即返回一个 AsyncResult 对象。可以通过 .get() 获取结果(可设超时),或注册回调函数 .apply(callback)。 |
map_async(func, iterable) |
非阻塞 | AsyncResult |
map 的异步版本。返回 AsyncResult,稍后调用 .get() 获取完整列表。 |
close() |
- | None |
告诉池不再接受新任务。调用后不能再提交任务,但已提交的任务会继续执行。 |
join() |
阻塞 | None |
等待所有工作进程结束。必须在 close() 或 terminate() 之后调用。 |
terminate() |
- | None |
强制停止所有工作进程,不等待任务完成。慎用,可能导致资源未释放。 |
代码示例
from multiprocessing import Pool, cpu_count
import time
def square(x):
time.sleep(0.5)
return x * x
if __name__ == '__main__':
data = [1, 2, 3, 4, 5, 6, 7, 8]
# 默认进程数 = CPU 核心数
# 也可以指定:Pool(processes=4)
with Pool(processes=cpu_count()) as pool:
# 方法 A: map (阻塞,按顺序返回结果)
# results = pool.map(square, data)
# 方法 B: imap (迭代器,结果出来一个yield一个,节省内存)
# results = list(pool.imap(square, data))
# 方法 C: apply_async (异步,最灵活,适合不同参数或回调)
async_results = [pool.apply_async(square, args=(x,)) for x in data]
# 获取结果 (get() 会阻塞直到该任务完成)
results = [r.get() for r in async_results]
print(f"计算结果: {results}")关键注意事项
-
if __name__ == '__main__':保护:
在 Windows 和 macOS 上,必须将Pool的创建和使用代码放在if __name__ == '__main__':块内。否则,子进程导入模块时会递归创建新的进程池,导致无限循环崩溃。 -
可序列化对象 (Picklability):
传递给Pool的func、args以及返回值都必须能被pickle序列化。- ❌ 不能传递:
lambda函数、局部定义的函数、类方法(在某些旧版本或特定配置下)、打开的文件句柄、锁对象。 - ✅ 推荐:在模块顶层定义的普通函数。
- ❌ 不能传递:
-
进程数量选择:
- CPU 密集型:
processes = os.cpu_count()是最佳实践。过多会导致频繁的上下文切换,降低效率。 - I/O 密集型:如果任务主要是等待网络或磁盘,可以设置
processes大于 CPU 核心数(例如 2 倍或 4 倍),因为进程在等待时会释放 CPU。但在这种情况下,使用threading或asyncio可能更合适。
- CPU 密集型:
-
异常处理:
如果在子进程中发生异常,map会在主进程中重新抛出该异常(通常是RemoteTraceback包装后的异常)。使用apply_async时,异常会在调用.get()时抛出。
9 正则表达式
Python 的正则表达式功能由标准库 re 模块提供。它的语法风格主要基于 Perl 5,功能非常强大,用于字符串的匹配、查找、替换和分割。
9.1 元字符
这些字符在正则中有特殊含义,如果要匹配它们本身,需要使用反斜杠 \ 转义(例如匹配真实的 . 需写为 \.)
| 字符 | 含义 | 示例 | 匹配内容 |
|---|---|---|---|
. |
匹配除换行符以外的任意单个字符 | a.c |
"abc", "axc", "a $ c" |
^ |
匹配字符串的开头 | ^Hello |
"Hello world" (匹配开头) |
$ |
匹配字符串的结尾 | world$ |
"Hello world" (匹配结尾) |
* |
匹配前一个字符 0 次或多次 | ab* |
"a", "ab", "abb", "abbb" |
+ |
匹配前一个字符 1 次或多次 | ab+ |
"ab", "abb" (不匹配 "a") |
? |
匹配前一个字符 0 次或 1 次 | colou?r |
"color", "colour" |
{m,n} |
匹配前一个字符 m 到 n 次 | a{2,4} |
"aa", "aaa", "aaaa" |
[] |
字符集,匹配括号内的任意一个字符 | [aeiou] |
任意元音字母 |
| ` | ` | 或 操作,匹配左边或右边的表达式 | `cat |
() |
分组,将多个字符视为一个单元,也可用于捕获 | (ab)+ |
"ab", "abab" |
\ |
转义符,取消特殊含义或表示特殊序列 | \d, \. |
数字, 真实的点号 |
9.2 预定义字符集
以 \ 开头的常用简写形式
| 序列 | 含义 | 等价写法 |
|---|---|---|
\d |
匹配任意数字 | [0-9] |
\D |
匹配任意非数字 | [^0-9] |
\w |
匹配字母、数字或下划线 | [a-zA-Z0-9_] |
\W |
匹配非字母、数字或下划线 | [^a-zA-Z0-9_] |
\s |
匹配任意空白字符 (空格, tab, 换行等) | [ \t\n\r\f\v] |
\S |
匹配任意非空白字符 | [^ \t\n\r\f\v] |
\b |
匹配单词边界 (单词的开始或结束) | \bword\b 匹配独立的 "word" |
\A |
仅匹配字符串绝对开头 (不受多行模式影响) 同^ | - |
\Z |
仅匹配字符串绝对结尾 同$ | - |
9.3 匹配模式
贪婪与非贪婪匹配
默认情况下,量词(*, +, ?, {m,n})是贪婪的,即尽可能多地匹配字符。在量词后加 ? 可变为非贪婪(最小匹配)。
贪婪: <.*> 在字符串 "<div>hello</div>" 中会匹配整个字符串 "<div>hello</div>"。
非贪婪: <.*?> 在上述字符串中会先匹配 "<div>",再匹配 "</div>"。
9.4 常用函数
在使用前需导入:import re
| 函数 | 描述 | 返回值 |
|---|---|---|
re.match(pattern, string) |
从字符串开头开始匹配。如果开头不符合,直接返回 None。 | Match 对象 或 None |
re.search(pattern, string) |
扫描整个字符串,返回第一个匹配项。 | Match 对象 或 None |
re.findall(pattern, string) |
找到字符串中所有匹配项,返回列表。 | 列表 ['match1', 'match2'] |
re.finditer(pattern, string) |
找到所有匹配项,返回一个迭代器(节省内存)。 | 迭代器 (包含 Match 对象) |
re.sub(pattern, repl, string) |
将匹配到的部分替换为 repl。 |
替换后的新字符串 |
re.split(pattern, string) |
根据正则模式分割字符串。 | 列表 |
re.compile(pattern) |
将正则字符串编译成对象,可重复使用,效率更高。 | Pattern 对象 |
match像startWith,所以一般查找用search
9.4.1 match
从开始匹配,所以不需要^开头.如果字符串包含换行符,且你想让 match 匹配每一行的开头,需要配合 re.MULTILINE (re.M) 标志,但要注意 match 始终只匹配整个字符串的起始位置,即使加了 re.M,match 也不会去匹配第二行的开头。
| 方法 | 描述 | 示例 |
|---|---|---|
.group() |
返回匹配到的完整字符串 | result.group() |
.start() |
返回匹配开始的索引(对于 match 通常是 0) | result.start() |
.end() |
返回匹配结束的索引 | result.end() |
.span() |
返回 (start, end) 元组 |
result.span() |
.groups() |
返回所有捕获分组 () 的内容元组 |
见下文示例 |
import re
text = "Python is great"
# 模式以 "Python" 开头,文本也是以 "Python" 开头 -> 匹配成功
result = re.match(r"Python", text)
if result:
print("匹配成功:", result.group()) # 输出: Python
print("start:", result.start()) #start: 0 必然是0
print("end:", result.end()) # end: 6
print("span:", result.span()) # (0,6)
else:
print("匹配失败")import re
text = "2024-03-24"
# 使用 () 创建分组:年、月、日
pattern = r"(\d{4})-(\d{2})-(\d{2})"
result = re.match(pattern, text)
if result:
print("完整匹配:", result.group()) # 2024-03-24
print("第一组 (年):", result.group(1)) # 2024
print("第二组 (月):", result.group(2)) # 03
print("所有分组:", result.groups()) # ('2024', '03', '24')9.4.2 search
re.search() 找到第一个符合条件的子串后就会立即停止,不会继续寻找后面的匹配项
import re
text = "Order ID: A-1001 was placed on 2026-03-24 user_admin."
# 正则解释:
# (A-\d+) -> 第1组:订单号
# .*? -> 非贪婪匹配中间内容
# (\d{4}-\d{2}-\d{2}) -> 第2组:日期
# (\w+) -> 第3组:用户名
pattern = r"(A-\d+).*?(\d{4}-\d{2}-\d{2}).*?(\w+)"
match_obj = re.search(pattern, text)
if match_obj:
# --- 基础获取 ---
print("1. 完整匹配 (.group()):", match_obj.group())
# 输出: Order ID: A-1001 was placed on 2026-03-24 by user_admin (注意:这里取决于正则是否覆盖了整句,通常只覆盖匹配部分)
# 修正:上面的正则只匹配 "A-1001 ... user_admin" 部分
# 实际输出: A-1001 was placed on 2026-03-24 by user_admin
# --- 分组获取 ---
print("2. 订单号 (.group(1)):", match_obj.group(1)) # A-1001
print("3. 日期 (.group(2)):", match_obj.group(2)) # 2026-03-24
print("4. 用户 (.group(3)):", match_obj.group(3)) # user_admin
# --- 位置信息 ---
print("5. 整体起始 (.start()):", match_obj.start()) # 10 (假设 "A" 在索引 10)
print("6. 日期起始 (.start(2)):", match_obj.start(2)) # 日期开始的索引
print("7. 整体范围 (.span()):", match_obj.span()) # (10, 55)
# --- 批量获取 ---
print("8. 所有组元组 (.groups()):", match_obj.groups())
# 输出: ('A-1001', '2026-03-24', 'user_admin')
else:
print("未找到匹配")9.4.5 findall用法
re.findall() 会扫描整个字符串,找到所有符合正则模式的子串,并将它们放入一个列表中返回。如果没有找到任何匹配,则返回空列表 []
import re
text = "Order A-100 on 2026-01-01; Order B-200 on 2026-02-02; Order C-300 on 2026-03-03"
# 组1: 订单号 (A-\d+)
# 组2: 日期 (\d{4}-\d{2}-\d{2})
pattern = r"([A-Z]-\d+).*?(\d{4}-\d{2}-\d{2})"
result = re.findall(pattern, text)
print(result)
# 输出: [('A-100', '2026-01-01'), ('B-200', '2026-02-02'), ('C-300', '2026-03-03')]
# 类型: 列表中包含元组
# 如何遍历?
for order_id, date in result:
print(f"订单 {order_id} 的日期是 {date}")
output='''
[('A-100', '2026-01-01'), ('B-200', '2026-02-02'), ('C-300', '2026-03-03')]
订单 A-100 的日期是 2026-01-01
订单 B-200 的日期是 2026-02-02
订单 C-300 的日期是 2026-03-03
'''返回值
| 正则表达式模式 | 示例 | 返回值类型结构 | 示例输出 |
|---|---|---|---|
| 无括号 | r"\d+" |
List[str] |
['1', '23'] |
| 1 个括号 | r"(\d+)" |
List[str] |
['1', '23'] |
| 2+ 个括号 | r"(\d)(\d)" |
List[Tuple[str, ...]] |
[('1', ''), ('2', '3')] |
| 无匹配 | (任何不匹配的正则) | List (空) |
[] |
9.4.6 sub
re.sub(pattern, repl, string, count=0, flags=0)
| 参数 | 含义 | 说明 |
|---|---|---|
pattern |
正则模式 | 要查找的模式(字符串或编译后的正则对象)。 |
repl |
替换内容 | 可以是字符串,也可以是函数。 |
string |
原字符串 | 需要被处理的原始文本。 |
count |
替换次数 | 默认为 0(表示替换所有匹配项)。如果设为 1,只替换第一个。 |
flags |
标志位 | 如 re.IGNORECASE (忽略大小写) 等。 |
场景一:简单字符串替换
将匹配到的内容直接替换为固定字符串。
import re
text = "Order A-100 and Order B-200"
# 将所有 "Order [字母]-[数字]" 替换为 "订单"
result = re.sub(r"Order [A-Z]-\d+", "订单", text)
print(result)
# 输出: 订单 and 订单场景二:使用反向引用(保留部分内容)
在替换字符串中,可以使用 \1, \2 来引用正则中括号捕获组的内容。
\1代表第一个括号()匹配的内容。\2代表第二个括号()匹配的内容。
import re
text = "2026-03-24"
# 将 "年-月-日" 格式转换为 "年/月/日"
# (\d{4}) 是组1, (\d{2}) 是组2, (\d{2}) 是组3
result = re.sub(r"(\d{4})-(\d{2})-(\d{2})", r"\1/\2/\3", text)
print(text)
print(result) # 输出: 2026/03/24场景三:使用函数进行动态替换
当替换逻辑比较复杂(比如需要计算、判断、格式化)时,repl 参数可以传入一个函数。
- 该函数接收一个 Match 对象 作为参数。
- 函数必须返回一个字符串,作为替换内容。
import re
text = "价格: 100元, 折扣价: 200元"
def double_price(match):
# match.group(0) 是完整匹配的内容 (如 "100元")
# match.group(1) 是第一个括号的内容 (如 "100")
num_str = match.group(1)
num = int(num_str)
new_num = num * 2
return f"{new_num}元"
# 正则只捕获数字部分,但匹配的是 "数字+元"
# 这里的函数会对每一个匹配项执行一次
result = re.sub(r"(\d+)元", double_price, text)
print(result) # 输出: 价格: 200元, 折扣价: 400元场景四:限制替换次数
只替换前 N 个匹配项。
import re
text = "cat dog cat dog cat"
# 只替换前 2 个 "cat" 为 "mouse"
result = re.sub(r"cat", "mouse", text, count=2)
print(result)
# 输出: mouse dog mouse dog cat9.4.7 split
e.split() 是正则表达式中用于分割字符串的函数。它比标准的 string.split() 更强大,因为它允许你使用正则表达式作为分隔符,从而处理复杂的分割场景(例如:同时用逗号、分号或空格分割)
re.split(pattern, string, maxsplit=0, flags=0)
场景一:多分隔符分割
当文本中包含多种分隔符(如逗号、分号、空格混用)时,标准 split 很难处理,而 re.split 可以轻松搞定。
import re
text = "apple,banana;orange grape,melon"
# 分隔符是:逗号、分号 或 空格
# 正则: [,;\s]+ 表示匹配一个或多个逗号、分号或空白字符
result = re.split(r"[,;\s]+", text)
print(result)
# 输出: ['apple', 'banana', 'orange', 'grape', 'melon']场景二:限制分割次数
只切前 N 刀,剩下的部分保持原样放在最后一个元素中。
import re
text = "A,B,C,D,E"
# 只切 2 刀(遇到前两个逗号就停)
result = re.split(r",", text, maxsplit=2)
print(result)
# 输出: ['A', 'B', 'C,D,E']场景三:保留分隔符
如果在正则模式中使用了捕获组 (),那么分隔符本身也会被保留在结果列表中。
import re
text = "one,two;three four"
# 注意括号:([,;\s]+) 把分隔符也捕获了
result = re.split(r"([,;\s]+)", text)
print(result)
# 输出: ['one', ',', 'two', ';', 'three', ' ', 'four']
# 解释:数据和分隔符交替出现场景四:处理空字符串
如果分隔符出现在字符串开头、结尾,或者连续出现,默认会产生空字符串 ''
import re
text = ",apple,,banana,"
# 简单分割
result = re.split(r",", text)
print(result)
# 输出: ['', 'apple', '', 'banana', ''] (包含空串)
# 优化:过滤掉空串
result_clean = [x for x in re.split(r",", text) if x]
print(result_clean)
# 输出: ['apple', 'banana']9.5 匹配标志
作为函数的第三个参数传入,或用 (?...) 写在正则内部。
re.I或re.IGNORECASE: 忽略大小写。re.M或re.MULTILINE: 多行模式。^和$不仅匹配字符串首尾,还匹配每一行的首尾(针对\n)。re.S或re.DOTALL: 让.也能匹配换行符。re.X或re.VERBOSE: 允许正则表达式中包含空白和注释,提高可读性
10 多线程
多线程目的是为了提高并发处理能力,线程比进程更轻量级。对于单cpu,多线程是通过分配时间片实现并发,对多cpu才能实现真正并发(同时执行)。
在 Python 3(特指最主流的 CPython 实现)中,全局解释器锁(Global Interpreter Lock,简称 GIL) 是一个互斥锁,它确保在任何时刻,只有一个线程能够执行 Python 字节码。结合当前时间(2026年3月),关于 GIL 的最新状态和核心要点如下:
1. 核心机制与影响
- 工作原理:即使你的机器有多个 CPU 核心,对于同一个 Python 进程内的多个线程,GIL 会强制它们排队执行。同一时刻,只有一个线程在“跑”代码。
- 主要影响:
- CPU 密集型任务(如复杂计算、图像处理):多线程无法利用多核优势,性能甚至可能不如单线程(因为多了锁的切换开销)。
- I/O 密集型任务(如网络请求、文件读写):影响较小。因为线程在等待 I/O 时会主动释放 GIL,其他线程可以趁机执行。
2. 2026年的最新现状(重要更新)
根据搜索结果和 Python 社区的最新进展,截至 2026 年初:
- 默认状态:在标准的 Python 3.13 及之前的版本中,GIL 依然是默认开启的,以保证最大的兼容性和稳定性。
- “无 GIL”版本的进展:
- Python 3.13 引入了实验性的“自由线程”(Free-threading)构建选项(通过
--disable-gil编译),允许用户在编译时选择移除 GIL。 - Python 3.14(预计 2025 年底发布,2026 年广泛使用)标志着重大转折。官方正在推动将“无 GIL”模式从实验性转为正式支持。这意味着开发者可以选择安装一个没有 GIL 的 Python 版本,从而实现真正的多线程并行计算。
- 注意:这并不意味着 GIL 被彻底“删除”了。为了兼容性,官方可能依然提供带 GIL 的标准版本,而“无 GIL”作为一个可选构建或特定模式存在。许多第三方 C 扩展库在 2026 年仍在适配线程安全的过程中。
- Python 3.13 引入了实验性的“自由线程”(Free-threading)构建选项(通过
3. 为什么 GIL 长期存在?
- 内存管理简化:CPython 使用引用计数进行内存管理,GIL 避免了多线程修改引用计数时的复杂锁竞争和数据损坏风险。
- C 扩展兼容性:大量现有的 C 语言扩展库依赖 GIL 来保证线程安全,移除 GIL 需要整个生态系统的重构。
4. 如何在 2026 年绕过 GIL 限制?
如果你需要利用多核性能,目前有以下几种成熟方案:
| 方案 | 适用场景 | 说明 |
|---|---|---|
多进程 (multiprocessing) |
CPU 密集型 | 最稳妥的方案。每个进程有独立的解释器和内存空间,不受 GIL 限制,可跑满多核。 |
| 无 GIL 构建版 | CPU 密集型 & 多线程需求 | 使用 Python 3.13+/3.14+ 的 --disable-gil 编译版本。注意:需确认所有依赖库都支持线程安全。 |
| 其他解释器 | 特定场景 | 使用 Jython (运行在 JVM 上) 或 IronPython (.NET),它们没有 GIL。或者关注 PyPy 的 STM 分支(软件事务内存)。 |
| C/C++/Rust 扩展 | 高性能计算 | 将计算密集型代码写成 C 扩展或 Rust (通过 PyO3),并在代码中显式释放 GIL (Py_BEGIN_ALLOW_THREADS)。 |
异步 IO (asyncio) |
I/O 密集型 | 虽然不解决 CPU 并行问题,但在高并发网络服务中是比多线程更高效的选择。 |
因为python在AI领域的应用处于领先地位,生态越来越复杂,研究有余,工程化能力不足,所以在想尽办法来弥补缺点。如果前期不考虑好,就会留下一堆烂摊子。需要工程化,如果有更好的选择,最好不要选择脚本语言。
10.1 threading 模块
threading 是一个比较推荐的模块,语法和java比较像,很多用脚本语言的都在吐槽java、c++之类的面向对象强类型语言不够灵活,但是所有都在往这方面靠,理由不言而喻。
早期有个thread模块,但是一看api就很奇怪,不推荐使用了。threading 和Java中的并发工具包非常像
主要功能组件:
Thread类:用于创建和启动线程。Lock/RLock:互斥锁,用于保护共享数据,防止竞态条件。Event:事件对象,用于线程间通信(一个线程发信号,其他线程等待)。Condition:条件变量,用于复杂的线程同步(如生产者-消费者模式)。Semaphore/BoundedSemaphore:信号量,用于控制同时访问资源的线程数量。Timer:定时线程,在指定时间后执行函数。local:线程局部数据,每个线程拥有独立的数据副本。
| 名称 | 类型 | 说明 |
|---|---|---|
current_thread() |
函数 | 最重要。返回当前正在执行的 Thread 对象。等价于旧版的 currentThread()。 |
main_thread() |
函数 | 返回主线程对象 (MainThread)。即使你在子线程中调用,它也能找到主线程。 |
enumerate() |
函数 | 返回一个列表,包含当前所有存活的 Thread 对象。 |
active_count() |
函数 | 返回当前存活的线程数量 (等于 len(threading.enumerate()))。 |
get_ident() |
函数 | 返回当前线程的标识符 (等价于 current_thread().ident)。 |
get_native_id() |
函数 | 返回当前线程的原生 ID (等价于 current_thread().native_id)。 |
stack_size([size]) |
函数 | 获取或设置新创建线程的栈大小 (单位字节)。需在创建线程前设置。 |
import threading
def check_info():
current = threading.current_thread()
print(f"当前线程名: {current.name}")
print(f"当前线程ID: {current.ident}")
print(f"是不是主线程? {current is threading.main_thread()}")
t = threading.Thread(target=check_info)
t.start()
t.join()
# 查看系统中有多少线程
print(f"活跃线程数: {threading.active_count()}")
print(f"活跃线程列表: {[th.name for th in threading.enumerate()]}")10.2 Thread
表示一个单独的控制线程。
- 功能:创建、启动、管理线程。
- 常用方法:
__init__(target=None, name=None, args=(), kwargs={}, daemon=None): 初始化线程。start(): 启动线程(调用run()方法)。run(): 线程活动时调用的方法(通常被重写)。join(timeout=None): 阻塞当前线程,直到该线程结束。is_alive(): 检查线程是否仍在运行。name: 线程名称属性(可读写)。daemon: 守护线程属性(主程序退出时,守护线程会自动退出)。
__init__参数详解
1. target ( callable )
含义:线程启动后要执行的可调用对象(通常是函数)。
默认值:None。
说明:
如果提供了 target,当调用 start() 方法时,线程会自动执行 target(*args, **kwargs)。
如果为 None,则必须子类化 Thread 并重写 run() 方法,否则线程启动后什么都不做。
示例:target=my_function
2. name ( str )
含义:线程的名称。
默认值:None(自动生成,格式为 Thread-N,N 是递增整数,如 Thread-1, Thread-2)。
说明:
主要用于调试和日志记录,方便区分不同的线程。
可以通过 thread.name 属性在运行时读取或修改。
主线程的名称默认为 MainThread。
示例:name="Worker-01"
3. args ( tuple )
含义:传递给 target 函数的位置参数元组。
默认值:() (空元组)。
说明:
即使只有一个参数,也必须写成元组形式(例如 (1,) 而不是 1)。
这些参数会在 target 被调用时按顺序传入。
示例:args=(10, 20) -> 对应 target(10, 20)
4. kwargs ( dict )
含义:传递给 target 函数的关键字参数字典。
默认值:{} (空字典)。
说明:
用于传递命名参数。
可以与 args 同时使用。
示例:kwargs={"url": "http://...", "timeout": 5} -> 对应 target(url="...", timeout=5)
5. daemon ( bool )
含义:是否为守护线程。
默认值:None。
说明:
None:继承创建该线程的当前线程的守护状态。如果是主线程创建的,默认为 False(非守护)。
True:设置为守护线程。关键特性:当主程序(主线程)退出时,所有存活的守护线程会被强制立即终止,无论它们是否执行完毕。
False:设置为非守护线程。主程序会等待所有非守护线程执行完毕后才会退出。
注意:必须在调用 start() 之前设置此属性,否则会抛出 RuntimeError。
适用场景:后台监控、心跳检测等不需要阻塞程序退出的任务通常设为 True;需要确保数据保存完成的任务应设为 False。
import threading
import time
def worker(task_id, delay, prefix="Task"):
print(f"[{prefix}-{task_id}] 开始工作...")
time.sleep(delay)
print(f"[{prefix}-{task_id}] 工作完成。")
# 1. 基本用法
t1 = threading.Thread(
target=worker,
args=(1, 2), # 位置参数: task_id=1, delay=2
kwargs={"prefix": "A"}, # 关键字参数: prefix="A"
name="Worker-A" # 自定义名称
)
# 2. 守护线程用法 (程序退出时自动杀掉)
t2 = threading.Thread(
target=worker,
args=(2, 10), # 这个任务需要10秒,但因为是守护线程,主程序不会等它
daemon=True # 设置为守护线程
)
print(f"主线程: {threading.current_thread().name}")
t1.start()
t2.start()
# 主线程只等待 t1 (非守护),不等待 t2 (守护)
t1.join()
print("主程序结束。")
# 此时 t2 可能还在睡梦中,但会被强制终止,不会打印 "工作完成"10.3 Timer
threading.Timer 是 Thread 类的子类,用于在指定的秒数后执行某个函数。它非常适合用于延迟任务、超时处理或周期性检查(需手动重启)。
timer = threading.Timer(interval, function, args=None, kwargs=None)interval(float): 延迟执行的秒数。function(callable): 要执行的函数。args(tuple): 传递给函数的位置参数(默认为())。kwargs(dict): 传递给函数的关键字参数(默认为{})。
| 方法 | 说明 |
|---|---|
start() |
启动定时器。调用后开始倒计时,时间一到自动执行函数(在新线程中)。 |
cancel() |
取消定时器。如果在倒计时结束前调用,函数将不会执行。这是 Timer 最重要的功能。 |
is_alive() |
检查定时器线程是否还在运行(包括等待时间和执行函数时间)。 |
场景一:简单的延迟执行
import threading
def say_hello(name):
print(f"你好, {name}! 这条消息延迟了 3 秒才出现。")
# 创建定时器:3秒后执行 say_hello("Alice")
t = threading.Timer(3.0, say_hello, args=["Alice"])
t.start()
print("定时器已启动,等待 3 秒...")
# 主线程继续做其他事,不会被阻塞
print("主线程正在忙别的...")场景二:取消定时器
import threading
import time
def alarm():
print("⏰ 警报响起!时间到!")
print("设置 5 秒后的警报...")
t = threading.Timer(5.0, alarm)
t.start()
print("哎呀,用户取消了操作!")
time.sleep(1) # 模拟用户操作耗时
# 在警报响起前取消它
t.cancel()
print("警报已取消。")
# 等待足够长的时间确认警报不会响
time.sleep(5)
print("程序结束,警报确实没响。")10.4 Local
python 中实现线程局部存储(Thread-Local Storage, TLS)的核心工具。
它的核心特性是:创建一个对象后,每个线程访问该对象的属性时,看到的都是各自独立的副本,互不干扰。 即使多个线程操作同一个 local 实例,它们也不会看到彼此修改的数据。
这在多线程编程中非常有用,常用于保存数据库连接、用户会话信息、事务上下文等“每个线程独有”的状态,从而避免使用复杂的锁机制。
import threading
import time
import random
# 创建一个线程局部存储对象
my_data = threading.local()
def worker(thread_name):
# 1. 设置当前线程的专属数据
# 注意:这里不需要初始化,直接赋值即可
my_data.value = random.randint(1, 100)
my_data.name = thread_name
print(f"[{thread_name}] 初始值: {my_data.value}")
# 模拟一些工作
time.sleep(random.uniform(0.1, 0.5))
# 2. 修改数据
my_data.value += 10
# 3. 读取数据
# 关键点:这里读到的 value 是当前线程自己设置的,不会受到其他线程影响
print(f"[{thread_name}] 修改后: {my_data.value} (名字: {my_data.name})")
# 创建并启动多个线程
threads = []
for i in range(3):
t = threading.Thread(target=worker, args=(f"Thread-{i}",))
threads.append(t)
t.start()
for t in threads:
t.join()
print("\n--- 主线程尝试访问 ---")
# 主线程访问时,因为没有设置过属性,会抛出 AttributeError
try:
print(f"主线程的值: {my_data.value}")
except AttributeError as e:
print(f"主线程报错 (预期行为): {e}")10.5 Lock / RLock
threading.Lock 和 threading.RLock 是 Python 多线程编程中用于保护共享资源、防止竞态条件 (Race Condition) 的两个核心锁机制。虽然它们看起来很像,但关键区别在于“可重入性”
1 lock
lock这是最基础的锁。它的规则非常简单粗暴:
- 状态:只有两种状态 —— “锁定” 或 “未锁定”。
- 获取:如果锁是空的,当前线程拿走锁;如果锁已被别人(或自己)拿走,当前线程阻塞等待。
- 释放:任何持有锁的线程都可以释放它(实际上通常由持有者释放,但底层不检查是谁)。
- 致命限制:不可重入。如果一个线程已经持有了锁,再次尝试获取同一个锁,会导致死锁 (Deadlock),程序永远卡住。
❌ 错误示例:死锁
import threading
lock = threading.Lock()
def bad_function():
print("1. 尝试第一次获取锁...")
lock.acquire()
print(" -> 锁已获取")
print("2. 尝试第二次获取锁 (在同一个线程内)...")
# 致命错误:因为锁已经被当前线程拿走了,这里会无限等待自己释放
# 但代码卡在下面这行,永远无法执行到 release()
lock.acquire()
print(" -> 这行永远不会打印")
lock.release()
lock.release()
t = threading.Thread(target=bad_function)
t.start()
t.join()
# 程序会挂起,必须强制终止✅ 正确用法
适用于简单的临界区保护,且逻辑中没有嵌套调用需要同一把锁的情况
import threading
lock = threading.Lock()
counter = 0
def safe_increment():
global counter
# 方式一:手动 acquire/release (推荐配合 try/finally)
lock.acquire()
try:
temp = counter
counter = temp + 1
finally:
lock.release()
def safe_increment_with():
global counter
# 方式二:使用 with 语句 (更推荐,自动处理异常和释放)
with lock:
temp = counter
counter = temp + 1
print(f'{threading.current_thread().name}+{counter}')
# 运行测试
threads = [threading.Thread(target=safe_increment_with,name=i) for i in range(1000)]
for t in threads: t.start()
for t in threads: t.join()
print(f"最终计数: {counter}") # 必定是 10002 Rlock
RLock = Reentrant Lock。
它是 Lock 的升级版,专门解决“同一个线程需要多次获取同一把锁”的场景。
核心特性:可重入。
它内部记录了 “哪个线程” 持有了锁,以及 “获取次数”。
如果是同一个线程再次请求锁,计数器 +1,直接通过,不会阻塞。
如果是其他线程请求,则阻塞。
释放规则:必须调用相同次数的 release(),计数器归零后,锁才真正释放给其他线程。
当你有一个函数 A 加了锁,而 A 内部调用了函数 B,函数 B 也需要加同一把锁时,必须用 RLock
import threading
# 使用 RLock 允许递归调用
r_lock = threading.RLock()
def outer_function():
print("[Outer] 尝试获取锁...")
with r_lock:
print("[Outer] 锁已获取 (计数=1)")
inner_function() # 调用内部函数
print("[Outer] 内部函数执行完毕")
def inner_function():
print(" [Inner] 尝试获取锁...")
with r_lock:
# 因为是同一个线程,RLock 允许再次获取,计数变为 2
print(" [Inner] 锁已获取 (计数=2,没有死锁!)")
# 做一些操作
print(" [Inner] 准备释放锁 (计数变回 1)")
# with 块结束,自动 release 一次
print(" [Inner] 内部锁已释放")
# 启动线程
t = threading.Thread(target=outer_function)
t.start()
t.join()
print("✅ 程序正常结束,没有死锁。")10.6 Condition
threading.Condition(条件变量)是 Python 多线程中最强大但也最复杂的同步原语。
如果说 Lock 是“独占厕所”,Event 是“红绿灯”,那么 Condition 就是“带休息室的会议室”:
- 线程可以进入会议室(获取锁)。
- 如果条件不满足(比如人没到齐),线程可以释放锁并去休息室睡觉(
wait),把会议室让给别人。 - 当有人改变了状态(比如人到了),可以叫醒休息室里的特定线程或所有线程(
notify/notify_all)。 - 被叫醒的线程会重新尝试获取锁,然后继续执行。
它主要用于解决“生产者 - 消费者”模型或“等待特定状态变化”的场景,比 Event 更灵活,比单纯的 Lock 更高效。
Condition 内部实际上包含了两部分:
- 一把锁 (
Lock或RLock):用于保护共享数据。 - 一个等待池:存放那些因为条件不满足而暂时挂起的线程。
你可以直接使用默认的锁,也可以传入自定义的锁(通常用 RLock 以支持重入)
cond = threading.Condition()
# 或者
lock = threading.RLock()
cond = threading.Condition(lock)| 方法 | 说明 | 关键点 |
|---|---|---|
acquire() / release() |
获取/释放内部的锁。 | 通常配合 with cond: 使用。 |
wait(timeout=None) |
释放锁 -> 进入等待状态 -> 被唤醒后重新获取锁 -> 返回。 | ⚠️ 必须在持有锁的情况下调用,否则报错。 ⚠️ 唤醒后不一定条件就满足了(可能有虚假唤醒),通常需要放在 while 循环中检查条件。 |
notify(n=1) |
唤醒等待池中 最多 n 个 线程。 | ⚠️ 必须在持有锁的情况下调用。 ⚠️ 被唤醒的线程不会立即运行,它们要等当前线程释放锁后才能抢锁。 |
notify_all() |
唤醒等待池中 所有 线程。 | 适用于状态改变影响所有等待者的场景(如“系统关闭”、“资源耗尽”)。 |
import threading
import time
import random
# 共享资源
buffer = []
MAX_SIZE = 5
# 创建条件变量
cond = threading.Condition()
def producer(name):
for i in range(10):
item = f"Item-{i}"
with cond:
# 1. 检查条件:如果缓冲区满了,就等待
while len(buffer) >= MAX_SIZE:
print(f"[{name}] 缓冲区满 ({len(buffer)}/{MAX_SIZE}),等待消费者...")
cond.wait() # 自动释放锁,进入等待
# 2. 生产数据
buffer.append(item)
print(f"[{name}] 生产了: {item} -> 缓冲区: {buffer}")
# 3. 通知消费者:有新数据了!
cond.notify()
# 模拟生产耗时
time.sleep(random.uniform(0.1, 0.5))
def consumer(name):
for _ in range(10):
with cond:
# 1. 检查条件:如果缓冲区空了,就等待
while len(buffer) == 0:
print(f"[{name}] 缓冲区空,等待生产者...")
cond.wait() # 自动释放锁,进入等待
# 2. 消费数据
item = buffer.pop(0)
print(f"[{name}] 消费了: {item} -> 缓冲区: {buffer}")
# 3. 通知生产者:有空位了!
cond.notify()
# 模拟消费耗时
time.sleep(random.uniform(0.2, 0.6))
# 启动线程
p = threading.Thread(target=producer, args=("Producer",))
c1 = threading.Thread(target=consumer, args=("Consumer-1",))
c2 = threading.Thread(target=consumer, args=("Consumer-2",))
p.start()
c1.start()
c2.start()
10.7 Semaphore / BoundedSemaphore
threading.Semaphore(信号量)和 threading.BoundedSemaphore 是 Python 多线程中用于控制同时访问特定资源的线程数量的同步原语
信号量的本质是一个计数器。
- 初始化:创建一个信号量时,你设定一个初始值
value(例如 5)。 acquire()(P 操作):- 如果计数器 > 0:计数器减 1,线程继续执行。
- 如果计数器 == 0:线程阻塞等待,直到有其他线程释放信号量。
release()(V 操作):- 计数器加 1。
- 如果有线程在等待,唤醒其中一个
| 特性 | threading.Semaphore |
threading.BoundedSemaphore |
|---|---|---|
| 计数器上限 | 无限制。可以无限次调用 release(),计数器会一直增加。 |
有上限。计数器不能超过初始值。 |
| 异常行为 | 如果你调用 release() 的次数多于 acquire(),计数器会虚高,导致后续过多的线程进入临界区,失去限流意义。 |
如果 release() 次数多于 acquire(),会抛出 ValueError。 |
| 安全性 | 较低。容易因代码逻辑错误(如多释放)导致并发失控。 | 较高。强制保证并发数不超过初始设定值。 |
| 推荐度 | ⭐⭐ (仅在特殊场景使用) | ⭐⭐⭐⭐⭐ (默认首选) |
建议:除非你有非常特殊的理由需要计数器无限增长,否则永远使用 BoundedSemaphore。它能帮你发现“多释放”的逻辑错误。
import threading
import time
import random
# 创建一个最大值为 3 的信号量
# 意味着同一时间最多允许 3 个线程进入临界区
max_connections = 3
sem = threading.BoundedSemaphore(max_connections)
print(sem._value) #
def access_database(thread_id):
# 尝试获取信号量
# 如果当前已有 3 个线程在内部,第 4 个线程会在这里阻塞
sem.acquire()
try:
print(f"[线程-{thread_id}] 获得许可 (剩余名额: {sem._value}),正在访问资源...")
# 模拟耗时操作 (访问数据库/网络请求)
time.sleep(random.uniform(1, 3))
finally:
# 【关键】无论是否出错,必须释放信号量,否则名额会被永久占用
sem.release()
print(f"[线程-{thread_id}] 完成操作,释放许可,剩余名额: {sem._value}")
# 启动 10 个线程,但只有 3 个能同时运行
threads = []
for i in range(3):
t = threading.Thread(target=access_database, args=(i,))
threads.append(t)
t.start()
for t in threads:
t.join()
print("✅ 所有任务完成。")
output='''
3
[线程-0] 获得许可 (剩余名额: 2),正在访问资源...
[线程-1] 获得许可 (剩余名额: 1),正在访问资源...
[线程-2] 获得许可 (剩余名额: 0),正在访问资源...
[线程-0] 完成操作,释放许可,剩余名额: 0
[线程-1] 完成操作,释放许可,剩余名额: 1
[线程-2] 完成操作,释放许可,剩余名额: 2
✅ 所有任务完成。
'''❌ 陷阱 1:忘记释放 (资源泄露)
如果线程在持有信号量时崩溃或抛出异常,且没有 finally 块释放,计数器就不会加回去。
- 后果:可用名额永久减少。如果所有名额都被泄露,后续所有线程都会永久死锁。
- 解决:务必使用
try...finally或with语句。
❌ 陷阱 2:普通 Semaphore 的“超发”风险
如果你用普通的 Semaphore,并且代码逻辑写错了(比如在一个循环里意外调用了两次 release):
sem = threading.Semaphore(2)
sem.acquire()
sem.release()
sem.release() # 错误!计数器变成了 3
# 现在允许 3 个线程进入,突破了设定的 2 个限制!✅ 最佳实践:使用 with 语句
和 Lock 一样,Semaphore 也支持上下文管理器,这是最安全的写法
# 推荐写法
with sem:
do_something()
# 离开 with 块自动 release,即使中间报错高级用法:带超时的获取
# 尝试获取信号量,最多等待 2 秒
acquired = sem.acquire(timeout=2)
if acquired:
try:
do_work()
finally:
sem.release()
else:
print("等待超时,放弃执行任务,处理降级逻辑...")10.8 Event
threading.Event 是 Python 多线程编程中最简单、最常用的同步原语。
它的核心作用相当于一个“信号灯”或“旗帜”:
- 线程可以等待这个信号变成“真”(Green)。
- 其他线程可以在任何时候将信号设置为“真”,从而唤醒所有正在等待的线程。
- 信号也可以被重置为“假”(Red),让后续等待的线程继续阻塞。
它非常适合用于:线程间通信、优雅停止线程、等待初始化完成、批量启动任务等场景
| 方法 | 说明 | 返回值 |
|---|---|---|
wait(timeout=None) |
阻塞当前线程,直到事件被设置为 True。- 如果事件已经是 True,立即返回。- 如果提供了 timeout (秒数),最多等待这么久,超时后返回 False。- 如果事件被设置,返回 True;如果超时,返回 False。 |
bool |
set() |
将事件内部标志设置为 True。所有正在 wait() 的线程会被立即唤醒。 |
None |
clear() |
将事件内部标志重置为 False。后续调用 wait() 的线程将会再次阻塞。 |
None |
is_set() |
检查内部标志是否为 True。相当于 flag == True 的判断。 |
bool |
import threading
import time
def worker(stop_event):
print("👷 工作线程启动,开始监控...")
while not stop_event.is_set():
# 执行一些任务
print(" ... 正在处理数据 ...")
# 关键点:使用 wait 代替 sleep
# 这样如果 stop_event 被设置,线程会立即醒来并退出循环,
# 而不需要睡完剩下的时间。
# 这里等待 1 秒,或者直到事件被触发
if stop_event.wait(timeout=1.0):
print("⚠️ 收到停止信号,准备退出...")
break
print("👋 工作线程已安全退出。")
# 创建事件对象
stop_event = threading.Event()
# 启动线程,传入事件对象
t = threading.Thread(target=worker, args=(stop_event,))
t.start()
# 主线程运行 3.5 秒
time.sleep(3.5)
print("\n🛑 主线程决定停止工作线程...")
stop_event.set() # 发送信号
t.join() # 等待子线程彻底结束
print("✅ 程序结束。")import threading
import time
# 事件:表示“初始化是否完成”
init_done = threading.Event()
data_store = {}
def loader():
print("📥 加载数据中... (耗时 3 秒)")
time.sleep(3)
data_store['config'] = "Loaded!"
print("✅ 数据加载完成!")
# 设置事件,通知所有等待者:我好了!
init_done.set()
def user_request(request_id):
print(f"🙋 请求 {request_id} 到达,等待数据就绪...")
# 阻塞在这里,直到 loader 线程调用 set()
# 如果没有 timeout,会一直等下去
init_done.wait()
print(f"🚀 请求 {request_id} 开始处理,读取数据: {data_store.get('config')}")
# 启动加载线程
t_loader = threading.Thread(target=loader)
t_loader.start()
# 模拟几个并发请求,它们都会卡在 wait()
threads = []
for i in range(3):
t = threading.Thread(target=user_request, args=(i,))
t.start()
threads.append(t)
#上面的代码实际上不需要,只有所有线程运行结束,主线程才会结束
t_loader.join()
for t in threads:
t.join()10.9 总结
| 场景 | 推荐工具 | 原因 |
|---|---|---|
| 互斥访问 (只能 1 个) | Lock / RLock |
语义清晰,开销最小。虽然 Semaphore(1) 也能用,但没必要。 |
| 限制并发数 (N 个) | BoundedSemaphore(N) |
首选。防止因代码错误导致并发数超标。 |
| 特殊计数逻辑 | Semaphore(N) |
仅当你确实需要计数器超过初始值(极少见)时使用。 |
| 事件通知 | Event / Condition |
如果只是通知“发生了某事”,而不是限制数量,请用这两个。 |
10.10 queue
线程安全
| 类名 | 行为模式 | 适用场景 |
|---|---|---|
queue.Queue |
FIFO (先进先出) | 通用场景,如日志处理、任务分发。 |
queue.LifoQueue |
LIFO (后进先出/栈) | 需要“最新任务优先处理”的场景,或深度优先搜索的多线程版。 |
queue.PriorityQueue |
优先级队列 | 任务调度。放入的数据必须是可比较的,通常放入元组 (优先级, 数据),优先级数字越小越先出。 |
queue.SimpleQueue |
简化版 FIFO | (Python 3.7+) 去掉了 task_done() 和 join() 功能,也不支持 timeout。由于内部实现更简单,性能略高。适用于只需要简单传递数据,不需要等待任务完成的场景。 |
放入数据 q.put(item, block=True, timeout=None)
block=True(默认): 如果队列已满(达到maxsize),调用线程会阻塞,直到有空间。timeout: 设置阻塞等待的最大秒数。超时抛出queue.Full异常。block=False: 如果队列满,立即抛出queue.Full,不等待
11 异步编程
11.1 核心概念
要理解异步编程,需要掌握以下四个核心概念:
-
async def(定义协程)
使用async def定义的函数被称为协程函数。调用它并不会立即执行,而是返回一个协程对象。这个对象就像一个“任务计划书”,描述了要执行的操作。 -
await(暂停与让出)await关键字只能在async def函数内部使用。当执行到await时,当前协程会暂停,并将控制权交还给事件循环,让事件循环可以去执行其他任务。等待的操作完成后,事件循环会再回来恢复该协程的执行。await后面必须跟一个“可等待对象”(如另一个协程、Task 或 Future)。 -
事件循环 (Event Loop)
事件循环是异步编程的“总指挥”或“调度中心”。它负责管理和调度所有的协程任务。它会不断检查有哪些任务可以运行,哪些任务在等待,并在任务之间进行高效的切换。 -
asyncio(标准库)asyncio是 Python 用于编写异步代码的标准库。它提供了运行协程、创建任务、实现并发等所需的所有工具。
await 是 Python 异步编程的核心关键字之一,它只能在 async def 定义的协程函数内部使用。它的核心作用是:暂停当前协程的执行,将控制权交还给事件循环,等待一个“可等待对象”完成,然后恢复执行。 这个过程是非阻塞的,意味着在等待期间,事件循环可以去执行其他任务,从而实现高效的并发。
await 能等待什么?
await 后面必须跟一个“可等待对象”(Awaitable),主要有以下三种:
- 协程对象 (Coroutine Object)
通过调用async def定义的函数来创建。 - Task 对象
通过asyncio.create_task()创建,它包装了一个协程并立即将其加入事件循环进行调度。 - Future 对象
一个代表异步操作最终结果的底层对象,Task是Future的子类
11.2 基本示例
示例1
import asyncio
import time
async def say_after(delay, what):
await asyncio.sleep(delay)
print(what)
async def main():
print(f"程序开始时间: {time.strftime('%X')}")
# 并发执行
await asyncio.gather(
say_after(2, 'Hello'),
say_after(1, 'World')
)
print(f"程序结束时间: {time.strftime('%X')}")
# jupyter直接 await main(),不要用 asyncio.run(main())
# 因为jupyter已经有事件循环了
await main()
#输出
output='''
程序开始时间: 10:28:31
World
Hello
程序结束时间: 10:28:33
'''示例二
import asyncio
import time
# 1. 修改函数,使其返回一个值
async def say_after(delay, what):
await asyncio.sleep(delay)
# print(what) # 打印操作
return f"{what} (延迟了{delay}秒)" # 返回结果
async def main():
print(f"程序开始时间: {time.strftime('%X')}")
# 2. 使用变量接收 gather 的返回值
# 注意:results 是一个列表,顺序与传入顺序一致
results = await asyncio.gather(
say_after(2, 'Hello'),
say_after(1, 'World'),
say_after(1, '!')
)
# 3. 打印结果
print("--- 任务全部完成 ---")
print(f"程序结束时间: {time.strftime('%X')}")
print(f"获取到的结果列表: {results}")
# 4. 你可以像操作普通列表一样操作它
print(f"第一个结果: {results[0]}") # 对应 Hello
print(f"第二个结果: {results[1]}") # 对应 World
# 在 Jupyter 中运行
await main()
output='''
程序开始时间: 10:45:20
--- 任务全部完成 ---
程序结束时间: 10:45:22
获取到的结果列表: ['Hello (延迟了2秒)', 'World (延迟了1秒)', '! (延迟了1秒)']
第一个结果: Hello (延迟了2秒)
第二个结果: World (延迟了1秒)
'''示例三
import asyncio
async def job(name, seconds):
print(f"🔵 任务 {name} 开始,预计耗时 {seconds} 秒...")
await asyncio.sleep(seconds) # 模拟耗时操作
print(f"✅ 任务 {name} 完成!")
return f"{name}的结果"
async def main():
print("--- 1. 串行模式(排队做) ---")
start_time = asyncio.get_event_loop().time()
# 必须等 job("A") 做完,才会开始 job("B")
result1 = await job("A", 2)
result2 = await job("B", 2)
print(f"串行总耗时: {asyncio.get_event_loop().time() - start_time:.2f} 秒\n")
print("--- 2. 使用 create_task(并发做) ---")
start_time = asyncio.get_event_loop().time()
# create_task 会立即把任务扔到后台运行
# 此时 task1 和 task2 同时开始倒计时
task1 = asyncio.create_task(job("A", 2))
task2 = asyncio.create_task(job("B", 2))
print("💡 两个任务已在后台同时启动,主程序可以继续做别的事...")
# await task1 会等待 task1 完成并获取结果
# 注意:因为两个任务是同时开始的,这里只需要等待剩下的时间
result1 = await task1
result2 = await task2
print(f"最终结果: {result1}, {result2}")
print(f"并发总耗时: {asyncio.get_event_loop().time() - start_time:.2f} 秒")
# 如果你在 Jupyter Notebook 中运行,请使用 await main()
# 如果你在 .py 文件中运行,请使用 asyncio.run(main())
await main() - await 串行模式:
- 任务 A 耗时 2 秒,任务 B 耗时 2 秒。
- 总耗时约 4 秒。因为 B 必须等 A 做完。
- create_task 模式:
create_task被调用时,任务 A 和 B 同时开始计时。- 主程序打印提示语。
- 然后
await等待它们。 - 总耗时约 2 秒。因为两个任务是重叠进行的
11.3 异步 vs. 多线程
| 特性 | 异步编程 (Asyncio) | 多线程 (Threading) |
|---|---|---|
| 并发模型 | 单线程,协作式切换 | 多线程,操作系统抢占式切换 |
| 资源开销 | 极低,可轻松创建上万协程 | 较高,线程数量受系统限制 |
| 适用场景 | I/O 密集型 (网络、文件、数据库) | I/O 密集型,但库不支持异步时 |
| CPU 密集型 | 不适用 | 受 GIL 限制,效率不高,推荐用多进程 |
12 工程架构
这个可以参看博客
后续如果有新章节,可能另外写一篇文章,这个内容太多卡

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)