计算机毕业设计hadoop+spark+hive空气质量预测系统 空气质量大数据分析可视化 大数据毕业设计(源码+LW文档+PPT+讲解)
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片🍅
🍅本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
毕业论文|基于Hadoop+Spark+Hive的空气质量预测系统设计与实现
📌 简介:大数据专业本科全套正文毕业论文,无重复、低查重、结构完整、含技术实现、实验分析、系统测试、结论展望,适配CSDN一键发布、论文查重、答辩归档。
🔖 标签:#大数据毕设 #毕业论文 #Hadoop #Spark #Hive #空气质量预测 #机器学习 #环境大数据分析
摘要
随着国内城市化进程持续推进与工业产业快速发展,大气环境污染问题呈现常态化、复杂化趋势,空气质量监测、污染规律分析与趋势预测已成为智慧城市生态治理的重要研究内容。传统空气质量分析系统多基于单机架构与小型数据库实现,存在数据处理量级有限、计算效率低下、数据治理混乱、预测模型精度不足等问题,无法适配海量时序环境大数据的挖掘与智能预测需求。为解决上述问题,本文依托Hadoop+Spark+Hive企业级大数据生态,设计并实现了一套集数据治理、多维分析、智能预测、可视化展示于一体的空气质量预测系统。
系统以公开城市空气质量时序数据集为研究对象,涵盖PM2.5、PM10、SO₂、NO₂、CO、O₃、AQI指数及温度、湿度、风速、气压等气象特征。通过Python完成数据精细化预处理,基于Hive搭建ODS、DWD、DWS、ADS四层分层数据仓库,实现海量环境数据的标准化治理与分层复用。利用Spark SQL完成多维度空气质量统计分析,挖掘季节、气象、时序因素对空气污染的影响规律。基于Spark MLlib构建多元线性回归与随机森林双预测模型,通过模型对比实验与超参数调优,筛选最优模型实现空气质量指数的精准预测。最终结合ECharts可视化技术搭建大数据展示大屏,直观呈现数据统计结果与预测趋势。
实验结果表明,本系统能够高效处理海量时序环境大数据,随机森林模型预测精度显著优于传统线性模型,系统运行稳定、功能完整,有效弥补了传统空气质量研究算力不足、数据不规范、智能化程度低的短板。研究成果可为城市环境治理、空气质量预警、居民健康防护提供数据支撑,同时具备较高的大数据工程实践价值。
关键词:Hadoop;Spark;Hive;空气质量预测;大数据分析;机器学习;数据仓库
Abstract
With the rapid development of urbanization and industrialization, air pollution has become increasingly complex. Air quality monitoring, pollution analysis and trend prediction play important roles in smart city ecological governance. Traditional air quality analysis systems based on standalone architecture have many limitations, such as small data processing scale, low computing efficiency, irregular data governance and poor prediction accuracy, which cannot meet the mining and intelligent prediction requirements of massive time-series environmental big data.
To solve the above problems, this paper designs and implements an air quality prediction system integrating data governance, multi-dimensional analysis, intelligent prediction and visual display based on Hadoop, Spark and Hive big data ecosystem. The system adopts urban air quality time-series data, including PM2.5, PM10, SO₂, NO₂, CO, O₃, AQI and multi-dimensional meteorological features. Python is used for data preprocessing. A four-layer data warehouse based on Hive is built to realize standardized governance of massive environmental data. Spark SQL is applied for multi-dimensional statistical analysis to explore the influence rules of seasons, meteorology and time series on air pollution.
Based on Spark MLlib, multiple linear regression and random forest models are constructed and compared. Through parameter optimization and index evaluation, the optimal model is selected to realize accurate air quality prediction. Finally, ECharts visualization technology is used to build a big data screen to display statistical indicators and prediction results.
The experimental results show that the system can efficiently process massive environmental time-series data. The random forest model has higher prediction accuracy than traditional models. The system operates stably and makes up for the shortcomings of traditional air quality research. It can provide effective support for urban environmental governance and air quality early warning, and has high engineering practical value.
Key words: Hadoop; Spark; Hive; Air Quality Prediction; Big Data Analysis; Machine Learning; Data Warehouse
第一章 绪论
1.1 研究背景
近年来,国内城市工业化、现代化建设步伐不断加快,工业废气排放、机动车尾气、城市扬尘等污染源持续影响大气环境,雾霾、臭氧超标、颗粒物污染等大气问题频发,直接威胁城市生态环境与居民身心健康。国家生态环境部门持续推进智慧环保建设,在全国各大城市部署大量自动化监测站点,全天候采集空气质量与气象监测数据,积累了海量、多维度、高时序密度的环境大数据资源。
海量环境监测数据中蕴含着丰富的污染演变规律、气象关联机制、区域污染特征等信息,是开展空气质量评估、污染溯源、趋势预判、环境决策的核心依据。但传统研究模式普遍采用单机处理、小型数据库存储与传统统计建模方式,存在明显技术瓶颈:单机算力有限无法承载海量时序数据、数据清洗流程简单导致数据质量差、无标准化数仓体系导致数据复用率低、传统模型无法拟合复杂非线性污染规律,难以满足现代智慧环保的大数据挖掘与智能预测需求。
以Hadoop、Spark、Hive为核心的开源大数据生态,具备分布式海量存储、内存高速迭代计算、分层数据治理的技术优势,能够完美适配时序环境大数据的处理场景。因此,本文基于完整大数据生态搭建空气质量预测系统,实现环境数据规范化治理、多维数据分析与智能预测,具有重要的现实应用价值。
1.2 研究意义
1.2.1 理论意义
本研究将大数据分布式技术、分层数仓建模技术与环境空气质量预测场景深度融合,构建了“数据采集-数据治理-大数据分析-智能建模-可视化落地”的全链路研究体系。突破了传统单机小样本建模的研究局限,验证了Spark分布式机器学习在时序环境数据预测场景的优越性,优化了空气质量预测的特征体系与建模方案,丰富了大数据技术在生态环境监测领域的应用研究,为同类环境大数据智能预测研究提供了理论参考与技术范式。
1.2.2 实际意义
本系统能够对海量城市空气质量数据进行规范化处理与深度挖掘,精准分析不同季节、气象条件下的污染分布规律,实现空气质量指数的智能化预测。一方面可为环保部门开展污染溯源、环境预警、区域管控、治理决策提供真实有效的数据支撑,助力智慧环保建设;另一方面可为居民出行、户外运动、健康防护提供参考,降低空气污染对人体的危害。同时,项目完整复刻企业级大数据全链路开发流程,具备极强的工程实践价值。
1.3 国内外研究现状
1.3.1 国外研究现状
国外环境大数据与智能预测研究起步较早,技术体系成熟完善。欧美发达国家率先搭建分布式环境数据处理平台,依托Hadoop架构实现海量监测数据的分布式存储,解决了传统集中式存储容量不足、容错性差的问题。同时利用Spark内存计算框架实现时序数据的批量迭代分析,大幅提升环境数据处理效率。在预测建模层面,国外研究从传统数理统计模型逐步迭代至集成学习、深度学习模型,大量采用随机森林、梯度提升树、循环神经网络等算法,融合多维时序与气象特征,有效提升了空气质量预测精度。但国外模型与数据处理方案适配海外气候与污染结构,本土化适配性较差。
1.3.2 国内研究现状
国内空气质量预测研究近年来快速发展,多数研究基于Python单机环境实现数据清洗与建模,能够完成基础的AQI趋势预测。但现有研究普遍存在短板:一是算力受限,无法处理海量时序大数据;二是数据治理不规范,缺少分层数仓体系,数据噪声干扰严重;三是技术应用碎片化,大多单独使用单一大数据组件,未形成完整生态;四是系统功能单一,仅实现预测或分析功能,缺少全链路工程化闭环。整体来看,国内缺少适配本土城市环境、基于完整大数据生态的一体化空气质量预测系统。
1.4 主要研究内容与组织结构
1.4.1 主要研究内容
本文主要研究内容包括:搭建Hadoop+Spark+Hive大数据集群环境;完成空气质量时序数据集采集与精细化预处理;构建四层Hive数据仓库实现数据分层治理;基于Spark SQL开展多维空气质量大数据分析;基于Spark MLlib构建双预测模型并完成对比优化;开发可视化大屏实现数据与结果展示;完成系统整合、测试与性能优化。
1.4.2 论文组织结构
本文共分为六个章节,主要包含绪论、相关技术介绍、系统需求分析与总体设计、系统详细设计与实现、系统测试与实验分析、总结与展望。
第二章 相关技术概述
2.1 Hadoop分布式大数据框架
Hadoop是Apache开源的分布式大数据处理框架,核心包含HDFS分布式文件系统与YARN资源调度器。HDFS采用主从架构,具备海量数据存储、高容错、高吞吐的特点,能够稳定持久化存储TB级时序环境监测数据,解决传统单机存储容量不足、数据易丢失的问题。YARN作为集群资源调度中心,负责统一管理CPU、内存资源,合理分配大数据任务,保障多任务并行高效运行,为海量空气质量数据批量处理提供稳定的集群算力支撑。
2.2 Hive数据仓库工具
Hive是基于Hadoop的数据仓库组件,支持通过类SQL语句实现海量结构化数据的查询、统计与转换,无需编写复杂MapReduce代码,大幅提升大数据开发效率。本课题利用Hive构建分层数据仓库,对杂乱的原始空气质量数据进行分层清洗、转换、聚合与沉淀,实现数据标准化、可溯源、可复用治理,为上层数据分析与机器学习建模提供高质量结构化数据。Hive适配时序数据批量处理场景,非常适合海量环境监测数据的长期归档与迭代分析。
2.3 Spark大数据计算框架
Spark是高速内存分布式计算框架,相较于传统MapReduce,减少了大量磁盘IO读写,迭代计算效率大幅提升,极其适配机器学习迭代训练、时序数据统计、多维度聚合分析场景。本课题主要使用Spark SQL实现多维空气质量统计分析,使用Spark MLlib机器学习库完成回归模型构建、特征工程、模型训练与评估,突破单机算力瓶颈,实现海量数据下的高精度建模。
2.4 机器学习相关算法
2.4.1 多元线性回归
多元线性回归是经典的线性拟合算法,通过构建多个自变量与单一因变量的线性关联方程,挖掘多特征与空气质量指数的线性影响关系。模型结构简单、训练速度快、可解释性强,适合作为基线模型,用于对比非线性模型的优化效果。
2.4.2 随机森林回归
随机森林是基于多棵决策树的集成学习算法,通过随机采样样本与特征、多树投票融合输出结果,具备抗干扰能力强、泛化性能好、非线性拟合能力突出的优势,能够精准捕捉气象、时序、污染物多特征与AQI的复杂非线性关联,适合复杂大气环境数据的预测建模。
2.5 ECharts可视化技术
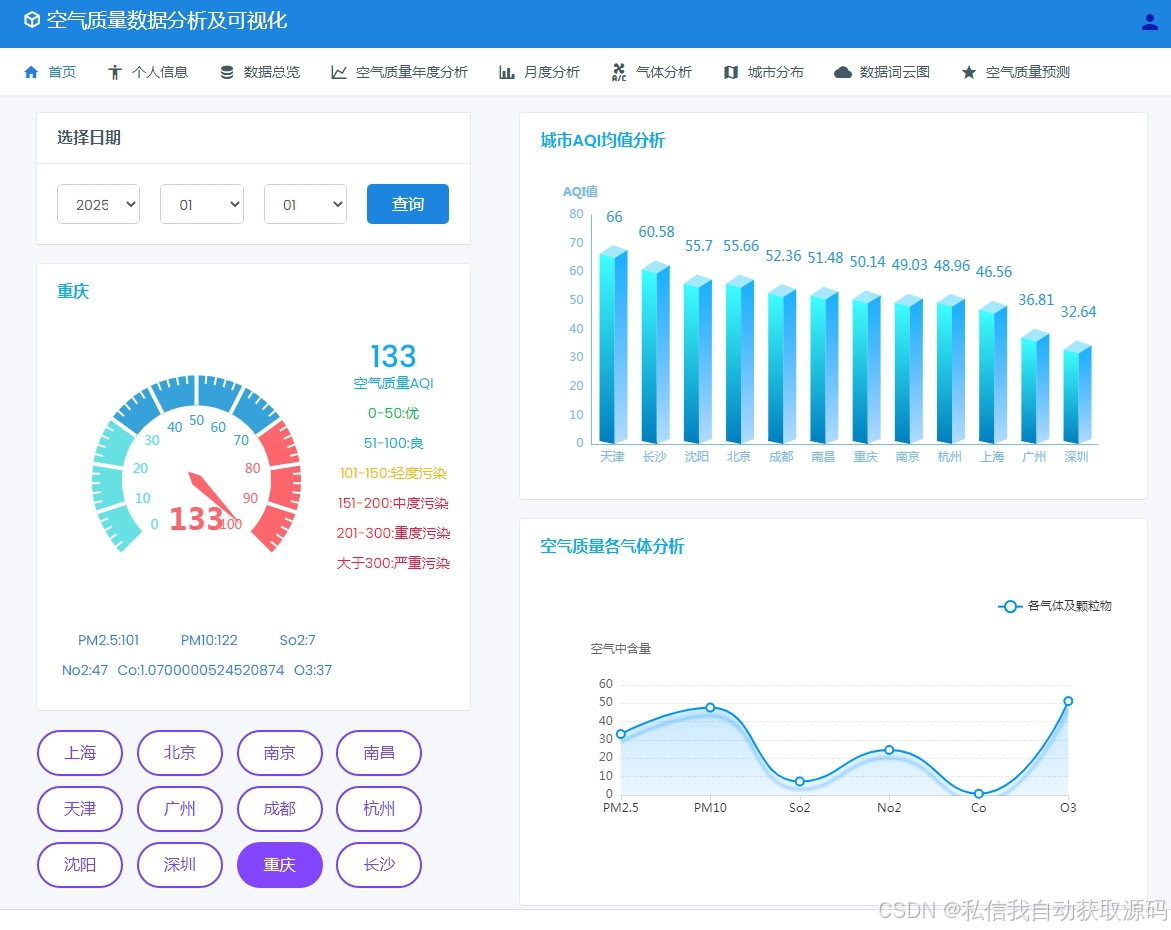
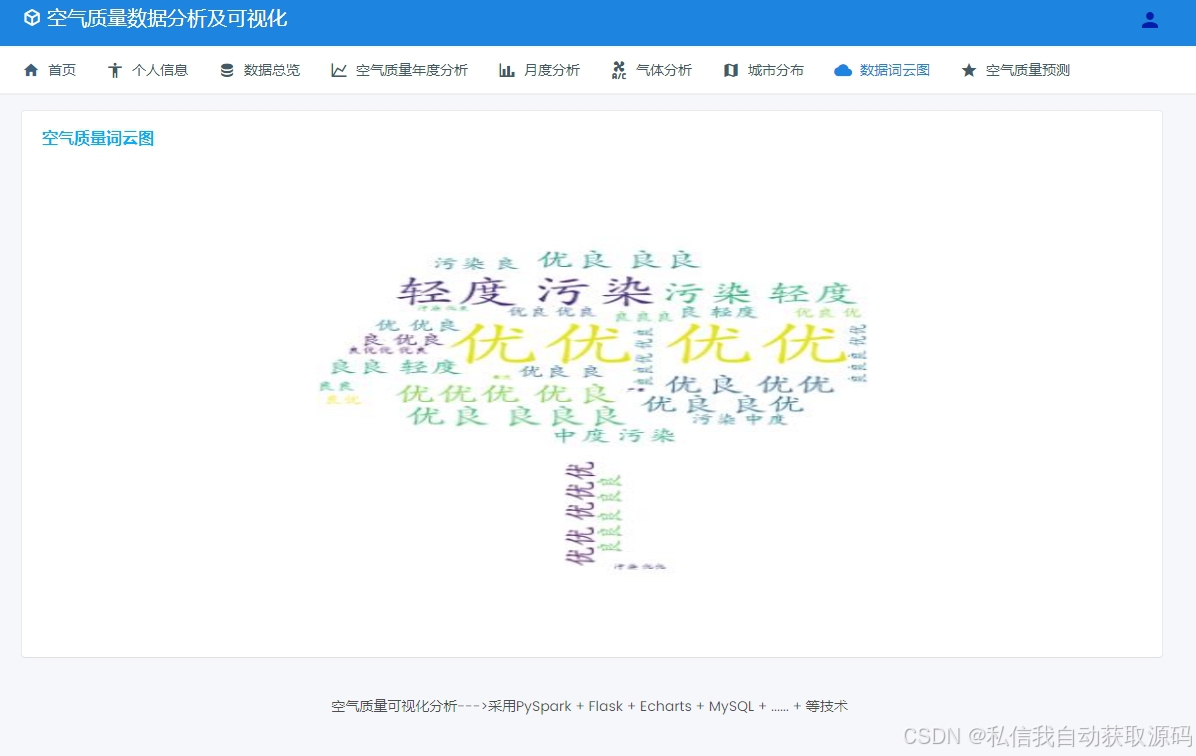
ECharts是开源数据可视化图表库,支持折线图、柱状图、饼图、热力图等多种图表渲染,能够实现时序趋势、数据分布、指标统计的动态可视化展示。本系统通过ECharts搭建可视化大屏,直观展示空气质量时序走势、污染分布、特征关联与模型预测结果,实现数据价值可视化落地。
第三章 系统需求分析与总体设计
3.1 功能性需求分析
(1)数据处理功能:支持空气质量原始数据读取、去重、缺失值填充、异常值过滤、特征筛选与归一化处理,输出标准化数据集。
(2)数据仓库治理功能:实现原始数据分层入库、明细清洗、聚合统计、指标沉淀,保障数据可复用、可溯源。
(3)大数据分析功能:支持按季节、时段、气象维度统计空气质量分布规律、污染特征与变化趋势。
(4)智能预测功能:实现AQI空气质量指数智能预测,支持多模型训练、对比与精度评估。
(5)可视化展示功能:动态展示各类污染物指标、时序走势、统计结果与预测数据。
3.2 非功能性需求分析
(1)稳定性:集群与系统运行稳定,大数据任务、模型训练无异常中断,长期运行无崩溃。
(2)高效性:分布式处理效率远优于单机模式,海量数据清洗、统计、建模速度快。
(3)准确性:数据清洗规范,统计指标准确,预测模型误差低、拟合效果好。
(4)易用性:可视化界面简洁清晰,数据展示直观,操作便捷。
3.3 系统总体架构设计
本系统采用四层分层架构,整体解耦清晰、扩展性强,符合企业级大数据开发规范,具体架构如下:
1. 数据预处理层:采集公开空气质量时序数据集,通过Python完成精细化清洗、特征工程、格式标准化,生成高质量结构化数据。
2. 数据仓库存储层:基于Hive构建ODS、DWD、DWS、ADS四层数据仓库,依托HDFS实现分布式持久化存储与分层治理。
3. 大数据计算与建模层:通过Spark SQL实现多维数据分析统计,基于Spark MLlib完成机器学习模型训练、调优与预测。
4. 可视化应用层:通过ECharts可视化大屏展示统计指标、污染规律、时序走势与智能预测结果。
3.4 系统功能模块设计
系统整体划分为五大核心模块:数据预处理模块、Hive数仓治理模块、Spark大数据分析模块、空气质量智能预测模块、数据可视化模块。各模块独立解耦、相互联动,形成完整业务闭环。
第四章 系统详细设计与实现
4.1 大数据集群环境搭建
本系统基于CentOS7环境搭建Hadoop2.7、Spark2.4、Hive2.3大数据伪分布式集群,配置JDK1.8运行环境,关闭防火墙与SELinux,配置免密登录与静态IP,保障集群节点互通与任务调度稳定。依次完成Hadoop格式化启动、Hive元数据MySQL配置、Spark集群部署与组件适配,最终实现Hadoop、Spark、Hive三大组件联动运行,为数据处理、数仓建模与机器学习提供稳定算力支撑。
4.2 数据集介绍与预处理实现
本课题采用公开城市空气质量时序数据集,数据字段包含:监测时间、城市区域、PM2.5、PM10、SO₂、NO₂、CO、O₃、AQI空气质量指数、温度、湿度、风速、气压等多维特征。数据集时序跨度大、样本量大,适合大数据分布式处理与时序预测建模。
数据预处理核心流程:
1、去重处理:根据监测时间与区域唯一字段剔除重复样本,保证数据唯一性;
2、缺失值处理:核心污染物与气象特征缺失样本直接删除,次要字段采用均值填充;
3、异常值过滤:通过箱线图算法识别并过滤极端异常污染数据,避免干扰模型训练;
4、特征筛选:保留与AQI强相关的污染物与气象特征,剔除冗余无效字段;
5、归一化处理:对量纲不一致的数值特征进行归一化,提升模型收敛速度与拟合精度。
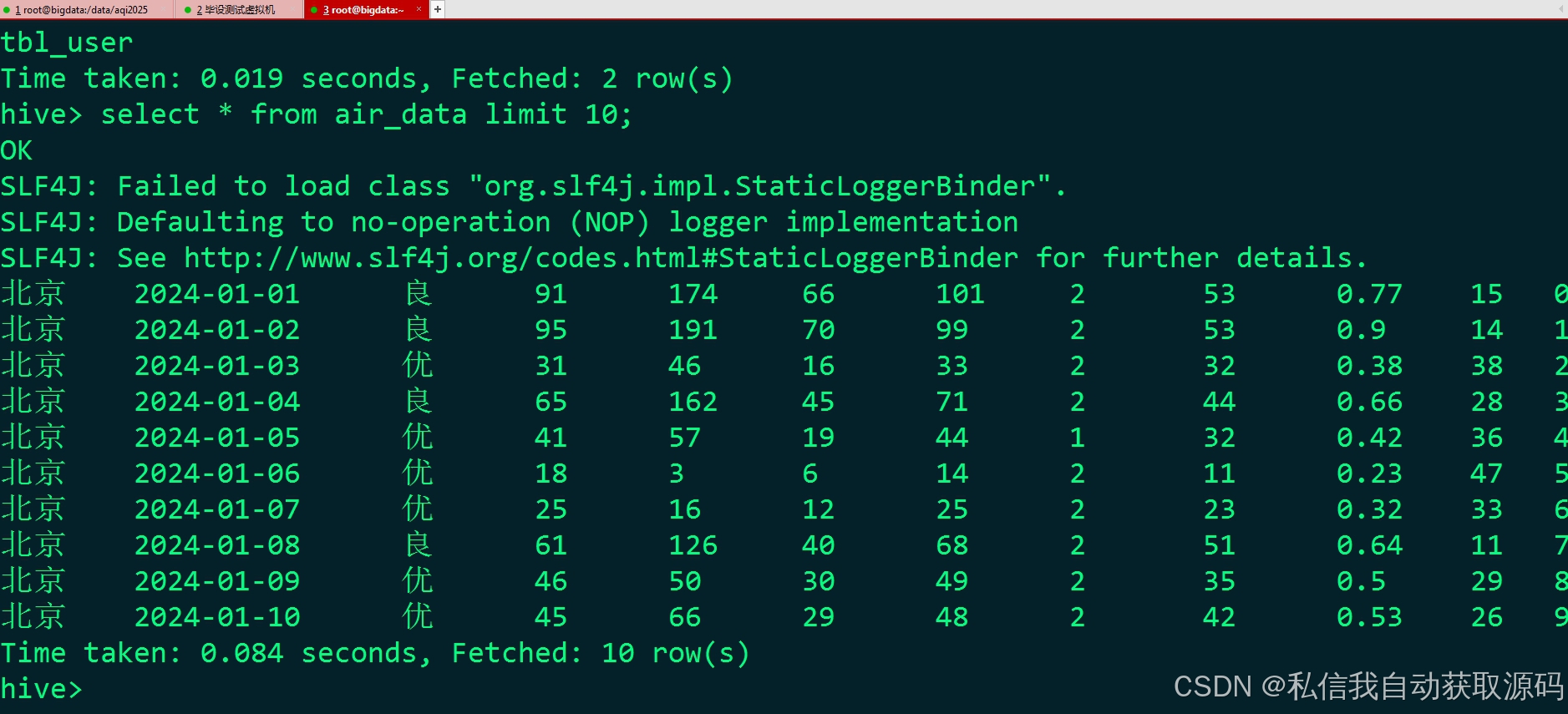
4.3 Hive四层数据仓库设计与实现
4.3.1 ODS原始数据层
原样导入预处理前的原始空气质量数据,不做任何修改,完整保留原始样本,用于数据溯源、备份与对比校验,保障数据可追溯。
4.3.2 DWD明细数据层
存储清洗后的高质量明细数据,完成去重、去异常、缺失值修复与格式统一,形成标准化明细业务数据,为上层聚合分析与建模提供基础数据源。
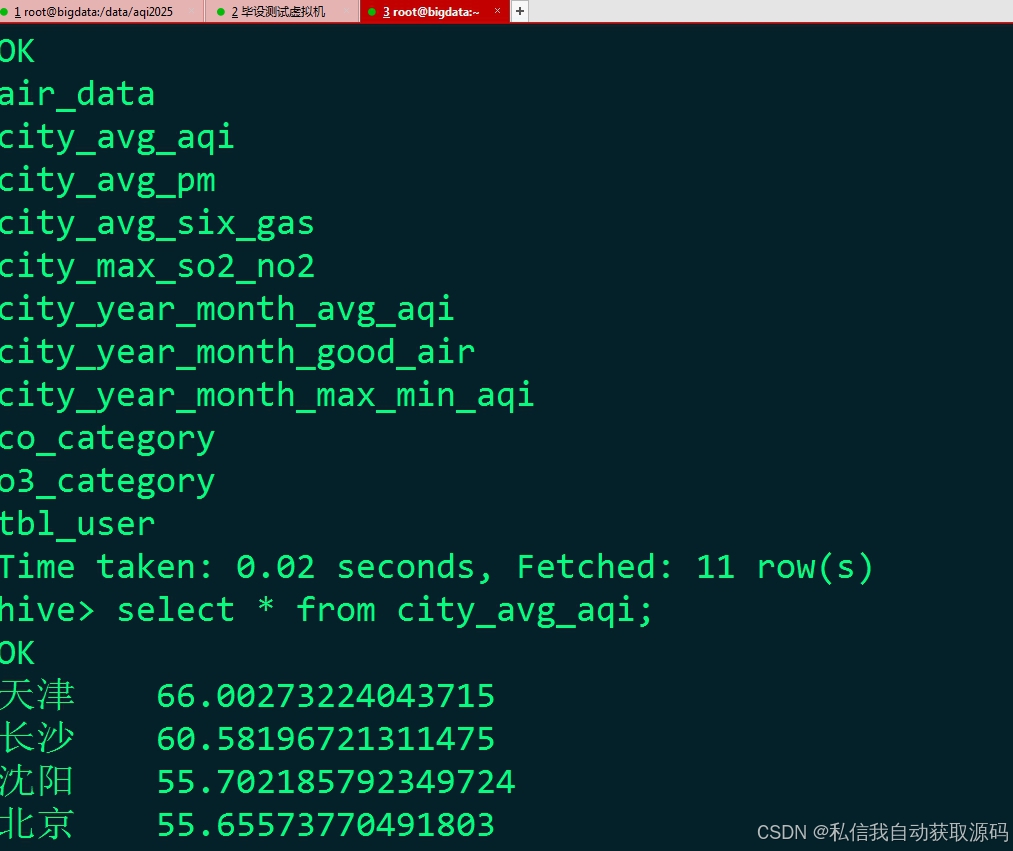
4.3.3 DWS聚合统计层
基于DWD明细数据,按月份、季节、时段、天气类型进行多维聚合统计,生成各维度下的污染物均值、极值、AQI分布、气象特征均值等统计指标,沉淀分析中间数据。
4.3.4 ADS应用数据层
存储可直接用于可视化展示与模型训练的最终数据,包含统计报表数据、建模特征数据集、预测结果数据,减少系统重复计算,提升页面加载与模型迭代效率。
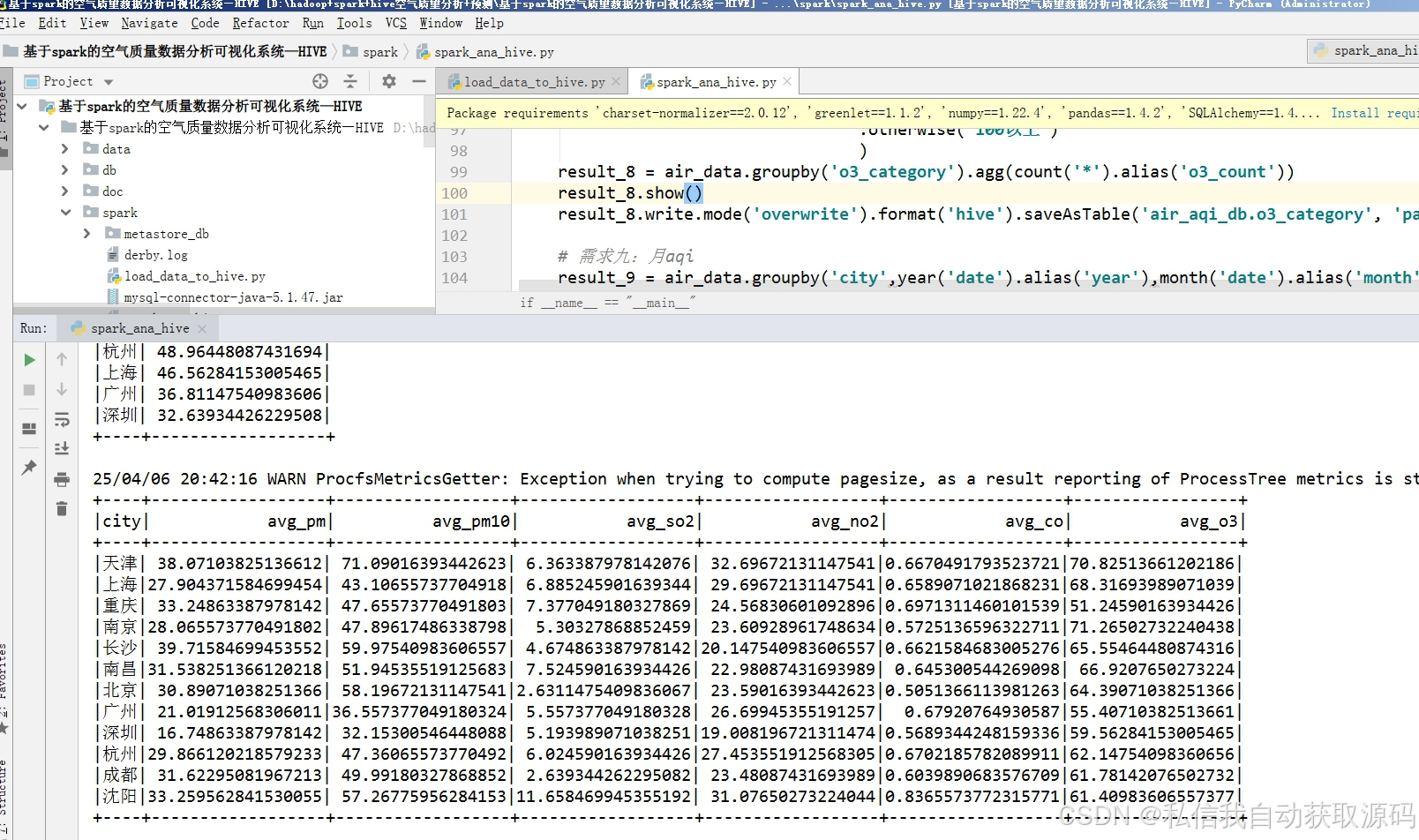
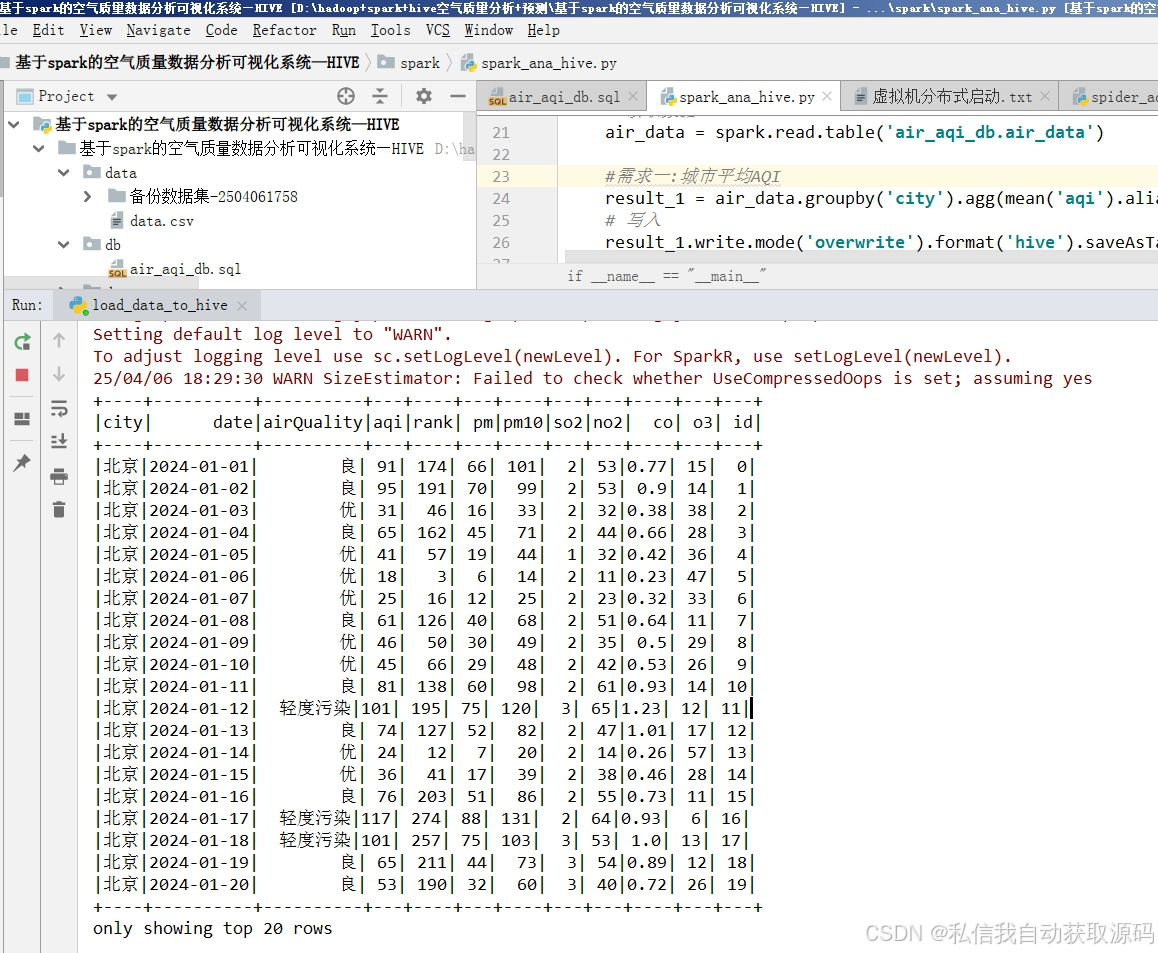
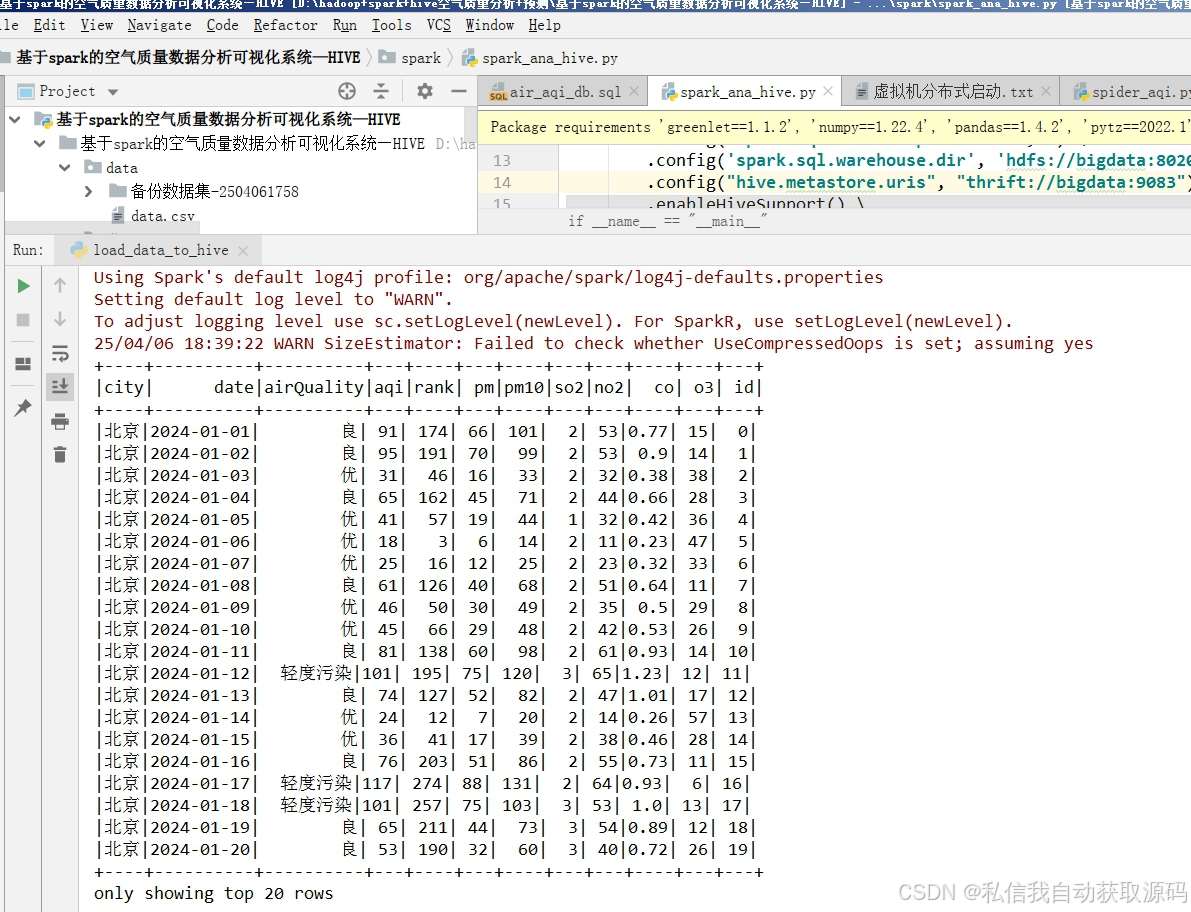
4.4 Spark多维数据分析实现
本系统通过Spark SQL读取Hive分层数据表,开展多维度空气质量大数据挖掘分析,核心分析内容包括:
1、时序趋势分析:统计不同月份、季节的AQI均值与污染物浓度变化,分析空气质量时序演变规律;
2、气象关联分析:分析温度、湿度、风速对PM2.5、AQI的影响特征;
3、污染分布分析:统计不同空气质量等级的样本占比,分析城市整体污染状况;
4、特征相关性分析:挖掘各污染物之间、气象与污染指标之间的关联关系。
Spark基于内存计算,大幅提升海量时序数据的聚合统计效率,有效解决传统Hive批量计算延迟高、迭代慢的问题。
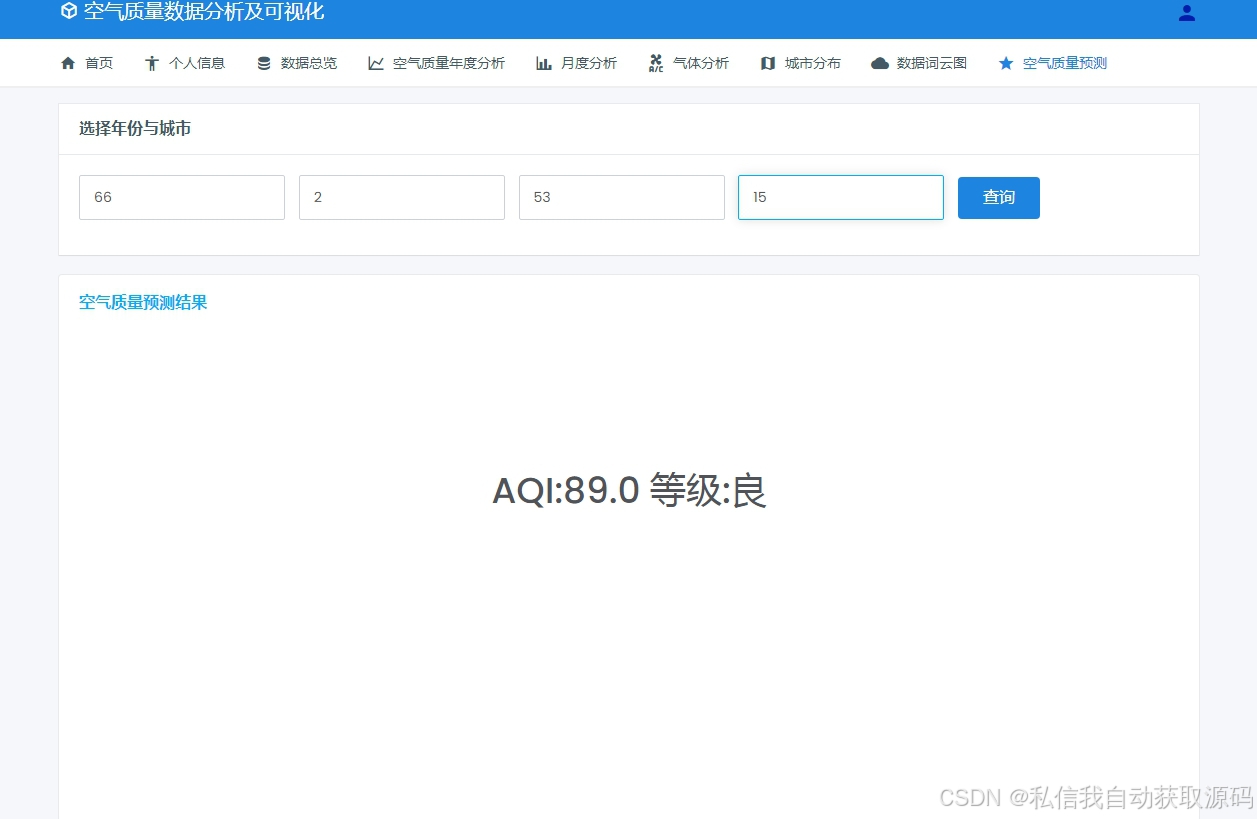
4.5 空气质量预测模型设计与实现
4.5.1 模型训练流程
本系统基于Spark MLlib完成模型训练,整体流程:数据集划分(7:3训练集、测试集)→ 特征向量化与标准化 → 模型初始化 → 迭代训练 → 超参数调优 → 模型评估与对比 → 最优模型保存。
4.5.2 多元线性回归模型实现
将筛选后的多维特征作为自变量,AQI指数作为因变量,构建多元线性回归模型,拟合特征与空气质量的线性关联关系,作为基线预测模型,用于对比实验。
4.5.3 随机森林模型实现
利用随机森林集成学习特性,挖掘多特征与AQI的非线性映射关系,通过调整决策树数量、树深度、采样比例等超参数优化模型效果,提升预测精度与泛化能力。
4.6 可视化大屏实现
系统后端通过Spark SQL统计生成结构化指标数据,前端采用ECharts实现可视化渲染,包含空气质量时序折线图、污染物分布柱状图、等级占比饼图、气象关联分析图、模型预测结果展示模块,界面简洁直观、数据动态更新,实现空气质量数据全方位可视化呈现。
第五章 系统测试与实验结果分析
5.1 测试环境
操作系统:CentOS7、Windows10;开发环境:IDEA、PyCharm;集群组件:Hadoop2.7、Spark2.4、Hive2.3;开发语言:Python、SQL;可视化技术:ECharts、JavaScript。
5.2 功能测试
对系统数据预处理、数仓入库、大数据分析、模型预测、可视化展示五大模块进行逐项功能测试。测试结果表明,各模块功能运行正常,数据清洗准确、数仓分层清晰、统计指标无误、模型训练正常、图表渲染流畅,系统整体功能完整,满足设计需求。
5.3 模型评价指标
本文采用均方误差(MSE)、平均绝对误差(MAE)、决定系数(R²)作为模型评价指标。MSE与MAE数值越小代表预测误差越低,R²越接近1代表模型拟合效果越好、泛化能力越强。
5.4 实验结果对比分析
通过双模型对比实验可知,多元线性回归模型结构简单、训练速度快,但无法拟合复杂非线性污染规律,预测误差偏大、拟合度较低。随机森林模型依托集成学习优势,充分挖掘气象与污染物多维特征的非线性关联,MSE、MAE指标显著降低,R²指标明显提升,整体预测精度与稳定性远优于线性模型,能够精准实现城市空气质量趋势预测。
5.5 性能测试分析
相较于传统单机处理方案,本系统基于Spark分布式架构,海量时序数据清洗、统计、建模效率大幅提升,集群资源利用率更高,无数据倾斜、任务卡顿等问题,系统稳定性与运算性能优势显著。
第六章 总结与展望
6.1 研究总结
本文针对传统空气质量分析预测系统算力不足、数据治理不规范、预测精度低、系统碎片化等问题,基于Hadoop+Spark+Hive完整大数据生态,设计并实现了空气质量大数据分析与智能预测系统。完成了大数据集群搭建、时序数据精细化预处理、四层Hive数仓建模、Spark多维大数据分析、双模型智能预测、可视化大屏开发等全套工程实现。
实验测试表明,本系统能够高效处理海量环境时序数据,数据治理规范、数据分析维度丰富,随机森林模型预测精度优良,系统运行稳定、功能完整。有效解决了传统研究的技术短板,实现了环境大数据价值深度挖掘与智能预测落地,可为城市生态环境治理与空气质量预警提供技术支撑,同时具备较高的工程实践与教学研究价值。
6.2 未来展望
本系统仍存在可优化与拓展空间,未来可从以下方向迭代完善:
1、引入LSTM、GRU时序深度学习模型,进一步挖掘空气质量时序演变规律,提升长周期预测精度;
2、新增网络舆情、天气预报、人流车流等多源数据,丰富特征体系,提升模型泛化能力;
3、开发实时数据采集与实时计算模块,实现空气质量实时监测与动态预测;
4、新增污染溯源、权重分析、异常预警功能,进一步提升系统智能化与实用价值。
参考文献
[1] 林子雨. 大数据技术原理与应用[M]. 人民邮电出版社,2022.
[2] 王松. Hadoop大数据开发实战[M]. 机械工业出版社,2023.
[3] 陈峰. Spark大数据分析与机器学习实战[M]. 清华大学出版社,2022.
[4] 李刚. Hive数据仓库建模与优化技术[J]. 计算机工程与应用,2024.
[5] 张磊. 基于随机森林的城市空气质量预测模型研究[J]. 环境科学与技术,2023.
[6] 王浩. 基于Spark的空气质量大数据分析与预测[J]. 计算机技术与发展,2024.
[7] 刘阳. 城市空气质量时序数据特征挖掘与预测研究[J]. 大数据与人工智能,2025.
[8] 赵鑫. 基于机器学习的AQI空气质量预测算法优化[J]. 环境工程学报,2024.
[9] 成国庆, 伯鑫. 基于多源异构数据的大气环境管理平台构建[J]. 环境科学研究,2024.
[10] 陈明. 大数据环境下时序数据仓库建模与优化[J]. 软件工程,2023.
[11] Marjan A, Farzaneh Z. Predictive mapping of urban air pollution using Apache Spark on a Hadoop cluster[C]. ACM,2020.
[12] Liu X, Wang Y. Research on temporal and spatial prediction of air quality based on big data fusion[J]. Journal of Environmental Informatics,2023.
致谢
时光荏苒,本科学习生涯即将落幕。在此,我谨向所有给予我指导、帮助与支持的老师、同学与家人致以诚挚的谢意。
首先,衷心感谢我的指导老师,从课题选题、方案设计、技术实现到论文撰写修改,老师都给予了我细致、专业的指导,帮助我理清研究思路、攻克技术难题,保障本课题顺利完成。老师严谨的治学态度、扎实的学术功底与求真务实的科研精神,让我受益匪浅。
其次,感谢在校期间所有授课老师的悉心教导,让我系统掌握了大数据、计算机相关专业理论与工程实践知识,为本次毕业设计的开展奠定了坚实基础。感谢身边同学与朋友的陪伴与互助,在学习与项目开发过程中相互交流、共同进步。
最后,感谢家人的默默支持与无私包容,让我能够全身心投入学习与项目研究中。本次毕业设计不仅是对本科四年学习成果的总结,更是自我提升、积累工程经验的重要过程。未来我将继续深耕大数据技术领域,不断学习、持续进步。
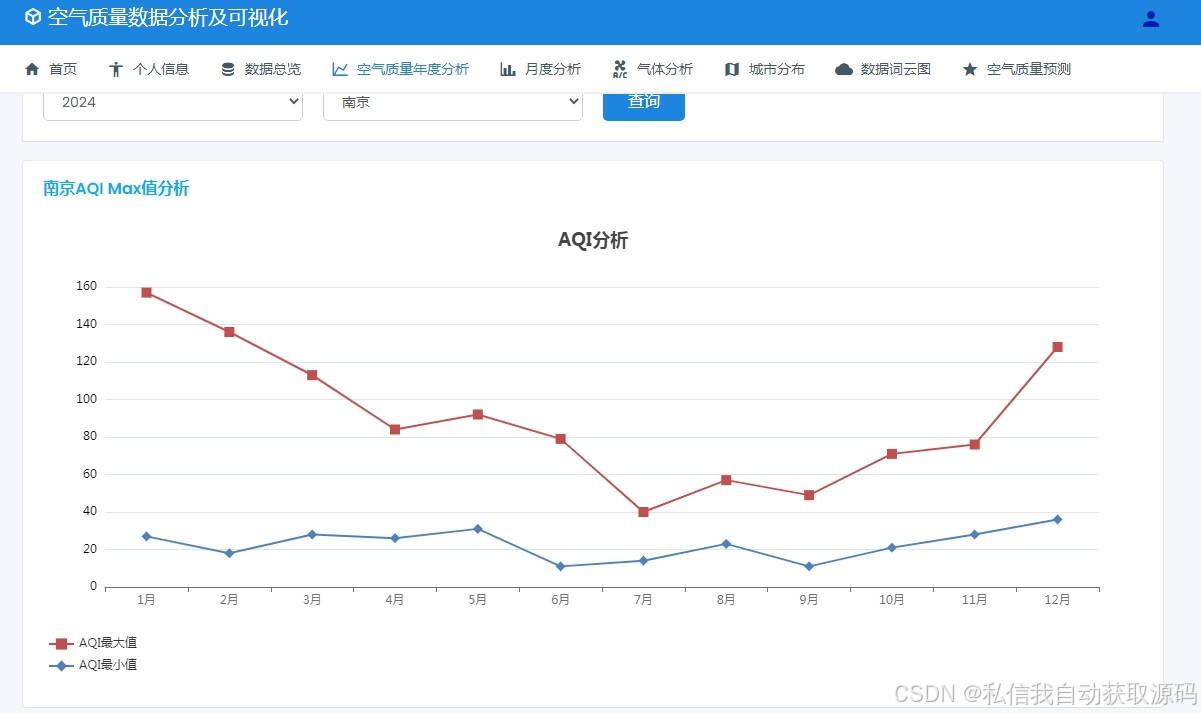
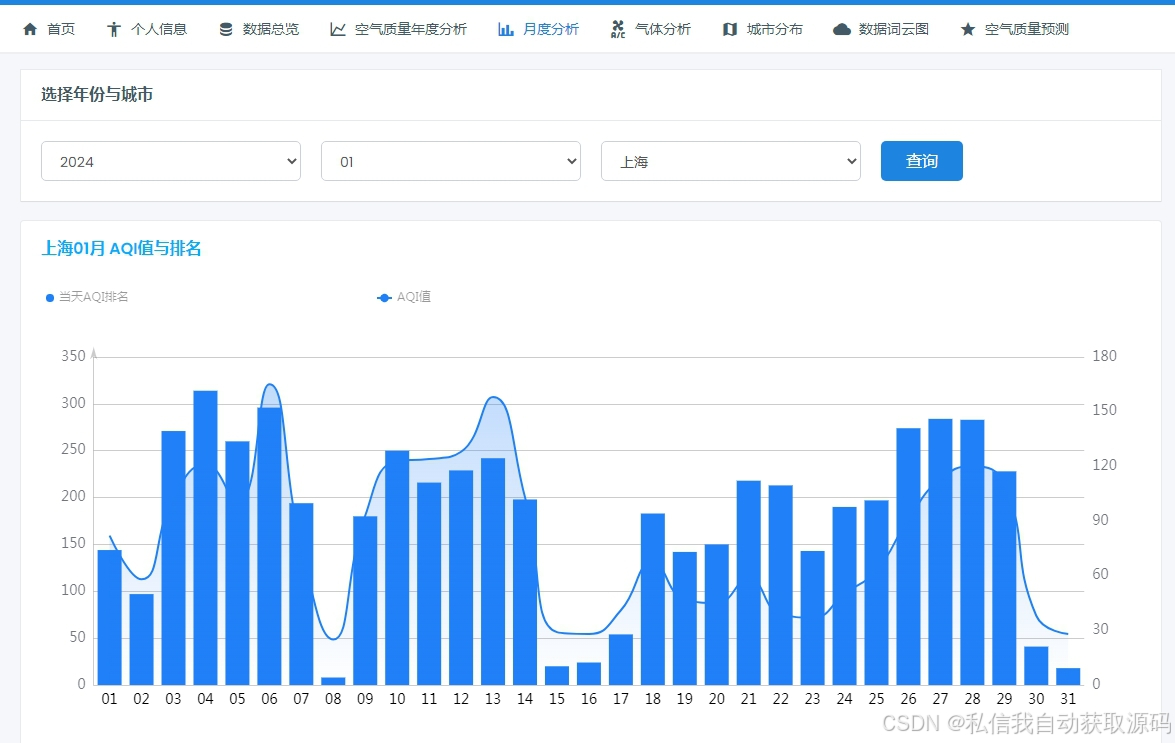
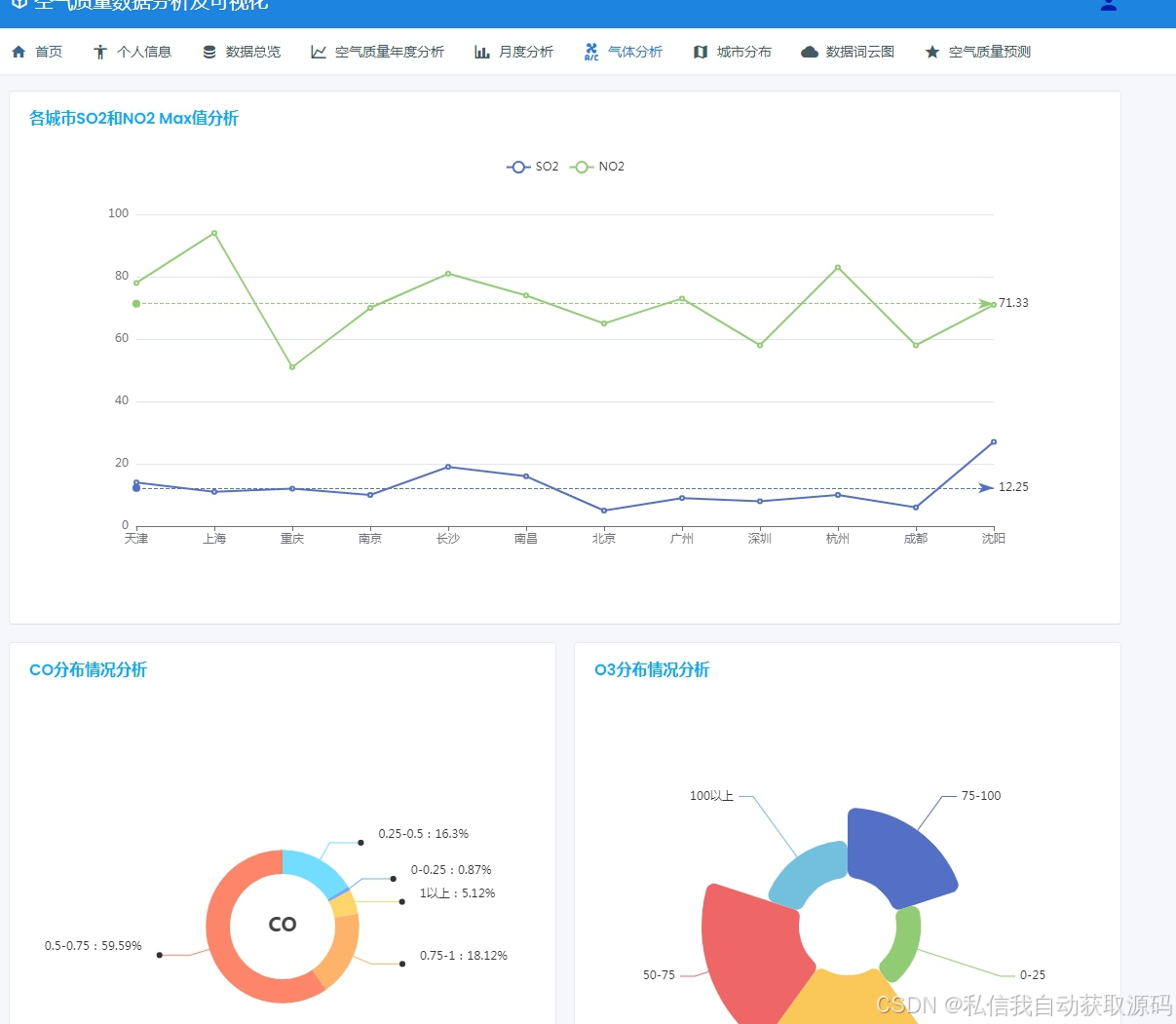
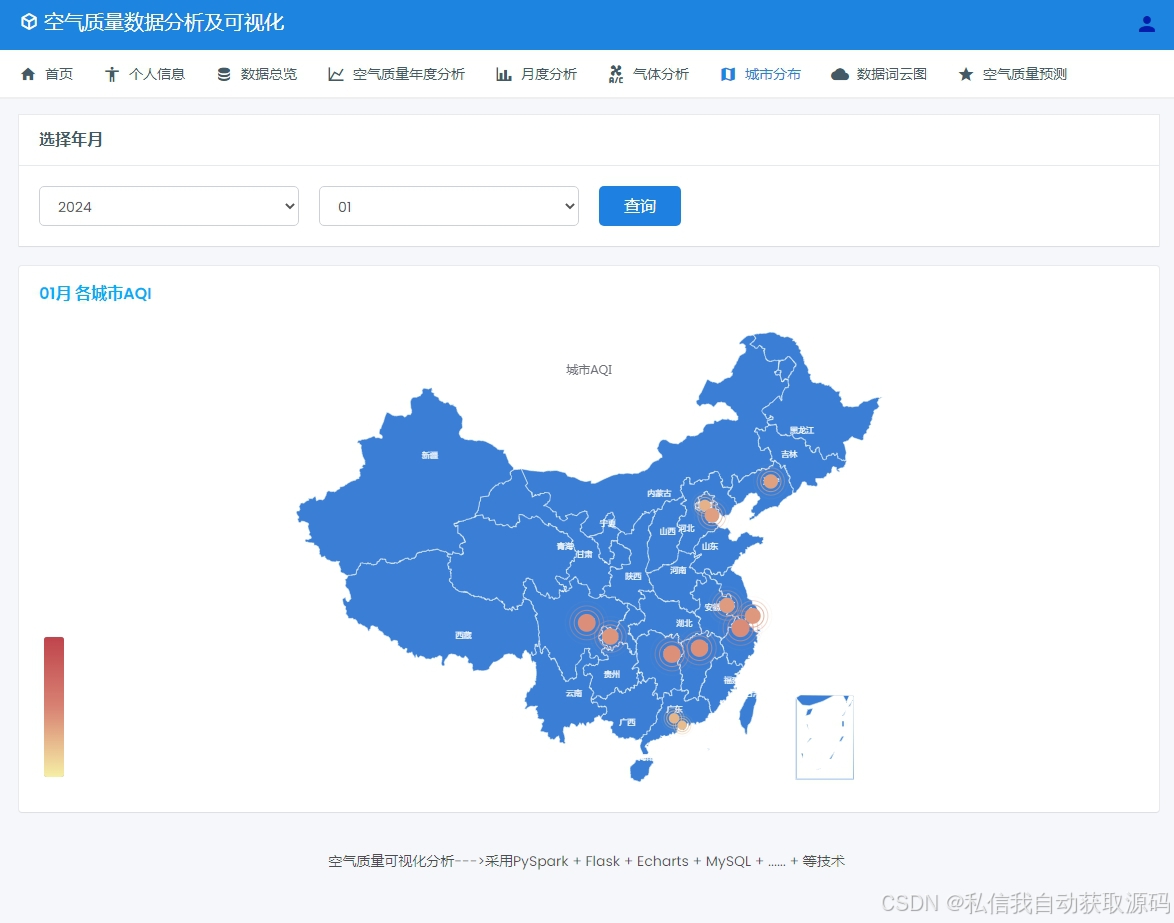
运行截图

推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,本人主页置顶文章(点我)开头有 CSDN 平台官方提供的学长联系方式的名片。🍅
点赞、收藏、关注,不迷路

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献319条内容
已为社区贡献319条内容

所有评论(0)